
基于联合学习的成分句法与AMR语义分析方法
2022-09-05 09:00黄子怡李军辉贡正仙
中文信息学报 2022年7期
黄子怡,李军辉,贡正仙
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 概论
抽象语义表示(Abstract Meaning Represent-ation,AMR)是一种新兴的语义解析表示形式,旨在抽象出句子中的语义特性,利用图结构呈现树结构无法表示的句子结构信息。AMR标注将句子语义结构表示为一个单根的有向无环图,并为句子中的实体、事件、属性和状态引入变量,作为图中的概念节点(Concept);两节点之间的边表示对应的语义关系[1-2]。AMR解析已经被广泛应用于机器翻译、问答系统、文本摘要[3-5]等下游自然语言处理领域任务中。句法分析(Syntactic Parsing)是自然语言处理中的一个基础任务,同时也是许多自然语言处理和自然语言理解(NLU)任务的基础。目前常见的句法分析可以分为成分(短语结构)句法分析(Constituency Parsing)和依存句法分析(Dependency Parsing),前者侧重于探索句子中短语及短语之间的层次逻辑结构,后者侧重于句子中各个单词之间的依存关系。由于句子的句法结构与AMR概念的修饰与被修饰关系是兼容的,并且句子中谓词与论元的修辞关系与AMR图中概念之间的语义关系对应。那么AMR与句法分析任务能否为彼此提供帮助?本文将尝试在各个场景下回答该问题,其中包括无外部标注资源、存在BERT和未标注资源等场景。
考虑到AMR解析的任务通常较句法分析更困难,目前的相关研究皆在于如何利用句法分析来提高AMR解析的性能。例如,Ge等人[6]探索了利用成分句法分析来辅助AMR解析。他们的实验表明了句法可以为AMR解析任务提供帮助。但该方法依赖于句法分析的质量,存在着错误传播的潜在问题,即如果句法树中存在错误,那么这些错误将负面影响AMR解析的性能。Xu等人[7]通过对成分句法分析、AMR解析和机器翻译三个任务进行联合学习,来提高AMR解析的性能。此外,以上研究均基于单一场景探索句法分析在AMR解析中的应用。
为了更好地探索AMR解析与句法分析任务之间的关系,本文提出了基于联合学习的成分句法与AMR语义分析方法。具体地,本文使用序列到序列(Seq2Seq)模型同时对成分句法分析(以下简称为句法分析)和AMR解析任务进行建模,回避句法树和AMR图在结构上的差异,简化训练的难度,提高模型在任务间的迁移性。为了减少数据稀疏带来的模型对数据的依赖问题,我们还利用训练好的句法和AMR解析器对大规模无标注数据进行解析,得到自动标注语料,并使用这些语料对模型进行预训练。此外,本文探索了预训练模型BERT在联合学习任务中的应用。实验结果表明,对AMR与句法分析任务进行联合学习,可以同时提高两个任务的性能。相比于单任务提升了8.73和6.36个F1值,并超越目前使用Seq2Seq模型的最好性能。目前使用Seq2Seq模型进行句法分析的最好性能为91.36[8]F1值,我们提出的方法F1值可以达到95.10。AMR解析使用相同的语料在Seq2Seq模型上最好性能是F1值可以达到80.20[7],使用同样的语料我们的方法可以达到80.35的F1值。
为了方便进行论文复现,我们将模型源码发布在https://github.com/Victoriaheiheihei/syn-sem-multi_task_learning.git.
