
基于生成对抗模型的序列推荐算法
2022-09-05 09:00陈继伟汪海涛
中文信息学报 2022年7期
陈继伟,汪海涛,姜 瑛,陈 星
(昆明理工大学 信息工程与自动化学院,云南 昆明 650550)
0 引言
推荐系统作为缓解信息过载的智能工具受到学术界和工业界的广泛关注[1]。传统的推荐算法依据显式反馈建模用户的长期稳定偏好,无法学习隐式反馈数据的深层特征[2]。显式反馈指用户对物品喜好的明确表示,主要包括评分、评级。隐式反馈行为指不能明确反映用户喜好的行为[3]。隐式反馈(如页面浏览,点击)虽然不明确,但数据量更大[4]。基于深度学习的序列推荐算法可以学习用户行为日志,挖掘隐式反馈数据的深层特征,从而捕获用户兴趣偏好[5]。此外,用户的行为意图往往随着各种因素的影响发生改变,呈现出某种趋势或者序列模式。序列推荐算法不仅能够捕获用户的长期稳定偏好,而且能够学习用户项目交互的序列模式,弥补了传统推荐算法的不足[6]。
现有的序列推荐算法聚焦于用户的交互序列,忽略项目内容之间的联系,然而项目内容对预测用户下次交互项目具有重要意义[7]。在电影推荐中,同一导演、同一主演等信息可能成为用户选择影片的重要决定因素。此外,用户交互的时间戳信息包含重要的上下文语义[8]。例如,在商品推荐系统中,人们往往喜欢在夏天购买短袖,冬天购买羽绒服,亦或人们购买某种商品时在时间上呈现某种周期性规律,对于用户下次交互项目的预测具有重要意义[9]。现有的序列推荐算法采用生成预测向量的方式来预测下一时间点的交互项目,使用极大似然估计(Maximum Likelihood Estimate,MLE)来学习模型参数,容易受到数据稀疏或暴露偏差等问题的影响[10]。此外,传统的序列推荐算法,将交互项目的内容信息(如电子商务场景中产品的价格和品牌)混合在顺序上下文表示中,无法准确计算出每个个体因素如何影响最终的推荐性能。这些缺点削弱甚至阻碍了它们在决策中的作用[11]。明确有效地描述序列推荐系统中各种因素的影响非常重要,因此本文运用多判别器的生成对抗模型建模序列推荐任务。
基于上述研究,本文提出一种基于生成对抗模型的序列推荐算法,命名为CT-GAN。本文的主要贡献有以下几点:
(1) 通过改进的时间嵌入建模用户交互的时间戳信息,充分捕获用户项目交互关于时间的周期性模式。
(2) 运用卷积神经网络作为生成对抗模型的生成器捕获用户的动态偏好,运用注意力机制捕获用户的静态偏好,并通过生成对抗模型将动态偏好和静态偏好融合,提升推荐系统的用户体验。
(3) 多判别器分别建模不同的因素,通过不同因素判断生成器生成的推荐是否合理,并作为反馈信号指导生成器训练。充分利用项目的时间、内容信息,提高推荐系统的可解释性。
1 相关工作
序列推荐旨在通过用户交互历史为用户推荐下次交互的项目。马尔可夫假设是较早运用于序列推荐的方法,Shani等人认为用户下次交互的项目只与最近交互的L个项目相关,并将推荐生成形式化为一个序列优化问题,并使用马尔可夫决策过程(Markov Decision Processes,MDP)来解决这个问题,能够有效建模用户的近期交互,但无法捕捉用户的长期稳定偏好[12]。Rendle等人通过个性化的马尔可夫链分解(Factorizing Personalized Markov Chains,FPMC)将马尔可夫链(Markov Chains,MC)和矩阵分解(Matrix Factorization,MF)结合起来同时建模用户的短期偏好和长期偏好。FPMC为每一个用户建模一个马尔可夫转移矩阵,并通过矩阵分解模型来缓解由于只考虑单个用户维度导致的数据稀疏不容易估计的问题[13]。循环神经网络(Recurrent Neural Network, RNN)因为建模项目与项目之间顺序关系的潜在优势而备受关注,GRU4Rec[14]提出后,RNN被广泛运用于推荐算法,成为序列推荐算法的主流模型。基于RNN的序列推荐算法利用循环神经网络和损失函数将用户交互历史编码到一个向量中,用来表示用户偏好,并据此进行预测。标准RNN认为连续项目之间的分布是均匀的,然而用户历史交互序列中的各项目对生成下一项预测的影响是不一致的,并且基于RNN的推荐算法不利于捕获长距离依赖。为了建模用户交互序列联合级别的影响,跳过某些对用户下次可能交互项目影响较小的项目,Tang和Wang等人提出基于卷积神经网络(Convolutional Neural Network,CNN)的推荐算法Caser,使用水平和垂直卷积滤波器来学习序列模式,并采用简单地可学习用户潜在表示和连接操作来融合用户的长期偏好和近期偏好[15]。近年来,注意力机制在语音识别、自然语言处理领域取得巨大成功,Wang和McAuley等人受Transformer[16]启发,采用自注意力机制建模用户的历史行为信息,并将得到的信息与所有的物品嵌入做内积,根据相关性的大小筛选、排序,最终获得项目推荐列表[17]。生成对抗网络(Generative Adversarial Network,GAN)最初被用来模拟给定数据样本的生成过程。IRGAN首先将生成模型和判别模型统一起来用于信息检索领域,采用简单的矩阵分解构造生成器和判别器,没有考虑交互项目的序列信息和内容信息[18]。
本文通过对抗训练将内容信息与序列预测分离。与原始GAN框架结构相似,设置生成器和判别器两个不同的组成结构。生成器仅依靠用户项目交互历史预测下次可能交互的项目,判别器则根据各种影响因素判断生成的推荐是否合理,从而更好地建模用户偏好,提高推荐系统的推荐性能和可解释性。
2 基于GAN模型的序列推荐算法
本文提出的序列推荐算法,主要由生成器和判别器两部分组成。模型的整体框架如图1所示。

