
基于YOLOv5算法的钢印字符识别方法
2022-09-13 03:52:18宫鹏涵
兵器装备工程学报 2022年8期
宫鹏涵
(陆军工程大学石家庄校区, 石家庄 050000)
1 引言
枪身号码作为枪支的身份标识,不仅是枪械生产与管理过程中的重要内容,更是轻武器信息智能化管理的重要组成部分。为了方便武器的质量把控和信息管理,在枪械的生产过程中,往往会采用压印或激光刻字的方法在枪身及其他主要金属部件上标注相应的生产编号。压印字符通过字符模具对钢板压印所产生,具有不易磨损,可长期保存的优点,因此在工业制作上得到广泛使用。此外,在枪支的生产销售、出库入库管理、退役报废等环节中都必须登记枪号,而传统的人工记录方法需要大量的劳动力,不但耗时耗力,而且容易出现记录错误等问题。因此,研究钢印字符智能识别方法对于提高压印字符的实时识别速率有着积极的意义。
与手写字符和印刷字符等普通字符不同,压印字符是对物体表面施压生成,其颜色与背景颜色一致,两者的对比不明显,并且环境、光照条件等元素的影响会进一步加大对钢印字符识别的难度。因此,对钢材压印字符采用传统的字符识别技术,如模板匹配,所得到的识别准确率难以保证。近年来,在计算机视觉(Computer Vision)领域中,目标检测是其中备受人们关注的问题,通过应用目标检测算法,可学习每个对象的可视模型,并找到合适的边界区域和对象类别。在早期,主要的目标检测算法是通过特征描述算法,如HOG算法等,对图像进行特征提取,并应用各种分类器,如支持向量机SVM等,对得到的图像特征进行分类。基于HOG和SVM图像分类的算法被提出时,运用该算法对自然场景中的行人进行检测,取得了较好的效果。但传统目标检测算法在进行特征设计时需要人工设定,对于多样性的变化并不能表现出良好的鲁棒性。而且算法过程繁琐,消耗时间长,并不能满足实际生活中要求的实时性。
为了解决传统目标检测算法中存在的问题,Girshick等提出区域卷积神经网络算法(R-CNN),将候选区域(Region proposal)与卷积神经网络结合起来,以替换传统目标检测中使用的滑动窗口与手工设计特征的结合,在此基础上设计了R-CNN框架,该算法推动了在深度学习基础上发展目标检测的进展。然而,作为最早的基于深度学习的目标检测算法,R-CNN框架存在训练繁琐,耗时长,占用磁盘空间大和速度慢的缺点。针对速度慢问题,何凯明等提出了SPP-NET,采用空间金字塔采样,提高了目标检测的速度。2015年Girshick提出了快速区域卷积神经网络(Fast R-CNN),该算法将多任务损失函数引入其中,并提取了R-CNN和SPP-NET二者的优点,算法的训练和测试过程更加快捷。但是,候选区域的提取方法依然为选择性搜索算法,目标检测时间绝大多数都耗费于此,依旧无法进行实时的应用。为了解决Fast R-CNN存在的问题,2017年Ren和Girshick提出了超快区域卷积神经网络(Faster R-CNN),该网络使用卷积神经网络直接产生候选区域,将之前算法中一直处于分离中的卷积神经网络和候选区域融合在一起,使该网络变为端到端的网络,目标检测的速度和精度都得到了显著的提升。然而令人遗憾的是,Faster R-CNN依然无法满足实际需求,无法对目标进行实时性检测,Faster R-CNN需要提前获得候选区域,并且在对每个候选区域进行分类时,同样会消耗很多时间于计算上。2016年Redmon 等提出了YOLO (You Only Look Once)网络,该算法将图像检测视为一个回归问题。在训练过程中,YOLO可以查看整个图像,在目标检测中更关注目标检测中的全局信息。YOLO的核心思想是将整张图片作为检测网络的输入,并在输出端直接返回到边界框的方位和其属于的类别。因此相对于前述的目标检测算法,YOLO算法的检测速率得到了极大的提升,使其更加接近实际生活中需要的实时性。但是在提高检测速率的同时YOLO的检测精度并不是很高。在之后的研究中,基于YOLO算法,YOLOv2、YOLOv3、YOLOv4、YOLOv5等算法被依次提出,准确率和检测速度均得到了显著提高。
近年来,关于钢印字符识别的方法也被提出。文献[13]中提出一种基于改进的EAST深度学习文本检测器和CNN的钢材表面字符检测与识别方法。文献[14]中提出了一种基于MobileNet模型的钢材表面字符检测识别算法。文献[15]中提出了基于YOLOv2算法的钢材压印字符识别方法。
本研究中提出了一种基于YOLOv5网络的钢材识别方法,对标注着生产编号的钢材部件图像进行预处理,再通过YOLOv5网络对经过处理后的数据集训练,学习各类字符的特征,对字符进行分类的同时得到字符的位置信息,利用图像中各个字符所得的位置信息进行排序操作,即可得到钢材部件的生产编号,实现实时、快速、准确地一步式识别钢材部件的生产编号。
2 识别方法
2.1 数据集采集
由于没有公开的钢印字符数据集,本研究根据枪支编码的编制要求,制作了相应的带有字符编号的试验部件,并用相机对整块部件拍摄图片。所获取的钢材压印字符有3种规格,如图1所示。

