
面向小目标提取的改进DeepLabV3+模型遥感图像分割
2022-08-18 08:53郭新张斌程坤
遥感信息 2022年2期
郭新,张斌,程坤
(1.中国地质大学(武汉) 地理与信息工程学院,武汉 430078;2.武汉工程大学 计算机科学与工程学院,武汉 430205)
0 引言
遥感已经成为观测地球表面重要的技术手段。进入二十世纪以来,随着传感器技术的不断改进,可以获得如哨兵系列、高分系列等高分辨率多光谱图像。此外,利用无人机技术(unmanned aerial vehicle,UAV)可以获得亚米级的超高分辨率的遥感图像。目前高分辨率遥感影像的解译在城市环境、精准农业、基础设施建设、林业调查、军事目标识别、灾害应急评估等诸多领域都具有极其重要的意义。传统的遥感影像解译技术主要依靠人工目视解译以及专家先验知识构建的物理模型,但其存在精度低、效率低等缺陷,面对井喷式增长的海量遥感数据,传统的影像解译方法已经无法满足当今的实际应用需求。
近年来,随着计算机视觉技术的不断进步,图像分割算法在深度学习的助推下取得了较大发展。全卷积神经模型(fully convolutional networks,FCN)[1]是最早提出的基于卷积神经模型(convolutional neural network,CNN)的具有较高影响力的图像分割模型之一,之后FCN方法被用于提取高分辨率遥感影像的建筑物[2-3],但是FCN仅使用深层特征图来执行像素分类,忽略了含有丰富空间信息的浅层特征,导致其处理小目标的能力较弱,使得模型最终的分割图像较为粗糙。U-Net[4]和SegNet[5]采用了编码器-解码器结构,编码器用于提取特征信息,解码器将提取到的特征图恢复至原始图像维度。为了解决编码器由于不断卷积导致图像细节信息严重丢失的问题,在编码层中融合浅层特征,使模型能够提取不同层级的特征信息,提升模型精度,Li等[6]在U-Net的基础上提出了DeepUNet模型用于遥感影像分割,该模型引入了两个带有U连接和正连接的新模块进一步提升模型性能。Pan等[7]提出了密集金字塔网络(dense pyramid network,DPN)用于语义分割,该模型分别提取每个通道的特征图以增强模型的表示能力,最终在Vaihingen数据集上表现良好。
最近,DeepLabV3+模型[8]由于其出色的分割性能变得较为流行,该模型由DeepLabV1~3[9-11]系列改进而来,其整体上继承了U-Net等模型的编码器-解码器结构,在编码器部分引入空间空洞金字塔池化(atrous spatial pyramid pooling,ASPP)模块并添加了全局平均池化操作,解决了之前提取的特征图尺度单一的问题,有效提升了模型的性能,但是也存在训练速度较慢、小尺度目标信息丢失严重以及多类别分割任务中由于数据集类别不均衡导致性能欠佳等问题。部分学者对DeepLabV3+存在的缺陷进行了研究,刘文祥等[12]在该模型中引入双注意力机制模块(dual attention mechanism module,DAMM),并将该模块与ASPP通过串联和并联两种方式连接起来,结果证明DAMM注意力机制能够有效提升模型训练收敛速度,增强图像边缘目标特征,且在INRIA aerial image数据集上MIoU分别提升了1.12%和1.8%。