
基于云计算的电力系统计算分析平台构建
2022-09-02 09:09苏寅生周挺辉郑外生赵利刚甄鸿越黄冠标
南方电网技术 2022年7期
苏寅生,周挺辉,郑外生,赵利刚,甄鸿越,黄冠标
(1. 中国南方电网电力调度控制中心,广州510663;2. 直流输电技术国家重点实验室(南方电网科学研究院),广州510663;3. 中国南方电网有限责任公司,广州510663)
0 引言
电力系统建模与仿真分析是支持大电网安全稳定运行的重要技术基础,南方电网在多年的规划运行中应用多种计算分析工具,开展了稳态分析、动态分析、暂态分析等多类型的仿真计算。但随着大量分布式新能源的接入以及系统建模的精细化[1]、控制系统的复杂化[2]、系统规模的不断扩大[3],仿真效率将急剧降低,当前单人单机的仿真模式已经无法满足日益增长的仿真需求。
在国内,国家电网公司首先于2015年构建新一代特高压交直流电网仿真平台,核心仿真分析平台为部署于中国电科院的超算平台。超算平台承载着超级并行计算和仿真计算核心程序,并以网络方式对外提供计算服务,另外通过协同计算平台提供异地计算能力,满足大批量故障任务并行批处理[4 - 5]。
相对而言,南方电网公司在基于云计算共享的电力系统计算分析平台方面起步较晚,仍主要采用传统的工作模式,未能充分利用先进的高性能计算和智能化处理技术。另一方面,南方电网总调为解决传统集中式架构中的诸多问题,因地制宜地提出了兼顾性能与安全性的分布式解决方案,实现了从集中式架构转变为分布式架构的转变,以数字化、智能化代替了传统的“烟囱”设计。依托阿里私有云构建了电力行业第一个完全基于互联网新技术的调度自动化系统基础平台[6]。
基于上述挑战和机遇,本文以南方电网总调分布式底层平台为依托,提出了基于现代互联网新技术的电力系统计算分析平台。异于传统超算平台自研管理及调度系统管理刀片机的做法,本文以当前互联网领先的Kubernetes集群管理系统及Docker容器化部署技术为基础,对基于云计算共享的电力系统计算分析平台进行探索,提出了可实时动态扩展的集群系统架构,构建了高效、可靠、绿色的共享计算平台和协同工作平台,并与传统的计算结果进行比对,验证该平台的准确性、可靠性及效率。
1 计算分析平台的需求分析
在电力系统计算分析方面,南方电网各级调度、规划部门传统的计算模式在数据准备、执行仿真、结果处理等各阶段均需大量人工操作,而且耗时较长,电网仿真分析的并行化和自动化程度较低,与现代计算机发展脱节。此外,在大电网的大量计算分析中涉及的电网运行方式众多,但目前仅主要关注电网的稳定性结论,对于大量的有价值的计算过程信息并没有进行有效地存储和分析,可能对后续分析工作造成不利影响。此外,随着新型电力系统的发展,未来将有较多的新能源进行接入,新能源的随机性、波动性、间歇性使得发电计划的不确定性大幅增加,传统的典型工况(丰大、丰小、枯大、枯小)难以覆盖新能源电力系统的运行状态。