
基于GA-SLSTM模型的城市轨道交通短时客流预测
2022-09-06 09:14刘正琦王小敏
铁路计算机应用 2022年8期
滕 腾,刘正琦,王小敏
(西南交通大学 信息科学与技术学院,成都 611756)
近年来,城市轨道交通因其便捷舒适、绿色低碳等特点受到大众青睐,但大客流也造成了高峰时段站点拥挤、列车晚点等一系列问题[1]。客流的不断增加,使得短时客流预测成为运营部门保障行车安全、优化行车运营效率的关键,同时也为乘客出行规划提供参考依据[2-3]。短时客流预测指预测粒度小于15 min的客流预测,相比中长期预测具有更大的随机性和波动性,预测的准确性也直接关系到城市轨道交通组织运营的高效性和合理性。
针对城市轨道交通短时客流预测,众多学者研究采用非线性预测方法或组合优化模型的预测方法,证明了对短时客流进行预测的可行性[4-5]。但常用于客流预测问题的卷积神经网络或循环神经网络(RNN ,Recurrent Neural Network)模型受困于梯度消失或梯度爆炸,难以处理存在显著的季节特性、长时间跨度的数据,长短时记忆(LSTM,Long Short Term Memory )模型对这些问题进行了改进。王秋雯等人[6]将LSTM模型与自适应K-means算法结合,并证明了该方法在客流预测问题上的有效性;Liu等人[7]将历史数据分为最近、近期和长期分别输入LSTM模型中 ,提高了预测准确性。预测模型超参数的选择至关重要,影响着模型的好坏,一些研究人员引入优化算法进行优化。仇建华等人[8]使用遗传算法(GA,Genetic Algorithm)优化相关向量机的核函数和核参数;惠阳等人[9]使用粒子群算法优化BP(Back Propagation)神经网络。
本文引入能有效处理复杂非线性问题、优化初始值和阈值的GA,对堆叠式LSTM(SLSTM,Stacked LSTM)模型的神经网络结构进行优化,构建了GA-SLSTM预测模型。采用该预测模型对车站进出站客流进行预测,以杭州市地铁历史运营数据为例展开试验。对比GA-RNN模型和单层未优化LSTM模型对普通站点和换乘站的客流预测结果,证明了本文方法能够提高短时客流的预测精度。
1 GA-SLSTM地铁客流预测模型
1.1 SLSTM模型概述
LSTM模型在1997年由Hochichreiter和Schmidhuber提出[10],保持了RNN模型的链状结构,改进了RNN模型不能处理长期依赖的情况,并在一定程度上解决了梯度消失的问题,适用于学习具有长期趋势性和周期性的客流序列。LSTM模型单元内部结构增加了遗忘门ft、输入门it和 输出门ot3个门限控制,通过Sigmoid函数和点乘操作,限制序列信息的流入,并将上一时刻状态输入下一时刻进行计算,其数学表达式为
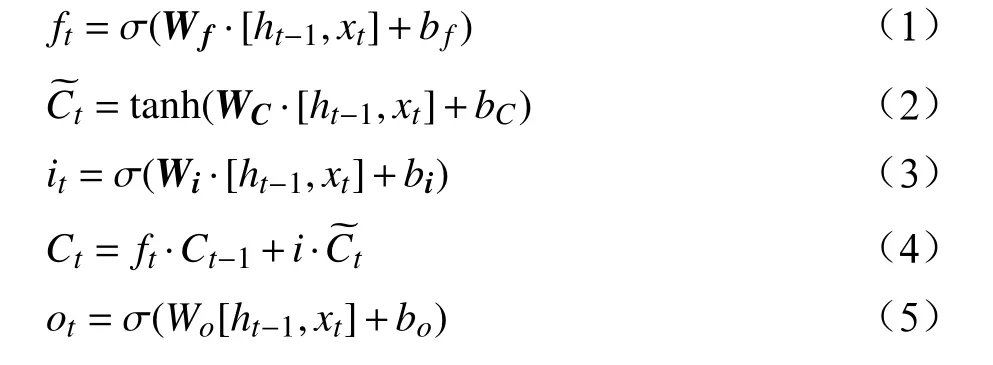

