
基于深度学习的移动机器人障碍物检测研究
2022-08-16 10:29黄家才顾皞伟吕思男汤文俊
南京工程学院学报(自然科学版) 2022年2期
陈 田,黄家才,张 铎,顾皞伟,吕思男,汪 涛,汤文俊,唐 安
(南京工程学院工业中心、创新创业学院, 江苏 南京 211167)
随着人工智能技术的快速发展,移动机器人能够实现的功能越来越全面、实用,在人类的生产生活中扮演着越来越重要的角色,接替人类完成部分复杂、危险的工作.由于对移动机器人的需求不断增加,其所处的工作环境也越来越复杂.为使移动机器人安全稳定地行驶、工作,对移动机器人所处环境的障碍物进行检测显得尤为重要.
近年来,对移动机器人的研究最先开始于军事领域,而后又扩展到了其他诸多领域,呈现出快速发展的态势.随着深度学习和目标检测算法的兴起,越来越多的研究人员将其应用于移动机器人的工作环境检测.20世纪90年代,文献[1]对神经网络进行离线训练,将训练后的网络应用于室外环境的理解,具有较高的实时性,但在复杂环境下,对环境的适应性较差;文献[2]基于SSD算法,将改进后的算法运用于矿用巡检机器人,实现了自动检测矿下工作人员的实时工作状况;文献[3]对SSD算法主干网络做出改进后直接运用于扫雪机器人的障碍物检测,在试验环境中取得了较好的效果.本文研究当前目标检测领域的YOLO系列算法,基于YOLO v4算法分析其结构并实现对室内外常见障碍物的检测.
1 YOLO v4算法
1.1 YOLO v4网络结构简介
YOLO v4算法属于单阶段目标检测算法,主要包括输入、主干网络、颈部和预测四个部分.YOLO v4算法最基础的模块为CBM模块和CBL模块,其中CBM模块由卷积(Conv)、批量归一化(BN)和Mish激活函数组成,与之类似的CBL模块仅将Mish激活函数替换为Leaky Relu激活函数.在YOLO v3算法[4]的基础上,将YOLO v4算法这四部分融入多种先进的算法,主要包括:1) 数据输入采用mosaic增强,此方法借鉴于CutMix[5],输入图像由4张图片经过随机缩放、裁剪等处理后拼接而成(2×2),这丰富了图片背景,也间接地增加了batch_size大小;2) 主干网络CSPDarknet借鉴了CSPNet[6]中的CSP结构,在不影响准确率的前提下,减少了网络参数和计算量,且将激活函数换成Mish函数,与Leaky Relu函数相比,Mish函数拥有更平滑的梯度,使深入神经网络的信息更准确;3) 颈部将SPP结构和FPN+PANet结构相结合,其中SPP使用4种不同尺度大小的最大池化核(k={1×1、5×5、9×9、13×13})将图像中的特征融合,主干网络感受得到增强,上下文特征也能够显著分离,FPN自顶向下通过上采样与低层的特征融合,增强了语义信息,而PANet[7]自下而上,加强定位信息,弥补了FPN在传递过程中缺失定位信息的缺点,通过两者相结合的方式,加强了网络的特征提取能力;4) 将Loss函数中边框回归部分改为CIOU函数[8],综合考虑交并比、中心点距离和长宽比,提高了模型的预测精度.
1.2 YOLO v4模型压缩
YOLO v4算法需要部署在嵌入式开发板上,与PC端强大的GPU运算能力相比,嵌入式开发板的运算能力有限,需要对原网络模型进行压缩以减少计算量,提高推理速度.本文使用通道剪枝法对模型进行剪枝(通道剪枝的原理如图1所示),在原始网络模型参数中保留权重较大的卷积层,剪掉权重影响不大的通道和层.这样不仅能减小大量冗余参数所占用的存储空间,而且对模型精度影响也较小.该方法对硬件需求较低,容易部署在小型移动设备上.

图1 通道剪枝原理示意图
对每一个通道引入一个缩放因子γ与输出通道相乘,然后联合训练缩放因子与网络权重,将缩放因子大的通道保留,缩放因子小的剪除,修剪后的模型通道变少.
