
基于双注意力对偶学习的图像超分辨率重建算法
2022-09-03 05:07:26刘琳珂
辽宁科技大学学报 2022年2期
刘 恒,梁 媛,潘 斌,刘琳珂,侯 健
(1.辽宁石油化工大学 信息与控制工程学院,辽宁 抚顺 113001;2.辽宁石油化工大学 理学院,辽宁 抚顺 113001)
图像是人类传递信息的常用方式之一,但受拍摄设备和天气等因素的影响,获取的图像在分辨率上往往不尽人意。图像超分辨率重建技术在一定程度上满足了人们对高质量图像的需求,并且在视频监控、医学影像、图像压缩等领域广泛应用。
实现单幅图像超分辨率重建的方法有三大类,分别是基于插值、重建和学习的方法。其中,基于插值的方法[1]是依据低分辨率图像的像素灰度值估算其它像素点的灰度值,进而实现超分辨率图像的重建。但是采用该方法获得的重建图像,在边缘会产生锯齿效应和块效应。基于重建的方法[2]是建立图像的退化模型,利用退化前后低分辨率图像的误差进行迭代,优化求解,从而重建出高分辨率图像。但是该方法依赖高分辨率图像的先验知识,所以不适合做放大倍数的图像重建。基于学习的方法[3]是输入一组高分辨率和低分辨率图像对,利用低分辨率图像对模型进行训练,学习低分辨率图像与高分辨率图像的对应关系,从而更好地输出超分辨率图像。与其他两类方法相比,基于学习的方法重建的图像具有更好的视觉效果。
近年来,基于深度学习的方法成为研究重点。2014年,卷积神经网络首次被Dong等[4]引入图像超分辨率重建技术中,提出SRCNN(Superresolution convolutional neural network)算法,但该算法运行效率低。2016年,Dong等针对该问题,提出FSRCNN(Fast super-resolution convolutional neural networks)算法[5],将需要提高分辨率的图像直接输入网络,从而提高运行效率,但是图像重建效果一般。为了避免输入图像预处理带来的重构伪影,Lai等将拉普拉斯金字塔引入图像超分辨率重建中,提出LapSRN(Laplacian pyramid super-resolution network)算法[6],在图像特征空间域和通道域采用均等处理,浪费计算资源。现有算法没有考虑超分辨率图像重建模型的自适应性问题,限制了图像的重建质量。
本文引入基于双注意力机制的对偶学习算法,在深层特征提取模块引入注意力机制,提高重建精确度,从而优化重建过程中的映射关系;在处理图像特征空间域和通道域时,更多关注目标任务显著性的特征,从而使计算资源得到最大化的利用。采用对偶学习策略,为低分辨率图像提供额外的重建监督,减少映射函数的可能空间,并通过迭代反馈误差有效指导超分辨率图像重建,以更好地解决超分辨率图像重建模型的自适应性问题。
1 基于双注意力机制的对偶学习算法
1.1 网络结构
本文算法分为两个子网络,即原始重建网络和对偶学习网络。其中,原始重建网络包含三个模块:浅层信息提取模块、深层信息提取模块和重建模块。浅层特征提取模块和深层特征提取模块包含的基本模块数由放大倍数S决定,为log2S个基本模块。浅层特征提取模块的每个基本模块依次由卷积层、激活函数、卷积层组成;深层特征提取模块每个基本块由一个双重注意力模块、亚像素卷积层和卷积层组成。网络结构如图1所示。

