
深度学习在论辩挖掘任务中的应用
2022-09-05 09:00石岳峰
中文信息学报 2022年7期
石岳峰,王 熠,张 岳
(1. 新华通讯社,北京 100803;2. 媒体融合生产技术与系统国家重点实验室,北京 100803;3. 西湖大学 工学院,浙江 杭州 310024;4. 西湖高等研究院 前沿技术研究所,浙江 杭州 310024)
0 引言
论辩挖掘[1](argument mining)是文本挖掘任务的一个分支,旨在运用自然语言处理与机器学习技术来自动挖掘非结构化文本中包含的论辩性质文本及论辩结构信息。如图1所示,给定一段文本,抽取其中论辩性质的文本片段(AC1等)并判断其论辩类型(CLAIM等)以及文本片段间的论辩关系(SUPPORT等)。

图1 论辩挖掘示例
在实际应用中,不同领域的文本中蕴含了大量论辩性质信息,其中的主要观点、依据及隐含的论辩逻辑过程信息对验证结论有着重要的作用,如在法律文书中对记录的已认定的事实与法律条款结合进行逻辑论证的过程,可以作为审判结果的重要依据;在科学论文中,对已有定理和实验数据结合进行相关逻辑的论证,可以推导出新的结论。与情感分析[2](Sentiment Analysis)等只挖掘文本表达观点的任务不同,论辩挖掘任务通过对论辩信息进行挖掘和分析进而理解所持观点背后的原因,具有重要的研究价值。
对论辩挖掘任务的研究始于2007年,Moens等人[1]研究在法律文本中抽取论辩性质的句子。随着自然语言处理技术的进步,研究者对于该方向的研究逐步深入,明确了文本中论辩成分的类型及挖掘论辩结构信息的需求,完善了论辩挖掘的研究对象和范围[3]。随着领域的成熟化,自2014年起,计算语言协会每年会举办论辩挖掘专题研讨会(ArgMining Workshop, ACL 2014[4]),至今已经举办了八届(ArgMining Workshop, EMNLP 2021[5]),以及从2006年开始举办国际论辩计算模型会议(COMMA[6])。除此之外,在计算语言学和人工智能的国际顶级学术会议中,与论辩挖掘任务相关的文章数量也是逐年增加,均证明了该任务受到了学术界越来越多的关注。
近年来,基于神经网络的深度学习技术已经逐步代替传统的机器学习模型,被广泛应用在自然语言处理领域中[7-9],并在各项任务中取得了令人瞩目的进步。在论辩挖掘领域,深度学习模型同样被广泛地应用。首先,深度学习模型具有强大的编码能力和表征能力,不但在各项任务中取得了更好的结果,而且具有了学习更复杂任务的能力。其次,当前网络中日益增加的产品评论、在线论坛等论辩文本为进行大规模的深度学习模型训练提供了数据基础。由此可见,基于深度学习的论辩挖掘模型已成为未来研究的趋势和重点。
本文系统性地介绍基于深度学习的论辩挖掘相关工作。我们首先介绍论辩挖掘相关的基本概念及主要数据集,再根据任务的不同介绍基于深度学习的论辩挖掘模型,最后总结及讨论现有论辩挖掘领域的优缺点,并分析未来发展的趋势。与已有论辩挖掘综述[3,10-13]相比,本文主要针对基于神经网络的深度学习模型进行了详细的阐述。
1 论辩挖掘的基本概念及数据集
1.1 论辩挖掘构架及概念
Habernal和Gurevych[14]将论辩挖掘任务定义为: 从语用学的角度分析语料,并应用论辩理论对语料进行建模和自动分析的一般任务。为了完成论辩挖掘任务目标,Cabrio和Villata[3]提供了一个详细的论辩挖掘流程构架(Argument Framework)总览,将论辩挖掘任务分为如下两个阶段:
