
全局关系注意力引导场景约束的高分辨率遥感影像目标检测
2022-08-19 02:54吴鑫嘉赵晓蕾
电子与信息学报 2022年8期
张 菁 吴鑫嘉 赵晓蕾 卓 力② 张 洁
①(北京工业大学信息学部 北京 100124)
②(北京工业大学计算智能与智能系统北京市重点实验室 北京 100124)
③(中国地质大学(武汉)资源信息工程系 武汉 430074)
1 引言
高分辨率遥感影像目标检测技术对人们提炼地表有用信息,充分发挥遥感数据效用具有重要的研究意义和实际应用价值[1]。近年来,以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习方法,在高分辨率遥感影像目标检测中表现出优良的性能[2]。
基于深度学习的目标检测方法大致分为两类[3],一是以R-CNN, Fast R-CNN, Faster R-CNN为代表基于区域生成的二阶段方法,二是以YOLO, SSD为代表基于回归的一阶段方法。遥感影像具有背景复杂,目标分布密集、方向多变且尺度差异的特点,需要根据这些特点改进深度网络以完成遥感影像目标检测任务。Wang等人[4]提出了一种端到端多尺度视觉注意网络,通过关注目标区域的细节信息,改善了遥感影像背景复杂、目标分布密集的问题。Cheng等人[1]基于R-CNN提出了旋转不变的CNN模型,训练网络学习到具有旋转鲁棒性的特征。在我们已有的研究工作中[5]提出了一种多尺度特征融合检测网络(Feature fusion and Scalingbased Single Shot Detector, FS-SSD)用于无人机影像的小目标检测,通过加入反卷积层和平均池化层组成特征金字塔,经过特征融合完成多尺度特征预测。此外,我们还提出一种联合通道注意力和旋转不变深度特征的高分辨率遥感影像多尺度目标检测方法[6],在FS-SSD基础上加入通道注意力和方向响应卷积,获得旋转不变性的深度特征。
高分辨率遥感影像中地物目标和所处场景类别息息相关[7],而现有的检测方法较少考虑场景-目标的关联关系和总体认知关系,因而检测性能仍有提升空间。已有一些学者利用场景和目标的上下文关系改善目标检测性能,如Liu等人[8]通过融合场景和物体之间关系信息提出了结构推理网络,在提升目标检测任务的性能上发挥了很大作用。Zhang等人[9]提出全局关系注意力模块(RGA),通过充分利用图像中的全局结构信息,来获得特征的注意力权重,在行人再识别中取得了优异性能。这些研究结果表明,借助场景信息可以有效提高目标检测性能。
为此,本文提出全局关系引导场景约束的高分辨率遥感影像目标检测方法。主要贡献如下:
(1) 与现有的高分辨率遥感影像目标检测方法不同,提出利用全局关系注意力学习全局场景特征作为约束,通过建立场景信息和地物目标的关联关系指导目标检测任务。
(2) 在场景约束条件下,利用方向响应卷积模块和多尺度特征模块,生成兼具旋转不变和多尺度的目标特性信息,实现更准确的目标定位和分类。
(3) 通过交叉熵分类损失和定位损失的加权和联合优化目标检测网络,达到更优的预测性能。
2 提出的方法
本文提出的全局关系引导场景约束的高分辨率遥感影像目标检测方法(OR-FS-SSD+RGA)总体架构如图1所示。以FS-SSD为基础网络,首先将遥感影像图片输入VGG16网络,在其之后加入全局关系注意力模块RGA,捕获全局的结构化关系信息;然后将全局场景特征作为约束输入方向响应卷积模块和多尺度特征模块,获得旋转不变的深度特征和多尺度预测特征图;最后利用损失函数优化网络实现高分辨率遥感影像目标检测。