张鑫禄等[13]提出了基于DeepLabV3的小波域(markov random field,MRF)算法,改善了边缘目标的分割效果,整体精度提升了3%;Du等[14]提出将DeepLabV3+和基于对象的图像分析融合以增强地物轮廓;Baheti等[15]提出降低ASPP的空洞卷积采样率可提升小目标的特征提取能力;刘志赢等[16]提出异感受野融合策略扩大了空洞卷积感受野,提升了DeepLabV3+模型多尺度特征提取能力,并引入通道注意力模块,强化了对重点通道的学习能力;刘航等[17]在DeepLabV3+模型引入了自适应感受野机制可以有效提取不同形状目标的特征;郭梦利等[18]使用占比加权的方法解决了模型训练中正负样本严重不均衡的问题。
以上学者只是针对DeepLabV3+的不足进行单方面改进,且改进效果有限。针对DeepLabV3+模型在遥感影像语义分割上存在小目标提取能力弱等缺点,本文提出以下改进策略。
1)改进ASPP模块。减小空洞卷积采样率,采用多组并行空洞卷积增强多尺度特征提取能力,同时提出感受野融合策略,扩大感受野,提高特征信息利用率;
2)添加特征注意力融合模块(feature attention fusion,FAF),利用通道注意力和空间注意力充分挖掘不同特征图的信息;
3)优化损失函数,利用加权基于子模块凸优化的Lovasz-softmax损失函数能有效解决多类别分割任务时的类别不均衡现象。
基于以上策略分别对模型改进,最后融合改进策略整体提升模型性能,并通过Landcover和CCF2017高分辨率遥感影像数据集验证改进策略的有效性。
1 模型与改进
1.1 DeepLabV3+模型
DeepLabV3+是Google公司于2018年最新提出的语义分割算法,该算法由DeepLabV1~3发展而来,DeepLabV1提出带空洞的卷积操作,在避免下采样的情况下扩展了模型感受野,同时模型采用了条件随机场(conditional random field,CRF)优化分割结果,但是DeepLabV1对于多尺度目标的分割性能欠佳。DeepLabV2在DeepLabV1基础上提出了最初的ASPP结构,对输入的特征图使用不同采样率的空洞卷积操作进行采样,可以有效提取不同尺度目标的特征信息,同时沿用CRF以提高模型的分割性能。DeepLabV3将ASPP结构改为三个3×3卷积操作,采样率分别为(6、12、18)和一个全局平均池化,由于ASPP融合了像素级特征,包含了目标的位置信息,因此DeepLabV3取消了CRF操作。DeepLabV3+基础模型的结构如图1所示,以改进的Xception为骨干模型,原始图像输入到编码器模块,经过输入流、中间流和输出流卷积运算,生成分辨率为原图1/16或1/8的特征张量,将提取的特征张量传入ASPP结构,其中包含了一个全局平均池化特征层和三个不同采样率的并行空洞卷积层,将通过并行空洞卷积层处理后的特征张量连接后通过一个1×1的卷积层压缩通道后输出。在解码器模块中,对编码器模块输出的特征图通过双线性插值四倍上采样至原始图像的1/4大小,然后与来自骨干网络提取的相同分辨率的浅层特征图拼接,兼顾图像的语义信息和细节信息,避免了从深层特征图直接上采样恢复至原图尺寸时造成细节信息丢失的误差,再次经过3×3卷积和四倍上采样后输出分割结果。
