
基于珞珈一号和随机森林的兰州市GDP空间化
2022-08-18 08:53谢甫孙建国于明雪吕建康马恒利
遥感信息 2022年2期
谢甫,孙建国,于明雪,吕建康,马恒利
(1.兰州交通大学 测绘与地理信息学院,兰州 730030;2.地理国情监测技术应用国家地方联合工程研究中心,兰州 730030;3.甘肃省地理国情监测工程实验室,兰州 730030)
0 引言
国内生产总值(gross domestic product,GDP)是反映经济发展和资源配置的重要指标[1]。传统GDP数据一般以行政区划为单元进行统计,无法反映行政单元内部的空间分布差异。为了解决这一问题,近年来众多学者开展了GDP空间化研究,将行政单元GDP分配到特定大小(常用1 km×1 km)的格网上。空间化的GDP与其他地理数据结合,能够更好地应用于一些地表现象的空间格局分析[2]。
GDP空间化方法的发展大致经历了三个阶段:空间插值法[3]、基于土地利用数据的回归模型法[4]和结合多源数据的回归模型法[5]。一般地,第三种方法精度更高,尤其是夜间灯光(night-time light,NTL)卫星遥感数据的使用极大地提高了模型性能。NTL数据在夜间收集,消除了大多数自然干扰,可以有效反映人类活动强度和社会经济发展水平[6]。
目前,大多数研究采用的NTL是美国国防气象卫星计划(DMSP/OLS)和美国国家极地轨道卫星提供的可见光红外成像辐射仪(NPP/VIIRS)数据[7-9]。但是,DMSP/OLS的过饱和现象会削弱与GDP的相关性,NPP/VIIRS因空间分辨率相对较低而应用受限。我国自主研发的全球首颗专业夜光卫星珞珈一号(LJ1-01)NTL的空间分辨率为130 m,光谱分辨率为32 bit,均远高于DMSP/OLS和NPP/VIIRS,具备更丰富的细节特征,在社会经济相关学科领域逐渐展现出广泛的应用潜力[10]。从模型实现来看,以往研究大多使用传统的多元线性回归(multivariate linear regression,MLR)。近年来,机器学习方法由于其预测精度高且不需要数据假设而逐渐在社会经济数据空间化研究中得到应用,将机器学习方法应用于社会经济数据空间化可以极大地提高建模精度[11-14]。其中,随机森林(random forest,RF)在防止过度拟合、处理缺失值和分类值建模等方面具有较大优势,更多地被应用于GDP空间化研究中[15]。
以往,GDP空间化大多基于县级及以上行政单元的统计数据而实现,格网和行政单元之间存在较大的尺度间隙,会导致预测的准确性偏低[16]。乡、镇和街道是我国的基本行政单元(以下简称“乡镇”),相对而言,其尺度与空间化目标格网尺度更为接近,以乡镇为统计单元进行GDP空间化建模可以有效降低尺度间隙导致的不确定性。本文基于118个乡镇单元的统计GDP,使用LJ1-01 NTL及辅助数据和MLR/RF方法进行兰州市GDP的1 km×1 km格网空间化,分析其空间格局,旨在验证乡镇行政规模上通过LJ1-01 NTL数据预测GDP的潜力,同时为兰州市城市规划和经济发展决策提供数据支撑。
