
利用移动窗口卷积神经网络反演土壤湿度
2022-08-18 08:53刘英何雪岳辉魏嘉莉
遥感信息 2022年2期
刘英,何雪,岳辉,魏嘉莉
(西安科技大学 测绘科学技术学院,西安 710054)
0 引言
土壤湿度(soil moisture,SM)是表征地-气间水分和热量蒸发变化的重要变量之一,是作物生长发育的必要条件。传统SM监测方法有烘干法、电阻法和中子水分仪法等,这些方法准确率高,但无法在短时间内获取大范围SM空间分布[1]。遥感可获取连续区域的SM分布情况,包括光学反演、热红外反演、微波反演。光学反演方法有反射率法、植被指数法等。光学遥感受云层、植被及气象条件影响,地物穿透力差,多用于裸地或低植被地区。热红外反演方法有热惯量法、温度植被指数法等[2-3]。热惯量法适合裸地或作物出苗期,在湿润地区使用受限,温度植被干旱指数法依赖于地表温度反演精度,结果存在不确定性与局限性。微波穿透力强且不受云层和大气影响,针对裸露地区,常用的方法有Dubois模型[4]、Chen模型[5]、Shi模型[6]、Oh模型[7]等经验半经验模型及物理光学模型[8]、高级积分方程模型[9]、几何光学模型[10]等理论模型。理论模型过于复杂,应用效率低,经验、半经验模型由特定地点数据建立,需大量实测数据,成本高且鲁棒性差。对植被覆盖区常用的方法有水云模型[11]和密歇根微波冠层散射模型[12]等,这些方法受粗糙度和植被覆盖的影响大,通常只适用于特定植被类型和植被生长期,对下垫面复杂的山区适用性较差。
机器学习具有黑箱特征,不指定回归函数形式,可进行任意的线性或非线性回归。国内外学者利用支持向量机(support vector machines,SVM)、随机森林(random forests,RF)、径向基神经网络(radial basis function neural network,RBF)、人工神经网络(artificial neural networks,ANN)等多种机器学习方法反演SM。上述浅层网络对输入数据经过较少层的线性、非线性处理,往往造成网络学习能力不足、局部最优、过拟合等问题。深度神经网络包含多层隐含层且具有深层非线性的特点,较浅层神经网络更具优势,其中影响力较大的就是卷积神经网络(convolutional neural network,CNN)。CNN此前多用于分类研究,近年来被用于SM反演。李奎等[13]利用多源遥感数据联合CNN实现了广域SM反演;韩颖娟等[14]利用一维卷积网络结合FY-3D遥感影像对宁夏进行了SM监测;Wang等[15]利用热红外波段反射率联合CNN反演SM,该模型精度较深度神经网络高。CNN常将单点特征作为网络输入,实际上存在像元位置偏移以及邻近地物反射辐射影响,利用单点特征反演SM并不合理。移动窗口常用于评价景观格局分析中的区域差异,将区域作为基本单元引入到SM特征处理中可一定程度上减小上述因素带来的影响。SM回归模型普遍建立在特定条件约束下的区域,而迁移学习可解决重训练中样本少、成本高等问题[16]。Zhu等[17]融合残差网络、双向长短期记忆网络及多头注意力模型构建预训练模型监测太湖溶解氧含量,通过模型微调将其应用到其他湖泊。Tariq等[18]基于残差神经网络,利用转移学习的方法对地铁站内PM2.5的连续变化进行预测。迁移学习虽能应用在回归预测的同类问题中,但对SM模型异地迁移的研究较少。
