
勘探开发数据智能质量检查方法研究
2022-08-23 07:16李春生陈思宇张可佳
计算机技术与发展 2022年8期
李春生,陈思宇,张可佳,富 宇,刘 涛
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
勘探开发数据作为重要的生产开发数据,其数据质量的优劣将直接影响到后续的油田开发生产过程。为此人们开展了对油田数据质量检测方法的研究。文献[1]针对油田开发数据特点,研究数据内部机制,围绕数据库建设全过程,建立完整的质量控制体系,实现数据查错排错,有效控制数据质量。文献[2]通过对油田开发数据的错误类型和产生原因进行分析,提出在数据生命周期中建立质量监控标准规范并设置质量控制点。文献[3]在技术方面,对元数据技术、数据模型驱动技术等展开分析研究和运用。文献[4]针对油田开发规划引入突出影响因子的非线性模糊综合评价,从传统评判方法例如模糊评判方面,首先要克服主要影响因素被忽略的弱点,又强调了利用线性模糊评判的优点。文献[5]通过数据库应用模型构建技术,实现了专业应用在信息方面的有效支持。在异常检测方面,文献[6]对传感器网络异常检测进行了综述,文献[7]提出了基于深度学习的视频异常检测方法,并总结了其他领域的一些异常检测方法。综上所述,现存的油田质量控制方法都是对数据模型、数据库建设方面进行研究,未对相应的质检规则进行相关研究。因此,选用机器学习技术结合专家系统推理机制进行数据质检是勘探开发数据质量检查领域的趋势。
1 勘探开发数据智能质量检查模型架构
该文结合专家系统及机器学习相关知识,构建勘探开发数据智能质量检查模型。模型分为数据层、推理学习层、应用层三个层次,具体模型框架如图1所示。
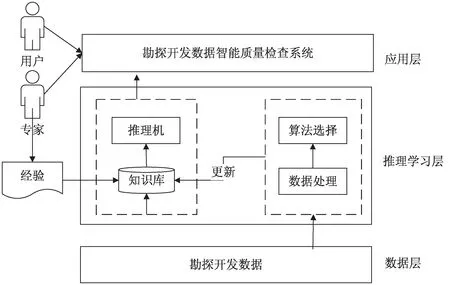
图1 勘探开发数据智能质量检查模型
上述模型中数据层为机器学习和系统应用层提供业务数据,知识库用于存储根据专家经验得到的质检规则,并及时地为推理机提供推理所需的知识。推理机作为程序模块用于执行推理、搜索等操作。由于专家系统不具备从经验中学习的能力,无法自动修改知识库,因而通过机器学习的方式调整、更新知识库。