1 研究区概况与数据来源
1.1 研究区概况
兰州市(图1)位于甘肃省中部,102°36′E~104°34′E,35°34′N~37°07′N,属黄土高原低山丘陵区,深居大陆腹地,现辖城关、七里河、安宁、西固、红古5个区和永登、榆中、皋兰3个县,包括118个乡、镇和街道,东西长153 km,南北宽130 km,总面积13 086 km2。市区呈东西向,长约35 km,位于黄河谷地中,海拔约1 500 m。
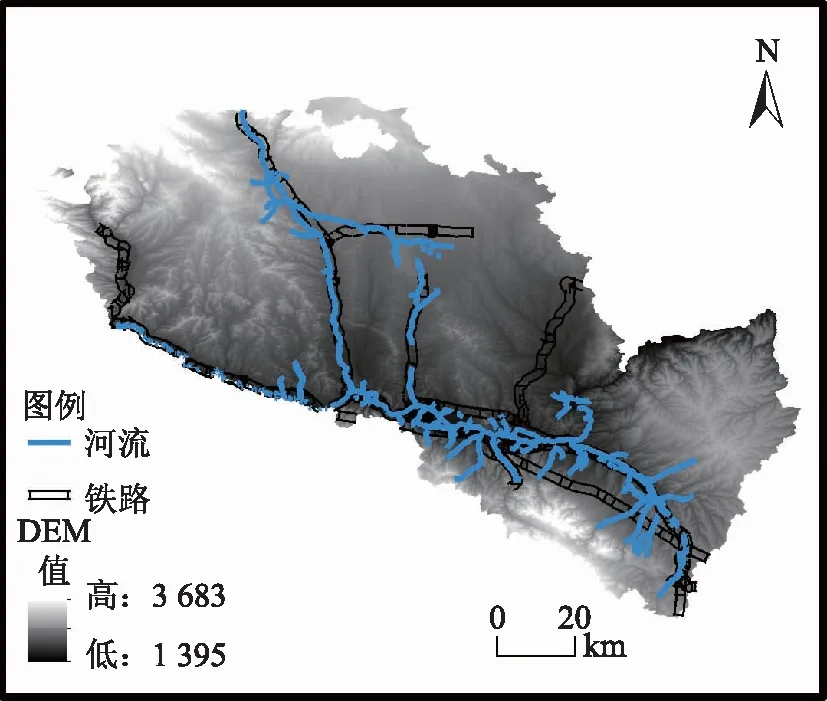
图1 兰州市概况图
兰州市作为计划经济时期兴起的以石化产业为主导的综合性工业城市,目前正处于由工业化中期向工业化后期过渡的关键时期,其工业生产功能不断弱化,服务功能逐渐强化,产业结构也逐渐由生产制造型向生产服务型转变,现已成为我国西北内陆具有重要影响力的中心性城市。
1.2 数据来源
本研究中使用的数据主要包括LJ1-01 NTL、Landsat 8影像、数字高程模型(DEM)、路网、土地利用数据、归一化植被指数(NDVI)和GDP统计数据。覆盖兰州市的LJ1-01 NTL影像共10幅,时间跨度从2018年7月—2019年2月。DEM为30 m空间分辨率的ASTER GDEM。Landsat 8数据为2018年8月的多幅影像,空间分辨率为30 m。土地利用数据来自清华大学地球系统科学系宫鹏教授团队研发的世界首套“2017年10 m分辨率全球土地覆盖产品(FROM-GLC10)”,包括10个地类。路网数据源自开源数据OSM,包括公路、城市道路、农村道路和铁路。NDVI来源于美国国家航空航天局的MODIS植被指数产品MOD13Q1,时间分辨率为16 d,空间分辨率为1 km,采用最大值合成法计算出2018年NDVI均值。GDP数据由兰州市各县统计局发布数据整理而来。建立研究区1 km×1 km规则格网,并将所有数据统一转换到Albers投影。
2 方法
2.1 自变量选择与处理
根据前人研究成果,本研究考虑了6个自变量:NTL、地表温度(land surface temperature,LST)、建筑用地占比(building coverage,BC)、平地占比(flat pixel coverage,FPC)、路网密度(road network density,RND)和NDVI。
LST受人造地表和人类活动的高度影响,可以在很大程度上表明经济活动的强度,因此是一个重要的GDP预测因子。研究区LST由陆地卫星Landsat 8影像计算而来。NDVI可以反映植被覆盖度和植被生长状态,与农业、林业的产出有较强的相关性,以NDVI为预测因子有助于提高GDP预测的精度。土地利用直接反映了人类活动和环境之间的相互作用,地形和交通条件也对经济分布有很大影响。因此,BC、FPC和RND也被列为候选预测因子,分别从土地利用数据、DEM和OSM中计算获取。FPC计算中,坡度小于5°的像素被认为是平面像素。
