
诈骗犯罪中认罪认罚影响机制实证研究
2022-09-07 12:14王超
河南警察学院学报 2022年4期
王 超
(河北地质大学 法政学院,河北 石家庄 050031)
诈骗案件是日常生活中的常发、多发案件,对普通百姓的生活影响较大。认罪认罚从宽制度是我国刑事诉讼法中的一项重要制度,它在分流刑事案件、减轻法院审判压力等方面起着重要作用。2016年9月,全国人大常委会通过《关于授权最高人民法院、最高人民检察院在部分地区开展刑事案件认罪认罚从宽制度试点工作的决定》,我国认罪认罚从宽制度开始步入法治化及体系化的试点过程。2016年11月,“两院三部”(即最高人民法院、最高人民检察院、公安部、国家安全部、司法部)发布了《关于在部分地区开展刑事案件认罪认罚从宽制度试点工作的办法》,对认罪认罚从宽制度的适用事项进行了详细规定[1]。2018年《刑事诉讼法》将“认罪认罚从宽”明确为刑事诉讼程序的一项原则,使该制度具有更强的生命力,并且成为我国刑事诉讼领域独树一帜的特色制度[2]。认罪认罚从宽制度自2016年设立并试行以来,在一审法院的案件审判工作中得到了广泛适用。但在实践中也存在诸多差异,包括地区适用差异。对该制度适用差异的研究大多表现在对其刑罚适用结果和二审程序中的差异等问题上。而对该制度在某一罪名上从犯罪特征、刑罚适用等多个方面进行深入剖析,并通过数据建模对适用刑罚和缓刑的结果进行预测的研究相对较少。
本文以诈骗犯罪案件的一审刑事判决书为研究对象,通过数据挖掘、统计分析、预测建模等方法并进行卡方检验和t检验,研究认罪认罚从宽与犯罪特征、刑罚特征、刑事程序等变量的交叉效能。通过多种变量对刑罚值的预测构建线性回归模型,对适用缓刑的预测构建神经网络模型,并进行模型评估,研究影响认罪认罚制度的多个变量的重要程度,为我国司法实践中对认罪认罚从宽制度的理性适用提供参考。
一、研究方法
主要从三个方面进行分析,包括研究数据、研究变量和研究方法三个方面。
(一)研究数据
本研究使用的诈骗案例直接来自“聚法案例”数据库的部分数据,间接来自于中国裁判文书网上的法律文书。全网搜索,共检索到2021年10月25日前的诈骗犯罪案例一审法院裁判文书287845篇。本研究随机抽取其中的4000例法律文书进行实证分析,所有案例的法律文书均为一审法院的刑事判决书,其中抽取适用认罪认罚从宽的判决书2000例、没有适用认罪认罚从宽的判决书2000例,共计4000例法律文书。这样抽样的目的是为了保证数据的平衡,便于对比分析。
数据分布特征:
1.数据在认罪认罚变量上的分布情况。本研究抽取一审法院适用认罪认罚从宽的判决书和没有适用认罪认罚从宽的判决书案例各2000例,共4000例,各占50%。
2.数据在各省(区、市)的分布情况。案例数据在各省(区、市)的分布上并不平衡,具体情况见表1。