其中,xt为t时刻输入数据;σ为Sigmoid函数;{Wi,Wf,Wo,WC}分别为输入门、遗忘门、输出门和细胞状态的参数矩阵; {bi,bf,bo,bC}为输入门、遗忘门、输出门和细胞状态的偏移量;为候选细胞状态,Ct为 细胞状态;ht为隐藏状态。
SLSTM模型中有多个隐藏LSTM层,每层包含多个LSTM单元,可对长期状态进行处理。Graves等人[11]证明了LSTM层级的堆叠比增加内部LSTM单元具有更好的预测性能,可通过加深网络层级解决更加复杂的问题。SLSTM结构层级间的状态转移如图1所示,上层的LSTM结构输出一个隐藏状态序列,输入到下一层结构中,其中,和分别是第l层t时刻的细胞状态和隐藏状态。

图1 SLSTM神经层状态传递释义
1.2 GA-SLSTM模型
GA是生物遗传和进化的优化算法,具有较强的全局搜索能力,本文采用GA对SLSTM模型进行优化。主要优化的参数有:SLSTM层数、SLSTM隐藏层每层单元数量、全连接层层数、全连接层每层神经元个数。针对具有非线性和随机性的城市轨道交通短时客流预测问题,建立了GA-SLSTM 预测模型,如图2所示。

图2 优化GA-SLSTM模型流程示意
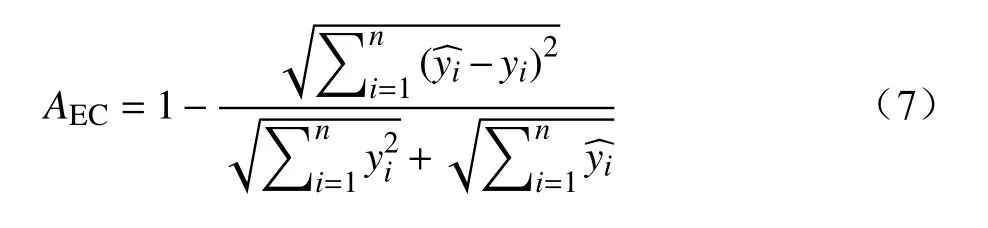
其中,yi为 真实值;为预测值。均等系数AEC∈[0,1],其值越接近1表示预测值越接近真实值,则该个体被选择的概率也越大,下一代种群根据适应度选择个体,并进行交叉、变异操作。本文设置最大种群迭代为20代,重复选择、交叉和变异生成随机种群,并搭建相应模型直至最大种群迭代,输出预测结果AEC值最大的最优个体和相应预测模型。
2 客流变化特征分析
由于乘客日常出行具有规律性,站点进出站客流表现出明显的周期性,同时,由于天气、突发活动等随机因素的影响,使其具有波动性。本文以杭州市1号线普通站点西兴站和换乘站火车东站为例分析客流变化特征。
2.1 一个星期内客流特征
2019年1月5—25日西兴站3个星期内的客流进站情况如图3所示。从图3中可知,单日内客流随机波动大,1个星期内客流曲线存在相似性,工作日和休息日客流特性呈现出明显差异,工作日表现出双峰型客流特征,休息日表现出明显的无峰型客流特征;星期与星期之间客流变化趋势相似,具有明显的周期性。

图3 西兴站进站客流的周期特性
采用层次聚类算法将1个星期7天客流量作为聚类特征,簇间样本点间距离采用欧式距离计算,生成层次聚类树形图如图4所示,虚线为类别分割线。从图4中可看出,虚线将西兴站1个星期进站客流划分为星期一~星期五和休息日两类,工作日和休息日客流特征分化明显,可将1个星期内的进站客流量分为工作日和休息日2类。而属于换乘站的火车东站工作日与休息日之间客流分布没有明显相似性,每一天客流趋势都被单独划分,与其余几天欧式距离较大。西兴站2个星期之间每日客流的Spearman相关系数如表1所示。从表1中可知,工作日与上个星期工作日间相关系数大,相关系数最大值在上个星期相邻几日间略有浮动,和上个星期工作日的相关系数较小;休息日和上个星期工作日相关性小,星期六和星期日分别与上个星期六和上个星期日相关系数最大,周期性明显。

