
基于线程池的社交网络影响力最大化
2022-08-31 00:54贾苏符精晶张君
电脑知识与技术 2022年19期
关键词:社会网络
贾苏 符精晶 张君


摘要:互联网的发展也带动了社会网络的发展,但社会网络规模较大,网络结构较为稀疏,都给实际应用带来了挑战,且单线程算法对算力的使用不充分,因此在单机上开展了对算法并行化研究,使用线程池技术,通过实验证明减少了算法运行的实际时间。
关键词:社会网络;影响力最大化;线程池
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)19-0119-03
1 引言
随着互联网的快速发展,越来越多的人开始从传统的线下社交转移到线上社交,这给社交网络[1]的发展带来了前所未有的机遇,涌现出了一批像Facebook、Twitter、QQ等知名互联网社交产品。社交网络在方便人们沟通的同时,也会影响着人们实际的社会行为,这给我们对社交网络的分析与应用带来了机遇,比如商家想要通过在线上的活跃用户的推荐获取其销量上的提升,也就是病毒式营销(virtal -marketing)[2]。病毒式营销基于具有较大影响力的个体群体向其他的个体进行推荐,感化其他不具有购买意愿的个体,因此如何找出社交网络中影响力最大的群体是病毒式营销开展的关键。
影响力最大化问题(Influence Maximization)最先由Domingos和Richardson等人[3]提出并定义,Kempe等人[4]在此基础上进一步研究,提出了top-k的影响力最大化问题,并证明了影响力最大化问题是一个NP-hard问题。并提出了一个贪心算法,可以保证在[1-1/e]的范围内接近最优解。
2 背景知识
2.1 影响力最大化问题(Influence Maximization)
将社交网络抽象为一个图[G=V,E],其中[V]是网络中个体的集合,[E]是网络中个体之间关系的集合。网络中的个体我们使用[v∈V]来代表,节点[v]的状态有两种,一种是活跃(active),在营销中表示具有购买欲望,另一种是不活跃(inactive),营销中表示不具有购买欲望。个体间的关系使用[e∈E] 来代表。网络上不同节点之间的影响力是不同的,我们使用[Pu,v→(0,1)] 代表節点[u]对节点[v]的影响力即集合E中边[u,v]上的值。
影响力最大化问题就是希望从[V]中选择k(0<=k<=|V|)个节点作为种子集合[S],种子集合中所有节点的状态均为活跃。非种子集合的节点均为不活跃。然后在扩散模型下,种子集合中的节点去激活非激活状态的节点。节点一旦激活便不再改变。我们希望最终的被激活的节点是最多的,即找到这样的一个种子集合[S]:
[S*=argmaxInf(S)]
表示种子集合S的影响力扩散的大小。
2.2 影响力传播模型-独立级联模型(Independent Cascade Model)
独立级联模型[4-6]最初是Jacob Goldenberg提出,是一个离散的概率模型。在此模型下,节点的状态分为两种,一种是激活状态,另一种是不激活状态。激活状态的节点会尝试激活不激活状态的节点,节点对节点的激活作用是相互独立的,不会累积,而且只能尝试激活一次,只能从不激活状态变为激活状态且激活之后状态不再发生改变。节点间激活状态的改变模拟了信息的传播,在此传播模型下,连续的信息传播被分解为独立、离散的过程,也更有利于分析统计。
Kempe首次使用独立级联模型作为影响力传播的模型,节点激活的状态代表节点被影响力影响了,处于非激活的状态代表此时节点尚未被影响。此模型下的影响力传播过程如下:
初始时刻[t=0], 网络中只有种子节点处于激活状态,其余非种子节点处于未激活状态。
在任意时刻[t>0] , 任意一个[t-1]时刻被激活的节点[u]有且仅有一次机会以概率[puv]去尝试激活它的每一个处于非激活状态的邻居[v]。[puv]是节点[u]和[v]边上的传播概率。
如果存在多个处于激活状态的节点同时尝试激活它们的共同邻居节点[v],按照独立级联模型的定义,节点间的激活顺序是独立的,那么这些节点以随机且独立的顺序去尝试激活[v],一旦激活,节点[v]的状态即改变,不再受其他节点的影响。
在[t]时刻被激活的节点,会在[t+1]时刻也尝试激活其邻居节点。
重复上述过程,直到某一个时刻网络中不再有新的节点被激活,影响力传播过程终止。此时,网络中被激活的非种子节点数就是此种子集合影响力的规模。
3 影响力最大化算法及其多线程实现
影响力最大化的贪心算法如下:
其中[InfS?v] 为种子集合加入节点[v]之后的影响力规模,为了准确地度量,我们使用Monto-carlo模拟来模拟影响力扩散的过程。由于每加入一个节点都需要多次的模拟,所以造成了算法所需要的时间很高。解决此问题有两种思路:第一种是对其算法进行一定的改进,第二种是使用并行化手段完成算法的运行。
为了缩短算法运行所需要的时间,我们使用了多线程技术。针对当前机器核心数为4,我们使用了大小为4的线程池,其中每一个线程都去度量在当前种子集合的影响力大小,使用Callable接口去持有线程返回的结果。筛选出具有最大增益的非种子节点后更新种子集合,完成此轮种子节点选择。线程池的使用可以降低传统多线程创建和销毁带来的开销,并对线程进行了统一的分配和监控,处理大量计算任务时其优势更加明显。
使用线程池具体代码如下:
private Set
// 线程池
ExecutorService threadPool = Executors.newFixedThreadPool(4);
// 初始化非種子节点
noseeds.addAll(fromNodes);
for (int i = 0; i < k; i++) {
Map
int ca_c = 0;
for (Integer candidate : noseeds) {
if(edges.get(candidate).size() == 0) //当节点->目的节点的个数不为0
