
基于可扩展的自表示学习波段选择算法在近红外光谱回归建模中的影响研究
2022-08-17 01:39:16梁小娟马晋芳葛发欢肖环贤
分析测试学报 2022年8期
郭 拓,梁小娟,马晋芳,袁 凯,葛发欢,肖环贤
(1.陕西科技大学 电子信息与人工智能学院,陕西 西安 710021;2.暨南大学 光电工程系,广东 广州510632;3.中山大学 南沙研究院,广东 广州 511458;4.江西保利制药有限公司,江西 赣州 341900)
近红外光谱包含丰富的化学结构信息、化学成分信息以及物理信息,被广泛应用于食品安全、药物检测和饲料营养成分鉴别等领域[1]。但由于仪器噪声的干扰以及近红外光谱之间多重共线性问题,导致光谱信息中存在冗余信息,使得模型计算复杂,预测精度降低[2]。为排除无效信息,提高方法的准确度,有必要对建模波段进行筛选[3]。研究者们现已提出许多波段选择方法,并取得了一定的效果。
波段选择分为有监督和无监督两种方式[4]。有监督方法利用标签信息来选择波段,以最大限度地提高训练样本光谱数据与标签数据之间的联系。但由于人为标记误差或光谱数据本身的影响可能远大于光谱数据与标签数据之间的联系,进而导致所选波段具有典型的不稳定性[5]。这些因素促使了无监督波段选择算法的研究。
一般来说,无监督的方法通过探索与标签信息无关的光谱数据的内在关联性来选择具有代表性的波段。Ahmad等[6]提出了一种新的基于k均值聚类的统计波段选择方法,可较好地用于高光谱数据的波段选择。Thiagarajan等[7]使用核空间中的多层一维子空间聚类来推断字典,并使用一个简单的水平追踪方案获得稀疏码,最终得到特征波段。马盈仓等[8]提出了基于流形学习与L2,1范数的无监督多标签特征选择方法,该算法在L2,1范数回归的基础上,用特征流形和数据相似矩阵共同约束特征权重矩阵和伪标签矩阵,达到特征选择的目的。简彩仁等[9]提出了正交基低冗余无监督特征选择法,该方法在正交基下运用最大互信息系数矩阵选择低冗余性的特征子集。但是这些方法需要额外的分类或聚类来选择具有低冗余度的波段,且无法进行波段的自动选择。Zhu 等[10]提出了一种结合行稀疏性范数和自表示学习(Self-representation learning,SRL)的频带选择模型,可自动进行有效的波段选择。针对自表示学习算法只关注波段信息而忽略不同样本对波段选择的影响,以及无法进行动态存储波段权重的不足,可扩展的自表示学习算法(Scalable one-pass self-representation learning,SOP-SRL)在自表示学习的基础上添加了一个权重函数,以区分每个样本的贡献度。同时该算法设计了权重向量q,可根据系数矩阵的变化动态存储波段得分,以及通过添加选择波段和保持局部流行结构的约束项,更好地捕捉样本的内在信息。
