
基于云边端协同垃圾分类检测系统的设计和实现
2022-09-13 11:01:36周原
河北软件职业技术学院学报 2022年3期
周 原
(闽江师范高等专科学校 数字信息工程学院,福州 350018)
0 引言
随着人们消费能力的日益增强和生活节奏的不断加快,消费物品种类和数量呈急剧上升趋势,产生了越来越多的生活垃圾和工业垃圾,城市生活的垃圾量、清理量不断加大,给城市垃圾的管理和处置带来了巨大的压力[1]。垃圾分类在助力环保、资源回收以及降低人工分拣成本等方面起到了重要作用。但是垃圾分类的落地并不理想,错误投放垃圾,导致垃圾分类的难度增大,人力分拣垃圾成本高,影响了垃圾分类的全面推广。
随着计算机视觉和深度学习的发展,计算机系统已经能够高质量地对物体进行正确识别。将计算机视觉中目标检测技术应用于垃圾分类领域能够极大地解决垃圾分类成本高的问题。从垃圾生产端来看,垃圾分类系统能够帮助识别垃圾种类,指导垃圾的正确投放。从处理垃圾的工厂端来看,自动化垃圾识别分类能提高自动化水平,降低人工分拣成本。智能垃圾分类助力减少垃圾对环境的污染,将垃圾变废为宝。由此可见,智能垃圾分类的应用普及是必然趋势。
目前,智能垃圾分类的应用集成了计算机视觉、深度学习和机器人技术等。来自加拿大的分类垃圾桶Oscar,通过人工智能摄像头和显示屏,帮助识别不同垃圾应该投入哪个对应垃圾桶里。垃圾分拣系统Zen Robotics Recycler(ZRR)机器人以平均每小时3000件的速度全自动分离各种垃圾,可以识别纸板、金属、木材、石膏、石块、混凝土等20余种可回收垃圾。FANUC分拣机器人Waste Robot能够对物品的化学成分以及形状进行实时扫描和分析,利用视觉分析系统对物品进行跟踪和判断,驱动机械臂实时抓取物品进行分类。
基于深度学习和计算机视觉技术,将人工智能中的物体检测应用于垃圾分类领域,设计并实现基于云边端协同的垃圾检测系统,从垃圾数据采集和预处理,到配置神经网络模型,并将模型部署在硬件开发板上,实现理论研究到生产实践落地的整个过程。
1 总体结构设计
基于视觉的垃圾检测系统包含三部分:数据准备与预处理;模型训练与评估;模型转换与边缘部署。“云、边、端”协同开发流程如图1所示。
数据的准备和预处理包括:数据采集和标注,划分训练数据集和测试数据集,配置标签文件,将训练数据集转换为符合Caffe框架训练要求的lmdb格式的数据库文件。对模型进行训练和评估包括:环境和框架配置、Caffe solver超参数设置、模型训练和模型评估。对模型进行转换和边缘部署主要是为了实现在边缘端的应用,通过摄像头采集垃圾物体数据,对采集数据预处理,进行模型推理得到结果,并将结果通过驱动QT界面反馈,将分类结果显示在平板的屏幕上。通过基于云边端协同垃圾分类检测系统实现智能垃圾分类,助力降低人工分拣成本。
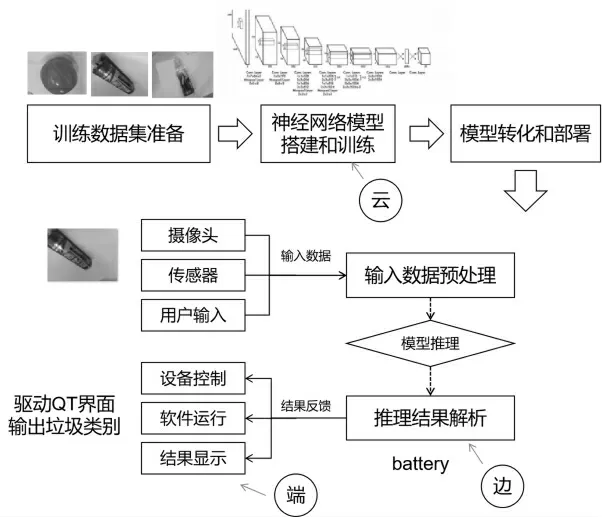
图1 “云、边、端”协同开发流程
2 数据准备与预处理
为了成功模仿或超越人类的视觉功能,计算机视觉在对目标设备进行研发的过程中,需要通过对大量模型训练,实现对图像的标注。图像标注是一个将标签添加到图像的过程。数据采集和数据标注是整个开发过程中工作量最大、最基础的一个环节。项目选用精灵标注工具,对1391个垃圾物体图片进行标注,从而得到相应的xml格式的垃圾物体标注文件。标注后的图片样例见图2。