未来将会构建海量的运行方式进行仿真计算,即便进行了典型运行方式的辩识,动辄还需要数十上百个运行方式的计算。在未来找到合理的安全边界解析方法大量缩减运行方式数量前,为保障系统的安全稳定性,对大量运行方式的计算是较为可靠的方法之一。面对比当前增加十多倍工作量的计算,传统的单机或单机多核计算在效率上已经捉襟见肘。另一方面,国家电网的超算中心仿真平台的研发已经证明了,开发一套集中管理式的电力系统计算分析平台经济社会价值意义重大,可为提升电网分析水平提供强有力支撑。
为支撑电网的安全稳定运行,实行数字电网推动构建新型电力系统[7],本文所开发的平台应具备如下功能。
1)承载电力系统主要分析功能的核心程序,包括但不限于潮流、机电暂态、短路计算、交直流相互影响分析等[8]。上述程序以网络的形式对外提供服务,可满足用户大批量故障任务的并行批处理。另一方面可实现复杂单一故障的并行计算,例如电力系统安全稳定导则(2019年版)[9]新增的机电-电磁暂态混合仿真需求,为电网运行分析提供高效、精确的仿真能力。
2)具备满足各级规划、调度人员开展异地联合计算分析的功能,包括但不限于计算编辑、计算设置、单任务计算、批处理任务提交、结果分析等。实现不同层级用户的并发、协同使用需求,最终实现网、省、地计算业务的底层资源共享和一体化管理。
3)具备价值信息的存储与回溯能力。对于大量有价值的计算过程与结果信息,一方面通过友好界面为初始用户提供决策信息,另一方面通过集中式的储存,为日后发展人工智能学习、大数据挖掘提供充分的历史信息。
2 关键技术与技术难点
计算分析平台构建关键点有3个:高效、可靠以及绿色。高效即计算速度要快,能在尽量短的时间内完成用户的计算;可靠即系统的安全性高,在平台部分故障的情况下依然不中断服务;绿色即节能,尽量减少资源的占用和闲置浪费。
基于现代计算机的发展,高效以及可靠完全可以依靠堆砌硬件予以实现,通过联合部署众多的多核计算机、服务器等,近年来涌现了多种技术方案[10 - 13],提供数百核乃至数万核进行并行计算。然而电力系统的仿真计算闲时忙时特征尤其明显,在年度方式、迎峰度夏期间,计算需求将明显倍增,平时十倍、数十倍的计算需求将冲击计算平台。为了应付在这期间的高并发需求,需要底层硬件平台需提供足够的算力,不得不部署大量的底层计算机。但峰值过后,大量的闲置计算机又造成了资源的浪费,不符合绿色的特点。同时,如何对众多的计算节点进行有效地管理,提供不间断的运行服务,也是重点之一。
为实现上述的关键点,既能够高可靠性地满足用户的使用需求,同时又不造成资源的浪费,是计算分析平台的技术难点。为此,本文从技术选型、系统设计等方法进行了综合考虑。通过对现代的计算机技术的综合比较,结合互联网开发的前沿技术,提出了基于云平台的可实时动态扩展的集群系统架构。该架构实现了从传统单体应用向微服务化的转变,将数据管理、计算服务、统计服务、归档服务进行了解耦与隔离。去中心化的设计带来了更高的可用性和弹性、松耦合也便于各个服务的独立升级维护,并阻止了可能的系统故障蔓延。该部分在第3节进行了探索。通过弹性扩展的系统设计共享调度云数万核心的资源池,从硬件、软件等多层次实现了资源的共享,为用户提供了高性能计算服务的同时,最大限度地减少了资源的占用,实现对硬件的绿色使用。
