
轻量化卷积神经网络的步态识别
2022-08-18 12:55:50王红茹苑浩然
哈尔滨商业大学学报(自然科学版) 2022年4期
王红茹, 苑浩然
(哈尔滨工程大学 信息与通信工程学院, 哈尔滨 150001)
步态特征是一种重要的人体生物特征,基于步态特征的识别技术与传统的生物识别技术如虹膜识别,指纹识别,面部识别[1]等相比具有识别距离远、对分辨率要求较低、以及无需目标配合等优势.近些年来,基于视频序列的步态识别技术相继被提出,因为视频序列中可以包含整个行走过程中的全部信息.基于上述两种问题,本文提出利用目标的步态视频序列合成步态能量图作为识别载体,基于深层卷积神经网络来进行特征提取与分类的步态识别方法.步态视频序列中包含目标整个行走过程中的全部信息,步态能量图(Gait energy image, GEI)[2]是将一个步态周期内的步态图像加权平均得到的.GEI充分利用了步态序列之间的连续性和动态性,同时减少了输入计算量,提高了特征提取效率.利用多组标记好身份的GEI组成数据集,通过卷积神经网络(Convolutional neural networks,CNNs)[3]提取出训练集中的高级步态特征,根据这些特征找到与待测目标最为相似的身份标签是最高效的步态识别方法.
卷积神经网络算法在图像分类领域有着卓越的表现,卷积神经网络通过多层卷积操作提取出图像中的高级特征,并通过反向传播算法不断更新卷积核中的参数完成对数据集中不同对象的特征的学习[4].相比于传统图像分类算法深度学习技术可以将特征提取与识别分类相结合,提高算法的应用效率.Yan[5]等首先提出将步态能量图与CNN 结合的步态识别算法,该方法可以提取步态能量图中的非线性高级特征, 并引入多任务学习模型,极大的优化了步态识别算法性能.但受网络层数限制,对有遮挡条件下的识别效果有限.Li[6]等提出一种基于深度学习 VGG-19 网络的识别方法,这是一种深层的卷积神经网络模型.步态序列经过周期检测后直接送入 VGG 网络进行特征提取, 最后利用联合贝叶斯进行步态识别,该方法提高了对遮挡条件下的识别准确率.
为了解决跨视角下的步态识别问题,Tan[7]等提出将GEI 送入使用双通道卷积神经网络训练匹配模型, 两个通道共享参数,通过比对探针(Probe)与图库(Gallery)中不同视角下的特征相似度达到匹配步态特征来识别人的身份的目的. 提高了应对视角改变后识别的鲁棒性.Wolf[8]等利用3D卷积神经网络,充分利用步态序列中的时空特性,提高跨视角识别能力.Cao[9]等在步态识别中加入了严谨的时序维度特征,使用MGP(Multilayer Global Pipeline)模块融合不同卷积层的输出信息,增加模型感受野.
上述研究者所提出的算法在特定的数据集上都达到了理想的识别效果,证明步态能量图与卷积神经网络相结合的高效性.同时利用卷积神经网络的步态识别算法存在着统一的弊端,如随着模型的复杂化造成的运算量增加,难以部署在嵌入式设备上.
对于模型轻量化的设计主要方法有:减少计算量,减少训练参数,降低实际运行时间以及简化底层实现方式四个方面.研究者相继提出了深度可分离卷积, 分组卷积, 可调超参数降低空间分辨率和减少通道数, 新的激活函数等方法[10], 并针对一些现有的结构的实际运行过程作了分析, 提出了架构设计原则,并根据这些原则来重新设计模型.
模型修剪(pruning connections)是通过将神经元间不必要的链接剪除[11]以缩减参数达到压缩模型的目的.量化模型(Model quantization)将具有代表性的权值和激活函数做量化处理[12],有利于模型的压缩和提高训练速度.知识蒸馏(Knowledge dis-tillation)利用大模型来教小模型,提高了小模型的性能.这些方法一定程度上解决了深度学习模型的轻量化问题,但对模型的性能并没有提高.