图2 自建数据集
模型训练过程是训练、测试不断迭代的过程,图片标注之后,按照设定比例(8∶2)将标注的垃圾图片数据集随机划分为训练数据集和测试集,并生成图片和标注文件地址对应的训练集以及测试集关系清单的txt文件。
在训练模型之前,模型需要知道目标检测物体的类别标签。模型及其优化以纯文本的形式定义,而非代码模式,使用Caffe框架可以在配置中定义模型和优化,不需要硬编码,更方便高效[2]。学术和工业领域,运算速度对模型和海量数据的处理至关重要,Caffe结合cuDNN,速度更快。Caffe工作流程如图3所示。Caffe框架中的layer是模型和计算的基本单元,用以实现前向和反向传播。再通过blob结构来存储、交换和处理网络中间正向和反向迭代时的数据和导数信息,实现数据传递。solver定义针对net网络模型的求解方法,记录神经网络训练过程,保存神经网络模型参数。
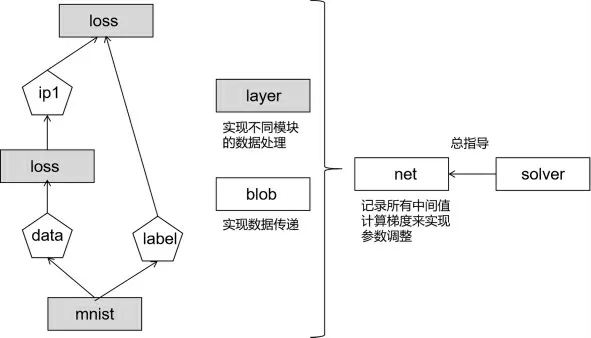
图3 Caffe工作流程
在Caffe框架下,通过输入标签参数来自动生成模型所要使用到的标签配置文件和标签文件。其中,labelmap.prototxt是Caffe框架使用的标准配置文件,用以描述模型文件具有的标签清单,得到垃圾图片的标签及其格式如图4所示。

图4 Caffe框架下标签清单格式
使用Caffe框架下自带的convert_annoset工具,将训练数据集转换成复合Caffe训练要求的lmdb格式数据文件,这是一种小型的键值对数据库[3]。其中,每个键值对都是数据集中的一个样本。使用lmdb数据库来存放垃圾物体图像数据,是因其具有极高的存储速度,在系统访问开发中使用到大量图片、小文件时,用以减少磁盘IO时间开销。得到lmdb格式数据需要满足以下要求:(1)垃圾物体的图片地址与其对应标注文件的txt清单文件;(2)转换工具convert_annoset。使用转换工具为普通图片数据源转换为lmdb数据库提供便捷方法,配置关键参数快速找到lmdb数据文件。执行完脚本后,根目录下出现Caffe训练数据文件和测试数据库文件。
3 模型训练与评估
神经网络训练过程包括模型训练和模型测试,虽然两者的模型主体架构完全相同,但其数据输入方式不同,且对应不同数据集,需要对数据层部分参数进行手动配置。本项目的神经网络模型是基于YOLO v3[4]的深度学习框架,优点是速度快,充分发挥多核处理器和GPU并行运算的功能。并且,在尺寸中等偏小的物体上有超高准确率,适合垃圾物体的识别。
YOLO v3网络结构如图5所示。它只有卷积层,通过调节卷积步长控制输出特征图的尺寸,对于输入图片尺寸没有特别限制;它采用金字塔特征图,借鉴ResNet,将输入的特征图与输出特征图对应维度进行相加;同时也借鉴DenseNet将特征图按照通道维度直接进行拼接。YOLO输出特征图解码是它的关键点之一。根据不同的输入尺寸,会得到不同大小的输出特征图。每个特征图的每个格子中,都配置有3个不同的先验框。检测框位置(4维)、检测置信度(1维)、类别(80维)都在其中,共计85维。v3沿用v2中关于先验框的技巧,使用k-means对数据集中的标签框进行聚类,得到类别中心点的9个框,作为先验框。有了先验框与输出特征图,就可以解码检测框。置信度在输出85维中占固定一维,由sigmoid函数解码,解码之后数值区间在[0,1]中。COCO数据集有80个类别,类别数在85维输出中占了80维,每一个维度代表一个类别的置信度,使用sigmoid函数替代了v2中的softmax,取消了类别之间的互斥,可以使网络更加灵活。