论辩提取(Argument Extraction) 论辩提取的任务目标是识别文本中包含的论辩性质的句子并判断其论辩成分类型。论辩提取可以进一步地被分解为两个任务: 论辩成分挖掘(Argument Component Identification)及论辩成分分类(Argument Component Classification)。
论辩成分挖掘任务根据原始文本是否包含具有论辩性质的文本片段而对文本进行分割,分割的文本片段需要包含最小的论辩分析单元,即论辩文本单元[13](Argumentative Discource Unit, ADU)。此外,根据论辩文本单元的边界确定不同,论辩成分挖掘分为句子级和文本片段级两种不同的粒度。相对于句子级的论辩文本单元,文本片段级的论辩文本单元提供了更精确的论辩起止位置,适合标注复杂句式中存在多种论辩成分的情况。
论辩成分分类,即对论辩文本单元在论辩文本中承担的功能类型进行分类。常见的标注类型有前提(Premise)和结论(Claim)(图1),其标注了论辩文本单元在整体论辩结构中的功能信息,是论辩成分分类任务的主要研究对象。其他如依据(Evidence)、事实(Fact)、价值(Value)等[15](见图1)论辩文本单元自身固有的属性也提供了有价值的论辩信息。
论辩关系预测(Argument Relation Prediction) 论辩关系预测的目标是预测文本单元(ADUs)之间的论辩关系。该任务分为两个阶段,首先判断给定的文本单元之间是否存在论辩关系,其次对论辩关系的具体类型进行分类。一般性的论辩关系类型包含支持(Support)、反对(Attack)和中立(Neutral)。鉴于相关数据集的标注难度及任务的复杂度,目前的研究重点仍集中在一般性的论辩关系判断。然而,在实际文本中,简单的支持-反对关系难以涵盖完整的论辩信息,因此探究相同文本内不同主张间论辩关系的对话关系(Dialogical Relations)[16]及丰富论辩机构的修辞关系(Rhetorical Relations)[17](如解释、引用关系等)也受到一定关注。与此同时,识别论辩关系可以构成完整的论辩树结构(Argumentation Tree)或论辩图结构(Argumentation Graph)[18],其节点代表论辩文本单元,边代表论辩成分间包含的论辩关系,以实现对论辩文本中完整论辩结构的提取。
论辩挖掘任务流程图如图2所示,根据任务的复杂性分为两个不同的阶段,箭头的方向说明了当前任务的结果可以用于执行下一阶段的任务。同时,论辩挖掘任务的结果可用于论辩拓展任务(见1.3节)中。

图2 论辩挖掘流程图
1.2 论辩挖掘数据集
现有工作根据论辩挖掘任务的定义和流程框架,并结合不同论辩领域的文本特性、论证结构和任务目标构建了论辩挖掘任务数据集。具有论辩性质的长文本中通常包含了对给定主题的大量论辩过程,而对其中蕴含的繁杂辩证关系和论辩逻辑信息的挖掘和分析可以有效地解释复杂现象背后的原因。通常一个数据集包含了对识别论辩文本单元、论辩成分类型及论辩关系的一个或者多个任务的标注。其中,政治辩论[19-21]及在线辩论文本[22-23]是论辩挖掘任务最直观的应用领域,其包含了辩论双方对争议性话题的主张及论辩逻辑交互过程,标注数据主要集中在总统选举辩论、政治议题及人文和社会热点问题中。法律文本[24-25]中记录了案件审理过程,蕴含控辩双方丰富的论辩知识。因此,对于其中的主张及其依据的挖掘有助于挖掘最终判决的结果及原因,以此实现案件的自动审理。议论文[26-27]直观地阐述了对争议性主题表达的观点及其内在原因,因该领域数据存在相对固定的论辩逻辑结构,标注难度相对较低,所以在论辩挖掘任务中得到了广泛的应用。学术论文[17]中记录了研究者对特定科学领域研究的创新结果及对其进行推导和论证的过程。自动识别学术论文中的主张及前提也是论辩挖掘研究的主要领域。其中,与生物医疗领域[28-29]相关的数据可以获取诊断依据等重要信息。同时,学术会议的论文评审文档[30]中包含了审稿人对投稿论文是否接受的主张及其原因,也同样得到了关注。