表1 各省(区、市)的案例分布情况
上表显示,各省(区、市)的认罪认罚适用案例分布较为分散,各省(区、市)均有案例,案例具有较强的代表性。
(二)研究变量
本研究对我国一审诈骗案例进行分析,通过数据挖掘软件进行变量提取,主要分析了认罪认罚从宽、是否签署具结书、赔偿被害人、被害人谅解、自首、坦白、立功、缓刑、刑罚值、前科、从轻处罚、悔罪表现、被害人过错、共同犯罪、主犯、从犯、初犯、主观恶性、地区差异等45个变量。研究中的变量大部分为二分类变量,即“是”和“否”两个选项;有一些变量为数值变量如刑罚值等。研究变量广泛而多样,分析出的结果具有很强的解释力,能够发现更多关于认罪认罚从宽适用中的差异问题和特征。
地区分类特征:我国各省、自治区、直辖市可按地区分成东部、中部、西部和东北部地区,其中东部地区是指北京、天津、河北、上海、江苏、浙江、福建、山东、广东、海南等省、自治区、直辖市;中部地区是指山西、安徽、江西、河南、湖北、湖南六省;西部地区是指内蒙古、广西、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆等省、自治区、直辖市;东北部地区是指辽宁、吉林和黑龙江三省。我国各省、自治区、直辖市的地区分类见表2。本研究将各变量数值与地区分类进行两变量或多变量的差异分析。

表2 我国各省(区、市)的区域分类情况
(三)研究方法
本研究采用统计软件对收集的数据进行统计分析,使用描述性统计、频率性统计、交叉表分析、方差分析、t检验、线性回归分析模型、神经网络模型等方法进行分析。在对数据进行统计分析之前首先对数据进行整理和预处理,包括数值提取、变量转换、数值的标准化处理等操作。
对刑罚值的预处理需要说明一下。裁判文书案例中的裁判结果为汉字,如“判决如下:判处有期徒刑三年,缓刑四年”,该刑罚为汉字,不能直接由计算机进行统计分析,需要将其转换为数值,转换的方式为:分别提取刑罚值,将其设置为两个变量;其中的刑罚值将“有期徒刑三年”中的“三年”转换为月数值“36”。本研究案例中的拘役刑罚为1—6个月,直接转换为有期徒刑的数值“1—6”。有期徒刑的6—11个月直接转换为数值“6—11”。无期徒刑转换为300个月,然后将转换后的刑罚数据进行汇总,汇总后数值大于300的均为无期徒刑。
本研究对适用缓刑的案例进行单独变量分析,从裁判结果中直接提取是否适用缓刑作为一个独立变量。本研究的样本中,没有适用死刑立即执行和死刑缓期二年执行的样本,因此也不对其进行分析。
二、诈骗犯罪案件中的犯罪特征因素分析
诈骗案例中,认罪认罚从宽适用存在犯罪变量与刑罚适用的诸多方面差异。犯罪特征差异主要分析认罪认罚从宽案例中在前科、共同犯罪、主犯、从犯、初犯、是否未成年犯、被害人伤害情况等方面的差异。采用交叉表分析,使用Pearson 卡方检验方法进行检验。具体结果,见表3。
