
深度学习模型法鉴别橙盖鹅膏菌
2022-08-29 12:52谢龙珠
黑龙江工业学院学报(综合版) 2022年7期
谢龙珠,高 飞,张 蕾
(1.合肥学院,安徽 合肥 230000;2.安徽大学,安徽 合肥 230000)
我国在2021年12月7号发布了关于食用菌的“十四五”规划,推动此行业发展。目前已知在中国可食用的菌类有1020多种,具有药用价值的有690多种,具有毒性的达到480多种。其中鹅膏科、鹅膏属,是世界上毒性最强的大型真菌之一,在欧美国家有“毁灭天使”的名称,具有淡淡的清香,具有很大的迷惑性,经验不足的情况下,很容易被误食,并伴随极高的中毒者死亡率(不同文献记载高达50%~90%)[1]。在鹅膏菌属中橙盖鹅膏菌是最著名的食用菌之一,富含多种多糖成分,目前已经成为研究新型肿瘤药物的重要原料[2]。
目前传统的菌菇类鉴别方法,其大致分为四大类,分别为形态特征识别的方法[3]、化学原理检测的方法[4]、动物实验检验法[5]和利用真菌法[6]来进行鉴别。但是这些方法应具有很多缺陷,要不依靠大量的经验,要不实验方法很复杂,需要消耗大量人力物力。
近年来,物理、化学、生物学和计算机的快速发展,各种学科交叉技术不断创新。紫外、核磁共振、计算机图像处理分析、各种电泳、X射线衍射技术、聚类分析法等均被运用到鉴别分析的方法中来,形成了以“四大鉴别”法为基础,理化分析为重点的科学与先进鉴别体系。鹅膏菌因幼时呈鹅蛋状而得名,它的菌盖多为黄桔色,表面很光滑,略带粘液,其表面上有一层白色的外衣紧紧包住鹅蛋菌菌盖,肉呈白色,内部空心。从外表更容易鉴别橙盖鹅膏菌,因此本文采用的是计算机图像处理分析技术。
图像处理技术发展迅速,也在各个领域更加广泛的应用,比如计算机视觉、虚拟现实、三维重建等等。本文采用的是深度学习模型法(Geoffrey Hinton,2006)[7]。它所具有的多隐层神经网络具有优异的特征学习能力,通过构建多层网络,对目标采取多层表达的方式,提取高层次特征来表达样本所具有的抽象语义信息。将深度学习与药材鉴别相结合来提高效率是一种趋势。比如2015年刘斌等人通过贝叶斯分类算法从蘑菇的特征属性出发预测蘑菇的毒性,该方法对毒蘑菇识别准确率达到98%以上[8]。2020年王一丁等人提出了基于深度学习的小样本中药材粉末显微图像识别,与原始ResNet网络相比,准确率提升了4.1个百分点[9]。2019年陈秋月等人搭建了Android平台下基于深度学习的蘑菇识别APP,可以对8种不同种类的蘑菇进行识别,识别率可以达到95%[10]。可以看出深度学习模型已经取得良好的检测效果,依然存在检测算法较为复杂,生成的模型运行较为缓慢,在实时检测的效果上并不成熟等问题,检测鉴别的成功率还能进一步提高。
1 YOLOv5网络结构
YOLOv5包括YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5s四个类别,其中YOLOv5s型号更小,反应速度更灵敏。因此,本文以YOLOv5s为模型。然后对主干加入注意力机制进行优化,然后在头部进行多特征融合,并改进损失函数以保证检测的精度和速度。YOLOv5s算法框架如图1所示,其由输入(Input)、主干网络((Backbone)、颈部(NECK)以及预测(Prediction)四个部分组成。

