
基于集成学习的电动汽车充电站超短期负荷预测
2022-08-25 08:52李恒杰朱江皓傅晓飞梁达明
上海交通大学学报 2022年8期
负荷预测对于智能电网的可靠性运维和有效管理至关重要.对充电负荷进行超短期精确预测是提高充电站安全经济运行的重要措施,还能为智能电网的安全监测、成本控制、调控决策提供重要依据,同时也是充电基础设施投资新建、充电站容量扩充与规划决策的有力支撑.在电动汽车还未大规模并入电网时,对能源系统中的负荷进行预测已经有20多年的发展历史,研究方法主要有两类:一类是基于数学预测模型的传统预测方法,包括趋向外推法、弹性系数法、时间序列法、线性回归法等,主要基于线性关系构建,忽略了气候、日期类型等因素对超短期充电负荷预测的影响,预测准确率较低;另一类是机器学习类算法,包括决策树、神经网络、集成学习、深度学习等.
在全生育期注意防治螟虫、纹枯病等病虫害。在抽穗期注意防治稻粒黑粉病和稻曲病。一般在破口期、见穂期和齐穂期用克黑净或爱苗各防治1次。
近年来,基于机器学习的电力系统负荷预测方法因其越来越高的精度,已成为负荷预测领域的热点.文献[7]通过条件生成式对抗网络(Conditional Generative Adversarial Network, CGAN)对抗学习复杂的非线性数据之间的联系,减少了特征值的偏差,提高了预测精度,但训练数据仅包含单一类型数据,缺少泛化能力.文献[8]结合降噪自编码器、奇异谱分析和长短期记忆神经网络构建综合电力预测模型,降低了噪声干扰,提高了预测精度,但模型较为复杂,对平台算力有较高要求.文献[9]使用反向传播网络人工神经网络(Back Propagation-Artificial Neural Network, BP-ANN)提取数据特征向量,卷积神经网络(Convolutional Neural Networks, CNN)提取图像特征,通过多层BP-ANN进行短期预测,但模型训练时间过长,难以部署.文献[10]将改进的随机森林与密度聚类组合,通过叠加各分量预测值来获取负荷预测值,但模型构建复杂,泛化能力较低.文献[11]构建道路模型,通过Dijkstra路径寻优算法在出行链上预测电动汽车(Electric Vehicle, EV)充电负荷概率密度函数,但时间尺度长,无法面对超短期的负荷预测.
近些年来我国的公路里程不断创下历史新高,公路建设规模不断扩大,这就对公路工程建设提出了新的挑战。面对日益复杂的公路工程建设环境,只有严格做好公路工程质量的管理工作,才能够确保良好的工程质量。
考虑到超短期充电负荷预测问题数据的大体量、高时效、高计算资源要求等因素的影响,本文使用集成学习(Ensemble Learning, EL)进行超短期充电负荷预测.一般的回归性预测方法只考虑到天气、温度、湿度等因素的影响,并未考虑到电动汽车基础设施需求的特异性.电动汽车充电负荷需求具有时空不确定性、随机性,且电动汽车配置参数存在个性化差异,为超短期充电站负荷的精确预测带来了挑战.为解决上述问题,使用占用资源极低的轻量级梯度提升框架(Light Gradient Boosting Machine, LightGBM)构建基础充电负荷,预测基础回归器群;为进一步提升预测精度,使用提升集成方法对基础回归器群进行集成,在经过多次迭代和超参数调整后构成最终的充电负荷预测模型.
1 EEB-LGBM预测框架
能量集成轻量梯度提升框架(Energy Ensemble Boosting-Light Gradient Boosting Machine, EEB-LGBM)结构包括2层,即基础回归器群生成层和集成决策层.基础回归器群生成层的作用是学习构建后的数据集的特征,并生成数个具有差别的基础回归器构成基础回归器群.集成决策层的作用是对基础回归器群进行串行优化,在合并后输出最终模型用于超短期充电负荷预测.EEB-LGBM预测框架的结构如图1所示.结构中的各个参数及其意义如表1所示.
他注意到,随着改革开放的深入,再加上医生忙碌的客观事实,关爱正在逐渐淡化。“我们希望鼓楼医院的价值理念中多一点点关爱。而这种关爱不仅仅局限于父母亲人,而是一种大爱,即关心服务的每位患者。”