因此文章选择与SM存在显著非线性关系的变量,利用具有深度学习特点的CNN结合移动窗口对曼尼托巴农业区SM进行反演,与常用光学干旱指数方法做对比,并采用参数微调的方式将上述模型迁移到青藏高原那曲县,为少样本情况下SM监测提供新思路。
1 研究区及数据
1.1 研究区概况
曼尼托巴位于加拿大红河流域,中心地理坐标为-98.23°W、47.78°N,面积约26×48 km2(图1(a)),夏季炎热且光照充足,地势平坦开阔,适合作物生长。该地区主要发展混农经济,种植多为一年生作物,如油菜、大豆、小麦、玉米和燕麦等。那曲县(图1(b))位于青藏高原中部,平均海拔4 500 m以上,气候寒冷且相对干燥,年均降水为455.1 mm,中西部地形辽阔平坦,多盆地湖泊;东部属河谷地带,多高山峡谷,并有少量森林和灌木,东部植被覆盖好于西北部。
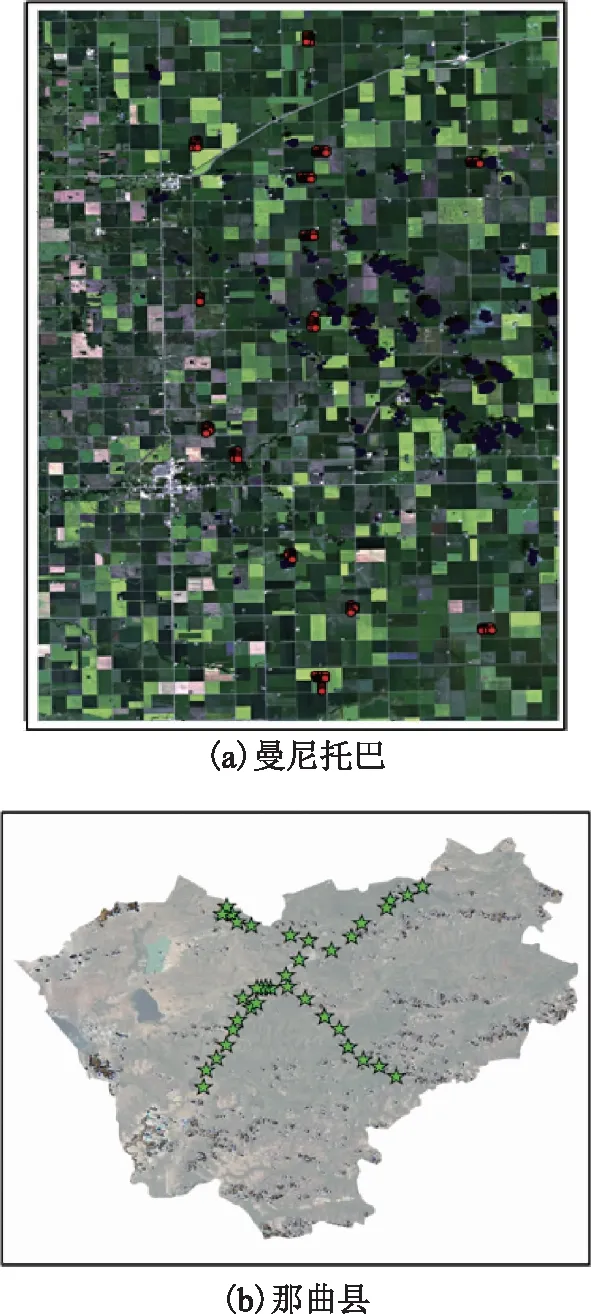
图1 研究区位置及实测点分布图
1.2 曼尼托巴地区实测数据
实测数据来源于SMAPVEX16数据集(soil moisture active passive validation experiment 2016)。文中用到的数据为实测SM。实测SM是利用Stevens Poke and Go装置垂直插入土壤表面收集50个农田和两个辐射计站点的真实介电常数数据并校准得到。每块农田有16个采样位置,每个采样位置按照5、10、20 cm深度平行观测三次,取不同深度测量均值作为SM实测值。
1.3 那曲县土壤湿度数据
那曲县SM实测资料来自荷兰特温特大学的青藏高原土壤温湿度观测数据集。统计38个实测站点2013—2016年间5、10、20 cm深处SM均值,剔除部分无效数据,获取SM实测数据91组。
1.4 Landsat 8
在美国地质调查局下载曼尼托巴2016年7月18日和那曲县2013—2016年间云量低于10%的Landsat 8 OLI/TIRS影像,空间分辨率为30 m。利用ENVI对数据进行辐射定标、大气校正及波段合成等预处理工作。
1.5 Sentinel-2数据
由于曼尼托巴实测SM值对应日期的Landsat 8影像少(只有一幅),利用Sentinel-2数据作补充。Sentinel-2A Level-1C是经正射校正和亚像元级几何精校正的大气上层表观反射率产品,需进行大气校正获得各波段真实地表反射率。通过Sen2cor模型生成Level-2A数据,在此基础上调用SNAP软件中的Sentinel-2工具箱模块进行重采样等操作,最终生成10 m、20 m空间分辨率地表真实反射率影像。表1为实测数据、遥感影像的详细信息。
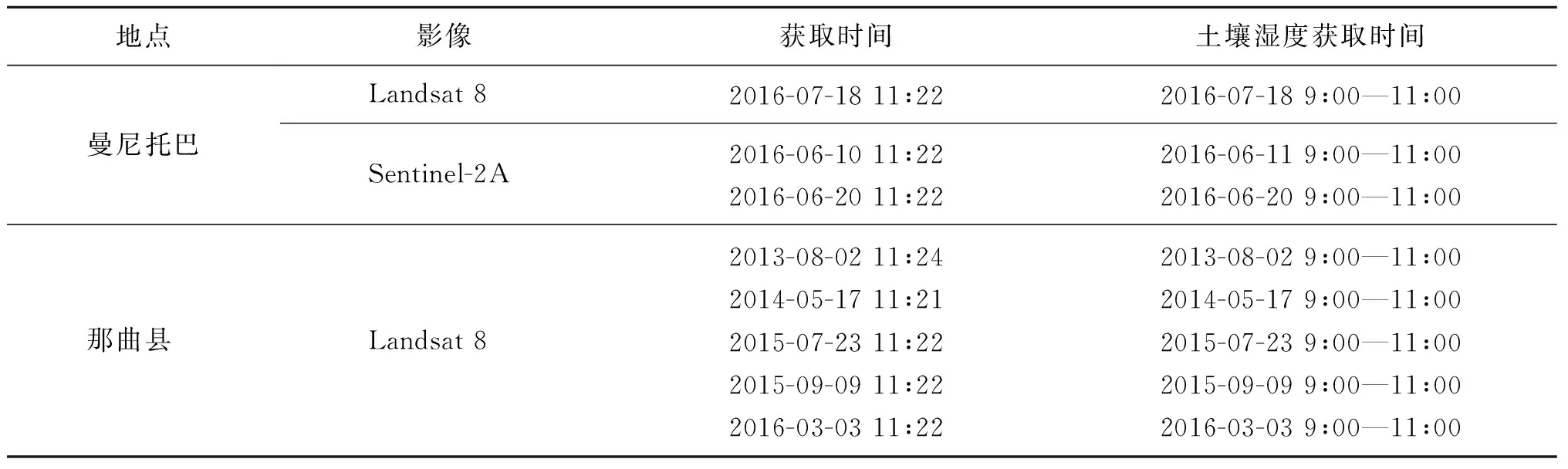
表1 实测数据和遥感数据信息
2 实验方法
2.1 土壤湿度网络建立