图1 模型的整体框架
2.1 CT-GAN模型的整体构架
2.1.1 CT-GAN模型框架
构造生成器和判别器两个不同组成结构,在序列推荐任务中执行不同的任务,实现序列建模和相关影响因素建模分离。
(1) 生成器作为序列推荐任务的生成模型,通过卷积神经网络学习用户的交互历史,生成用户下次交互预测。生成器只捕获用户交互历史的序列模式,不关注交互的具体时间和项目内容相关信息。
(2) 判别器{D1,D2,…,Dm}作为序列推荐任务的评估模型,利用m个判别器分别建模交互的时间信息和项目内容信息,判断生成器生成预测向量的合理程度,并作为反馈信号指导生成器下一轮的训练。例如,在商品推荐中可以用多判别器分别建模商品的流行度、商家或者所属的商品种类。
2.1.2 算法的整体流程

2.2 生成器
在CT-GAN模型框架中,本文用GX来表示生成器,其中X表示生成器GX中的一系列相关参数。生成器GX的主干网络为卷积神经网络。通过嵌入层、卷积层和全连接层连接,捕获用户交互的序列模式,并预测用户下一时间点的交互项目。生成器的预测过程如图2所示,下面将详细介绍各层的实现细节。

图2 生成器的预测过程
2.2.1 嵌入层
生成器GX捕获潜在空间中用户交互历史的序列特征,预测用户下次可能交互的项目。生成器的输入为用户前n次交互项目嵌入向量构成的嵌入矩阵。首先构造一个包含所有项目的嵌入矩阵I∈R|I|×d,其中,I为可学习的项目嵌入矩阵,|I|为所有项目个数,d为嵌入维度。然后通过在项目嵌入矩阵I中执行查询操作,构造用户前n次交互的项目矩阵EG∈Rn×d[19]。
2.2.2 卷积层
卷积神经网络中的卷积滤波器被运用于图像识别[20]和文本分类[21]等领域以获取局部特征,并取得较好的实验结果。本文利用卷积神经网络在文本分类中的方法,将n×d维的矩阵EG视为用户交互序列在d维潜在向量空间上的图片,序列模式为图片的局部特征。利用卷积滤波器获取用户交互的序列模式,水平滤波器为h×d维的矩阵,其中高度为h,宽度与嵌入向量的维度相同为d,通过水平滤波器EG在矩阵的行向量上滑动,获取用户交互的序列模式信号。与水平滤波器相似,用n×1维的矩阵来构造垂直滤波器,并让其在矩阵EG的列上滑动,与普通的图片不同,嵌入矩阵EG并非直接给出,而需要跟随卷积滤波器一起学习,下面介绍实现的具体细节。
水平卷积层: 本文运用m个水平滤波器Hk∈Rh*d,1 (1) (2) 因为最大值代表卷积滤波器捕获的最重要特征,所以接下来运用最大池化操作来处理Ck,从卷积滤波器生成的向量中获取最大值。m个卷积滤波器的输出用O∈Rm表示,如式(3)所示。 O={max(C1),max(C2),…,max(Cm)} (3) 水平滤波器与项目嵌入矩阵中连续h个项目交互。水平卷积滤波器和项目嵌入矩阵都被学习以最小化目标函数。滑动不同尺寸的卷积滤波器,将获取不同的序列模式。不同卷积滤波器建模不同数目的交互项目,通过水平滤波器的学习可以捕捉到多种维度的级联序列模式。 垂直卷积层: 假设有m1个垂直卷积滤波器Vk∈Rn×1,1≤k≤m1,每个卷积滤波器Vk与交互序列的一列交互,经过d轮从嵌入矩阵EG的最左侧移动到最右侧,生成卷积结果,如式(4)所示。 (4) 卷积滤波器Vk与矩阵为内积交互,容易证明交互的结果为嵌入矩阵的n行加权和,权重为垂直卷积滤波器中各个维度的取值,计算如式(5)所示。 (5) (6) 2.2.3 全连接层 该层整合前两层卷积神经网络的输出,将结果输入全连接神经网络,获得更高级别的抽象特征,如式(7)所示。 (7) 2.2.4 预测层 教师应该尊重理解学生的独特性,不以造型上的“像不像”“对不对”作为评价的标准,要按照儿童年龄发展规律去理解他们的作品。