
结合低秩分解与多流融合的行为识别方法
2022-08-29 09:55:20黄思翔高陈强
重庆邮电大学学报(自然科学版) 2022年4期
黄思翔,高陈强,陈 旭,赵 悦,杨 烽
(1.重庆邮电大学 通信与信息工程学院,重庆 400065; 2.信号与信息处理重庆市重点实验室,重庆 400065)
0 引 言
行为识别任务旨在让计算机识别出视频中发生的感兴趣的行为类别,在智能监控、自动驾驶、视频推荐与娱乐等领域有广泛的应用[1]。然而,由于视频行为的多样性和场景的复杂性,行为识别任务在实际应用中依旧存在较大的挑战。
近年来,深度学习在行为识别任务中发挥着越来越重要的作用。在先前的研究中[2-11],研究者们大多聚焦于对网络模型结构进行修改[2-4,6-8],或者使用更大规模的视频数据集进行模型预训练[3-5,9-11],从而让模型能够提取鲁棒性更强的特征以提升行为识别精度。这些方法的输入模态一般仅为原始视频,通过计算输入视频直方图特征或者用二维、三维卷积提取视频特征,并对获取的特征进行分类。双流模型[12]被提出后,通过大量的实验[2-4,13-14],验证了视频光流信息与RGB流信息进行融合后能进一步提高模型的行为识别准确率。然而,在获取视频光流信息时,由于仅参考了相邻两帧图像之间的像素运动,模型只能提取采样片段的局部时域信息,忽略了整个视频的全局时域信息的学习,这导致模型对视频行为类别的判别并不可靠。
对于场景固定的数据集[15-18],运动区域相对原图所占比例较少,稳定不变的区域较多。因此,原始视频可以粗略地看成是由大部分稳定的区域与少部分变化的运动信息组合而成。稳定的区域在整个视频中是不变或者近似不变的,该区域视频可以近似地用少量甚至一帧图像来代替。对于视频的运动部分,运动信息通常只占视频中的小部分。因此,可以认为运动部分对应的视频矩阵为稀疏矩阵,能够借助低秩分解来提取整个视频的全局时域信息。
为了更好地利用视频全局时域信息,本文先把原始视频进行低秩分解为低秩流和稀疏流两部分。低秩流包含视频中比较稳定的内容,稀疏流包含视频中运动信息,且这种信息具有全局性。把包含全局运动信息的稀疏流、包含局部运动信息的光流和RGB流分别输入3D CNN网络,并进行后期融合。模型在后期融合中聚合了光流和稀疏流两个不同尺度的时域运动信息与丰富的空域信息,多流融合的结果相较于仅融合单个尺度的时域信息与空域信息更可靠。
1 相关工作
近年来,深度学习方法在图像识别领域取得了巨大的成功[19-25],许多研究者开始将深度学习方法应用于行为识别领域[5,12,22-23]。
行为识别的难点是如何提高模型的时域建模能力,现有方法通常遵循两种思路来提高时域建模能力。
1)基于二维卷积神经网络(convolutional neural network, CNN)的方法。文献[12]提出了双流CNN,将单帧图像和多帧光流堆叠分别送入CNN网络进行训练,并将其预测结果进行融合。这种方法能够有效地提升模型的识别准确率,证实了光流与RGB流的双流融合能够有效提升识别准确率。虽然该方法以引入光流模态来引入相邻帧的时域信息,但是模型只获取了短时运动信息,无法对长时运动信息进行有效建模。文献[24-25]针对双流融合中只能处理短时运动而对长时运动的时间结构无法有效捕捉的问题,提出了时域分割网络(temporal segment network, TSN)。TSN采用稀疏时间采样策略,扩大了对原始视频的时域感受野,从而提高时域建模能力,但其比双流融合仅获得了较多的局部运动信息。文献[5]在分析了3D卷积相对于2D卷积的优势后,提出将3D卷积拆分为一个2D空间卷积与一个1D时间卷积的串联形式,构成新的时空卷积块R(2+1)D,极大地提升了模型的实时性且保证了模型的精度。
