
基于梯度复用的对抗鲁棒性模型的加速
2022-08-29 02:21:06见玉昆
现代信息科技 2022年12期
见玉昆
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
近年来,深度神经网络(Deep Neural Networks,DNNs)已经在多个领域取得巨大的成就,例如图像、音频、文字,然而最近的工作表明强大的深度神经网络模型在处理一种人眼不可察觉的噪声时表现出脆弱性,这种针对模型设计的噪声即为对抗样本。
为了提高神经网络分类器的对抗噪声鲁棒性,有大量的方法被提出来,有去噪、正则化、对抗训练、剪枝、集成学习。经过长期研究后,学术界认为有效提高对抗鲁棒性方法之一是对抗训练。对抗训练就是将对抗攻击算法生成的对抗样本作为训练数据,这样训练出来的模型能够抵御对抗样本的攻击,也就是具有了对抗攻击鲁棒性。
对抗训练需要生成对抗样本,而对抗样本的生成方式有单步迭代的方式以及循环迭代的方式,前者的生成速度快、攻击性差,后者的生成速度慢、攻击性强。因此使用迭代的方式生成的对抗样本训练可以获得更好的对抗鲁棒,然而迭代意味着更高昂的计算成本,甚至在大型数据集上训练一个鲁棒模型在工业界变得不可行。
研究表明鲁棒的模型相较于自然的模型需要更大的模型容量和更多样的训练数据,这对于模型部署是一个阻碍。模型压缩是缓解这一问题的一种方法,对于自然模型的压缩需要保证压缩后的精度损失在可接受的范围。然后对鲁棒模型进行压缩,需要同时保证良好的训练精度和对抗精度,只是考虑自然精度进行模型压缩有可能导致对抗精度降低。存在研究认为自然样本的数据分布和对抗样本的数据分布存在一定的差异,在高维流形上两种样本的决策边界并非重合的。如果仅使用自然样本的损失函数作为优化目标,模型会更好的拟合自然数据分布,导致对对抗样本分类错误,这也是对抗样本成因的一种假说。在压缩模型的同时保证自然精度和对抗精度是一个挑战,本文基于梯度复用的对抗训练加速方案改进对抗鲁棒模型的压缩速度。实验表明可以获得更快的模型压缩速度。
1 对抗攻击与防御
卷积神经网络经过训练可以对输入样本正确分类,对抗样本'是一种人类可以正常分类而卷积神经网络无法正确分类的样本,也就是满足式(1)的输入样本,其中(·)是分类器,是对抗扰动的超球半径,用于度量对抗扰动的幅度。用于度量对抗扰动的幅度。

