
基于DBSCAN和CNN算法的重型车辆NOx排放预测模型
2022-09-01 07:04杨志刚
重庆交通大学学报(自然科学版) 2022年8期
余 舒,杨志刚
(1. 宁波吉利汽车研究开发有限公司,浙江 宁波 315000; 2. 陕西汽车控股集团有限公司, 陕西 西安 710200)
0 引 言
随着城市机动车保有量的不断增加、城市交通拥堵问题的日益加剧, 机动车尾气污染日益严重。对此,国家的排放法规日趋严格,国六排放标准即将全面实施。目前,满足国六法规的重型车辆,其排放后处理技术,基本采用废气再循环(exhaust gas recirculation,EGR)结合氧化催化器(diesel oxidation catalyst,DOC)、颗粒捕集器(diesel particulate filter,DPF)、选择性催化还原(selective catalytic reduction,SCR)一体化的后处理技术手段。同时,在排气EGR后,安装排气节流阀和前NOx传感器,DOC催化器前后分别安装温度传感器,DPF前后安装压差传感器,SCR催化器前后分别安装温度传感器、Urea喷嘴以及后NOx传感器,上述催化器、传感器以及控制器等装置设备通过耦合作用,形成一套整体的柴油车后处理系统,共同完成重型车辆尾气净化的功能[1-3]。
在复杂的后处理系统中,当Urea喷射不合理时,不仅会降低SCR系统性能,还会对环境造成二次污染,而SCR催化器的前、后NOx传感器在其中发挥着监测排放和反馈控制的作用。X.YUAN等[4]研究了SCR系统Urea喷射,采用开环控制策略,依据发动机转速、扭矩和NOx原机排放脉谱图,计算不同车辆工况下的Urea喷射量,并利用催化器温度、排气流量、前后NOx浓度等关键状态参数进行喷射量修正,使SCR系统运行在最佳的性能区间,保证尾气排放符合要求;X.SHI等[5]基于PID控制器,依据SCR系统下游的NOx浓度值、NH3泄露量和发动机的实时排气流量,实现Urea溶液喷射量的精准控制;Y.YUJI等[6]和P.CHEN等[7]利用自适应控制算法,基于发动机工况、催化器温度、废气流量确定基本喷射量,实现SCR系统喷射量随环境变化和扰动的自适应控制。
笔者采用改进的机器学习算法:动态时间弯曲(dynamic time warping, DTW)-密度聚类算法(density-based spatial clustering of applications with noise, DBSCAN)、嵌入误差反馈的卷积神经网络(eCNN),结合重型车辆的15项参数和变量,构造重型车辆的原机NOx排放预测模型,应用于重型车辆的后处理SCR系统。通过嵌入预测模型的后处理控制器,作为替代系统入口处前NOx传感器,为后处理系统的降本增效提供基础支持。