图1 钢印字符图Fig.1 Steel embossing
2.2 数据集扩充
本研究通过对已经打上字符编号的钢材部件进行拍摄,得到422张图像。但作为数据集,400余张图像略显单薄,且在对数据图像进行采集时,拍摄条件均为同一角度和同一光照条件,这不太符合实际识别环境。因此为了保证样本的多样性,使其符合现实生产过程中采集到的图像,对现有的数据集进行扩充。
本研究采用图像模糊化,图像加亮,图像变暗,图像加噪等方法对已有图像进行处理,从而得到2 110张图像,并将其作为数据集,其中1 855张作为训练集,255张作为测试集。处理后得到的图像如图2所示。图2(a)为图像模糊化处理,图2(b)为图像加亮处理,图2(c)为图像变暗处理,图2(d)为图像加噪处理。

图2 处理后的钢印字符图Fig.2 Steel embossing after treatment
2.3 YOLOv5原理
2.3.1 YOLOv5网络结构
2020年,YOLO的第5个版本被Utralytics提出,并命名为YOLOv5,该版本在速度和准确性方面超过了YOLO以前的所有版本。YOLOv5算法使用参数depth_multiple和width_multiple来调整主干网络的宽度和深度,从而得到4个版本的模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。YOLOv5s是最简单的版本。它具有最小的模型参数和最快的检测速度。其网络结构如图3所示,由以下部分组成:focus、Conv-Bn-Leakyrelu(CBL)和CSP1_、CSP2_和空间金字塔池化(SPP)模块。Focus模块主要包含4个平行切片层来处理输入图像。CBL模块包含一个卷积层、批量归一化层和hard-wish激活函数。CSP1_块包含CBL块和个剩余连接单元。CSP2_块包含个CBL块。SPP块主要包含3个maxpool层。

图3 YOLOv5网络结构示意图Fig.3 YOLOv5 network structure
YOLOv5s将模型分为3个部分:Backbone网络部分、Neck特征增强部分和Prediction部分。每个部分都有不同的功能。
Backbone网络部分用于提取图像特征。首先,focus结构用于周期性地从高分辨率图像中提取像素,并将其重建为低分辨率图像。也就是说,将图像的4个相邻位置进行叠加,将(图像宽度)(图像高度)维度的信息集中到(图像通道数)通道空间,以提高每个点的感受野,减少原始信息的损失。该模块的设计主要是为了减少计算量,提高速度。然后,借鉴CSPNet的设计思路,设计了CSP1_x和CSP2_x模块。该模块首先将基础层的特征映射分为两部分,然后通过跨阶段的分层结构进行组合,这样既减少了计算量又保证了准确性。在Backbone网络的最后部分,利用SPP网络,该模块可以进一步扩大感受野,有助于分离上下文特征。
Neck特征增强部分是用来进一步提高特征提取能力的。它采用了PANet的思想来设计FPN+PAN的结构。首先,它使用FPN结构传递强语义特征,然后使用PAN模块构建的特征金字塔结构,从下到上传递强定位特征。通过这种方法,用于融合不同层之间的特征。
Prediction部分继承了YOLOv3的Prediction结构,它有3个分支。预测信息包括物体坐标、类别和置信度。Prediction部分继承了YOLOv3的Prediction结构,它有3个分支。预测信息包括物体坐标、类别和置信度。主要的改进是使用完全交并比损失(CIOU_Loss)作为边界盒区域损失。
2.3.2 检测过程
YOLOv5 采用-means 聚类方法对数据集中的人工标记框进行聚类分析。该方法对先验框Anchor boxes 的数量和框的大小进行确认,最后在网络的周边生成一些具有一定比例的边框。这样,每个网格单元都会对边界框和这些框的置信度分数进行预测。在这些边界框中,每一个边界框都包含了该区域中心点的位置,高度,宽度和置信度这5个信息。
置信度可表示为2个因子的乘积,即在边界框中检测对象的存在与否以及预测框的准确度,置信度计算公式为