字数较少的论辩文本中则更直观地表达了对某个特定目标的观点和前提。对于单个文本来说,相关领域的数据集主要标注了论辩的类型及对目标的立场信息;与此同时,将多个短文本进行共同标注也可以探究复杂的对话类型论辩关系。其中,对社交网络领域[31-32]文本中包含的社会热点话题的观点和讨论过程进行挖掘,可以应用于决策支持及舆情监控等方向的研究。对在线评论[15]文本中发言者的观点及潜在动机的描述进行挖掘,可以使得论辩挖掘技术在商业领域中得到广泛应用。此外,部分研究集中在多语言的论辩数据挖掘[33-34]及多数据源的论辩挖掘数据[35-36],其目标是探究论辩挖掘模型在不同领域或不同语言的数据上进行泛化和迁移的能力。数据集的详细信息见表1。

表1 论辩挖掘任务数据集
1.3 论辩挖掘拓展任务
除了论辩挖掘框架中包含的主要任务之外,与论辩相关的新任务形式逐渐受到关注。首先,论辩对识别(Argument Pair Identification)任务[37-38]的定义为,给出原始文本中一个论辩,从回复文本的论辩句中找出与其有着论辩对应关系的论辩句。其中对应关系可以看作对原始论辩文本的解释、赞同或者反驳,常用于对话型文本中。其次,对论辩数据评估的相关任务也逐步受到关注,分为两个研究方向。第一类是论辩说服性评估(Argument Persuasiveness)[39],即评价给定论辩文本对特定主题的说服性力度。通常,不同论辩成分的说服性力度通过人为设定的评估指标来对不同关键维度进行量化的评价。该任务后续被定义为给出一个争议性的主题及对该主题进行讨论的论辩语句列表,选出其中对主题更具说服性的语句。第二类论辩评估相关任务是论辩质量评估(Argument Quality)[40],即从逻辑、修辞和辩证性质等不同角度去人为地量化给定论辩的质量。
最后,对论辩的研究也会与传统的自然语言处理任务相结合。其中,论辩检索任务[41-42](Argument Retrieval)旨在从大量文档中检索与给定主题相关的论辩信息,通常应用在辩论机器人(如IBM Project Debater[43])等下游任务中。论辩检索任务可以分为检索主张和检索前提两类。检索主张任务的目标是: 对给出争议性的主题,从大量文档中检索支持[41,44]或反对[45]该主题的主张;检索前提[42]任务的目标是: 给定一个主张,从文档中检索支持该主张的前提。另一类相关任务是论辩总结(Argument Summarization)[46],即生成对给定文本论辩性质的总结。
2 论辩挖掘模型