网络层数的加深虽然可以提高的特征空间的丰富性,却稀释了有效的特征信息导致识别效果反而下降等问题.此外,目前现有的步态数据集多为小样本数据集,在训练过程中容易产生过拟合的情况.本文针对以上问题分别做出卷积过程和模型结构上的优化,实现了网络模型轻量化,有效地提高了模型的复杂条件下识别能力.
1 本文方法
本文从目标的行走视频中通过一系列图像处理的方式得到目标的步态能量图,并根据一定比例划分出训练集和测试集.对新的L-ResNet-50模型进行优化训练,直至模型收敛,再利用测试集验证模型的识别效果,整体的算法框架如图1所示.

图1 基于L-ResNet-50的步态识别算法框架Figure 1 Gait recognition algorithm framework based on L-ResNet-50
1.1 模型泛步态能量图的提取
首先使用上文提到的步态能量图作为卷积神经网络模型的学习对象.合成GEI图像首先是从原始视频中利用背景消减法提取出步态目标.再对提取出的目标做一系列形态学的处理,生成理想的目标剪影图像.通常采用步态周期来表示步态能量,步态能量可以反映人体步行过程中的步态静态信息和动态信息.根据每个像素点在同一位置出现的频率设置相应的像素值,反应人体行走过程中的能量信息.合成GEI公式如下:
(1)
其中:N代表一个步态周期内的所有图像,It是一张步态图像,t则代表帧数.由GEI组成训练集和测试集如图2所示.

图2 由步态能量图组成的训练集和测试集Figure 2 GEI samples of training and test set
1.2 轻量化处理
通过对CNN的特征图可视化操作本文发现,一个卷积层生成的特征图中存在大量的相似特征图.图3是一张步态能量图在卷积操作后一组的输出示例,这组特征图中存在彼此相似的情况.如这些相似的特征图之间存在误差允许内的相关性,便可以利用简单的操作从一部分基础的特征图中变换而来.相比于复杂的卷积过程这些简单的操作并不需要占用大量计算资源,在反向传播算法中也只需要更新生成基础特征图的卷积核参数,以此缩小训练参数规模.

图3 ResNet-50的第一卷积层获得的部分特征图Figure 3 Output of partial feature graph of ResNet-50
根据上述理论,本文设计一种新的轻量化的卷积方法,同样将卷积过程分为两部分:第一部分为传统的卷积操作,但是只生成部分基础特征图;第二部分是利用这些基础的特征图通过线性变换派生出冗余的特征图.该操作将一个传统卷积过程分为这两部分的具体步骤如图4所示.

图4 轻量化操作的基本结构Figure 4 Lightweight residual module
进一步分析轻量化操作对模型参数量的影响.假设我们在一卷积层中原本输出为c个通道的特征图,而新的轻量化操作只需要生成 个基础特征图,剩下的特征图由(s-1)组简单的线性操作完成.则原卷积层与轻量级处理后的卷积层参数比R如式(2)所示:
(2)
其中:⊕代表将两部分特征图相加的操作;s-1则代表不需要训练的参数部分.理论上这一卷积层在轻量化处理后需训练的参数量缩小了约s倍.
1.3 注意力机制模块
近些年来注意力机制被广泛的应用于CNN算法当中,SENet[13]作为一种基于注意力机制的深度学习模型是当年ImageNet比赛的冠军.它主要由Squeeze部分和Excitation部分组合而成,具体结构如图5所示.