本文首次将可扩展的自表示学习波段选择算法应用于近红外波长选择中,建立了安胎丸指标含量阿魏酸、黄芩苷和汉黄芩苷的近红外偏最小二乘校正模型,以期实现安胎丸3个指标含量的快速检测。
1 算法与原理
1.1 正则化自表示学习算法(Regularized self-representation,RSR)
给定矩阵X=[X1,…,Xn]T∈Rn×b,RSR 可将每个波段表示为其他波段(包括自身)的一种线性组合[10]。用公式表示如下:

式中,W∈Rb×b,E∈Rn×b分别为系数矩阵和残差矩阵。矩阵E的第i行表示重构误差,W反映不同特征的重要性并力求E达到最小。为了减小异常样本的干扰和避免平凡解,在求解W时采用L2,1范数描述E,并添加了正则化项R(W)。故上述最小优化问题可以描述如下:
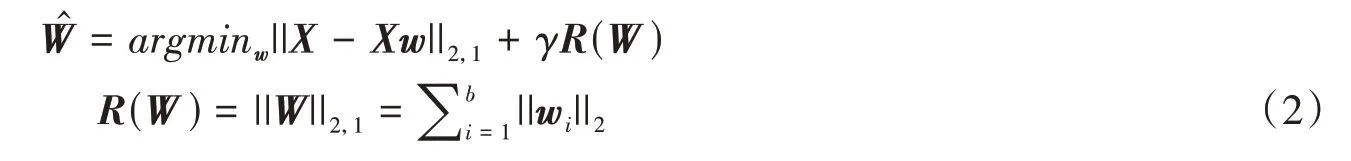
第一项是损失函数,第二项选用||W||2,1作为正则化项,γ为通过交叉验证确定的正则化参数,用来实现第一项和第二项之间的平衡。假设W= [w1,...,wi,...,wb]T,wi代表W的第i行,||Wi||2为特征权重,表示第i个特征在方程中的重要性,||Wi||2值越大,说明第i个波段选择的概率越大。在求解W后选择W得分较高的波段。
1.2 可扩展的自表示学习算法
正则化自表示学习算法对所有样本的贡献不加区分,但在光谱矩阵中,有些样本存在噪声干扰或人为操作因素的影响,不对样本的贡献度加以区分是不合理的。故SOP-SRL算法中加入了可扩展项,以区分不同样本对波段选择的贡献[11],优化问题(2)的表达式可扩展为:
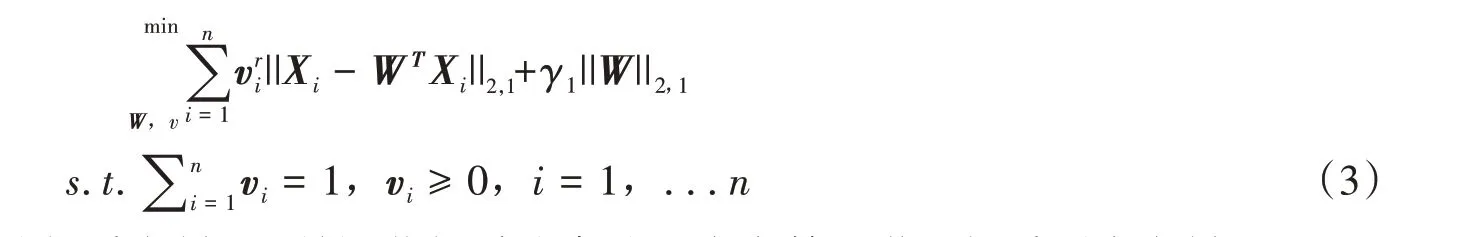
v∈Rn是取决于重构误差的权重向量,γ是调节权重分布的一个参数。设置权重缓存向量qϵRn用来动态记录所有波段的得分。由于RSR 算法在选取波段时,未考虑样本的一致性且仅从重构误差的角度来衡量,导致一些固有属性丢失,故SOP-SRL在表达式(3)中加入了新的正则化项,并考虑了数据的局部流形结构,因而新的优化表达式可表示为:
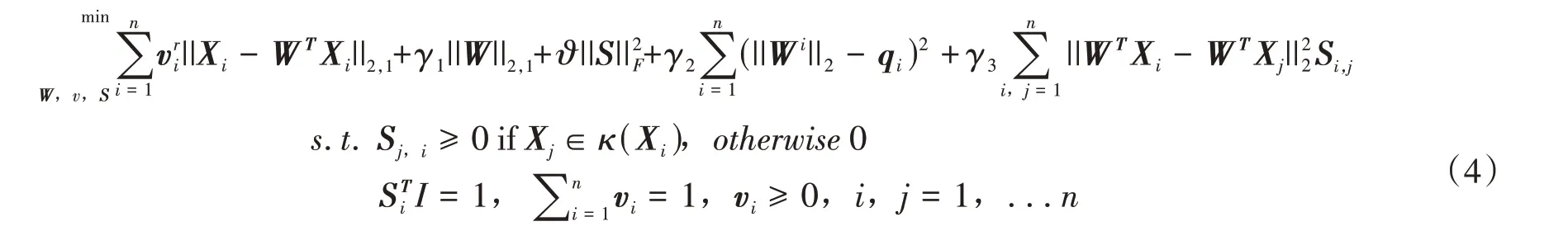