基于深度学习的神经网络模型已经取代机器学习模型成为论辩挖掘任务的基本模型。该方法的研究整体呈现以下特点: 首先,基于循环神经网络[47](RNN)及其变体长短时记忆网络[19,48-49](LSTM)的模型有强大的编码能力[50],并可以在编码过程中保留更远距离的上下文信息[51]。因此,相关模型在论辩挖掘任务上得到了广泛的应用,并实现了多任务学习和端到端学习[52-53]。其次,在论辩文本中,论辩结构信息通常以树或者图数据的形式存在,而图神经网络(GNN)[54-56]可以对结构信息进行有效编码[57],并且论辩知识、主题等信息也可以和论辩文本以图的形式进行共同编码[58],使得论辩挖掘任务的性能表现进一步提升。最后,随着大规模预训练语言模型(如BERT[59])的出现,基于预训练-微调(Pretraining-Finetuning[60])的方法在论辩挖掘的任务中取得了超越其他模型的表现。此外,在这些模型的基础上,进一步结合注意力机制[61](Attention)可以对输入之间的联系进行隐式的编码从而增强输入的表示[27],同时对齐不同类型的数据[62]。论辩挖掘模型的结构如图3所示,模型的输入为论辩文本,也可以将知识及结构信息等与论辩文本同时作为输入;针对不同的任务,可以使用一个或者多个模型对输入进行编码,并使用不同的解码器输出结果。
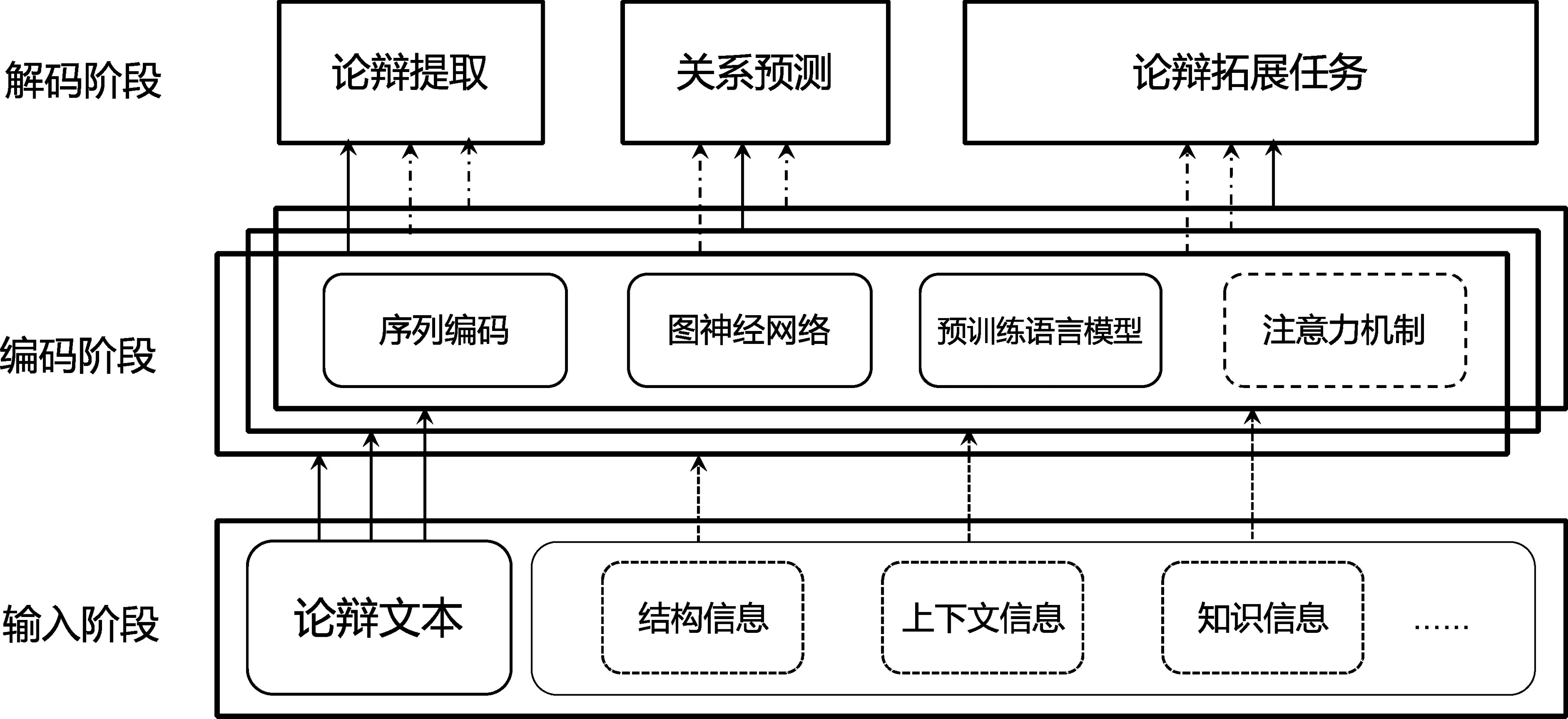
图3 论辩挖掘模型的结构
我们以任务为单位对模型进行总结,同时也考虑到模型从简单到复杂及发表时间的顺序等因素。本节论述涉及的典型模型方法如表2所示。

表2 典型论辩挖掘模型方法总结
2.1 论辩提取
论辩提取任务一共有两种粒度的标注,即句子级别的标注和文本片段级别的标注。句子级别的论辩抽取任务可以被看作是句子分类的问题,其任务设定为给出的一段文本,判断其是否为论辩句或具体的论辩类型。在这种任务设定下,常用的基线模型使用卷积神经网络(CNN)[50,63]或者长短时记忆网络(LSTM)[19,50,65]将原始文本编码并将编码后的隐向量作为整个句子的表征做句子分类任务。而文本片段级别标注的论辩抽取任务通常被视为序列标注的任务,即判断论辩文本单元在文本中的起点和终点位置。对于此类任务,其基线模型是结合条件随机场(CRF)[63-64]的LSTM模型,即使用经过LSTM编码后的原始文本的隐向量通过CRF层预测标注的论辩文本单元开始于结束为止的标签。随着预训练语言模型在论辩挖掘任务中开始应用,诸如BERT等模型[30,60,65]已逐步替代了LSTM模型来编码原始文本,并取得了更好的效果。
Song等[27]通过自注意力机制(Self-Attention)[61]将论辩文档中的句子位置信息和句子间的相互作用信息结合文档进行编码,以完成论辩抽取任务。即使文本领域不同,论辩成分在文本中通常出现在相对固定的位置上,因此编码位置信息有助于论辩抽取任务。作者通过BiLSTM模型编码句子级别的文本序列及其对应的位置信息,并运用自注意力模块隐式地编码句子间的关系。实验证明,位置信息的编码有利于模型性能的提升。
Wang等[66]根据论辩数据的结构特征对论辩抽取任务进行建模,识别长文档核心观点的论辩成分通常需要篇章级别或者文档级别的全局信息。以此为前提,Wang等提出了结合局部和全局信息的论辩挖掘模型。对于输入文本,作者使用三个不同的BERT模型分别以整篇文本、段落文本及句子文本为单位进行编码,分别训练主要主张、主张和前提的不同层级论辩抽取任务。实验结果证明,该模型对每一类论辩成分标签抽取的结果都优于基线模型。
数据增广的方法同样也被运用在论辩抽取的模型中。Mayer等[67]通过生成原始论辩数据集的对抗样本来增强语言扰动,以此来验证基于预训练语言模型的论辩抽取方法的鲁棒性。在保留句子语义的前提下,Mayer等使用了如对命名实体及同义词的替换、副词或者连词的增加等构造增广数据的方法,并使用一个经由原始数据训练的模型检验对抗样本的准确性。作者使用BERT模型对句子级别的文本序列进行编码,判断其是否为论辩句及论辩句的极性。在使用增广的对抗数据与原始训练数据混合训练后,对同主题数据的实验结果相较于只有原始数据训练的模型有了较大的提升。