2)基于文献[2]的3D CNN行为识别方法。该方法使用更适合学习时空特征的3D卷积替换了原本的2D卷积,文献[3,13]分别针对3D卷积中参数过多而数据集较小的问题提出了P3D和T3D网络,借鉴ImageNet网络进行预训练权重迁移,将对应2D CNN的预训练权重向3D网络迁移。这表明,图像识别领域中模型在ImageNet数据集上进行的预训练可以很好地应用到其他领域。文献[4]提出了大规模的Kinetice数据集,并根据基于2D卷积的LSTM模型、3D卷积与双流CNN的优缺点,设计了一种基于3D卷积的双流I3D(two-stream inflated 3D convNets)模型,表明在大数据集上预训练的3D网络能够在小数据集上大幅度提升精度。
上述方法都是扩大时域感受野来提升模型的精度,模型所得到的数据仍为局部运动信息,忽视了全局运动信息的显示提取。针对此问题,本文通过低秩分解从RGB流中显式地提取动态的全局运动成分与精致的纹理,有效地提升所提取特征的区分度,从而提升模型精度。
2 低秩分解基础
本文采用加速近端梯度算法(accelerated proximal gradient, APG)[26]来进行低秩分解,APG算法进行低秩分解是求解最优化问题,表示为
(1)
求解(1)式为NP难问题,需要通过凸松弛转化为新的最优化问题,表示为
(2)
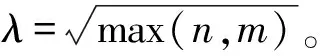
3 本文方法
本文提出的基于低秩分解与双流融合的行为识别方法如图1所示。第1步,将原始视频进行光流提取与低秩分解,由于当前的低秩分解算法不能直接处理三维视频数据,需要对原始视频先进行二维转化、低秩分解、三维还原,得到对应的低秩视频与稀疏视频;第2步,将原始视频以及提取得到的稀疏视频、光流视频分别通过对应的卷积神经网络处理得到对应的各行为概率;第3步,对3个模态的各行为概率进行后融合,得到最终预测结果。

图1 本文提出的基于低秩分解与双流融合的行为识别方法
3.1 基于低秩模型的视频全局运动信息提取
本文需要对视频的稳定区域与运动区域进行显式提取得到低秩流、稀疏流。低秩分解算法目前已经比较成熟,因此,本文直接使用经典的加速近端梯度算法[26-28]来进行低秩分解。
在现有的视频数据集[15-16]中,运动视频往往是由大部分的稳定区域与少部分的变化运动信息组合而成,可以借助低秩分解进行分离,即将原始视频数据矩阵HRGB分解为低秩流矩阵HA与稀疏流矩阵HE之和,表示为
HRGB=HA+HE
(3)
(3)式中,HRGB、HA、HE均为三维矩阵。传统的低秩分解算法通常只对二维矩阵进行低秩分解得到一个二维低秩矩阵与二维稀疏矩阵。然而,视频数据为三维矩阵,无法直接套用传统的低秩分解算法。本文对视频数据进行适当转化,使其转变为传统低秩分解算法所匹配的二维矩阵后再进行低秩分解。视频数据低秩分解的预处理方法如图2所示。首先,对三维结构进行转化;然后,对二维结构进行低秩分解,得到低秩部分与稀疏部分;最后,将低秩部分与稀疏部分按转化方法的逆过程还原为三维结构。