式中,第三项为考虑样本的一致性加入的新的正则化项,第四项和第五项用来调整图的流形化结构。ϑ、γ2和γ3为正则化参数,用来平衡这些项。S代表对应X的样本相似矩阵,Si,j代表第i个样本和第j个样本的相似度,κ(Xi)表示样本的KNN集合。
获取缓存向量q,选取得分较高的前m个q值用来选取波段,记为[q1,...,qj,...,qm]。
1.3 基于SOP-SRL的偏最小二乘算法
给定需要建立校正模型的光谱矩阵X=[X1,...,Xn]T∈Rn×b,通过SOP-SRL 算法,选取得分较高的前m个波段,故建模光谱矩阵变为X=[X1,1,...,Xi,j...,Xn,m]T∈Rn×m。假设每个指标含量矩阵为Y∈Rn×1,选用偏最小二乘建立安胎丸指标含量的校正模型。
假设Y与X线性相关,且Y=XB+N。其中,B为系数矩阵,N为噪声矩阵[12]。首先将X、Y分解为双线性,即:
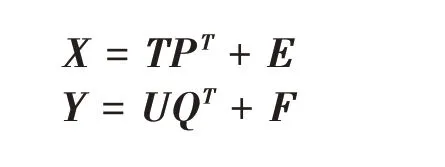
T、U分别为X、Y的得分矩阵,P、Q是载荷矩阵,E、F是残差矩阵。将X与Y相关联得U=TD+R。D∈Ra×a为通过使残差最小化而获得的内部模型系数的对角矩阵,又称为关联矩阵;a为PLS主成分数。由此可得性质值Y的估计量Ŷ=TDRT+F,计算得到的Ŷ即为每个指标含量预测矩阵。
2 实验部分
2.1 数据集
数据采集方式参考文献[13],本文采用在2015年测得的2013、2014、2015年的安胎丸样品数据,共计21 批105 个样本。这些光谱数据由近红外光谱仪(SupNIRl500,聚光科技(杭州)有限公司,光栅型)通过应用漫反射模式以1 nm 为间隔在1000~1800 nm 范围内测得,扫描次数32 次,每丸重复扫描3 次,取其平均值作为最终的光谱数据。同时采用高效液相色谱法(HPLC)(UltiMate 3000 高效液相色谱仪,美国Thermo公司)梯度洗脱测得21批安胎丸中阿魏酸、黄芩苷和汉黄芩苷的指标含量。
2.2 剔除异常数据及样本划分
在建模过程中,校正集数据可能存在异常光谱,影响校正模型的建立,导致预测结果存在偏差。本文首先使用马氏距离法剔除光谱中的异常数据[14],图1 为光谱值和指标含量值的马氏距离分布图。对样本和指标含量都进行异常值剔除,共剔除24 个样本,绘制剔除异常样本后安胎丸的近红外光谱图,如图2所示。
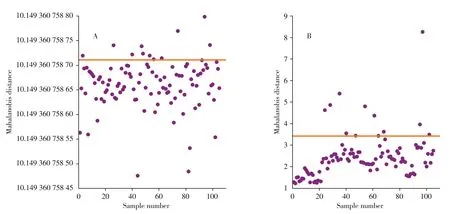