2.2 关系预测
2.2.1 一般性论辩关系
一般性的论辩关系预测任务可以看作是文本蕴含(NLI)或者文本分类任务。文本蕴含[68]是借由语义关系判断输入前提是否可以推断出输入假设的任务,而论辩关系预测则借由此思想判断前提与结论之间的关系。基于文本蕴含的论辩关系预测只适用于推断简单的支持或反对关系。与之相比,基于文本分类的论辩关系识别由于支持识别多种关系,因而得到更多的应用。其任务设定为,给出一对论辩文本单元(包含一个前提和一个结论),判断两者之间是否包含论辩关系或判断具体的论辩关系类型。对于基于深度学习的论辩关系预测任务来说,常用的基线模型运用LSTM[49,51]编码拼接后的一对论辩文本单元,并运用编码后得到的隐向量来判断两者之间的论辩关系。近期主要用基于BERT[49]等预训练语言模型编码拼接的论辩单元,并使用[CLS]标签对论辩关系进行预测。
Opitz[69]通过对论辩数据集的重构,根据其论辩关系标签的不同,人为对给定的论辩文本对添加对应的连接词,构建具备上下文语境的一句话,以此将论辩关系预测任务转化为文本合理性排序的任务。该任务定义为,给定重构的文本序列,判断重构文本的合理性。如果判断为合理,则证实该重构文本包含的论辩文本对具有对应的论辩关系。Opitz使用BERT作为文本的词向量,并经过BiLSTM+Attention模型对重构文本序列进行编码。实验证实了该方法的有效性,且对反对标签的预测结果有显著的性能提高。
论辩文本中包含了实体、事件和关系,而将与以上信息相关的外部知识融入模型中可以更准确地识别论辩关系。基于以上前提,对于给定的一对论辩单元文本,Paul等[62]分别从常识知识库和词汇知识库中抽取在论辩成分中出现的概念词相关的知识图谱,使用不同的BiLSTM+Attention模型对论辩文本单元对和知识进行编码,并通过Cross Attention[70]机制增强文本和知识的表示。实验证实了知识增强方法的有效性,且知识的选择和构筑方式对结果有比较大的影响。
2.2.2 复杂论辩关系
修辞关系Lauscher等[17]使用了基于多任务训练的模型,将论辩结构信息融入修辞关系挖掘的任务中。在一个已标注修辞关系的科学类文本数据集上,作者进一步标注其论辩成分和论辩类型,并对标注后的数据进行论辩识别和修辞关系识别的多任务训练。作者使用不同层级的BiLSTM模型分别对序列标注级别的任务和句子级别的修辞结构任务进行训练。实验证明,论辩信息的加入使得修辞关系预测任务有了较明显的性能提升。
对话关系Chakrabarty等[71]挖掘了在线评论领域文本轮次内(intra-turn)和轮次间(inter-turn)的对话类型论辩关系。轮次内论辩关系标注了同一论辩结构中不同前提对同一观点的论辩关系;而轮次间论辩关系标注了不同论辩观点之间的关系。对于给定的论辩文本对序列,作者使用经由不同大规模无标注辩论数据预训练后的BERT模型分别预测轮次内和轮次间的论辩关系;同时,因为文本间修辞关系与其论辩关系有强大相关性,作者使用修辞结构树[72](Rhetorical Structure Tree, RST)的根节点特征训练一个判别模型来判断输入文本间的论辩关系。最后,作者将基于BERT模型与基于RST模型的结果输入到一个集成模型中来判断最终的论辩关系结果。
2.3 联合训练模型