图1 YOLOv5网络结构
Input端包括Mosaic数据增强、自适应锚框计算、自适应图片缩放三个部分[11]。Mosaic数据增强随机采用4张图片进行缩放、裁剪后拼接在一起,使背景图片更充足。自适应锚框计算,神经网络在初始锚框的基础上输出预测框和真实框进行对比,计算两者之间的距离,最后反向更新网络参数。自适应图片缩放,对原始图像添加少量黑边,统一把图像缩放到640×640×3,最后送入到神经网络中。
Backbone主要包含了Focus模块和CSP(BottleneckCSP)结构[12]。CSP使得输出图保留了更多的网络梯度信息,在降低计算量的同时保持了网络的性能。在运算中,前一级的特征可以作为下一级的输入进行上采样或下采样,同时与主体部分相同大小的特征图进行合并。
Neck模块采用了SPP、FPN+PAN的结构[13],并且增加了CSP2模块提升了特征融合的能力。SPP模块增加了主干特征的接收范围,分离出最重要的特征。FPN+PAN向下传达强语义特征,向上传达强定位特征。
Prediction模块由分类损失函数(Classification Loss)和回归损失函数(Regression loss function)两部分构成。Prediction模块生成检测框,通过将锚框应用于来自Neck模块的多尺度特征图来生成类别、坐标和置信度。
2 改进YOLOv5算法
2.1 添加注意力机制
注意力机制被用于各种计算机视觉任务,如图像的分类和分割等。SENet[14]是一个早期的注意力,它简单地挤压每个2D特征地图,可以有效地建立通道之间的相互依赖关系。CBAM[15]是通过空间编码信息引入大尺寸内核的卷积,使通道域和空间域的相结合,进一步推进了这一思想。本文采用Coordinate Attention(CA)[16]方法如图2所示,将全局池化分解为两个一维编码过程,是一种更有效的捕获位置信息和信道关系的方式,以此来增强移动网络的特征。

图2 CA注意力网络结构
在结构上,SE块可以分解为两个步骤:挤压和激励,这两个步骤分别用于全局信息嵌入和通道关系的自适应重新校准。给定输入X,第c个通道的挤压步骤可以用公式(1)表示。
(1)
对全局池化公式(1)进行因子分解。具体地,给定输入X,我们使用两个空间范围的池核(H,1)或(1,W)来分别沿着水平坐标和垂直坐标编码每个通道。因此,第c通道在高度h处的输出可以表示为公式(2)。
(2)
第c通道在宽度w处的输出可以写成公式(3)。
(3)
f=δ(F1([zh,zw]))
(4)
将得到的图像f放进卷积核为1×1的卷积得到了在原图宽度和高度上通道数一样的图像Fh和Fw,在进行Sigmoid激活函数后得到在高度gh和宽度gw方向上的注意力权重。如公式(5)和公式(6)所示。
gh=σ(Fh(fh))
(5)
gw=σ(Fw(fw))
(6)
最后在原图上进行乘法加权计算,得到在宽度和高度方向上都带有注意力权重的图像。如公式(7)所示。
(7)
2.2 进行特征融合
在神经网络提取特征时,底层高分辨率特征图包含目标的细节信息,如轮廓、颜色、纹理和形状特征等这些特征,更方便对目标进行定位。但是,底层特征图的卷积运算较少,高级特征的提取不充足,语义信息相对较少,造成目标和背景的区分模糊。高层低分辨特征图有较多的卷积运算,语义信息提取相对较多,由于下采样过多,会造成细节信息严重丢失。
本文将低层特征与高层特征进行特征融合,使用Concat特征融合的方法,Concat是通道数的增加,相较于add是特征图相加,通道数不变,可以更有效的防止信息丢失。Concat层在不同尺度特征图中对语义信息进行提取,通过增加通道的方式来提升性能。在YOLOv5网络架构的第24层和27层输出特征图为小型和中型的输入特征图,将原始模型中15与19层改为13与25层,在增加检测层之后,17与22层进行特征融合。使其在特征提取时具有更丰富语义信息的同时对一些细微处也有较强的识别能力。改进后的YOLOv5网络结构如图3所示。

