
视觉手势识别的移动机器人手势控制系统设计
2022-08-30 09:11龙樟卢成娅李国鹏张维烈温飞娟李波
机械科学与技术 2022年8期
龙樟,卢成娅,李国鹏,张维烈,温飞娟*,,李波
(1. 西南石油大学 工程学院,四川南充 637000; 2. 西南石油大学 信息学院,四川南充 637000)
手势控制作为一种新型的交互方式,具有表达内容丰富、控制方便、快捷等特点,在娱乐行业得到了初步的应用[1],在机器人的控制方面也具有较强的实用性。目前手势控制主要分为基于数据手套为输入设备的手势控制和基于视觉设备为输入设备的手势控制[2-3]。基于数据手套为输入设备的手势控制通过检测手指的弯曲、手部的力觉反馈来模拟出人手所表达的信息,从而获得控制信息,其接触式检测方式限制了手势的丰富性及自然性。基于视觉检测的手势控制通过视觉识别技术以非接触的方式获取手势信息,使操作者拥有更好的操作体验,受到了国内外学者的青睐,且数据手套设备价格昂贵,使得数据手套的手势控制方式近年来逐渐被淘汰。
基于视觉检测的手势控制关键技术在于手势的识别。早期视觉手势识别依赖于在人手部涂抹或粘贴便于识别的颜色或形状的标记,通过视觉识别标记实现手势的识别[4],该方法由于标记数量及质量受限,难以识别丰富的手势。随着视觉技术的发展,无标记的视觉手势识别成为了当前的主流,通常意义上的基于视觉的手势识别就是无标记的视觉手势识别(后述未特殊说明都为无标记的视觉手势识别)。
视觉手势识别的主要流程包括:1) 图像采集:通过视觉相机采集手势图像;2) 手部检测及分割:检测手势图像中手部位置并分割出手部区域;3) 手势识别:提取手部区域图像特征,并根据特征识别出手势类型。图像采集装置主要为单目相机、双目相机及深度相机。单目相机成本较低,采集图像比较直观,由于其存在多视角性,从而影响手势识别的准确率[5];双目相机获得的手势信息更丰富,但需要进行相机校准以及畸变矫正,计算量相对较大,手势图像成像质量影响因素较多[6];深度相机除获得图像彩色信息外还可直接获得对应像素位置深度信息,避免了立体视觉的计算环节,但其硬件成本相对较高[7]。手部检测与分割常常采用形状、肤色、深度及运动等信息[8]。图像识别方法主要有模板匹配法[9]、状态转移图模型法[10]、统计学习法[11]以及神经网络法[12]。其中基于卷积神经网络的深度学习方法在图像识别中因识别准确率高成为了目前核心方法,也是手势识别的主要方法之一,但其随着网络层的增加对处理器的要求也较高,甚至需要采用GPU并行计算[13]。
目前国内外学者初步研究了手势控制在无人机、机械臂控制中的应用[14-15]。从国内外现有研究可知,目前视觉手势识别在要求精度下往往对硬件要求高,手势控制在移动机器人控制方面尚缺相关文献论述。为了实现移动机器人控制人机交互的智能化、多功能化以及低成本、普适性,本文基于普通USB摄像头、一般性能的个人电脑设计了一种视觉手势识别的移动机器人手势控制系统。该手势控制系统采用VGG16卷积神经网络模型构建了手势识别模型,实验验证了该控制系统工作稳定,能够高效、准确的识别手势命令并控制机器人运动。
1 总体系统结构
本文采用麦克纳姆轮搭建全向四轮移动机器人平台,其运动灵活性强,具有较大的应用场景,移动机器人平台如图1所示。

图1 移动机器人平台
手势控制系统包含手势识别图像处理及电机控制两个部分,视觉图像处理对处理器性能要求较高,而电机控制对处理器性能要求低,考虑整体控制性能,采用实时性较好、适用于高精度及高速度控制的主从控制方式。上位机负责手势识别,下位机负责机器人运动控制,上位机与下位机之间通过TCP协议进行WIFI无线通信。
为了满足视觉手势识别控制系统的普适性、通用性需要,在满足控制性能需要下,应尽可能减小硬件成本。因此,本文视觉处理采用普通的PC机,视觉相机采用单目USB摄像头,机器人运动控制器采用树莓派3B+上位机以PyCharm2019作为开发平台,并搭载OpenCV、Keras,下位机以Raspbian操作系统为开发环境,整个系统结构如图2所示。

图2 系统整体架构
2 手势识别框架
手势识别采用深度学习方法,为了保证识别的准确率,首先要对手势图像进行处理,再用深度学习训练的网络模型进行识别。因此,手势识别框架由手势图像预处理、深度学习网络模型训练两个部分组成。
为保证上、下位机具有高效、准确的交互控制,选用了6种最常见的手势与全向移动机器人6种最通用的运动方式,手势指令与运动方式对应关系如表1所示。