图1 基于双注意力机制的对偶学习算法网络结构Fig.1 Dual learning algorithm network structure based on dual attention mechanism
浅层特征提取时,首先对原始图像预处理,采用双三次插值法将图像尺寸放大至与输出图像相同,记作ILR,将其作为输入图像,使用3×3卷积核提取ILR的特征,记为;接着使用3×3卷积核、以2为步长做卷积操作,使用Leaky ReLu函数激活,再通过3×3卷积核、以1为步长做卷积操作,得到下采样处理特征图。下采样次数为log2S,得到与原图像尺寸相同的特征图I,使用1×1卷积得到原图像。计算过程
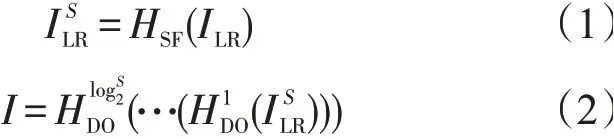
式中:S为图像的放大倍数;HSF()为单层卷积映射;()表示第一次进行卷积-激活函数-卷积操作。
深层特征提取时,将最后一次下采样得到的特征图作为双注意力机制模块的输入,之后使用亚像素卷积进行上采样操作,这一过程同样执行log2S次。为了更好地进行特征融合,对上采样得到的特征图使用1×1卷积核降维,降维后的特征图与尺寸相同的浅层特征图进行特征融合,融合后的特征图作为下一次双注意力机制的输入,特征融合次数为log2S次。
重建模块中,对融合的特征图进行卷积操作得到高分辨率图像ISR即为所求图像。计算过程
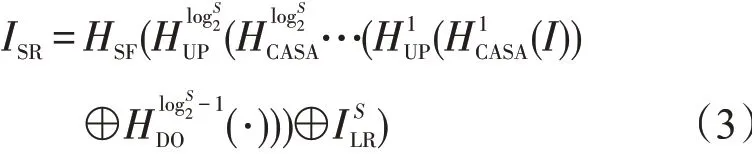
式中:HUP()为上采样操作,上标表示第几次执行上采样操作;HCASA()为双重注意力操作,上标1表示第1次执行双注意力操作;⊕表示特征融合操作。
对偶学习中,用重建高分辨率图像下采样生成低分辨率图像。当放大倍数为S时,基本模块数为log2S个。对偶模块框架如图2所示。

图2 对偶模块框架Fig.2 Dual module framework
1.2 双重注意力机制
受CBAM(Convolutional block attention module)算法[7]的启发,将双重注意力机制的内部结构设置为通道注意力模块和空间注意力模块,如图3所示。

图3 双重注意力机制的结构Fig.3 Structure of dual attention mechanism
1.2.1 通道注意力 通道注意力机制即网络通过自动学习的方式获取每个特征通道的显著性,并且据此给每一个特征通道赋予一个权重值,从而使网络将重点放在信息多的特征上,重新标定前面得到的特征。其结构如图4所示。

图4 通道注意力机制的结构Fig.4 Structure of channel attention mechanism
首先对输入的特征图H×W×C进行全局平均池化,得到1×1×C的特征向量,计算式

式中:C为特征图的个数;H×W表示特征图的尺寸;uc(i,j)为特征图第c个通道位置在(i,j)的像素值;Fsq()为全局平均池化操作,用来求出每个特征图对应的均值。
使用两个全连接层建立通道与通道间的相关性,并根据网络学习各通道的重要程度对特征图的权重进行调整,计算式
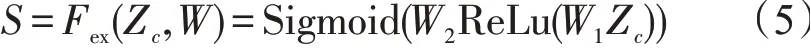
其中,Fex为特征提取函数;W1和W2分别为两个1×1卷积层的权重,W1以比率r的形式进行通道缩减,W2以比率r的形式进行通道增加,通过训练网络学习不断调整权重值。
最后,不同的通道乘上相应的权重,得到每个特征图的权重。计算式

式中:xc为新的特征图;sc为第c个通道的权重;uc为第c个通道;Fscale为sc和uc的乘积函数。
1.2.2 空间注意力 每个通道的特征图显著性不同,每个特征图上不同位置的纹理细节也是不同的,由此,本文引入空间注意力模块,捕捉图像的纹理细节。网络结构如图5所示。将H×W×C的特征图F同时进行一个通道维度的平均池化和最大池化,得到两个H×W×1的通道描述,之后将两个描述按通道完成拼接。为保证拼接后的描述能强化所有空间位置并实现非线性映射,本文使用7×7卷积核进行卷积操作,采用Sigmoid激活函数得到权重矩阵Ms,并将其与特征图F的权重信息相乘,得到具有新权重的特征图。

图5 空间注意力机制的结构Fig.5 Structure of spatial attention mechanism
1.3 对偶回归网络
对偶回归网络通过反馈信息对学习任务的效果进行加强和指导,结构如图6所示。将低分辨率图像输入原始重建网络,生成高分辨率图像,再利用对偶网络将其转化为低分辨率图像。这一过程存在噪声[8],因此转化后的低分辨率图像与原始图像之间存在差异。若将这个差异最小化,可同时改进两个子网络模型的性能。考虑到对偶任务概率分布之间的联系,在训练过程中加入约束条件:目标函数1

图6 对偶学习网络结构Fig.6 Dual learning network structure
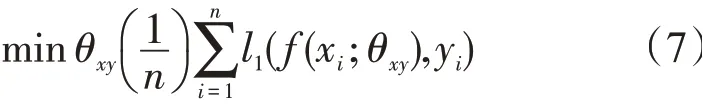
目标函数2