1 数据集和预处理
重型车辆运行过程中,产生的变量参数多、样本数量大,为构建合理的车辆排放预测模型,利用相关性分析从海量参数中筛选出与排放相关的变量;利用降维分析-主成分分析减少模型变量的维度,采用聚类分析处理相似数据,降低样本数据量的大小。通过上述统计分析及机器学习算法,构造模型的训练和测试数据集,以得到准确有效的车辆NOx排放预测模型,实现替代后处理系统入口处的前NOx传感器,具体方案如图1。
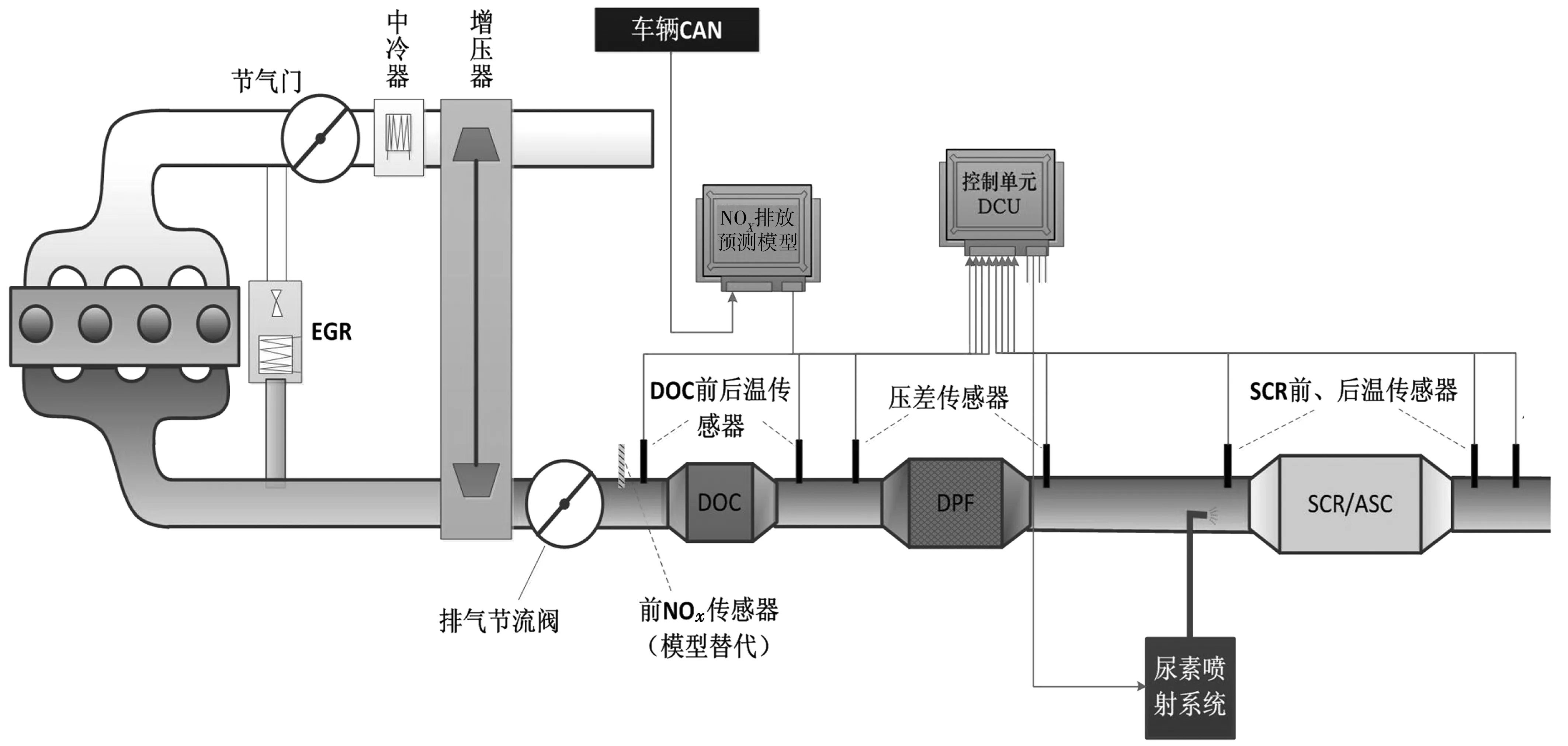
图1 预测模型的替代方案Fig. 1 Alternative to predictive model
1.1 数据样本
采集的原始样本数据来源于200辆不同系列的重型商用车,时间跨度为3个月,数据规模约为2 000万条。在采集的原始数据样本中,不同传感器或不同来源的变量数据间存在时间标签错位问题,需在数据集成时针对数据时间标签进行对齐处理。
同时,采集的车辆参数需要通过转换处理,衍生为与车辆或道路环境相关的变量参数,如:档位传动比和桥速比转换为车辆实时档位;GPS信号转化为道路坡度信号;车辆迎风面积和整车质量等参数转换为车辆比功率(vehicle specific power,VSP)等。通过参数转化,将采集的车辆参数转变为更贴合车辆特性的变量参数,部分参数转换方法如图2。

图2 衍生参数计算逻辑Fig. 2 Calculation logic diagram of derivative parameter
1.2 数据预处理
通过采集和衍生,用于构造模型的数据样本体量更加庞大,需要利用合理的数据预处理方法,缩减数据样本量,构造模型的训练和测试数据集。采用的数据预处理方法包括:变量相关性分析、降维(主成分)分析、聚类分析。
1.2.1 变量相关性分析
在车辆的可采集参数中,主要分为道路环境参数、发动机参数、车辆参数,这些参数主要包括:空气温度、空气湿度、经纬度、海拔、道路坡度、道路类型、发动机转速、发动机扭矩、发动机排气流量、车辆速度、车辆加速度、车辆油耗、车辆档位等。其中,一部分参数对车辆NOx排放的影响已在其他研究中得到原理性的验证,如:发动机转速、发动机扭矩、空气温度、空气湿度、车辆油耗等[8];另一部分参数与车辆NOx排放的影响关系未知,需要应用合适的方法进行分析,以筛选出用于构建模型的特征参数。
