
基于通道特征融合的RGB-D图像语义分割方法
2022-08-27 03:36伏娜娜胡志锋郑书展
四川轻化工大学学报(自然科学版) 2022年4期
伏娜娜,许 钢,陈 玲,胡志锋,郑书展
(安徽工程大学检测技术与节能装置安徽省重点实验室,安徽 芜湖 241000)
引 言
图像语义分割是一种像素级别的分类任务,旨在根据图像中每个像素点的语义含义进行分类,并对各个类别赋予不同的语义标签。作为图像处理中场景理解的重要组成部分,根据场景类别不同,可以分为室外场景语义分割和室内场景语义分割。室外场景具有类别少、易区分等优点,该类场景的语义分割技术目前已经非常成熟。而室内场景存在语义类别较多、物体特征不突出、光照不均匀等问题[1],使得室内场景语义标注研究极具挑战性。
随着深度传感器的普及,采集的图像信息从彩色信息扩展到RGB-D 信息。相比于传统的语义分割大多只考虑RGB 信息,RGB-D 图像语义分割引入了对RGB 数据进行补充的深度信息,其作为一个独立于室内光照条件的通道,可以有效解决室内场景语义标注问题。近年来,深度学习[2]在计算机视觉领域得到快速发展,基于深度网络的RGB-D图像语义分割方法也取得了一定进展。研究初期,不论是早期融合还是后期融合都过于简单,均不能有效地将RGB 图像和深度图像特征融合。为了更好地将两者特征融合,Cao 等[3]提出了一种新颖的RGBD 特征融合方法,采用固有的不对称方式处理RGB和深度信息并以乘法方式融合它们。Jiang 等[4]提出了基于改进的Faster-RCNN 算法,采用深度图像与彩色图像融合的方法来提高多任务语义分割模型的性能。Lin 等[5]使用一种利用深度信息辅助图像语义分割的多分支神经网络,引入情境感知接受域(CARF),丰富了特征图的上下文信息。Liu 等[6]通过一个协作反卷积神经网络(C-DCNN)来联合建模,将深度图作为RGB 的附加通道输入网络,同时进行语义分割和深度估计的学习。
以上方法大多只是将RGB 和深度特征通过简单地等权拼接或求和的方式进行融合[7],不能充分挖掘深度信息并将两者信息有效融合。基于此,本文引入基于多任务学习的注意力机制和用于细化通道特征的优化残差模块。首先,注意力机制在通道维度上对输入的特征图进行加权处理并聚焦于局部信息,目的是调节特征图中不同通道的权重[8],从而改善网络的分割精度。然后,在RGB 特征网络层后采用优化残差结构,进一步细化卷积层提取的特征。最后,focal loss[9]通过添加权重和调制系数解决深度学习目标检测模型中类别不平衡的问题。
1 语义分割网络框架
