
基于机器学习算法建立胎母输血综合征预测模型*
2022-08-22 06:19范可欣朱鹏汇王云王勇军张宁洁
临床输血与检验 2022年4期
范可欣 朱鹏汇 王云 王勇军 张宁洁
胎母输血综合征(fetomaternal hemorrhage syndrome,FMH)是指一定量的胎儿红细胞经由破损的胎盘绒毛间隙进入母体血循环,造成胎儿不同程度的失血及母亲和胎儿溶血性反应的临床症候群[1]。严重的FMH可以造成新生儿严重贫血、胎儿非免疫性水肿等不良围产期结局,甚至危及胎儿生命,其占死产原因的14%[2]。然而,大多数情况下胎儿出血为持续发生且量较小,因此临床症状不典型、起病隐匿,临床医生普遍缺乏对该疾病的认识,从而导致早期宫内诊断困难[3],通常于不良孕产结局发生后才得到确诊。目前临床上尚无有效的预测FMH发生风险的手段。近年来,人工智能方法在医学领域发展迅速,利用机器学习算法建立精准的预测模型也已开始广泛应用于医学领域,为我们探究各种疾病、发掘新的研究角度提供了新的技术手段[4-6]。本研究拟基于机器学习算法构建FMH预测模型,旨在辅助临床诊疗中尽早识别诊断FMH并有效干预治疗。
材料与方法
1 数据资料 本研究纳入2019年6月~2020年12月于中南大学湘雅二医院产科进行产检的孕妇总共1933名。纳入标准为:孕周在6~42周(孕早期:6~12周;孕中期:13~27周;孕晚期:28~42周)在我院进行产检,并获得知情同意的孕妇(伦理批件编号:20191009)。排除标准:1)存在严重贫血、镰刀细胞性贫血、遗传性胎儿血红蛋白持续存在症、珠蛋白生成障碍性贫血的孕妇;2)由于非病理性原因终止妊娠的孕妇;3)未在我院生产的孕妇;4)可查阅的相关资料记录不完整的孕妇。相关定义:1)FMH:经过改良Kleihauer-Betke(K-B)试验[7]估算胎儿失血量超过2 mL的孕妇,即至少有2 mL胎儿红细胞转移到了母亲血液循环的孕妇;2)大量胎母输血:将胎母输血量高于30 mL的患者定义为大量胎母输血;3)产前血红蛋白:是指该妇女分娩前48 h内所测得的血红蛋白水平。
2 数据收集 本研究收集了已知或推测可能与FMH发生相关的特征变量。主要包括孕产妇的一般情况(年龄、身高、体重、胎龄、怀孕次数、妊娠次数、流产次数、围产期增加体重、单胎/双胎、是否为体外人工受精、产时孕周)、产前检查情况(孕妇血红蛋白水平、孕妇ABO血型、孕妇Rh血型、孕妇血小板抗体检测、孕妇甲胎蛋白水平、孕妇血红蛋白F(HbF)水平、孕妇血清炎症细胞因子水平(IL-2、IL-4、IL-6、IL-10、TNF-α、IL-17A)、胎盘分级、羊水指数、脐动脉阻力、胎心监护情况)、孕妇合并症及并发症(疤痕子宫、妊娠期糖尿病、妊娠期高血压、妊娠合并子宫肌瘤、妊娠合并贫血、胎膜早破、前置胎盘、是否存在生殖道感染)、产妇分娩情况(生产方式、产时出血)、围产儿结局(Apgar'1分钟评分、Apgar'5分钟评分)等。