3 计算分析平台技术路线
3.1 基础硬件平台选型
自1983年中国首台超算银河一号研制成功后,国内超算已有近40年的发展历史,并成为了国家科技发展水平和综合国力的标志之一。而在2006年亚马逊云服务Amazon Web Services (AWS)对外公开使用,2010年阿里云正式对外运营,云服务不过才10余年的历史;但云服务的飞速发展,甚至让传统超算也形成了“云超算”的发展趋势,表1展示了二者的对比情况[14]。

表1 传统超算与现代云服务的对比Tab.1 Comparison between traditional supercomputing and modern cloud services
基于上述的特点对比,为满足电力系统计算分析平台的共享性、爆发性需求,本文采用了云服务的技术路线,以南方电网总调的调度云平台为依托而建设。该平台是南方电网总调联合阿里企业云建设的分布式解决方案。截至目前为止,SCADA 系统、电力现货交易系统、电网负荷预测等一系列核心应用系统均已完成了云平台的改造和部署,解决了传统系统负载集中、应用受单个服务器性能限制的问题,大大降低了原有应用的响应时间、提升了应用的运行效率。
3.2 Kubernetes集群管理系统
为保障本文所述平台的高效及可靠性,核心系统采用了工业级的Kubernetes(简称K8s)集群管理系统及Docker容器化部署技术,提高平台的可用性及灵活扩展特性[15 - 17]。Docker是一个应用容器引擎,让开发者可以应用以及依赖包到一个可移植的容器中,在一台机器上瞬间创建几十个相同的或不同的应用,且相互之间使用沙箱机制进行隔离,不会出现相互干扰。而K8s是开源的容器集群管理系统,可以实现docker容器集群的自动化部署、自动扩缩容、维护等功能[18]。如图1所示,通过一系列的组件提供了容器编排、调度的服务,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等功能,提高了大规模容器集群管理的便捷性,为当前基于容器技术的分布式架构领先方案。

图1 K8s集群组件示意图Fig.1 Component diagram of K8s cluster
Kubernetes在当前互联网领域得到了广泛的应用。京东早在2016年年底上线了京东新一代容器引擎平台JDOS2.0,成功从Openstack切换到JDOS2.0的Kubernetes技术栈[19]。2018年,阿里巴巴将核心控制系统Sigma 重新设计并迁移成兼容 K8s API,至2019年多数应用都在K8s上运行,并成功应对了2019年的“双11”购物节[20]。该管理系统已在事实上成为了现代互联网系统管理大规模并发的主流解决方案。