在EEB-LGBM预测框架中,初始的样本划分将影响因素、噪声数据与真实充电负荷数据同步输入进行训练集划分,并对每一轮生成的基础回归器的参数进行记录,在下一轮时通过计算出的回归权重不断进行串行迭代并更新自身参数,以此不断优化,最终集成为基于EEB-LGBM预测框架的超短期充电负荷预测模型.
在用该结构进行超短期充电负荷预测时,用实际充电负荷数据、影响充电负荷的相关因素和随机噪声数据构成原始数据集.将原始数据集进行权值划分后用于训练基础回归器,并搜索基础回归器的最优参数进行并行化优化,数个基础回归器构成基础回归器群进行多次迭代,最终集成为用于超短期充电负荷预测的最终模型,从而进行超短期充电负荷预测.

在整个集成过程中基本回归器()错误回归的样本权值增大,而被正确分类样本的权值减小,以此完成自我优化和纠错,最终回归模型的加权过程如图2所示.


(1)

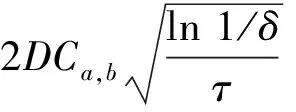
(2)

来自样本和特征的扰动将增加基础学习器的多样性,有助于提高泛化性能,但同时也会导致训练流程中误差的叠加增大.为减小特征选择时造成的误差,同时避免重复特征和零特征构成的不必要计算,引入EFB特征选择策略进行特征束的构建.通过向特征要素的原始值添加偏移来保证特征的排他性,使得驻留在不同的面元中的特征聚集,将具有排他性的特征捆绑到更少的密集特征上,以此构建特征束.
区内褶皱构造不甚发育,总体上表现为一向东偏南倾斜的单斜构造,由于应力作用的影响,局部可见到层间小揉皱构造及勾状构造。
基础回归器群易受到偏差-方差权衡的影响,而使用自适应提升(Adaptive Boosting, Adaboost)方法进行集成,可以在维持模型方差和偏差平衡时增加模型的预测能力,避免因单一模型过于依赖训练集,使得在测试集上测试与真实预测时产生回归精度降低、结果失真等问题.在初始化构建完成数据集的权值分布后,对每一个基础训练样本都赋予相同的权值:

利用数据挖掘技术分析HIF-1α在胃癌中的预后意义…………………………………孙美涛,自加吉,陈 莹,严长宝,戴莉萍,余 敏,熊 伟(32)

(3)
=1, 2, …,
式中:为基础回归器的权重和;1为基础回归器的初始权值;为权值分布的数量.基础回归器框架对权值更新后的训练数据集进行学习,得到原始回归器为

(4)
..影响充电负荷的条件因素 目前对于电力充电负荷预测研究大多考虑的气象影响因素有温度、湿度、降水、风向、风速等.但为了更加精细化和实时化地进行充电负荷预测,还需合并考虑连接时长、充电功率、车型配置、节假日等因素.本文使用 1~7代表星期一至星期日,节假日使用0和1进行二值化处理,车型分为纯电、混动,同样使用0和1进行二值化处理.

(5)
式中:为规范化因子.
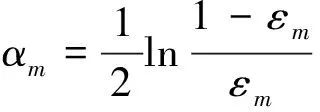
(6)
根据回归误差率更改每个基础回归器的权重系数,预测表现更好的基础回归器具有更高的权重.之后更新训练数据集的权值分布:
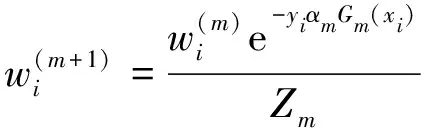
(7)

(8)
=1, 2, …,
每个基础回归器通过不同的权重系数集合为最终的回归模型,()在最终回归器中的权重系数为
在不断更新迭代后,根据权值将1~的所有基础回归器集合为最终回归器:

