
结合注意力与循环神经网络的专家推荐算法
2022-09-15 10:27:44吕晓琦陈贞翔孙润元李浥东
计算机与生活 2022年9期
吕晓琦,纪 科+,陈贞翔,孙润元,马 坤,邬 俊,李浥东
1.济南大学 信息科学与工程学院,济南 250022
2.济南大学 山东省网络环境智能计算技术重点实验室,济南 250022
3.北京交通大学 计算机与信息技术学院,北京 100044
互联网将全球信息互连形成了信息时代不可或缺的基础信息平台,其中知识分享服务已经成为人们获取信息的主要工具。为了加快互联网知识共享,出现了大量以知乎为代表的问答社区。用户注册社区后可交互式提出与回答问题,达到知识共享和交换。然而,伴随用户急剧增多,平台短时间内积攒了数目巨大、类型多样的问题,远远超过有效回复数,严重降低了用户服务体验。如何将用户提出的问题有效推荐给可能解答的用户,以及挖掘用户感兴趣的问题是这些平台面临的严重挑战。这种情况下,工业界和学术界对以上问题开展了广泛研究,提出了一些针对问答社区的专家推荐方法提高平台解答效率。
现有工作大多利用基于内容的推荐算法解决该问题,比如配置文件相似性、主题特征相似性等,匹配效果依赖于人工构建特征的质量。近年来,以卷积神经网络(convolutional neural network,CNN)、Attention 注意力机制为代表的深度学习技术不断发展,并且已经成功应用到文本挖掘领域。相比传统方法,深度模型可以学习到表达力更强的深度复杂语义特征。于是,出现了一些深度专家推荐算法,比如DeepFM、XDeepFM、CNN-DSSM等,大幅提升了传统推荐算法的准确度。
虽然以上工作很好地实现了专家推荐,但都是根据用户长期关注的话题及相关解答历史刻画用户兴趣,产生的推荐结果也相对固定。随着时间推移,用户会不断学习新知识,其关注点及擅长解答的问题也很可能发生改变,由此会产生用户兴趣变化,甚至短期兴趣漂移。这些动态变化会严重影响推荐算法效果,因此如何动态刻画用户兴趣就显得尤为重要。其实,用户历史回答行为具有明显的时间序列关系,通过对已解答问题的序列分析有很大可能感知用户兴趣变化。近年来,循环神经网络(recurrent neural network,RNN)被广泛用来处理序列数据,比如长短期记忆网络(long short-term memory,LSTM)、门控循环单元(gated recurrent unit,GRU)等,可以根据前面状态输入结合当前模型状态产生当前输出。该类方法可与CNN 结合处理问题内容序列数据,从用户历史解答行为中挖掘长期与短期兴趣,从而动态产生当前兴趣。
综合以上讨论,本文提出了结合注意力机制与循环神经网络的问答社区专家推荐算法,能够根据用户历史解答序列动态构建用户兴趣特征,实现推荐结果随时间发展不断调整。
主要工作与贡献如下:
(1)基于预训练词嵌入模型分别实现了问题标题与主题标签的语义嵌入向量表示,将CNN 卷积模型与Attention 注意力机制结合,构造基于上下文的问题编码器,生成不同距离上下文的深度特征编码。
(2)问题编码器对用户历史回答的问题进行序列编码,利用长短期记忆循环神经网络Bi-GRU 模型处理编码后的问题序列,并结合用户主题标签嵌入向量构造用户兴趣动态编码器。
(3)将问题与用户编码器产生的深度特征点积运算后加入全连接层实现相似度计算产生推荐结果。在知乎公开数据集上的对比实验结果表明该算法性能明显优于目前比较流行的深度学习专家推荐算法。
1 相关工作
1.1 推荐系统