若通过单因素变量的原则逐一分析车辆参数与NOx排放的影响关系,会面临众多变量难以有效控制的问题,且数据集庞大,难以快速简洁筛选出数据集以得到影响关系。为此,利用皮尔逊(Pearson)和斯皮尔曼(Spearman)相关系数,分析各车辆参数对原机NOx排放的影响关系。当Pearson和Spearman系数的绝对值越接近1,则此变量对NOx排放相关关系越强;当系数取值在0.7以上,变量间的相关性较强;当相关系数数值越接近0,则表示此变量对NOx排放的影响微乎其微[9]。
依据Pearson和Spearman相关系数的计算公式,如式(1)、(2),计算车辆档位、车辆加速度、道路类型、道路坡度、排气流量、VSP[10]与车辆行驶过程中的NOx排放的相关性,据此评价各参数与NOx排放间的影响关系,相关系数的绝对值结果如图3。
(1)
(2)
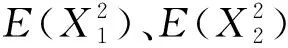
由图3可知:在未知影响的车辆参数中,排气流量与NOx的相关性系数均较小,表明其对重型车辆的NOx排放影响不明显;车辆档位、加速度、道路坡度和VSP的Pearson相关系数不大,但Spearman系数均处于0.7以上,说明上述参数与NOx排放存在强相关性;道路类型与NOx的Spearman相关系数大于0.6,表示道路类型与NOx排放存在一定相关性。
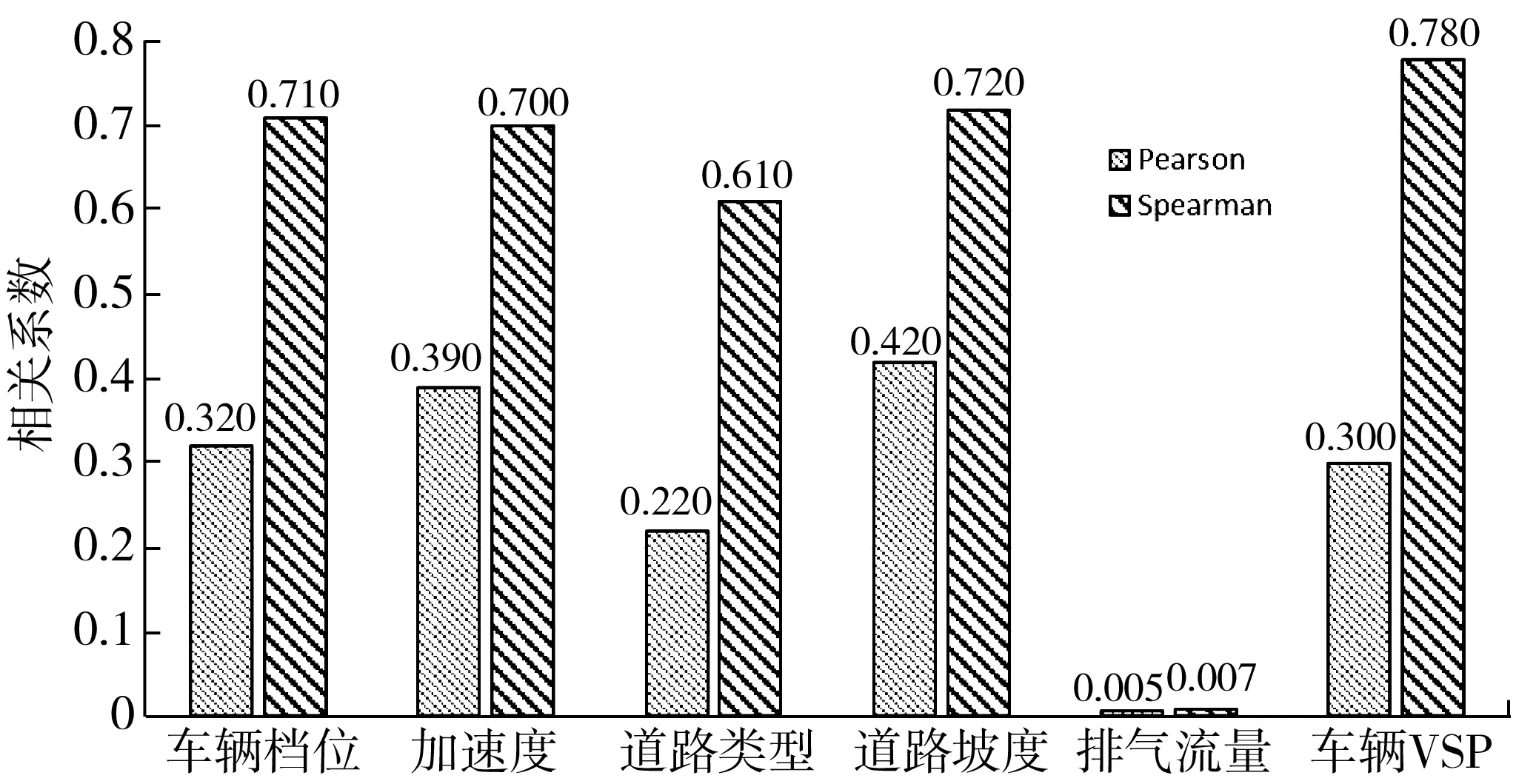
图3 各车辆参数与NOx的相关系数Fig. 3 Correlation coefficient between various vehicle parametersand NOx
依据变量相关性分析,在繁杂的车辆参数中,筛选出NOx排放预测模型的有效输入变量参数,包含:发动机转速、发动机扭矩、车辆速度、车辆加速度、车辆油耗、道路坡度、道路类型、车辆档位、车辆VSP,构成建模分析的训练集和测试集。
1.2.2 主成分分析
在车辆采集参数中,与NOx排放存在相关性的参数较多,但相关参数间也存在较强的相关关系,参数间存在大量重复信息。如直接利用变量参数的数据集构造模型,会因为多重共线性问题降低模型预测精度。为解决变量多造成的复杂性和共线性的问题,需找到新的评价参数,代替数量较多的原有特征参数,用更少的新变量集来尽可能的反映原始变量信息,在简化的基础上更好的解释问题。
主成分分析作为统计分析中数据化简和信息浓缩的主要方法,可将多个变量中的同类信息集中、提纯,减少变量个数的同时,更好的解释和利用变量中的数据信息。此方法可从NOx排放相关的多个变量中,提取出能表征原始变量参数特点且互不相关的主分量,用于揭示NOx排放的实际影响因素。在实际应用中,通常只选取前几个方差最大的主成分,虽然损失了部分信息,但提取的绝大部分变异信息已足够分析问题,既减少了变量数目,又抓住了问题本质。