式中:l为两个函数的差异函数;f和g是两个对偶网络的模型;θxy为低分辨率图像到高分辨率图像的映射;θyx为高分辨率图像到低分辨率图像的映射;x为低分辨率图像;y为高分辨率图像;P(x)P(y|x;θxy)为对偶学习对原始重建模型的约束;P(y)P(x|y;θyx)为原始重建模型对对偶模型的约束。
为了求解这个问题,使用拉格朗日乘数法,为两个目标函数增加乘数项

若能较好地估计P(x)和P(y),对偶学习算法就能提升两个对偶网络的性能。
1.4 损失函数
两个子网络都使用L1损失函数,则原始重建网络的损失函数为LP(P(xi),yi),其中,i为第i张图像,P(xi)为超分辨率图像,y原始高分辨率图像。对偶网络的损失函数表示为LD(D(P(xi)),xi),其中,D(P(xi))表示超分辨率图像下采样得到的低分辨率图像;x表示由预处理图像经过浅层特征提取模块卷积得到的低分辨率图像。总损失函数为

其中λ为超参数,用来控制两个网络的权重。
2 实验结果及分析
2.1 实验设置
实验使用pytorch框架对网络进行构建,实验操作系统为64位Ubuntu18.04,计算平台版本为CUDA10.0,硬件配置为Intel Xeon(R)Platinum 8160 CPU,250G内存,GPU为4张NVIDIAP100。
2.2 网络参数
注意力卷积核数为64,每次上采样前包含30个注意力模块;采用自适应矩估计优化器,β1=0.9,β2=0.999;对偶回归中的权重λ为0.1,批量大小为6。本文算法放大4倍图像重建的参数设置如表1所示。

表1 训练模型网络参数Tab.1 Network parameters of training model
2.3 数据集
使用的训练集为DIV2K和Flickr2K,基准数据集为Set5、Set14、B100、Urban100。
2.4 评价指标
从主观与客观两方面对图像的重建质量进行评估。以峰值信噪比(Peak signal-to-noise ratio,PSNR)、结构相似度(Structural similarity,SSIM)以及重建时间作为客观评价的指标。其中,PSNR值越大,图像失真的程度就越小,即图像的重建效果越好;SSIM值越接近于1,重建图像与真实图像就越接近。主观评价依据直观的视觉效果,对图像的重建质量进行评估。
2.5 结果分析
(1)算法性能及时间分析。分别在4个基准数据集上完成算法的性能评估及重建时间分析,并与SRCNN算法进行对比,实验结果如表2所示。虽然本文算法的重建时间比SRCNN算法平均每张图像多消耗0.03~0.2 s,但是本文算法的PSNR值和SSIM值都高于SRCNN算法。尤其是在Set14数据集中,相比SRCNN算法,本文算法平均每张图像的重建时间缩短了0.01 s,且PSNR值提高1.16 dB,SSIM提升0.018。本文算法的性能以及重建效率均可满足相关应用的需要。
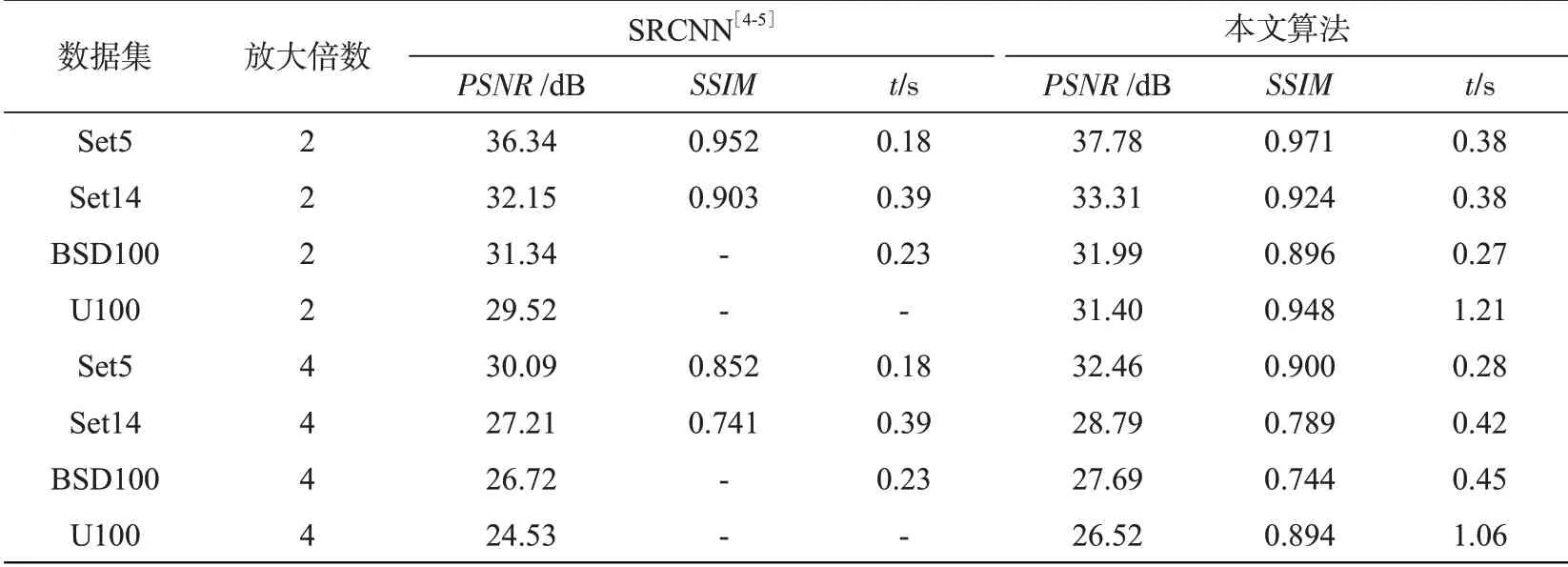
表2 在放大2倍和4倍下PSNR、SSIM及时间分析Tab.2 PSNR,SSIMand time analysis under 2 times and 4 times magnification factors
(2)不同算法性能对比。设置相同实验参数,将本文算法与Bicubic、SRCNN、ESPCN(Efficient sub-pixel convolutional neural network)、DRRN(Deep recursive residual network)、LapSRN、DBPN(Deep back-projection networks)算法进行对比,结果如表3所示。当放大倍数为2和4时,本文算法的峰值信噪比和结构相似度都高于其他算法。