“信息过载”是互联网发展过程中面临的巨大挑战,人们通过网络接触到大量冗余信息,远远超过个人能力。推荐系统是解决这一问题最有效的技术,已经广泛应用到许多领域,实现了有价值信息的快速甄别及个性化服务。目前,应用比较流行的推荐算法有基于内容的推荐算法、基于协同过滤的推荐算法、混合推荐等。基于内容的推荐算法是推荐系统最早采用的算法,具有很好的解释性,核心思想是利用交互历史构建用户兴趣特征,根据用户兴趣和项目的特征相似性产生推荐结果。协同过滤算法根据用户与项目之间的显性与隐性交互信息构造矩阵模型,利用矩阵中相似用户和项目的历史评分数据预测当前用户对给定项目的偏好程度。混合推荐算法可将已有算法进行组合弥补各自推荐技术的弱点。
1.2 专家推荐
专家推荐是推荐系统的一种特殊应用,用于发现特定领域中具有解决问题能力的专家用户。科研人员针对问答社区的专家推荐问题开展了一系列研究。早期工作主要依靠传统信息检索技术。后来,很多工作提出了基于内容的推荐算法解决该问题,主要根据用户兴趣与问题内容的特征匹配程度产生推荐结果。其中,自然语言处理技术常被用来进行信息提取,比如隐含狄利克雷分布主题模型(latent Dirichlet allocation,LDA)可以形成隐含语义主题分布特征来表征信息,但训练数据不足时其表示能力会减弱。后续研究将相似性计算转化为分类问题,从问题-用户交互角度考虑了更多的内容特征。近年来,深度学习技术被应用到推荐系统,出现了一些基于神经网络的专家推荐算法,可以学习到表达力更强的语义特征,大幅提升了准确度,比如DeepFM将神经网络与传统因子分解机进行了结合;XDeepFM引入了压缩交互网络自动学习高阶特征交互;深度语义匹配模型(deep structured semantic models,DSSM)通过深度神经网络(deep neural networks,DNN)对文本进行语义降维表达及语义相似性计算;CNN-DSSM在DSSM 的基础上引入卷积层、池化层替代DNN 实现了上下文信息提取。
1.3 深度学习
深度学习是机器学习最热门的研究方向之一,已经在计算视觉、语音识别、自然语言处理等领域取得了巨大成功,其优势在于通过深层网络结构可以组合低层特征形成更加抽象的高层语义特征。典型深度学习模型有卷积神经网络CNN、循环神经网络RNN。CNN 是一种前馈神经网络,通过卷积层、池化层等结构可隐式地从训练数据学习到局部权值共享的特殊结构特征,代表模型有ResNet、VGGNet、TextCNN等。RNN 是一类擅长处理序列数据输入的神经网络,通过层与层之间连接实现了序列数据前后关联,适合挖掘序列数据中的动态时间行为,代表模型有LSTM、GRU等,后续逐渐衍生出更具特色的双向变体模型Bi-LSTM、Bi-GRU,可以灵活控制长短距离依赖信息。近年来出现了基于RNN和CNN 的复合神经网络,此外Attention 注意力机制也被引入到深度学习模型,可以灵活地捕捉全局和局部联系,使模型对特征有不同关注力。
2 问题定义
假设用P 表示问题集,U 表示用户集,p为P 中的一个问题样本,μ为U 中的一个用户样本。给定问题-用户对(p,μ),为它设置一个状态标签y∈{0,1},其中1 代表接受问题邀请并且回答,0 代表未接受问题邀请,(p,μ,y)是一个训练样本。根据上述定义,个训练样本就组成了训练数据集,如式(1)所示:
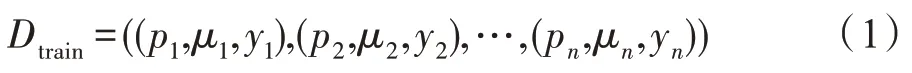
本文利用训练数据集构建模型,定义损失函数对模型进行优化,判断当前用户μ是否会接受某个新问题p邀请的标签y。