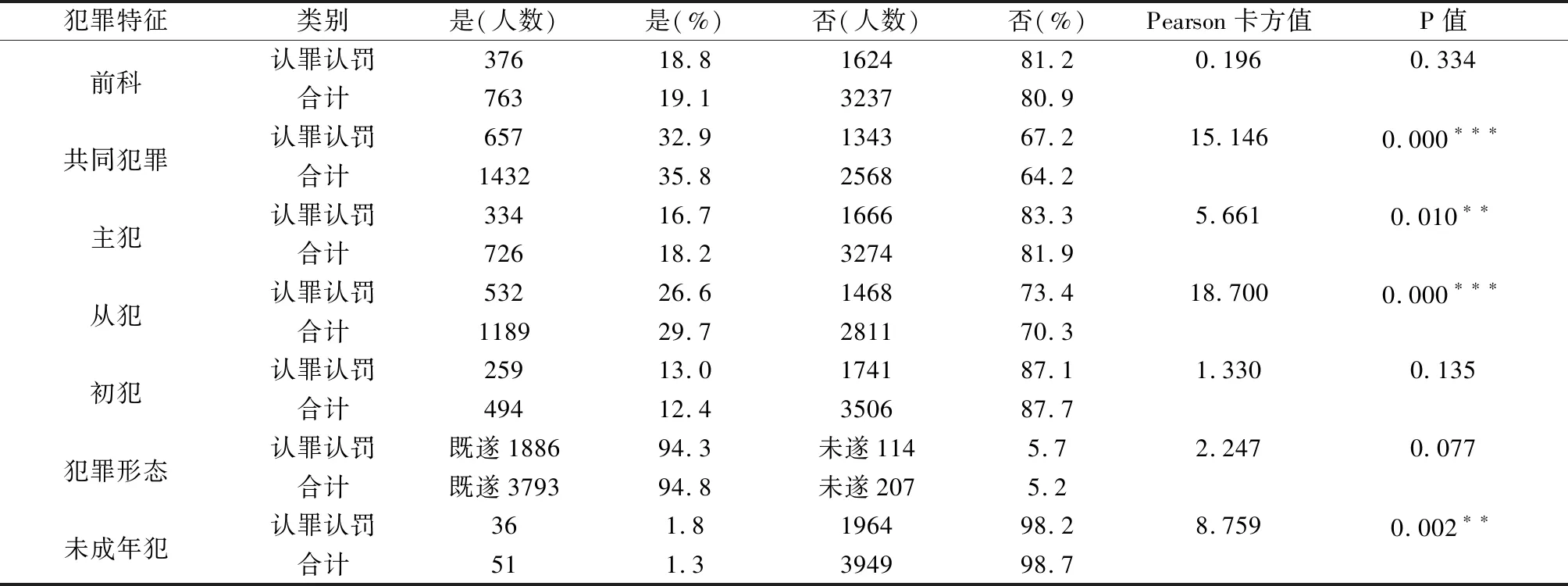
表3 犯罪特征的交叉表分析及卡方检验结果
在诈骗案件中的认罪认罚案例与非认罪认罚案例中,各犯罪特征存在较大差异。其中在共同犯罪、从犯特征中存在显著差异,达到了0.001的显著性水平;在主犯、未成年犯特征中达到了0.01的显著性水平;在前科、初犯、犯罪形态特征中不存在显著差异。这表明,罪犯是否有前科并没有影响认罪认罚的认定;而在共同犯罪中,认罪认罚的数量和比例均比较小。这表明,在诈骗犯罪中,共犯中的犯罪人似乎更不容易认罪认罚,主犯中的认罪认罚比例更低。可见,共犯中的主犯和从犯均更不容易认罪认罚。从犯罪形态看,诈骗案件中的犯罪既遂的数量都比较多,认罪认罚案件中的既遂数量低于无认罪认罚案件中的既遂数量。未成年犯数量偏少,数值可供参考。在认罪认罚案件中,未成年犯的数量要多于无认罪认罚案件中未成年犯的数量。也就是说,在诈骗案件中,有更多的未成年犯愿意认罪认罚。
三、诈骗犯罪案件中的量刑影响因素分析
量刑影响因素主要包括量刑情节认定差异和缓刑等因素的适用差异。
(一)量刑情节认定差异
不同的量刑情节对认定认罪认罚是有影响的。主要分析自首、坦白、立功、认罪悔罪、赔偿被害人、被害人谅解、被害人过错、犯罪人主观恶性小、签署认罪认罚具结书、是否从轻处罚、是否缓刑、犯罪事实清楚、证据确实充分等变量与认罪认罚制度的关系。采用交叉表分析,使用Pearson 卡方检验方法进行检验。具体结果,见表4。

表4 不同量刑情节的卡方经验结果
在诈骗案件中的认罪认罚案例与非认罪认罚案例中,各量刑情节存在较大差异。其中在自首、坦白、签署认罪认罚具结书、是否缓刑方面存在显著差异,差异达到了0.001的显著性水平;在立功方面存在显著差异,达到了0.01的显著性水平;在认罪悔罪、犯罪事实清楚方面达到了0.05的显著性水平;在赔偿被害人、被害人谅解、被害人过错、犯罪人主观恶性小、是否从轻处罚、证据确实充分方面没有达到统计学上的显著性水平。
这表明,认罪认罚的犯罪人自首的数量和比例偏少,明显低于没有认罪认罚的犯罪人自首的比例。这似乎表明,部分自首的犯罪人更不愿意选择认罪认罚。认罪认罚的犯罪人选择坦白的数量和比例要低于没有认罪认罚犯罪人的比例。这似乎也说明,认罪认罚的犯罪人似乎更不愿意选择坦白。认罪认罚案件中,立功的犯罪人数量和比例也偏低,要低于没有认罪认罚犯罪人的比例。这表明,没有立功表现的犯罪人似乎更愿意选择认罪认罚。
在诈骗案件中,被害人有过错的比例非常低,是否认罪认罚并不存在差异。认罪认罚案件中,被告人选择赔偿被害人的比例略低于无认罪认罚案件中的比例。被害人谅解的比例要高于无认罪认罚案件中的比例。可见,被害人谅解是影响认罪认罚的一个重要因素。