1 相关工作
1.1 成分句法解析
成分句法分析的方法主要包括以下几种:基于转移的方法(Transition-based)[9]、基于图(Graph-based)[10]的方法和序列到序列的方法(Seq2Seq-based)[11]。
基于转移的成分句法分析,将整个句法树的构建视为对序列解析动作(action)的预测。自左向右地对句子单词进行扫描,每一步根据预测的动作或将单词逐个压入栈中或生成一个新的句法结构。Watanabe等人[12]首先利用神经网络来实现基于转移的成分句法分析,他们通过RNN来生成动作序列。随后,Dyer等人[13]利用Stack-LSTMs自顶向上预测解析动作来完成树的构建。另外一种常用的分析方法是基于图的方法。基于图的方法通过对句子中所有可能的句法成分进行打分,通过分值的高低来判断该句法成分是否为句法树中的一个节点。虽然基于图的方法可以并行预测所有的句法成分,但是为了确保预测得到的结果满足树的性质还需要使用复杂的CKY(Cocke-Kasami-Younger)算法进行结构化解码。Stern等人[10]最早提出可以对不同位置的BiLSTMs输出进行相减,将输出作为句法成分的表示,并在此基础上对句法成分进行打分。在后续的工作中Kitaev等人[14]将其中的BiLSTMs表示替换为内容和位置信息相分离的Transformer,Zhang等人[15]利用双仿射注意力(Biaffine Attention)机制代替相减特征,并利用GPU批量化运算加速结构化解码操作。
近年来随着深度学习的快速发展,特别是注意力机制和Transformer架构的提出,让序列到序列模型的性能得到不断的提升。在此背景下,Vinyals等人[11]首先尝试将句法解析任务建模为序列到序列任务并利用LSTM加注意力的模型进行训练。为了降低预测难度,在对句法树进行序列化时,他们只保留括号、句法标签以及词性标签,同时将句法标签与其相对应的括号进行合并。在后续的工作中[8,16],研究者引入Transformer模型结构,使得无结构约束的成分句法分析性能接近于目前最好的基于转移和基于图等有结构约束的句法分析模型。
1.2 AMR解析
目前针对AMR数据进行语义解析的方法大致可以分为以下几类:基于转移的方法(Transition-based Parsing)[17]、基于图的方法(Graph-based Parsing)[18]和序列到序列的方法(Seq2Seq-based Parsing)[6]。
早期AMR解析借鉴依存句法分析任务的既得经验,使用处理句法树的方法进行AMR解析,从缓冲区中读取单词并逐步将它们组合成堆栈中的语法结构的一系列决策。Wang等人[19]设计了一系列具有语言直觉性的动作,借助句子依赖结构与AMR之间映射的规律,将Text2AMR任务转变为Text2Dependency、Dependency2AMR两个过程。Ballesteros等人[20]引入了Stack-LSTMs,使用栈从左至右处理句子并递增地生成对应的AMR图,后来又有学者[21]提出用Stack-Transformer代替了上述模型中的Stack-LSTMs。在基于图的方法中,JAMR[22]先预测AMR图中的概念节点,然后利用最大生成树的思想来获取这些概念节点所构成的最优AMR图。最新基于图的方法均采用图神经网络,例如,Cai等人[23]利用两个编码器(序列编码器、图编码器)在维持AMR的图结构基础上进行概念识别和关系预测递增地生成图中的每个节点和关系。