(9)
在推动水质不断变好的同时,2004年,淳安出台《关于加强千岛湖生态渔业管理的若干意见》,加码“保水渔业”的实施力度。
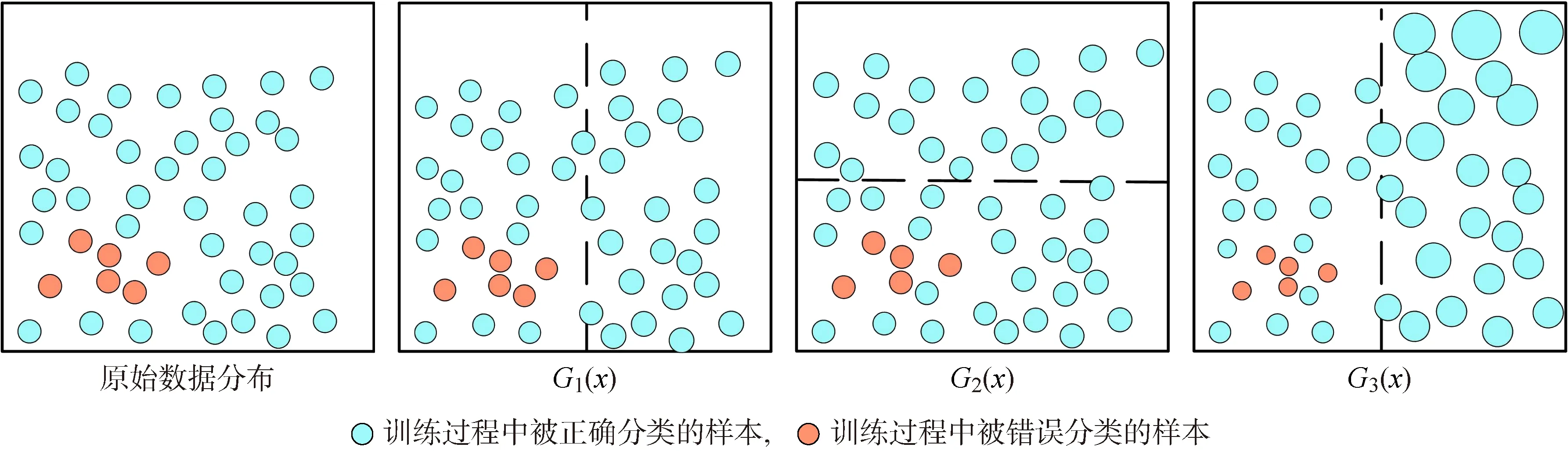
2 基于EEB-LGBM预测框架的超短期充电负荷预测模型
基于EEB-LGBM预测框架的超短期充电负荷预测模型主要包括数据集构建、回归器集成和充电负荷预测结果输出,其结构如图3所示.