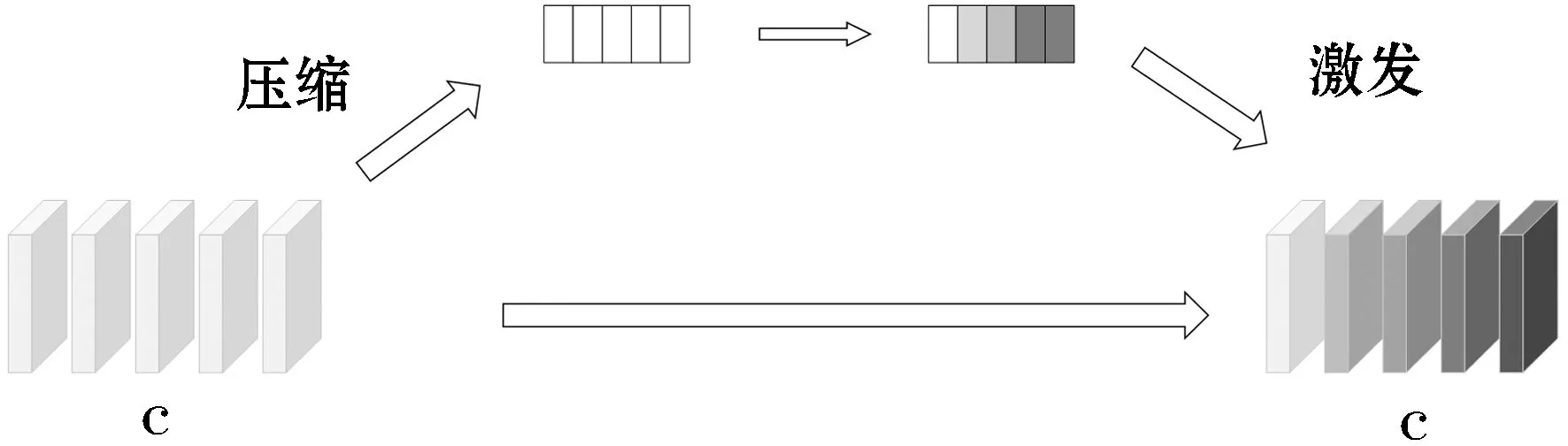
图5 SENet的基本工作原理Figure 5 Basic working principles of SENet
Squeeze(压缩)部分,原始特征图的维度为H*W*C,C是通道数.压缩过程是把H*W*C压缩为1*1*C,相当于把H*W变成一个一维的序列,实际操作中一般是用global average pooling实现该目的.H*W压缩成一维后,这一维参数获得了之前H*W全局的视野,感受区域更广.Excitation(激发)部分,在得到Squeeze的1*1*C的表示后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用激励到之前的feature map的对应channel上.
将SENet的思想设计成SEmodule,插入到轻量化网络的关键输入节点,成为轻量化模块的基础特征图的选择机制,提高了关键特征的利用率并保证这些特征不会随着模型深度的增加而被稀释.
1.4 线性操作
为了实现对基础特征图的再卷积,本文使用深度可分离卷积[14]中的Depthwise卷积操作.Depthwise convolution的一个卷积核只负责一个通道,一个通道只被一个卷积核卷积,具体操作如图6所示.

图6 使用Depthwise卷积生成冗余特征图Figure 6 Specific Depthwise of the lightweight module
利用再卷积操作使派生出的特征图更接近原始的特征图,有效保留特征图中的步态信息.Depthwise卷积核中的参数只需要完整训练一次,当模型收敛后冻结卷积核中的参数,成为模型的固定参数反复使用.
2 轻量模型搭建
2.1 轻量化模块优化
由于轻量化模块使用的是利用简单的线性操作来生成冗余的特征图,深层次特征图的失真情况不可避免.本文引入残差网络[15](ResNet)的架构思想,在每个轻量化模块中引入一条“捷径”,通过恒等映射的方式将上一层输出的信息传输到后面的层中,保护了初始信息的完整性,改善了深层卷积时的特征图失真问题.通过优化轻量级模块的最终结构如图7所示.
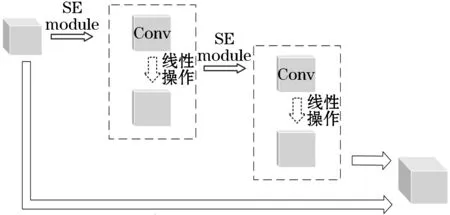
图7 轻量级模块的结构示意图Figure 7 Structure diagram of a lightweight module
2.2 轻量化卷积神经网络模型
利用优化后的轻量化模块,通过堆叠的方式组建成深层的卷积神经网络.同样是效仿ResNet-50的框架结构,用轻量化模块代替原来的残差块.第一层为标准的卷积操作生成16个通道的特征图,后续使用轻量化模块串联的方式扩展通道数.最后利用全局平均池和卷积层将特征图转换为全连接层以进行分类识别.由此组合成的轻量化ResNet模型本文称为L-ResNet(Light ResNet)的基本设计如表1.