由于大气干扰和偶然误差,LJ1-01 NTL数据的DN值存在偏差,需要进行年内稳定性校正和辐射校正[17]。年内稳定性校正公式如式(1)所示。
(1)
式中:DN(j,i)为j时期第i像元的DN值;n=10,分别代表10幅不同时期影像;DNi为校正后的第i像元的DN值。辐射校正参考高分辨率对地观测系统湖北数据与应用中心提供的辐射亮度转换公式进行转换,如式(2)所示。
(2)
式中:L为校正后辐射亮度值,单位为w/(m2×sr×μm);DN为原始影像灰度值。
自变量之间可能高度相关,因此通过计算方差膨胀因子(variance inflation factor,VIF)确定6个自变量的共线性。表1是通过共线性检验给出的自变量VIF值。其中4个自变量(TNL、LST、FPC、NDVI)显示相对较低的VIF值(VIF<5),2个自变量(BC、RND)VIF值较高(VIF>20),存在共线情况,因此需要选择自变量进行建模。

表1 自变量共线性检验
2.2 建模方法
MLR算法是流行的统计算法之一,已广泛用于GDP空间化。RF算法是Breiman[18]提出的一种集成学习算法,它通过自采样的多次迭代生成多个样本,并基于样本建立相应的决策树。RF回归是通过组合这些多重决策树开发的,最终的预测结果由所有决策树预测结果的均值来确定。与MLR相比,RF回归具有预测精度高、不需要假设先验概率分布以及具有分析变量重要性能力等优点[19]。
兰州市118个乡镇的6个自变量用于拟合和验证模型。为了避免模型过度拟合,有必要控制模型的复杂度。筛选变量数据有效值,采用筛选后的数据建立MLR和RF模型,调整建模自变量数量使模型误差最小,以选择最优的输入变量。同时对于RF模型,调整生成的决策树数量和树深,选择最优的参数设置,使RF回归模型误差最小。
2.3 模型验证
采用10-K交叉验证方法对MLR和RF模型的性能进行验证。把建模数据随机平均分成10个折叠,其中9个折叠用于训练模型,剩下的一个折叠用于验证模型。然后,重复该过程,直到所有的折叠都被用作验证数据一次。在本研究中,使用平均绝对误差(MAE)和决定系数(R2)表示模型精度,计算如式(3)、式(4)所示。
(3)
(4)

2.4 变量重要性分析
为了研究RF模型中各变量的重要性,进行了变量重要性分析,通过计算平均下降精度(%IncMSE)以衡量变量的重要性。%IncMSE指的是随机置换变量时均方误差的增加,增量值越高,表明变量的随机排列导致的误差越大,因此变量的重要性越大,其计算如式(5)所示。
(5)
式中:MSE是基于原始输入变量建立的模型的均方误差;MSEpermuted是变量随机排列后建立模型的均方误差。
2.5 GDP空间化