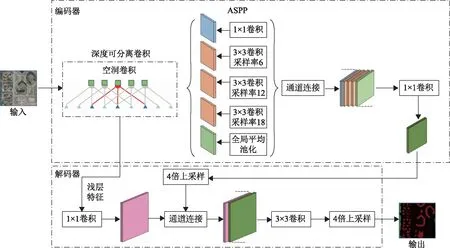
图1 DeepLabV3+模型结构
DeepLabV3+模型因其使用了编码器-解码器形式以及ASPP模块,同时利用骨干网络提取的浅层特征与ASPP处理后的深层特征融合以加强细节信息,所以具有出色的分割性能。但是对于遥感图像来说,ASPP模块中较大的空洞卷积采样率会丢失小尺度目标的信息,同时四倍上采样恢复图像细节信息具有较大难度,因此在遥感影像语义分割领域,DeepLabV3+面临诸多挑战。
1.2 注意力机制
近年来,众多计算机视觉研究工作者专注于注意力机制。注意力机制是聚焦于局部信息的机制,其使用一层全新的注意力权重,将特征数据中每个部分的关键程度表示出来并加以学习训练。根据作用形式的不同,可以将注意力机制分为三类,分别为:空间注意力(spatial attention)、通道注意力(channel attention)、混合注意力(mixed attention)。空间注意力[19]是将图像中的空间信息作对应的空间变换,从而将关键的信息提取出来,并对生成的掩码进行评估。通道注意力[20]是给每个通道增加一个权重,代表通道与关键信息的相关度,权重越大,表示相关度越高。Woo等[21]结合了上述空间注意力和通道注意力的优点,提出了CBAM;王中宇等[22]在DeepLabV3+模型中引入CBAM,将其应用在自动驾驶场景的语义分割工作当中,但是模型中的不同卷积层包含不同的语义信息,对单层特征图利用CBAM同时进行通道信息挖掘以及空间信息挖掘往往不能发挥注意力机制的最大效果,且引入的CBAM使得模型过于关注焦点区域,忽略了部分细节信息,最终导致分割结果过于圆滑。之后,作者采用了条件随机场(CRF)对分割结果进行处理才进一步改善了结果,但使模型产生了额外的计算。
本文提出了特征注意力融合模块(feature attention fusion,FAF),将空间注意力模块用于挖掘包含更多空间位置信息的浅层特征,将通道注意力模块用于挖掘包含更丰富语义编码信息的深层特征图,将两者挖掘到的注意力信息进行特征融合并输出到后续的模型中。
1)通道注意力。给定H×W×C的特征图F,分别采用全局平均池化和最大池化得到两个1×1×C的特征,随后将其送入一个共享的神经模型,再将得到的两个特征相加后经过激活函数得到权重系数,最后将权重系数与原特征相乘输出。通道注意力模块的公式表示参见文献[21]。
2)空间注意力。给定H×W×C的特征F,经过通道维度的全局最大池化和平均池化之后连接起来,组成两个通道的特征图,经过一个卷积层融合,输出一个单通道的特征图,最后经过sigmoid激活操作生成空间注意力特征图Ms。将该权重矩阵和输入特征图进行点乘运算,得到最终需要的特征图。空间注意力的公式表示参见文献[21]。
3)特征注意力融合模块。如图2所示,分别给定H1×W1×C1的浅层特征F1和H2×W2×C2的深层特征F2,由于浅层特征和深层特征包含不同的语义信息,为充分挖掘特征图的信息,本文提出特征注意力融合模块。首先,将F2上采样后与F1进行通道连接;然后,通过1×1卷积压缩通道,利用ReLU激活函数和批归一化操作得到F3;其次,利用空间注意力模块对F1进行处理,得到空间注意力加权的特征,通过1×1卷积扩张通道后与F3特征融合得到F4;最后,利用通道注意力模块对深层特征F2进行处理得到注意力加权特征F5,将F5和F4融合输出得到最终的特征图。特征注意力融合模块可以用式(1)表示。