认罪认罚的犯罪人存在更多的悔罪表现,其悔罪比例也比较高。总体看,诈骗犯罪案件中签署认罪认罚具结书的数量和比例均偏低,但认罪认罚的犯罪人签署具结书的比例要明显高于没有认罪认罚犯罪人的比例。犯罪人主观恶性小的比例都比较低。认罪认罚案件中的犯罪事实清楚的数量和比例要低于没有认罪认罚案件中的比例。这似乎表明,在一部分犯罪事实并不太清楚的情况下,犯罪人也选择了认罪认罚。在认罪认罚案件中,证据确定充分的比例略低于没有认罪认罚的比例。这说明,有个别诈骗犯罪案件在证据并不太确定充分的情况下,犯罪人也会选择认罪认罚。
在诈骗犯罪案件中,有无认罪认罚的犯罪人都得到了一定程度的从轻处罚,二者没有显著差异。这一点也与司法实践中的适用特征相符合。司法实践中,认罪认罚案件的从宽处罚实际适用为从轻处罚,这极大地限缩了从宽处罚的空间,影响了认罪认罚从宽制度的适用效果。对此,第十三届全国人大常委会第二十二次会议分组审议最高人民检察院关于人民检察院适用认罪认罚从宽制度情况的报告时,与会委员也指出,认罪认罚案件的从宽尺度,应当根据被追诉人认罪认罚的具体情况和相关法律规定来确定,不应局限于从轻处罚[3]。
(二)地区差异
通过对地区分布与认罪认罚的交叉表分析,采用卡方检验方法进行检验,结果发现,二者不存在统计学上的显著性(P>0.05)。这表明,在认罪认罚案件和无认罪认罚案件中,在地区分布比例上并不存在显著差异。具体情况,见表5。
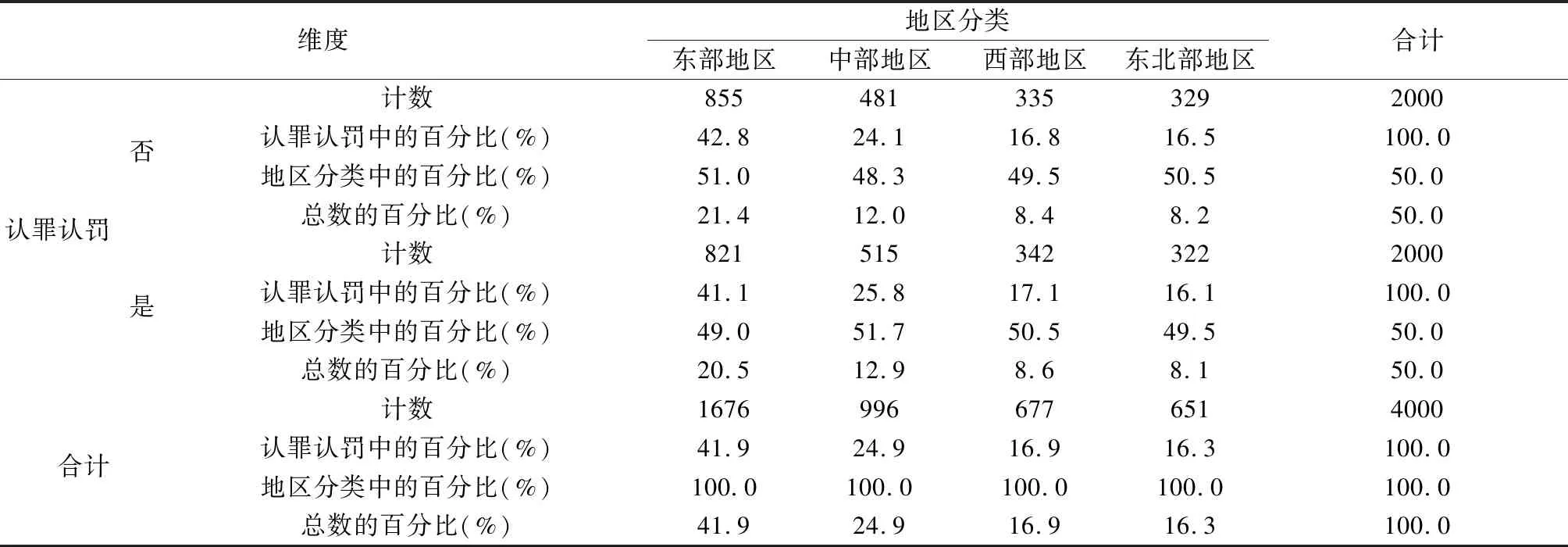
表5 认罪认罚与地区的交叉表
以上数据表明,东部地区认罪认罚的案件数量最多,中部地区和西部地区认罪认罚的案件比例高于无认罪认罚案件的比例。东北部地区中是否认罪认罚的案件数量相差不大。总体看,认罪认罚案件的数量在东部地区、中部地区、西部地区和东北部地区的分布上并不均衡,呈依次下降趋势。
(三)犯罪数额差异
通过对犯罪数额与认罪认罚的交叉表分析,采用卡方检验方法进行检验,结果发现,二者不存在统计学上的显著性(P>0.05)。这表明,在认罪认罚案件和无认罪认罚案件中,在犯罪数额上并不存在显著差异。具体情况,见表6。
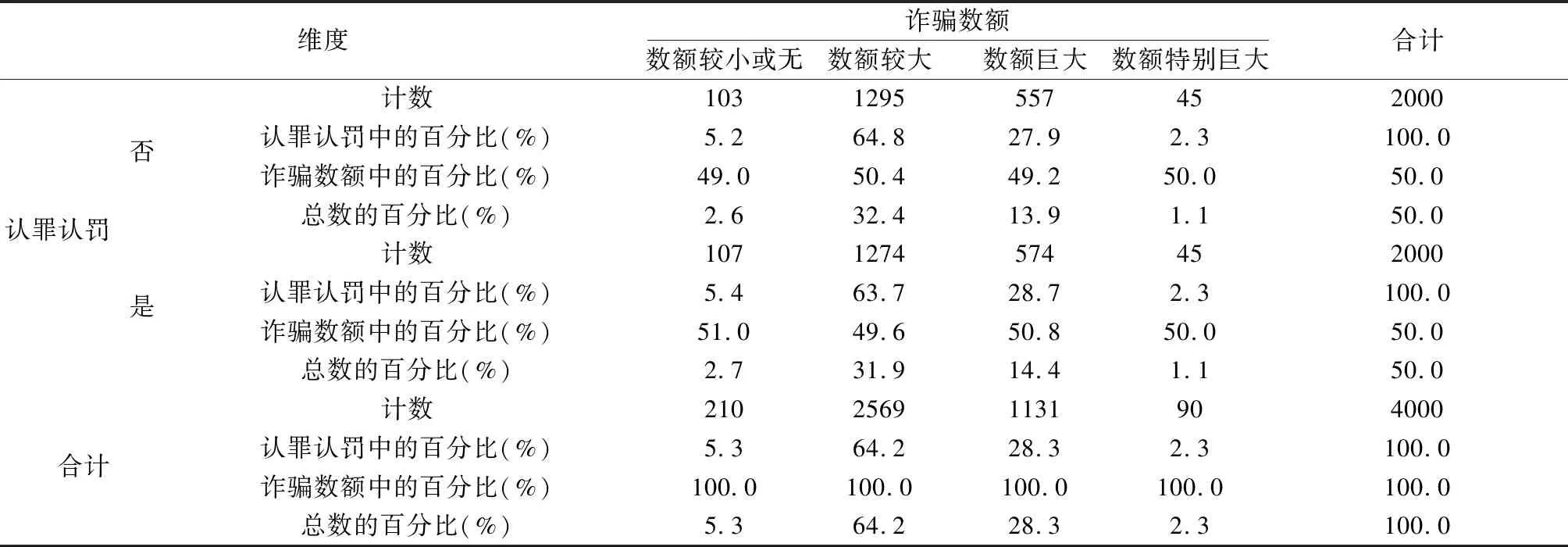
表6 认罪认罚与诈骗数额的交叉表
从诈骗案件的犯罪数额看,绝大部分案件中的犯罪数额较大,数额巨大的也占一定比例。数额特别巨大和数额较小的比例都偏低。在有无认罪认罚方面,犯罪数额并没有对其产生影响。
四、诈骗案件中研究变量对刑罚结果影响的建模分析
对于诈骗犯罪案件,通过将犯罪因素、影响量刑因素作为输入变量,将缓刑和刑罚值作为输出变量,分别构建神经网络模型和线性回归模型,对刑罚进行预测。预测结果显示,构建的模型具有很好的预测效果,显示的预测变量重要性具有较好的实践参考价值。