(1)
式(1)中,()表示边界框中是否包含检测对象。
若包含检测对象,则()取值为1,那么置信度就等于的值;若检测对象在边界框中不存在,则()=0,的值等于0。而表示预测边界框与标记的真实边界框的重合程度,其计算方式为
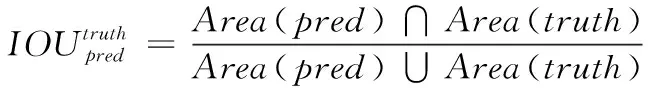
(2)
表示预测边界框与标记的真实边界框的交集与并集的比,当的大小与1相近时,预测边界框与标记的真实边界框的重合程度越高。
那么,预测边框某一类别的置信分数就可以通过下式进行计算。


(3)
置信分数表征预测边界框中含有某一类别的概率及边框坐标的准确度。根据置信分数的大小,采用非极大值抑制()筛选获得最终的检测结果。
相较于之前的YOLO算法,YOLOv5使用完全交并比损失(_)作为边界盒区域损失。其计算方法为

(4)

(5)
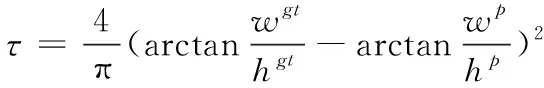
(6)
式中:_为标注框和预测框中心点的欧氏距离;_为最小外接矩形的对角线距离;∂是权重函数;是度量宽高比的一致性;为预测框宽、为预测框的高、为标注框的宽、为标注框的高。
2.3.3 输出改进
虽然经过算法检测,可以得到钢印字符的种类,但是所得到的结果是乱序的,只有种类而无序列。因此,为了得到与钢印一致的生产编号,需要对检测到的字符位置信息进行排序,本研究采用冒泡排序法,对位置信息按从小到大顺序进行排序,从而把相对应的字符从左到右排列,从而得到准确的生产标号。
利用字符位置信息进行冒泡排序的方式比较简单,对于保存有字符位置信息的数组而言,只需要对在数组中邻近的两个坐标数值进行大小的比较,如果排在前的坐标数值比排在后的坐标数值大,则交换2个坐标数值的位置,如果小就不用进行交换。同时位置信息对应的字符数组也进行相同的操作,最终得到位置信息从小到大的序列和按生产标号从左到右的字符序列。
3 实验结果及分析
3.1 实验环境
实验平台为PC端,PC配置为AMD Ryzen 7 3700X 8-Core Processor,显卡/GPU为NVIDIA GeForce RTX 3060,16G运行内存。cuda版本是11.2,集成开发环境是Pycharm,编程语言是Anaconda Python3.9。
YOLOv5x模型训练参数的设置,批处理大小(batch Size)设为8,迭代次数(epochs)设为100次,学习率(learning_rate)设为0.001。
3.2 训练结果及分析
为了得到良好的识别效果,在字符识别前需要对YOLOv5网络进行训练,而经过训练获得的网络模型的优劣程度将直接影响到识别的效果是否达到满意的程度。本研究使用Labelmg软件对训练集中所有图片上的字符打上各自相应的标签,生成每一幅图片对应的.xml文件,然后将每一个.xml文件生成txt文件,存储标签信息。并将YOLOv5网络进行参数设置,而后应用该网络对训练集进行训练。
在对训练集进行训练时,YOLOv5网络通过计算损失函数CIOU_Loss来判断训练的效果。为了得到较好的训练效果,所需求的CIOU_Loss值越小越好。
使用YOLOv5网络进行训练得到的loss函数曲线如图4。

图4 损失率曲线Fig.4 Loss rate curve
在训练结束后,可得到包括最佳训练权重、字符识别混淆矩阵、各类标签个数等信息数据。混淆矩阵元素如图5所示。各类标签个数如图6所示。