依据式(3)的主成分分析的数学模型,结合主成分分析的原理,得到式(4)、式(5):
(3)
(4)
(5)
式中:Fi为第i个主成分;Xi为原始数据的集合;Zi为第i个主成分;li为X对应的单位特征向量;S为X的样本协方差矩阵;XT为原始数据矩阵的转置。
原则上,如果有n个原始变量,就可以提取出n个主成分,但是如果将它们全部提取出来,就失去该方法简化变量的实际意义。一般是按照累计贡献率的大小取主成分因子,当提取的多个主成分因子的累计贡献率达到90%,表明提取的因子已包含足够多的原始数据信息,其他的变量对因变量的影响较小,可以忽略不计。
针对上述众多参数变量的数据集进行主成分分析,得到的主成分因子1~9的累计方差贡献率如表1。

表1 主成分的累计方差贡献率Table 1 Cumulative variance contribution ratio of principalcomponents
按照主成分分析计算的累计贡献率可知,因子1~4的累计方差贡献已达到90%以上,表明因子1~4已包含原始9个变量参数的大部分信息,据此可推断出,影响NOx排放的最佳主成分因子为因子1~4。
主成分因子1~4确定后,结合式(3),通过变量的样本数据计算主成分得分矩阵,构造各车辆参数与主成分因子之间的数学表达式,模型表达式的部分结构如式:
(6)
依据主成分的数学模型,可以将9个存在相关关系的车辆参数转换为4个互不相关的主成分因子,将其作为车辆NOx排放预测模型的直接输入变量参数。
1.2.3 DTW密度聚类
车辆参数的数据基本以时间序列形式存在于数据库中,且车辆行驶产生的时序数据中存在较多的相似性特征,如:车速相同、发动机工况相同、加速度相同、油耗相同、道路坡度相同等。针对数据特点,拟采用聚类算法对数据进行离散化预处理,消除时间参数对模型的影响,考虑到各序列段的数据长度不一致,引入动态时间弯曲距离(dynamic time warping,DTW)作为序列片段的相似性类别判断依据,据此筛选出合理的训练集,作为车辆NOx排放预测模型的输入集合。
密度聚类(DBSCAN)是基于空间密度的聚类算法,使用“领域”概念来描述样本分布的紧密程度,将有足够密度的样本区域划分为相似的类别,此算法不需要人为预先确定聚类数量,能有效解决聚类数量不合理导致的误差;DTW算法,用于计算评估不同长度样本序列间的距离,能有效解决车辆参数中相似特征样本的数据段长度不同的问题。
结合两种算法优点,使用DTW-DBSCAN算法,通过DBSCAN确定有效的聚类中心,通过DTW算法的距离作为相似类别划分的依据,计算更佳的聚类结果以构造合理的模型训练样本。此聚类算法的逻辑流程如图4。