联合训练模型通过使用一个编码器同时训练论辩抽取和论辩关系预测任务,借此得以端到端地完成论辩挖掘任务。这种多任务设定的论辩挖掘任务目标是解析树状[图4 (a)]或者图状[图4(b)]的论辩结构。我们分别从解析论辩树结构及论辩图结构两个方面对相关模型进行介绍。

图4 论辩树结构及论辩图结构(基于图1文本)
论辩树结构针对给定的论辩文本序列,Eger等[52]尝试将论辩结构抽取任务转化为基于多任务的字符级别序列标注任务或者依存句法解析任务,进而识别输入文本序列的论辩文本单元边界,并判断论辩文本单元之间的连接关系。首先,对于序列标注任务,Eger等为每个论辩文本字符标注了四种不同类型的论辩标签,并使用了LSTM+CRF模型共同训练论辩成分分类和论辩关系预测任务。对于依存句法解析任务,Eger等将输入文本编码为一个有向树,每个字符包含了与其相连论辩成分的首字符信息,其对应的边包含了论辩起止位置,论辩类型和论辩关系信息。作者使用了LSTM-ER[73],一个端到端的识别实体类型及实体间关系的分类模型对论辩结构进行抽取。
Potash等[74]应用了基于注意力的指针网络[75](Pointer Network),端到端地来解决论辩结构抽取问题。指针网络不但可以将论辩文本序列编码,并且在解码过程中可以限定一个单向的输出序列链,使得输出的格式得以约束为树状。与Eger等将原始文本序列作为模型输入不同,Potash等将论辩文本单元作为输入,同时训练论辩成分分类和论辩关系抽取两个任务。Potash等通过LSTM模型对论辩文本单元进行序列编码,在解码阶段,其使用多层感知器判断论辩成分类型;同时运用指针网络模型输出当前论辩成分对每个论辩成分的分布,如果当前论辩成分指向其他论辩成分,则视为二者之间存在论辩关系。实验结果证明联合训练的模型对该任务有着较大的性能提升。
Kuribayashi等[76]尝试对论辩文本片段的表示进行建模,并将语言学特征融入论辩结构抽取模型中。作者对每个论辩文本单元手动构建了语言学特征,将其分为论辩成分(主张和结论)和论辩标记(论辩文本中常用的连词表达),并使用不同的LSTM-minus[77],一个基于LSTM的片段编码模型,对论辩成分和论辩标记进行编码。在解码阶段,Kuribayashi等运用不同的线性分类层预测论辩成分类型和论辩关系类型,并通过自注意力模型预测论辩关系。实验结果证明了该语言学特征对论辩关系挖掘任务有着巨大的性能提升。
论辩图结构[18,78]Morio等[53]使用基于双仿射注意力机制[79](Biaffine Attention)的神经网络,对论辩成分分类和论辩关系抽取问题进行联合训练,构建论辩图结构。双仿射注意力常用于依存解析任务中,通过对经由LSTM编码后的隐层进行仿射变换,进而预测节点等依存关系和依存节点的关系类型。Morio等使用LSTM+Attention模型对论辩成分单元进行编码,并通过两个仿射注意力层分别预测任意两个论辩成分间是否存在论辩关系,并预测其论辩关系的类型,以此构筑论辩文本对应的论辩图。在此工作的基础上,Ye和Teufel[80]将输入的层级从论辩文本单元转化为论辩文本序列,同时按照依存分析任务的数据形式对论辩文本字符重新标注,并使用BERT对论辩文本进行编码。实验结果证明,相较于基于论辩树结构抽取的方法,该模型在论辩成分分类和论辩关系任务上取得了更好的结果。