图1 光谱值(A)和指标含量值(B)的样本马氏距离分布图Fig.1 Mahalanobis distance distribution of spectral(A)and target ingredients(B)
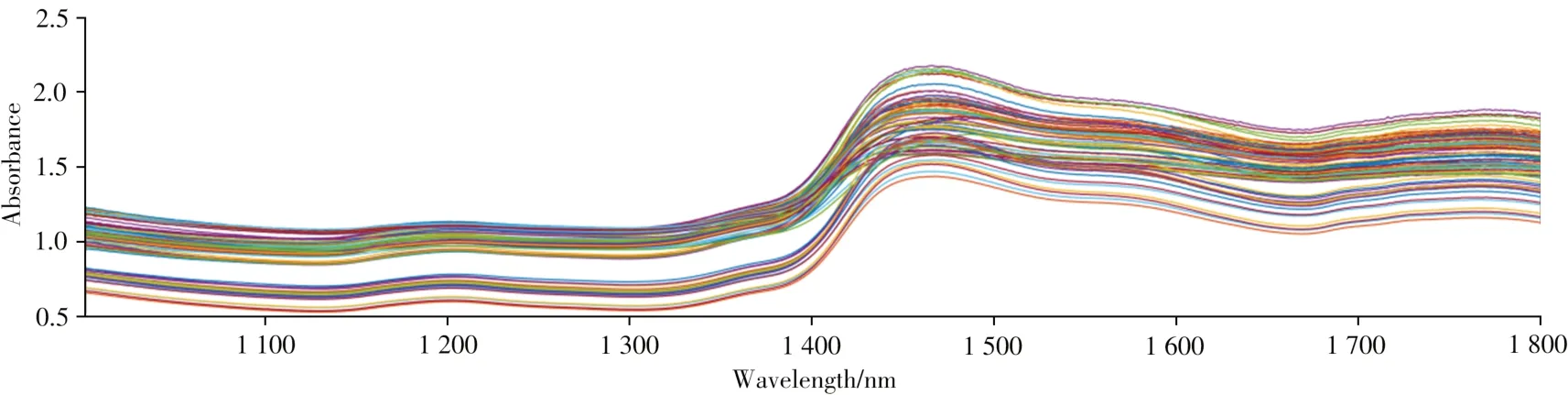
图2 剔除异常样本后的光谱图Fig.2 Spectra of abnormal samples removed
将余下的81 个样本按照X-Y 共生矩阵法(Sample set partitioning based on joint X-Y distance,SPXY)进行分组[15],选取56 个样本用于建模,25 个样本用于模型性能验证。样本集的分类结果如表1所示。

表1 安胎丸样本集的分类结果Table 1 Classification results of the Antai pills sample set
2.3 特征波长的选择及模型评价
特征波长选择通过去除不相关和冗余的特征,找到具有良好泛化能力的原始特征的紧凑表示,以提升模型的预测能力[10]。为了评价SOP-SRL 波长选择算法的有效性,分别对安胎丸关键指标成分阿魏酸、黄芩苷和汉黄芩苷建立偏最小二乘定量校正模型,并采用全波长、相关系数法(CC)、正则化自表示(RSR)、稀疏子空间聚类(SSC)算法作为对比算法。以校正决定系数、校正均方根误差(RMSECV)、预测决定系数和预测均方根误差(RMSEP)作为评价标准,对校正模型的预测效果进行评估[16]。决定系数反映变量之间的相关关系密切程度,RMSECV 用来衡量模型对校正集的预测能力,RMSEP 用来衡量模型对预测集的预测能力。决定系数越大,均方根误差越小,表明模型的性能越好。
3 结果与讨论
3.1 变量选择结果
CC、RSR、SSC 和SOP-SRL 在阿魏酸、黄芩苷和汉黄芩苷数据集上筛选出来的变量数分别为784、559、556、70,724、431、601、67,709、431、570、87。图3 为3 种指标成分运用4 种波长选择算法筛选的变量分布图。
从图3可以看出,不同波长选择算法对不同指标含量的波长筛选存在随机性。CC 选择的变量过多且过于集中,可能过分考虑了光谱数据与指标含量之间的相关信息而忽略了光谱数据本身之间的关联性,未能继续去除冗余。RSR、SSC 算法和SOP-SRL 算法选择的变量分布较为类似,都集中在1000~1100 nm 和1400~1700 nm。这3 种算法通过分析光谱数据的内在关联性选择出代表性较好的波段,SOP-SRL 算法涵盖了RSR 算法和SSC 算法的波段范围,说明SOP-SRL 算法在有效选择代表信息的同时更好地去除了冗余信息。