图4 7天内客流层次聚类
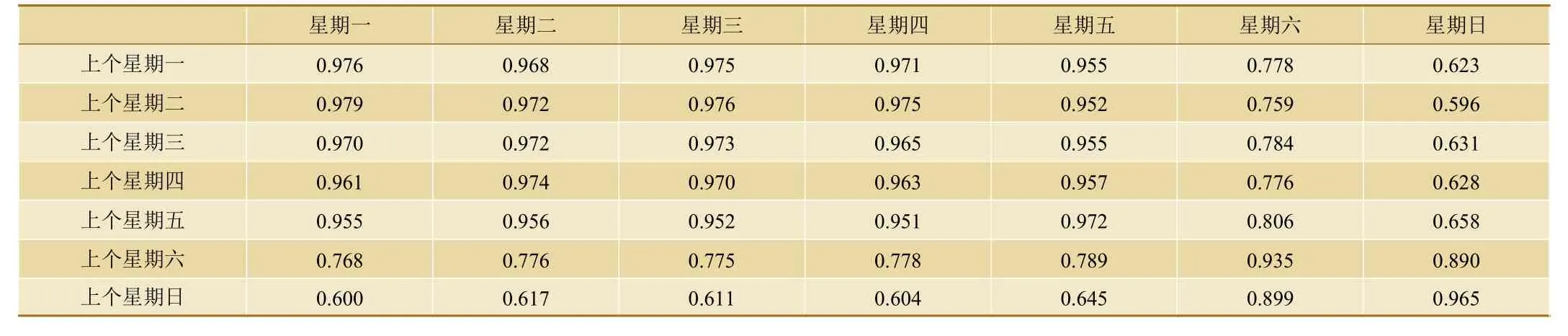
表1 西兴站2个星期之间客流Spearman相关系数
2.2 日客流特征
车站1日内进出站客流体现出固定的客流趋势,分为单峰型、双峰型、全峰型和无峰型,早晚高峰不同时间段和平峰不同时间段间客流存在相似性。图5是星期一不同时间段进站客流层次聚类的散点图,选用刷卡闸机数/min、客流量/min、当前时间段客流量、前后时间段客流量等23维聚类特征映射到多维空间进行聚类。西兴站远离市中心,全天客流量较小,高峰时进站客流量在60 人/min左右,平峰时在5 人/min左右。火车东站属于全峰型客流特征,高峰客流达到150 人/min。虽然不同站点日内客流分布不同,但图5中高峰段和平峰段等不同时间段分类明显。

图5 1日内不同时间段进站客流量聚类
3 地铁客流预测实例与结果分析
3.1 数据预处理
本文采用2019年1月5—25日杭州市地铁AFC系统的历史刷卡记录作为实验数据,共81个站点,每天约200万条刷卡记录。每条刷卡记录的数据包含刷卡时间、用户ID、站台编号闸机设备编号、进出站状态、线路号和支付类型。检查重复值和空值后,整理成10 min为粒度的进出站客流数据样本,整理后共291600个数据样本。将2019年1月5—21日的数据作为训练集,2019年1月22—24日的数据为验证集,对2019年1月25日站点进出站客流进行10 min粒度预测。
3.2 特征提取
提取乘客进出站时间、星期、每10 min间隔的进出站刷卡闸机的数量和天气等14维基本特征,其中,天气特征包括空气质量、风向、风速、气温和状态(晴、阴、雨)。将1日内每10 min和1个星期内每天客流量聚类结果进行定量转换,提取每类的类别标签、平均值和方差作为1日内和1个星期内时间特征。2个星期之间的时间特征直接提取上个星期Spearman相关系数最大的一天的客流数据。
3.3 实验及结果分析
图6是对西兴站的预测模型进行GA优化的前11代种群的适应度曲线。可以看出,第4代之后适应度值趋于平稳,第11代种群的适应度基本高于0.9,逐渐收敛于全局最优解。因此,设置最大种群迭代为20代,每代有10个个体。