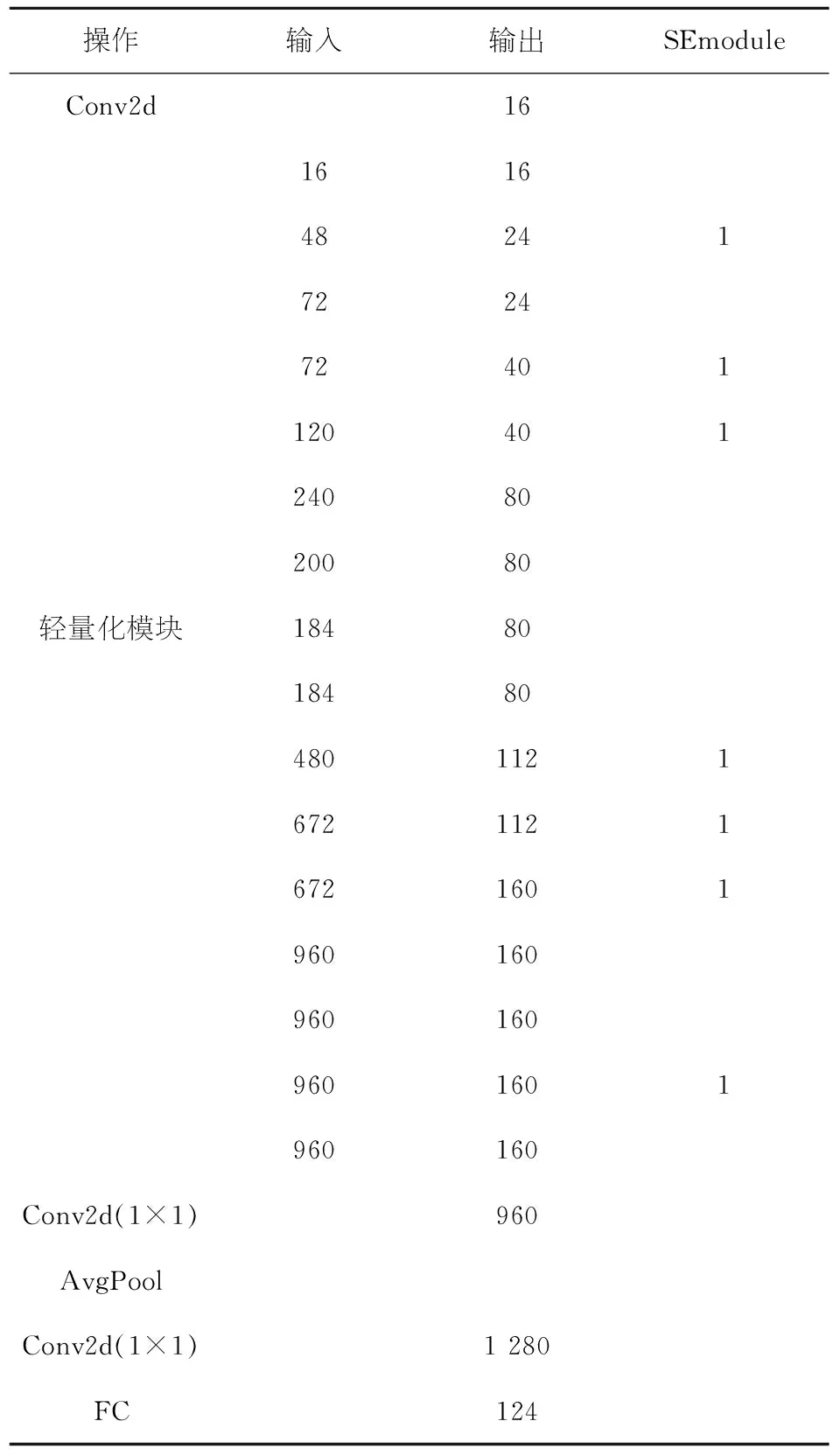
表1 轻量化网络结构参数
3 实验部分
本文使用新模块构建的L-ResNet模型在主流的步态数据集上完成实验,检验模型不同条件下的识别效果.