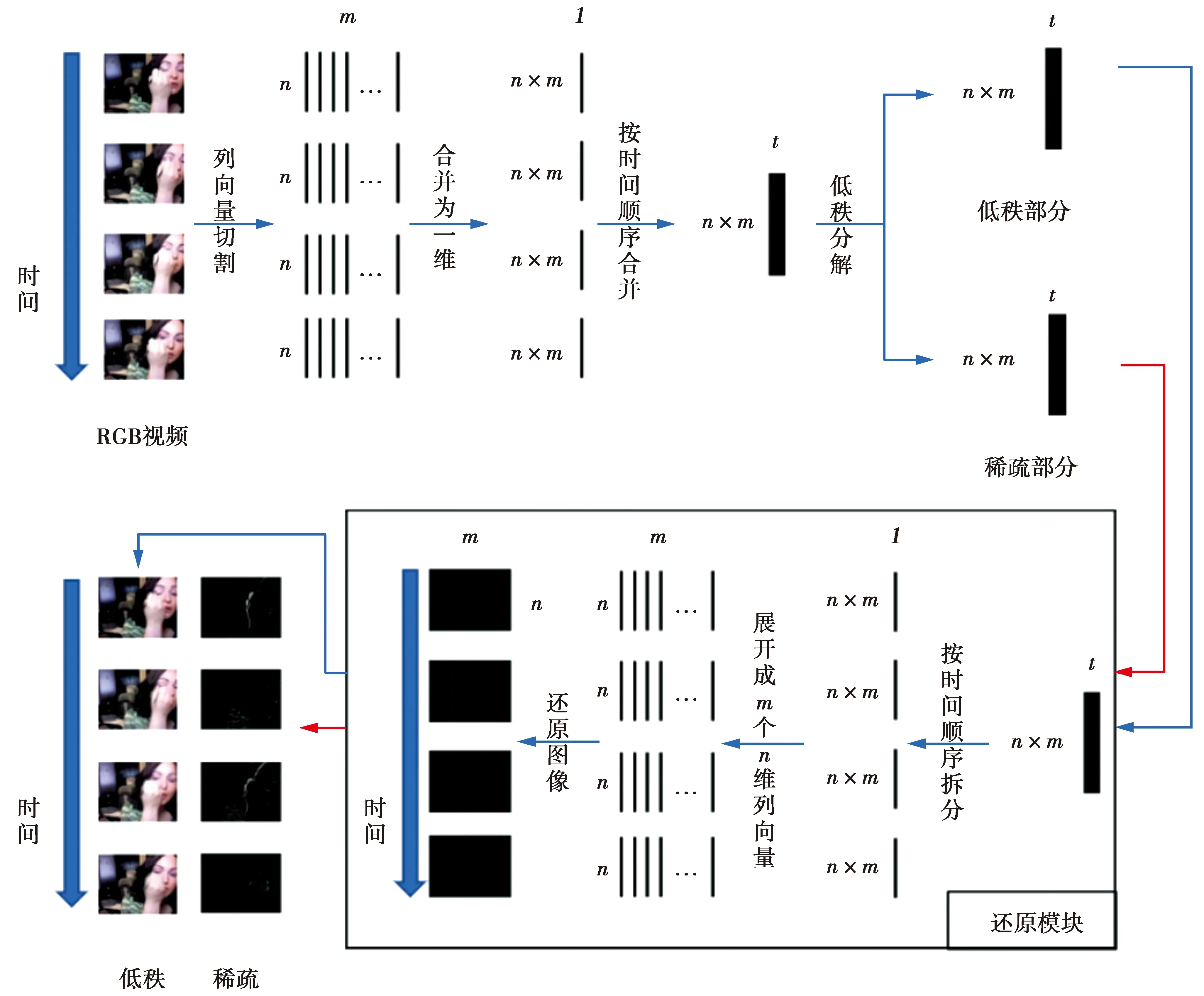
图2 视频数据低秩分解的预处理方法
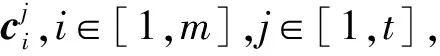
(4)
视频数据的三维矩阵HRGB,经过上述操作以后转化为一个t×n×m的二维矩阵D,表示为
D=[C1,C2,…,Ct]
(5)

(6)

(7)
(8)
同理有
(9)
将得到的A、E还原为HA、HE。
从上述过程可以得到,在进行低秩分解时,整个视频的时域信息被整合为一个二维矩阵,每一帧的运动信息均包含了整个视频的时域信息。因此,其比光流包含更加丰富的时域信息。
3.2 卷积神经网络模型
为了验证本文方法的有效性与泛化性,选用双流I3D[4]、C3D[2]、R(2+1)D[5]、TSM[29]4个卷积神经网络作为验证模型。
I3D模型网络结构如图3所示。I3D的输入为一段长度为64帧、单帧图像大小为224×224的视频段,其损失函数使用分类中常用的交叉熵,定义为

图3 I3D网络结构
(10)
(10)式中:yi为第i类的真实概率;pi为第i类的预测概率;C为类别数。双流I3D网络借鉴了ImageNet中的Inception-v1网络[29],经证实,在Kinetics[4]大数据集上预训练过的I3D模型在UCF101和HMDB51上能取得很高的识别准确率。不过,此预训练模型是在对应模态(即RGB和光流数据)上进行的,缺少低秩、稀疏部分在大规模数据集上的预训练模型,而直接加载对应模态预训练模型会因为模态信息不匹配而造成实验结果不够好。因此,为了保证对比实验的公平性,本文所有实验在训练时不加载任何的预训练模型,所有的模态采用I3D单独训练一个模型直至在对应模态上收敛,并融合所有模态的测试集结果作为最终结果。
C3D模型是在2D CNN上将2D卷积核扩展为3D卷积核得到的模型,3D卷积拥有更加强大的时域建模能力,在行为识别上相对2D卷积表现更好。C3D有8个卷积层、5个全连接层以及2个全连接层,并且卷积核的大小为3×3×3,其损失函数为交叉熵。
R(2+1)D模型是将3D卷积用一个2D空间卷积和1D时间卷积串联代替,总体结构与R3D结构相似,不同之处是R(2+1)D在块与块的连接中有更多的ReLU(rectified linear unit)激活层。R(2+1)D使用了和R3D相同的参数量却获得了两倍的非线性参数,损失函数为交叉熵。
TSM[29]模型提出将用于时域建模的时间转移模块聚合时域特征,保证在二维卷积模型的结构不被破坏的前提下聚合到丰富的时域信息[30]。TSM保证了整体网络的轻量级并取得了较好的识别效果,损失函数为交叉熵。
本文参考文献[27]的模型设置对C3D网络结构进行同样的改进。在每一个卷积层后加上了批归一化层,这样可以帮助模型在训练过程中抑制过拟合。
3.3 后融合
本文方法采用的融合方式为后融合,对所有支路的预测结果进行融合,将每个模态所预测的每个行为类别的分数进行加权平均得到最终每个行为类别预测概率,取最高的加权平均概率行为作为最终的行为识别结果,表示为
(11)
4 实验与分析
4.1 实验数据集
本文在行为识别中使用最经典且常用的UCF101[15]、HMDB51[16]以及红外视频行为识别InfAR[31]数据集。