(一)t检验结果
比较认罪认罚制度对刑罚值的影响,使用独立样本t检验方法进行检验,检验结果见表7。

表7 独立样本t检验统计结果
检验结果显示,刑罚值在是否认罪认罚案件中变化不大。是否认罪认罚对刑罚(月数)变量并不存在统计学上的显示性差异(P>0.05)。这说明,总体来看,在诈骗案件中,认罪认罚对最终的拘役和有期徒刑量刑的影响不大。另从对缓刑结果的预测分析看,认罪认罚主要是对缓刑结果影响较大。
(二)神经网络模型
通过构建神经网络模型预测各分析变量对诈骗案件中适用缓刑的影响程度(重要性)。人工神经网络是一种人脑的抽象计算模型, 一种模拟人脑思维的计算机建模方式。目前,人工神经网络在聚焦人工智能应用领域的同时,也成为机器学习中解决数据预测问题的重要黑箱方法。多层神经网络通常由输入层、隐藏层和输出层组成,它能够解决更为复杂的回归和分类预测问题[4]。本研究采用一个具有多输入单输出的三层BP神经网络作为评估模型。将犯罪特征、犯罪情节等多个影响因素指标作为输入变量,以是否适用缓刑作为输出变量(即目标变量)构建神经网络模型进行计算。输入层有30个节点,输出层有1个节点。中间有隐含层,采用模型默认参数运行该模型。结果显示,模型的总体正确率为96.55%。总体看,预测效果较好。
预测缓刑的主要变量组成的神经网络模型结构,见图1。

图1 预测缓刑的主要变量神经网络模型结构
神经网络模型中适用缓刑的主要预测变量的重要性,见表8。

表8 预测缓刑中主要变量的重要性
由表8可见,神经网络模型中适用缓刑的主要预测变量的重要性值,主要影响变量依次为:主观恶性小、被害人谅解、自首、地区分类、量刑建议、悔罪、辩护人、立功、初犯、认罪认罚。
神经网络模型预测缓刑的主要变量的重要性,见图2。

图2 神经网络模型预测缓刑的主要变量的重要性
(三)线性回归模型
线性回归模型是利用线性拟合的方式探寻数据背后的规律[5]。回归分析在诸多行业和领域的数据分析应用中发挥着极为重要的作用,常用的方法是线性回归分析模型,当输出变量是数值变量时,采用线性回归分析;当输出变量是多分类变量时,采用的是多项Logistic回归分析。通过构建线性回归模型预测各分析变量对诈骗案件中刑罚值的影响程度。本文采用的是线性回归分析模型,因为预测变量虽多为分类变量,但最终的预测结果刑罚值为数值变量。
通过构建线性回归分析模型,最后得出线性回归模型的回归方程式:刑罚月数=认罪认罚*-1.856+法院采信证据*0.07011+法院不予采信证据*-1.294+证据是否充足*-0.6686+赔偿被害人*-0.1039+被害人谅解*-1.391+自首*-1.504+坦白*0.4973+立功*1.425+前科*-0.2963+从轻处罚*4.002+悔罪*-1.394+是否