3.1 数据准备
实验基于中科院CASIA-B[16]数据集,该数据集包含124个人步态序列,每个人物下有10组行走序列:6组正常情况(nm),2组穿着大衣情况(cl)以及两组背包情况(bg).每种情况下又包含了11种不同的视角下的步态序列(0°,18°,36°,…,180°).为了验证模型的泛化能力,使用大阪大学的OU-ISIR[17]步态数据库检验测试效果.选取数据库中50个身份的四个视角下正常行走的步态视频合成步态能量图,每个身份合成四张,其中:两张作为训练集,两外两张用于测试.
3.2 实验结果
3.2.1 比例参数性能验证
收集了正常行走条件下三种不同的基础特征图与冗余特征图的比例下的实验数据(s=1,s=2,s=3),包括识别率,需训练参数量和浮点运算量.模型的参数计算与浮点运算量计算公式如式(3)、(4)所示.Param代表参数数量,FLOPs代表浮点运算量,每种计算量均分为卷积层(conv)和全连接层(fc)大小两部分.实验结果与原始的ResNe-50模型在这三个维度进行了对比试验.对比结果如表2所示.
paramconv=(kw*kh*cin)*cout+cout
paramfc=(nm*nout)+nout
(3)
FLOPsconv=[(kw*kh*cin)*cout+cout]*H*W
FLOPsfc=(nin*nout)+nout
(4)

表2 三种不同比例与原始ResNet-50模型比对
根据表2分析,当基础特征图与冗余特征图的比例为1∶1时( =1)识别效果最好,超过了原始的ResNet网络,参数量与浮点计算量缩减幅度接近50%.而当 继续增大,模型的参数量会继续大幅度缩减,识别效果却不理想,分析原因可能是基础特征图过少造成的特征图失真.综上所述s=1时,模型的识别效果最为理想,超过原始模型且参数量较小.在相同超参数的情况下模型所需要的训练时间更短,而在loss曲线的收敛效果上新的轻量级网络优于传统的ResNet-50网络,图8为L-ResNet模型在训练和测试时的损失函数曲线.

图8 两种网络的loss曲线Figure 8 Loss function
3.2.2 比例参数性能验证
该部分实验分别验证了模型对遮挡条件下和跨视角条件下的步态识别能力.验证有遮挡条件下的识别效果时训练集选取124组步态能量图,测试集分为携带挎包的能量图以及穿着大衣的能量图,测试两种情况下的识别率;验证跨视角条件下的识别效果则是选取100个步态目标的所有步态能量图组成训练集,剩余24个目标每个角度下选取四张正常行走能量图作为模板图像集,剩余的24组能量图组合成测试集.跨视角测试中会生成121个识别结果,平均识别率是这121个结果的平均值.表3为正常行走条件时的跨视角识别率,表4携带背包条件下的跨视角识别率,表5为穿着大衣条件下的跨视角识别率.
3.3 模型泛化实验
本节利用OU-ISIR[17]步态数据集检验该模型的泛化能力.选取数据集中50个步态目标,每个目标包含四个不同的视角(55°,65°,75°,85°),将标记好的GEI随机分为五组,每次实验保持一组用来测试,其余四组用来训练网络.最终的平均识别率如表6所示.实验结果表明新的轻量化模型对不同数据集的泛化能力非常出色.