表3 不同算法在图像放大2倍和4倍下PSNR和SSIM对比Tab.3 Comparison of PSNR and SSIM for different algorithms under 2 times and 4 times magnifications
(3)不同算法的视觉效果对比。将本文算法与原始高分辨率图像(High resolution,HR)、低分辨率图像(Low resolution,LR)、Bicubic、SRCNN、DRRN、LapSRN和DBPN算法从重建图像的视觉效果上进行对比。从基准数据集中随机选取图像,将其输入到各网络模型中,重建图像的局部放大图与真实图像的局部放大图详见图7和图8。与其他算法相比,本文算法重建的高分辨率图像,在边缘和纹理细节上更加清晰,与真实图像的视觉效果更接近。

图7 Set5图像放大2倍下不同算法的视觉效果对比Fig.7 Comparison of visual effects of different algorithms under 2 times magnification of Set5 image

图8 Set14图像放大4倍下不同算法的视觉效果对比Fig.8 Comparison of visual effects of different algorithms under 4 times magnification of Set14 image
3 结论
为了解决图像重建的自适应问题和避免图像重建浪费过多计算资源,本文引入双注意力机制和对偶学习用于单幅图像超分辨率重建。算法使用对偶学习减少低分辨率图像到高分辨图像的函数映射空间,并且结合通道注意力机制和空间注意力机制获取不同位置不同通道的权重值,使网络可以依据权重高效分配计算资源,同时使用极少的参数提高超分辨率重建的质量。在基准数据集Set5、Set14、BSDS100、Urban100上进行放大2倍和4倍的重建测试实验,并对比峰值信噪比和结构相似度指标。实验结果表明,与Bicubic、SRCNN、ESPCN、DRRN、LapSRN算法相比,本文算法的峰值信噪比和结构相似度都高于其他算法,视觉效果比其他算法图像更清晰。本文算法的重建时间比SRCNN算法稍长或持平。
猜你喜欢
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
雷达学报(2020年3期)2020-07-13 02:27:16
艺术科技(2018年2期)2018-07-23 06:35:17
应用数学与计算数学学报(2015年1期)2015-07-20 11:39:06
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
数学年刊A辑(中文版)(2014年6期)2014-10-30 01:41:24
航天返回与遥感(2014年4期)2014-07-31 17:47:42