Bao等[81]使用一个基于转移[82](Transition-based)的方法,该模型通过有穷状态传输器[83](Finite-State Transducer)构建输出,根据当前论辩成分的状态信息以及历史的论辩图构筑信息,迭代式地生成下一步的转换动作,通过一系列动作来增量地构建论辩图结构。这种基于转移的方法有效避免了低效率的潜在论辩对枚举次数,并且可以避免数据标签不平衡的问题。Bao等使用BERT编码论辩文本单元,并使用线性分类器对论辩成分进行分类。对于论辩关系抽取任务,作者应用四个列表存储了论辩成分的不同状态及六种处理列表的转换动作类型,并使用四个不同的LSTM模型对四个列表进行编码,预测下一个转换动作的类型。该方法在两个不同领域的数据集中取得了最好的结果。
2.4 实验结果
这一节我们对以上方法中出现较多的两个数据集(由Stab和Gurevych[26]标注的论辩文本数据及Park和Cardie[15]标注的在线评论数据)的实验结果进行了统计,并对相关的实验结果进行分析。具体的任务设定及实验结果如表3所示。首先,对于论辩成分挖掘任务,由于输入形式的复杂度不同,以论辩文本单元作为输入的模型[74]表现要远优于以原文中的句子作为输入的模型[52];同时,在相同输入的形式下(句子形式),由于序列标注任务的复杂度较高,因此基于序列标注的论辩成分挖掘模型[66]表现低于基于句子分类的论辩成分挖掘模型[27]。其次,在相同的设定下,基于联合训练的模型在论辩关系预测任务中的表现[76]要优于单独训练论辩关系预测任务的模型[62]。最后,因为对文本序列强大的建模和表征能力,在相同的任务设定下,基于BERT的模型[80-81]在不同任务中都取得了更好的结果。

表3 常见的论辩挖掘数据集性能总结(F1)
2.5 论辩拓展任务
论辩对识别论辩对识别的任务设定分为两类,其中一类设定是多项选择任务,即给出原始文本中的一个论辩文本单元,选择在回复文本中与给定论辩文本单元有交互关系的待选文本。Ji等[37]运用离散变分自编码器[84]将论辩对文本的原文序列和回复序列进行了重构,通过离散隐变量的后验分布得到论辩文本对的表示,并使用CNN+GRU[85]模型将论辩的上下文信息融入模型中。Yuan等[56]依据论辩文本数据集的主题信息,利用基于该数据集的论辩知识增强对论辩对的识别。论辩对文本及知识分别经过BERT及GCN[55]+Transformers[61]模型进行编码,并应用基于注意力机制的信息对齐网络对齐文本和知识的表示,以预测论辩对的匹配分数。
另一类论辩对识别设定是信息抽取类型的任务,即对于给出原始文本和回复文本,自动挖掘出其中包含的所有论辩对。在实际应用中,该类任务通常是一个多任务设定,即同时训练论辩抽取和论辩对挖掘的任务。Cheng等[38]使用了基于序列标注的文本分类的方法,应用BERT+BiLSTM模型编码输入文本,并经过一个CRF层判断句子的论辩类型;而后,作者将所有被判断为是论辩成分的句子组合成原文-回复论辩对,以判断其是否由一个论辩对组合。Cheng等[86]提出了一个基于注意力机制的多层交叉编码的方法对原文和回复序列之间的内在联系进行建模。同时,作者构建了一个针对两个输入文本的表状特征表示层显式地将文本配对信息融入模型之中。文本序列特征被用来预测论辩成分,而表状特征被用于预测论辩对匹配的任务。
论辩说服性Habernal和Gurevych[39]使用不同的LSTM编码器将论辩文本和主题进行编码后获取各自的隐向量,使用一个多层感知器将隐向量进行编码并给出论辩文本的说服性分数。Ji等[87]应用基于互注意力机制的模型来显式地编码论辩原文和论辩回复文本之间的论辩交互关系,并且应用了一个过滤门机制选择性地增强论辩文本。Huang等[88]尝试将论辩结构信息编码到模型中以优化论辩说服性任务。首先,Huang等应用基于依存句法分析的方法抽取论辩结构树;而后,作者应用异质图注意力模型[89]对论辩文本单元及其论辩结构同时进行编码,并使用编码后的主题节点和论辩文本节点信息对说服性进行预测。Zhao等[90]使用不同的基于BERT的编码器分别对主题特征和辩论者信息进行编码,并使用了一个基于相似度的神经网络模型编码论辩文本和主题文本信息,以此对论辩文本说服性进行预测。
