
A-LinkNet:注意力与空间信息融合的语义分割网络
2022-09-07 15:19:38杜敏敏司马海峰
液晶与显示 2022年9期
杜敏敏,司马海峰
(河南理工大学 计算机学院,河南 焦作 454000)
1 引 言
作为图像理解的基础,图像语义分割是指根据语义信息将图像划分为不同的区域,而相同的语义区域具有相同的颜色[1]。其中,道路场景的图像语义分割作为自动驾驶的核心技术,近几年成为研究的热点之一。然而,由于受到光照、天气等各种外界因素的影响,道路图像中物体具有位置关系复杂和种类变化大的特点,使得城市道路图像实时分割变成一项具有挑战性的任务[2]。一方面,由于道路图像涵盖目标种类多且存在很多细小目标,例如栏杆、交通指示灯等,增加了图像语义分割的难度。另一方面,同一物体在不同图像中呈现出不同的大小,如何保存多尺度信息成为分割的关键。
随着深度神经网络的发展,图像语义分割进入新的时代,分割速度与精度得到了大幅提高。2014年,FCN[3]的出现将图像语义分割带入一个新的时代。该模型使用卷积层替换传统网络中的全连接层,然后通过上采样将提取的特征还原成原图大小,极大地促进了语义分割的发展。但是该方法对于复杂场景图像的分割并不理想,因此后续很多模型都是在FCN的基础上进行改进。
2015年,Ronneberger等人[4]提出的U-Net网络将编码器-解码器结构应用到图像语义分割中,给图像语义分割带来创新。通过跳跃连接将编码器与解码器直接相连,实现了编码层的特征复用,一定程度上弥补了FCN细节特征丢失的问题,但是忽视了不同特征的重要程度。2017年,Badrinarayanan等人[5]提出了用于自动驾驶的深层语义分割模型,该模型与FCN结构相似,使用VGG-16的卷积层作为编码网络并保留特征图的最大池化索引,在解码器中利用最大池化索引进行上采样,提高了网络性能。虽然上述结构能取得较好的分割精度,但也存在参数多、计算量大的问题,因此研究者在如何提高编码器-解码器结构的分割速度上也进行了大量的探索。ENet[6]、LEDNet[7]模 型 使 用 非 对 称 的 编 码 器-解 码 器 结构,减少了参数量,有效地提高了语义分割的速度。目前,编码器-解码器模型在图像处理领域得到广泛应用。
此外,在深度神经网络中,普遍使用池化操作进行下采样,虽然可以扩大感受野,但是在上采样过程中容易导致精度的损失。针对这一问题,Yu等人[8]提出了空洞卷积(Atrous Convolution)思想,在保证不改变图像分辨率的前提下增大感受野。但是如果在较深层网络使用采样率较大的空洞卷积,会导致“网格效应”,造成局部特征的丢失。为了解决这一问题,Wang等人[9]提出了HDC结构,与普通空洞卷积不同,该结构采用了具有不同膨胀率的空洞卷积来保证感受野的连续性。而文献[10]则提出了空洞空间金字塔池化模型(Atrous Spatial Pyramid Pooling,ASPP),使用一组具有不同膨胀率的空洞卷积并行连接来捕获图像的上下文信息,提高模型的性能。2017年,Chen等人[11]又在文献[10]的基础上,在ASPP模块中加入了图片级特征,对输入特征做全局平均池化,然后与并行的空洞卷积相融合,可以更好地捕获全局上下文信息。