3 DSIERM 算法
本章介绍本文提出的专家推荐算法,将算法命名为DSIERM(dynamic and static interest based expert recommendation model),算法主要包括问题编码器与用户编码器两个核心部分,分别根据问题描述信息和用户历史解答行为构建问题和用户相对应的深度编码特征,结合用户动态兴趣与长期兴趣产生推荐结果。
3.1 问题编码器
用户提出一个问题后会形成问题标题,同时也会被绑定若干标签便于引起专家用户关注。问题编码器分别从问题标题和绑定标签学习特征向量产生最终的向量表示,其架构如图1 所示。

图1 问题编码器结构Fig.1 Structure of question encoder
根据数据集中的所有问题记录进行训练,构造问题编码器。
第一步,对问题的标题进行分词并执行词嵌入表示,将标题转换成隐含语义空间的词向量表示。假设标题中的词为=[,,…,t],代表标题长度,转化后的词向量表示如式(3)所示。

其中,代表词向量集合,为词嵌入方法。
第二步,使用CNN 卷积神经网络捕捉局部上下文信息来进一步优化词向量,假设用C表征T的上下文词表示,如式(4)所示。

其中,是位置在和+-1 之间单词的嵌入连接矩阵;和是CNN 卷积神经网络滤波器的参数;是窗口大小;是非线性激活函数ReLU。
第三步,由于不同的词对标题有不同的重要性,本文引入Attention 注意力机制为每个词赋予不同权重。假设第个词的注意力权重为A,计算方法如式(5)和式(6)所示。

其中,α是Attention 执行时的中间生成变量,和是可训练参数。问题标题的最终向量表示是带有权重的上下文词向量表征总和,如式(7)所示。

问题的绑定标签一般由提问用户自己设置,帮助锁定其他用户对当前问题的关注。假设当前问题的所有标签组成了集合=[,,…,g],是标签个数。输入,利用词嵌入实现每个标签的向量化表示=()=[,,…,G],然后对所有标签向量全局平均池化取平均值后形成标签向量表示q,如式(8)所示。

是池化平均参数矩阵,大小为·,是标签向量的维度。
给定第个问题,经过问题编码器,产生该问题的标题和绑定标签表示向量,两者拼接产生最终问题向量表示Q,如式(9)所示。

3.2 用户编码器
用户回答问题的时间序列反映了用户兴趣变化,可以据此分析用户动态兴趣。此外,用户也会选择一些标签主动展示自己的兴趣,并且用户标签相对固定,很长时间都不会发生变化,可以反映用户长期固定兴趣。用户编码器分别从解答行为序列和用户标签学习特征向量组成最终的用户向量表示,架构如图2 所示。

图2 用户编码器结构Fig.2 Structure of user encoder
结合数据集中的用户记录和问题记录,构造用户回答序列,并从用户记录中提取用户相关信息进行训练,构造用户编码器。
挖掘当前用户回答过的问题,首先,把它们按照回答时间先后排列为=[,,…,I],其中为该序列长度;然后,利用3.1节的问题编码器对每个问题进行编码获取它们的问题向量表示=[,,…,Q];最后,把序列输入双层Bi-GRU 网络结构来捕捉用户动态兴趣变化。