Zhang等人[24]先是利用序列到序列模型预测目标端概念序列,然后再基于这些概念序列构建AMR图。最后一种方法是基于序列到序列[6]的AMR解析,相较于上述方法,基于序列到序列的模型以端到端的方式构建AMR图,可以利用较少的特性让模型学习到任务信息。Barzdins等人[25]首次利用序列到序列模型进行AMR解析任务。在预处理过程中,通过复制AMR中共用的概念节点、删除wiki链接和变量,将原本复杂的AMR图简化为AMR树,然后通过先序遍历将AMR树转化为序列。然而,受到数据稀疏问题的影响,序列到序列模型的结果远不及同一时期最好的模型。为了解决这一问题,Peng等人[26]提出一种对标签的分类方法来克服目标端词汇稀疏的问题,并且在模型中引入有监督的注意力机制,进一步提升AMR解析的性能;van Noord等人[27]、Konstas等人[28]和Xu等人[7]则尝试利用额外的大规模无标注数据。近年来随着Transformer模型的提出和改进,Ge等人[6]和Xu等人[7]将Transformer模型应用于AMR解析,同时通过子词化将低频词切分为更小的粒度,以减少低频词对模型的影响。
1.3 联合学习
联合学习也称为多任务学习,旨在使用单个模型建模多种任务,通过参数共享来捕获任务之间存在的隐藏关联信息,从而提高模型在这些任务上的性能。
句法任务与语义任务存在很强的互补性,近年来越来越多的工作开始关注于如何利用句法信息来提升语义解析的性能[6,29]。但这些工作往往需要引入复杂的模型结构。相比之下,如果让语义解析与句法分析任务联合学习,会使模型变得更加简单,同时也理应为模型带来显著的性能提升。然而正如Zhou等人[30]所指出目前关于句法和语义分析的联合学习的研究很少,大部分只关注依赖结构,且在这些利用联合学习进行语义和句法学习的研究[31]中,并没有探讨联合学习是否同时对语义和句法任务的性能都有提升。Xu等人[7]借助于Seq2Seq模型的优势,即输入和输出之间无须建立一一对应的关系,首次对句法分析、AMR解析和机器翻译三个任务进行联合学习,实验结果表明简单地通过联合学习可以借助句法信息来提升AMR解析的性能。本文是对Xu等人[7]工作的深化,探索多种场景下AMR与句法分析任务之间的关系。
2 基于Transformer的AMR解析和句法分析
本文使用目前综合性能最佳的Seq2Seq模型Transformer[16]作为AMR解析和句法分析的基准模型。Transformer是第一个完全依赖self-attention机制来计算输入和输出表示而不使用序列对齐的RNN或CNN的模型,且对于RNN和CNN中比较明显的短板,如无法实现并行计算、计算冗余而低效、进行顺序计算时信息会丢失导致RNN缺乏长距离依赖等问题,在Transformer模型中都可以得到较好的解决。Transformer本质上是一个由编码器和解码器组成的端到端结构,可以实现原始数据到目标任务结果的直接输出。编码器包含自注意力层(Self-Attention Layer)和全连接前馈神经网络(Position-wise Feed-Forward Networks, FFN),自注意力层和全连接前馈神经网络之间使用残差连接(Residual Connection)及层级正则化(Layer Normalization)进行数据处理。解码器包含自注意力层(Self-Attention Layer)、上下文注意力层(Context-Attention Layer)和全连接前馈神经网络(Position-wise Feed-Forward Networks, FFN)层。有关Attention机制及Transformer的更多细节,可以参阅文献[16]。