UCF101数据集是从YouTube收集,具有101个操作类别的真实行为视频行为识别数据集。凭借来自101个行为类别的13 320个视频,UCF101在行为方面提供了良好的行为多样性,并且在相机运动、物体外观和姿势、物体比例、视点、杂乱背景、照明条件等方面存在较大的变化,它是迄今为止仍具有一定挑战性的数据集。
HMDB51数据集在电影中剪辑而得,有小部分数据来源于Prelinger档案库、YouTube和Google视频。数据集包含了6 849个剪辑视频,共划分为51个行为类别,每个行为类别至少包含101个剪辑视频。
InfAR数据集是由40多名不同的志愿者在多个不同场景下采集的红外视频行为识别数据集。数据集包含了12个行为,每个行为类别包含50个视频,总共600个视频。
4.2 实验细节
本文先在UCF101与HMDB51两个数据集上进行训练和测试,对数据集的划分参考文献[2,5-6,30]。在未加说明的情况下,本文实验中所有模态的训练过程均不加载任何的预训练模型。I3D训练使用标准的SGD优化算法,其动量设置为0.9,权重衰减因子10-7,均使用2张2080Ti显卡,学习率在60轮和100轮衰减至10%。C3D与R(2+1)D训练均使用标准的SGD优化器算法,其动量设置为0.9,权重衰减因子为5×10-4,训练使用1张2080Ti显卡,学习率每10轮衰减一半,初始学习率为0.001。所有模型均在UCF101或HMDB51上训练120轮,初始学习率为0.001。
在I3D的训练过程中,本文使用随机裁剪的方式,在视频帧上随机裁剪出224×224的区域。对视频帧的长或者宽小于256的视频,在保证视频长宽比不变的基础上将长和宽的最小值扩展到256,然后随机裁剪一块224×224的区域。在时域上,随机选择足够早的起始帧,以保证能够取到所需的帧数。对于帧数不足64的视频,循环视频直到视频达到64帧。在训练过程中,随机对视频进行左右翻转。在测试过程中,对所有视频均在中心裁剪出224×224的图像块,并将整个视频进行8帧的等间隔采样,将所有采样数据的预测结果取平均后作为最终的预测结果,并据此计算各项指标。在C3D与R(2+1)D的训练过程中,先将原始的视频按照4帧的等间隔采样,并将采样的帧缩放到128×171。每次随机从采样帧选取16帧后随机裁剪一块112×112的区域,在训练过程中随机进行左右翻转。测试时,保证选取的帧为中心裁剪以及对整个采样的数据进行12帧等间隔采样,取平均后作为最终的预测结果。在TSM训练过程中,对整个视频采样8帧,其余参数参考TSM的默认训练配置。
在InfAR数据集上本文采用I3D进行训练,其训练参数与UCF101、HMDB51数据集训练参数一致。用TV-L1算法[28]计算光流,用APG算法[26]对原始视频进行低秩分解,得到低秩部分与稀疏部分。
表1所示为I3D、C3D、R(2+1)D、TSM方法在UCF101与HMDB51数据集上的实验结果。从表1可得,稀疏流对RGB流的全局时域信息进行提取,在单流识别、双流融合和多流融合的实验中,也能明显地提升模型的行为识别准确率。

表1 各种方法的实验结果
4.3 实验结果与分析