调解*1.002+是否签署认罪认罚具结书*10.04+量刑建议*-0.7874+共同犯罪*0.9407+主犯*0.2951+从犯*-1.755+初犯*-1.368+未成年犯*3.902+辩护人*0.7668+犯罪形态*0.2333+主观恶性小*-3.465+犯罪事实清楚*2.562+证据确实充分*-0.06185+被害人过错*-5.986+地区分类*-0.8866+诈骗数额*3.312+2.259。
该模型显示,在诈骗案件中,认罪认罚并不是影响最后法院适用拘役和有期徒刑以上刑罚的最重要因素,而诈骗数额、共同犯罪、主犯、立功、坦白、是否有辩护人、是否未成年犯、犯罪形态(既遂、未遂)、法院采信证据、从轻处罚情节、犯罪事实清楚、是否调解、是否签署具结书等因素对刑罚期限具有正向作用,数值越大,刑罚越重;其他因素如认罪认罚、从犯、初犯、被害人过错等因素对刑罚值具有负向作用,数值越大,刑罚越轻。
线性回归模型中预测变量的重要性,见图3。

图3 线性回归模型中预测变量的重要性
线性回归模型中预测变量的重要性显示,在诈骗案件中,比较重要的影响刑罚的因素包括:诈骗犯罪数额、是否签署认罪认罚具结书、犯罪事实清楚、从轻处罚因素、悔罪、从犯、自首、认罪认罚、未成年犯、初犯等。其中影响最大的是诈骗犯罪数额。
(四)模型评估
综合模型的评估结果,可以看出,评估模型很好,具有很高的置信度和准确率,模型的评估效果,见表9。神经网络模型的正确率很高,达到了96.55%。线性回归分析模型的结果显示,模型预测的平均误差为0.0。模型相对较好。因此,我们可以选择神经网络模型和线性回归分析模型作为对诈骗案件中的认罪认罚从宽适用的刑罚预测最终评估模型。

表9 评估模型结果(N=4000)
线性回归模型的评估结果,见表10。

表10 线性回归分析模型评估结果
五、研究结论
认罪认罚从宽制度是我国2018年《刑事诉讼法》新确定的一项重要制度,其在司法适用中存在诸多方面的差异。通过对4000例一审法院审判的诈骗案件进行统计分析,可以发现,基层法院适用认罪认罚从宽时在犯罪特征如共犯、主犯等方面,在刑罚适用如缓刑、附加刑等方面存在多项差异;在量刑情节如自首、立功、悔罪表现、赔偿被害人、被害人谅解等多个方面也存在差异。差异水平为P值小于0.05,甚至达到了P<0.001水平。一是犯罪特征方面。统计分析发现,共同犯罪、主犯、未成年犯等因素对认罪认罚具有重要影响。二是影响量刑情节因素方面:诈骗案件中,犯罪人自首、坦白、立功、是否认罪悔罪、是否签署认罪认罚具结书、是否适用缓刑方面存在显著差异;诈骗数额是影响认罪认罚认定的重要因素,其重要性远远大于其他因素。三是适用刑罚方面:在认罪认罚案件中,适用拘役和三年以下有期徒刑的比例都非常高。四是地区差异方面。东部地区认定认罪认罚的案件数量和比例要高于其他地区。而中部、西部地区认罪认罚案件的比例要高于无认罪认罚案件的比例。这似乎表明,经济发达的东部地区在诈骗案件中更多适用认罪认罚从宽制度处理案件。