F=Mc(F2)×[Ms(F1)×γ(F1+F2)]
(1)
式中:Mc表示通道注意力;Ms表示空间注意力;γ为ReLU激活函数。
1.3 改进ASPP
受空间金字塔池化以及空洞卷积成功应用的启发,原始DeepLabV3+模型在编码器ASPP模块利用三组采样率分别为6、12、18的并行空洞卷积可以有效提取不同空间尺度的特征信息。研究表明[23],在ASPP模块中6、12、18的采样率适用于自然图像中目标尺寸较大的密集像素,遥感图像的成像方式和成像特点与自然图像存在较大差距,遥感影像中单个的地物目标像素所占整幅图像之比远低于自然图像,因此若继续沿用原始DeepLabV3+的采样率将导致影像中的像素占比较小的目标如建筑物、道路等细节信息丢失,致使模型误差变大。
1)多组并行空洞卷积。原始模型ASPP结构使用采样率分别为6、12、18的空洞卷积扩大感受野。空洞卷积是通过卷积核补零的方式扩大感受野,最终输出非零采样点的卷积结果。本文在继承原始的ASPP的优势上,考虑到遥感影像中既存在像素面积占比较小的建筑物,同时存在如水体、林地等集中连片的像素占比相对较大的地物目标,因此提出减小初始采样率,并使用六组并行的兼顾小尺度和大尺度目标的空洞卷积,采样率分别为4、8、12、16、20、24,以此来提取更多不同尺度的地物目标信息。
2)感受野融合。随着采样率增加,非零采样点在卷积核中的占比快速降低,在同等计算量条件下空洞卷积获取的信息量丢失严重,提取到的特征关联性差,阻碍模型训练[24]。基于以上问题,文献[16]提出了异感受野融合的ASPP结构,该结构将原始特征图与r=16卷积层处理过的特征图拼接后传入r=12卷积层,又将r=12处理过的特征图传入r=18卷积层,这样可以在不增加并行卷积层的同时有效提升感受野。然而,该方法只是融合了上个卷积层的信息,虽然有利于提取更丰富的信息,但提取的信息有限。
本文改进了ASPP模块的感受野融合思路,在ASPP模块中,将当前卷积层提取后的特征与之前每个卷积层提取到的特征以及原始特征融合并进行通道压缩后传入下一卷积层提取信息,该方法可以有效提升卷积层的特征利用率。
定义特征利用率θ为原始特征图中参与有效运算的元素量与感受野内元素总量的比值,则感受野融合前后空洞卷积在原始特征图的特征利用率如表1所示。融合后,相较原始ASPP,采样率为12的感受野从25扩大至49,特征利用率从1.56%增加至7.56%,由此可见该方法通过增强不同感受野特征间的相关性,从更大感受野内判别单个像素的属性,可以有效降低特征信息丢失。
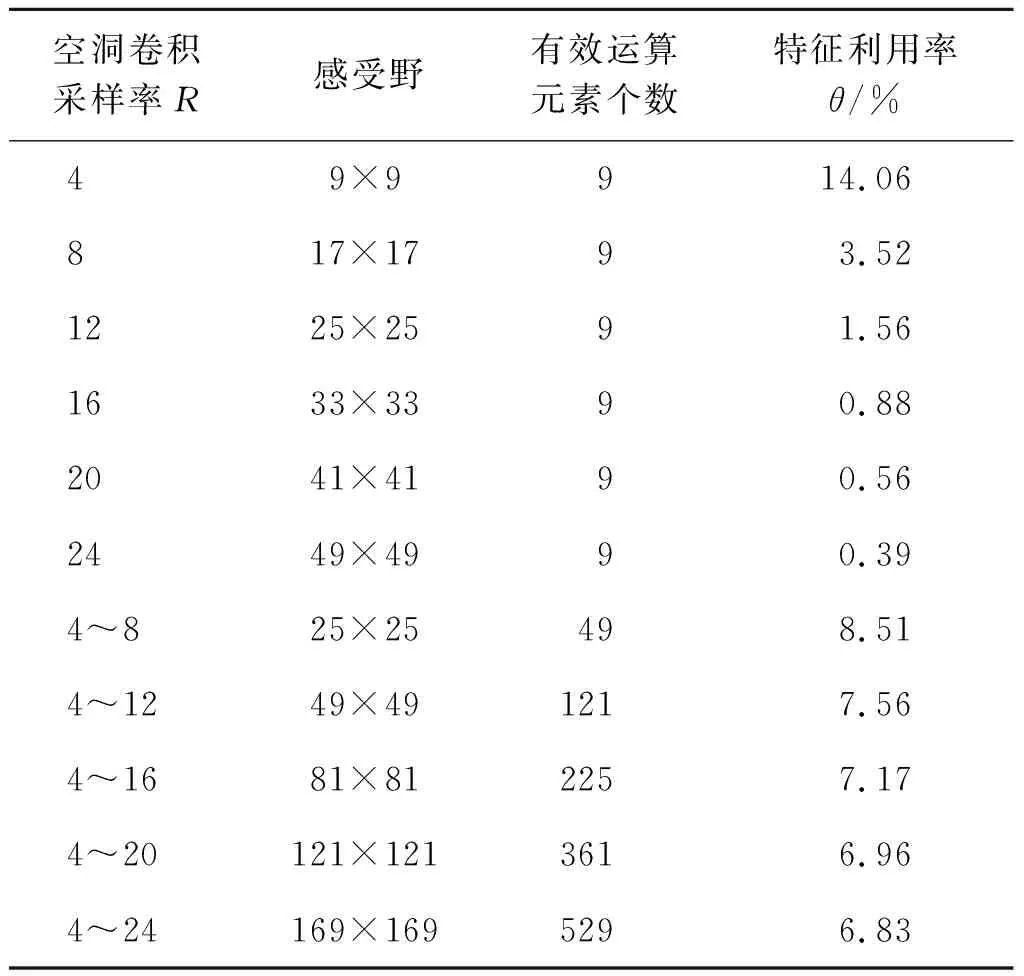
表1 感受野融合特征利用率
感受野融合将增加大量模型运算,为兼顾模型的轻量性和精度,对ASPP的输入特征使用1×1卷积进行通道压缩,由原来的2 048个通道压缩到1 024个通道,输出通道保持不变。模块输入前后特征分辨率维持一致,则原始ASPP模块的参数量如式(2)所示。
N1=2 048×32×256×3=14 155 776
(2)