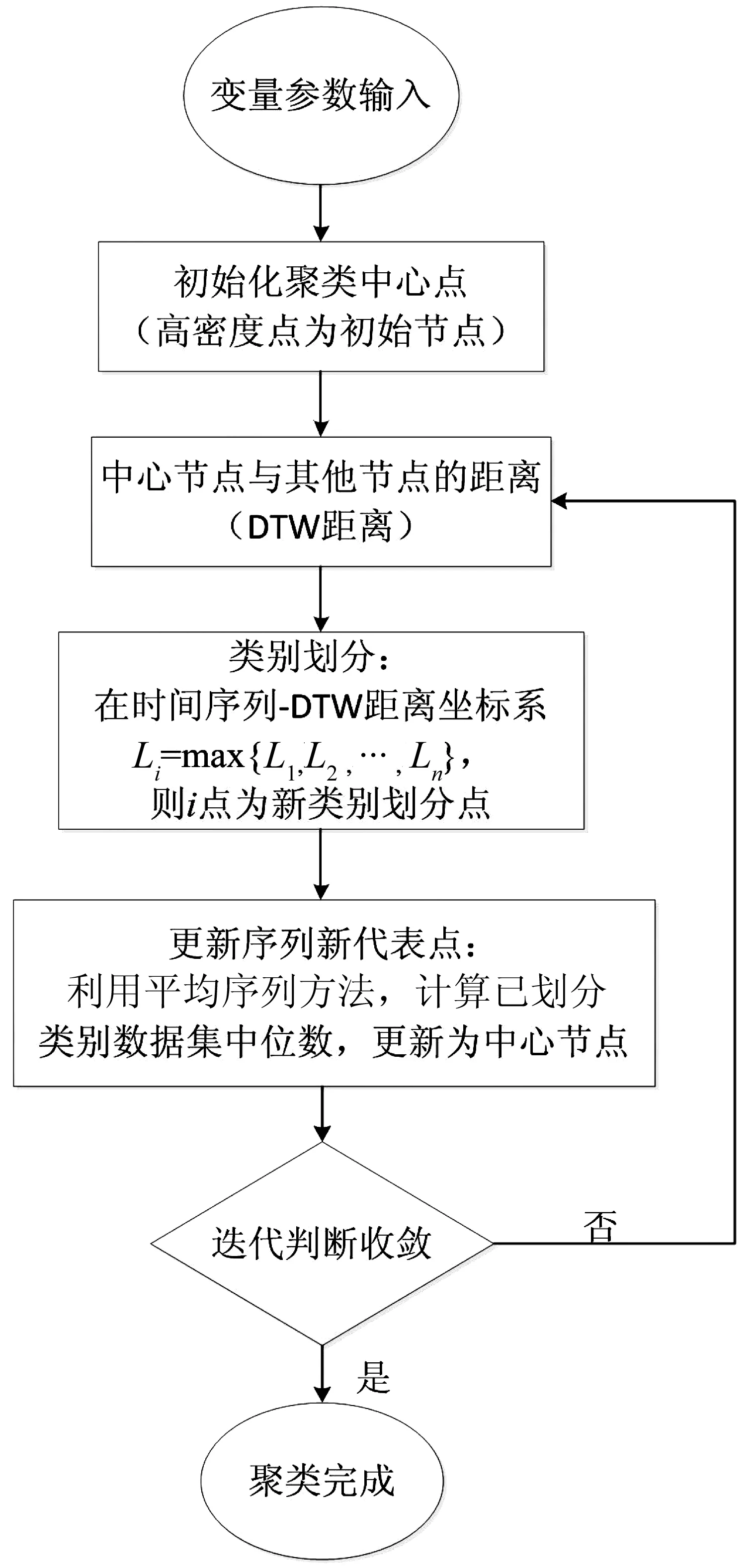
图4 DTW密度聚类算法的流程Fig. 4 The flow chart of DTW and DBSCAN algorithm
综合上述数据预处理算法,经过主成分降维、DTW密度聚类等机器学习算法,将原始数据集样本划分为不同类别,最终形成变量维度低、数据样本精炼的模型训练数据集,用于后续预测模型训练。
2 预测模型及结果分析
原始数据样本经1.2节预处理后,形成多个不同类别的数据片段集合,各集合中的序列片段均视为输入矩阵,利用卷积神经网络(convolutional neural networks,CNN)的“黑箱”模拟出输入与输出之间映射模型。预处理后的数据样本,80%作为模型的训练集,利用训练集构造模型,利用另外20%样本数据,进行预测模型的测试验证,比较模型预测值和实测值。依据NOx排放模型预测的精确程度,分析模型用于替代后处理系统NOx传感器的可行性。
2.1 eCNN预测模型
eCNN模型,即在卷积神经网络中,引入具有一定独立性的误差反馈神经元,以此来计算输出误差,修正最终输出,改进模型在NOx排放突变情况下的收敛速度和预测精度。eCNN模型的结构包含:输入矩阵、卷积层、池化层、误差反馈单元、输出层共5个层次,如图5。
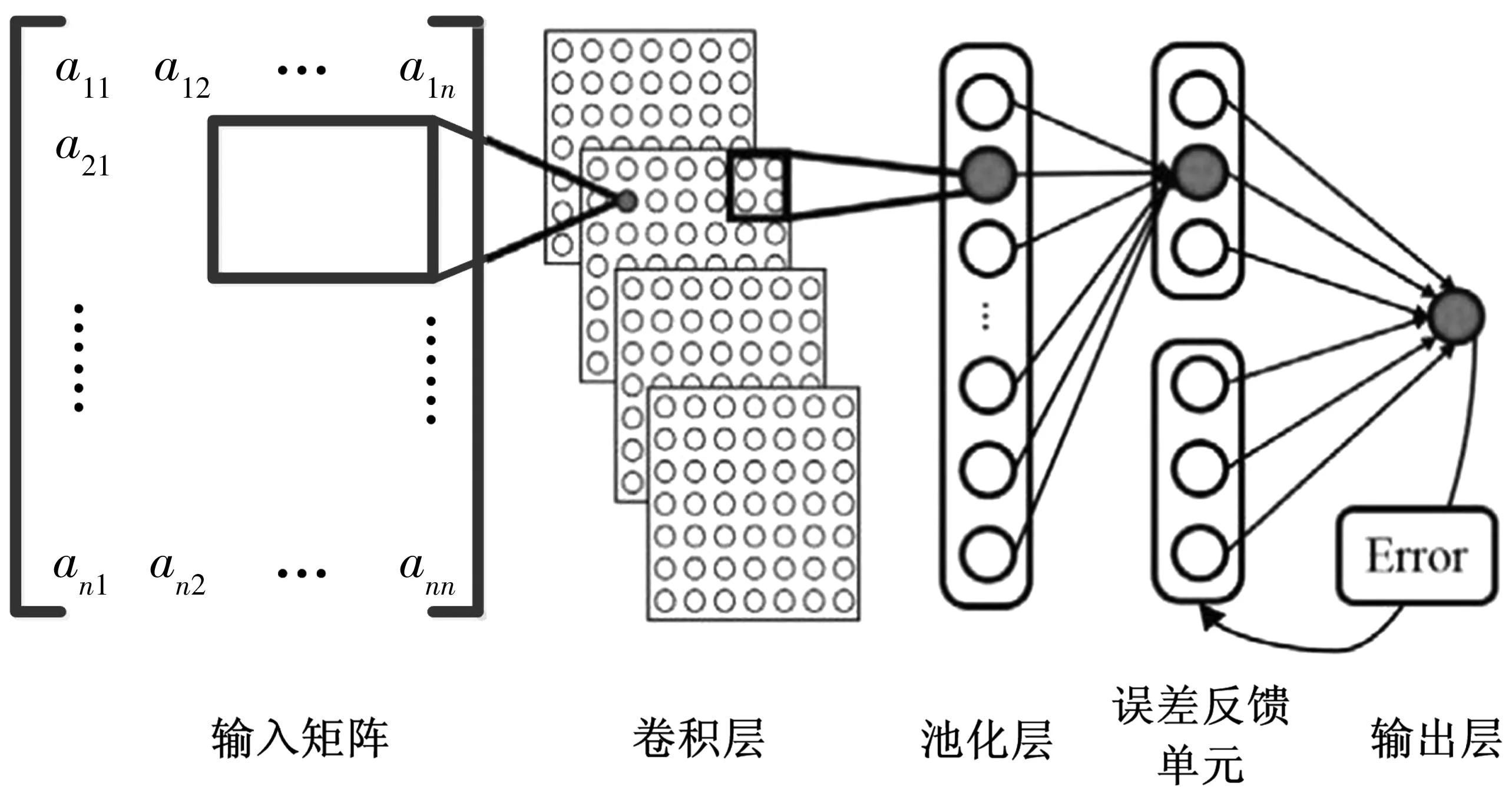
图5 eCNN算法结构Fig. 5 The structure of eCNN algorithm
输入层将预处理后的主成分数据和信息转化为矩阵,用于卷积层进行特征提取;卷积层和池化层通过卷积核、平均池化原则,提取出各车辆主成分参数的特征;误差反馈单元利用相同类别中上一次输出的误差,来补偿修正当前输出结果,此层包含当前输出神经元和误差反馈神经元;输出层利用调整后的线性单元,预测车辆在不同状态的NOx排放浓度。
通过改进的误差反馈神经网络模型,结合数据预处理算法,构建车辆NOx排放预测模型,结构如图6。

图6 NOx排放模型计算逻辑Fig. 6 Calculation logic diagram of NOx prediction model
将利用改进的eCNN方法构建的预测模型,与1维卷积神经网络(1-D CNN)、卷积神经网络(CNN)方法构建的预测模型进行比较,分析多种模型在NOx预测方面的性能差异。利用预处理后多个类别中的数据样本,比较不同模型之间预测值的平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE),结果如图7。