网络总体结构如图1所示。本文分割网络模型结构由编码器和解码器组成[10],编码器采用两个预先训练的残差网络(Residual Network,ResNet)[11]作为独立分支,分别用于提取输入的RGB 图像和深度图像特征。设置两个分支目的是保留在上采样之前的原始RGB 信息和深度信息,并且双分支网络能够更加高效地收集特征。融合模块用来处理特征合并;解码器则完成分割预测部分[12],连续对特征进行上采样处理,即将编码器产生的特征信息转化成精细的分割图,用来恢复图像分辨率。

图1 RGB-D语义分割网络框架
文中针对室内场景语义分割进行研究,由于受到光照不均等一系列困扰,引入深度图像分支[13]。网络整体为四通道输入,即在RGB 三通道的基础上附加一个代表像素点与相机距离的深度通道。深度数据对光照变化具有鲁棒性[14],能够更好地区分室内环境语义类别。因此,使用RGB-D图像能够取得较好的分割效果。
为进一步提高网络模型性能,本文加入了通道注意力机制(AB)[15]和优化残差模块(RRB)[16],如图2所示。具体做法是:一方面,在两个编码器的每一层网络(Conv1、Layer1~Layer4)后面均引用注意力机制模块,可以重新组织每一层网络后生成的特征图;另一方面,在RGB 图像提取网络层Layer1、Layer2 和Layer3 后面添加RRB 结构,用于加强网络的识别能力,使得获取的特征图语义信息更强。此外,多分支架构能够利用深度信息和RGB 信息的互补性,在有效组合RGB-D特征的同时保留原始数据信息,很好地避免了特征过迟或过早融合现象。

图2 网络模型整体结构
总体来说,本文网络在5 个层次编码特征上学习并优化感兴趣区域信息,融合分支将两个特征充分融合,解码部分对融合特征5 次上采样操作得到最终的语义分割结果。
1.1 通道注意力模块
通道注意力机制(AB)是图像识别结构,通过对特征通道之间的相关性建模和重要特征的强化,提高特征提取准确性。大多数网络结构往往忽略了阶段间的差别,仅使用通道相加来实现不同阶段的特征结合。而AB 能够使每个阶段的特征权重发生变化,用来加强一致性。整体结构如图3所示。

图3 通道注意力结构图
假设向网络模型输入特征图A∈RC×H×W,首先对其进行全局平均池化,得到一个大小为C× 1 × 1的特征图B,第m个通道特征图表示如下:

然后在不改变B的通道数的基础上,加入一元卷积层用来确定通道间的权重分布。紧接着,在卷积结果上使用sigmoid 激活函数得到约束权重向量的值,使其保持在[ ]0,1 之间。σ是sigmoid 激活函数,整个过程表示为:

最后,将约束值与输入特征图A进行叉乘,得到一个包含更多有用信息的特征图A*,其表达式为:

本文编码部分引入通道注意力模块,可以增强网络对关键通道的关注,进一步提升网络模型性能。
1.2 优化残差模块