3.3 平台架构说明
确定了以上的核心技术选型后,本文计算分析平台服务器端调用了总调调度云(阿里私有企业云)的对象存储(object storage service,OSS)组件、键值数据库组件(remote dictionary server, Redis)、消息中间件(rocket message queue, RocketMQ)、企业级分布式应用服务(enterprise distributed application service,EDAS)、K8s集群管理系统;用户采用客户端或浏览器进行访问,客户端沿用南网科研院自主研发的计算分析软件(dynamic simulation program,DSP)户端并进行了适当的改造,浏览器版本则与客户端系统架构采用共同的后台服务。本文以客户端为例,整体方案如图2所示。
平台架构以K8s集群为核心,运行主要的调配及处理、计算服务;阿里云RocketMQ作为消息中间件,作为各个服务间的传递触发载体与缓冲;对象存储OSS作为数据的存储空间;数据库Redis作为高速缓存以及任务队列。企业级分布式应用服务EDAS与负载均衡(server load balancer,SLB)相互配合,为用户提供高可靠性的网络服务。

图2 系统架构示意图Fig.2 System architecture diagram
以电力系统最常规的机电暂态仿真批处理为例,说明上述平台的运作流程。用户提交数据后(可为用户主动提交的任务,或由其他系统推送),产生了以下的动作。
1)网络请求通过SLB负载均衡及EDAS后,通过反向代理获得其中可用的其中一个Tomcat服务器;服务器收到请求后,将数据存入OSS存储区,并向消息中间件RocketMQ的“待计算”队列生成消息,向高速缓存Redis标记该任务为“未完成”。
2)运行于K8s的“调配服务”订阅了RocketMQ的“待计算”队列,一旦队列非空,则消费收到的消息:一方面分析计算任务请求,将具体的计算任务(例如100个机电暂态仿真子任务)形成队列存入Redis高速缓存;随后启动“计算服务”,下达指令给集群中的各个Worker计算节点,让其启动服务;同时对计算服务进行监控,根据不同的状态执行不同的操作。
(1)待计算队列已空、且无任务计算失败,则认为计算已成功完成,停止“调配服务”,并向RocketMQ的“待处理”队列生产消息;
(2)待计算队列已空、但有任务计算失败,则认为任务计算已不正常完成;重新计算失败的任务,若重试N次(例如2次)仍无法成功,则停止“调配服务”,并向RocketMQ的“待处理”队列生成消息。
3)运行于K8s的“计算服务”,受到“调配服务”控制。启动时将在各个计算节点同时启动多个计算应用(Pod),根据“调配服务”的指令从本地(若有)或服务器下载计算核心引擎镜像,从OSS下载计算数据,每个Pod从Redis高速缓存中取当前任务的子任务(例如,其中一个故障的机电暂态仿真)进行计算,成功执行后数据存回OSS。