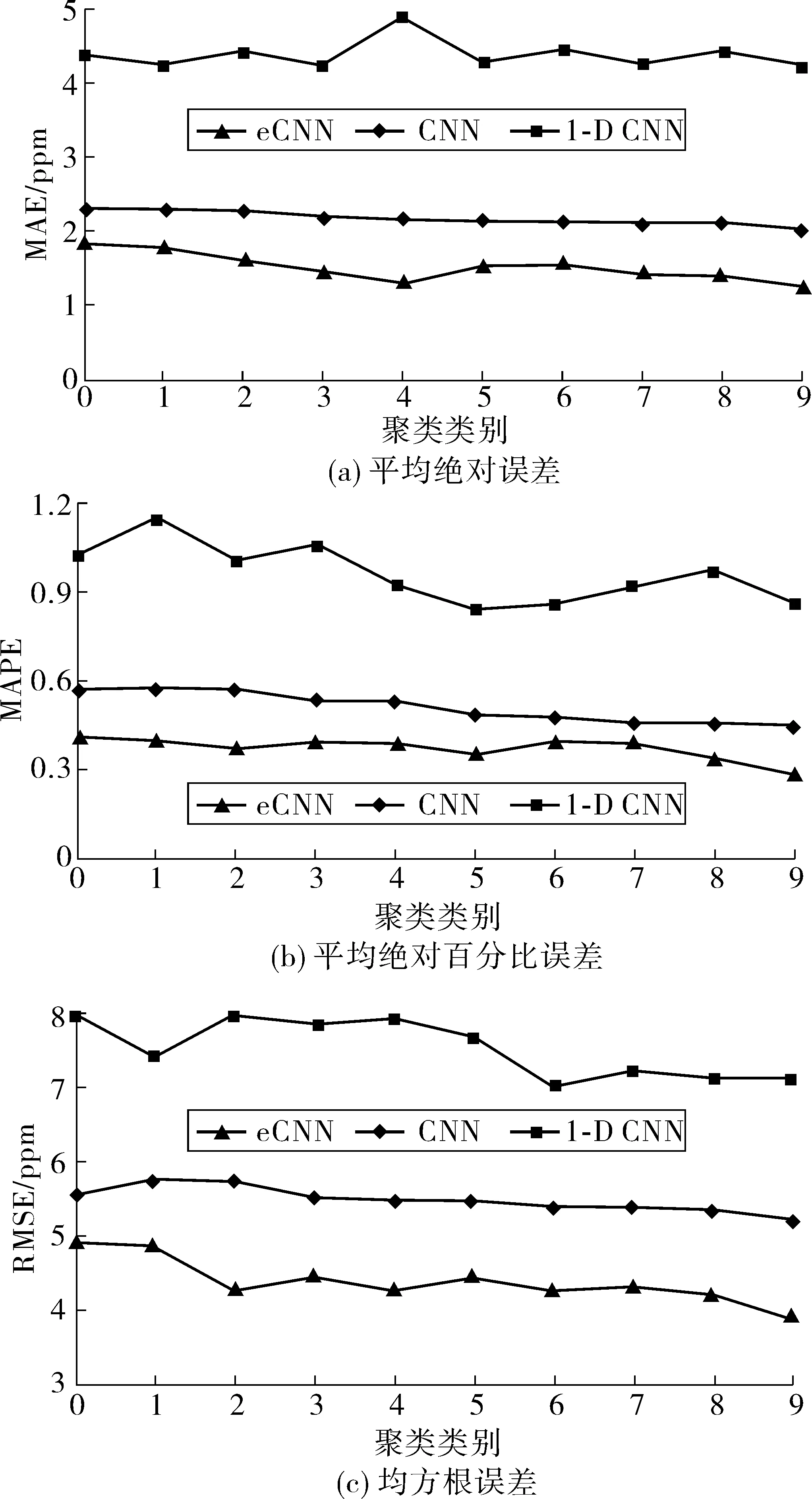
图7 不同模型的预测误差比较Fig. 7 Comparison of prediction errors of different models
由图7可知:eCNN构建的车辆NOx排放模型,其预测精度在CNN的基础上有一定改善,特别在预测时长增加后保持了更高的精度,相对于其他回归模型而言,预测精度有明显的优势。
2.2 评价指标及结果分析
笔者用于建模的样本数据为前NOx传感器的数据,且后NOx预测需考虑物理化学过程,模型复杂,暂不考虑应用于后NOx传感器。
为评价NOx排放预测模型替代系统前NOx传感器的可行性,针对预处理数据和eCNN模型构建排放预测模型,分析模型预测值与实际测量值的差异,通过不同的后处理SCR系统技术指标,分析排放预测模型的精确度和可行性。
基于不同的SCR系统控制策略:开环策略系统和闭环策略系统,选择合适的预测评价指标。
1)开环策略系统:系统的控制策略是依据车辆发动机实时工况参数和脉谱图来实现,NOx传感器实现排放监测的功能[11],不做误差反馈来修正系统参数;此时,预测模型的评价指标可为NOx排放浓度误差和NOx比排放值误差。
2)闭环策略系统:系统的控制策略是由前、后NOx传感器的实时测量值来实现[12],基于实时测量浓度值,进行系统控制策略(Urea喷射量)的反馈修正;此时,预测模型的评价指标可设定为NOx浓度误差、Urea喷射量误差和NOx比排放误差。
2.2.1 开环策略系统指标分析
在实施开环控制策略的后处理SCR系统中,NOx传感器仅监测处理后NOx排放是否达标。为验证模型预测精度,针对NOx浓度和衍生的NOx原机比排放2个数据,分析模型预测值与实际值的差异,计算模型的拟合优度,评价模型精度与可行性。
依据预处理数据和eCNN模型构建的预测模型计算NOx浓度值,并与传感器的实测浓度进行比较,差异如图8。

图8 模型预测浓度值与实测值差异Fig. 8 Difference between the predicted concentration value of themodel and the measured value
由图8可知:NOx预测模型的浓度预测值基本接近传感器的实际测量值,两数值的最大绝对误差小于50 ppm,相对误差百分比保持在2%以内。分析模型的拟合情况,由式(7)计算RMSE为4.3,RMSE的数值较小表明模型的拟合效果较好,可用于重型车辆的原机NOx排放预测。
(7)

在开环系统中,为探究浓度值差异对后处理系统的影响,可依据NOx浓度衍生的NOx比排放值作为评价指标。NOx比排放值,是指发动机输出单位功率下产生的污染物气体质量,主要用于评价车辆行驶时的排放水平,计算如式(8)(欧洲稳态循环,ESC[13])。