2 知识库构建
2.1 标准值获取
由于专家给出的经验相对模糊,且油田数据受地理位置、地貌特征等因素影响,专家经验可能会产生一定的偏差,因此需对数据进行分析,得到更准确的规则。该文以孔隙度、渗透率、砂岩厚度、有效厚度为例,获取它们的标准值。
(1)采用k-means聚类算法对孔隙度、渗透率进行聚类得到聚类的中心点作为标准值,聚类结果如图2所示,其中x轴为孔隙度,y轴为渗透率,以相别为分类标准,分为4类,其中*所代表的为某一相别孔隙度和渗透率的中心点。第一类中心点坐标为(0.000 6,0.138 4),第二类中心点为(22.703 8,0.060 2),第三类中心点为(27.389 6,0.204 8),第四类中心点为(30.495 5,0.533 5)。
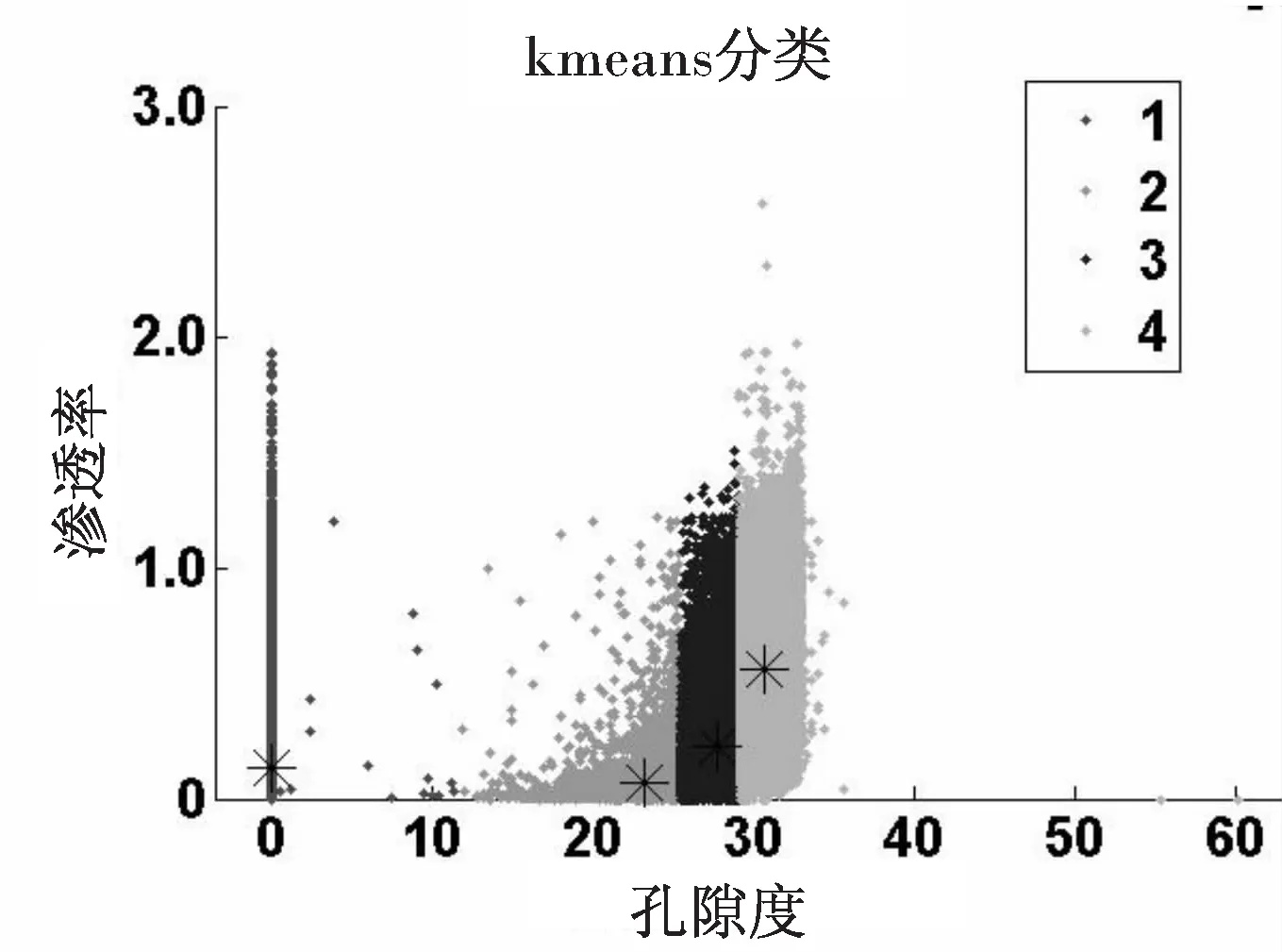
图2 k-means算法结果
(2)选取临近井获取其有效厚度和砂岩厚度的均值当作标准值。使用公式如下:
(1)
得到有效厚度的均值为2.875,砂岩厚度的均值为0.9,以此作为规则的标准值。
2.2 知识库设计
知识库是专家系统的核心,是专家系统有别于传统软件系统的标志[8]。知识的数量与质量是决定专家系统性能的关键因素[9]。
知识获取是初建知识库要完成的工作。知识获取是指将问题求解的知识从相应的知识源中提取出来,转换为特定的计算机语言,其实质就是知识库建立的过程。该文将现场工作人员提供的专业知识结合数据分析的结果解析成相关的规则,建立知识库。知识库建立的前期基础为知识表示,知识表示就是通过使用不同体系对客观世界进行归纳和描述[10],选择合适的知识表示方式有利于系统更好的应用,目前被广泛使用的知识表示方式有产生式规则表示法、语义网络表示法、谓词逻辑表示法、框架表示法、面向对象表示法,由于产生式规则法的表达方式符合勘探开发数据质检流程,故该文采用产生式规则法对规则进行描述。产生式规则通常用如下方法表示:IF P THEN Q,P表示条件,Q表示结论或动作,具体含义:若条件P得到满足,则可以推出结论Q[11]。