上述网络结构在一定程度上提高了语义分割网络的精度,但是没有考虑到不同特征信息之间的依赖程度,不能很好地区分特征的重要性,注意力机制的出现则很好地解决了这一问题。注意力机制的主要思想是为图片中的关键特征赋予一层新的权重,从而使神经网络能够学习到图片中需要关注的地方,增加上下文的相关性。2018年,Hu等人[12]提 出了一 种全新的可以嵌 套到任意网络的子结构SENet,该结构通过网络自主学习来获取不同通道的权值,从而根据不同的权值表示不同特征通道的重要性,建模各个通道之间的依赖性。文献[13]在SENet的基础上提出一个简单有效的注意力模块CBAM,与SENet不同的是,该模块结合了空间和通道两个维度上的注意力机制,取得了更好的分割结果。Fu等人[14]又在CBAM的基础上提出一种适用于自然场景图像的DANet,通过结合自注意力机制,并行连接空间注意力机制以及通道注意力机制,最后将两个模块的输出相加,进一步提高了分割结果的准确度。
Chaurasia等[15]提 出 的LinkNet是 一 种 有 效的实时图像语义分割网络,结合残差结构[16]以及Unet模型形成对称式的编码器-解码器结构,将解码器与对应的编码器直接相连,在保证分割速度的同时获得了较高的分割准确率。自此,多个基 于LinkNet的 网 络 被 相 继 提 出。Zhou等 人[17]提出了D-LinkNet,它是一种被用于高分辨率卫星道路图像提取的模型,通过结合LinkNet、预训练编码器以及扩张卷积进行道路提取,在一定程度上解决了道路连通性问题。文献[18]又在D-LinkNet的 基 础 上 进 行 改 进,使 用DenseNet[19]代替ResNet,减少了网络的参数并且提高了道路提取的准确度。
受以上分割模型的启发,本文结合编码器-解码器结构以及注意力机制的优势,提出了一种基于编码器-解码器结构的道路图像语义分割网络(A-LinkNet)。由于LinkNet编码器与解码器直接相连,导致大量背景特征被引入,对有效特征的提取造成了干扰,因此A-LinkNet在LinkNet的每个编码块后接入注意力模块,增加对有效特征的提取,抑制对无效特征的响应,使得分割过程中更加注意目标特征的提取,避免在解码阶段引入过多的背景特征。同时,由于LinkNet不具有提取多尺度上下文特征的能力,所以对于细小目标以及边界的分割准确度不高,我们引入了空洞空间金字塔池化模块(ASPP),利用多个并联的具有不同膨胀率的卷积操作来捕获多尺度的上下文信息,融合图像的多尺度特征,进一步提高模型分割的准确率。