通道剪枝法具体步骤为:1) 训练过程中,对BN层的γ添加L1正则化,使模型向结构稀疏方向调整;2) 稀疏训练完成后,将模型按设定的剪枝率进行剪枝,降低模型大小;3) 剪枝完成后,对模型进行微调以恢复到剪枝前的精度.
通道剪枝的损失函数为:

(1)
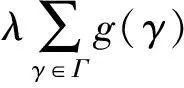
2 目标定位
2.1 相机坐标系转换
相机检测到障碍物目标后,需要计算出目标相对于相机的三维位置,对目标进行定位,为机器人的下一步运动规划提供信息.在单孔相机成像模型中,可由图像坐标系中一点计算该点在相机坐标系下的三维坐标,单孔相机成像模型如图2所示.
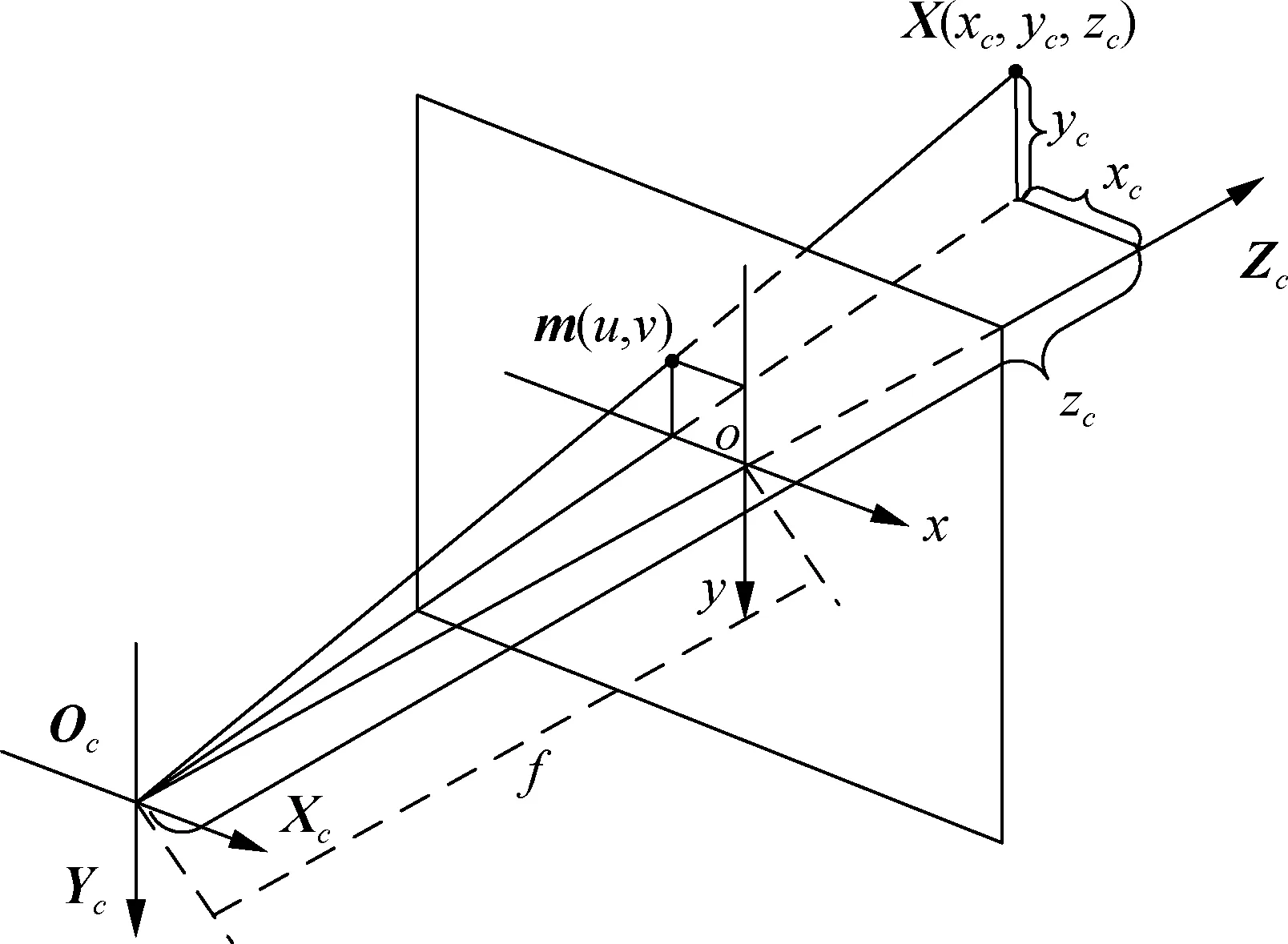
图2 单目相机成像模型
图2中,o-xy为图像坐标系,Oc-XcYcZc为相机坐标系,设三维空间中的一点X为齐次坐标,X=[xc,yc,zc,1]T,它在图像像素坐标系中的成像点m为齐次坐标,m=[u,v,1]T.