图1 全局关系引导场景约束的高分辨率遥感影像目标检测方法(OR-FS-SSD+RGA)
2.1 全局关系引导的注意力
注意力机制旨在加强有区分度的特征和弱化无关的特征,但现有研究更多关注图片局部信息。如前所述,Zhang等人[9]提出全局关系注意力对行人再识别性能的提升具有很好的推动作用。而高分辨率遥感影像的目标检测方法也较少考虑场景信息和地物目标之间的关联关系,忽略了图像中有价值的全局上下文信息。此外,遥感影像目标往往具有多个尺度,文献[5]提出的FS-SSD目标检测网络对多尺度目标预测效果尤为突出。为此,本文在FSSSD目标检测网络中加入全局关系注意力模块,包括全局空间关系注意力/全局通道关系注意力,通过提取全局场景特征作为约束获得全局场景上下文信息。
全局关系注意力结构如图2所示,输入图像由前端网络处理后得到特征图,特征图中的特征向量作为原始特征表示为特征节点xi∈RL,其中i=1,2,···,N,N为特征数量,当前特征节点与其他所有特征节点之间的成对关系用r表示,将原始特征与成对关系拼接组合得到全局关系特征y。以特征节点x1举例来说,图中x1与其他特征节点之间的成对关系表示为r1=(r1,1,r1,2,···,r1,N),将x1与成对关系r1拼接组合得到全局关系特征y1=[x1,r1]。同理,全部特征节点可以产生所有全局关系特征y(y1,y2,···,yN),y作为全局注意力的特征向量用于计算全局关系注意力权重值(a1,a2,···,aN)。
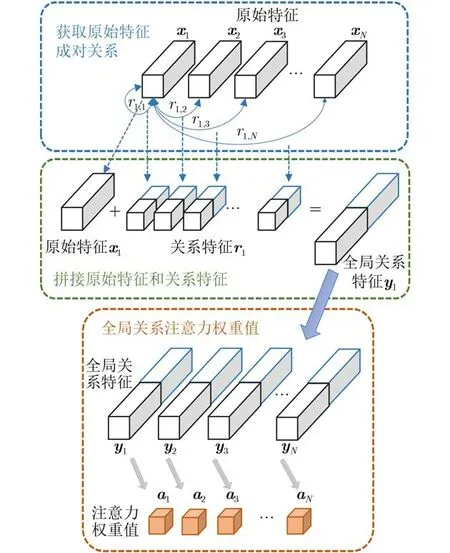
图2 全局关系注意力结构
这种成对特征关系的学习由于结合了所有特征位置的关系,可以很好地表示整张图片的全局场景特征,为此本文将依此建立全局关系来引导场景注意力的实施。下面将重点介绍全局空间关系注意力和全局通道关系注意力。
2.1.1 全局空间关系注意力
全局空间关系注意力是在特征图的空间维度上学习各个特征节点,对所有特征节点之间的成对关系进行紧凑的表示,得到在空间上具有全局化的结构信息。本文方法就是在目标检测网络中加入全局空间关系注意力(RGA-S),以获得整张遥感影像在空间上的全局场景信息作为场景约束。全局空间关系注意力的结构如图3所示,具体实现过程为:
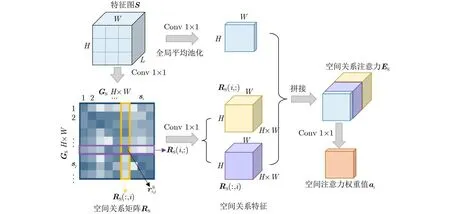
图3 全局空间关系注意力
步骤1 输入特征图S∈RL×H×W,将特征图中每个空间位置的L维特征向量作为特征节点si∈RL(i=1,2, ···,N, N=H×W),形成一个节点图GS。


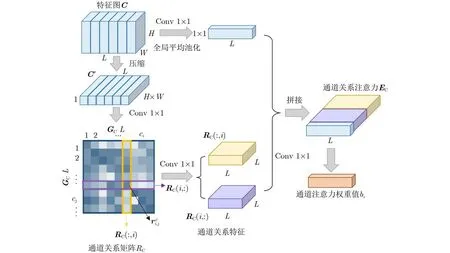
图4 全局通道关系注意力
步骤4 连接原始特征和通道关系矩阵,使通道关系注意力同时获得全局结构信息和局部原始信息:

2.2 场景约束的高分辨率遥感影像目标检测
将全局场景特征送入方向响应卷积和多尺度特征模块,生成兼具旋转不变和多尺度的目标特性信息,实现更准确定位和分类。最后通过交叉熵分类损失和定位损失的加权和联合优化目标检测网络。
2.2.1 方向响应卷积模块和多尺度特征模块
方向响应卷积模块包括4层大小为3×3的方向响应卷积(ORConv6_1, ORConv6_2, ORConv7_1,ORConv7_2)和Alignment特征编码(ORAlign)。方向响应卷积由主动旋转滤波器ARF构成,产生具有方向通道的特征图,使用ORAlign编码方式将具有方向性的特征图编码,使获得的特征具有旋转不变性。将遥感影像全局关系结构特征输入方向响应卷积后,得到在场景约束条件下旋转不变的深度特征。
多尺度特征模块包括反卷积层、平均池化层和特征融合3个部分。反卷积层包括3个卷积核大小为2×2的反卷积层和1个3×3的卷积层,用于提高特征图的空间分辨率,使得经过多层卷积的遥感影像特征图信息得到有效保留,之后加入平均池化层可以得到更加紧凑的特征信息。特征融合中将Conv4_3,FC7和ORConv6_2融合在一起,这样获得的遥感影像目标特征同时具备低层视觉信息和高层语义信息。在获得场景约束下的遥感影像目标特征之后,使用平均池化层和多尺度特征融合中最后的6个卷积层,共7个特征图作为预测特征图,特征图尺寸大小如表1所示。