2 A-LinkNet模型
2.1 A-LinkNet网络结构
本文所提模型主要分为3部分:编码区、中心区以及解码区,其结构图如图1所示。其中,编码区由残差块以及注意力模块串联组合而成。对于输入图像,首先通过一个初始卷积模块对输入图片进行降维,该模块由一个卷积核大小为7、步长为2的卷积层以及一个卷积核大小为3,步长为2的最大池化层组成。然后连接4个残差块,残差块结构如图2所示。与LinkNet编码器不同的是,我们在前3个残差块后分别连接一个注意力模块,使用位置注意力机制对特征图中的每个像素点进行建模,增加目标特征的响应能力,同时使用通道注意力机制对特征图中的不同通道特征进行建模,对不同的通道赋予不同的权重,增加对有利通道的响应,然后将得到的通道特征与位置特征进行特征融合,得到注意力模块的输出。
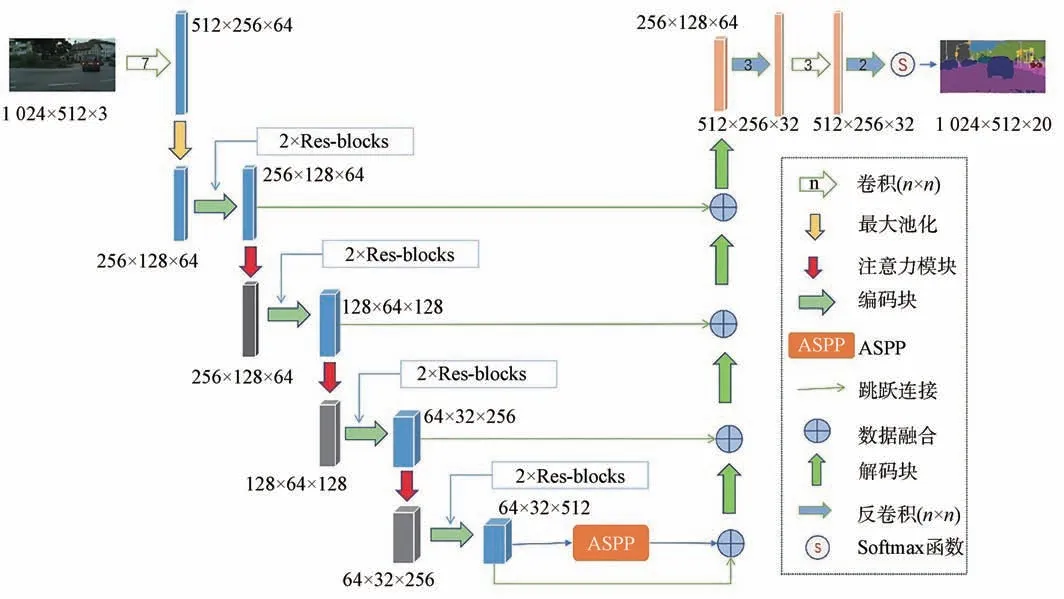
图1 A-LinkNet结构Fig.1 Structure of A-LinkNet
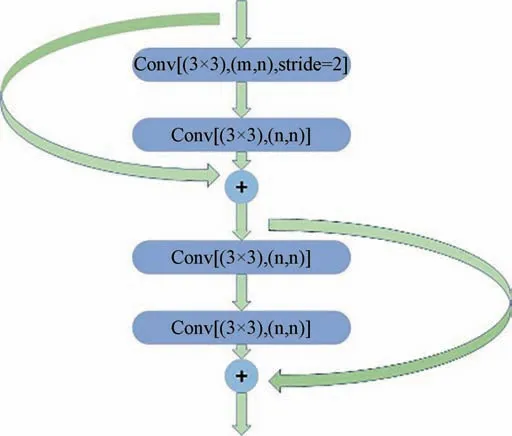
图2 残差块结构Fig.2 Structure of residual blocks
中心区在LinkNet的基础上引入了ASPP模块,该 模 型 最 早 是 在DeepLabv2网 络[10]中 被 提出,因为其在处理多尺度特征提取中表现优异,而后在图像语义分割中得到广泛应用,其结构如图3所示。ASPP模块由一个卷积核大小为1的卷积层、3个卷积核大小为3、膨胀率为6、12、18的空洞卷积层以及一个全局平均池化层并联而成,之后将得到的特征图在通道维度上进行特征融合,最后通过一个1×1卷积操作来降低特征通道数。通过使用空洞卷积,可以在不影响图像分辨率的前提下增大图像的感受野,更好地捕获上下文信息。设置不同的空洞率可以得到不同尺度的特征图,更好地提取多尺度信息。最后增加全局平均池化,将图像级特征融进ASPP中,提供位置信息。
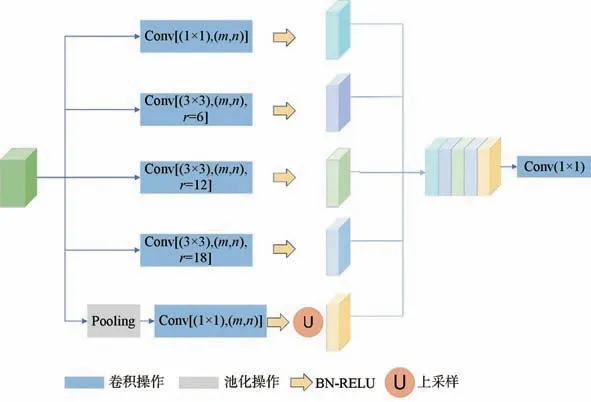
图3 空洞空间金字塔池化模块Fig.3 Atrous spatial pyramid pooling module
解码区的结构和LinkNet相同,由4个解码块串联组成,每个解码块的结构如图4所示。该结构使用两个卷结核为1的卷积提高网络的计算效率,使用一个3×3的反卷积进行上采样,逐步恢复特征图大小。此外,直接将解码器与编码器相连接,与编码阶段的特征信息进行融合,可以更好地保留空间信息,最终得到与输入图像大小相同的分割图像。
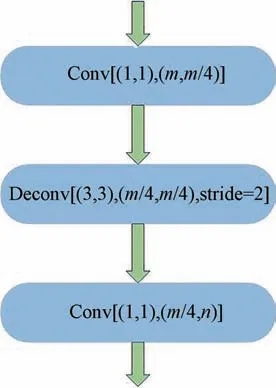