2.1 数据预处理
由于AMR图中包含大量的用于指示共同引用节点的变量,这些变量本身并不影响AMR的语义,除此之外还包含用于补充专有名词等特定名词信息的wiki链接。本文使用Zhu等人[32]和Barzdins等人[25]实验中基准系统所使用的预处理方法,将AMR图中多余的变量、wiki链接、空格及标点等删除,在不改变句子语义的情况下获得线性化的AMR图。图1给出了源端句子、源端句子对应的标准AMR图以及经过线性处理后的线性化AMR。

图1 AMR预处理
对于句法树的处理方法,本文参考文献[11]实验中的数据处理方法,将一棵句法树自顶向下地采用先序遍历的方式访问,获得该树对应的线性化表示,并且为了加强机器对于句法的学习能力,删除了句子中的词语,仅保留词语对应的词性和句子的句法成分。在早期的实验中我们发现,如果句法分析中存在大量括号,会影响模型对句子信息的学习,为了使模型更好地捕捉到句子的结构信息,我们为括号添加了标注,将标注后的整体作为一个符号输入模型进行计算。图2给出了源端句子、其对应的线性化句法树以及经过后处理的线性化句法树。

图2 句法树预处理
2.2 后处理
模型生成的AMR序列是一个不包含共用节点、wiki变量、包含冗余和重复信息的线性化AMR树,需要通过一系列的后处理来恢复AMR图。后处理包括恢复共用节点和wiki变量,修复模型生成的不完整的概念等。为方便起见,本文使用Van Noord等人[27]实验中使用的AMR解析预处理和后处理脚本(1)https://github.com/RikVN/AMR。
类似地,模型生成的句法树只包含句法标签和词性标签。为了还原为句法树,我们自定义后处理脚本,将模型生成的线性化句法树还原为标准句法树结构。
2.3 子词化
AMR解析和句法分析都存在训练语料不足的问题。在有限的数据集下,低频词在训练中对模型性能的影响就会扩大。为了解决由于数据量不足带来的数据稀疏问题,在基线实验和不使用BERT预训练模型的实验中,采用字节对编码(Byte Pair Encoding,BPE),将低频词切分为粒度更小、出现频率更高的子词,使神经网络对数据进行更好的学习,捕捉到深层的隐藏信息。而在涉及BERT的实验中,根据使用的BERT模型不同,其tokenizer的实现可能有WordPiece和Byte Pair Encoding。作者应当在此处详细注明具体的tokenizer类型。
3 基于联合学习的成分句法与AMR语义分析方法
不同任务可以通过训练捕捉到不同的语言特征,将多种任务同时训练可以强化模型对语言中隐藏信息的捕获能力。正如上文所述,以AMR为表达形式的语义解析和以句法树为表达形式的成分句法解析的标签在侧重点上各有不同,如AMR拥有语义角色,而句法树拥有AMR中没有体现的介词、助词、时态等信息,此外它们对于相同词性的词的处理方式也不同,从句法树中可以学习到句子中哪一个词是名词,而在AMR中可以学习到哪些词是地点,而地点多以名词的形式出现,反过来又有助于句法分析。本文提出一种可行的基于联合学习的句法分析和AMR解析方法。
3.1 AMR解析与句法分析联合学习