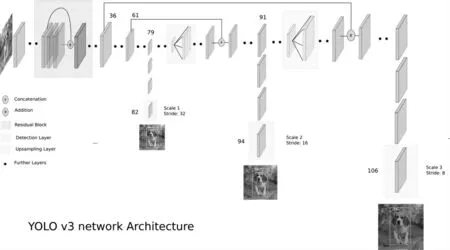
图5 YOLO v3模型结构
Caffe框架下,神经网络各功能层高度模块化,以“layer{}”为标志形成块的形式堆叠,最后组成完整的神经网络。配置神经网络训练模型和测试模型文件之后,进行solver超参数配置。Caffe solver定义整个模型如何运转,它的配置信息如下:(1)网络参数配置,包括train_net训练神经网络模型文件地址,test_net测试神经网络模型文件地址,test_iter网络测试迭代次数为图片总数量N除以批次大小,test_interval测试间隔设置为500,display设置为0;(2)学习率参数配置,包括base_lr基础学习率设置为0.01,lr_policy学习率调整策略设置为multistep,max_iter最大迭代次数设置为100 000;(3)模型优化参数配置,type迭代优化算法设置SGD;(4)模型保存快照参数配置,snapshot快照输出评率设置为5000。
调用Caffe框架自带命令caffe train执行模型训练,包括从头训练和基于预训练模型进行训练两种训练模式,得到不同的log日志文件。输出日志文件如图6所示,可以看到no obj期望值越来越小,obj置信度越来越接近1,iou预测出和实际标注的交集相关,值越大效果越好,loss参数随着训练次数增加而降低。

图6 训练输出结果
最后,选择合适的评估方法,迭代地对模型进行优化。将评价指标数据可视化能够快速且直观地判断模型训练情况,提取日志文件中的参数信息,处理loss参数信息和iou参数信息,如图7所示。loss图中的折线总体呈下降趋势,说明随着不断迭代训练次数的增加,损失在不断减少。由iou图可见,总体趋势向上,随着训练次数增大,预测框和物体标注框的重合程度正当上升,但值并不高,说明仍需继续训练达到模型收敛。
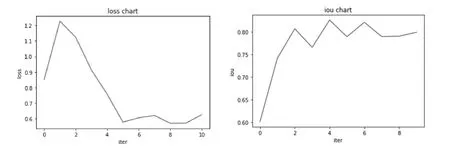
图7 模型评估图
4 模型转换与边缘部署
完成数据集划分,通过神经网络学习训练集中的数据得到模型参数,通过测试集来模拟测试模型的泛用性,这些都是基于一种数据源的图片文件进行的,且输出结果是对图片预测程度正确与否的系列评价指标。
边缘计算是一种分布式处理和存储的体系结构,是利用靠近数据源的边缘地带来完成运算程序,可在大中小型运算设备、本地端网络内完成[5]。将训练好的神经网络模型部署到边缘端设备,虽然部署的神经网络模型主体结构与训练时的神经网络结构保持相同,但与训练和测试过程存在两大区别:(1)边缘端的神经网络模型需要处理摄像头采集到的未标注垃圾物体图片,所以神经网络模型的数据层不必再定义数据集的来源,但需要定义输入数据的大小格式;(2)边缘端的神经网络模型处理图片后,输出不再是对图片预测准确率评价指标,而是对实时采集到的物体图片预测和分类的反馈结果。