图4 解码块结构Fig.4 Structure of decoder blocks
2.2 注意力模块
在道路图像中,由于物体种类比较多,类间差异比较大,图像的背景比较复杂,给分割带来了一定的难度。在深度卷积网络中,较浅层中的特征图分辨率高,可以学到轮廓、边界等低级的空间特征。随着网络的加深,可以得到语义更加丰富的高层特征,但是由于低层特征中含有大量背景特征信息,会给深层特征的学习带来干扰。因此,受到SENet[12]以及DANet[14]的启发,我们提出了基于位置和通道的注意力模块,可以从空间相对位置以及不同通道间的依赖中捕获全局上下文信息,对特征进行加权,减少背景特征的权重,增加目标特征的权重,抑制无用信息的干扰。
注意力模块由位置注意力机制和通道注意力机制组成,结构如图5所示。其中,上半部分表示位置注意力模块,下半部分表示通道注意力模块,最后将两个模块的结果进行特征融合。具体来说,位置注意力机制通过对任意两个像素点进行建模来表示两个位置的相关性,这样具有相似特征的两个像素可以相互提升,得到较高的权重。通道注意力机制通过网络学习得到不同的通道权重,进而增加有效通道的响应。
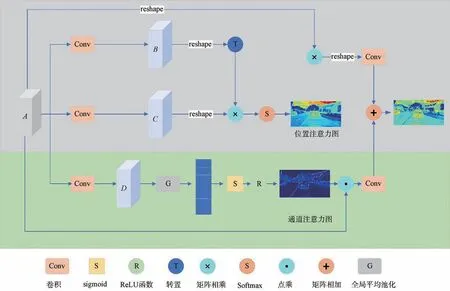
图5 本文提出的注意力模块Fig.5 Attention module proposed in this paper
对于输入特征A,经过卷积核大小为1的卷积层进行降维操作,得到与输入特征A尺寸相同的特征B、C;将特征B进行转置后与特征C进行矩阵相乘,进而建模特征图中任意两个像素点之间的相似性,然后通过Softmax函数计算得到相应的位置注意力图P,如式(1)所示:
其中,Pji∈RN×N表示特征图中第j个像素与第i个点之间的特征相似性,B、C∈RN×T,N=H×W,H、W分别表示特征图的高和宽,T表示通道数。最后将注意力图P与输入特征A进行相乘得到处理后的位置注意力特征Pf,如式(2)所示:

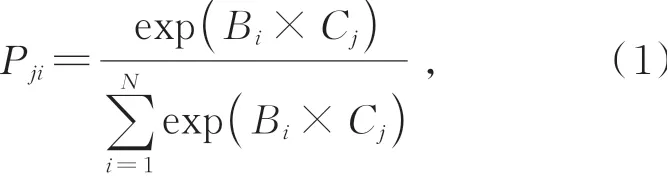
其中,α表示尺度系数,初始化为0,逐渐学习得到更大的权重。
同样,输入特征A经过卷积核大小为1的卷积层进行了降维操作,得到新的特征D,然后对特征D进行全局平均池化,得到可以表征各通道的全局信息;然后连接两个全连接层来建模通道间的非线性相关性,第一个全连接层后我们使用ReLU函数来提取更多的非线性特征,第二个全连接层后我们使用Sigmoid函数获得通道注意力图H,具体计算方法如式(3)所示:
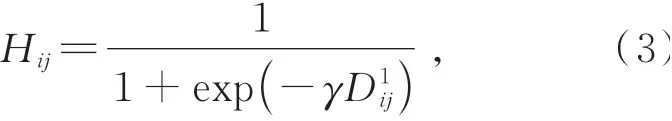

最终,使用1×1卷积将得到的位置注意力特征与通道注意力特征还原至输入维度,最后进行特征融合,得到注意力输出特征。
3 实验结果与分析
3.1 数据集及实验设置