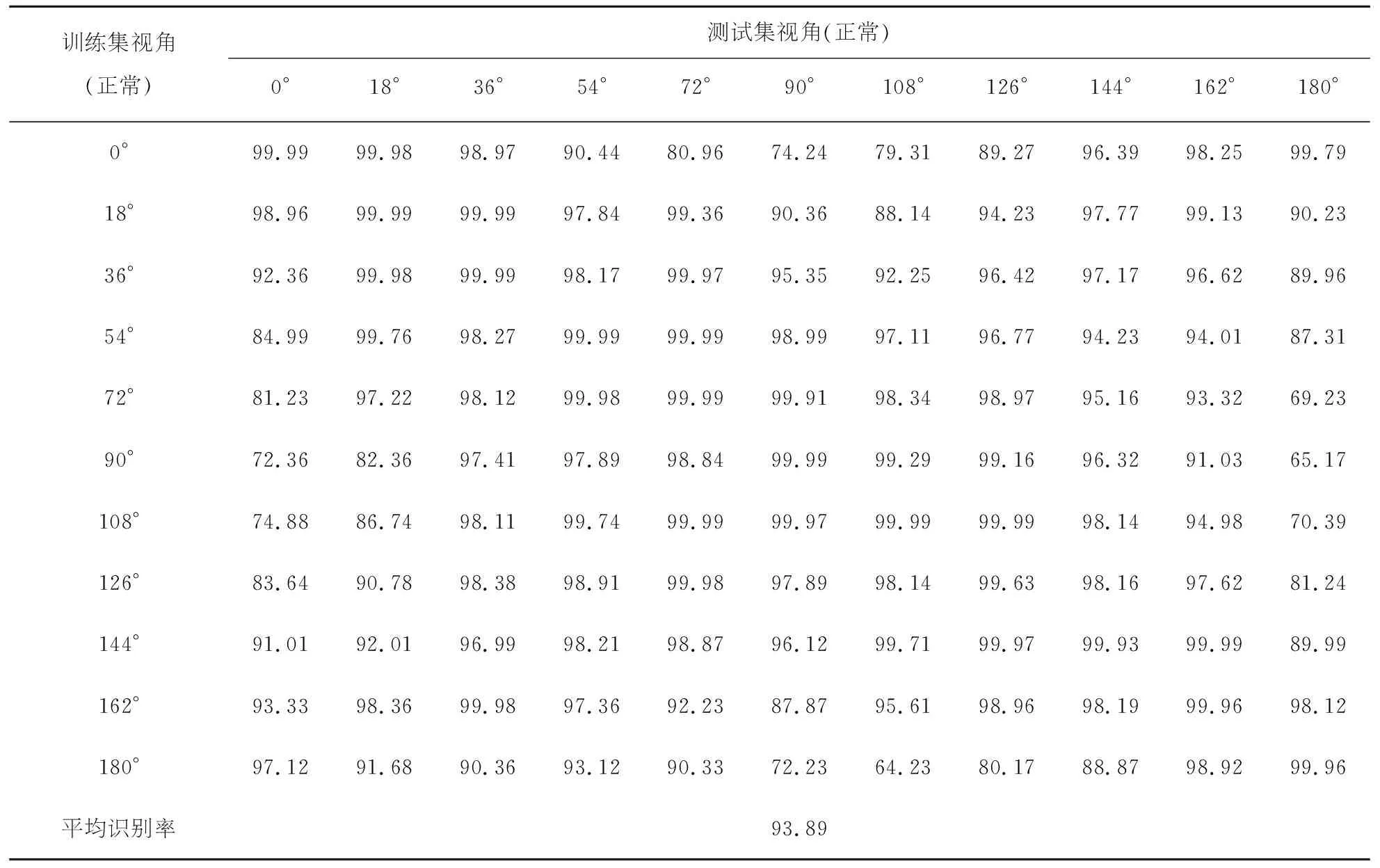
表3 正常行走跨视角识别率
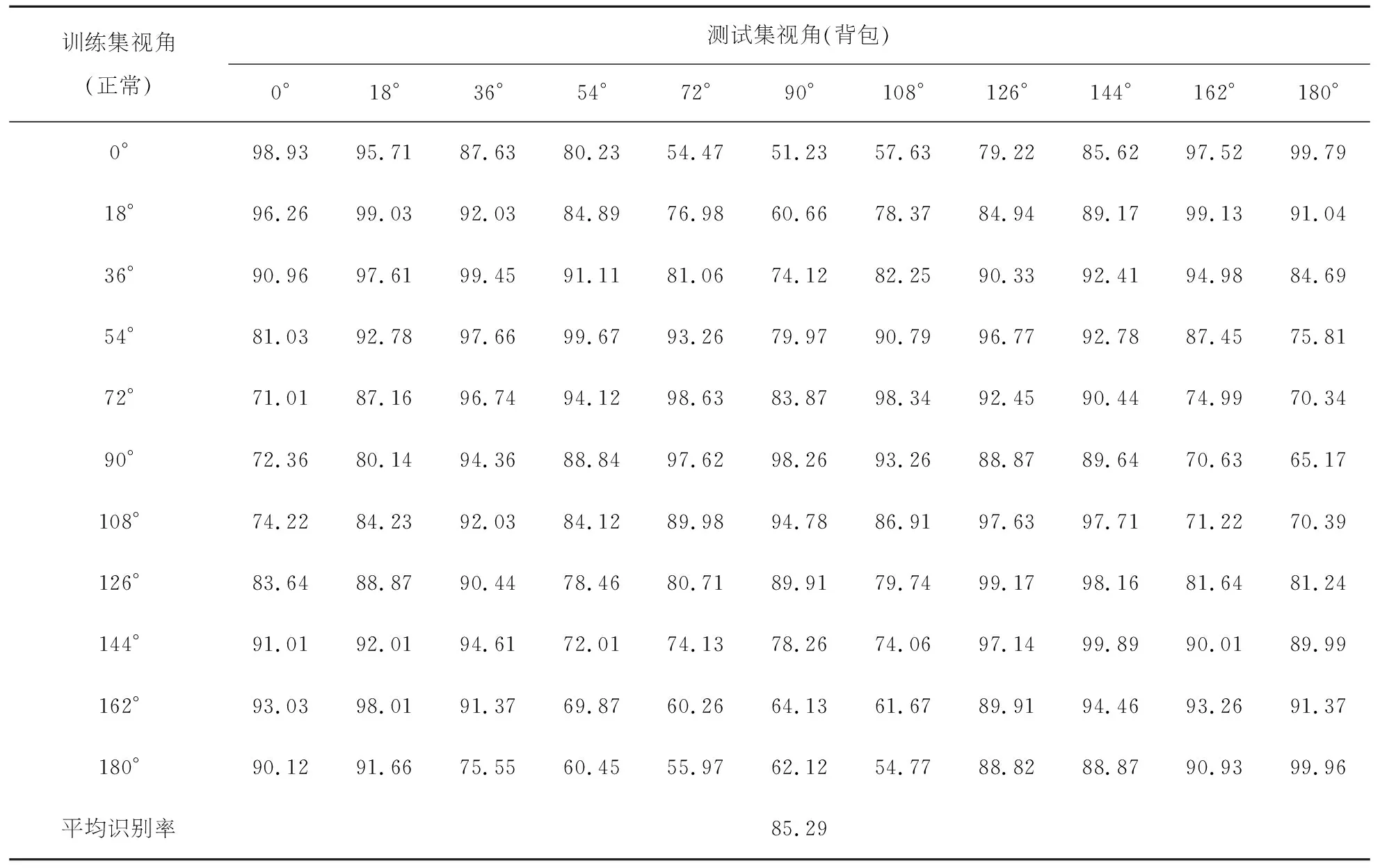
表4 携带背包条件下行走跨视角识别率
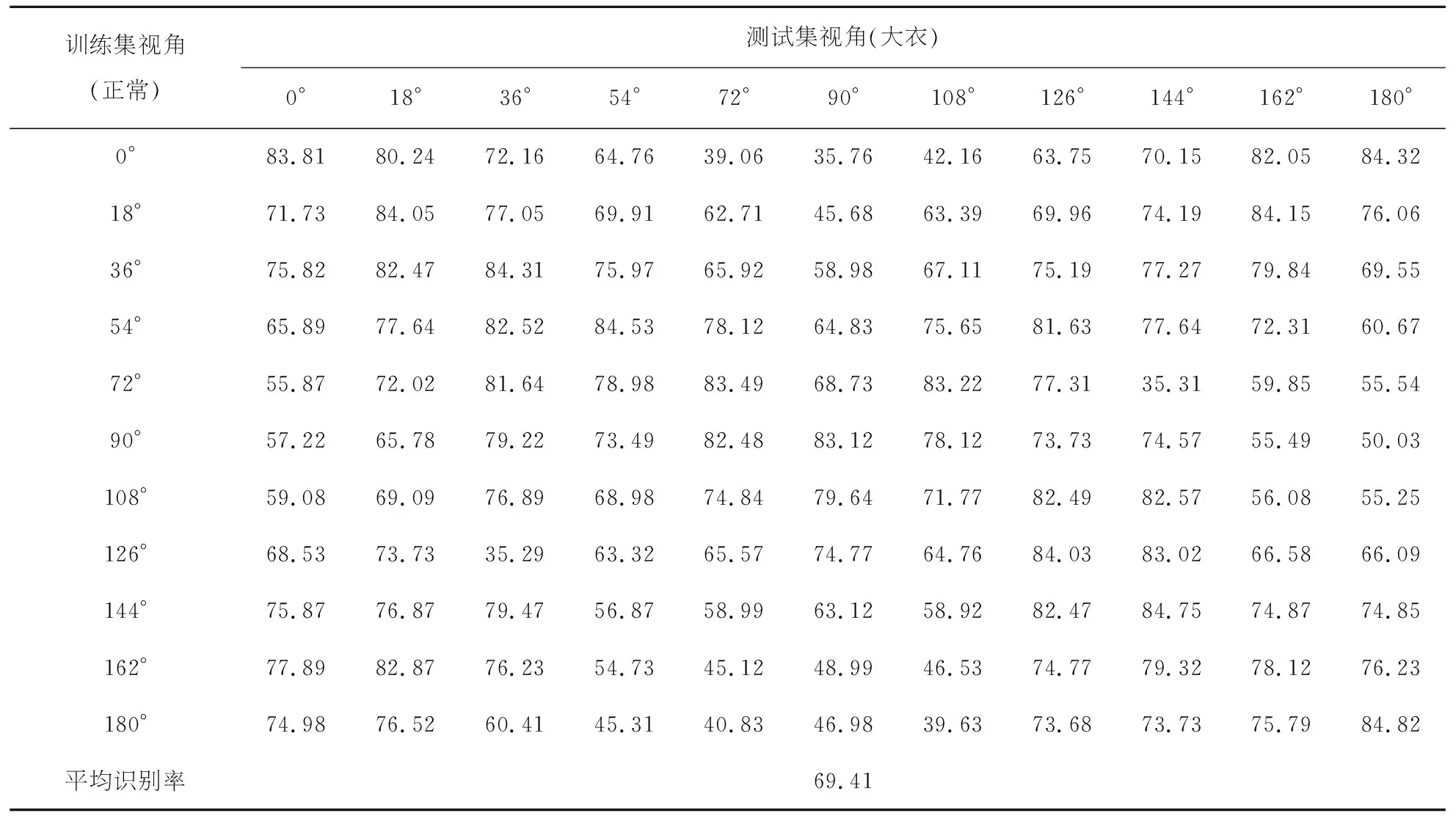
表5 穿着大衣行走条件下跨视角识别率

表6 在OU-ISIR步态数据集上获得的跨视角识别结果
4 结 语
本文提出了一种使用注意力机制选取主要的提出步态特征图,再利用无需训练的简单线性操作生成冗余特征图的思想搭建了新型的轻量化深层卷积神经网络模型.该模型有效提高了复杂条件下步态识别效果,同时减少了模型参数量,使得本文方法可以在普通的嵌入式设备上应用.
猜你喜欢
科学大众(2024年5期)2024-03-06 09:40:34
精密成形工程(2022年2期)2022-02-22 05:44:14
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
智富时代(2019年2期)2019-04-18 07:44:42
电子制作(2018年18期)2018-11-14 01:48:04
自动化学报(2018年6期)2018-07-23 02:55:42
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
专用汽车(2016年1期)2016-03-01 04:13:19