改进后ASPP模块的参数量如式(3)所示。
N2=2 048×32×256+(1 024+256)×
32×256×5=19 464 192
(3)
与原始ASPP模块相比,改进的多组并行融合感受野ASPP模块参数量增加了37.5%,但是感受野扩大了四倍以上,因此该方法以较小的模型参数增量有效扩大了感受野并提高了特征利用率。
1.4 优化损失函数
损失函数是用来评估模型预测值和真值的不一致程度,损失函数的值越小,模型的性能越好。图像分割任务中,经常会出现类别不均衡的情况,DeepLabV3+模型里使用了softmax损失函数。softmax损失函数能够有效处理多类别分割任务,但处理图像分割中常见的类别不均衡的情况性能欠佳。Berman等[25]提出了基于子模块凸优化的适用于多类别任务的Lovasz-softmax loss。由于本文所用数据集为高分辨率遥感数据集,其中建筑物在影像中的像素占比较低,存在类别不均衡情况,基于子模块凸优化的Lovasz-softmax损失函数能有效解决多类别分割任务时的类别不均衡现象,但该损失函数由于过分关注小尺度样本致使较大尺度的样本存在类内不一致的情况,因此本文汲取Lovasz-softmax loss与softmax loss的优势,采用两者加权组合的方式作为DeepLabV3+模型的loss,在保证高效处理多类别任务的同时降低由于数据集类别不均衡引起的误差。
1.5 改进编码器上采样
在DeepLabV3+模型中,由Xception骨干模型和ASPP提取的特征图分辨率是原始图像的1/16,在解码器模块需要对该特征图进行上采样,恢复至原始图像的分辨率,DeepLabV3+首先采用四倍双线性插值上采样至原始图像大小的1/4,然后与Xception骨干模型提取的浅层特征拼接,再次使用四倍双线性插值上采样至原始图像大小。但研究表明,从较小的图像以较高上采样倍数重建图像存在较大挑战,因此本文分别采用四次两倍双线性插值上采样,在编码器模块结束后,分两次进行两倍双线性插值上采样将特征图恢复至原始图像的1/4大小,与Xception骨干模型提取的浅层特征拼接后再以同样的方式恢复至原始图像尺寸。
1.6 本文方法
DeepLabV3+模型是目前最经典的语义分割模型之一,其为增加对多尺度目标的提取能力,引入由采样率分别为1、6、12、18的3×3空洞卷积以及一个1×1全局平均池化操作共同组成的ASPP结构,并在VOC、COCO、Cityscapes等大型公开数据集上获得优异成绩。针对原始DeepLabV3+模型小尺度目标提取性能欠佳、类别不均衡引起的误差等缺陷,本文融合上述改进策略,提出在原始模型的基础上采用感受野融合策略和增加多组并行空洞卷积改进ASPP模块,在解码器模块中添加FAF注意力机制充分挖掘不同特征的信息,改进上采样策略,并利用基于子模块凸优化的Lovasz-softmax加权优化损失函数,增强小目标的特征提取能力(图2)。
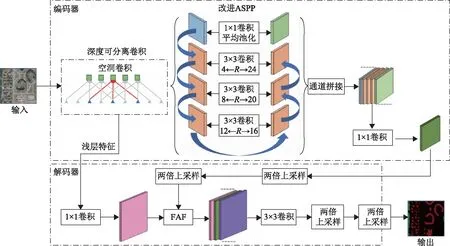
图2 本文方法
2 实验结果及分析
为验证本文方法的有效性,对上述改进方法进行验证。
2.1 实验平台及相关参数设置