本文实验采用的是Cityscapes数据集[20],该数据集主要包含来自50个不同大型城市的街道场景,其中包含5 000张带有精细标注的图像以及20 000张带有粗糙标注的图像。我们使用精细标注的图像进行实验,其中2 975张用作训练集,500张用作验证集,剩余1 525张为测试集。数据集共包含30个类别,其中的19个类别被选定用于训练和评估。
本文实验均在内存为48 G的NVIDIA Quadro RTX 8 000 GPU上进行训练,采用pytorch1.2.0框架。模型优化器选用Adam算法[21],初始学习率设置为5e-4,并使用交叉熵损失函数优化所有模型。输入图片大小为1 024×512,批处理大小为16,epoch设置为200。
本文采用平均交并比(Mean Intersection over Union,MIoU)作为评估指标,表示分割结果与真实值的重合度,是目前语义分割领域最常用的评价指标之一。其计算公式如下:

其中,N表示类别总数,TP、FN、FP、TN分别表示真正例、假反例、假正例、真反例。
3.2 对比实验
3.2.1 ASPP模块实验
为了验证ASPP模块不同膨胀率组合的效果,本文设计了多组ASPP结构进行实验,结果如表1所示。
在相同的计算条件下,ASPP模块可以提供更大的感受野,采用不同膨胀率的空洞卷积可以捕获不同尺度的信息。随着感受野的增大,模型的性能逐渐提高。在表1中,可以看到ASPP模块的增加对模型的性能有一定的提高,与LinkNet原始模型比较,MIoU分别提高了0.86%、1.69%、2.06%以及1.18%。但是如果膨胀率过大,会导致卷积核跑到padding区域,产生无意义的权重,导致性能下降。本文采用[12,18,24]组合的ASPP模块与[6,12,18]组合相比,MIoU并未有效提高。因此,在本文后续实验中,选择膨胀率为[6,12,18]的空洞卷积来提高模型的准确度。
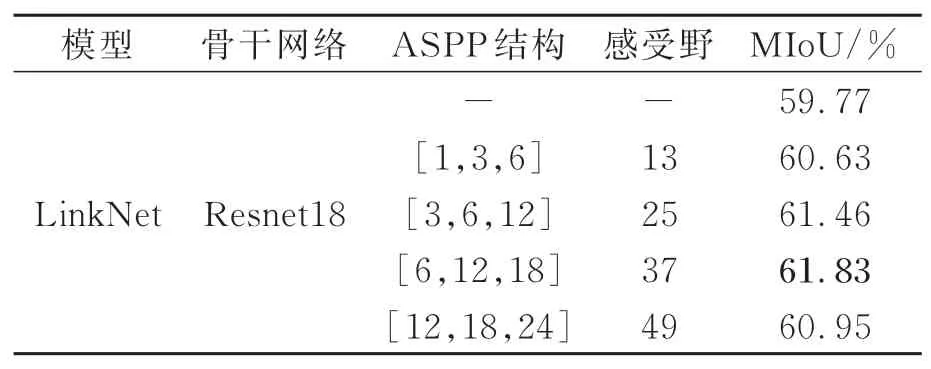
表1 不同膨胀率组合对比实验Tab.1 Comparative experiment of different dilation rate combinations
3.2.2消融实验
为了验证注意力机制以及ASPP模块的有效性,本文在Cityscapes数据集上进行了消融对比实验,具体实验设置以及结果如表2所示。

表2 在Cityscapes数据集上的消融实验Tab.2 Ablation experiment on the Cityscapes dataset
从表2可以看出,使用LinkNet原始模型得到的MIoU为59.77%,与原始模型相比较,仅加入注意力机制的模型分割结果为62.04%,增加了2.27%;仅加入ASPP模块,虽然参数量和计算量有所增加,但是MIoU提高了2.06%;同时加入注意力机制和ASPP模块,最终的分割结果为64.78%。可以看出,本文方法有效提高了道路语义分割准确率。