表1 OR-FS-SSD+RGA最终预测特征图尺寸
2.2.2 网络目标损失函数
由目标检测网络得到目标的深度特征后,比较网络输出和实际标注框的目标类别、位置信息,计算分类损失和定位损失的加权和来联合优化网络。本文分别使用交叉熵损失Lconf和Smooth L1损失Lloc作为分类损失函数和定位损失函数,对于任意目标u,交叉熵损失函数Lconf可以表示为其中,N为匹配的候选框的数量,α用于调整分类损失和定位损失之间的比例,默认设为1。

3 实验结果与分析
3.1 实验步骤
3.1.1 数据集
本文实验采用西北工业大学标注的NWPU VHR-10[10]数据集。数据集包含10类目标,2934个实例,共800张图片(650张包含目标,150张为不包含目标的背景图片),其中715张通过Google地图获得,空间分辨率在0.5~2 m,其余85张图像是锐化的彩色红外图像,空间分辨率为0.08 m。输入网络图片大小为512×512,由于原始数据集数据量较小,容易产生过拟合现象,考虑到高分辨率数据特点,本文采用水平和垂直的镜像以及亮度调节的数据扩充策略,扩充为原来的6倍,60%作为训练集,20%验证集,20%测试集。
3.1.2 实验设置
实验使用Ubuntu16.04操作系统,NVIDIATITAN XP加速处理器进行加速,Pytorch作为深度框架,SGD优化算法进行优化,VOC07+12预训练模型作为初始化,超参数设置如表2所示。

表2 网络超参数设置
性能评价指标使用平均检测准确率(mean Average Precision, mAP)和检测速度(frames per second, fps)。
3.2 实验1:不同注意力模块对目标检测性能影响
本实验以OR-FS-SSD网络为基础,测试了分别加入不同注意力模块对目标检测准确率和速度的影响。为了简化表示,加入不同模块的网络记为“+模块名”,结果如图5所示。OR-FS-SSD是在FS-SSD中加入方向响应卷积的检测网络,获得93.86%mAP和29.50fps;+SE采用SENet[11]中的SE模块,使用经过空间全局平均池和两个非线性的全连接层的特征计算通道注意力,获得92.93%mAP和26.93fps;+CA采用DANet[12]中的通道注意力模块CAM,在局部特征建立丰富的上下文依赖关系,获得94.74%的mAP和29.57fps;CBAM[13]是从通道和空间两个维度获取注意力的模块,该模块和+ CBAM-C(仅通道),+CBAM-S(仅空间) 的mAP分别为92.78%, 93.53%和93.77%,检测速度分别为25.81fps, 27.77fps和27.88fps;本文方法通过关注全局场景信息检测目标,+RGA, +RGA-C(仅通道)和+RGA-S(仅空间)的mAP分别达到93.90%, 94.74%和95.59%,检测速度则为28.80fps,28.18fps和30.07fps。
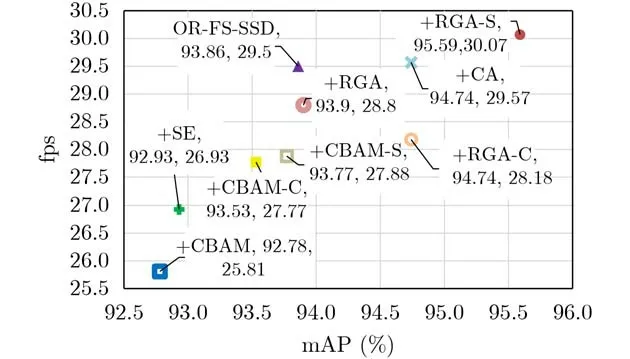
图5 不同注意力模块的检测结果
分析上述结果,在OR-FS-SSD网络基础上,各模块检测效果表现为RGA-S优于RGA-C优于RGA, CBAM-S优于CBAM-C优于CBAM,即CBAM和RGA均在仅使用空间注意力模块时效果最好。一般来说,遥感影像场景往往比较复杂,具有较强的空间分布规律,空间信息会显得更为重要,而空间注意力表达的是同一通道上不同位置的结构信息,可以使场景特征不受通道维度的影响。若同时使用空间和通道注意力,会使得空间特征和通道特征相互影响反而降低了检测效果。
3.3 实验2:每类目标检测准确率对比
本实验选取实验1中检测准确率较高的+SE,+CA, +CBAM-S和本文的+RGA-S共4个网络进行比较,每类目标准确率对比结果如图6所示。可以看出,本文方法+RGA-S在飞机检测上和其他方法相比有明显的提升,达到99.32%的检测准确率,这是因为在检测过程中加入场景信息作为约束,有效捕获了图像中的全局结构信息,而其他3种方法仅在局部范围内获取特征图的注意力权重值。对于棒球场、网球场、篮球场和田径场这些类目标,4个网络的检测准确率均达到99%以上,因为这些目标所在的场景类似,场景约束对其检测性能的提升并不明显。由于海港所在的场景较明显,+RGA-S很好地学习到了海港的场景特征,获得99.45%AP,相比+SE和+CBAM-S的网络准确率提高了8.57%和8.84%。4种方法在船舶、储油罐、桥和车辆的检测中准确率普遍较低,只有90%左右,尤其是车辆检测,这是由于其形态多变且所处的场景较复杂。综合来看,本文方法在目标检测中加入场景信息作为约束,对一些典型场景的目标检测性能是有作用的。
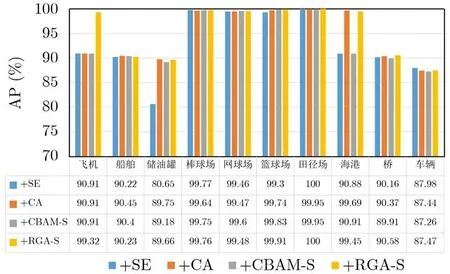
图6 4个网络中每类目标检测准确率
3.4 实验3:目标检测的主观检测结果
为更直观展示所提方法的检测性能,图7示出了FSSD, FS-SSD, Faster-RCNN, +CA和+RGA-S的主观结果。由于FSSD, FS-SSD, Faster-RCNN是用于常规图片的目标检测方法,对飞机、储油罐、桥和车辆等遥感影像目标存在漏检现象,检测准确率不高,Faster-RCNN对储油罐和车辆等分布密集的目标存在大量检测重叠框。+CA可以学习遥感影像目标方向不变性和尺度不变性的特征,在检测飞机上取得了较好的性能。本文+RGA-S方法利用场景信息作为约束对飞机实现了更精确的检测,检测出了所有的飞机目标,获得比其他方法更高的分类置信度。