表1 手势指令与运动方式对应关系
2.1 手势图像预处理
经摄像头采集到的图像为RGB彩色图像,其色彩丰富,包含大量信息及噪声,直接对其识别处理可能导致整体处理速度降低,影响交互控制的流畅度及识别率,而手势图像一般都有明显的特征,在灰度图像下亦能满足识别需求。因此,在手势图像进行识别前,首先要对其进行预处理,包括图像灰度化、图像滤波、图像镜像。
1) 手势图像灰度化
采集到的RGB图像进行灰度化处理常用的方法有:加权平均法、分量法、最大值法等。加权平均值法是根据颜色的筛选需求及其它指标,将R、G、B这3个分量设置独立的加权系数实现加权平均,其相比分量法和最大值法能够有效地避免彩色图像灰度化处理后引起的图像失真,而且经加权平均法处理后的灰度图像还具有边缘亮度噪声少,平滑效果好的特点,为后续的图像处理提供了有利条件。因此,综合考虑选择加权平均法对图像进行灰度化处理,其图像处理表达式为
Gray(i,j)=0.114B+0.587G+0.299R
(1)
式中:Gray表示灰度图像;i,j表示图像矩阵的行和列位置;R表示红色通道;G表示绿色通道;B代表蓝色通道,3个分量前的系数代表它们被分配的权重,3个系数之和为1。
2) 手势图像滤波
针对获取的图像存在噪声,对后续手势识别效果有着直接的影响,因此需要对图像进行滤波处理。图像滤波常用方法主要有均值滤波、中值滤波、高斯滤波、高通滤波、低通滤波等。高斯滤波常被用作消除图片中的高斯噪声,由于其较好的去噪效果,被广泛应用于一般的降噪操作之中。手势图像中存在的噪声主要为高斯噪声,因此采用高斯滤波对图像进行降噪处理,模板采用5×5大小。
很多地区对农机的使用安全问题上意识比较淡薄,很多农机操作者比较粗心,不重视对农机的正确使用。还有些操作者操作水平不高,没有根据要求去操作农机。还有些操作者为了方便,会更改一些农机的安全部件,没有较好的利用,因此,经常会发生在农机操作时发生安全事故。
3) 图像镜像
为了提高交互的灵活性,使左、右手都能实现手势动作的高效识别,将手势图像进行镜像处理。本文手势图像预处理都采用OpenCV视觉库相应函数,手势图像预处理结果如图3所示。
2.2 深度学习网络模型设计与训练
手势的识别过程基于深度学习的神经网络模型进行分类、识别,其中包括手势图像数据集的制作,网络模型结构的设计,以及网络模型的训练和调优,然后利用网络模型进行手势识别。
1) 手势图像数据集的制作
制作手势图像数据集采集手势图像采用与识别手势相同的USB摄像头,通过设置一定的时间间隔对摄像头捕捉到的视频进行图像截取。
在手势图像数据集的制作程序中设置了2个按钮和2个窗口,2个按钮分别负责图像的截取和手势灰度图像的保存,2个窗口分别显示摄像头获取的原始图像和手势灰度图像,如图4所示。通过设置程序的窗口位置参数可以改变获取手势图像的位置,从而适应不同的摄像头视域位置。

图4 手势数据集制作
为获得较为理想的手势识别网络模型训练效果,将采集到的手势图像的尺寸、像素等参数设置在一定范围内,并对其正确分类后制作成手势图像数据集,如图5所示。每一种手势的图像数据集为1 500张手势图像,包括了不同手尺寸大小、不同位姿、不同背景环境的手势图像,保证了手势图像数据集的多样性,为后续网络模型训练提供丰富的数据。本文将所有的数据集按照8∶2的比例分为了用于训练的数据集和用于测试的数据集。

图5 手势库的建立和分类
2) 网络模型的设计
本文深度学习采用基于CNN学习框架下的VGG网络模型,该网络模型是一个相对稳定且经典的模型,相对AlexNet网络模型对硬件要求低,相对GoogLeNet网络模型更简单[18-19]。除此之外还有很多数量庞大且复杂的网络模型,但无法满足低成本、通用性要求。VGG Net在ILSVRC Classification(图像分类比赛)中也被证明是很好的分类网络。VGG Net包含6种结构不同的网络模型,它们的相同点是每一个网络的卷积都有5组,且每一个卷积层都采用3×3的卷积核,其中C列中的conv1除外,每组卷积之后是2×2的最大池化,紧接着的是3层全连接层。本文根据手势识别的实际需求,设计了13个卷积层和3个全连接层的VGG16网络模型。
3) 网络模型的训练与调优
对VGG16网络模型进行训练与调优的流程如图6所示,主要包括:1) 读取图像文件并对图片的数据类型进行修正;2) 产生用于训练的批次;3) 定义训练模型的参数;4) 采用训练集进行训练得出初步的识别模型;5) 采用测试集进行模型检测根据检验结果进行参数调优直至满足识别要求,得到识别网络模型。