3 总结与展望
综上所述,基于深度学习的模型已经广泛地运用在论辩挖掘及其相关任务中,取得了比基于机器学习模型更好的结果,其共性有以下几点: 首先,由于序列建模的编码方法(如BiLSTM)和基于预训练语言模型的方法在该任务中得到了广泛的应用,且基于预训练语言模型的方法在所有的任务上取得了最好的结果[60,80,90],并已成为论辩挖掘任务新的基准模型。其次,论辩文本的结构信息被大量运用在各类论辩挖掘任务中,其中论辩文本自身的属性,如连接词信息、上下文信息及文本位置等都被显式地编码至模型中,使得模型获得了文本结构的全局信息;同时,注意力机制的应用使模型得以编码文本间或者文本与其他属性间的关系,间接使得模型编码了结构信息。最后,论辩拓展任务中大量地应用了论辩成分信息,在模型中直接添加论辩结构信息与论辩知识[88],并使用联合训练模型共同训练论辩拓展任务及基础的论辩挖掘任务[86],使得效果有了较大的提升。
然而,现阶段的论辩挖掘任务仍然存在许多问题。首先,因为论辩本身的复杂性及部分领域的专业性,使得论辩挖掘任务的数据标注难度较大,只有少数领域有较大规模的高质量数据集,且不同领域之间对各自论辩信息的定义标准差别很大[35-36],无法直接利用不同的数据集进行联合训练或迁移训练。其次,尽管深度学习模型已得到广泛地应用,但因为大量的论辩信息是隐性地存在于论辩文本中,因此模型表现与人类表现差距仍然很大,尤其表现在对复杂论辩关系预测的任务中。最后,现阶段的论辩关系抽取任务主要集中于前提-主张的简单二元关系,导致现阶段的论辩挖掘任务无法充分挖掘观点背后复杂的原因及逻辑结构。
以下后续的研究方向值得关注。首先,研究者需要结合语言学理论对论辩挖掘任务的框架做进一步地细化及拓展,使得在此框架下的论辩挖掘任务设定可以应用于多领域、多类型的标注,扩大高质量数据集的规模。从算法的角度考虑,目前论辩挖掘任务是一个较新的研究领域,所以借鉴自然语言处理任务前沿的算法(如Prompt-Learning[91]等),并根据任务的形式构建适当模型是一个可行的研究方向;与此同时,基于预训练语言模型的方法是论辩挖掘任务未来的趋势,借用其强大的表征能力并结合多样的外部信息将是论辩挖掘任务的重要研究方向;最后,针对复杂论辩结构的探索,诸如探究论辩文本单元在不同论辩结构中的论辩成分的转化,复杂论辩结构抽取及长文档的整体论辩结构抽取等也是未来可以探究的方向。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
云南教育·小学教师(2022年4期)2022-05-17
小学生学习指导(中年级)(2021年12期)2021-12-30
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
汉字汉语研究(2020年2期)2020-08-13
艺术评论(2020年3期)2020-02-06
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年18期)2018-11-14
汽车导报(2017年5期)2017-08-03