图3 改进后的YOLOv5网络框架
2.3 改进损失函数
YOLOv5算法采用的是GloU[17]作为边界框回归的损失函数,GloU方法解决了IoU[18]中预测框和目标框不相交时IoU_1oss无法优化的情况。也克服了当两个预测框和IoU一样时,两者相交IoU_loss无法区分的情况。GIoU实现原理如公式(8),GIoUloss实现原理如公式(9)。
(8)
GIoUloss=1-GIoU
(9)
A为预测框,B为真实框,C表示为包含A与B的最小凸闭合框。
本文所采用的DIoU[19]将目标与检测框之间的距离、重叠率以及尺度都考虑了进去,克服了IoU和GIoU在训练中出现发散的情况。DIoU_loss使两个目标框之间的距离最小化,相较于GIoU_loss收敛速度更快。当两个框处于水平方向和垂直方向上时,DIoU_loss的回归更快,而GIoU_loss与IoU_loss水平相当。并且DIoU可以替IoU用在NMS中,使NMS得到的结果更准确。DIoU原理如公式(10)和公式(11)所示。
(10)
(11)
式(11)中,RDloU是两个框中心点之间的距离,且ρ代表的是计算真实框b和预测框bgt的欧式距离。C是能够包含预测框和真实框的最小对角线距离。
如图4所示,当检测框位于图4(c)中心位置时,损失值都一样,当检测框位于图4(a)图4(b)位置时,GIoU和IoU的损失值一样大,而DIOU的损失值较两者都大,所以DIoU更能够描述当前位置信息。

图4 目标框不同位置IoU、GIoU与DIoU的损失值对比
非极大值抑制算法(Non-maximum suppression, NMS)[20]本质上就是抑制非极大值的元素。在对目标检测时,同一个物体可能有好几个框,为了保留一个最优的框,用非极大值抑制来抑制那些冗余的框。
DloU_NMS和原始的NMS不同,DloU_NMS不仅考虑了loU的值,还考虑了两个Box中心点之间的距离,决定一个框是否被删除。如公式(12)和(13)所示。
si=IoU-RDIoU(M,Bi)<ε
(12)
当si=0时
si=IoU-RDIoU(M,Bi)≥ε
(13)
M为得分最高的框,Bi为待处理的框,Bi和M的IOU越大,Bi的得分Si就下降的越厉害。
3 实验结果
3.1 实验环境
本文的深度学习框架为YOLOv5s,实验环境是Python 3.6+Pytorch 1.7.1,GPU加速驱动为CUDA10.1和CUDNN7.6。处理器用的是Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz 12G运行内存,显卡为GeForce GTX 950M。
3.2数据集
本文整理了一个关于橙盖鹅膏菌的数据集,参考了Mushroom Classification和Secondary Mushroom Dataset两个经典的蘑菇分类数据集,网络爬虫了一些我们所需要的样本和自己所采集的样本制作了本文的数据集。最后使用软件Make Sense对采集到的橙盖鹅膏菌图像进行标注,生成本文数据集。为了使模型更加精确对已有的数据集进行扩充处理。在已有的数据下采用了平移、旋转、加噪和裁剪等方法把数据集扩充到783幅图像。
目标框的中心点在图中的位置坐标分布从图5(a)可以看出,目标框大多居于图像的中部位置,如图5(b)所示,目标框的尺寸也不一样,总体来看中等尺寸较多。
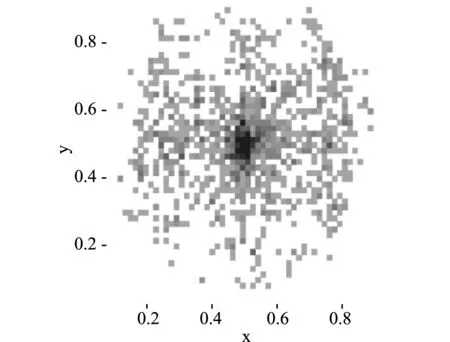
(a)目标框的位置
如图6所示对图像进行了Mosaic数据增强,随机采用了四张图像进行拼接,使背景图片更丰富。减少对大物体的过度响应,增强模型检测中小目标的能力。

图6 Mosaic数据增强
3.3 评测指标
本文所采用的评价指标有精确度(Precision, Pr)、召回率(Recall, Re)、平均精度(Average Precision, AP)、平均精度均值(mean Average Precision, mAP)和每秒计算的帧数(Frames Per Second, FPS),分别如式(14)、式(15)、式(16)、式(17)所示。
(14)
(15)
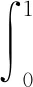
(16)
(17)
3.4 模型训练
目前YOLOv5有四个版本,包括YOLOv5m、YOLOv5l、YOLOv5x和YOLOv5s,其中YOLOv5s模型更小,更容易快速部署。所以本文使用YOLOv5s代码被用作基本框架,在PyTorch中实现了上述的所有修改。按照比例7∶3随机划分训练集和测试集。输入图片大小为640×640×3,Bath Size设置为4,学习率设置为0.01,训练次数为200次。训练模型如图7所示。