本文选用ResNet50 作为编码网络,该残差结构有3 个卷积层,中间的3 × 3 卷积层前后都使用了1 × 1 卷积,第一个用来压缩输入的特征通道维度,第二个用于恢复通道维度。虽然整体结构通过使用瓶颈层来减少参数和计算量,有益于使网络模型更好地收敛,但是ResNet 作为基础识别模型时每个阶段识别能力存在差异,低阶段感受野较小,导致语义一致性表现不佳。
针对上述问题,在RGB 低阶特征提取网络层中引入了优化残差结构(RRB)。由于第1 层网络没有改变输出特征图的通道数,本文在第2、3、4 层网络后面加入RRB 结构,有助于增强低阶特征语义信息。如图4 所示,RRB 实际上就是一个类似ResNet的残差结构,但它结构更精细且有信息传递过程。该模块主干线的第1个组件是1 × 1卷积层,文中用它把通道数量统一为512,能够将所有通道信息整合在一起。后面则是一个基本的残差模块,图像先经 过3 × 3 卷 积、批归 一化(Batch Normalization,BN)、修正线性单元激活函数(Rectified Linear Unit,ReLU)、3 × 3 卷积,再与主干线路特征融合叠加。支线上两个相同输出通道数的卷积层,沿用了VGG网络的全3 × 3 卷积层的设计,通过叠加卷积层来获得与大卷积核相同的感受野,增加了局部上下文信息。总体来说,RRB 不仅可以重新优化低阶特征,还能在一定程度上强化网络在每一阶段的识别能力。

图4 RRB图
1.3 特征融合模块
目前,很多方法都通过融合不同尺度的特征来提高分割性能。特征融合的目的是将从图像中获得的特征,组合成一个比输入更具识别能力的特征[17]。现有的RGB-D 语义分割网络在编码部分过早或过晚将两者特征融合[18],前者会造成原始信息的破坏,后者导致利用信息效率较低。因此,如何有效地融合这两种信息是改进分割模型的关键。
为解决以上问题,文中引入特征融合模块。不同于Concat 方式,此模块采用逐元素相加来融合特征。Concat 只是增加了图像本身的通道数,每一特征下的信息不发生变化。而逐元素相加是保持图像的维度不变,将对应阶段的RGB-D 特征图加起来,再进一步卷积操作,相当于加了一个先验,有利于后续的图像分类。
整个网络模型是一个三分支架构,两个相互独立的特征提取分支能够保留原始特征图信息,之后利用融合分支合并收集重要特征,可以有效避免现有融合方法的不足。输入图像经过卷积后,上述RGB-D 分支在每个输出阶段,如Conv1、Layer1 等后都提供一组特征图并由注意力模块重新组织。接着,处于感兴趣区域内的特征图,将被逐元素添加为融合分支的输入,直到融合分支的Layer4 网络层。最后,将三分支的输出在Layer4 后相加,可得到含有更多信息的融合特征。
1.4 损失函数