以相机坐标系为参考坐标系,通过坐标变换可得转换公式为[9]:
(2)
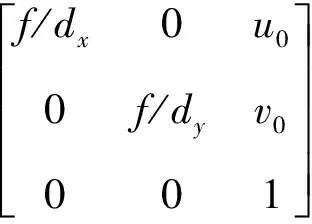
2.2 相机标定
为获得相机的内参矩阵K,需要对相机进行标定.使用张正友标定法[10],利用opencv视觉库对相机进行标定.具体流程为:打印出棋盘格标定板,将其贴在平面物体的表面,拍摄过程中不断移动棋盘标定板,并且始终保持标定板完全处于相机视野中,从不同方向拍摄25张标定棋盘格图像,部分标定图像如图3所示;对拍摄的每张图像提取图像中的角点,即黑白棋盘的交叉点;使用opencv视觉库函数对相机进行标定,得到相机标定结果(内参和畸变参数);最终使用重投影误差评价标定结果.

图3 部分相机标定图像
3 试验结果与分析
3.1 训练过程及结果
本文以室内外常见障碍物为检测对象(如行人、车、桌椅等),在开源VOC数据集的基础上再添加相机采集的2 000张图像以扩充数据集.试验采用pytorch深度学习框架,服务器软件配置为Ubuntu18.04操作系统,硬件GPU为Nvidia RTX3090显卡.训练过程为:
1) 进行模型的基础训练,整个训练过程共进行100次迭代,初始学习率设置为10-4,batch_size大小设置为32,输入图像大小为640×640,训练的损失函数收敛曲线如图4所示,由图4可见,随着迭代次数的增加,YOLO v4深度学习网络模型损失函数值逐渐降低,并趋于平缓,说明模型已收敛;
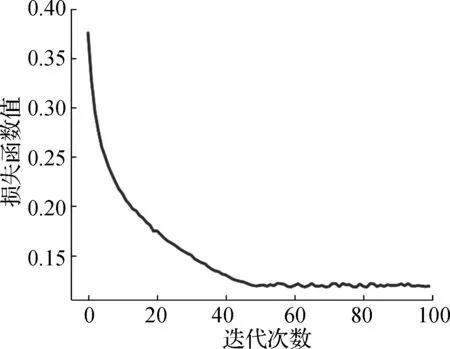
图4 损失函数收敛曲线
2) 进行稀疏化训练,稀疏率设置为0.001,迭代次数为400次,学习率为4×10-4,BN层γ系数稀疏训练情况如图5所示,由图5可见,随着迭代次数的增加,γ被压缩趋于0,仅有部分γ未衰减到0,说明γ系数变得稀疏,迭代至300次左右,γ趋于稳定,说明稀疏训练也趋于稳定;

图5 稀疏训练BN层γ系数变化情况
3) 将稀疏训练后的模型进行剪枝,剪枝率设为0.8,原模型有161层、32 256个通道和63 943 071个参数,权重大小为244 MB,剪枝后参数下降为8 312 599个,压缩了87%,通道数下降为12 515个,压缩了61.2%,模型大小为28.1 MB,压缩了88.5%;
4) 对剪枝完的模型进行微调训练,恢复精度.
为验证压缩后模型的准确性与鲁棒性,选取VOC数据集与添加的数据集中未参与训练的200张图像进行测试验证,压缩前后两者的性能参数如表1所示.由表1可见,压缩前后模型平均精度均值仅下降了0.3%,而帧率提升了1.5倍.

表1 压缩前后模型指标
3.2 目标定位试验
为验证定位算法的精确度,搭建如图6所示的实验平台,并在ROS平台上搭建对应的统一机器人描述格式(unified robot description format,URDF)模型.