目前多任务学习方法大致可以总结为两类,一是不同任务之间共享相同的参数(Common Parameter),二是挖掘不同任务之间隐藏的共有数据特征(Latent Feature),前者被称为Hard参数共享,后者被称为Soft参数共享。为了在最大程度上发挥联合学习的优势,我们选择对这两个不同的任务共享全部的模型参数,即Hard参数共享模式。也就是说,在进行联合训练时,AMR任务和句法任务都是使用相同的一个编码器和相同的一个解码器。在进行联合学习时使用相同的编码器是十分常见的[33-35],这样可以使编码器获得更多不同任务的训练数据,以提升其对输入文本的编码能力。但值得注意的是,我们同样也在这两个不同的任务中共享了模型的解码器部分。在联合学习中共享解码器,首先是考虑到经过数据预处理后的线性化AMR图与句法树有着很高的相似性,可以通过相同的解码器进行解码,因此共享解码器不但可以减少模型中的参数数量,还能让解码器得到更加充分的训练;其次,我们希望通过共享解码器的参数来让两个任务彼此间变得更加紧密,更能够互相帮助。但是这样的模型容易造成两个任务的标签混淆,模型无法学习到任务的私有特征。为了使两个任务区分开,两个任务的语料在目标端数据预处理上使用了不同的起始符。如图3所示,在对AMR任务进行解码时解码器的起始标签为“

算法 1 联合学习算法输入: AMR图的训练集G,句法树的训练集T,训练迭代步数N输出: AMR和成分句法联合模型参数Θ随机初始化模型参数: Θfor n in 1,2,3,…,N do //n为当前训练步数 //训练AMR解析任务 从G中随机抽取一批数据: (sg,g) 预测: g'=Θ(sg) 计算目标函数: Lg=L(g,g') 计算梯度: Δ(Θ,Lg) 更新模型: Θ=Θ-ΔΘ //训练句法分析任务 从T中随机抽取一批数据: (st,t) 预测: t'=Θ(st) 计算目标函数: Lt=L(t,t') 计算梯度: Δ(Θ,Lt) 更新模型: Θ=Θ-ΔΘend
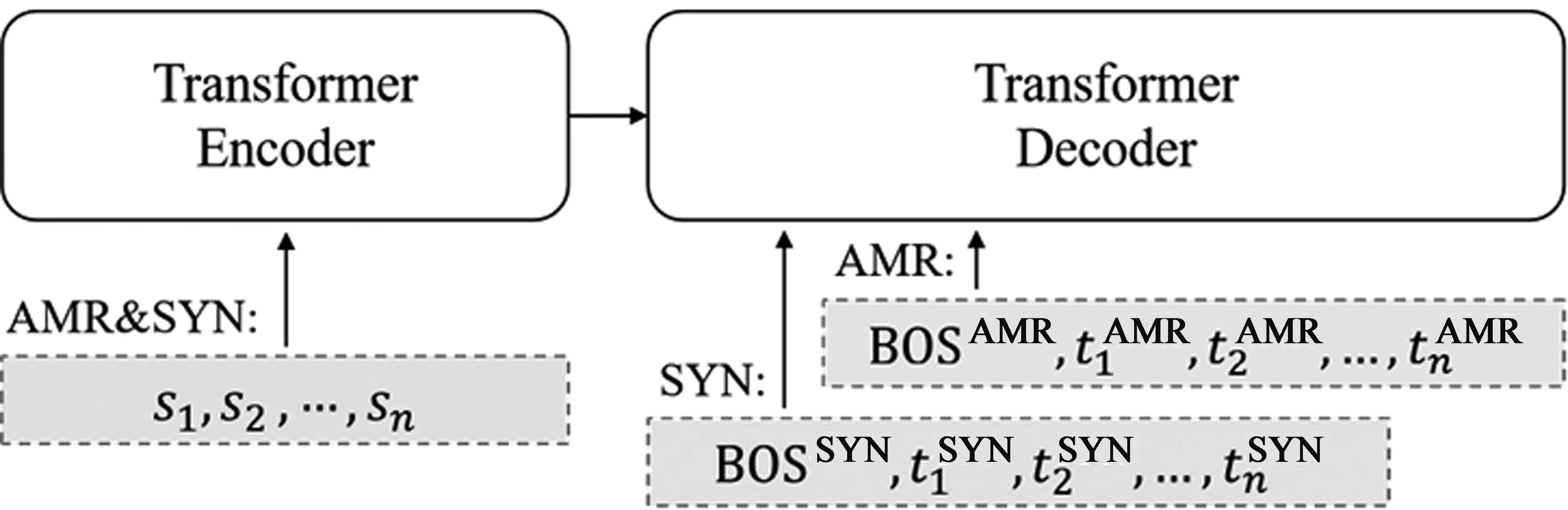
图3 模型示意图其中SNY指句法分析任务
3.2 预训练模型
预训练模型是在深度学习架构上用大量数据在特定任务上进行训练的语言模型。本文以BERT为例,探索在使用强而有效的BERT预训练模型场景下,AMR解析和句法分析的联合学习是否有效。Xu等人[7]分析并比较了四种BERT应用于AMR解析的方法,包括用BERT替代Transformer中的编码器、将BERT作为特征提取器、将BERT作为额外的编码器以及用BERT代替Transformer中的词嵌入。在前期实验中发现,使用BERT 代替词嵌入的方法在AMR解析和句法分析任务上的效果最好,因此本文实验中使用该方法,简称为 BERT embedding。同时,受Tenney等人[36]启发,本文将BERT的各层输出加权求和后得到的上下文相关表示作为后续编码器的输入,该方法称为ScalarMix,计算如式(1)所示。
(1)
其中H=[H1,H2,…,HK]是BERT最后K层的输出,ω∈K是可学习的K维向量,γ∈用来确定最终输出的方差。可学习标量则用来调整最终输出向量的方差。
3.3 自动标注外部语料
Xie等人[37]的工作表明: 当缺少标注数据时,半监督学习可以有效地改善深度学习模型的性能。为了克服AMR解析和句法分析对标注数据集规模的依赖,本实验中利用大规模未标注数据,通过在小规模数据上已经训练好的解析器,获得大规模自动标注数据,再利用该自动标注数据对模型进行预训练,以此解决AMR解析和句法分析数据不足的问题。通过这种方法可以得到AMR解析和句法分析的自动标注数据(EN,AMR,SyntaxTree)。我们先利用该自动标注数据对模型进行预训练,然后再利用人工标注数据对预训练模型进行微调(Fine-tuning)。