实验过程中的Loss曲线如图6(a)所示,可以看出,在经过约100个epoch之后,该模型可以很好地实现收敛。同时,我们统计了训练过程中的平均像素准确度(Mean Pixel Accuracy,MPA),如图6(b)所 示。随着epoch的增加,MPA逐渐增大,在167个epoch时,模型的平均像素准确度达到最大,为93.42%。

图6 训练曲线图Fig.6 Curvs of training
3.3 结果与分析
为了验证所提方法的实验效果,与其他方法在相同的软硬件环境下进行实验,采用相同的实验参数在Cityscapes验证集上进行对比。对比方法选择了FCN[3]、SegNet[5]与ENet[6]。FCN是图像语义分割领域的经典模型,SegNet是编码器-解码器结构的代表,ENet则是轻量级模型的代表。实时性对比结果如表3所示,MIoU对比结果如表4所示。
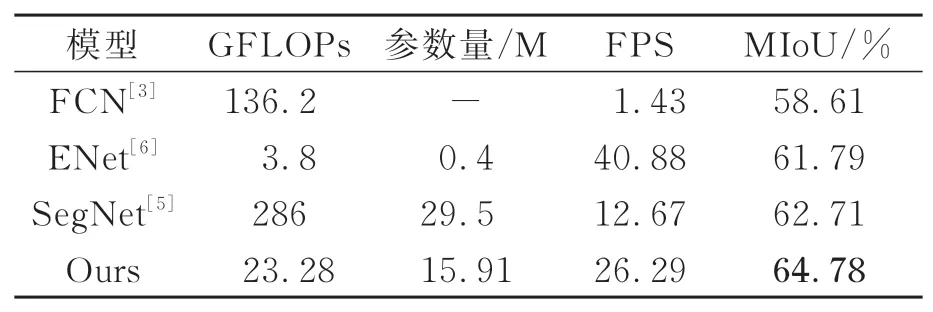
表3 实时性能对比实验Tab.3 Real-time performance comparison
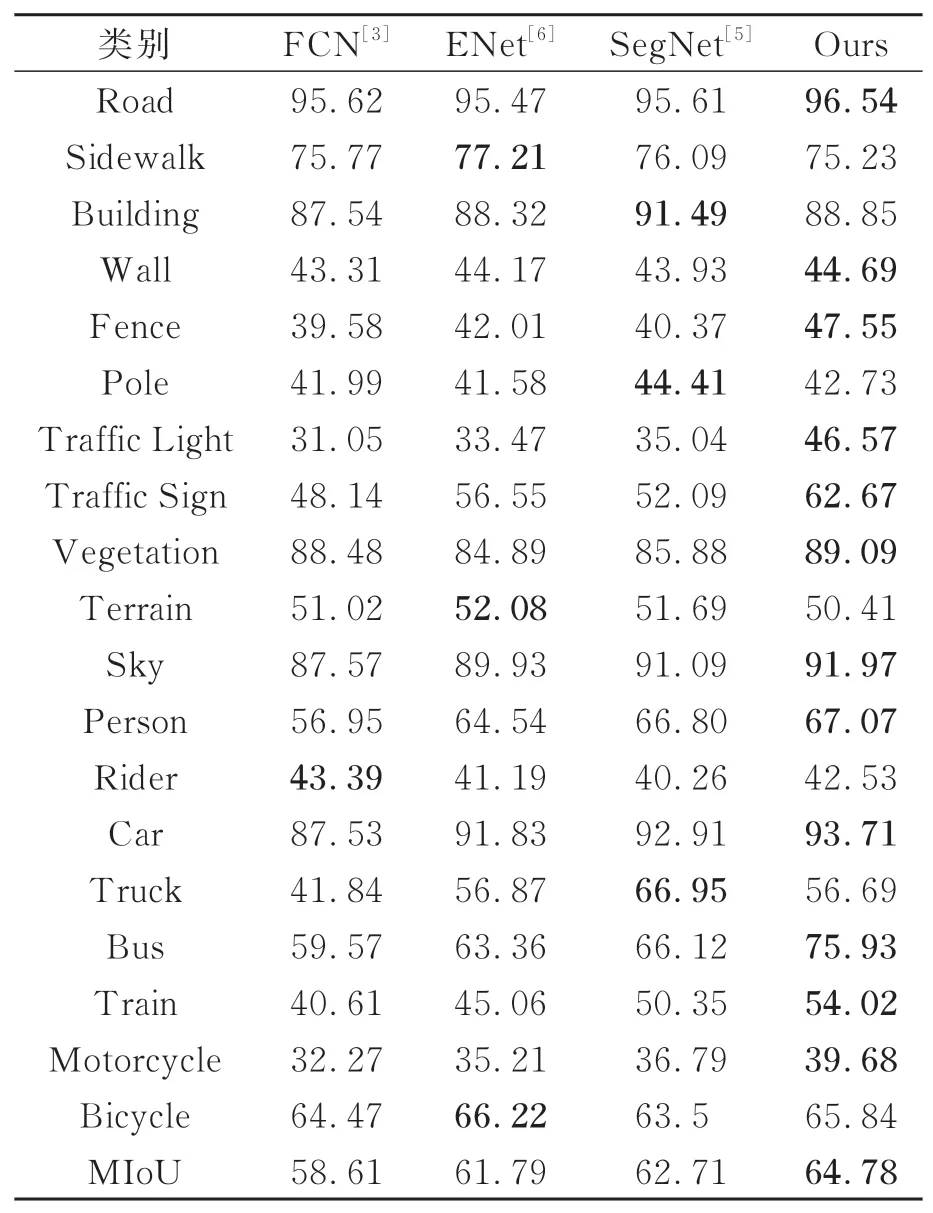
表4 本文方法与其他网络在Cityscapes验证集上MIoU值对比结果Tab.4 Comparative of MIoU values between the method in this paper and others on the Cityscapes validation set
从表3可以看出,FCN网络的分割速度最差;SegNet的分割速度有所提高,但其参数量庞大;ENet作为轻量级网络的代表,具有良好的实时性。本文所提算法虽然实时性不及ENet,但是对比FCN、SegNet,分割速度大幅提高,并且MIoU高于ENet。
从表4可以看出,本文所提方法MIoU结果为64.78%,与其他方法相比,模型性能有了一定提高,比经典的FCN提高了6.17%。另外,我们统计了每一类的IoU,所提方法虽然没有达到每一类都是最优,但是对于多数类别表现最佳。由于注意力机制以及ASPP模块的增加捕获了更加丰富的上下文信息,对于信号灯、信号标志等细小物体的分割,MIoU获得大幅提高。