4)运行于K8s的“处理服务”订阅了RocketMQ的“待处理”队列,触发后从OSS下载数据,对各个独立的子任务结果进行统计,形成汇总表;随后向高速缓存Redis修改该任务为“已完成”。
5)用户定时或手动询问某个任务是否完成,若已完成则通过Tomcat返回汇总表和/或结果数据。用户通过客户端或者浏览器对结果进行查看。
4 可靠性设计
计算分析平台的核心思想是云共享,将支撑总调、中调及地调各层面的计算分析需求等,满足各级调度人员异地联合高效开展各类日常运行方式计算工作,对可靠性提出了极高的要求。虽然当前计算机技术已经对可靠性进行了极大的保障,但实际中仍存在节点失效不可用的情况。比如,由于安全漏洞、硬件故障或者设备断电、计划维护等问题,导致某些承载机重启或下线。平台需保证在上述意外情况下,降低不良影响,保证高可靠性。为此,平台设计了多层防护措施。
4.1 高可靠组件
平台全部采用阿里云成熟的工业级产品,包括但不限于储存、集群、数据库、消息中间件等。上述组件由阿里云、云原生计算基金(cloud native computing foundation, CNCF)、Apache软件基金会等厂家和开源基金会进行维护和升级,从底层上确保平台组件的高可靠性。
4.2 冗余设计
平台的核心程序均运行于K8s集群上,K8s集群是本平台的核心部分。为保障其可用性,K8s集群采用了3.Master+N.Worker(3主机N从机)设计,如图3所示[21]。
主服务器Master采用了3台服务器集群的形式,只要有任意一台服务器正常使用,平台即可正常地提供控制服务。计算节点采用N个Worker的形式,即使其中部分的服务器不可用,仅造成算力的下降,仅在平台极高负载率的情况下对计算效率有轻微的影响,不会影响平台的正常使用,且随时可以通过增加Worker的形式以恢复甚至增强平台的算力。
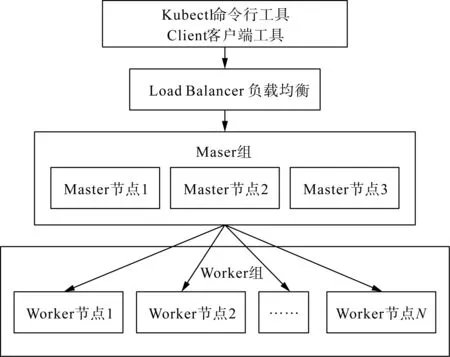
图3 K8s高可用性集群Fig.3 K8s high availability cluster
对用户的接口服务器采用了SLB负载均衡和EADS企业级分布式应用服务,多层负载均衡服务可以保障平台应对高用户并发时的处理能力。从架构上支持多个集群的冗余和Tomcat应用的多实例,只要在整个平台中有其中任意一个Tomcat服务正常,即可提供有效的网络服务。同时,多个Tomcat实例也有效地降低了多用户高并发时的压力。
Redis数据库采用了主从设计,主服务器不可用时,从服务器自动切换为主服务器,不间断地提供服务。
通过上述的保证措施,实现了任意组件的其中一个节点(“N-1”)乃至更多节点(“N-2”)情况下,平台仍能在用户无感知的情况下平稳运行。
4.3 容错及自愈特性