单流识别实验中,与RGB流相比,稀疏流在UCF101数据集上准确率平均提升了6.97%(其中I3D上提升5.37%,C3D上提升8.22%,R(2+1)D上提升10.66%,TSM上提升3.65%);在HMDB51数据集上平均提升6.24%(I3D上提升8.24%,C3D上提升5.75%,R(2+1)D上提升8.56%,TSM上提升2.42%)。这表明稀疏流所提供的全局时域信息更有利于模型对视频运动特征的提取。
在双流融合实验中,稀疏流和RGB流进行融合后,最优结果得到了提升,在UCF101数据集上准确率平均提升4.44%(I3D上提升3.12%,C3D上提升2.88%,R(2+1)D上提升7.66%,TSM上提升4.10%);在HMDB51数据集上平均提升3.45%(I3D上提升3.79%, C3D上提升3.66%,R(2+1)D上提升3.21%,TSM上提升3.13%)。这表明稀疏流所提供的全局时域信息能够很好地与RGB流所提供的空间信息互补。在稀疏流与光流进行双流融合后,最优结果得到了进一步提升,在UCF101数据集上准确率平均提升5.57%(I3D上提升1.69%,C3D上提升8.01%,R(2+1)D上提升5.32%,TSM上提升7.27%);在HMDB51数据集上准确率平均提升6.29%(I3D上提升4.57%,C3D上提升8.89%,R(2+1)D上提升8.75%,TSM上提升2.94%)。本文所有双流融合实验都取得了最佳的识别效果。
光流、RGB流与稀疏流进行三流融合,效果超过了本文所有的双流融合方法,达到了最佳分类精度。相对于原始RGB流与光流融合,本文方法在UCF101数据集的识别精度比I3D提升了0.64%,比C3D提升了3.47%,比R(2+1)D提升了4.39%,比TSM提升了0.43%;而在HMDB51数据集上,比I3D提升了3.07%,比 C3D提升了4.06%,比R(2+1)D提升了7.32%,比TSM上提升4.38%。这进一步说明,稀疏部分提供的时域全局运动信息是有助于模型提升识别精度的。
本文在InfAR数据集上补充了多流融合的对比实验,其结果如表2所示。由表2可以看出,本文方法在多流融合方法中具有较大优势,超过了其他多流融合方法,达到最佳精度。

表2 InfAR数据集的多流融合实验结果
5 总结与展望
本文通过分析行为数据中运动信息的本质,将原始视频分为稳定区域与运动区域,并且通过低秩分解将这两个区域分离,得到涵盖了全时域的稀疏运动信息,用神经网络验证了稀疏运动信息让模型提取的特征具有更高的特征识别度。实验表明,低秩分解对RGB流中的运动信息进行提取后,其稀疏表示能够极大提升模型的识别精度,与原始RGB或者光流有很好的融合效果,并在三流融合后显著提升效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
测控技术(2018年11期)2018-12-07 05:49:02
电光与控制(2018年10期)2018-10-13 08:19:00
数学物理学报(2017年5期)2017-11-23 07:51:31
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
西北工业大学学报(2015年4期)2016-01-19 03:31:55
电测与仪表(2015年2期)2015-04-09 11:28:50
中国铁道科学(2014年6期)2014-06-21 06:35:32