图7 FSSD, FS-SSD, Faster-RCNN, OR-FS-SSD+CA和OR-FS-SSD+RGA-S的主观结果对比
3.5 实验4:和其他主流网络的检测性能对比
本实验选取表现最好的+RGA-S方法与其他主流网络的目标检测方法进行了性能比较,如表3所示,本文方法达到最高的95.59%mAP和30.07fps,Faster-RCNN检测精度高但速度较低,YOLOv3相对较好地权衡了检测速度与精度,两种方法分别获得mAP为93.10%和91.04%,检测速度为0.09FPS和14.68FPS。+CA[6]通过挖掘各个通道之间的相互依赖关系获得更具区分度的目标特征,获得mAP为94.74%和29.57%fps,已经取得了很好的性能,但没有利用场景类别和地物目标的关联关系。相比YOLOv3, Faster-RCNN和+CA,本文方法的mAP分别提高了4.55%, 2.49%和0.85%,检测速度提高了15.39fps, 29.98fps和0.5fps。LCFFN[14], GBD[15],CBD-E[16]和ORSIm[17]是专门用于遥感影像目标检测的网络,尽管mAP均在90+%,但是算法复杂度都比较高,fps仅为0.35, 2.2, 2和4.72。本文网络相比这4种方法检测准确率分别提高了1.92%, 1.64%,0.61%和0.2%,检测速度大幅超过了这4种方法。

表3 和主流网络的检测准确率对比
经过综合比较,本文方法利用方向响应卷积和多尺度融合策略,获得了目标旋转不变和多尺度特征,采用RGA-S在空间上提取遥感影像的全局场景信息,获得更好的目标检测性能。
4 结束语
本文提出了一种全局关系注意力引导场景约束的高分辨率遥感影像目标检测方法。以FS-SSD目标检测网络为基础,加入全局关系注意力模块,获得遥感影像的全局结构化信息;然后以全局关系引导场景约束,结合方向响应卷积模块和多尺度特征模块进行目标预测;最后利用两个损失函数联合优化网络实现目标检测,提升了目标检测性能。在NWPU VHR-10数据集上,和现有的深度学习方法相比取得了更好的检测性能,mAP达到95.59%,检测速度30.07fps,说明在场景约束下可以有效提升目标检测的整体性能。然而在一些所处场景复杂且变化较大的目标,检测性能提升并不明显,说明利用全局注意力来学习场景上下文信息仍有改进空间,之后将考虑在目标检测网络中加入门控机制来强化捕获全局上下文信息的能力,产生更鲁棒的场景特征表达,进一步提高目标检测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
军事历史(1986年4期)1986-08-21