Fast Gradient Sign Method(FGSM)是Goodfellow 等人提出的对抗样本生成方式,特点是只需要单次访问模型即可生成对抗样本。生成方式如式(2),其中代表的是损失函数,sign 代表损失函数的梯度方向。
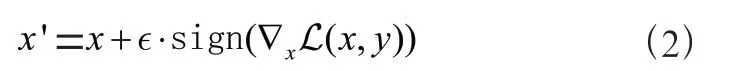
Projected Gradient Descent(PGD)是Goodfellow 等人基于FGSM 提出的迭代攻击方法。PGD 的对抗样本生成算法式(3),其中表示单次攻击的扰动步长,是裁剪函数,对超出超球半径范围的对抗扰动裁剪。
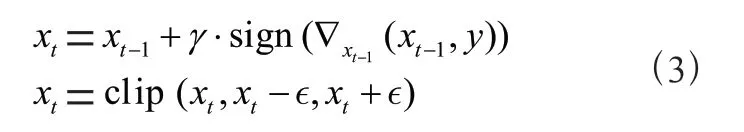
对抗训练的损失函数是一个最小最大化的非凸优化过程,对抗训练的优化目标为式(4),其中是网络的参数,是数据集。其中最小化的优化目标通过优化网络参数使损失减小。最大化的优化目标通过最大化对抗扰动'使损失增大。
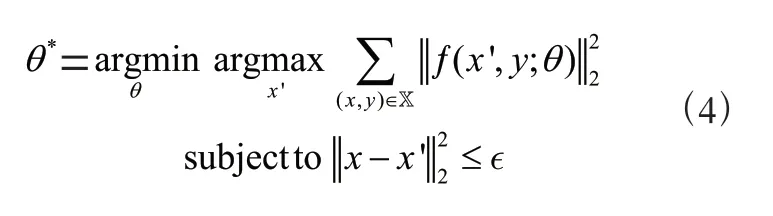
2 鲁棒模型的压缩与加速
2.1 模型压缩
模型压缩是一种成熟的技术,旨在促进DNN 在资源受限情况下的实现。用于减少模型的存储空间和推理时间,同时不会显著地降低准确性。模型压缩技术有参数剪枝、低秩分解、知识蒸馏等。参数剪枝是对已经训练好的模型进行压缩,以删除冗余、低权重的网络权重达到DNN模型的参数量。参数剪枝同样是一种避免过拟合的有效方式,由于过拟合模型普遍具有较差的对抗鲁棒性,因此参数剪枝也作为提高模型鲁棒性的一个技巧。低秩分解是将卷积神经网络里面较大的卷积核进行分解成多个较小的卷积核用于降低计算量,可以有效地降低内部冗余性,然而低秩分解会增加模型深度使得一些模型出现梯度消失,无法广泛应用到所有模型上。知识蒸馏的核心思想是用一个较小的网络实现原有网络的功能,通过教师模型生成的软标签作为学术模型的学习目标。
彩票假说提出了一种观点,一个具有对抗鲁棒的模型内部是存在一个相同对抗鲁棒性的子网络,很多人努力找寻一种能够找到这个子网络的方法。Ye等人提出了一种参数剪枝的训练方法ADMM(Adversarial Robustness Model Compression)。这是一种基于ADMM 生成剪枝阈值的对抗模型压缩方法,避免显著降低自然精度和对抗精度。ADMM 算法可以分为三个部分,分别是预训练、剪枝、微调重训练。预训练部分训练一个具有良好精度的网络模型。剪枝部分使用交替方向乘子(Alternating Direction Method of Multipliers)优化算法剪枝,使用较高的剪枝比例会显著降低模型的精度。重训练部分对剪枝后的模型训练,使精度一定程度的恢复。最终的网络模型为经过重训练的模型。