语义分割是将相同的语义标签分配给一类事物,而不是为每个像素分配单独标签。在处理多分类语义分割任务时,会遇到两个影响最终效果的基本问题[19]:(1)所采样的不同对象类别数量不平衡。在室内环境中,背景占据所要处理图像的大半区域,如枕头、毛巾等物体尺寸较小、形状多变,缺乏显著特征且存在卧室、衣柜等特定场合,从而造成网络在某一场景只能学习到较少类别物体特征。(2)每个场景的RGB 图像和深度图像包含信息有所不同。即RGB 分支和深度分支在每一层网络上权重不一致,由于RGB 图像一般含有许多冗余纹理,网络倾向于在较低级别层次上赋予更多的有效信息;而在较高层次上,两者的权重接近。

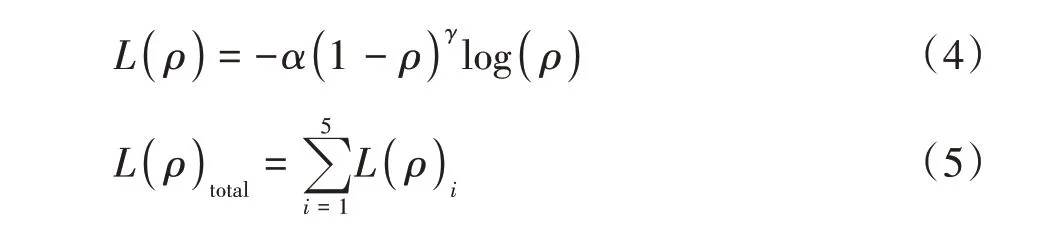
2 实验结果与分析
2.1 实验简介
实验选用处理器为GTX1080Ti,使用Ubuntu 16.04 操作系统,运行环境为Cuda9.0+pytorch1.1.0。设置一个特征图(C×H×W)原始通道数为64、高度为480、宽度为640。同时,还设定了NYUDv2 和SUN-RGBD 两个常用数据集对应的标签类别,分别为40和37。
NYUDv2数据集由微软Kinect的RGB 和深度摄像机记录的各种室内场景的视频序列组成,有1449张标注的RGB 图片和深度图、407 024 张没有标注的图片,且每个对象都对应一个类和一个实例号;而SUN-RGBD 数据集是一个有关场景理解的数据集,包含10 335 张不同场景的室内图片,146 617 个2D 多边形标注和58 657 个3D 边框,具有准确的对象方向以及3D房间布局和场景类别。
2.2 实验结果
图5 所示为AcNet 和本文算法在NYUDv2 数据集上得到的语义分割结果,从左到右依次为彩色图、深度图、真实标签图和预测图。图5(a)为基于AcNet的没有RRB的RGB-D 语义分割结果,图5(b)为加入RRB 的语义分割结果。从图5(a)能够明显地看出仅基于AB 的图像分割结果中有很多的误匹配,如一块隔板同时被赋予了多个标签,而语义分割的目的是给图像中的每一个像素分配一个类别标签,这种分割结果不是希望得到的。图5(b)中隔板整体被贴上了同一标签,且边界分割清楚,达到了预期效果。虽然本文预测结果与真实标签相比仍存在一些误匹配,但其显著优于AcNet 方法下的语义分割结果。
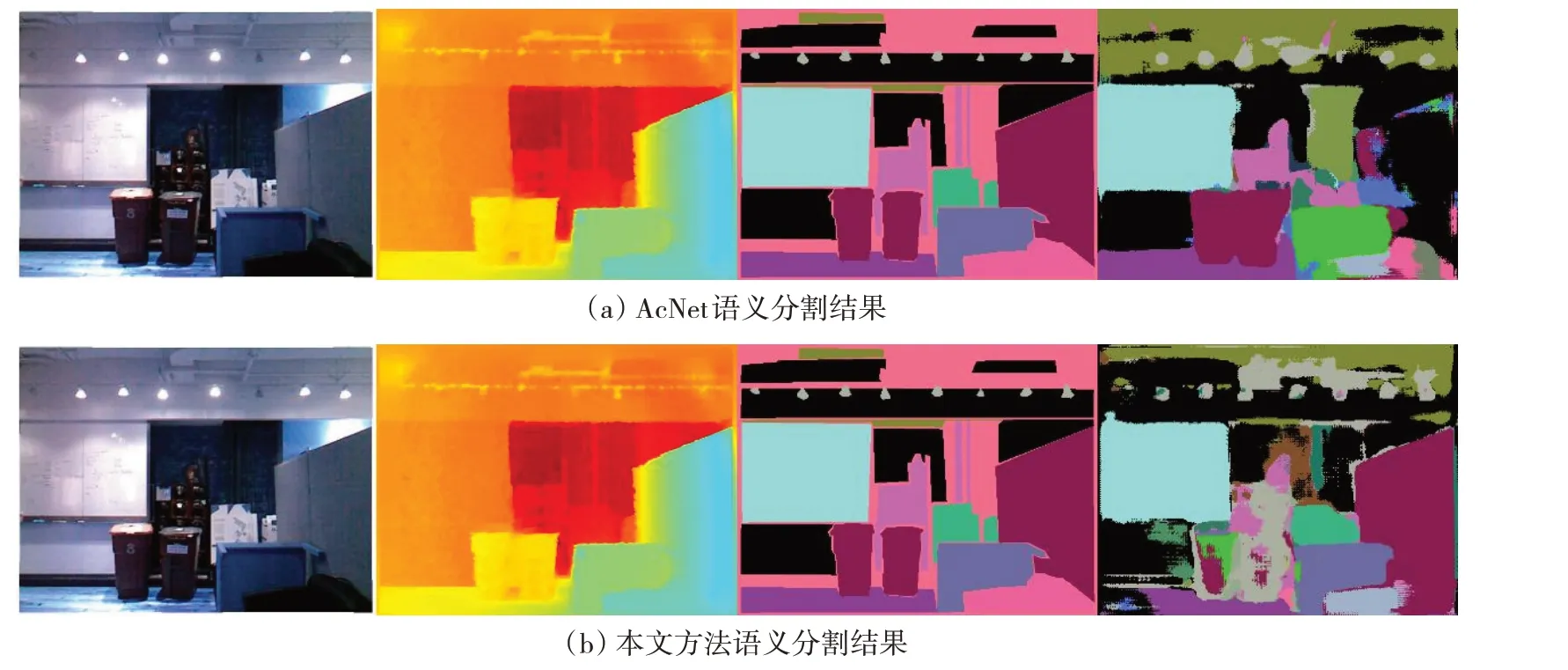
图5 AcNet与本文方法在NYUDv2数据集上的语义分割结果
图6 所示为AcNet 和本文算法在SUN-RGBD 数据集上得到的语义分割结果。图6(a)为仅基于AB方法的RGB-D语义分割结果,物体预测结果边界模糊,柜台、窗户等存在较多的误匹配;图6(b)为在此基础上加入RRB 的语义分割结果,客厅里的桌、椅等边缘轮廓变得更加清晰,而且误匹配也有所降低,图像分割精度明显提高。不难看出,采用本文算法得到的语义分割效果优于仅使用AB 的语义分割的方法。