通过冗余设计,本平台可以有效应对某个组件部分崩溃的问题。但为以防万一组件发生全面崩溃,或设计中引入了未知的BUG,在设计中采取了多种措施以避免任务计算失败、故障持续。
1)看门狗策略:调配服务设立超时机制,单个计算任务设置了超时时间,提供重启策略及限制重启次数。在努力对用户的任务进行计算的同时,也考虑了用户数据有误造成计算失败的问题,对各个任务实现了隔离,避免了故障的蔓延。
2)自动驱逐及恢复策略:基于K8s集群策略,限制了单一应用的CPU、内存等占用的上限。一旦应用发生异常造成资源消耗过大,管理系统将驱逐异常应用并进行重构,以恢复应用的正常运行。
3)组件崩溃的备份重构策略:各个组件间提供备份重构的方案。例如,若K8s集群整体发生了崩溃,在集群重新上线或存在备用集群时,调配服务可从高速缓存Redis和消息中间件RocketMQ重启未计算的任务、部分计算任务中未完成的子任务;若RocketMQ或Redis不可用,待平台组件恢复正常后或存在备用集群时,可从OSS存储中恢复RocketMQ和Redis缓存。
平台的最终保障为OSS存储,即相当于计算机的硬盘。当OSS存储损坏时,本系统才发生不可逆转的数据损失。根据平台设计,OSS存储可以开启本地的冗余以及异地备份,基本难以发生全面崩溃的情况。根据阿里云的官方数据,数据安全可靠性为99.999 999 999%(11个9)。
用户成功提交了计算任务后,平台将通过上述多项措施保证任务的正常执行。
5 高效、协同设计
计算分析平台的最终目标是供网、省、地三级调度系统人员进行使用,平时状态下一般用于日常的方式计算安排等,同时在线用户数较少;但在迎峰度夏、年度方式等场景下,将在短时间内产生爆发性的计算需求。为应对大规模使用时的高并发高负载,同时避免堆叠硬件资源造成的闲时资源浪费,平台设计了多种效率提升和共享方案。
5.1 可弹性扩展的硬件资源
核心计算K8s集群采用了图3的3.Master+ N.Worker设计,其中每个Worker均由南网调度云平台的硬件资源池模拟,可以提供8~64核甚至更多的虚拟CPU核资源。集群的硬件资源并不独享,而是共享调度云数万节点的海量计算资源。在有需要的情况下,可将单个Worker的资源扩展至64核以上;或是将Worker的数目扩展至二三十台及以上,最终实现超过数千核心的计算平台。在平台负载压力不大的情况下,可及时释放硬件资源。该设计可充分利用资源池的优势,既保证了忙时的效率,又减少了闲时资源的浪费。
5.2 共享的软件资源池
核心计算K8s集群可实现与其他应用系统的共享。多个应用间通过命名空间实现资源隔离,具体的资源使用可由管理员进行单独控制或者由集群自行管控,实现基于云计算的共享特性。
5.3 用户间的负载均衡
平台设计了平衡用户间任务的调配服务,避免单个用户不合理地抢占资源、由于计算任务的堆积对其他用户的请求产生延迟响应。例如,仅有1个用户使用时,其将可以动用所有的计算核心;但当在线用户数M大于1时,其可动用的核心将调减为所有核心的1/M个,同时将每个用户的同时运行任务数调整为1。