3 FMH实验室诊断检测 随机收集2019年6月~2020年12月来医院做产检的孕妇EDTA抗凝全血标本利用改良版的K-B试验进行初筛,取收集到的EDTA抗凝全血制作血涂片,选取成年男性抗凝全血标本作为阴性对照,取同型脐带血作为阳性对照。并进一步估算胎儿失血量。初筛阳性的孕妇血样采用流式细胞术进行验证[8]。流式细胞术所用FITC-抗HbF单克隆抗体试剂盒购自美国Invitrogen公司,流式细胞分析仪FACSCalibur购自美国BD公司。
4 预测模型的建立 本研究通过对患者数据进行收集构建数据集,并对数据进行清洗,剔除离群值,对于缺失值多使用多重插补进行估算,而对于缺失比例过高的特征变量,为了不影响模型结果判断予以剔除。本研究主要使用递归特征消除法(recursive feature elimination,RFE)对FMH预测中的关键特征变量进行筛选。
为了能够更好地构建、验证模型,本研究将所收集到的数据随机分成训练集(70%)和测试集(30%)。在训练集中采用RFE筛选出的特征变量,采用包括了极端梯度提升决策树(eXtreme Gradient Boosting,XGBoost)模型[9]、梯度提升决策树(gradient boosting decision tree,GBDT)模型[10]、随机森林模型(random forest,RF)[11]、K近邻算法模型(k-nearest neighbor,KNN)[12]、自适应提升算法模型(adaptive boosting,Adaboost)[13]、朴素贝叶斯模型(naive bayes,NB)[14]、支持向量机模型(support vector machine,SVM)[15]、多层感知器模型(multi-layer perceptron,MLP)[16]以及逻辑回归模型(logistic regression,LR)等9种方法来构建模型,并对所构建的模型性能进行对比。由于部分模型不能自动处理缺失值,因此,我们使用多重插补的方法来对缺失值进行填补。
5 统计学分析 本研究中的实验数据主要运用SPSS 25.0、Python 3.6进行统计分析:1)服从正态分布的计量资料用平均值±标准差(mean±SD)表示,采用t检验进行组间比较;2)不服从正态分布的计量资料采用中位数±四分位数表示,采用Mann-Whitney U非参数检验进行组间比较;3)计数资料使用频数(%)来表示,卡方检验或Fisher确切概率法用于组间比较(P<0.05即差异为具有统计学意义)。机器学习预测模型采用Python软件包进行建模,十折交叉验证主要用于模型效能验证,评价指标选择受试者工作特征曲线下的面积(AUC),其面积越大,则表明模型的预测效能更好。
结果
1 临床资料 本研究纳入2019~2020年在中南大学湘雅二医院进行产检的1933名孕妇血液进行K-B试验检测,排除患有相关血液疾病、未在我院分娩的181名孕妇后,最终纳入1752名孕妇资料进行分析(图1所示)。