将性能最优的RF回归模型应用于兰州市1 km×1 km格网,绘制兰州市GDP 空间化分布图。由于模型存在适用性误差,预测的乡镇内格网GDP总和与乡镇统计GDP数据之间存在差异。为了确保预测的乡镇GDP和实际统计乡镇GDP之间的一致性,预测的GDP采用式(6)校正。
(6)

3 结果与分析
3.1 模型表现
图2为 MLR和RF回归模型10-K交叉验证的MAE的均值随自变量个数的变化。对于MLR模型,MAE随自变量个数变化较小。对于RF模型,当自变量数量为3时,MAE达到最小,模型精度最高。图3为RF回归模型中6个自变量的%IncMSE增量百分比。NTL的增量值最高,为0.35,这表明NTL可以有效地描述经济活动的强度。NTL反映了夜间照明的强度和密度,与社会经济活动密切相关。仅次于TNL,BC也有较高的%IncMSE增量值,为0.33。BC反映了土地开发强度,兰州市受限于地形,其工厂和商业地区较为集中,BC值越高,地区产值也就越高。FPC和LST的%IncMSE值分别为0.18和0.12,兰州市平坦地区主要分布在黄河两岸的建成区,而影响地表温度的主要因素即人造地表和人类活动也主要分布在建成区,变量信息相互解释,导致其重要性较为一般。RND和NDVI的%IncMSE值较低,说明这两个变量对GDP估计精度的影响较低。道路交通分布是反映经济分布的重要因素,但是在兰州市“两山夹一河”的地形条件下,道路交通密度与建成区和平坦地区高度重合。且兰州市由于气候、地形等原因,农、林产业不发达,在地区产值中的占比较低。这些可能是RND和NDVI在建模时重要性低的主要原因。因此,选取NTL、BC、FPC 3个自变量作为MLR和RF模型的输入变量。

图2 模型MAE随自变量个数的变化

图3 RF模型自变量重要性检验
在RF模型的拟和过程中,调节决策树棵树n以提高模型预测精度。图4显示了模型交叉验证的MAE均值随决策树棵树n的变化。MAE均值在n等于13时达到最小值,然后逐渐趋于平稳。因此,RF回归模型最终确定的参数n为13。

图4 RF模型MAE随决策树棵树n的变化
图5显示了MLR和RF预测乡镇GDP和实际乡镇GDP的散点图。MLR模型的R2为0.73,MAE为303.18百万元,RF回归模型的R2为0.85,平均绝对误差为246.64百万元。虽然RF回归模型低估了几个高价值样本,但大多数样本的真实和预测值分布都比MLR模型更接近1∶1,表明实际GDP和RF模型预测的GDP之间有较好的一致性。RF算法对变量多重共线性不敏感,并且在定义涉及多个变量的复杂非线性关系时具有鲁棒性,因此可以表现出更好的性能[20]。结果表明,RF在GDP预测时表现出较大潜力。
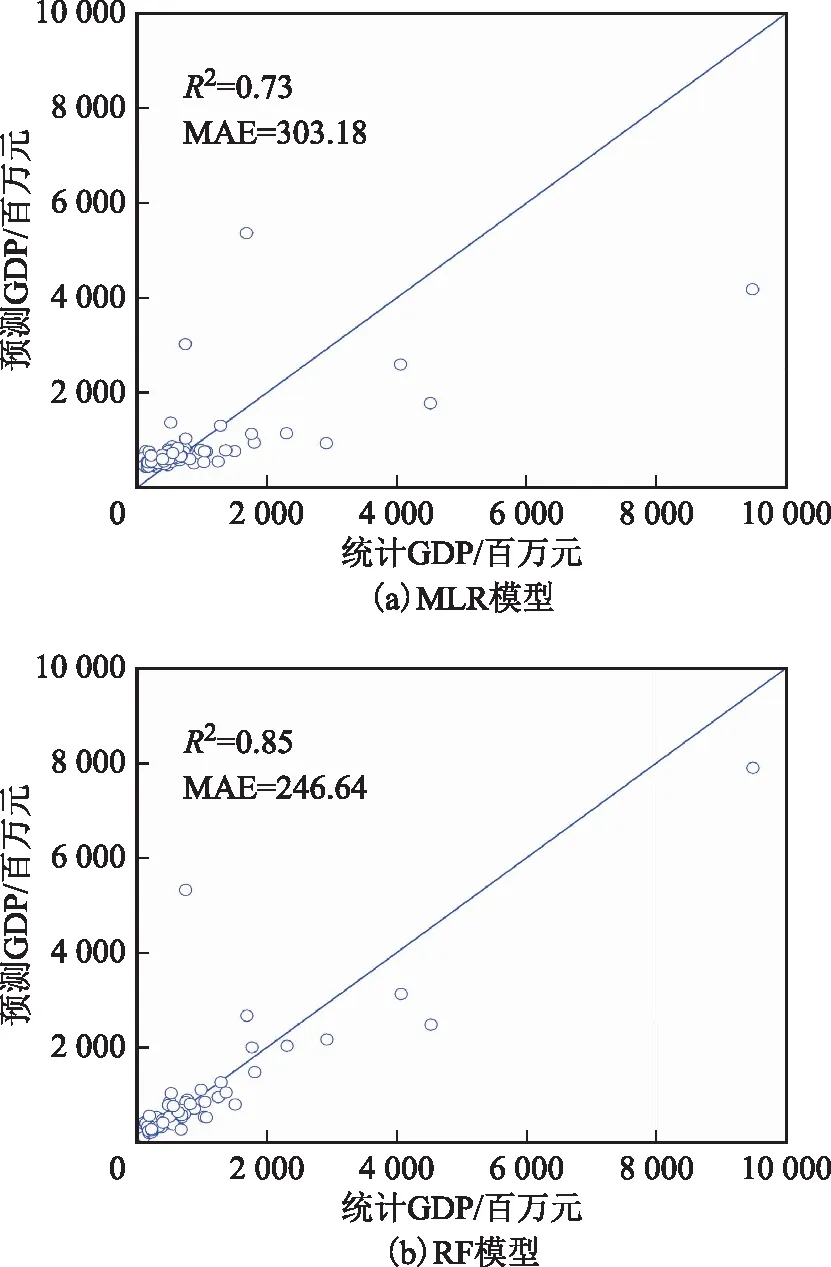
图5 统计GDP和预测GDP分布散点图
3.2 兰州市GDP空间化结果