在预测缓刑和刑罚值时进行建模分析,结果发现:预测是否适用缓刑,预测准确率均达到了96.55%以上。通过对适用刑罚进行预测建模,使用线性回归模型进行预测,误差也在很小水平。建模分析还给出了对预测认罪认罚案件中刑罚变量影响较大的变量程度值。实证研究结果显示,在诈骗案件中的认罪认罚案例中,比较重要的影响刑罚的因素包括诈骗犯罪数额、是否签署认罪认罚具结书、犯罪事实清楚、从轻处罚因素、悔罪、从犯、自首、认罪认罚、未成年犯、初犯等。其中影响最大的是诈骗犯罪数额。而对适用缓刑影响较大的因素是主观恶性小、被害人谅解、自首、地区分类、量刑建议、悔罪、辩护人、立功、初犯、认罪认罚。这一发现显示,在对诈骗案件适用认罪认罚机制方面,理论和实践中存在较大差异。理论上认为相对重要的因素在实践中却并不一定是最为重要的因素。为此,一定要重视认罪认罚机制在司法实践中的重要作用。为统一指导全国量刑建议,最高人民法院、最高人民检察院应尽快联合制定适用于认罪认罚案件的量刑指南,修改、完善量刑协商程序的相关规范,明确不同阶段认罪认罚的量刑减让幅度,共同研究制定常见罪名量刑标准[6]。但也应当注意,实践中案件的复杂程度远高于模型能够描述的最大限度,简单的数学运算难以得出公正的量刑。应坚持定性分析与定量分析并用,将规则与价值判断相结合,将模型计算出的量刑结果根据案件具体情况进行调整[7]。此外,推进案件的类案检索和适用制度也有着非常重要的实践价值。最高人民法院《关于统一法律适用加强类案检索的指导意见》中规定,承办法官在处理某些待决案件过程中,应当采用诸多方法,检索与其在基本事实、争议焦点、法律适用问题等方面具有相似性的案件,重点在于最高人民法院发布的指导性案例、典型案例以及本省高级法院、上一级法院和本院已裁判生效的案例等[8]。在实践中,可将以上模型预测结果应用在诈骗犯罪同类案件中,通过建模影响因素与同类案件的双向迭代运算,不断提高模型的预测准确率,从而实现同类案件的精准同类裁判目标。
猜你喜欢
中老年保健(2022年5期)2022-11-25
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
作文大王·低年级(2019年10期)2019-11-25
活力(2019年22期)2019-03-16
今日农业(2019年16期)2019-01-03
学生天地(2018年19期)2018-09-07
少儿科学周刊·少年版(2017年4期)2017-07-01
人间(2015年22期)2016-01-04
新高考·高二数学(2014年7期)2014-09-18