图1 纳入排除标准流程图
2 胎母输血预测模型构建 研究中将1226名(70%)孕妇的数据作为训练集进行模型构建,526(30%)名孕妇的数据作为验证集。在训练组中,128名(10.44%)孕妇在围产期发生了FMH,1098名孕妇没有发生FMH。在验证组中,54名(10.27%)孕妇在围产期发生了FMH,472名孕妇没有发生FMH。根据表1不难发现,各特征变量在训练集和测试集中的分布均不具有统计学差异。

表1 胎母输血综合征预测模型训练集、测试集数据分布比较
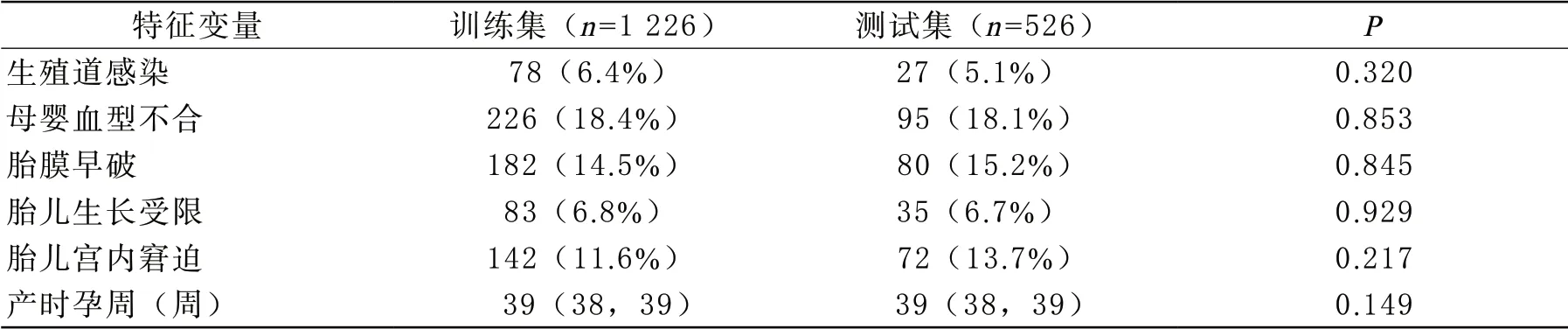
续表1
3 胎母输血预测模型性能比较 纳入所采集特征指标(表1)及回归分析所得的危险因素(高龄、双胎妊娠、怀孕次数更多、妊娠伴有子宫肌瘤、行人工体外受精、胎儿生长受限、妊娠伴子痫前期),运用RFE再次对特征变量进行筛选,分别采用8种机器学习算法和传统逻辑回归模型对孕妇是否在围产期发生胎母输血进行预测。其模型性能效果如图所示,通过十折交叉验证对其分别进行验证,发现XGBoost模型表现出明显的预测优势,其测试集AUC为0.808,准确率达0.76。其性能明显优于AUC仅为0.681的传统逻辑回归模型和其他7个机器学习模型(如图2)。

图2 构建的9种预测模型AUC比较
模型性能结果比较详见表2,根据约登指数,建议模型XGBoost的最佳预测概率临界值为0.74,灵敏度和特异度分别为0.75和0.80。逻辑回归模型LR的最佳cutoff值为0.74,其灵敏度仅为0.55,特异度为0.76。
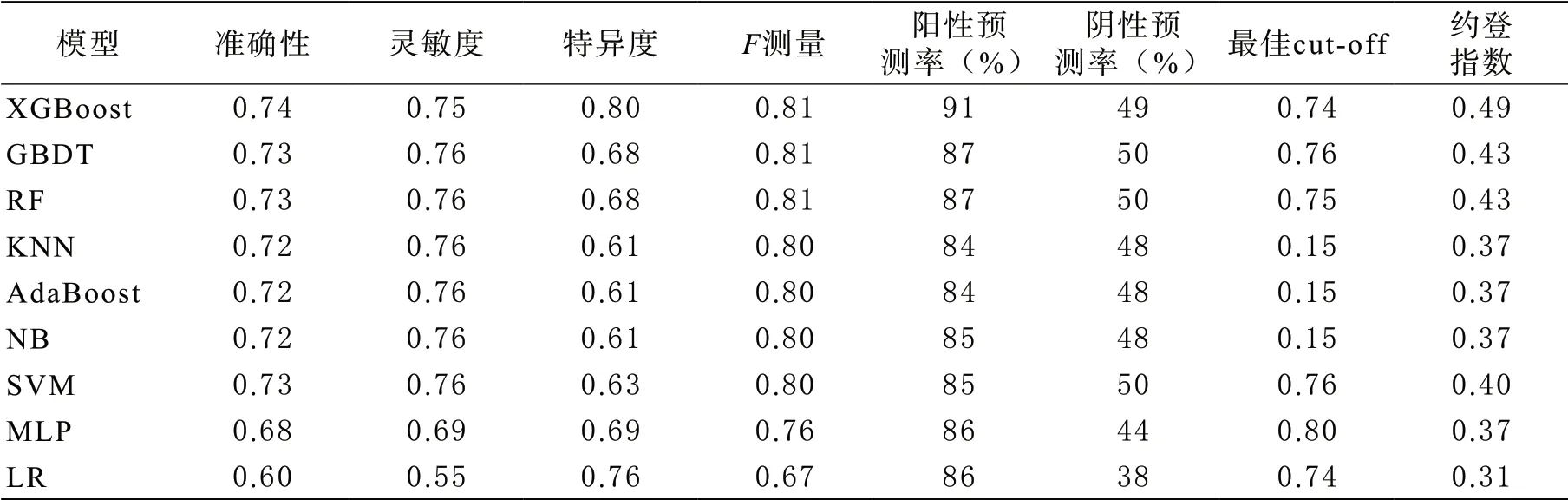
表2 九种模型预测性能比较
讨论
由于缺少特异性的诊断标准,FMH的早期诊断十分困难,因此常被临床医生所忽视。临床上常常是出现胎儿宫内生长受限、水肿甚至死胎后,才得到诊断。随着人工智能技术在医疗领域的广泛使用,基于机器学习算法建立精确的预测模型已广泛应用于心脏手术、骨科、儿科等领域,CHEN等[6]基于机器学习算法和生存分析相结合建立对IgA肾病结局进行预测的模型;AL'AREF等[17]利用机器学习算法不仅挖掘出了接受经皮冠状动脉介入治疗患者相关危险因素中的一些新联系,而且还实现了对该类患者住院死亡率的预测;JO等[18]使用梯度提升机算法建立了全膝关节置换术后输血的预测模型,显示出良好的预测性能。该技术具有高效、高精准性、能够有效挖掘隐藏在海量数据中隐藏关系等特点。能够直接应用于个体是机器学习的一大优点,特别是在处理像医疗问题这样的复杂的大数据时,它比传统的统计学方法有更多的优势,其不仅能从多个数据模块中进行学习,有效地识别与患者结局相关的变量、准确地预测相关危险因素、从复杂的数据中探索规律并建立数学模型,而且,还可以在验证的过程中具有反复校正的能力[19]。