在构建数据集部分需要确定数据集的大小和特性,选用合适的方法进行数据清洗,为训练部分划分原始训练数据.随机噪声数据为函数生成具有正态分布的变量,与原始训练数据共同输入后使得训练后的模型具有更强的稳定性.充电负荷的影响条件包括气候数据、日期类型数据、连接时长数据等.实际充电负荷数据为充电站监测得到的真实充电站充电负荷数据.在训练超短期充电负荷预测模型的过程中,采用LightGBM结合提升结构生成最终模型,用于超短期充电负荷预测.首先,将实际充电负荷数据、影响条件数据、随机噪声数据同步进行数据清洗后输入集成模型训练部分划分原始权值.其次,基于原始权值数据集生成数个基础回归器,以此构成基础回归器群后进行串行集成,在集成过程中不断迭代优化,最终使得整个基于EEB-LGBM预测框架的充电负荷预测模型达到最优.
为了探究模型效果,使用训练好的超短期充电负荷预测模型进行充电负荷预测,并与其他超短期充电负荷预测模型的预测结果进行对比.所有对比模型使用相同方法构建的初始数据集进行训练,输出1 d的预测曲线,并与真实值进行对比,观察模型拟合度.进行对比实验时,使用回归决定系数()、平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)、均方根误差(Root Mean Square Error, RMSE)、训练时间(Time to Training, TT)作为评价指标,对比不同模型的性能.
2.1 数据分析与处理
..实际充电负荷数据 实际充电负荷数据来源于充电站系统的实时采样,单站10个采集点,超短期充电负荷预测输出为未来24 h的充电负荷.为选择合适的基础回归器群框架与集成方式,对数据进行库克距离分析是有必要的.库克距离分析常用在最小二乘回归当中对数据点的影响进行评估,也可以用于检查数据集当中不同数据点的影响力,其计算公式如下:
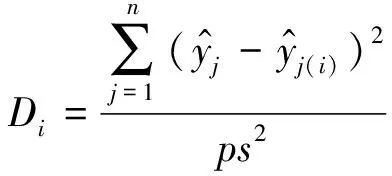
(10)
Previous papers have found that the prevalence of hospital undernutrition varies between 27% to more than 50% depending on the identification criteria, the medical or surgical setting and the age of the patients[6-10].
又写作“牢络”。《释名·释衣服》:“畱,牢也。幕,络也。言牢络在衣表也。”《释名疏证补·释衣服》:“先谦曰,留、牢双声。《淮南本经》注,除人读牢为霤,霤从雨留声。《士丧礼》注,牢读为楼,楼、留声近,皆其证也。络、幕叠韵。”由此可知“牢络”与“留幕”声相近,义相通。高明《琵琶记·几言谏父》:“名缰利锁,牢络在海角天涯。”《琵琶记·激怒当朝》:“羁縻鸾凤青丝网,牢络鸳鸯碧玉笼。”以上“牢络”均有“覆盖”之义。


回顾性分析2008年1月~2014年12月在本院接受手术治疗的80例GustiloⅢA、B型胫骨开放性骨折患者的病历资料。其中,27例接受非扩髓带锁髓内钉(unreamed tibial nail,UTN)固定,22例采用锁定加压钢板(locking compression plate,LCP)固定,31例接受单侧外固架(unilateral external fixator,UEF)固定。三组患者一般资料详见表1,三组在年龄、性别、损伤机制等方面的差异均无统计学意义(P>0.05)。

(11)

..数据预处理 在统一进行原始权值计算前,需要对数据集进行预处理,以便模型快速提取特征进行学习.对于缺失特征使用中位数估计函数插补,对于多级别特征根据轮廓系数标准使用均值聚类算法进行压缩,对于插补完成的所有特征使用鲁棒缩放将特征映射到[0, 1]区间上进行规范化,公式如下所示:
2.2 集成模型训练与优化
基础回归器群框架的选择对于最终模型的性能有较大影响,因此,对于所有适用于超短期充电负荷预测问题的共16种回归模型,使用相同的经过预处理构建完成的数据集进行训练,在相同的评价指标下进行对比.为适应超短期充电负荷预测问题,评价指标权重最大,生成时间次之,其他评价指标的权重依次减小.在所有框架中LightGBM框架在精确度上略微领先,但在训练时间上表现出极大优势,因此使用LightGBM框架学习数据集构建数个基础回归器.对于基础回归器群的单个基础回归器,以最优为目标进行多次迭代和参数优化,之后将优化好的基础回归器群输入集成层.对于LightGBM框架选取生长最大深度、叶片节点个数、缩分实例、随机部分特征、L1正则化、L2正则化等参数构建参数搜索空间.在超参数空间的参数搜索方法选择树状结构帕仁估计(Tree-Structured Parzen Estimator, TPE)算法,首先根据损失函数对超参数进行排序,并使用分位数对全体超参数进行分组.分别对优化表现较好的超参数组和优化表现较差的超参数组进行核密度估计,给定较好组有更高的被选择概率,较差组有更低的被选择概率.最后,经过优化效果评估后继续分组,不断迭代,最终输出经过最优表现超参数组合优化后的基础回归器群.为加快超参数搜索优化过程,对进行TPE算法搜索的超参数搜索空间使用MongoDB结构构建数据库,转为并行化搜索,进行超参数搜索过程优化,如图5所示.