图6 网络模型训练与调优流程
在产生训练的数据前对数据进行增强操作,采用随机旋转度数,随机水平、竖直平移,随机裁剪、按比例缩放图像处理方法,增强了原始的手势图像数据集,提高网络模型的泛化能力。采用迁移学习的方法对网络模型进行训练与调优,利用上文制作的80%手势图像数据集对设计的VGG16网络模型进行训练,其余20%手势图像数据用于测试,使得VGG16网络模型中的参数学习到最佳手势特征。
由于采用的已经训练好的VGG16网络需要预测的类别有1 000种,即最后一层全连接层的输出有1 000个,与本文要求的6个手势识别结果不相符,所以仅取VGG16模型的卷积层和池化层,重新搭建一个适应输出6个手势结果的全连接层。根据测试集数据的测试结果进行模型调优,包括参数及网络结构的修改等操作,并再次进行测试,最终得到一个理想的网络模型,改进后的VGG16网络结构如图7所示。

图7 改进VGG16网络结构
4) 手势识别方法
根据手势控制移动机器人的一般实际应用场景,可以采取两种方法实现实时的手势识别,一种是根据实时拍摄到的单张图像进行手势的预测,另一种是根据实时拍摄到的视频,然后获取视频每一帧进行手势的预测。两种方法获取采集到的图像都需要进行预处理操作,进一步对其进行适当大小的调整、图片转数组的变换和归一化处理,最后利用训练优化所得网络识别模型对手势进行预测,并输出预测的结果。
在实际测试中发现,实时拍摄获取的单张图像识别准确率较高,且运行也较为流畅,但针对有手势变化的图像进行识别则较为困难,实时性相对较差。对于视频中的手势图像进行逐帧识别的准确率较低,且运行稍显卡顿,但若只对偶数帧的图像进行预测,则可以有效的改善程序运行的流畅度。考虑到可变换手势的识别更具有实用性,最终采用第二种方法进行手势识别,并采用间隔帧图像进行识别,有效改善了逐帧识别卡顿问题,手势识别效果如图8所示。

图8 手势识别效果图
3 系统功能测试
为了验证视觉手势识别的移动机器人控制系统的可靠性,开展视觉识别功能测试,对影响手势识别的因素进行分析,提出改进措施,并对整体功能进行测试。
3.1 手势识别算法评估
手势识别是手势控制的前提,其稳定性、准确性直接影响到移动机器人控制的可靠性,因此有必要对手势识别算法的稳定性进行测试,并分析其影响因素。
通过改变手势在镜头中的出现位置与频率、手势的偏转角度、手势尺寸大小和识别的环境背景对手势识别进行测试。测试结果显示:改变手势在镜头中的出现位置、出现频率和改变手势尺寸的大小手势识别时间约为0.1 s,能够准确的识别手势,并具有很高的稳定性。
但若手势处于识别难度较大的位姿,即与定义的手势姿态特征不符,会对手势识别的结果造成一定影响。如图9所示,手势3在训练集与测试集均为3根手势间有间隙,若在识别时手指间无间隙则无法识别。同时在特别复杂背景下的识别准确率也有所下降。为保证手势控制移动机器人系统具有较高的准确率,被测试者在展示手势时,应尽量保证采集到的手势图片易于区分,且处于识别难度较小的位姿,同时也应选择较为简单或人为设计的环境背景进行手势识别。