2.3 规则库的建立
对于勘探开发数据中涉及的众多的规则条目,将所有规则条目以规则前件和后件形式录入数据库中,以孔隙度、渗透率、有效厚度和产液量数据为例,建立如下所示的规则库,其中包括知识表、规则前件表、规则表、规则后件表、结果表。以知识表、规则表、结果表为例,具体描述如下:
(1)知识表用于存储油田相关的术语,并对其进行解释,用于规则判断时的前提条件。满足此前提条件规则方可生效,知识表见表1。
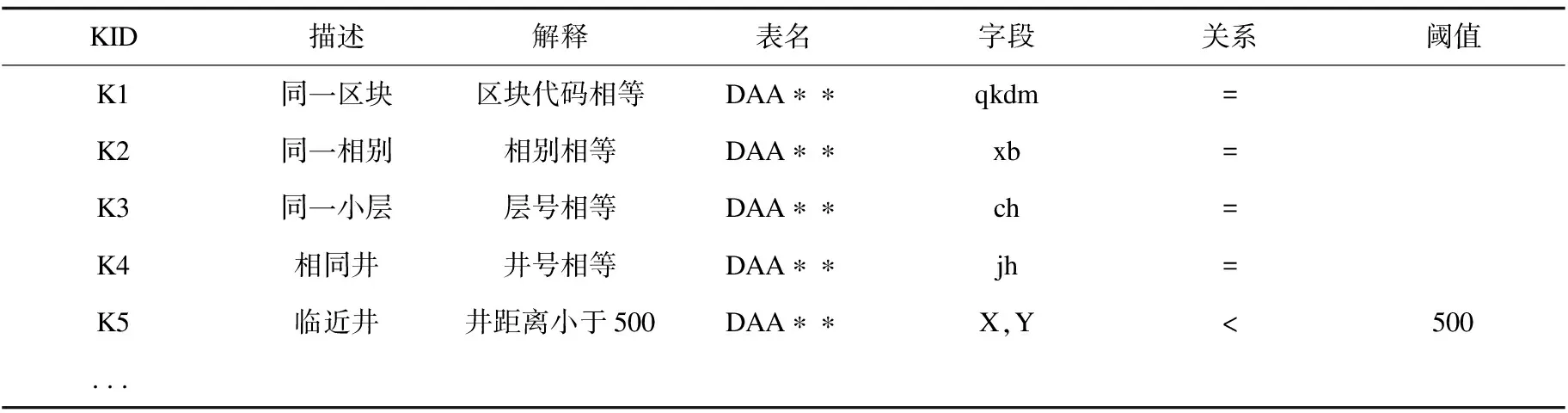
表1 知识表
(2)规则表用于描述质检所需的规则,其中特征为检测的字段名称,标准值为参照数据,阈值为判断数据异常的门限值,特征逻辑表示与门限值的关系。规则表见表2。

表2 规则表
(3)结果表用于描述质检结果,给数据异常一个相应的解释,若解释合理则数据为非异常数据,若无解释则根据上述规则判定为异常数据。结果表包含RSID、特征、特征逻辑、阈值、判断结果,特征为表中字段名,阈值可为表名或标准值,特征逻辑为包含、相等或不相等等逻辑关系,通过特征、特征逻辑和阈值来解释数据异常原因。结果表见表3。

表3 结果表
(4)规则前件表和规则后件表的简要描述如下 :规则前件表用于描述知识表和规则表的对应关系,包含ID、KID、RID字段,其中KID为知识表的ID,RID为规则表ID;规则后件表用于描述规则表和结论表的对应关系,包含ID、RID、RSID字段,其中RID为规则表ID,RSID为结果表ID。
以产液量为例进行如下描述:首先在规则表中获取相关产液量的规则,得到其规则ID,然后在规则前件表和规则后件表中找到该规则ID对应的KID和RID,找到其对应的知识表和结果表中的数据。最终得到的完整规则为:同一口井的月产液量变化率大于30%且本井不存在于注水库中则数据异常。
2.4 知识库更新
将需检测的数据进行检测得到质检结果后,通过现场人员的反馈,对知识库进行更新,主要更新规则库中的阈值,使知识库中的知识不断优化,质检的准确率不断增强。该文采用机器学习中不平衡分类阈值调整算法对知识库进行更新。知识库的更新过程如下:
Step1:提取质检结果和反馈结果,构成混淆矩阵。
Step2:将不同阈值情况下的多个混淆矩阵用ROC曲线表示。
Step3:得到约登指数,计算阈值。
Step4:更新知识库。将计算好的阈值更新到规则库中的阈值字段中。
3 推理机实现
专家系统主要通过系统的推理机来实现推理功能,推理机运用其推理方法对知识进行利用,通过其推理流程和推理控制策略完成知识的完整推理。推理机主要由推理方法、推理流程、推理控制策略等组成[12-13]。其问题解决算法可以区分为3个层次[14]。
3.1 推理方法
推理是人工智能的一项重要技术,比较常见的推理方法有基于案例的推理、基于规则的推理以及模糊推理。该文采用基于规则的推理方法,该方法将专家知识和经验转换为计算机中用于推理的规则框架,从一组前提推出一组结论。规则推理的一般推理步骤如图3所示。
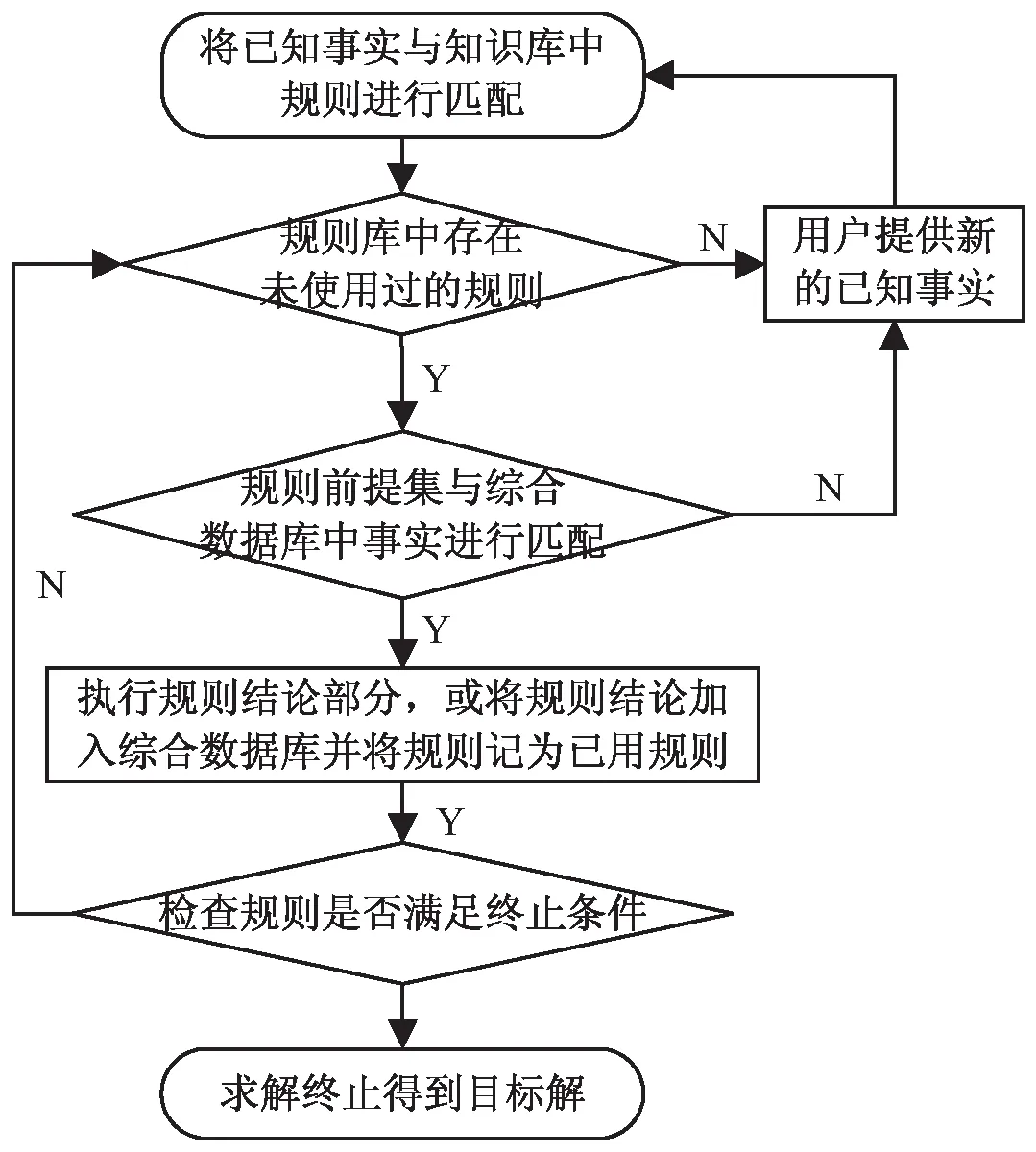
图3 规则推理步骤
3.2 推理流程
在勘探开发数据质检系统设计中,将专家的知识和经验抽象为若干规则,构建规则库并进行推理,推理流程如下:
Step1:检查字段的录入,操作人员将需要检查的字段输入到专家系统中,由专家系统进行检查。
Step2:检查字段的识别,将检查字段与知识库中规则表进行匹配,如果匹配成功,则将检查字段替换为规则编号,再进行下一步推理,如果匹配不成功,说明知识库中缺少该字段的知识,此时提醒用户输入新的字段重新进行检查,或者对规则库进行扩充。
Step3:进行推理,使用规则的编号查找匹配的知识,使用知识来进行推理,最后输出检查结果。
3.3 推理控制策略
推理机设计实现的过程不仅要考虑推理方法,还应该选择正确的推理控制策略,推理控制策略有前推式、回溯式[15]及双向式3种。推理控制策略会影响求解的效率和准确性,其包括推理方向、冲突消解策略等。
3.3.1 推理方向