4 实验
4.1 实验数据集
本实验使用的AMR数据集是AMR 2.0 (LDC2017T10),其训练集、开发集和测试集分别包含 36 521个、1 368个和1 371个句子以及对应的AMR图;句法分析数据集是Penn Treebank,其训练集(WSJ02-21)、开发集(WSJ24)和测试集(WSJ23)分别包含39 611个、1 346个和2 416个句子以及对应的句法树。此外,为了获取大规模自动标注AMR以及句法树,本文对WMT14英德数据集中的390万英文端句子使用基线AMR模型以及开源工具AllenNLP(2)https://github.com/allenai/allennlp分别进行解析得到自动标注AMR和句法树。为了缓解数据稀疏问题,本文将自动标注语料以及标准语料进行子词化处理,词频参数设置为2万(3)https://github.com/rsennrich/subword-nmt.git。此外,由于BERT模型会自动对句子进行子词化处理,因此在涉及BERT预训练模型的实验中,为了与BERT模型的子词化处理结果一致,我们使用transformers(4)https://github.com/huggingface/transformers工具包中的BertTokenizer对数据进行子词化处理。实验中所使用的BERT为bert-base-uncased (12 layers, 768 dimensions, 12 heads)。
4.2 模型设置
本实验所使用的代码是以OpenNMT-py为基础的Transformer模型。实验中Transformer编码器和解码器的层数皆设置为6层,将多头注意力机制的头数设置为8。词嵌入向量和隐藏层的维度都设置为512,前馈神经网络层的维度为2 048。标签平滑设为0.1。实验中还使用了Adam优化器对参数更新进行优化,其中β1=0.9、β2=0.998、batch size=8 192。除此之外,实验中的Warm up step、learning rate、dropout rate、label_smoothing分别设为16 000、2.0、0.1、0.1。在解码过程中,beam size设置为4。
在训练的过程,单任务的模型训练20万步,联合学习模型训练30万步。在进行模型选择时,基线实验以及仅使用外部语料进行预训练的实验中都选用在开发集上性能最好的模型进行测试,在使用BERT的实验中,选用最后的模型进行测试。在使用预训练模型联合学习的实验中,在微调的过程中仅使用单任务数据进行微调。
句法分析的评测使用标准的Evalb工具,AMR解析的评测使用Smatch[38]及其他细粒度的评判指标。
4.3 实验结果
表1给出并比较了在不同场景下,联合学习和非联合学习的AMR解析和句法分析的性能。在此,将不使用外部资源并且非联合学习的模型作基准模型。从中可以看出:
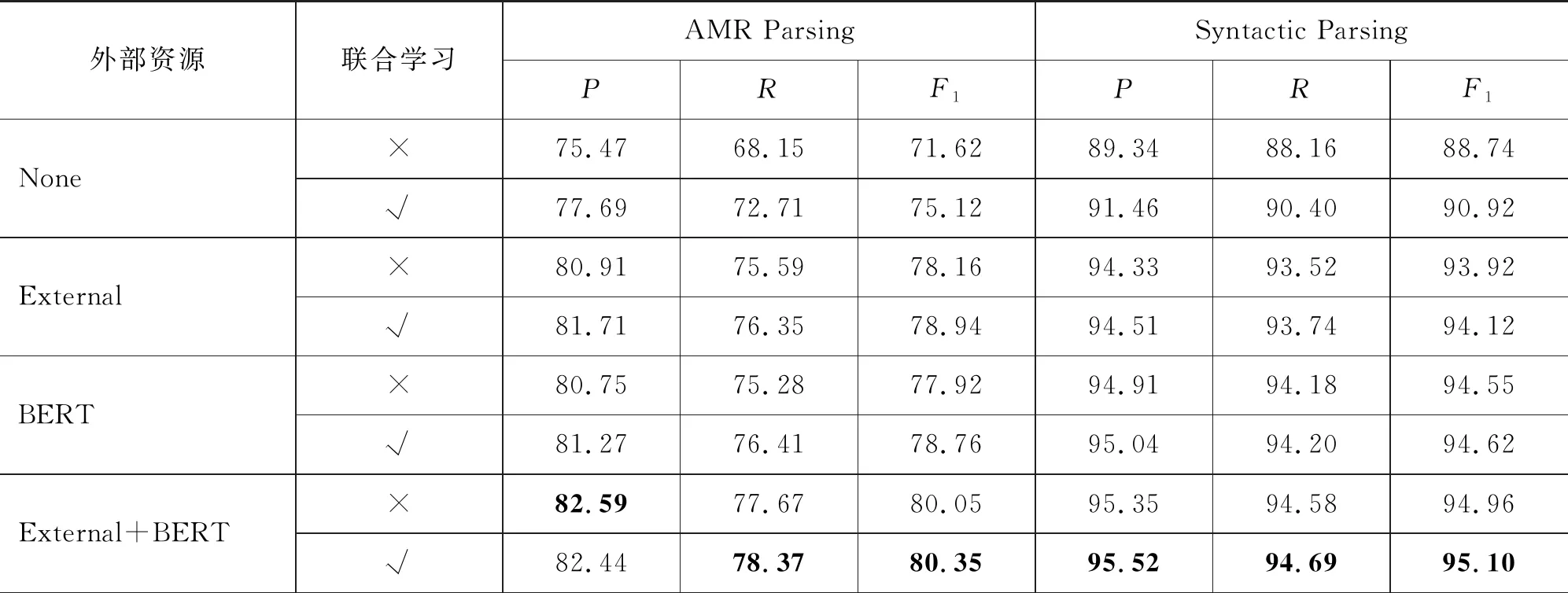
表1 基于AMR语义解析及成分句法分析联合学习实验性能
(1) 联合学习能够同时提高AMR解析和句法分析的性能。例如,在不使用外部资源的情况下,联合学习分别提升了AMR解析3.50个SmatchF1值和句法分析2.18个F1值。
(2) 随着外部语料的使用,AMR解析和句法分析的性能得到了大幅度的提升,造成联合学习较非联合学习的优势变小。例如,在同时使用大规模自动标注语料和BERT的场景,联合学习分别提升了AMR解析0.30个SmatchF1值和句法分析0.14个F1值。