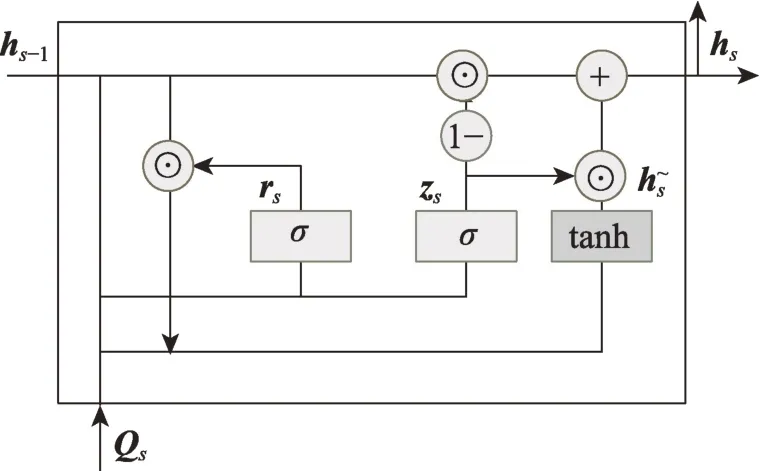
图3 GRU 模型结构Fig.3 Structure of GRU model

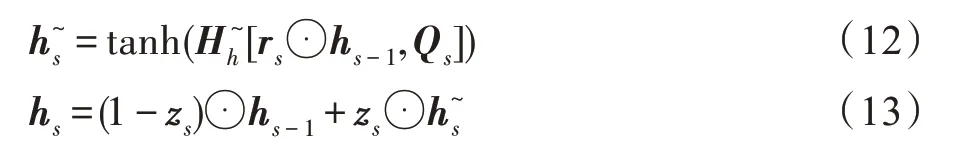
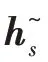
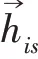
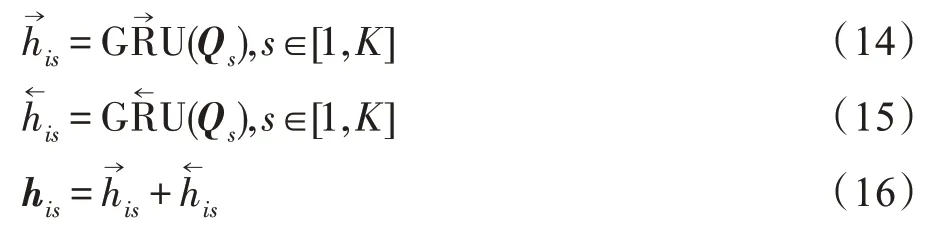
将第一层Bi-GRU 的所有隐层状态输出h(∈[1,])输入第二层Bi-GRU 获得更细粒度的动态表征,与第一层Bi-GRU 不同的是,第二层仅输出最具代表性的最后一个隐层状态h,作为给定用户当前的兴趣表示u=h。计算方式同式(10)~(16)。

问答序列可以捕捉到随时间变化的用户动态兴趣,标签信息可以提取到用户长期兴趣。用户动态兴趣和用户长期兴趣拼接后形成最终的用户表示向量,如式(17)所示。

3.3 最终训练与预测
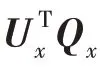

图4 判断当前用户是否会接受此问题Fig.4 Determine whether current user will accept the given question
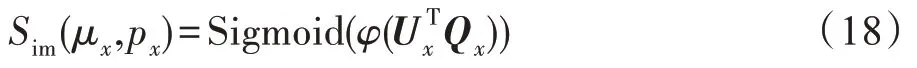
其中,为全连接层函数,激活函数为ReLU,并且可以设置为多个全连接层叠加结构将高维稀疏特征压缩映射到低维稠密特征。
4 实验
4.1 数据集
本文实验数据集来自知乎(https://www.zhihu.com)、被开放biendata 平台(https://www.biendata.xyz/competition/zhihu2019/)。知乎是中文互联网知名的问答社区,用户分享彼此知识,解答感兴趣问题,为互联网源源不断地提供多种多样原始信息。原数据集包括知乎的问题信息、用户画像、用户回答记录、用户接受问题邀请等信息,根据所提出的算法需求提取相关数据。表1 展示了数据集的基本统计信息,包括1 931 654 个用户描述记录(其中包括回答过的问题序列编码和用户配置资料)、1 829 900 个问题描述记录、500 000 个问题邀请记录、所有问题绑定标签和用户配置标签共形成的100 000 个主题标签。数据集按照一定比例划分为训练集和测试集,每次实验采用5 折交叉验证。