将经过优化的基础回归器群进行权重计算,以其中具有最大损失函数的回归器为目标增大优化权重进行迭代,构建集成预测模型.同样以最优为目标,以基础回归器群的最优数量、基础回归器的权重缩减系数、误差函数计算方式为超参数,构建MongoDB结构的超参数存储空间,使用TPE算法进行并行化搜索,进一步优化其预测精度构成最终的超短期充电负荷预测模型.
2.3 评价指标
回归模型的评价指标决定系数比对称平均绝对百分比误(Symmetric Mean Absolute Percentage Error, SMAPE)、均方误差(Mean Square Error, MSE)、RMSE、平均绝对误差(Mean Absolute Error, MAE)和MAPE等更具信息量和真实性,并且没有MSE、RMSE、MAE及MAPE对回归模型进行性能评价时的可解释性限制,甚至可以对比不同研究领域当中不同回归模型的性能.因此在选择基础回归器框架和集成框架时,给予更大的参考权重,在接近时同时参考MAPE、RMSE、TT等指标,各评价指标的计算公式如下:

(12)

(13)
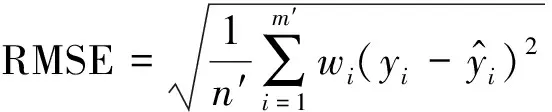
(14)
3 实验结果及对比
3.1 实验数据准备
使用Foundation E-Laad.nl(ElaadNL)在2019年实测某充电站的电动汽车充电负荷需求数据以及气象、日期类型数据构建数据集.ElaadNL充电站包括充电桩、快速充电器、电池、充电灯和 IOTA 三相充电器,每相电流至少为16 A,充电功率为11 kW.充电站由不同的用户群体共享,白天的用户群体主要为办公室工作人员,下午或晚上为游客,深夜主要为附近居民,同时还有一些特定的用户群体,如出租车、共享汽车或市内物流.