本文实验基于Ubuntu16.04操作系统,CPU为Intel Xeon Gold 6148,GPU为NVIDIA Tesla V100,使用百度研发的PaddlePaddle1.8.4框架,在Ai Studio训练并测试本文方法。
本文使用Cityscapes预训练的Xception65作为改进的DeepLabV3+特征提取骨干模型,设置初始化学习率(learning rate,lr)为0.01,使用随机梯度下降(stochastic gradient descent,SGD)法训练模型,使用“poly”学习策略[26],模型优化方法使用momentum,动量为0.9。
2.2 实验数据及流程
本文使用Landcover[27]和2017年“CCF卫星影像的AI分类与识别竞赛”(以下简称CCF2017)数据集验证改进的DeepLabV3+模型。Landcover数据集主要用于高分辨率可见光波段的遥感影像语义分割,总覆盖面积为216.27 km2,采用人工标注(其中建筑物1.85 km2,林地72.2 km2,水体13.25 km2)。CCF2017数据集为2015年中国南方某地区亚米级的高分辨率遥感影像,采用人工标注的方式生成标注图,相对Landcover数据集,CCF2017数据集产自中国,且含有道路信息,信息详见表2。

表2 数据集详情
为方便模型训练,本文先将两个数据集分别裁剪成2 000张512像素×512像素大小的小幅影像,其中1 600张图片作为训练集,200张图片作为验证集,200张图片作为测试集,然后对图像进行随机裁剪、翻转、缩放、添加噪声等预处理,利用本文改进DeepLabV3+模型、原始DeepLabV3+模型以及其他主流分割算法进行训练,最后进行评价分析、预测。实验流程如图3所示。
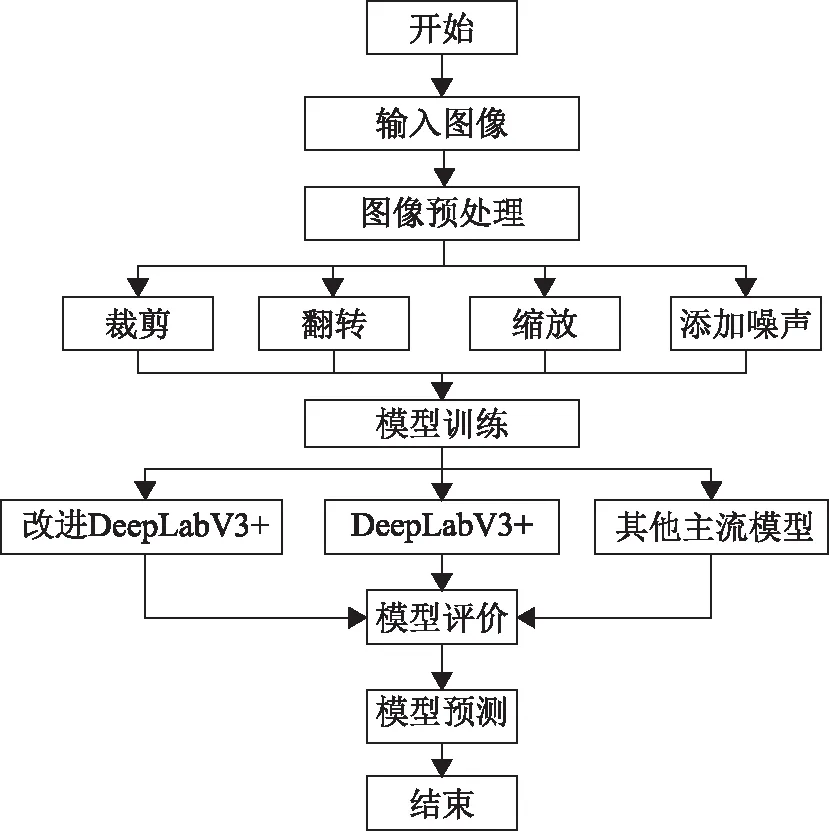
图3 实验流程
2.3 评价指标
在图像分割领域中,预测的结果会出现四种:真正(true positive,TP)、假正(false positive,FP)、真负(true negative,TN)、假负(false negative,FN),评估模型质量主要通过两个指标进行判断,即平均像素精度(mean pixel accuracy,mPA)、平均交并比(mean intersection over union,MIoU)。另外,由于本文的数据集类别不平衡,不加以调整,模型评价很容易偏向大类别而放弃小类别,因此需要一种能够惩罚模型的“偏向性”指标来纠正评价偏差。在传统的遥感影像分类领域中,Kappa系数是评价影像分类效果的一个重要指标,该系数能利用混淆矩阵对模型进行评价,可以有效解决指标“偏向性”问题。因此本文选择mPA、MIoU、Kappa系数共同作为评价指标。
2.4 改进的DeepLabV3+模型消融实验
原始DeepLabV3+为平衡精度与速度,使用骨干网Xception65提取到分辨率分别为64×64和32×32,即输出步长(output stride,OS)为16和8的特征图验证模型性能,其中OS等于16时的特征图尺寸相对较小,在相同配置环境下模型可以更快收敛但精度略低,OS等于8时的情况相反。本文沿用原始DeepLabV3+的思路,在Landcover数据集上,首先利用Xception65骨干网提取到上述两种64像素×64像素和32像素×32像素的特征图,然后分别对改进的ASPP模块、添加的FAF注意力模块以及基于子模块凸优化的加权Lovasz-softmax损失函数进行消融实验,经过50轮迭代训练后,模型收敛,最终的测试结果如图4所示。