土壤水分不足会影响植被生长,间接引起植被指数发生变化;缨帽变换中的湿度指标一定程度上能反映土壤湿度信息[19];而地表反照率随SM增加呈现指数递减趋势[20-21]。现有的研究已经证明上述指标和SM有一定联系,因此本文将反射率及归一化植被指数(normalized difference vegetation index,NDVI)、增强型植被指数(enhance vegetation index,EVI)、反照率(albedo)、湿度指标(wet)作为输入特征。上述特征和实测SM按4∶1的比例随机划分训练集和验证集。那曲县数据处理同上。实验基于Tensorflow及Keras深度学习框架开发环境,使用GTX1050显卡加速完成。
网络构建过程如下:1)将NDVI、EVI、Albedo、wet、反射率组成一个三维SM特征变量输入网络中,经过卷积-批归一化(batch normalization,BN)-激活处理得到具有浅层语义信息的特征图,使用一维卷积核可以保持样本特征尺度不变的情况下增加非线性特征,实现通道间的信息交互。BN层是对卷积后的结果进行归一化,减少数据偏移的影响。添加激活层(Relu)进行非线性映射,缓解梯度消失,加速收敛。将其作为下一层的输入经过新一轮卷积运算,逐层递进得到最终特征,卷积核数量分别为64(2层)、128(2层)、256(3层)、128(1层)、64(1层)。2)将卷积提取到的特征展平(flatten)成为一个一维向量有序输入到全连接网络进行线性加权,采用阈值函数sigmoid将结果映射到输出,限制SM值在0~1之间。3)添加L2正则项,限制神经元中权重大小的同时最小化误差,防止过拟合。采用均方误差(mean square error,MSE)计算预测值与真实值之间的误差,采用Adam算法进行网络参数更新,卷积步长设为1,网络迭代次数设为2 000。使用early stopping监视器来监测模型的内在状态,防止过拟合。并行运算通道数设置为36。网络结构见图2。
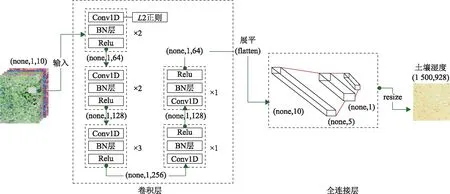
图2 土壤湿度提取网络结构
2.2 基于移动窗口的特征值建立
由于存在遥感像元的偏移(1~2个像元),利用单点数据模拟SM是不合理的,因此从景观生态学中引入“尺度”概念[22]。文章构造N×N像元(N为奇数)的移动窗口,将移动窗口按从左到右,从上到下的顺序在EVI、NDVI、Albedo、wet、反射率特征图像上滑动,将移动窗口内特征均值赋给中心像元,利用尺度化后的特征提取SM能一定程度上减小特征图像元偏移给精度造成的影响,削弱邻近地物反射光造成的辐射不均匀。新特征与SM的相关性较原始特征均有不同程度的提升。选取一系列不同大小的移动窗口对比发现,窗口大小设为3×3时SM的提取精度较高。
2.3 土壤湿度光学遥感反演
为验证所建立的SM监测模型的有效性,选择常见遥感干旱指数:土壤湿度监测指数(soil moisture monitoring index,SMMI)[23]、改进型土壤湿度监测指数(modified soil moisture monitoring index,MSMMI)[24]、垂直干旱指数(perpendicular drought index,PDI)[25]及改进型垂直干旱指数(modified perpendicular drought index,MPDI)[26],分析典型干旱指数与SM实测值的相关性。上述指数均基于NIR-Red特征空间构造,土壤线斜率利用研究区2016年6月10日和2016年6月20日Sentinel-2影像上部分裸土点(FVC<0.3)的nir和red波段反射率线性拟合得到,取值为1.445。