实测充电负荷数据集主要为连接类型、连接时长、充电功率、充电桩编号、总耗能,由充电站系统实时采集.温度、湿度、气压等气象数据采集频率为1次/h,再合并随机噪声数据后构成原始数据集.其中70%为训练集输入模型进行训练,剩余30%为测试集.对基础回归器群与集成方式都进行10折交叉验证进行性能对比.
c)当C(px,y)==C(px-1,y)且C(px,y)==C(px,y-1)时, 表示块px,y和上邻域块以及左邻域块之间均存在跨块缺陷, 此时将上邻域的标号赋值给块px,y; 另外, 如果Label[x,y-1]≠Label[x-1,y]表明左邻域和上邻域的标号存在冲突, 需要将其记录在等价标号关系表中。
3.2 模型构建实验
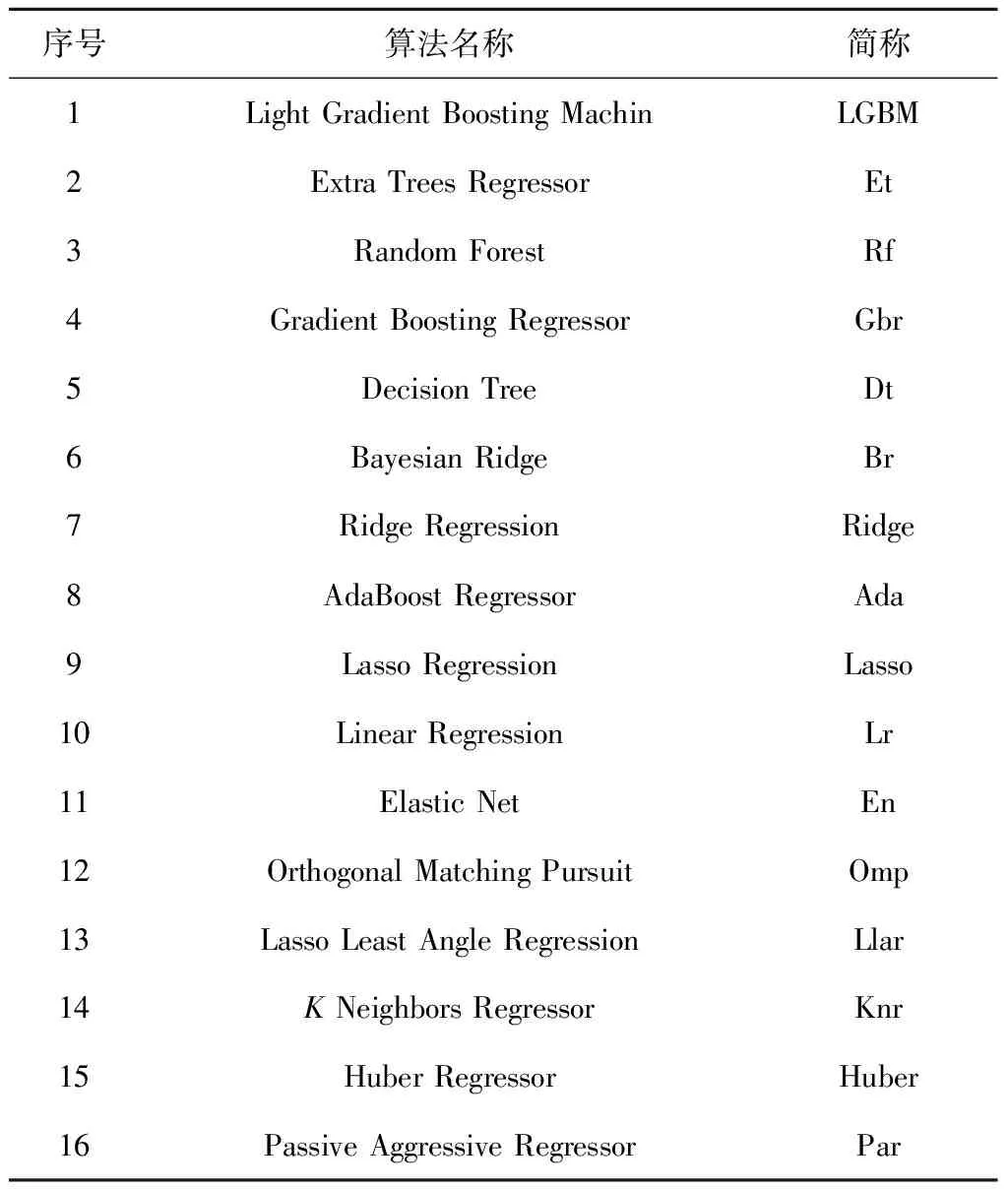
..基础回归器性能对比与选择 在基础回归器群的构建过程中,针对充电站充电负荷的超短期回归预测共选取了16种回归算法构建基础回归器进行比较.这16种算法的全称与对应简称如表2所示.选取的16种算法在构建后的相同数据集上进行训练,使用10折交叉验证在相同的测试集上验证所有模型的性能,在相同指标下降序排列,其结果如表3所示.
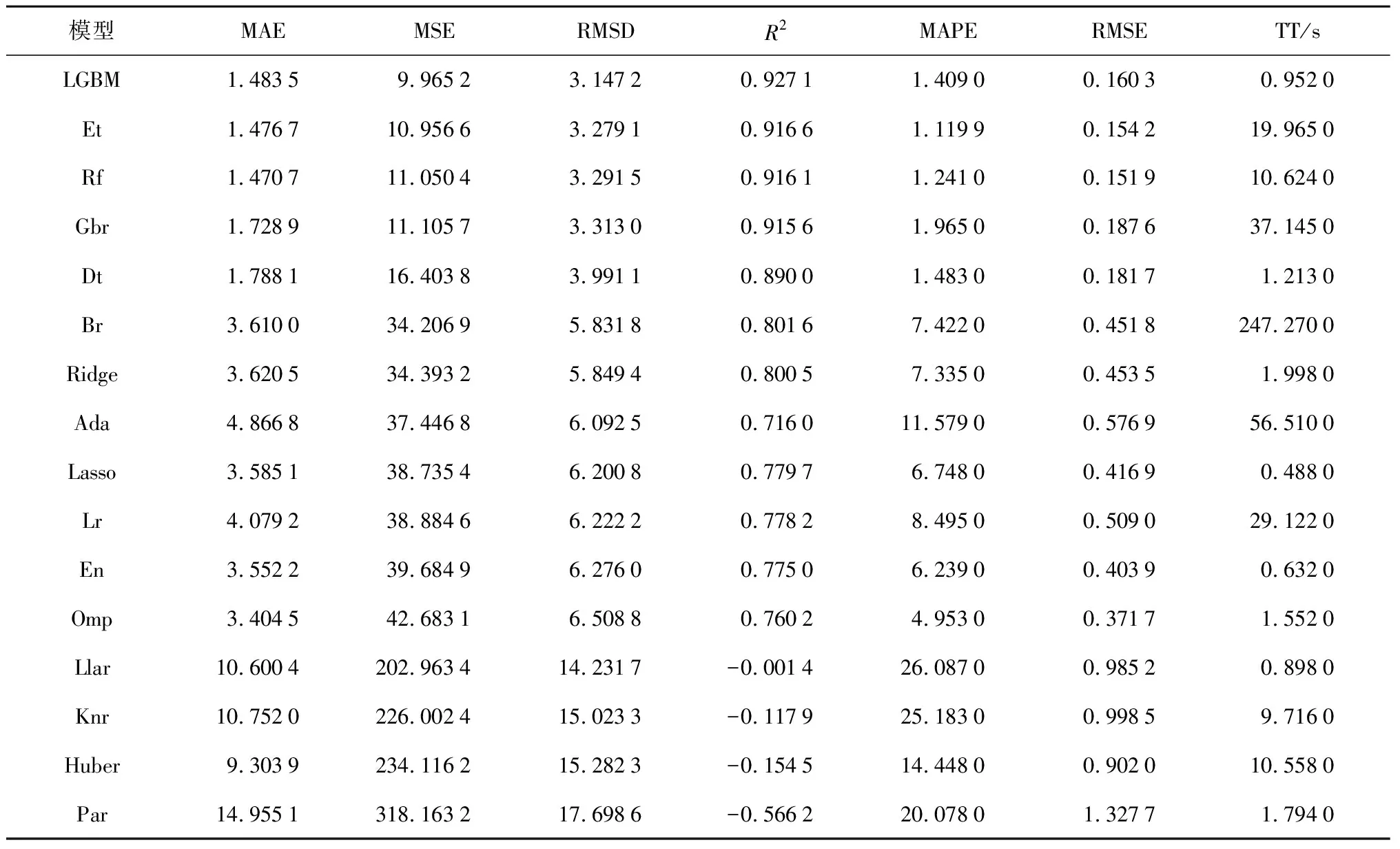
在充电站充电负荷超短期预测这一特定的应用场景上,LightGBM框架表现出极大优势:在精确度领先的情况下,其训练时间缩短为Et、Rf等算法的1/260~1/20,大幅增加了调控速度,更适合面对超短期尺度上的充电负荷预测问题;同时计算资源需求大幅度缩小,降低了充电站的构建、维护、检修、扩容的成本.
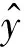