表1 数据集基本统计Table 1 Basic statistics of dataset
4.2 基线方法
本节将本文提出的算法DSIERM 和以下三个基准专家推荐算法进行性能比较:
(1)DeepFM是在因子分解机(factorization machines,FM)基础上衍生的算法,将深度神经网络(DNN)与FM 结合,同时提取到低阶和高阶特征,通过学习隐式的特征交互预测用户行为。
(2)XDeepFM是DeepFM 的改进,增加了压缩交互网络结构(compressed interaction network,CIN),以显式与隐式结合的方式学习高阶特征交互,侧重特征交叉带来的预测收益。
(3)CNN-DSSM是一种深度语义匹配模型,通过CNN 卷积层提取了滑动窗口下的上下文信息,并利用池化层提取了全局的上下文信息,根据上下文语义向量匹配度预测用户行为。
对比实验中本文还设置了该算法的另一种配置方式:
DSIERM-OS(only use static component)没有 考虑长期用户兴趣表示模块,仅使用动态兴趣表示模块,用来验证长期用户兴趣的辅助作用。
4.3 评价指标
实验部分本文综合利用AUC(area under the ROC curve)、ACC(accuracy)和Logloss 指标来评价算法预测效果:
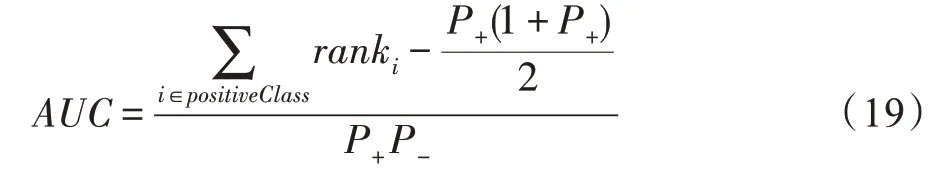
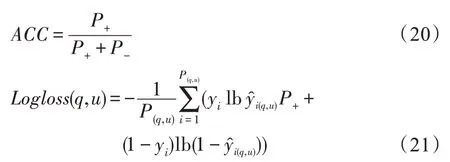

本文的实验环境如下:硬件配置IntelCorei7-9750H CPU@2.60 GHz+8 GB 内存;Windows10 X64位操作系统;深度学习框架Anaconda Python3.0+Tensorflow+Keras。
4.4 参数设置
将标题和标签的词嵌入都置于同一个向量空间,维度设置为64。CNN 卷积神经网络过滤器数量为64,窗口大小设置为3。Bi-GRU 设置了两层结构,神经元节点大小分别设置为128、32。对于问题和用户编码器输出向量的点积结果,最多设置了5 层全连接结构,其神经元节点大小依次是1 024、512、256、128 和64。对于参数最优化结构的实验在下文详述。在实验过程中,采用Adam 优化器,批处理大小设置为2 048,学习率设置为0.000 1。
4.5 实验结果
本节将所提出的算法与其他基准算法进行对比。图5 展示了本文算法DSIERM 在全连接层结构层数选择上的实验结果:过少的结构不利于提取稠密特征信息,过多的全连接层反而可能导致过拟合的状况,综合考虑把最终训练与预测时的全连接层结构固定为5 层。图6 展示了所有算法在不同迭代次数下的预测结果:随着迭代次数增加,算法性能不断提升,第4 次迭代后性能提升已经不明显,考虑到计算花销,接下来的实验将固定Epoch=4。图7 展示了不同比例训练数据下算法的预测结果:当采用10%训练数据时,算法依然可以达到一定精度,说明借助预训练好的词嵌入向量可以将其他知识迁移进来,保证算法具有稳定性,克服数据稀疏性问题;随着训练数据增加,算法性能不断提升,说明训练数据越多,算法构建的模型越准确,更能准确表示用户兴趣。

图5 不同全连接层结构的性能变化Fig.5 Performance changes under different FC layers
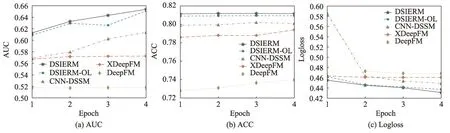
图6 不同Epoch 的性能变化Fig.6 Performance changes under different epochs
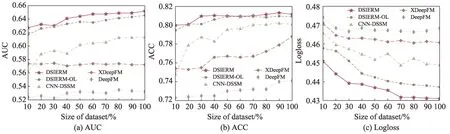
图7 不同比例训练数据的性能变化Fig.7 Performance changes under different proportions of training data
表2 展示了所有算法在30%、70%、100%比例的训练数据上取得的实验结果。对比后发现:首先,DeepFM 算法效果最差,原因在于其人工选取特征的方法效率较低,会损失一些特征信息;然后,XDeepFM算法效果要明显优于DeepFM,压缩交互网络的引入可以自动学习高层特征交互,验证了特征交互可以更好地实现特征表示;其次,CNN-DSSM 算法效果要优于XDeepFM,主要因为其滑动窗口特征表示方式使较多上下文信息得到保留,验证了上下文信息对特征表示的重要性;最后,总体上看本文提出的两个算法要明显优于以上基准算法,验证了用户回答问题的时序关系有助于发现用户动态兴趣,并且DSIERM 要优于DSIERM-OS,说明动态兴趣与长期固定兴趣结合可以更好地表示用户兴趣。另外,问题编码器是本算法中最基本的底层结构,其学习到的特征向量不仅作为问题特征表示,还作为用户编码器的问题序列输入用来学习用户动态兴趣表示,因此问题编码器的输出会严重影响最终预测结果。问题编码器的原始输入是问题标题和问题绑定标签,基于此本文设置了三组不同输入的对比实验(输入标签、输入标题、输入标签和标题的组合)来验证不同输入特征引起的编码效果的不同。由于实验仅验证问题编码器的效果,用户编码器无关变量需要去除,即仅使用用户编码器的动态兴趣表示模块进行接下来的实验。图8 展示了三组实验在不同指标下的结果,对比结果后发现:由于标题比标签携带更多信息,把标题作为编码器的输入要比考虑标签学习到更好的特征向量;综合考虑标题和标签组合要比单独考虑标签或者标题的使用有更好的表示效果,同时也证明了多样化的信息引入有助于优化特征表示。