该调整是动态实现的,执行中若出现超过占用超过1/M的核心时,平台提供多种策略予以调整:1)立刻终止超过1/M的计算子任务,资源调配给其他用户。被终止的子任务将在该用户的其他子任务执行完成后重启。2)不立刻终止,等待计算中的子任务执行完成后释放。
上述的策略可以保障用户间较为“均匀”地使用了集群的计算核心,但为了避免过多用户同时运行时,所有人的等待时间过长,又设计了单用户的最低占用核心数,限制同时运行的任务数,实行任务强行排队,以避免单个用户等待时间过长。
上述的效率提升方案在本平台中综合利用,在可预见的计算任务爆发前,由管理人员手动地增加硬件资源,调整Woker的核心及数量,以实现平台的扩容,该调整在几分钟内即可实现;在资源池有热备用机器的情况下,甚至在10 s以内即可实现调整。对于用户间的负载调整,将由平台自动实时地实现,无需管理人员的介入。
6 案例测试
本平台已于2021年5月份在测试环境中上线部署,并采用了南方电网月度数据对平台进行了测试。在测试阶段,采用了3.Master+10.Worker的硬件资源,单个Worker提供16核心的计算能力,总计160核心。
6.1 正确性测试
本文所指的正确性是指采用本平台计算与常规单机计算的差别,而非核心计算引擎本身计算正确与否。经过潮流、机电暂态仿真、短路电流计算等场景的测试,基于平台计算及常规的单机计算完全一致,曲线完全重合,如图4所示。
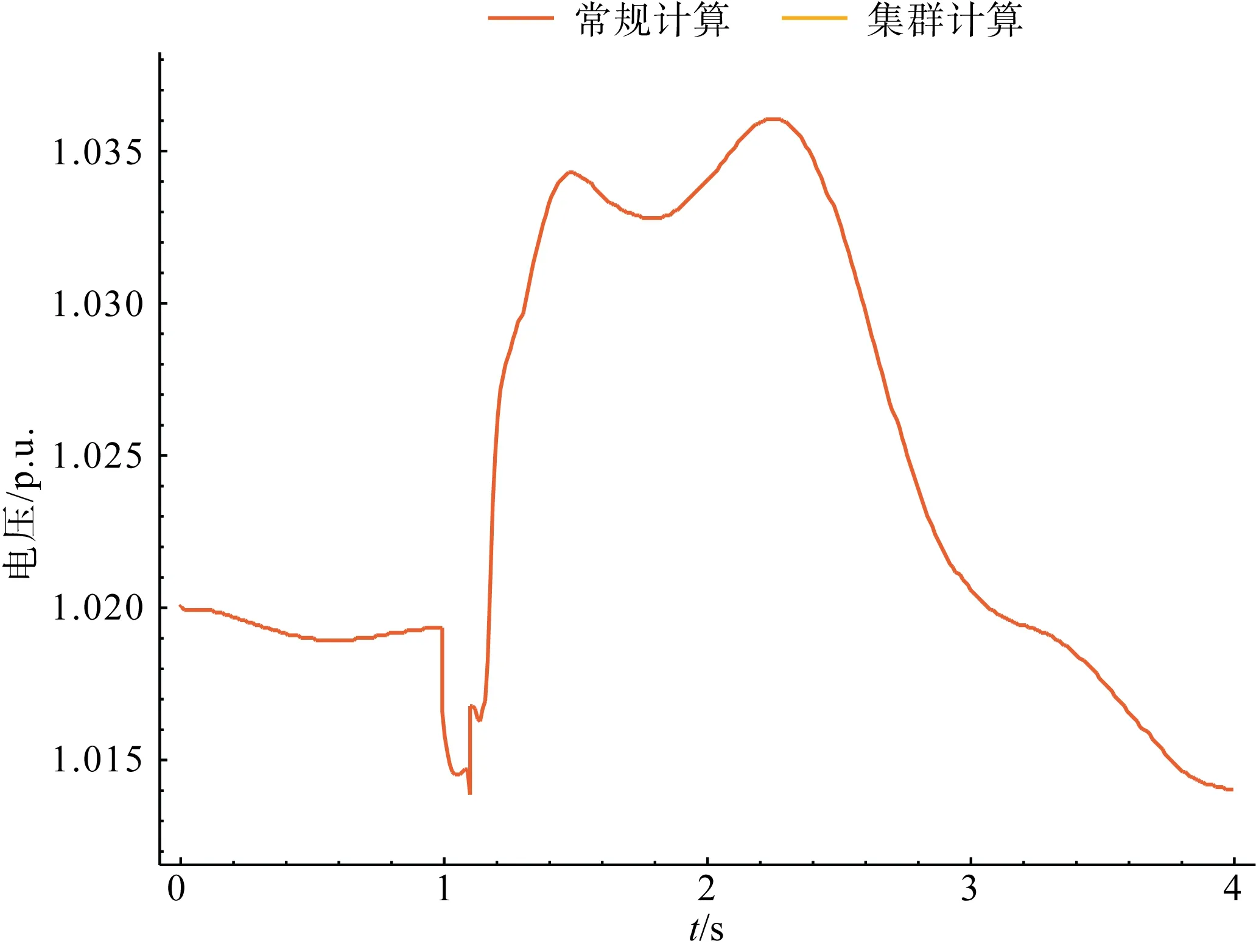
图4 常规计算与集群计算结果对比Fig.4 Comparison between conventional calculation and cluster calculation
6.2 可靠性测试
1)集群崩溃测试
在仿真过程中,手动关闭所有K8s集群Master服务器,再重新启动。测试中,包括“容错服务”、“调配服务”等正常地重新启动,并将未执行或未执行完成的任务重新进行计算。
2)RocketMQ消息丢失测试
在仿真过程中,通过伪造的客户端直接消费了“待计算”队列中的消息,以造成正常的调配服务无法正常获取消息。测试结果为,定时扫描的“容错服务”发现在OSS中该任务超时未完成,且不在“待计算”、“待处理”队伍中,即对该任务生产“待计算”消息;后续按照正常的流程执行完毕。
6.3 效率测试
采用南方电网2021年6月份的月度方式数据,对其主网层的320个N-1故障进行仿真。常规的单核计算下,需要耗时超过145 min;在本平台中,通过配置更改并行数为1~160个,其计算耗时及加速比如图5及表2所示。其中加速比定义为串行执行时间除以并行执行时间。
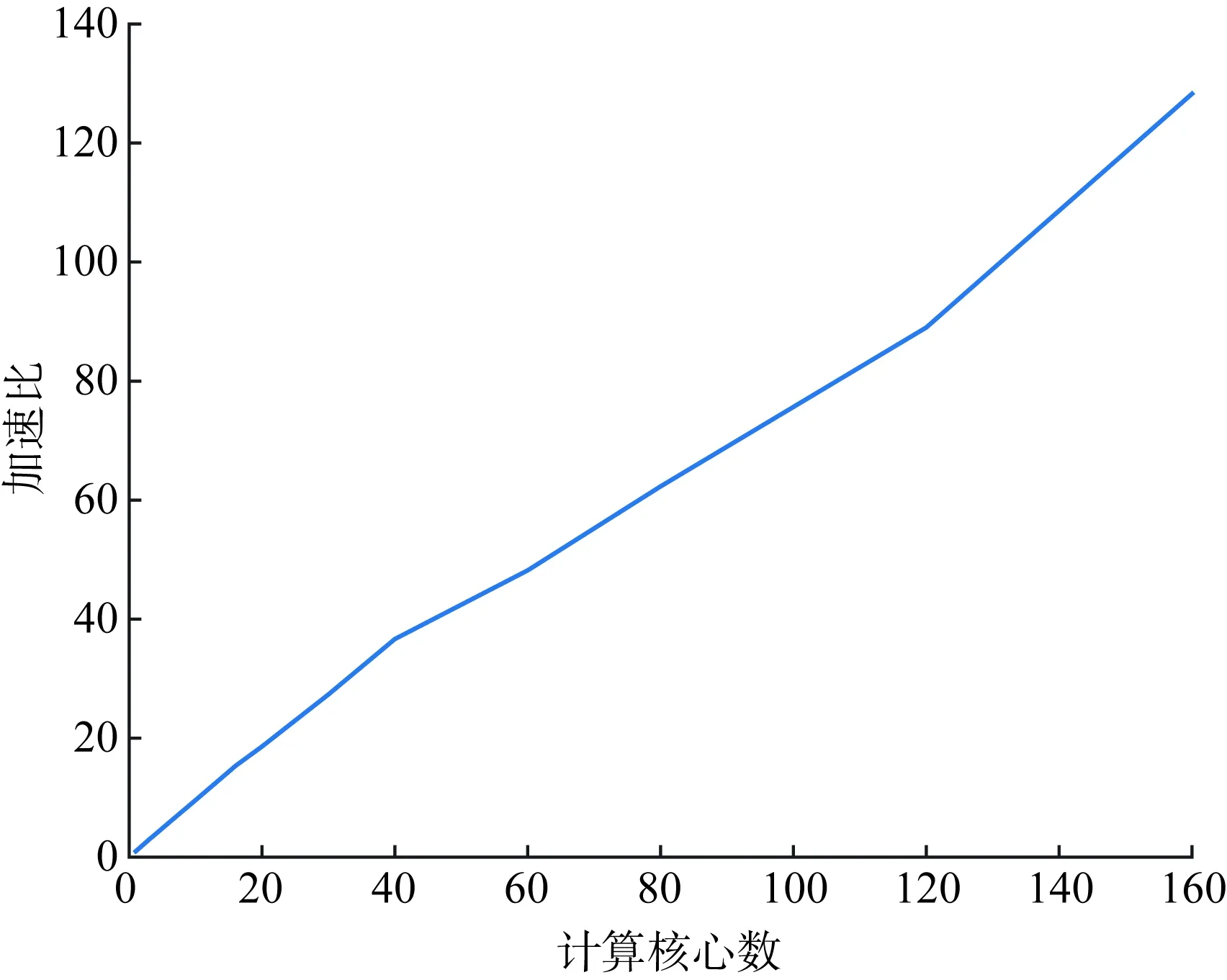