异构集成算法要结合3种不同的算法构建最终预测模型,因此在训练时间上大大落后于同构集成算法,且充电负荷预测的正确率提升并不明显.混合结构准确率提升至95.31%,堆叠结构产生了模型冲突,使得结果失真.在同构结构中,提升结构具有最高的准确率,达到97.23%.在袋化类结构中,采用多个基础回归器并行投票原则进行集成,因此当基础回归器对某个特征点不敏感时,会出现基础回归器群中的所有基础回归器在学习时都出现错误,导致最终回归器同样不能正确学习到该特征点的特征.但在提升类结构的串行集成过程中,后一个基础回归器会对前一个基础回归器不敏感的特征点加大训练权值,因此避免了袋化方式在预测时不断输出同一错误点的缺陷,具有自我纠正能力.因此选择提升方法对基础回归器群进行集成,构成最终的超短期充电负荷预测模型.
3.3 EEB-LGBM预测框架的性能分析
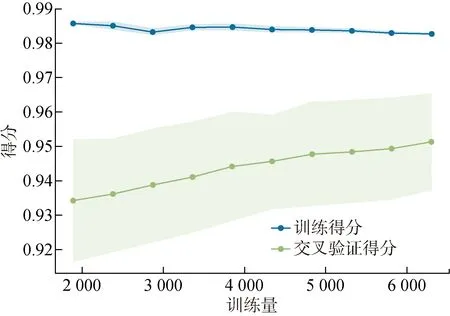
通过学习曲线和残差分析可以观察分析生成的模型对数据的利用效率与预测稳定性.学习曲线将模型在训练集上的损失函数的最优值与在验证数据集上评估的损失函数作对比,验证数据集的参数是否与产生最优函数的参数相同,同时可以观察到对数据的利用效率.计算基于EEB-LGBM预测框架的超短期充电负荷预测模型的学习曲线,可以观察到该模型对训练数据的需求量小,初始训练时收敛速度快,随着训练数据的不断增大,准确率稳步提升,在6000条数据时模型的整体准确率接近峰值,具有良好的泛化能力,其学习曲线如图7所示.
残差计算可以验证模型的残差是否与随机误差存在一致性,体现回归模型在面对真实随机数据时预测能力的稳定性.残差验证结果的可视化如图8所示.在对基于EEB-LGBM预测框架的模型进行残差计算后可以观察到,该模型在面对随机分布的误差时显示出了极高的稳定性,在训练集上预测精度达到了99.12%,在测试集上精度达到了97.23%.