2.4 基于参数微调的迁移过程
目前,SM的研究主要集中在不同地区建立不同反演模型,若发生地区迁移,现有预训练模型不能直接应用于另一个地区,而重建训练模型需要对模型全部权重随机初始化及与模型参数量相匹配的数据集,会增加成本、降低效率。基于参数微调的迁移学习放宽了源任务和目标任务间数据独立同分布的假设,将已训练好的模型及参数通过简单的调整实现目标任务和原任务相近时知识的迁移,解决了样本少、训练成本高的问题[27]。将曼尼托巴训练得到的SM模型参数进行微调应用于那曲县SM反演。首先,对那曲县原始影像进行预处理,然后根据实测站点提取特征值,将特征值和湿度值一一对应并按4∶1随机划分训练集、验证集;其次,实例化基本模型,加载曼尼托巴地区预训练模型及初始化参数,该参数是通过曼尼托巴数据集学习得到,避免随机初始化参数速度慢、目标数据集过小对精度造成的影响;然后,通过计算可知目标领域各特征值同实测SM相关性不高,需要对全连通层的参数进行重新初始化及更新,参数微调过程如图3所示。
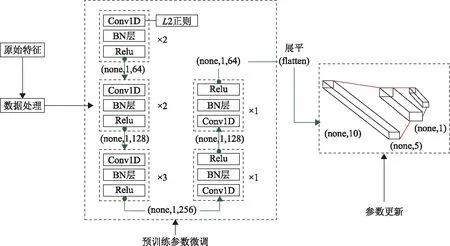
图3 基于参数微调的迁移学习过程
2.5 精度验证指标选取
采用平均绝对值误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、平均绝对百分比误差(mean absolute percentage error,MAPE)以及相关系数R共4个指标对模型预测的可靠性和准确性进行度量。其中MAE、RMSE、MAPE用来衡量观测值与真实值间的偏差,可评估模型预测结果好坏,其值越小代表预测效果越好。R衡量模型拟合数据的能力,其值越接近于1,模型效果就越好。
3 结果分析
3.1 土壤湿度反演
随着训练次数不断增加,损失值MSE由1.582下降到0.007。CNN_W收敛速度更快,当迭代至600次时,MSE下降至0.005,且逐渐趋于平缓。由图4(a)、图4(c)可知,二者得到的SM分布空间大部分一致,将SM以0.05 cm3/cm3为间隔划分成14个等级,SM范围集中在0.2~0.5 cm3/cm3间,与SM实测值范围一致。CNN_W得到的SM分布

图4 曼尼托巴SM分布
变化平滑,与SM实际变化趋势一致。SM较高地区集中在研究区东北部、中部和部分作物覆盖区,SM较低地区集中在西南部、裸地和部分植被覆盖区。两种方法在6月20日和7月18日SM分布存在部分差异,利用验证集来进一步检验。由图4(b)、图4(d)可知,大部分实测和反演结果散点都分布在1∶1回归线上及10%偏置范围内,CNN_W反演精度比CNN高,异常点个数少。