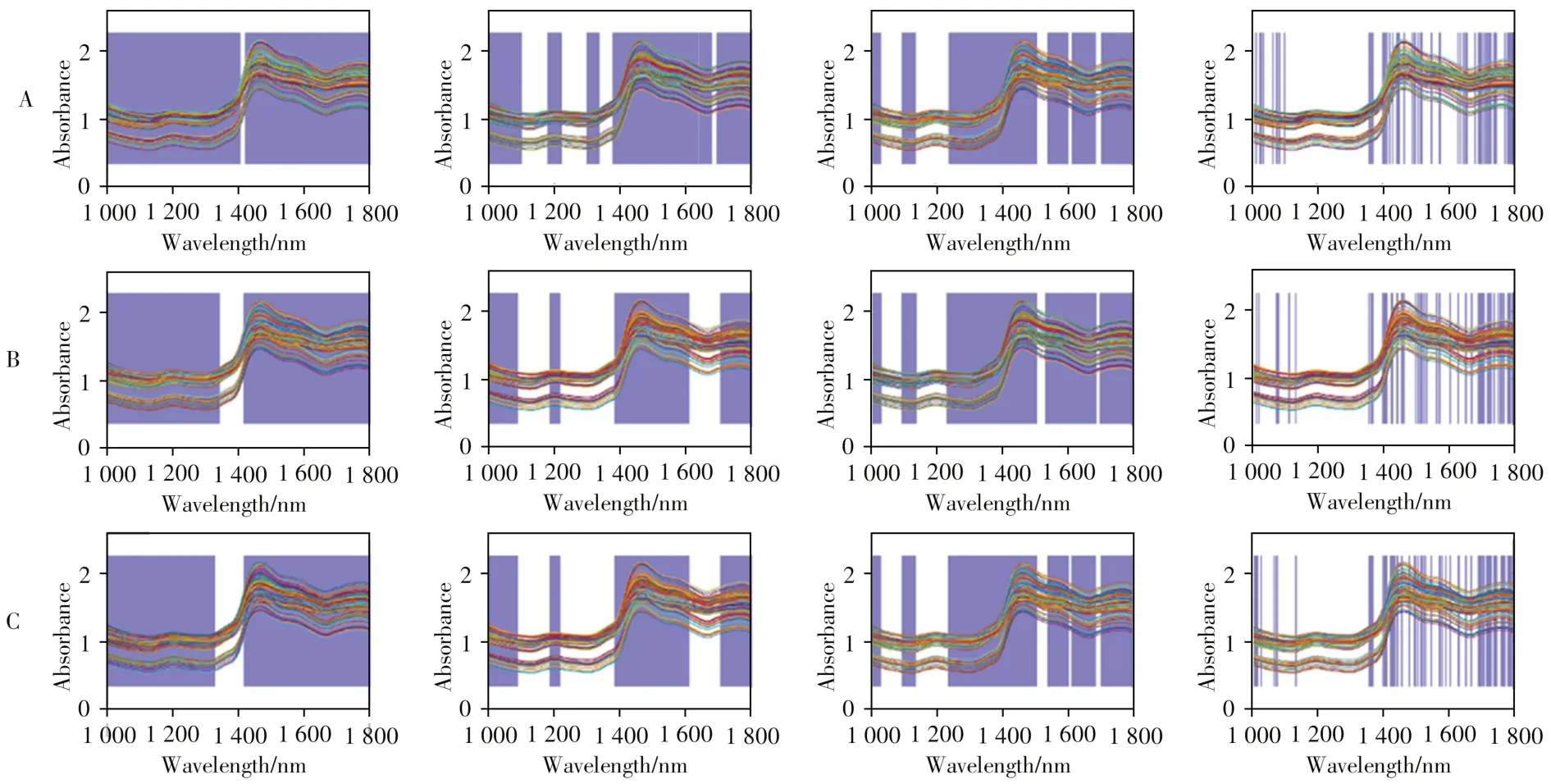
图3 各方法在3种安胎丸指标含量数据集中筛选出来的变量分布Fig.3 Distribution of variables selected by each method for three property values of Antai pillsA-C:ferulic acid,baicalin,wogonoside;from left to right:CC,RSR,SSC,SOP-SRL
3.2 PLS回归结果比较
按照表1的分类结果建立安胎丸指标含量阿魏酸、黄芩苷和汉黄芩苷的PLS校正模型。将基于4种波长选择算法保留的变量数建立的PLS 校正模型与基于全波长(FULL)建立的PLS 校正模型进行比较,以RMSECV 最小来确定样本的主成分数[17]。选用“2.3”所述4种指标评价模型性能,安胎丸光谱数据经过不同波长选择方法筛选的结果如表2所示。从表2可以看出,不同指标成分建立的模型不同,选择的波长变量数也不同;对于同一指标成分,采用不同的波长选择算法建立的近红外光谱校正模型较全波长有更好的预测效果,且建模所用的波长数更少。

表2 选用不同波长选择方法的PLS回归模型预测效果Table 2 Predictive effects of PLS regression model with different wavelength selection methods
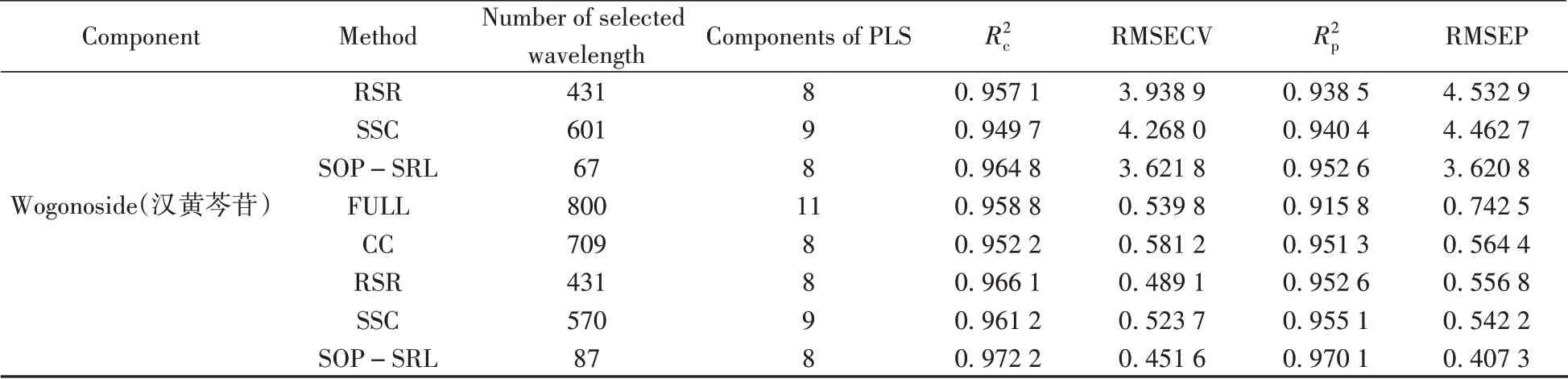
(续表2)
从阿魏酸的结果可以看出,4种波长选择算法的建模变量数分别为784、559、556和70,相比于全波长建模均有所减少,其中SOP-SRL算法选择出的变量数最少;相较于全波长,4种算法的分别从0.9306 提高到0.9323、0.9354、0.9308 和0.9473;分别从0.9119 提高到0.9129、0.9197、0.9231 和0.9388,表明4 种算法在减少波长变量的同时提高了变量之间的相关性。RMSECV 分别从0.0693下降到0.0685、0.0669、0.0692和0.0600,表明4种算法波长选择后模型的预测能力得到了提升;RMSEP 分别从0.0801 下降到0.0797、0.0765、0.0749 和0.0653,表明4 种算法波长选择后模型的泛化能力得到了提升。SOP-SRL算法相对于其他3种对比算法提升效果最为显著,表明对于安胎丸的阿魏酸这一指标含量,SOP-SRL 算法可以更加有效地筛选相关波长变量,并剔除无关变量,从而提升模型的预测效果。