推理机作为问题求解的主要手段,其推理方向对其求解过程有很大影响,选择合适的推理方向能大大提高推理效率。常用的推理方向包括正向推理、反向推理、正反向混合推理,正向推理是由原始数据出发,按照一定策略,运用知识库中专家的知识,推断出结论的方法。这种推理方式由于是由数据到结论,由于勘探开发数据库质检的过程即知识推理的过程,因此该文采用正向推理的推理方向。
3.3.2 冲突消解策略
冲突消解策略可实现从知识库的多条可用知识中合理地选择一条知识。在数学问题的求解过程中,冲突消解策略常采用深度优先或广度优先策略,其基本思想是先启用某一条知识,如果知识在执行过程中失效,再回溯其他知识。在专家系统求解问题环境中,这种策略的效率较低[13]。在专家系统中,一般采用简单直观的冲突消解策略,或添加启发信息来组合使用这些简单的冲突消解策略。简单冲突消解策略是将多条知识按优先级排序。常用的排序策略有专一性排序、知识库组织次序排序、据排序、就近排序、分块组织等。其中知识库组织次序排序是按照知识在知识库中的顺序得出优先级的次序,符合异常数据检测的顺序性,因此该文采用知识库组织次序排序的冲突消解策略,在知识库中为各条知识进行优先级排序。
4 实 验
4.1 数据选择
实验数据选择中西部高台子的现场工作人员提供的数据作为实验和测试数据,包括:小层信息、油井井史、连通关系、井基础信息等数据,对孔隙度、渗透率,有效厚度、砂岩厚度等静态数据,以及产液量等动态数据进行质量检查。
4.2 实验结果
4.2.1 专家系统检测异常数据实验
选取1 000条小层信息数据和井基础信息数据对孔隙度、渗透率、有效厚度、砂岩厚度、产液量进行检查。检查结果如表4所示,其中检查目标为异常检测的字段,实验结果为系统检查出的异常数据的条数,真实结果为实际异常数据的条数,正确数量为实验结果中检查正确的数量,阈值为检查标准,准确率为当前模型判断的准确率,其计算公式为:
准确率=判断正确的数量/数据量
(2)
其中判断正确的数量为:数据异常并且被判断为异常的数量与数据正确且被判断为正确的数量的总和,即下文中所提的TP和TN的和。

表4 异常检测结果
4.2.2 阈值调整实验