鼓励学生展示作品,让他们说说自己作品的创意。评价过程中要注重学生的自我评价和学生之间的互评。评价标准要多元化,不拘泥于形式,不以分数作为唯一标准,注重评价的过程。通过有效的评价激发学生兴趣。 在生成器的最后一层,我们通过Softmax函数计算用户对所有候选项目I的偏好,取用户下次实际交互项目it对应的取值作为生成器自身的奖励信号,计算如式(8)所示。 (8) 在判别器中,考虑交互序列的时间信息和m-1种可能影响序列推荐算法性能的内容信息,为每个因素建立一个单独的判别器,充分利用内容信息和时间戳信息。此外,分别建模不同的内容信息有利于探索各种因素对推荐结果的影响,提高推荐系统的可解释性。模型运用m个判别器Dθ={Dθ1,Dθ2,…,Dθm}来判断生成器生成的预测向量是否合理。其中θi表示第i个判别器的相关参数列表。此过程跟二分类问题相似,判别器比较生成序列和实际的交互序列,并生成奖励信号R。每个判别器的判定过程和参数都是独立的。 2.3.1 嵌入层 (9) 图3 注意力机制的计算过程 2.3.2 注意力机制层 运用目前在图像识别和自然语言处理领域[22]取得巨大成功的注意力机制作为判别器的主干部分。在本文的推荐算法中,生成器生成用户下次交互项目的预测,判别器生成反馈信号,提升生成器的预测性能。因此仅运用单层注意力机制来构造生成器,避免判别器自身构造能力太强不能为生成器提供有效反馈,单层注意力机制的计算过程如式(10)所示。 (10) 因为项目的内容信息与项目在交互序列中的位置无关,所以判别器的注意力机制去除面罩操作,使用双向结构。训练时可以运用整个交互序列的相关信息[19]。判别器可以建模任意用户项目交互,基于全体的用户项目交互序列做出更精确的判断,具体实现过程如图4所示,这是以时间嵌入为例。 图4 注意力机制的学习过程 最后,运用多层感知机(MLP)来判断生成器生成的预测向量的合理程度,计算方法如式(11)~式(13)所示。 正如前面各节所描述,本文的序列推荐算法由一个生成器和多个判别器组成。生成器基于用户交互历史预测下一个可能交互的项目。判别器判别生成序列和实际的交互序列,并生成反馈信号指导生成器训练。在本节中将介绍对抗训练的细节。 2.4.1 将项目预测基于强化学习形式化 (14) (15) 其中,γ是一个可学习的参数。判别器迭代更新,生成器逐渐收敛,预测性能达到极限,生成更符合用户意图的推荐项目。通过多因素增强模型架构,判别器从不同角度捕获交互序列中的内容特征,获取用户的长期稳定偏好。判别器在学习项目特征的同时,为生成器提供监督信号,提高生成器的收敛速度。 2.4.2 学习算法 将序列推荐任务形式化为强化学习背景后,运用原始的策略梯度来学习生成器模型的参数,通常生成器GX(it|S1:t-1)在时间步t的优化目标是最大化奖励Rt,计算如式(16)所示。 (16) 上文中已经定义过GX(it|S1:t-1)和R(S1:t-1,it),其中,Rt表示生成序列的奖励。目标函数L(X)的梯度可被延伸为如式(17)所示。 (17) 本文使用梯度上升更新生成器参数,计算如式(18)所示。 (18) 其中,β为参数更新的步长。更新完生成器后,通过最小化如下损失函数继续优化每个判别器Dθj,如式(18)所示。 ES1:t~GX[log(1-Dθj(S1:t))]} (19) 其中,S0表示交互序列的真实数据分布。首先预先训练好生成器GX和多判别器Dθ的参数。生成器的每个生成步骤,我们根据前面的序列S1:t-1生成推荐项目,然后运用多个判别器提供的奖励,通过策略梯度更新生成器参数,每个判别步骤,用户交互序列作为正例,生成序列作为负例,判别器同时进行参数更新,以更好地判别生成序列和交互序列,此过程一直持续到模型收敛。 