图9 手势位姿造成的识别困难示例
3.2 系统整体实验
系统整体测试在与训练集及测试集手势背景相同的环境下进行。通过以不同角度、距离、速度多次测试6种不同的手势命令,上位机手势识别系统能够准确识别无干扰的手势,且手势识别准确率达到100%,手势控制移动机器人能够按照演示的指令做出相应的动作,且网络通信稳定,系统工作状态正常,实现了预期的手势控制移动机器人运动目标。如图10所示,为手势3识别结果左横移,将该识别结果发送给下位机树莓派控制移动机器人实现左横移运动。本文设计的手势识别算法解决了旋转、缩放后手势动态识别率较低的问题,实现了低成本视觉手势识别手势控制系统设计目标,且具有高稳定性、可靠性和实际应用价值。
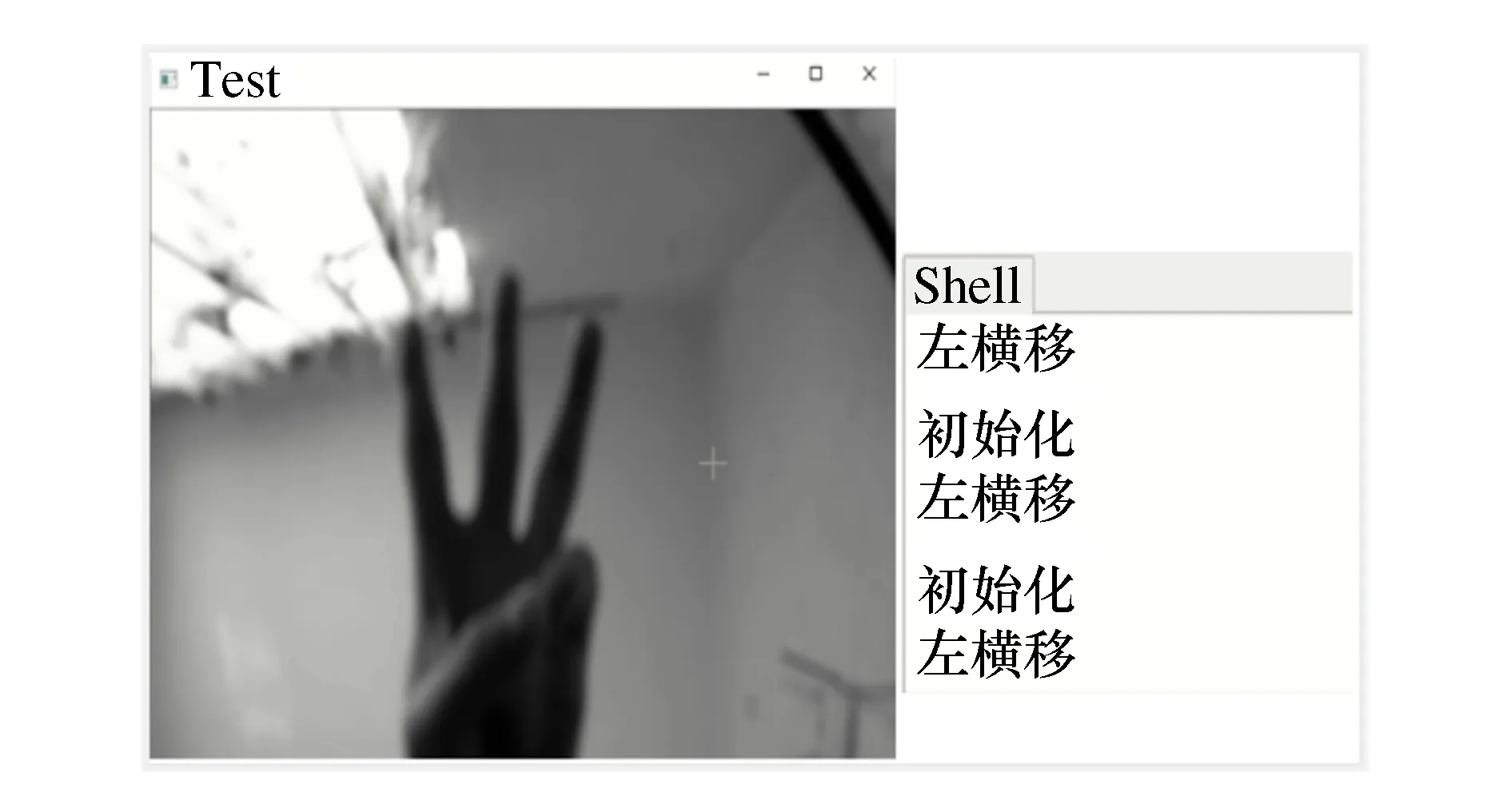
图10 手势控制移动机器人测试实验
4 结论
针对低成本、普适性手势控制在移动机器人运动控制需求,采用普通USB摄像头及个人计算机设计了视觉手势识别的移动机器人手势控制系统。采用改进的VGG16网络模型对手势进行识别,在网络模型的训练集中考虑了手势角度、缩放等因素,解决了旋转、缩放后手势动态识别率较低的问题。实验中,手势识别时间约为0.1 s,识别效率较高,在与训练集相似背景下识别准确率为100%,识别率高;移动机器人能够按照动态手势指令实时作出运动响应,控制准确、实时性强。实验结果表明,本文设计的视觉手势识别的移动机器人手势控制系统具有稳定性、可靠性及实用性,为无接触、自然的人机交互控制系统提供了应用参考。
猜你喜欢
现代电子技术(2022年20期)2022-10-15
包装工程(2022年9期)2022-05-13
集装箱化(2021年1期)2021-04-12
中国信息技术教育(2020年2期)2020-02-02
设计(2020年24期)2020-01-25
红领巾·萌芽(2019年9期)2019-10-09
现代职业教育·中职中专(2018年11期)2018-06-11
小学阅读指南·低年级版(2017年6期)2017-06-12
科学与财富(2016年28期)2016-10-14
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