(1)依据不同阈值下的多个混淆矩阵画出的ROC曲线如图4所示,其中横轴为负正类率(false positive rate,FPR),纵轴为真正类率(true positive rate,TPR),其中TPR=TP/(TP+FN);FPR=FP/(FP+TN)。TP(true positive,TP)表示真正类即数据是异常并且被判断为异常;FN(false negative,FN)表示假负类即数据为异常但是被判断为正确;FP(false positive,FP)表示假正类数据非异常,但是被判断为异常;TN(true negative,TN)表示真负类即数据为正确数据且被判断为正确数据。根据ROC曲线获取TPR、FPR的最大差值即约登指数,取当前TPR、FPR的坐标,进而找到最优阈值。孔隙经、渗透率、砂岩厚度、产液量以及有效厚度的ROC曲线如图4所示,根据曲线得出的最优阈值如表5中的阈值所示。
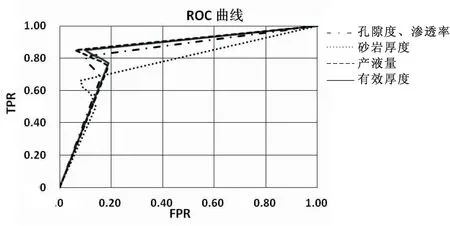
图4 ROC曲线
(2)将调整后的阈值更新到知识库后重新对数据进行检查,得到的结果如表5所示,通过表4和表5准确率对比可知:阈值调整后的准确率相比阈值调整前有所提高,为提高异常数据检查的正确率可进行多次阈值调整。

表5 阈值调整结果
5 结束语
该文将专家系统应用于勘探开发数据库质量检查中,通过建立知识库、推理机来进行异常数据的检查,同时使用阈值调整方法更新知识库进而提高质检准确率。通过真实数据验证其质检结果,证实提出的质检方法具有较高的准确率,且通过阈值调整可以提高质检准确率。因此,对勘探开发数据智能质量检查方法的研究具有一定的理论意义和应用价值。
猜你喜欢
电脑爱好者(2021年23期)2021-12-08
知识文库(2019年2期)2019-06-11
中国建筑科学(2016年11期)2017-02-28
中国科技纵横(2016年20期)2016-12-28
卷宗(2016年4期)2016-05-30
中国高新技术企业(2015年16期)2015-04-30
新世纪图书馆(2014年7期)2014-09-19
科学导报·学术论坛(2013年5期)2013-06-26
读写算·高年级(2009年3期)2009-11-16