CT-GAN推荐模型学习算法的形式化描述如下: 输入: 生成器GX,判别器Dθ={Dθ1,Dθ2,…,Dθm},用户交互序列S,候选项目集I。输出: 训练好的CT-GAN模型。1. 随机初始化GX、Dθ的参数X和θ;2.利用最大似然估计训练生成器GX;3.利用生成器GX为判别器Dθ生成负样本;4.利用最小化交叉熵函数预训练Dθ;5.repeat6. for G-steps do7. 根据用户交互序列I1:t-1生成项目预测it。 续表 本文采用MovieLens-1M、Amazon-Beauty两个不同领域的公开数据集作为实验数据,验证提出算法的推荐性能。对于所有数据集,我们将评分或评论信息转换成隐式反馈1,表示用户跟该项目存在交互。首先依据用户将交互记录分组,并根据交互的时间戳信息升序排列,形成用户的交互序列。然后将交互次数小于5的用户和项目过滤掉[17]。 这两个数据集包含多种内容信息,对于每个数据集,获取如下信息作为判别器的判别信息: (1) 对于MovieLens-1M[23],本文选取交互的时间戳信息、电影类别、电影流行度作为判别器的判别信息。 (2) 对于Amazon-Beauty[24],本文选取交互的时间戳信息、商品流行度和商品种类作为判别器的判别信息。经过处理后各数据集的静态特征如表1所示。 表1 数据集静态特征 3.2.1 评价指标 采用广泛使用的leave-one-out评估方法评价CT-GAN推荐算法的推荐性能。对于每个用户交互序列,将用户交互序列的最后一个交互项目作为测试集,将倒数第二个交互项目作为验证集,将其他的交互项目作为训练集。与其他经典的序列推荐模型设置一样,将随机抽取的100个尚未被指定用户交互过的项目作为负样本[17]。与用户实际交互项目排列在一起作为CT-GAN模型的输入,让模型对其排序。为了评价排序表,本文利用以下两个通用的评价指标: HR@10: 命中率,刻画正确推荐项目在测试项目中所占的比例。 (20) 其中,N表示用户的总数量,hits(i)表示第i个用户访问的值是否在推荐列表中,在为1,否则为0,@10表示推荐列表中项目的个数为10。 NDCG@10: 归一化累积增益,不仅考虑HR(命中率),而且考虑排列顺序。给位于推荐列表前端的命中项目分配高分,给位于推荐列表末端的命中项目分配低分。rank表示命中项目在推荐列表中的位置。计算如式(21)所示。 (21) 3.2.2 实验细节 本文运用卷积神经网络构造CT-GAN序列推荐模型的生成器,注意力机制构造推荐模型的判别器,其中嵌入层和预测层的项目嵌入向量相同。本文运用Tensorflow实现序列推荐模型,利用Adam优化器优化模型。在预训练阶段,首先单独训练生成器和判别器,直至收敛。生成器和判别器的mini-batch大小分别设置为128和16。对抗训练阶段,学习率设置为0.001,物品嵌入向量、时间嵌入向量、相关内容嵌入向量的维度均设为64。最大序列长度N在MovieLens-1M和Amazon-Beauty上分别设置为200和50。对于MovieLens-1M和Amazon-Beauty, dropout率分别设置为0.2和0.5,生成器中马尔可夫链的阶数n分别设置为7和5。 POP: 所有项目根据受欢迎程度来排序,受欢迎程度取决于交互的数量。 IRGAN: 通过对抗训练结合生成器和判别器。第一次将生成对抗模型运用于推荐系统,采用简单的矩阵分解法构造生成器和判别器[18]。 BPR: 将贝叶斯个性化排序与矩阵分解模型结合,是比较先进的非序列推荐算法,基于隐式反馈信息[25]。 FPMC: 结合矩阵分解和马尔可夫链,可以同时捕获序列信息和长期用户偏好[13]。 Caser: 在时间和潜在空间中将一系列最近的项目视为一个“图像”,捕获L个最近交互项目的高阶马尔可夫链[15]。 