图5 字符识别结果混淆矩阵元素图Fig.5 Confusion matrix of the characteristic recognition
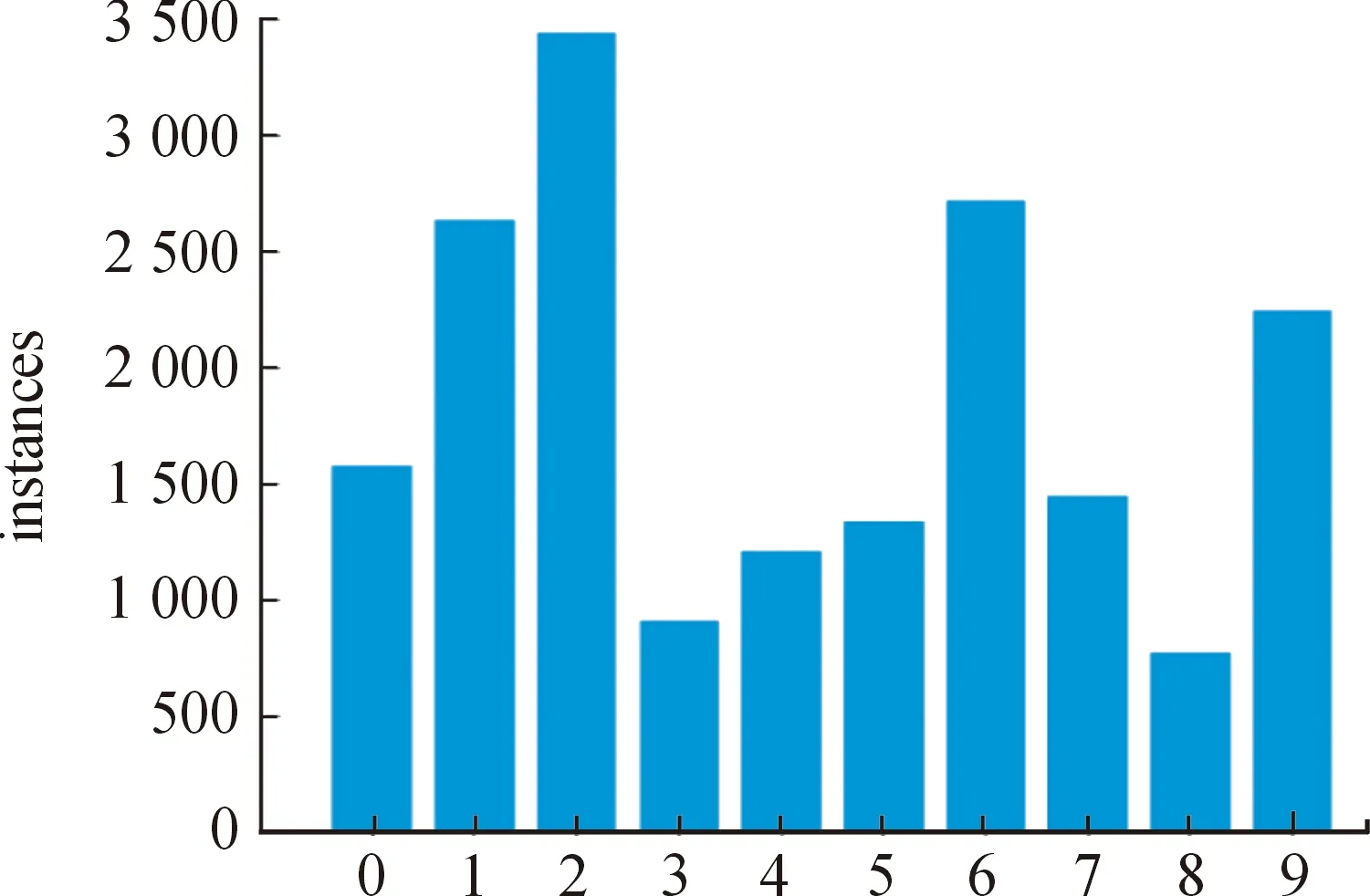
图6 各类标签个数直方图Fig.6 Number of labels
可以看出,混淆矩阵中,对字符3和字符8的检测效果并不算很好,在各类标签个数图中,字符间的分配并不均匀,3和8的个数最少,因此在之后的工作中可以尝试平衡各类字符的个数,使其均匀分配,以达到更好的效果。
训练结束后的-曲线如图7,曲线围起的面积即为值,可看到0~9每个类别的值均达到90以上,为所有类别均值,且达到974,这表明采用YOLOv5网络分类得到的效果很好。
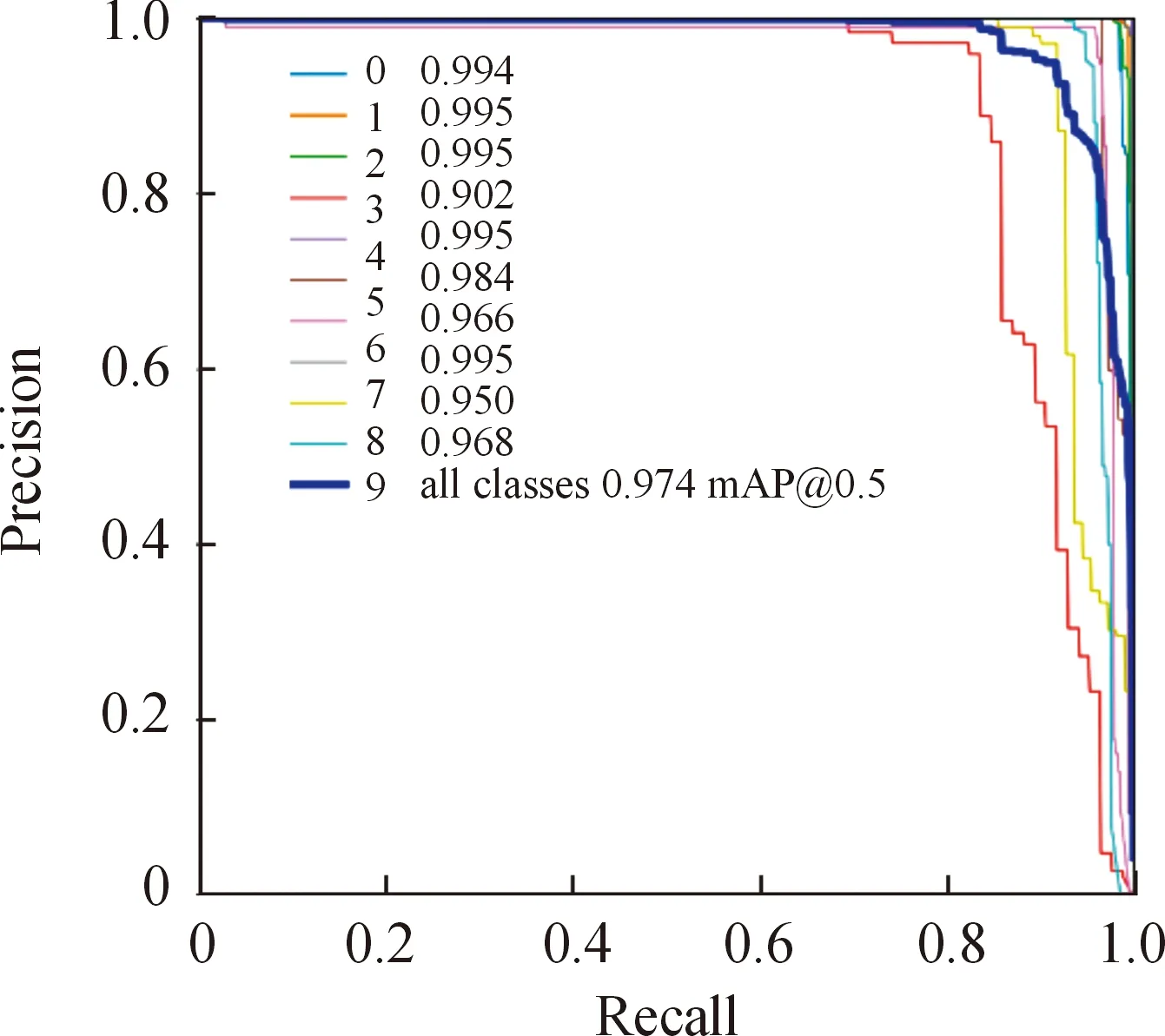
图7 P-R曲线Fig.7 P-R curve
3.3 测试结果
使用YOLOv5算法,对于3种不同的钢印字符识别效果如图8所示,YOLOv5基本能对0~9这10个数字进行分类,并能较为准确地标识出各个字符所在的位置。

图8 识别效果图Fig.8 Identification of the characteristic
同时,YOLOv5采用整张钢材压印字符生产编号图像作为输入,检测时即能输出一整串生产编号,比先分割字符输入,识别输出单个字符后再进行拼接的方法更加快速且便捷。
本文实验均利用Pycharm软件完成,结果显示如图9所示。该算法的检测时间为0.016 s。

图9 图像检测结果界面Fig.9 Image recognition process
4 结论
采用数据增广技术构建了枪支编码钢印字符数据集,将目标检测领域最新算法YOLOv5应用于枪支编码钢印字符识别。实验结果表明,所提出的方法在枪支钢印字符识别中,处理时间较快,准确率较高,具有较强的实际应用价值。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
电源技术(2015年7期)2015-08-22 08:48:32
国外科技新书评介(2014年3期)2014-12-17 17:26:53
印刷技术·包装装潢(2014年5期)2014-08-27 16:56:19