比较不同方法在验证集上的监测效果。由图5可知,反演方法按照精度从高到低排序依次是:CNN_W>CNN>光学。其中CNN_W精度最好(R=0.832,MAE=0.028 cm3/cm3);各干旱指数对复杂农用地SM监测效果较差(RSMMI=0.338、RMSMMI=0.337、RPDI=0.308、RMPDI=0.097)。总体上,不依赖于复杂物理关系、仅依靠深层挖掘特征变量和目标变量间关系的深度学习方法相较遥感指数法具有明显优势。

图5 不同SM反演方法精度比较
3.2 模型迁移应用
加载初始特征和尺度化特征训练得到的曼尼托巴SM模型,将上述模型参数作为迁移训练初始参数,对全连接层参数进行重新初始化和更新,比较不同模型的迁移效果。由图6(a)、图6(c)可知,那曲县2013—2016年偏旱,反演结果集中在0~0.35 cm3/cm3,与SM实测值范围一致,西北部高寒区干旱少雨,植被稀疏,干旱程度较东南更严重,东南部植被覆盖整体好于西北部,故更加湿润。且3月是寒冷的冬季,故干旱程度相较于5、7、8、9月更严重。利用验证集进一步定量分析(图6(b)、图6(d)),大部分实测和反演值散点分布在1∶1回归线上及10%偏置范围内。基于尺度化特征的预训练模型迁移精度略高,R为0.824,RMSE、MAE分别为0.045 cm3/cm3、0.036 cm3/cm3,基于原始特征的预训练模型迁移精度不及前者,部分实测点湿度被过分高估或低估。

图6 青藏帕里地区SM分布
4 结束语
文章使用一维卷积核构造CNN模型提取SM,CNN的一维卷积在不增加感受野情况下引入更多非线性特征,能有效模拟SM大小。为提升反演精度,本文考虑像元位置偏移及混合像元辐射给反演精度造成的影响,将移动窗口像元均值作为中心像元值,而大多数研究考虑的是网络参数优化、输入因子的选择。实验结果表明,移动窗口处理后的特征与SM相关性更高,提取精度较原始特征提高。
光学遥感是监测SM的主要手段,但本文发现,光学遥感指数无法实现小范围复杂农业地SM精准监测。基于近红外-红光构建的PDI、SMMI更适合裸地SM监测;引入FVC的MPDI和MSMMI对SM变化敏感性较差,在本文研究区范围内不适用;CNN方法在该地更适用。但目前该方法依靠大量实测样本,在实际中难实现,未来可尝试利用半监督或非监督的方法实现少样本或无样本的学习。
目前多数研究缺乏对SM模型异地迁移的研究。文章对曼尼托巴地区SM模型参数微调并应用于那曲县SM反演。基于尺度化特征模型的迁移精度更高(R、MAE分别为0.824、0.036 cm3/cm3),实测值误差在-0.1~0.07 cm3/cm3之间。预训练模型在那曲县的直接应用则效果较差。
猜你喜欢
中等数学(2022年5期)2022-08-29
成都信息工程大学学报(2021年5期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2021年4期)2021-08-30
中等数学(2020年2期)2020-08-24
天津农林科技(2020年3期)2020-08-13
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
电子制作(2019年13期)2020-01-14
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