为方便计算目标定位的误差,将待定位点在相机坐标系下的位置转换到一个固定坐标系下,两者间的转换关系已知(由旋转矩阵R与平移向量T构成).在计算出目标点在相机坐标系下坐标后,可将目标点转换到固定坐标系下:
(3)

图6 目标定位实验平台
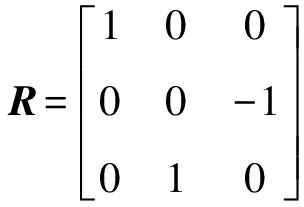
标定板长与世界坐标系X轴重合,宽距离世界坐标系Z轴正方向0.040 m,标定板每个正方形边长为0.025 m,在标定板上选取4个待定位坐标点,4个坐标点在固定坐标系下坐标分别为:左下(0.090,0.707,0.050),左上(0.090,0.707,0.150),右上(0.215,0.707,0.150),右下(0.215,0.707,0.050).相机在固定坐标系x轴方向移动,在不同位置计算4个待定位坐标点在固定坐标系下的位置,共选取5个位置计算目标定位结果,其结果如表2所示.
由表2得出,目标定位算法的定位精度在x、y、z轴方向的最大误差分别为0.004、0.004、0.005,定位算法的定位平均误差在各方向的绝对值都在0.005 m内,定位精度较高,能完全满足移动机器人避障需求.
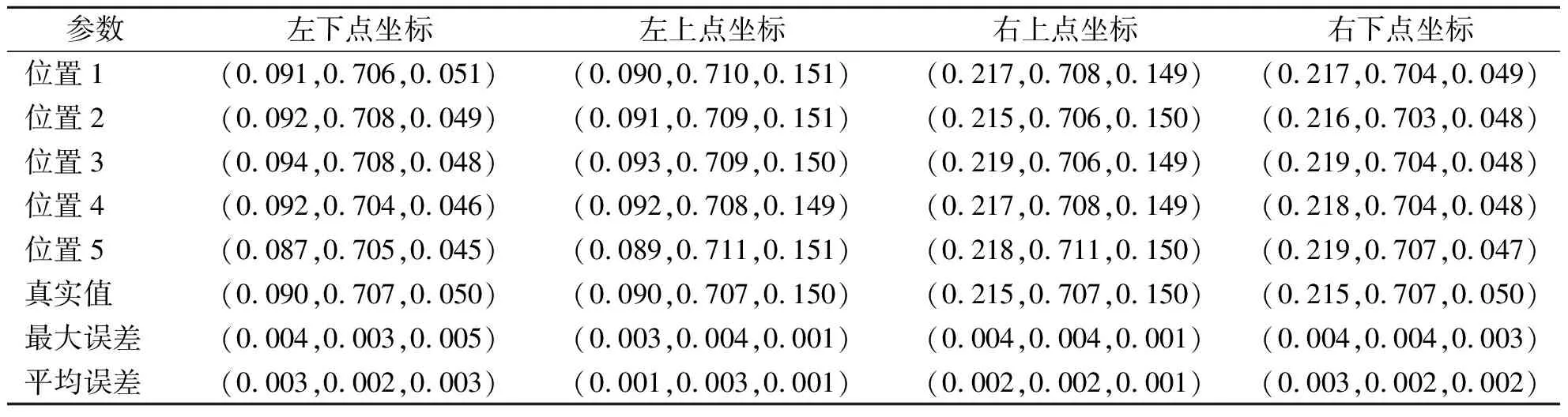
表2 目标定位测试结果
4 结语
本文将深度学习目标检测技术运用于移动机器人,在移动机器人上安装一台相机,基于通道剪枝的YOLO v4网络先检测出前方障碍物,然后通过定位算法计算出障碍物所在位置信息,机器人根据位置信息进行下一步动作.本文的目标定位算法定位精度较高,稳定性较好,增强了机器人的环境感知能力,丰富了移动机器人的应用场景.后期将进一步优化算法运行速度.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
汽车维修与保养(2020年11期)2020-06-09
计算机应用(2020年5期)2020-06-07
制造技术与机床(2017年3期)2017-06-23
中国惯性技术学报(2017年1期)2017-06-09
天津诗人(2017年2期)2017-03-16
西安建筑科技大学学报(自然科学版)(2014年6期)2014-11-10
燕山大学学报(2014年3期)2014-03-11