通过图4可以发现,本文所提的改进策略均能在一定程度上提升模型性能,且融合上述策略后,综合改进模型性能最佳,具体评价指标如表3所示。

图4 DeepLabV3+消融实验结果对比
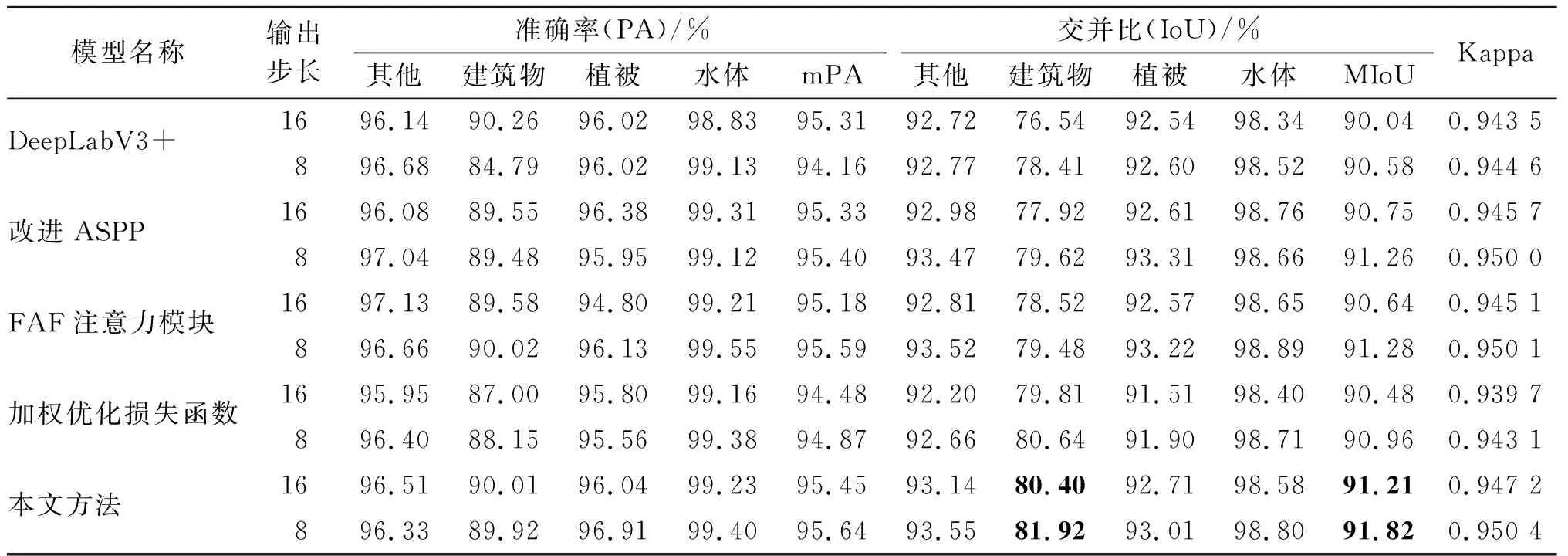
表3 DeepLabV3+模型实验对比
由表3可以看出,本文所提方法能有效提升DeepLabV3+的模型性能,不同的改进方法对原始模型均有一定的提升效果。
1)改进原始模型的ASPP后,由于使用了采样率分别为4、8、12、16、20、24的六组并行空洞卷积,同时使用感受野融合策略有效提高了特征利用率,改进的ASPP模块可以提取更多尺度的特征信息,尤其是对于像素占比较低的建筑物,同时也增强了较大尺度地物目标的提取能力,MIoU相对原始模型在OS=16和OS=8的情况下分别提升了0.71%和0.68%。
2)在添加了FAF注意力模块之后,由于FAF模块对含有丰富空间信息的浅层特征使用空间注意力特征进行加权,对含有丰富的语义编码信息的深层特征进行加权,能够最大效率地挖掘不同特征的信息,实验结果显示,经过FAF注意力加权的DeepLabV3+模型能够更有效地关注焦点区域,MIoU在OS=16和OS=8的情况下相对原始DeepLabV3+模型分别提升了0.6%和0.7%。
3)在使用基于子模块凸优化的Lovasz-softmax loss加权优化原始DeepLabV3+模型里的softmax loss后,显著改善了像素占比较小的地物目标分割效果,其中建筑物的IoU相较原始模型在OS=16和OS=8的情况下分别提升了3.27%和2.23%,模型的MIoU也分别提升了0.44%和0.38%。融合以上三种改进策略后,改进的DeepLabV3+取得了最佳分割性能,MIoU相较原始模型分别提升了1.17%和1.24%,准确率分别提升了0.14%和1.48%,Kappa系数分别提升了0.003 7和0.005 8。
2.5 主流分割算法对比实验
上述消融实验证明了本文所提方法的科学性和有效性,为充分对比本文方法与现阶段主流的语义分割算法如Fast-SCNN[28]、HRNet[29]、ICNet[30]、PSPNet[31]、U-Net的先进性与鲁棒性,本节选取Landcover和CCF2017数据集进行对比实验,采用与前文一致的数据预处理策略,所有模型经过50轮迭代训练之后,测试结果如图5所示。
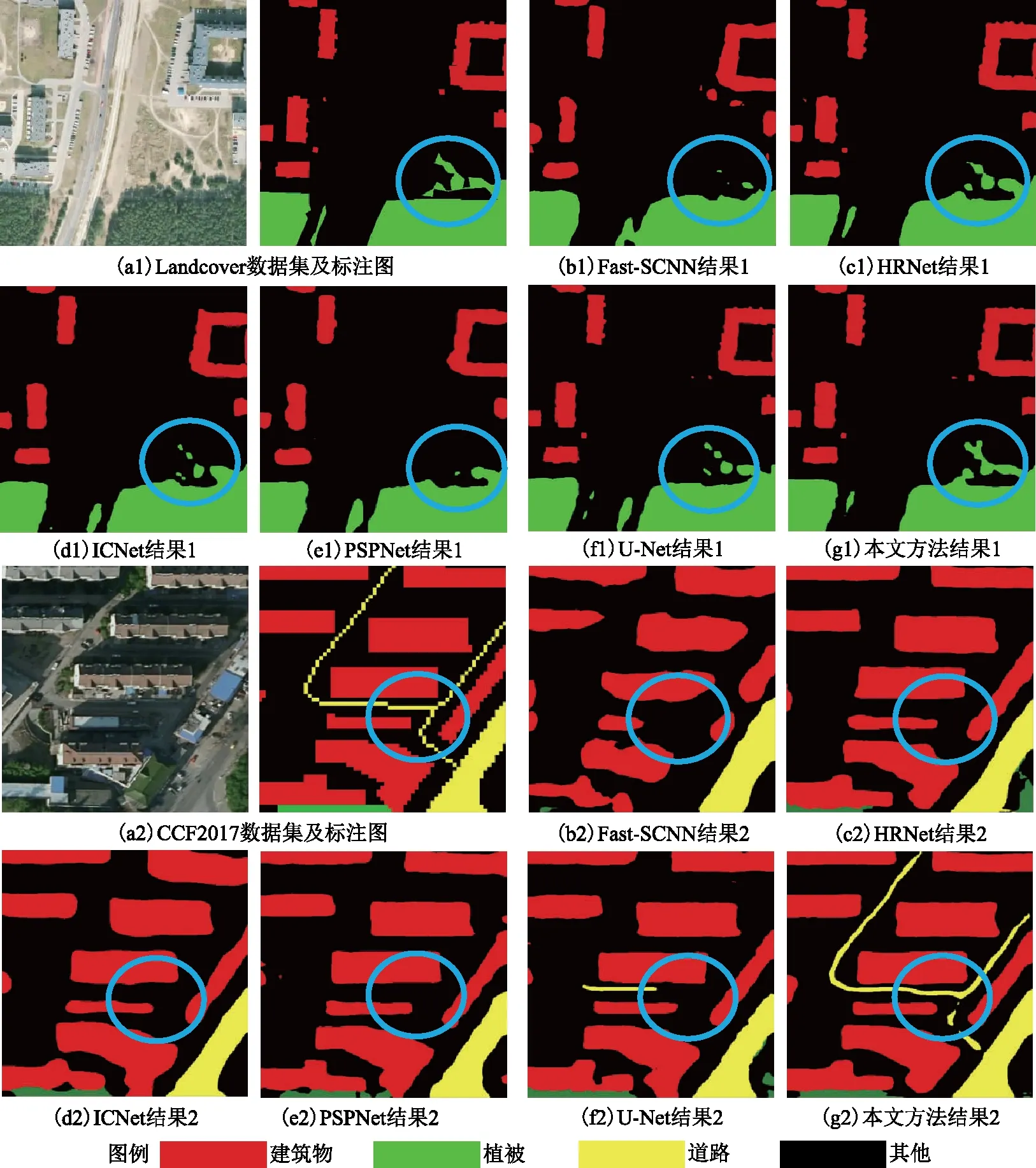
图5 主流分割算法对比
由图5可以看出,本文方法在DeepLabV3+模型的ASPP模块中减小采样率、改用六组并行空洞卷积,可以提取包含细节信息的更多尺度的特征,同时利用了感受野融合思想,通过融合输入与不同感受野的特征建立像素间的远程依赖,增强了不同尺度特征之间的相关性,有效提升了模型对于小尺度目标的特征提取能力。此外,通过优化损失函数有效解决了类别不均衡的问题,添加FAF模块能使模型更有效地从浅层特征和深层特征挖掘空间和通道信息。具体数据如表4所示,本文方法在Landcover和CCF2017数据集都取得了最高精度,尤其提取建筑物、道路等小尺度地物特征方面具有显著优势,建筑物的IoU在两个数据集上达到最高,为81.92%和90.31%,道路的IoU达到了83.77%,相对其他模型具有更高的道路连通性。