continue;
int count_Once = 0;
for (int j = 0; j < 100; j++) { // monto_carlo
Callable
// 执行任务并获取Future对象
Future
while (!f.isDone()) { // no execute end loop it
//System.out.println(" In while");
}
count_Once += f.get(); // spread的累加
} //end for
candidate_Spread.put(candidate, count_Once);
}
// refresh seeds
Optional
.max(Map.Entry.comparingByValue());
// 这里避免了每次都加入具有最大值spred值的candidate
if (!seeds.contains(max_vlu.get().getKey())) {
seeds.add(max_vlu.get().getKey());// 更新seeds
noseeds.remove(max_vlu.get().getKey());// 从noseeds中删除当前种子
}
}
return seeds;
}
4 数据集以及实验结果
4.1 数据集及实验相关设置
本文选择了DBLP数据集和LiveJournal作为实验的数据集(来自:http://snap.stanford.edu/data/com-DBLP.html)。DBLP是一个关于科研论文发表共同作者的网络,其中如果两位作者至少发表一篇论文,则可以将他们联系起来,即将作者看成是社交网络中的节点,联系则是节点间的边。LiveJournal是一个拥有近1000万会员的免费在线社区,它允许成员维护日志、个人日志和组日志,并且允许人们标记其他成员是他们的朋友。数据集的具体的拓扑信息如表2所示:
实验代码使用Java进行编写,运行于Windows10机器上,处理器为I5 9500,内存8GB。实验中使用独立级联模型(IC)作为影响力传播模型。为了保证实验结果的准确性,我们设置蒙特卡洛模拟的次数[R=2000],这个过程也是实验中最为耗时的过程,为了缩短运行所需要的时间,我们在这个过程中加入了多线程。
4.2 实验结果
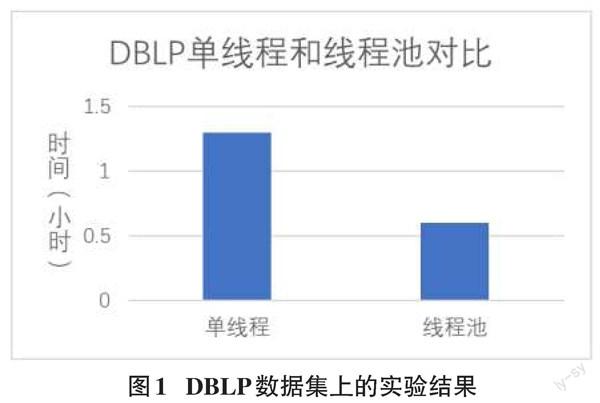
(1) 在DBLP上的实验结果
(2) 在LiveJournal上的实验结果
5 总结和展望
本文回顾了社会网络上影响力最大化的发展及在其上的应用—病毒式营销,针对影响力最大化的贪心算法做出了多线程的实现,在不影响实验结果精度的情况下,缩短了实验运行所需要的时间,并在DBLP和LiveJournal这两个真实的社会网络集合上进行了实验,将影响力最大化的贪心算法进行了并行化 ,并将实验运行时使用单线程和线程池所需的时间进行了对比。实验证明通过并行化可以减少算法运行的时间。
在企业的实际操作中,希望很快地获取他们期待的结果以供做出相对应的决策。因此,即使加入了多线程,也难以满足企业级的实时性。下一步,我们将对算法进行一定的改进以提高算法的效率,并使用服务器集群技术完成现有计算任务。
参考文献:
[1] 汪小帆,李翔,陈关荣.网络科学导论[M].北京:高等教育出版社,2012.
[2] Bass F M.A new product growth for model consumer durables[J].Management Science,1969,15(5):215-227.
[3] Domingos P, Richardson M. Mining the network value of customers[J].Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco,USA,2001.
[4] Kempe . Maximizing the spread of influence through a social network[J]. Proc.of Acm Sigkdd Intl Conf.on Knowledge Discovery & Data Mining, 2003.
[5] Goldenberg J , Muller L E . Talk of the Network: A Complex Systems Look at the Underlying Process of Word-of-Mouth[J]. Marketing Letters, 2001, 12(3):211-223.
[6] Goldenberg J, Libai B, Muller E. Using complex systems analysis to advance marketing theory development: Modeling heterogeneity effects on new product growth through stochastic cellular automata[J]. Academy of Marketing Science Review,2001,2001:1.
收稿日期:2021-09-18
基金项目:沙洲职业工学院青年教师基金(SGJJ2021B09)
作者简介:贾苏(1993—),江苏宝应人,男,沙洲职业工学院电子信息工程系助教;符精晶(1994—),江苏江都人,女,沙洲职业工学院电子信息工程系助教;张君(1986—),江苏张家港人,男,沙洲职业工学院电子信息工程系助教。
猜你喜欢
新闻世界(2017年1期)2017-01-20
预测(2016年3期)2016-12-29
商场现代化(2016年22期)2016-10-18
人民论坛(2016年8期)2016-04-11