图8 不同输入信息对问题编码器的影响Fig.8 Influence of different input information on question encoder
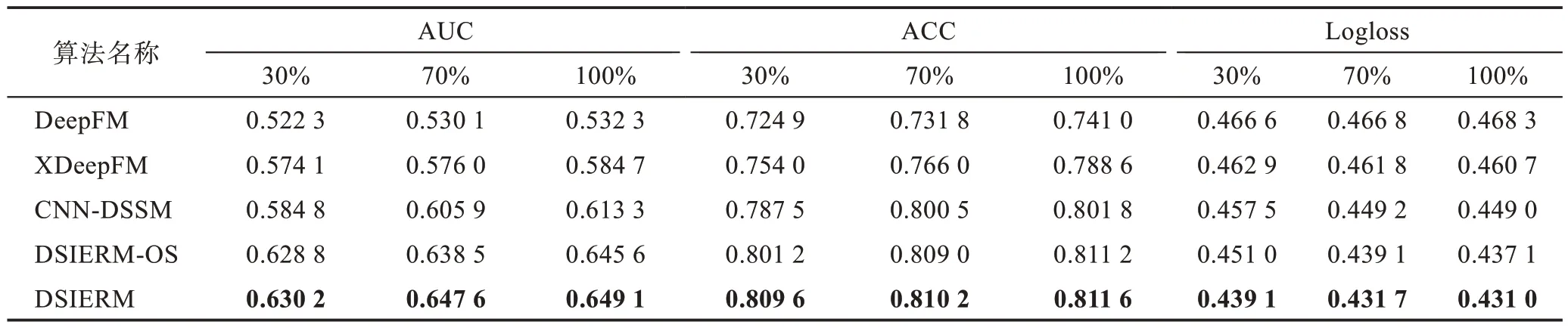
表2 不同比例训练数据上所有算法的实验结果比较Table 2 Comparison of experimental results of all algorithms on different proportions of training data
5 结论
问题数量大、解答效率低是互联网问答社区面临的严重挑战,本文提出了结合注意力与循环神经网络的专家推荐算法(DSIERM)来解决此难题。该算法包含问题编码器和用户编码器两大核心部分。问题编码器实现了问题标题与绑定标签的深度特征联合表示。用户编码器在用户历史回答问题的时间序列上捕捉到动态兴趣,并结合用户固定标签信息表征长期兴趣。最后的推荐结果根据问题与用户编码器输出向量的相似性计算,同时考虑了用户动态兴趣与长期兴趣两方面内容。在来自知乎社区的真实数据上设置了多组对比实验,结果表明该算法性能优于目前比较流行的深度学习专家推荐算法,显著提升了推荐准确度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
车迷(2018年11期)2018-08-30 03:20:32
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子设计工程(2017年20期)2017-02-10 03:39:29
公民与法治(2016年10期)2016-05-17 04:12:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
电子器件(2015年5期)2015-12-29 08:42:24
新高考·高二数学(2015年11期)2015-12-23 18:17:44