SASRec: 它是一种基于Transformer体系结构的序列推荐方法[17]。 BERT4Rec: 采用深度双向注意力机制建模用户行为序列,取得优秀的序列推荐性能[19]。 为了保证对比公平,本文根据作者提供的源代码,用TensorFlow实现BPR、IRGAN和FPMC。对于Caser,SASRec和BERT4Rec使用相应作者提供的源代码;对于所有模型中的通用超参数,运用网格搜索在验证集上寻找最优参数设置,考虑潜在向量维度的取值范围为{16,32,64,128,256},2正则化参数的取值范围为{1,0.1,0.01,0.001,0.0001},dropout率的取值范围为{0,0.1,0.2,0.3,…,0.9}。所有其他超参数设置和初始化策略与原论文保持一致,并使用验证集调整超参数,下面公布每种方法在其最优超参数设置下的结果。 本节对提出的CT-GAN推荐算法做整体的性能分析。CT-GAN推荐算法与各种对比方法在MovieLens-1M、Amazon-Beauty两个公共数据集基于评价指标HR@10和NDCG@10的性能比较如表2所示。 表2 整体性能分析 由表2显示的实验结果可以看出: (1) 基于流行度的POP推荐显示出不错的推荐性能,这基于人们往往倾向于选择比较受大众欢迎的物品,同时大众的选择倾向也会引起物品的热度提升。给人们推荐流行度较高的物品往往能取得不错的推荐效果,但推荐缺乏个性化。 (2) IRGAN作为目前为止性能较为优秀的非序列推荐算法,但我们基于序列的推荐算法在两个数据集上的推荐性能都较IRGAN好,充分显示建模用户项目交互序列的有效性。 (3) Caser、SASRec、BERT4Rec显示出较FPMC优秀的性能,充分显示出深度神经网络潜在特征的学习能力和序列任务建模能力,BERT4Rec较SASRec性能优秀,显示出深度双向注意力机制序列信息建模的有效性。 (4) CT-GAN在两个数据集上都显示出较基线方法优秀的推荐性能,得益于生成器CNN序列特征的建模能力、多判别器时间戳信息以及内容信息的建模能力,以及生成对抗模型的对抗训练。下文将通过实验详细验证模型各个部分的有效性。 3.5.1 多判别器和改进时间嵌入的有效性分析 本文采用多个判别器分别建模时间信息和内容信息,并通过改进时间嵌入,捕获用户交互序列关于时间的周期性变化模式。下文在数据集MovieLens-1M上进行各部分的有效性验证,首先分别构造CT-GAN模型的变体CT-GAN1和CT-GAN2,CT-GAN1仅运用一个判别器同时捕获用户交互的时间信息和内容信息,CT-GAN2使用可学习的时间嵌入矩阵T1代替构造的时间矩阵T,模型的其他部分与原模型相同,采用与原模型相同的参数进行训练。将变体CT-GAN1和CT-GAN2与原模型进行推荐性能比较,实验结果如表3所示。 表3 多判别器和改进的时间嵌入有效性分析 从表3的实验结果可以看出: 多判别器的采用和改进的时间嵌入有效提高了推荐算法的性能。CT-GAN1的推荐性能较Caser有所提高,证明将用户交互的序列模式建模与时间、内容信息建模相分离具有重要意义,同时也证明对抗训练在序列建模任务中的有效性。本文提出的改进时间嵌入,能充分捕获用户项目交互关于时间的周期变化规律,有效建模用户项目交互的时间特征。这基于用户喜欢在某个特定的时间段观看某种特定类型的电影,或者用户重复观看某一部电影或同一题材的电影呈现出某种周期性的变化规律。CT-GAN表现出较CT-GAN2强的推荐性能,证明CT-GAN模型改进时间嵌入设计的有效性。同时CT-GAN表现出较IRGAN好的推荐性能,充分验证CNN神经网络对于序列特征的建模能力,以及深度双向注意力机制潜在特征的捕获能力。