ADMM 的损失函数如下:
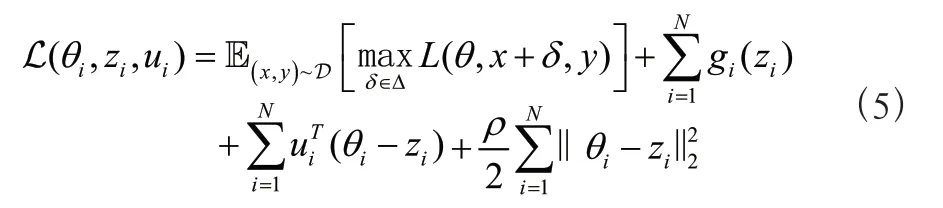
其中θ,z,u中任意两个可以迭代生成第三个,迭代公式如下:


2.2 对抗训练加速
对抗训练相较于自然训练需要更高的训练成本,这使得在大型数据集上训练鲁棒模型更加困难。对抗训练主要的计算代价是对抗样本的生成,Shafahi等人发现PGD 等迭代对抗攻击过程对反向传播生成的梯度并未加以利用,提出了FreeAdversarialTraining(FreeAT)的训练方法。FreeAT 在对抗样本迭代的过程中利用梯度同时更新对抗扰动和模型参数,可以降低对抗训练的成本。
ADMM 本文将对抗训练的加速方案用于模型压缩的对抗训练过程中,以达到加速模型的压缩。
3 实验结果与分析
3.1 实验环境
本文实验训练及测试的计算机硬件配置如下:CPU为Amd(R)Ryzen(TM)R9 5900X@3.70 GHz,GPU为NVIDIA GeForce RTX 3080 Ti,实验采用的操作系统是Ubuntu20.04,深度学习框架为PyTorch1.8.1、CUDA11.1、cuDNN8.0.4。
3.2 数据集
MNIST 数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60 000 个示例的训练集以及10 000 个示例的测试集。
3.3 评价指标
本实验采用自然精度、对抗精度、训练时间作为度量指标。
3.4 实验结果及分析
3.4.1 实验参数设置
输入图片大小设置为1×28×28,网络采用5 层的LeNet 网络,使用随机梯度下降法(SGD,Stochastic Gradient Descent)和自适应矩阵估计(Adam,Adaptive moment estimation)作为优化器,SGD 初始学习率为0.01,动量设为0.9,权重衰减系数设为1×10,Adam 初始学习率为0.01。Batch Size 设置为512,epoch 数设置为40 轮,对LeNet 网络的两个Batch Normalize 层进行压缩,参数剪枝比例分别为0.8 和0.947。