为了更加直观地对比实验结果,我们在图7中对部分分割结果图像进行了展示。在第1行中,FCN网络对于公共汽车的分割较为粗糙,边缘预测不够突出;SegNet网络对于公共汽车边界的分割有所提高,但是在车顶上方出现了干扰信息,有几处出现识别错误;而本文提出的方法对于公共汽车的轮廓预测更加清晰,对于车身的识别也比较完整。在第2行中,对比FCN网络以及SegNet网络对于图片左侧人行横道的识别,本文所提方法的效果更加完整。在第3行中,对于交通信号灯以及栏杆等细小物体的分割,FCN表现较差,分割边界不清晰,不能完整识别杆状物;SegNet网络分割效果较好,但仍有些细节处理不清晰。在第4行中,对于行人的分割,FCN网络以及SegNet网络分割效果粗糙,边界不明显,识别不完整;本文所提方法对于行人的识别比较完整,边界处较为清晰。在第5行中,对于草等水平植被的识别,FCN网络的分割结果最差,出现多处识别错误,将水平植被误识为树木等垂直植被;SegNet网络将水平植被误识为人行道;而本文所提方法分割相对完整。在第6行中,FCN网络以及SegNet网络对于建筑物的分割效果较差,出现大面积识别错误;而本文所提方法分割结果较为准确。另外,对于交通标志的识别,本文所提方法识别形状更为准确。在第7行中,对于自行车以及骑行者的识别,本文所提方法较为形象,分割结果更为完整。相比较而言,本文所提方法能更加准确地分割细小物体,边界更加清晰,形状更加完整。总的来说,本文所提方法在Cityscapes验证集上可以预测出更优良的分割结果。
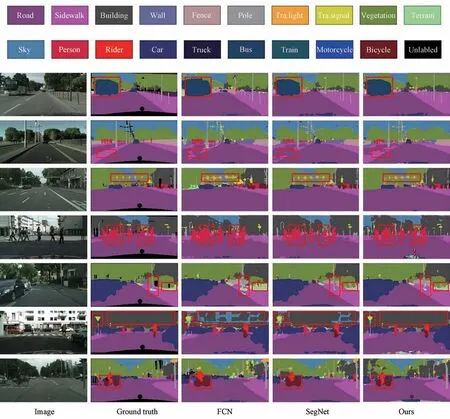
图7 不同模型在Cityscapes验证集上的分割结果Fig.7 Segmentation results of different models on the Cityscapes validation set
4 结 论
本文在LinkNet分割网络的基础上进行改进,可以较好地弥补LinkNet在道路图像分割中的不足。具体来说,在编码器-解码器的结构上加入注意力机制,分别对位置以及通道维度的特征进行建模,挖掘道路图像在空间维度以及通道维度的上下文依赖信息,提高模型对有效特征的提取能力,避免无效信息的干扰。另外,在中心区域引入空洞空间金字塔池化模块,通过使用不同膨胀率的空洞卷积融合道路图像的多尺度特征,提取更加丰富的上下文信息,进一步提高模型分割的准确度。本文模型在Cityscapes数据集上分割结果表现优异,与其他网络相比较,MIoU达到了64.78%,且分割结果中目标特征更加完整,边界更加清晰。在后续的研究中,会考虑优化损失函数,探索更高效的语义分割网络,保证模型在分割速度与分割精度上有更好的平衡。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
传媒评论(2017年3期)2017-06-13 09:18:10
电子设计工程(2017年20期)2017-02-10 03:39:29
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电子器件(2015年5期)2015-12-29 08:42:24