图7 评测结果
由图7可知,从整体上看三幅图的曲线都是趋向于稳定,没有太大的起伏变化,图7(a)和图7(b)的损失曲线都是前期快速下降,然后趋于平稳,当训练次数增加到180轮时,基本无波动,训练中没有出现发散或过拟合的现象。同样图7(c)由精准率与召回率构成的mAP值前期的上升值很快,训练次数在50左右mAP曲线逐渐的趋于平稳,当训练次数达到100时达到稳定,模型收敛。
3.5 测试模型
本文所采用的模型对橙盖鹅膏菌的检测效果如图8—图10所示,其中Y是橙盖鹅膏苏的简称,后面的数字表示的是正确检测出橙盖鹅膏菌的概率。从图8—图10中可以看出,该方法对小目标的检测、亮度不同的环境和有遮挡物的情况下仍有较高的准确性。如图8所示对图8(a)大小目标混合和图8(b)单独小目标仍良好的检测效果。如图9所示在图9(a)亮度高和图9(b)亮度低下,检测效果基本没有影响。如图10所示充分显示了在图10(a)和图10(b)有遮挡物和环境复杂的情况下,仍有较高的准确率。

(a)大小目标混合检测

(a)亮度高

(a)环境复杂和遮挡物下
3.6 消融实验
实验结果如表1所示。以YOLOv5为基础逐步添加CA注意力机制、进行多特征融合和更改回归损失函数为DIOU_NMS三个改进点,然后进行精确率、召回率、平均精确率和mAP@0.5:0.95(在IoU阈值从0.5到0.95,步长0.05)上的平均mAP数据对比。

表1 消融实验
从表1可知,原始的YOLOv5模型的精确度为0.9469,召回率为0.9549,mAP为0.9822,mAP@0.5:0.95为0.7922。加入CA注意力机制后,召回率增加了1.31%,mAP提升了0.28%。在加入注意力的基础上进行多特征融合后,精确率、召回率和mAP分别提升了0.11%,0.61%,0.78%。在前两步的基础上更改回归损失函数为DIOU_NMS,精确率、mAP值、mAP@0.5:0.95分别都增加了0.51%,1.81%,0.98%,3.28%。从总体来看,增强了对橙盖鹅膏菌的特征提取能力,对尺寸较小的橙盖鹅膏菌也有较好检测效果。
3.7 与主流模型比较
训练完成后,分别在将本文方法与、YOLOv3、YOLOv4、YOLOv5、Faster R-CNN和SSD主流检测模型进行性能对比,分析本文方法性能。
使用相同的数据集和评估指标对它们进行比较。如表2所示,我们从mAP和FPS两个方面对它们进行了比较。本文选择的是YOLOv3、YOLOv4、YOLOv5、Faster RCNN和SSD模型。上表显示了模型的实验结果。在mAP的维度上,本文提出的模型具有最好的性能,它是0.992,比YOLOv3、YOLOv4、YOLOv5、Faster RCNN和SSD分别高0.028、0.039、0.035、0.010和0.1。同时,在速度方面方面,我们的模型也优于其他模型。该模型的FPS为93.45,比YYOLOv3、YOLOv4、YOLOv5、Faster RCNN和SSD分别高38.45、23.11、11.24、2.4和25.57。

表2 主流模型对比
4 结论
根据橙盖鹅膏菌的特点,本文提出了一种深度学习模型法鉴别橙盖鹅膏菌的方法。YOLOv5是目前最新的神经网络模型,具有收敛速度快、精度高、可控性强等优点。它还具有强大的实时处理能力和较低的硬件计算要求,这意味着它可以很容易地移植到移动设备上。这些优点对于保证图像中目标的检测精度非常有帮助。本文做了一些改进,在残差块中引入进了CA(Coordinate Attention)注意模块,更有效的捕获位置信息和信道关系的方式来增强移动网络的特征。在检测阶段,为了更好地检测中小目标,对多尺度特征检测进行了改进。使用了Concat特征层融合法,提取不同尺度特征图的语义信息,用增加通道的方式实现更好的性能。此外,对损失函数进行了改进,采用了损失函数DIOU_NMS,使其更适应锚框的检测。
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
小天使·二年级语数英综合(2019年10期)2019-11-08
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2018年6期)2018-07-09
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