(8)
式中:λNOx为NOx的比排放值;ρNO, i为第i个工况点的NOx浓度值;qi为第i个工况点的流量;Pi为第i个工况的功率。
依据NOx排放预测模型和NOx传感器的测量值,利用公式计算车辆比排放值,传感器测量的比排放为:9.49 g/kWh,预测模型输出的比排放为:9.38 g/kWh,两比排放值的绝对误差为0.11 g/kWh,相对误差为1.16%,这说明:在车辆NOx排放水平的评估上,排放预测模型与NOx传感器测量的差异较小。
在实施开环控制策略的后处理系统中,排放预测模型可准确模拟前NOx传感器的测量信号,实时计算SCR系统的转化效率,结合后NOx传感器测量数据,分析尾气处理水平和催化器性能。
2.2.2 闭环策略系统指标分析
后处理SCR系统实施闭环控制策略,即传感器的测量值进入控制器中参与后处理系统决策,此时用NOx排放预测模型代替传感器,则需验证模型输出浓度值对后处理SCR系统决策的影响。因此,闭环系统的评价指标包含:浓度值误差、Urea喷射量误差、NOx比排放误差。
采用闭环策略的SCR系统,预测模型的NOx浓度值与传感器的测量值见图9。
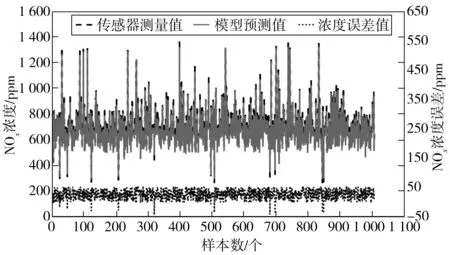
图9 闭环SCR系统的预测值与实测值差异Fig. 9 Difference between predicted value and measured value ofclosed-loop SCR system
由于NOx浓度值会影响SCR系统的Urea喷射量和NOx比排放值。为验证影响程度,基于闭环控制策略的SCR系统中,将NOx浓度值带入SCR系统的仿真模型,计算在相同工况和不同NOx浓度值下的Urea喷射量,如图10;结合SCR催化器的物理化学模型,筛选出对应WHSC(世界统一稳态循环)的工况点[14],计算SCR系统在催化前、后的NOx比排放值,如图11。比较不同浓度下的评价指标的差异程度,分析NOx预测模型替代前NOx传感器的可行性。并比较预测模型和传感器输出NOx浓度值的差异对Urea喷射量和比排放的影响。
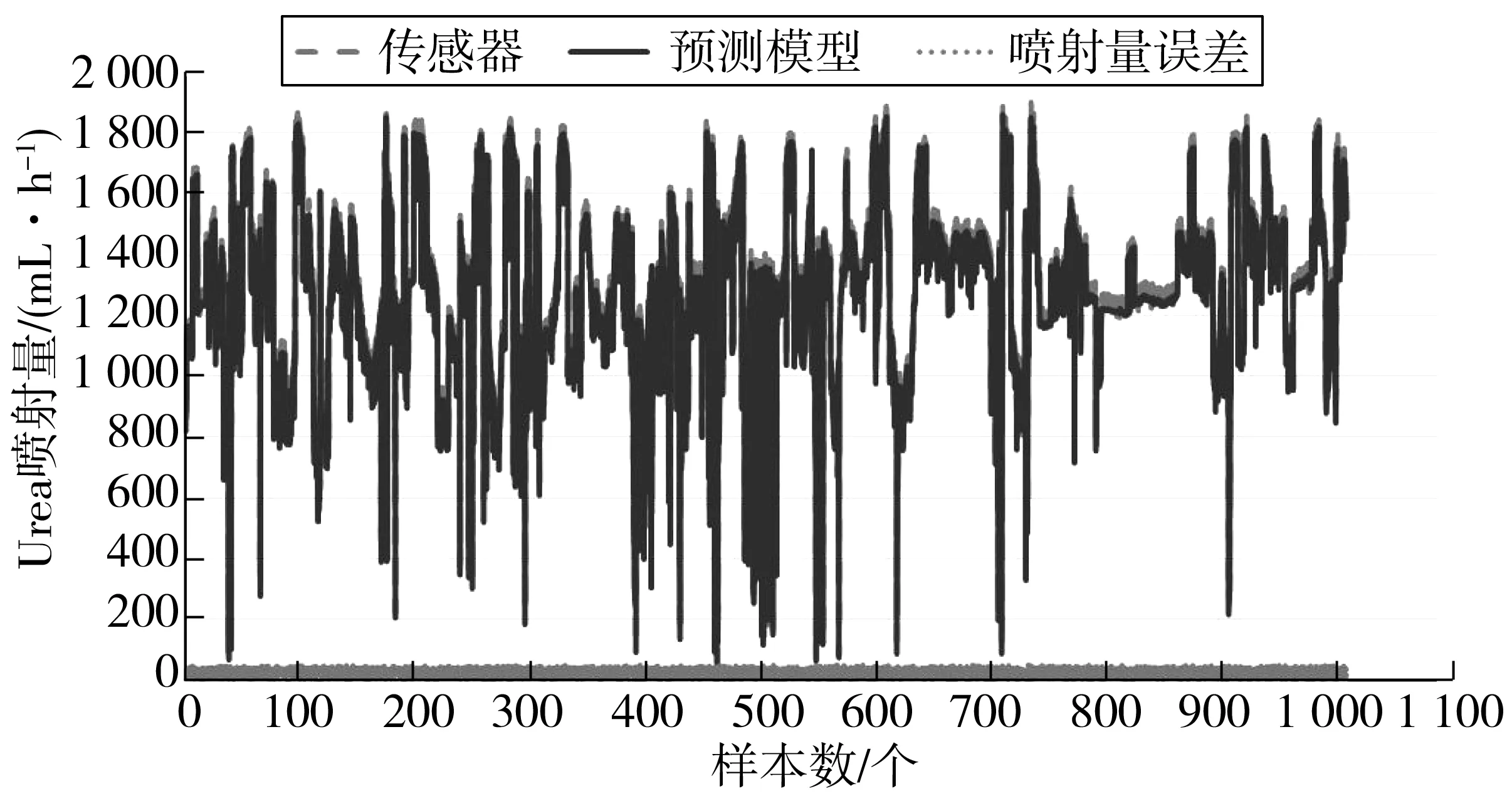
图10 Urea喷射量差异Fig. 10 Difference of Urea injection volume
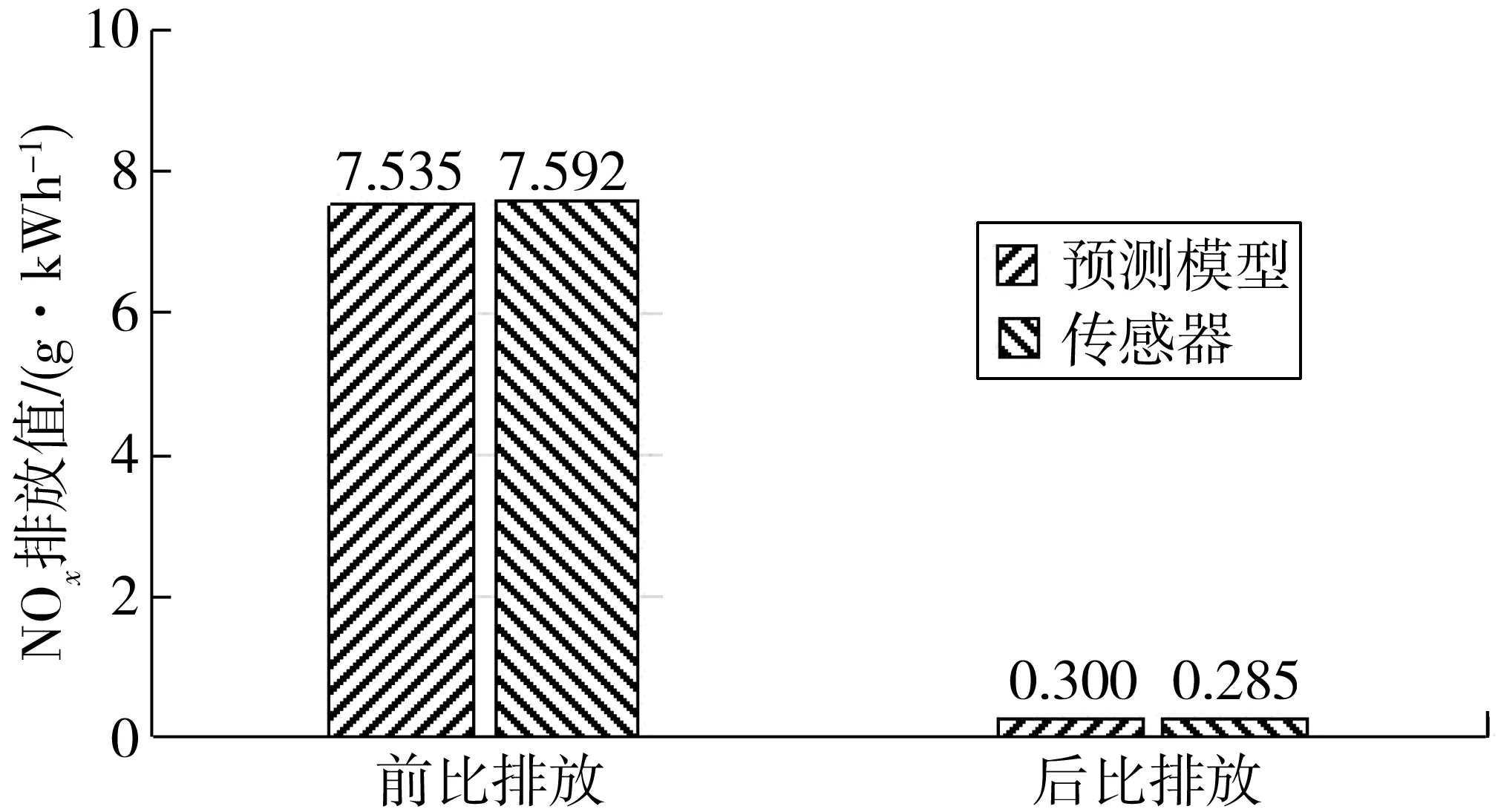
图11 NOx比排放的差异Fig. 11 Difference of NOx specific emission