将性能最优的RF回归模型应用于格网自变量(NTL、BC和FPC),生成兰州市1 km×1 km GDP空间分布图,图6为兰州市GDP空间化结果,图上a、b处分别为兰州市主城区和西北区域典型乡镇、街道。与城镇单元GDP统计数据相比,空间化后的GDP显示了乡镇内部的GDP空间差异,揭示了更详细的经济活动信息。整体上看,兰州市GDP高密度区集中在沿黄河干流两岸的建成区,次密度区主要位于黄河支流和铁路沿线的地形平缓区以及兰州新区。由于 “两山夹一河”的复杂地形,兰州市城区建设沿黄河两岸发展,因此兰州市GDP在黄河干流两岸形成了连续的积聚,并从城市中心向周围密度逐渐降低。兰州市西北、东南区域多为山地,受限于地形,经济发展落后,其GDP密度主要集中在道路尤其是铁路主干线周围,且密度相对较低。兰州新区作为自2012年开始建设的全国第五个、西北第一个国家级新区,受到政府扶持,经济发展迅速,GDP密度相对较高。
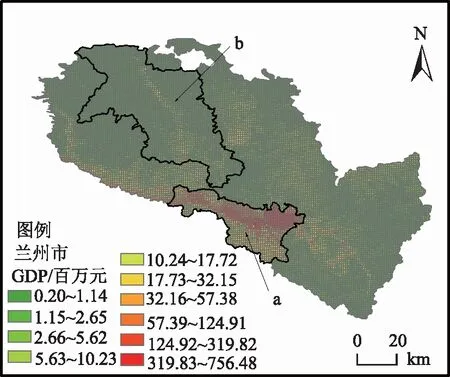
图6 兰州市GDP空间化结果
本文是基于乡、镇和街道行政单元的GDP空间化。街道一般是城市区域的再划分,其经济发展水平普遍高于乡和镇。图7为兰州市主城区部分乡镇、街道的空间化GDP分布。高新区、雁北街道、嘉峪关街道、西站路街道等单元内部格网表现出较高的GDP密度,主要因为这些单元分布在城关区、西固区、七里河区沿黄河两岸的城市中心,特点是商业经济发达。十里店街道、安宁堡街道、沙井驿街道等隶属于安宁区的街道,虽然较黄河两岸城市中心地理位置较差,但因为安宁区优秀的教育资源促进了这些区域的经济发展,其内部格网GDP密度也相对较高。而阿干镇、魏岭乡、西果园镇、河口乡、达川乡等和街道相邻的乡、镇,内部格网GDP密度向远离街道方向逐渐降低,形成连续的分级。

图7 兰州市主城区部分乡镇、街道GDP空间化详图
兰州市西北、东南区域的一些乡镇受山地地形影响,经济发展落后,GDP密度主要集中在铁路主干线周围平坦区域。图8为兰州市西北区域部分乡镇GDP空间化结果。由于兰新铁路修建在中堡镇、城关镇、柳树乡、红城镇等乡镇境内,这些乡镇内格网GDP分布表现出高度的不均衡,其GDP密度主要集中在铁路沿线平坦区域,并由铁路向外呈放射性降低。其他乡镇如武胜驿镇、通远乡等多为山地地形的乡镇,其内部格网GDP密度普遍偏低,这些地区的经济主要由农业和旅游业驱动,地形劣势限制了其经济发展。兰州市东南区域和西北区域GDP分布情况类似,其内部格网GDP密度主要集中在宝兰线沿线,并沿远离铁路线方向密度逐渐降低,其他山地地区内部格网GDP密度普遍偏低。
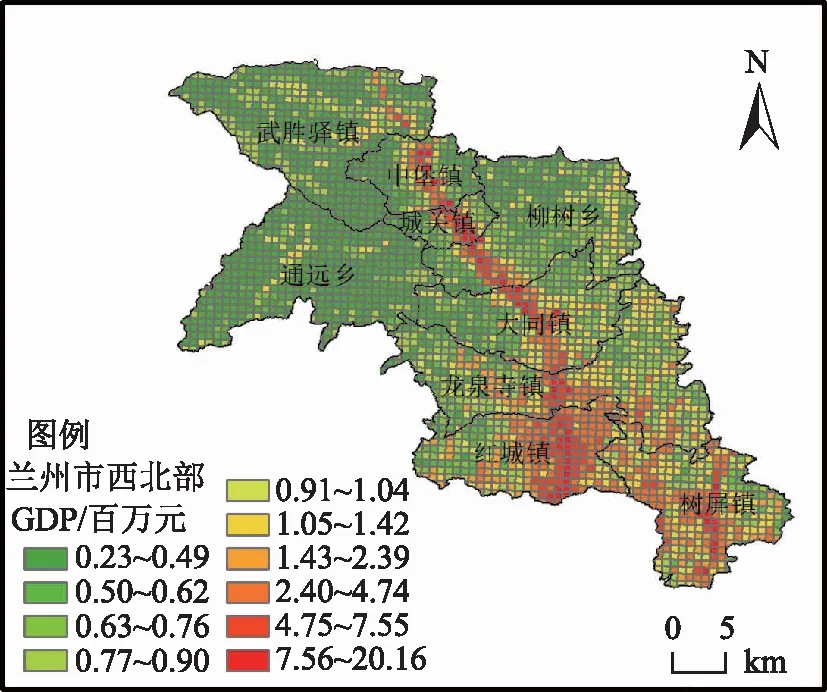
图8 兰州市西北部分乡镇GDP空间化详图
4 讨论