(3) 基准模型与相比,我们最好的模型在AMR解析和句法解析上分别提升了8.73和6.36个F1值。
4.4 与其他实验相关工作比较
以下分别针对AMR解析和句法分析,与相关工作进行比较。
4.4.1 与AMR 解析比较
表2列出并比较了近些年AMR解析相关工作的实验结果,其中G′19和X′20使用大规模自动标注语料,Z′19、Q′20和C′20使用BERT预训练模型。与他们的工作相比,本文提出的方法Smatch性能明显优于G′19、Z′19和Q′20,与X′20和C′20相当。同时,在NER和SRL两个方面取得的性能均优于其他系统。

表2 AMR Parsing与前人工作比较
4.4.2 与Syntactic Parsing比较
表3列出并比较了近些年英文句法分析的实验结果。其中“T”表示采用基于转移的方法,“G”表示采用基于图的方法,“S”表示采用序列标注的方法,无标注表示使用Seq2Seq的方法,“†”表示使用了BERT模型。从结果可以看出,本文模型性能要优于同样使用Seq2Seq的模型,并且在使用和不使用BERT的场景下,都能达到接近使用图模型的性能。
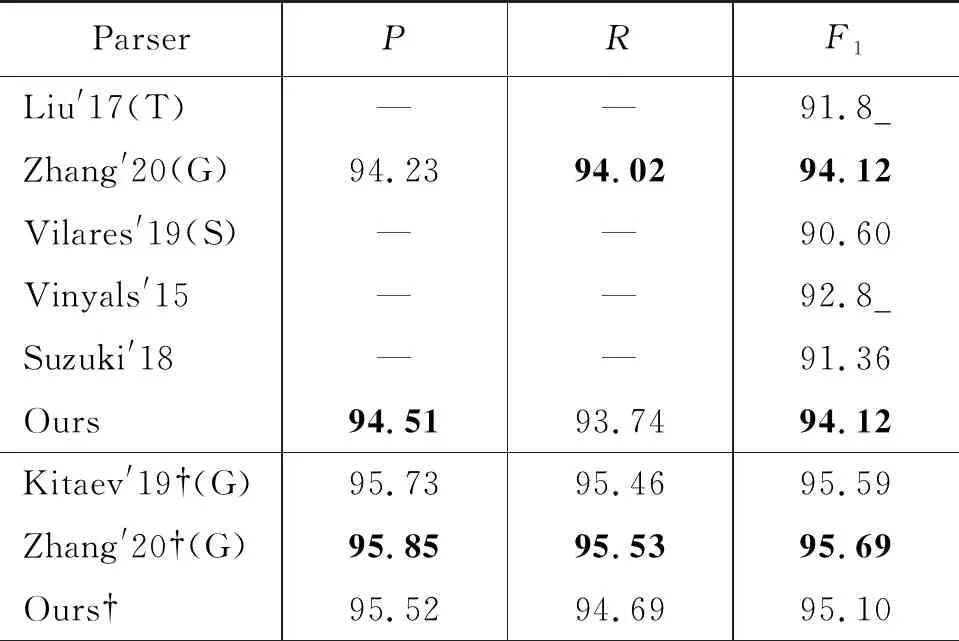
表3 Syntactic parsing与前人工作比较
4.5 实验分析
4.5.1 BERT ScalarMix对模型结果的影响
在3.2节中提到,本文实验中将BERT各层参数加权求和后的结果作为BERT embedding的输出,该方法被称为ScalarMix,此处对该方法在两个任务上进行了对比。本节中使用的BERT依旧为bert-base-uncased,在不使用ScalarMix的实验中,BERT embedding选择BERT第12层的输出作为模型的词嵌入。在模型的选择上,我们依旧根据模型在开发集上的性能选择最终的测试模型,实验结果如表4所示。
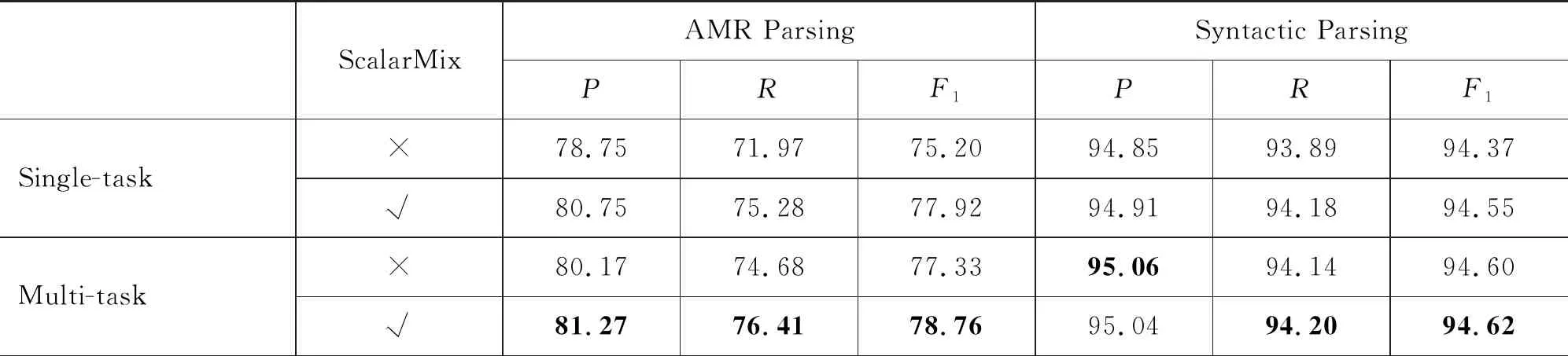
表4 BERT ScalarMix对模型性能的影响
结果表明,使用ScalarMix在单任务训练的实验中,AMR解析和句法分析分别提升了2.72和0.18个F1值;在联合学习的实验中,AMR解析和句法分析分别提升1.43和0.02个F1值。我们推测可能的原因是BERT的每一层对不同任务的信息捕获能力各不相同,ScalarMix通过加入两个习得参数w和γ,让模型根据BERT每一层对任务信息的捕获能力,学习BERT在每一层的利用程度。Tenney等人[36]发现在利用BERT词表示来训练词性、句法和语义等任务时,句法信息出现在BERT的较低层的表示中,而语义信息则贯穿整个神经网络。实验证明,即便是在AMR解析任务中这一结论依旧成立,且由于神经网络对提高句法信息已经拥有较好的捕获能力,ScalarMix对句法任务的性能不如AMR解析任务明显。
4.5.2 实例分析
AMR标注中除了包含语义角色之外,还拥有general semantic role (如: manner、:age、:location)、in quantities (如: quant)、in date-entity (如day、:month)等标签,在句法解析中的任意一个名词可以在语义解析中获得更充分的解释。如图4所示,对比单任务和联合学习任务的解码结果发现,在单任务句法分析的实验中,the selling panic in both stocks and futures并没有被看作是一个名词短语,而是被拆分成了两个名词短语。但是在联合学习中,模型成功学习到了这个短语,将这几个名词解析成一个名词短语,且在AMR中会对一个拥有词根的词做进一步的拆解,如investor,在AMR中就会被拆解为:

图4 单任务和联合学习在句法任务上的差异
(p / person
:ARG0-of (i / invest-01))
因此可以学习到相同词根但不同词性的词之间存在的联系,进一步帮助句法分析。
同样地,AMR解析在联合学习的过程中也可以借助句法信息更好地对语义以及短语之间的修饰关系进行学习。如图5所示,在单任务AMR解析任务中,模型没有学习到短语at the research center对at a news conference的修饰关系,然而在联合学习的模型中,模型成功学习到两个短语之间的从属关系,且输出的AMR图与正确结果一致。

图5 单任务和联合学习在AMR解析上的差异
4.5.3 句法性能对于AMR解析的影响
在上述实验中,我们使用AllenNLP作为自动标注句法树的来源,AllenNLP的性能为94.11,但Mrini等人[43]的模型性能可以达到96.38,是目前性能最好的模型。为了进一步探究句法分析对AMR解析性能的影响,我们使用Mrini等人[43]开源的代码和训练好的模型(5)https://github.com/KhalilMrini/LAL-Parser(LAL-parser)对WMT14数据进行解析,得到自动标注的句法树,并用该句法树重复表1中使用自动标注语料进行联合学习(External)的实验,实验结果如表5所示。从表5可以看出,准确性更高的自动标注句法树对AMR解析以及句法分析的性能都有一定的提升,但性能提升并不明显。我们推测是因为AllenNLP已经达到94.11的性能,其生成的自动标注句法树足以让模型学习到所需句法知识,因此更高准确性的句法对AMR提升并不大。

表5 句法分析性能对AMR解析的影响
5 总结
本文基于Seq2Seq模型提出了一种联合成分句法分析和AMR解析的学习方法。实验结果表明,成分句法分析和AMR解析的联合学习对两个任务的性能都有一定程度的性能提升。为了克服数据稀疏的问题,本文使用了自动标注的大规模外部语料,进一步提升了实验性能。除此之外,本文还以一种更有效的方法使用BERT预训练模型。在使用外部语料和BERT进行训练后,相比较于基线实验结果可以使AMR解析和句法解析性能分别提升了8.73和6.36个F1值。实验表明联合句法分析和AMR解析任务是一种行之有效的方法,但随着外部资源的加入,联合学习较非联合学习的优势逐渐减小。
在未来的工作中,我们计划在解码时加入对抗机制,让模型能够区分多任务之间的私有特征和共享特征,以避免两个任务由于共同更新参数而丢失掉对自身任务有益的部分信息。此外,近期有学者借助自训练进行AMR解析并取得了不错的效果,我们也在尝试将自训练的训练策略加入到联合学习的过程中。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化·高一版(2021年4期)2021-07-19
大连民族大学学报(2021年2期)2021-07-16
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
福建中学数学(2016年7期)2016-12-03
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