本文基于CNN的生成器捕获用户的近期偏好,基于注意力机制的判别器通过内容信息的学习,捕获用户的长期稳定偏好,并通过对抗训练将用户的长期静态偏好和近期动态偏好相结合,使推荐结果更准确,推荐内容多样。 3.5.2 嵌入维度分析 本节保持其他最优参数设置不变,在数据集MovieLens-1M上进行嵌入维度分析,探索嵌入维度d对序列推荐算法性能的影响。首先将嵌入维度d的取值范围设置为16~256。然后在不同嵌入维度下分别进行实验,获取衡量指标NDCG@10和HR@10的取值,实验结果如图5所示。 图5 嵌入维度分析 从图中可以看出,随着嵌入维度的增加,推荐算法的性能度量指标逐渐增大。当达到某一特定值后再增加嵌入维度,度量指标逐渐收敛或略有下降,说明并非嵌入维度d的值越大,推荐算法的性能越好。嵌入维度过大可能导致数据稀疏,训练难度加大。此外,嵌入维度过大也可能会导致过拟合发生。 本文提出的CT-GAN推荐算法在各个嵌入维度都取得较基线方法优秀的推荐结果,充分验证了本文提出算法的推荐性能。因为当嵌入维度达到64时,继续增加维度,推荐算法的度量指标基本不发生变化或略有下降,所以在本文的其他实验中将嵌入维度设置为64。 3.5.3 多判别器建模结果的可视化分析 先前的实验已经证实本文提出的CT-GAN推荐算法具有优秀的推荐性能。此外,CT-GAN推荐算法采用多判别器模型分别建模不同的影响因素,并为生成器提供反馈信号,使得推荐结果具有较好的可解释性。本节将在数据集MovieLens-1M上进行CT-GAN多判别器建模的可视化分析。图6为CT-GAN推荐算法为样本用户生成的Top-5推荐结果,其中{1,2,3,4,5}分别代表相应位置的推荐项目,图中提供各个推荐位置每个判别器根据特定因素生成的奖励信号值,取值范围为(0,1),其中判别器1为时间判别器,判别器2为项目类型判别器,判别器3为流行度判别器,直方图的高度为每个判别器提供的奖励信号,由直方图可以看出项目1和项目2获得较高的类型奖励信号,推荐项目与用户的交互历史具有较相似的类别特征。根据类别推荐,项目3获得较高的时间奖励信号,认为项目3符合用户交互序列的时间和序列特征。项目4和项目5获得较高的流行度奖励信号,项目推荐受到商品流行趋势的影响。现有的推荐算法将各种上下文信息集成到统一的表示中,无法具体建模每个个体因素对推荐结果的影响,CT-GAN通过多判别器分别建模不同的影响因素,使推荐结果具有一定的可解释性。 图6 多判别器建模结果的可视化分析 本文充分考虑影响用户下次交互项目预测的时间、内容、序列信息,提出一种基于生成对抗模型的混合推荐算法,同时建模用户的长期稳定偏好和近期动态偏好,为用户提供个性化的推荐。该算法充分挖掘用户的潜在喜好,使推荐的结果呈现多样性,提升推荐系统的用户体验。用户交互的时间戳信息包含丰富的上下文信息,有利于提升推荐系统的性能。在未来工作中,将考虑建模用户交互更细致的时间信息,例如,用户停留时间,采用更简单的网络结构获取同样的推荐性能。




2.3 判别器



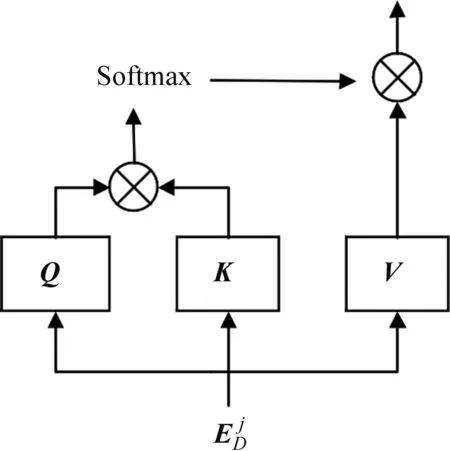


2.4 算法的训练和优化

2.5 算法描述


3 实验
3.1 数据集的构造

3.2 实验设置
3.3 对比方法
3.4 算法整体性能分析

3.5 算法的细节分析



4 结束语
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年17期)2018-09-28
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2018年1期)2018-04-04