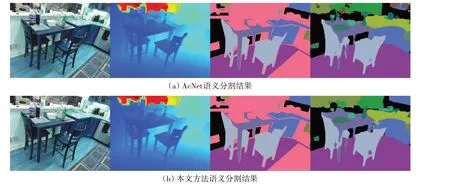
图6 AcNet与本文方法在SUN-RGBD数据集上的语义分割结果
2.3 实验分析
为了验证本文方法的有效性,在实验环境、数据集和图片输入大小一致的条件下,将文中方法与主流的AcNet方法进行实验对比。为评估图像语义分割方法性能,实验分别选取平均交并比(Mean Intersection over Union,MIoU)、像素准确率(Pixel Accuracy,PA)和总体准确率(Overal Accuracy,OA)作为语义分割的准确性标准度量,结果见表1。
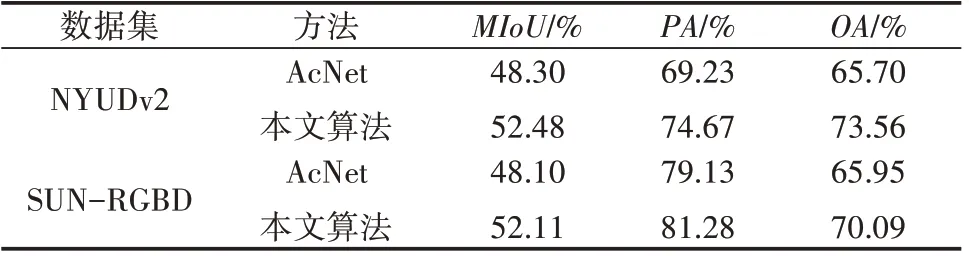
表1 两种分割方法性能对比
表1 显示了两种方法在NYUDv2 和SUN-RGBD两个数据集上的测试结果。实验中,两种网络的编码器均采用ResNet50,以保持参数量和计算量一致。与本文方法相比,AcNet 方法虽然引入AB 来调节特征图中不同通道的权重,但未达到细化特征图的效果。在NYUDv2 数据集上,本文方法相较AcNet方法MIoU提升了4.18%、OA增加了7.86%;在SUN-RGBD 数据集上,本文方法得到的MIoU、OA相对于AcNet 方法分别提高了4.01%和4.14%。与此同时,所有样本中被正确预测的PA在两个数据集上高达74.67%和81.28%。
实验表明,本文方法具有较好的分割结果。这是因为增加了优化残差模块,能够在提高网络学习效率的同时使物体边缘分割更加精确、降低误匹配率,有效地改善了图像语义分割精度。且focal loss可以进一步强化网络对难以分辨样本的学习,生成更加准确的语义分割结果。
3 结束语
针对室内场景语义标注,提出了一种优化通道特征融合的RGB-D 图像语义分割方法。通过注意力机制调节每一阶段输出的特征权重,有选择地从RGB 分支和深度分支中收集信息;在提取RGB 特征时加入了3 层RRB 结构,达到细化特征图的效果。多分支架构在保持原始RGB-D 特征的同时能够高效地收集特征。损失函数使用focal loss来解决正负样本比例失衡的问题,降低了简单负样本在训练中所占的权重。该方法对通道特征做优化处理,在上采样过程中将两者特征逐层有效融合,捕获了丰富特征信息,图像语义分割精度有所提高。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
中国社会历史评论(2016年2期)2016-06-27