本研究纳入2019~2020年在中南大学湘雅二医院进行产检的1933名孕妇血液进行K-B试验检测,排除患有相关血液疾病、未在我院分娩的181名孕妇后,最终纳入1752名孕妇资料进行分析。随后通过对患者数据进行数据集构建,并对数据进行清洗,剔除离群值,对于缺失值多使用多重插补进行估算,而对于缺失比例过高的特征变量,为了不影响模型结果判断予以剔除。由于在机器学习中不同特征变量对于结果的影响存在差异,因此,为了提升模型的精确性、降低模型的复杂性,需要针对与预测结局相关的特征进行筛选。本研究主要使用RFE对FMH预测中的关键特征变量进行筛选,最终得到年龄、体重、羊水指数等特征变量,随后将1226名(70%)孕妇的数据作为训练集进行模型构建,526(30%)名孕妇的数据作为验证集。在训练集中采用RFE筛选出的特征变量,采用包括了XGBoost模型在内的9种方法来构建“胎母输血综合征预测模型”,并对所构建模型的性能进行对比。由于部分模型不能自动处理缺失值,因此,我们使用多重插补的方法来对缺失值进行填补。通过十折交叉验证对9种方法分别进行验证,发现XGBoost模型表现出明显的预测优势,其测试集AUC为0.808,准确率达0.760。其性能明显优于AUC仅为0.681的传统逻辑回归模型和其他7个机器学习模型。
本研究发现所建立的XGBoost模型具有较强的区分性,预测性能好,表现出令人满意的特异性和敏感性。该模型的成功建立,我们后续可以利用所构建的模型,映射到可视化网页,医生仅需要通过网页输入孕妇相关信息,便可得到其是否有发生FMH的风险,从而及时帮助临床医生识别高危人群,减少漏诊的风险。此外,还可以针对不同孕妇的孕周和疾病严重程度对其制定个体化诊疗方案,尽早对患者进行救治,从而改善胎儿不良妊娠结局。
本研究尚存在一定的局限性,首先,本研究仅对单中心数据进行研究分析,所建立的模型并不具备普适性,有必要扩大样本量、纳入其他中心的数据对模型进行完善。总之,本研究运用8种机器学习算法和传统逻辑回归模型构建了预测孕妇围产期是否发生FMH的模型,并分别对其性能进行了比较,从而挑选出一款综合预测性能最佳的模型,探索FMH的早期预测方法,对FMH的早期临床诊断和早期干预具有积极意义。
利益冲突所有作者均声明不存在利益冲突
猜你喜欢
中国典型病例大全(2022年10期)2022-05-10
健康体检与管理(2021年10期)2021-01-03
特别健康·下半月(2020年2期)2020-03-13
Coco薇(2015年1期)2015-08-13
分忧(2014年9期)2014-09-22
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
中学生数理化·七年级数学北师大版(2008年5期)2008-10-14
小学教学参考(数学)(2006年7期)2006-12-31
祝您健康(1991年2期)1991-12-30