图6 遗传算法优化模型前11代适应度曲线
为更加直观地衡量预测效果,引入平均绝对误差(MAE ,Mean Absolute Error)、均方根误差(RMSE ,Root Mean Square Error)和决定系数(R2)对预测结果进行评价,计算公式为
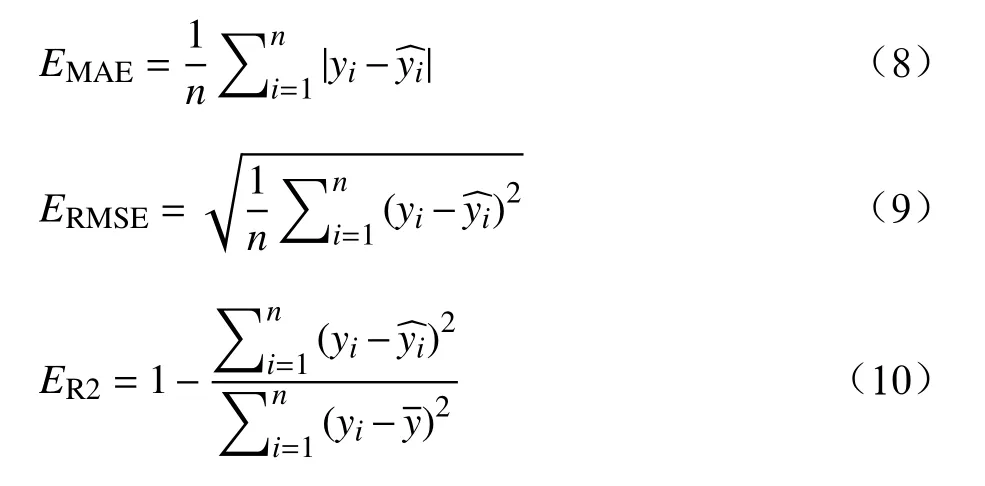
EMAE表示平均预测差值程度,ERMSE表示单位时间间隔平均预测误差的人数,因此EMAE、ERMSE越小,预测精确度越高。ER2代表模型对数据的拟合程度,数值越大,预测值越接近真实值。
LSTM模型是RNN模型的继承和发展,因此选取GA-RNN模型和单层未优化LSTM模型与本文提出的GA-SLSTM预测模型进行对比,每种模型训练3次取预测结果评价指标的平均值。单层LSTM模型的神经元个数在[32, 256]范围内、间隔32的数组中依次选取,以EMAE最小值的预测值作为预测结果。
3.3.1 普通站点预测结果
不同模型对西兴站的预测值与真实值曲线如图7所示,预测评价指标如表2所示。可见,本文提出的方法各项指标均优于其他方法,预测值更接近真实值,ER2可达0.95。

图7 西兴站不同模型预测结果
3.3.2 换乘站点预测结果
不同模型对换乘站火车东站的预测值及真实值曲线如图8所示,预测评价指标如表3所示。由于换乘站客流随机波动大,周期特征不明显,预测准确度低于普通站点。不同模型的预测值基本符合真实值,本文提出的方法各项指标均优于其他方法。

表3 火车东站不同模型预测指标对比

图8 火车东站不同模型预测结果
4 结束语
实验结果表明,本文提出GA-SLSTM模型能够提高城市轨道交通短时客流预测准确性。引入GA优化神经网络结构,相比手动调参等方式,使得模型更有说服性。优化后的SLSTM预测模型能够学习长序列信息,精确预测客流变化,无论是在普通站点还是在换乘站点,其预测效果都明显优于其他模型。此外,为更好地提高短时客流预测准确性,下一步需对换乘站的大客流数据进行趋势、周期和噪声分解分析及研究,进一步提高换乘站预测准确性。
猜你喜欢
环球时报(2022-12-12)2022-12-12
汽车实用技术(2022年7期)2022-04-20
现代电子技术(2021年15期)2021-08-06
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
数学大王·中高年级(2019年5期)2019-06-09
北方工业大学学报(2019年5期)2019-03-30
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