由图10可知:两种方式的NOx浓度平均差异为2.46 ppm,最大误差不超过50 ppm,相对误差低于3%;与此同时,闭环系统的Urea喷射量是基于NOx浓度来决策的,依据仿真计算结果,Urea喷射量的差异也较小,平均误差为25.96 mL/h,最大误差保持在49 mL/h以内,平均相对误差为2.08%。
由图11可知:由于两种方式的NOx浓度平均浓度、Urea喷射量均差异较小,导致系统的NOx比排放值误差也较小,替代后前NOx比排放相差约0.06 g/kWh,相对误差较小,为0.75%;利用模型代替前NOx传感器,实现尾气排放处理后,比排放增加0.015 g/kWh,此时的比排放值为0.30 g/kWh,车辆的尾气排放符合法规要求。因此,利用预测模型代替前NOx传感器对后处理系统的性能影响较小。
在应用闭环控制策略的后处理系统中,排放预测模型的预测精度较高,可替代后处理系统中的前NOx传感器,输出合理NOx排放值,可确保Urea喷射量的精确控制,能实现后处理系统清洁尾气的功能,并满足国家的排放法规要求。
3 结 语
利用改进的数据预处理算法和eCNN,基于200辆重型车辆营运3个月的实际行驶数据,构建重型车辆后处理系统的NOx排放预测模型。
通过不同类型系统的评价指标:NOx浓度值、Urea喷射量、NOx比排放值,分析NOx排放模型预测值与传感器的差异。结果表明:NOx排放预测模型的预测浓度与传感器实际测量浓度误差低于3%,系统的尿素(Urea)喷射量的变化小于2.08%;NOx的比排放变化保持在0.75%以内;利用预测模型替代传感器的后处理系统与利用传感器的系统之间差别较小。
在应用开环、闭环控制策略的后处理系统中,嵌入NOx排放预测模型,可替代后处理系统的前NOx传感器,保证SCR系统的性能仍满足法规要求,此方式能精简后处理系统,有效降低硬件成本。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19
教育周报·教研版(2021年47期)2021-12-19
现代仪器与医疗(2021年4期)2021-11-05
中学生数理化·高三版(2016年9期)2016-05-14
化学教学(2015年4期)2015-06-18
汽车工程学报(2015年1期)2015-04-13
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
中学生数理化·高一版(2009年6期)2009-08-31
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