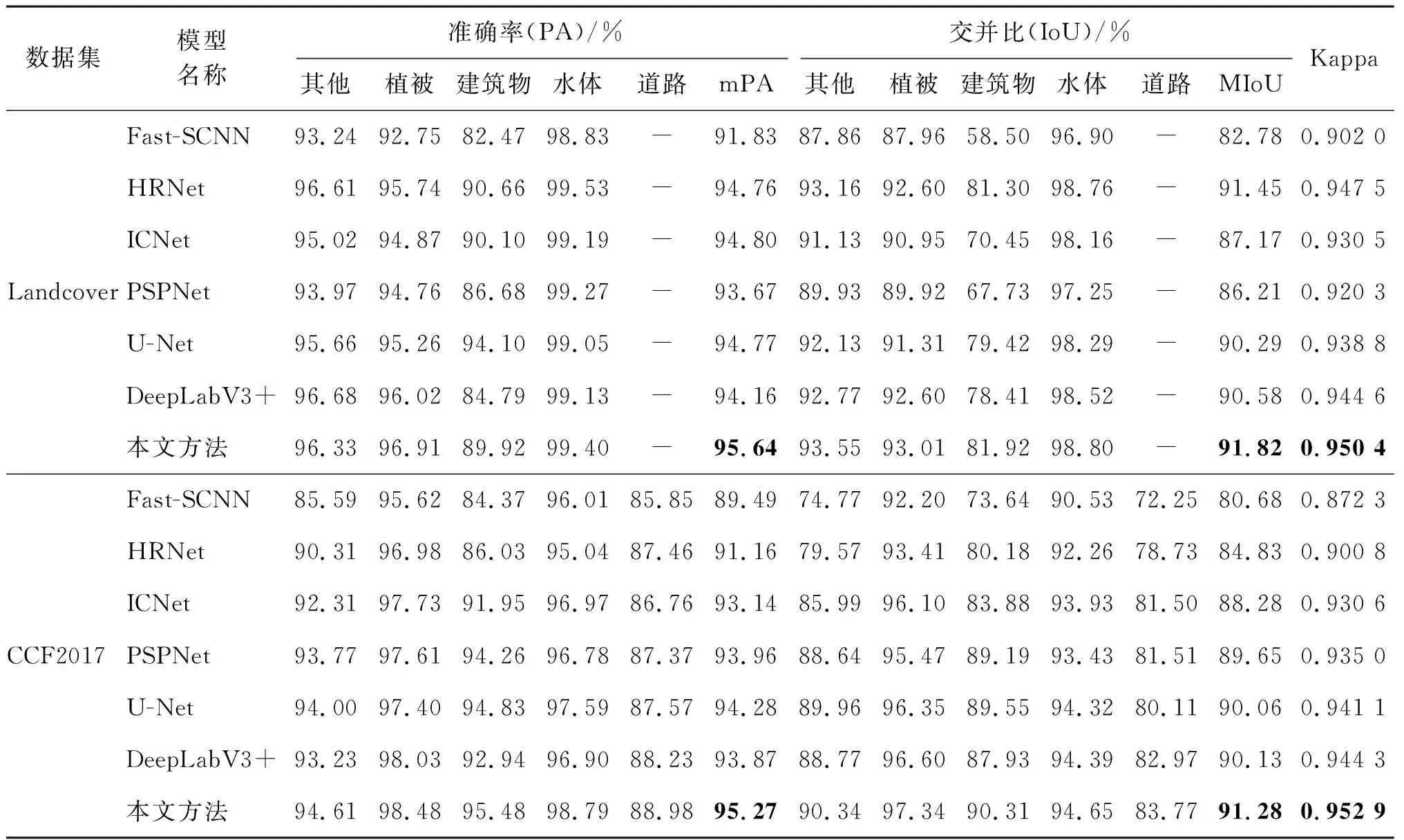
表4 主流分割算法精度评价
本文方法在两个数据集上均取得最高的MIoU,进一步验证了本文方法具有较高的鲁棒性,在遥感影像语义分割领域中有较好的应用前景。
3 结束语
本文采用多组并行空洞卷积提取多尺度特征,利用感受野融合策略改进ASPP,优化损失函数,提出利用FAF注意力充分挖掘不同特征信息,在Landcover和CCF2017数据集上进行训练和测试,得到以下主要结论。
1)利用多组并行空洞卷积能够有效提取更多尺度的特征信息,在降低空洞卷积采样率以及进行感受野融合之后,模型对于建筑物等小尺度地物提取能力在OS=16和OS=8的情况下分别提升0.71%和0.68%。
2)提出的FAF注意力模块能够有效挖掘浅层特征的空间位置信息和深层特征的语义信息,改进后模型预测结果的纹理信息更加精确,MIoU分别提升了0.6%和0.7%。
3)基于子模块凸优化的加权Lovasz-softmax loss能够有效改善类别不均衡问题,对于建筑物的特征提取改善效果最明显,在OS=16和OS=8两种情况下,IoU分别提升3.27%和2.23%,但由于过分关注小尺度目标,致使部分大尺度目标精度下降。
4)在融合以上三种改进策略后,改进的DeepLabV3+模型获得了最佳性能,有效解决了原始模型多尺度目标企图能力较弱、类别不均衡、空间位置信息挖掘欠佳的问题,最终的MIoU分别提升1.17%和1.24%。
5)利用不同数据集对本文改进的DeepLabV3+模型进行验证,测试结果表明,本文方法在不同数据集上都取得了最优结果,进一步证明了本文方法具有较高的鲁棒性和科学性。
本研究表明,基于以上策略改进的DeepLabV3+更适合遥感影像语义分割领域,在多尺度目标提取以及样本类别不均衡情况下相对其他模型均有较大优势。但本文未对目标边缘进行优化,林地等不规则地物目标分割纹理有待改进,后期将考虑添加边缘约束,基于边缘增强改进模型。此外,本研究使用的数据集类别相对有限,缺少耕地等典型地物要素,且数据类别较广,如水体没有进一步划分为河流、湖泊等,后期将增加改进模型在遥感影像更多地物类别方面的研究。同时,将考虑运用模型压缩和模型剪枝技术对改进的DeepLabV3+算法进行优化,保证在性能基本不变的情况下轻量化模型。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
上海金属(2021年2期)2021-04-07
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
学生天地(2020年18期)2020-08-25
传媒评论(2017年3期)2017-06-13
故事作文·高年级(2017年2期)2017-03-01
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
漫画月刊·哈版(2009年10期)2009-03-26