图5 集群并行效果测试Fig.5 Cluster parallel effect test

表2 并行效率测试Tab.2 Parallel efficiency test
加速比随着核心数及并行度的提升,基本呈现出线性的提升。在提供160核心的情况下,仅需要68 s左右就完成了传统情况下2.5 h的计算任务,加速比高达128。考虑到任务调度的延时,该数值已接近理论最优值。
上述结果说明了计算平台具有极其优越的仿真效率,可以有效地提升新型电力系统大规模新能源接入后的仿真速度,将某个方式多个故障的仿真耗时缩短至单个故障的仿真耗时,实现传统离线仿真工具的在线部署,实现从科研工具向生产工具的转变。
6.4 结果展示
计算结果在OSS存储中进行了归档,可长期存放用于未来的大数据挖掘、人工智能学习素材等。其可以通过丰富的形式予以展示,例如微软PowerBI或者阿里云QuickBI等,以及在线查看的报表、地理接线图等。为对接传统业务,针对当前大批量使用的机电暂态批量扫描,提供了客户端形式、浏览器形式的展示界面,如图6所示。二者共用后端服务,可适应不同的场合。

图6 展示界面示意图Fig.6 User interface diagram
7 结语
为了解决新型电力系统大量新能源接入后的仿真效率问题,本文提出了基于云计算共享的电力系统计算分析平台建设方案,并对该方案的技术选型、架构设计进行了详细的阐述。平台以当前互联网领先的Kubernetes集群管理系统及Docker容器化部署技术为基础,计算分析平台进行探索,提出了可实时动态扩展的集群系统架构,构建了高效、可靠、绿色的共享计算平台。测试效果表明,在底层硬件资源足够的前提下,效率提升已接近理论最优值上限,可将单个甚至多个方式多个故障的仿真耗时缩短至单个故障的仿真耗时,为新型电力系统海量运行方式的计算仿真提供了强力的工具支撑。
基于本文所建设的平台,可为大电网仿真提供海量任务的快速并行计算分析和远程云计算服务,满足总调、中调及地调各层面以及其他应用系统的计算分析需求。同时,在线计算为闭环的数据管控、共享的数据管理提供了基础分析工具,为其他应用系统提供了可靠、高效的计算服务。基于云计算共享的电力系统计算分析平台与另行建设的共享数据管理平台,将在互联网新技术的协助下,全面提升对电网的把握能力,保障新型电力系统的安全可靠运行。
猜你喜欢
民用飞机设计与研究(2020年4期)2021-01-21
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年18期)2018-11-14
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
商用汽车(2016年11期)2016-12-19
山东工业技术(2016年15期)2016-12-01
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