ResNet-152模型论文中提出了越宽越深越大的模型往往比越窄越小越浅的模型精度要高的证明[6]。但越宽越深越大的模型对计算机资源要求更高,现在的模型应用越来越倾向于从云端部署到边缘侧,而受限于边缘侧设备的计算资源,需要考虑设备存储空间、内存大小、运行功耗和时延性等问题。特别是在移动端和嵌入设备等资源受限的边缘侧应用场景中,更需要模型量化,以较低的推理精度损失将连续取值的浮点型模型权重等数据定点近似为有限多个离散值的过程。模型量化增加了操作复杂度,在量化时需要做一些特殊处理。
制作边缘部署使用的神经网络模型文件,从获取训练时使用的神经网络模型文件中的所有层,删除没有bottom字段的用于数据输入的数据层,并设置新的数据层,修改输出层。在训练时一般需要输出loss,但边缘部署对未知数据进行识别,输出内容为检测垃圾物体的分类概率,需要softmax层,并将该输出层封装在API内。
对应开发使用到的硬件资源包括开发板、高清USB摄像头和触摸显示屏。开发板选用NNIE,这是海思媒体SoC针对神经网络特别是深度学习卷积神经网络进行加速处理的硬件单元,芯片为Hi3559A。使用该开发板之前,需要先配置转换工具nnie_mapper的配置文件。
使用nnie_mapper转换工具来实现caffe model转换为wk文件。针对开发板芯片选择对应的版本命令nnie_mapper_11,执行转换命令生成wk文件,并下载标签文件,将它们置于model文件夹下,用于后续部署。电脑端与开发板连接,使用同一网段,设置配置ip地址。使用MobaXterm连接到开发板,将项目文件夹上传到开发板;运行项目文件,将目标物体放入摄像头下方,测试识别效果如图8所示。测试苹果置于摄像头下,识别出物体是苹果,且分类属于厨余垃圾。

图8 垃圾分类识别效果
经过训练后的模型,在复杂背景下识别垃圾的能力大大提升,经测试准确率可达90%,有一定的实用价值。
5 结语
本文研究了在垃圾分类中运用机器视觉和物联网应用技术实现云边端协同垃圾物体分类检测应用开发。通过对整个云边端协同开发流程进行梳理,从对垃圾物体数据进行采集、预处理,到配置神经网络模型,并在该模型上进行训练和评估,最终将模型分别部署在云端和边缘端,边缘端通过开发板控制摄像头实时采集物体数据,并将推理计算后的分类结果显示在触控屏上。通过训练策略得到性能好的模型,并赋能到实际垃圾分类检测场景之中,发挥AI分类检测的能力。
猜你喜欢
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
电子制作(2019年19期)2019-11-23 08:42:00
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
单片机与嵌入式系统应用(2017年1期)2017-04-13 20:40:48
电子制作(2017年22期)2017-02-02 07:10:14
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
海军航空大学学报(2015年4期)2015-02-27 13:45:47
电子技术应用(2014年3期)2014-03-26 01:48:58