从黄芩苷和汉黄芩苷的结果可以看出,相对于全波长,SOP-SRL的波长变量数从800分别减少到67 和87,RMSEP 从6.3495、0.7425 下降到3.6208、0.4073,分别下降了43%、45%。相应的R2p从0.8794、0.9158提高到0.9526、0.9701,分别提高了8%、6%。表明经SOP-SRL波长选择后的建模效果更好,模型的预测能力得到了显著提升。
整体来看,SOP-SRL 波长选择算法对3 种不同指标成分均有较好的预测效果,且相比于其他3 种波长选择算法效果更好,说明通过添加基于图形的正则化项和流形约束,能够显著提高所选频带的代表性。
4 结论
高效的中药质量评价是近红外光谱分析技术的一个重要研究方向,但在建立中药质量检测模型时,样品光谱数据中包含了大量的冗余信息,严重影响了模型的准确性。针对这一问题,本文提出了一种基于SOP-SRL 波段选择与PLS 建模的定量模型分析方法,并选取阿魏酸、黄芩苷和汉黄芩苷为研究对象,建立了安胎丸指标成分检测的近红外光谱模型。探究了可扩展的自表示学习波段选择算法对校正模型预测结果的影响,结果发现,基于该算法可以有效地选择出代表性更强的波段,大大减少模型计算量,同时模型的预测效果得到了显著提升。该算法为近红外光谱数据的波段选择提供了新方法。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
中国民间疗法(2021年16期)2021-11-04 08:13:48
现代畜牧科技(2021年8期)2021-10-13 07:21:56
中国民间疗法(2021年6期)2021-06-09 06:19:12
今日农业(2020年16期)2020-12-14 15:04:59
基层中医药(2020年7期)2020-09-11 06:38:06
中成药(2019年12期)2020-01-04 02:03:12
中成药(2017年12期)2018-01-19 02:06:54
中成药(2017年12期)2018-01-19 02:06:29
高师理科学刊(2016年8期)2016-06-15 20:27:45