3.4 充电负荷预测模型对比
为对比EEB-LGBM的实际预测能力,将其与使用反向传播神经网络(Back Propagation Neural Network, BPNN)、卷积神经长短期记忆网络(Convolutional Neural Networks-Long Short Term Memory, CNN-LSTM)、差分自回归移动平均模型(Autoregressive Integrated Moving Average Model, ARIMA)构成的充电负荷预测模型进行性能对比.各模型均使用相同的充电负荷数据集以及相同的充电负荷条件影响因素数据集进行训练,输出某一天的预测值与实际充电负荷值进行对比,其结果如图9所示.结果表明,虽然各预测方法都可以预测到充电负荷的变化趋势,但本文所提出的基于EEB-LGBM预测框架的超短期充电负荷预测模型与实际充电负荷曲线具有最高的拟合率.各对比预测方法在测试集上的决定系数、MAPE以及TT如表4所示.


4 结语
目前的超短期负荷预测模型具有准确率欠缺、时间尺度过长、训练时间长、计算资源需求大等缺点,同时未针对电动汽车充电站充电负荷的特点进行优化.本文提出的基于集成学习的双层预测框架进行超短期充电负荷预测方法通过LightGBM构建高性能的基础回归器群,对充电负荷数据集进行学习,以提升类同构结构进一步提升预测精度,并使用MongoDB构建超参数空间,TPE算法进行并行化超参数搜索进行优化,最终构成超短期充电负荷预测模型.对比实验证明,提出的基于EEB-LGBM预测框架的超短期充电站充电负荷预测模型,相比BPNN、CNN-LSTM、ARIMA预测模型不仅提高了预测精度,且显著缩短了训练时间,降低了计算资源需求,同时具有训练数据需求小、收敛速度快、泛化能力强的优点,能够满足充电站超短期电力充电负荷预测的高效性、稳定性及经济性等要求.
本文使用的提升类结构的串行集成方式在训练时间上还具有进一步优化空间.为更好满足超短期充电负荷预测对预测效率的高要求,后续工作将进行串行集成结构改善,以期进一步缩短模型的训练时间,加快预测响应速度.
猜你喜欢
煤气与热力(2022年4期)2022-05-23
煤气与热力(2022年2期)2022-03-09
小资CHIC!ELEGANCE(2022年1期)2022-01-11
环球时报(2020-12-08)2020-12-08
小资CHIC!ELEGANCE(2019年5期)2019-04-30
现代职业教育·职业培训(2019年12期)2019-02-03
电子技术与软件工程(2018年11期)2018-02-25
商界评论(2016年12期)2016-12-08
中学生数理化·八年级数学北师大版(2008年1期)2008-08-27