乡镇是我国的基本行政单元,相对于县级及以上行政单元,其内部环境、经济差异较小,以乡镇为单元进行GDP空间化建模可以有效减少将行政级别模型应用于格网时的不确定性。过去的GDP空间化研究主要在县级以上行政单元开展,建立预测回归模型所得到的R2普遍在0.6~0.9范围内,且大多数在0.7左右。本研究预测回归模型的R2为0.85,高于多数研究中的模型精度,表明以乡镇、街道单元建模优于更高的行政单元,基于精细尺度建模可以提高GDP空间化的可靠性。
LJ1-01是全球首颗专业夜光遥感卫星,也是目前国际上第三颗具备夜间灯光数据拍摄能力的卫星,弥补了我国在夜间灯光数据获取方面的不足,具有重要的历史意义及研究价值。但是,LJ1-01 NTL数据由2018年6月发射的卫星提供,目前只能生产自2018年始少数年份的数据,不能为长时间序列的研究提供数据支持。
近年来,机器学习算法在遥感应用中得到了广泛的使用。然而,目前将其应用在GDP空间化方面的研究还比较少。由于RF算法具有对多重共线性不敏感和分析变量重要性重要特质,在利用多源数据进行建模时具有优势。多源数据可以从多个角度反应经济活动的强度,从而提高模型的准确性。本研究将RF算法应用于兰州市GDP空间化中,结果表明,利用RF建立回归模型可以较好地描述社会经济和NTL及辅助数据之间的复杂关系。
社会经济活动极其复杂,不同地区和城市的自然环境、工业结构和发展水平的巨大差异使得以单一模型预测GDP空间结构非常困难。因此,有必要继续开发普适性更高的GDP空间化模型。此外,不同于传统农业和工业经济活动受到区域条件的高度影响,互联网经济等新经济形势超越了区域和空间限制,给未来的GDP空间化研究带来了巨大的挑战。
5 结束语
本文基于兰州市118个乡镇单元,采用LJ1-01 NTL数据和其他辅助数据(地表温度、路网密度、平地占比和建筑用地占比),使用MLR和RF进行GDP的1 km×1 km格网空间化,有以下结论:乡镇街道尺度上GDP预测模型的决定系数可达0.85,高于大多文献得到的基于更大行政单元的模型决定系数;RF模型(MAE=246.64 百万元,R2=0.85)的精度明显高于MLR模型(MAE=303.18 百万元,R2=0.73);LJ1-01 NTL在GDP空间化中有很大的应用潜力;兰州市GDP高密度区集中在沿黄河干流两岸的建成区,次密度区主要位于黄河支流和铁路沿线的地形平缓区以及兰州新区。
本文研究结果可为制定兰州市社会经济发展战略和政策提供重要参考,也为在其他区域进行精细尺度的社会经济空间分布图制作提供借鉴。
猜你喜欢
当代陕西(2021年1期)2021-02-01
中国科学数据(中英文网络版)(2020年4期)2021-01-20
华南地震(2020年3期)2020-10-20
学生天地(2020年15期)2020-08-25
空间科学学报(2020年6期)2020-07-21
甘肃教育(2020年12期)2020-04-13
当代陕西(2019年14期)2019-08-26
学生天地(2019年3期)2019-03-05
快乐语文(2018年25期)2018-10-24
法制博览(2018年22期)2018-08-16