鲁棒性测试采用PGD 攻击,对抗扰动半径设为0.3,迭代次数40,迭代步长设为0.01,随机种子固定为42。
3.4.2 对照实验
使用相同的数据集、超参数训练ADMM。在ADMM算法的三个过程的对抗训练的平均时长进行对照,最终实验结果如表1所示,从表中可以看出,本文提出的加速算法具有一定的加速作用。

表1 模型训练时间对比表
自然精度和对抗精度的测试如图1所示,两张图分别对应自然训练精度和对抗训练精度。图中点线连接的空心圆形是对照组,实线连接的五角星是本文。图中0 ~40 epoch 对应Pretrain,40 ~80 对应Pruning,80 ~120 对应Retrain。如图1所示,可以看出在预训练阶段ADMM 算法具有更好的自然精度和对抗精度,在剪枝和微调的阶段中本文可以获得更加良好的训练精度和对抗精度。
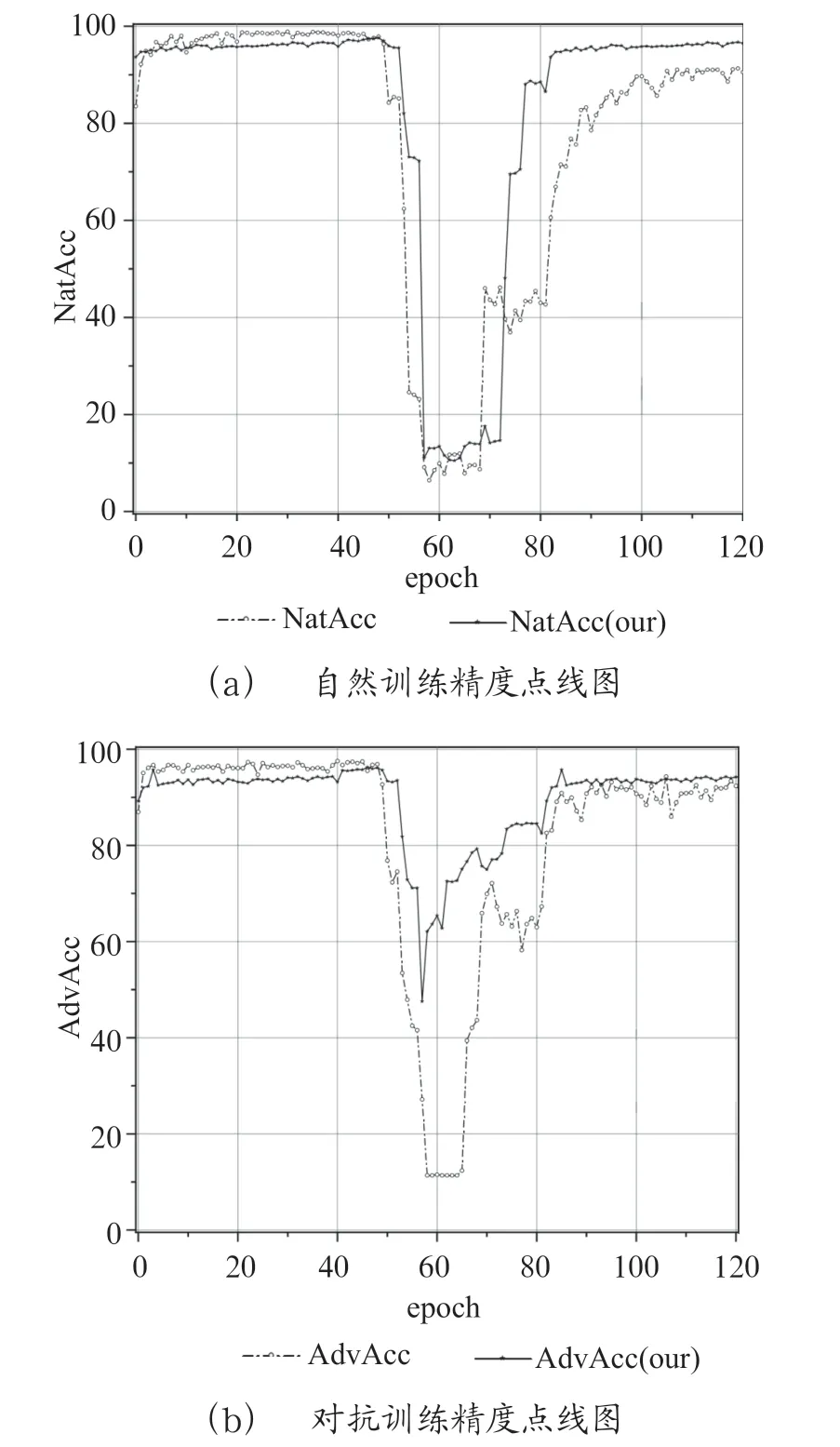
图1 模型精度和鲁棒性对比图
压缩后的模型精度如表2所示,与ADMM 相比,本文提出改进在保证对抗精度的同时,在自然精度上具有更低的自然精度损失。实验结果表明本文保证了压缩后模型的精度,降低了ADMM 算法的训练时间。
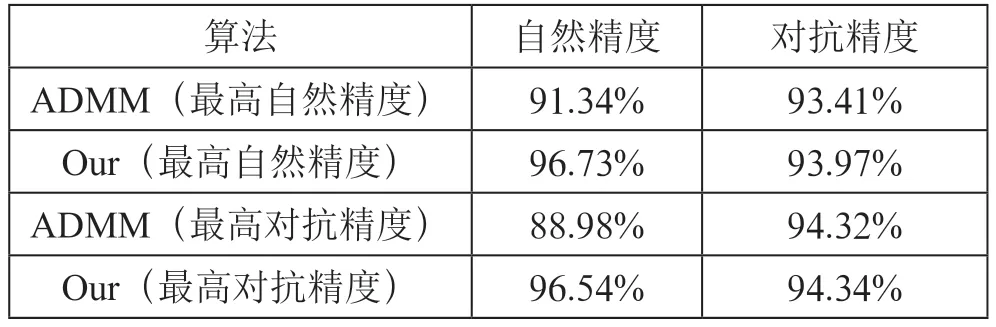
表2 压缩后模型精度
4 结 论
为解决深度学习模型鲁棒性存在的模型容量大、训练时间长问题,本文在ADMM 的基础上引入了对抗训练加速的方法,使用迭代过程中的梯度降低了对抗训练的迭代次数。实验结果表明我们在时间复杂度上得到线性的加速,同时保证了压缩后的模型具有良好的对抗鲁棒性,在鲁棒模型的压缩与加速取得了一定的成果。当前工作的不足是在精度损失可控的前提下,不能取得指数级的加速,接下来将考虑进一步提高训练速度。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
自动化学报(2019年6期)2019-07-23 01:18:18
自动化学报(2017年4期)2017-06-15 20:28:54
天津诗人(2017年2期)2017-03-16 03:09:39
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:42
