
无监督编解码模型的多聚焦图像融合算法
2022-08-16 03:11臧永盛周冬明王长城夏伟代
计算机工程与设计 2022年8期
臧永盛,周冬明,王长城,夏伟代
(云南大学 信息学院,云南 昆明 650504)
0 引 言
由于大多数数码成像系统的景深有限,往往只有在景深范围内的目标是聚焦清晰的,而范围以外的目标则容易失焦变得模糊,因此很难使所有目标都聚焦在一幅图像中。多聚焦图像融合技术其本质就是将同一场景具有不同聚焦区域的多幅源图像整合成一个所有区域都聚焦的融合图像。近年来,多聚焦融合技术已经被广泛应用在很多领域当中,例如医学成像、数码成像和视频监控等应用领域[1]。目前,针对多聚焦融合问题,大量的融合算法相继被提出,这些融合方法主要可以归纳成3类:基于变换域、基于空间域和基于深度学习。
基于变换域的方法主要由变换、融合和逆变换这3个步骤组成。首先通过多尺度变换或稀疏特征矩阵分解等方法将源图像分解成不同频带的系数,然后根据相应的融合策略将分解系数进行融合,最终将这些融合后的系数进行逆变换得到融合图像。基于不同的分解算法,变换域的代表方法主要有:交叉双边滤波(CBF)[2]、离散小波变换(DWT)[3]和非下采样轮廓变换(NSCT)[4]等。与变换域方法不同的是,基于空间域的方法只包括两个步骤:聚焦检测和重构。该类方法大致又可以分为:基于像素、基于块和基于区域这3种融合算法。基于像素的方法通过直接对单个像素值进行操作获得融合结果,但得到结果往往容易出现聚焦和失焦边界模糊以及像整体对比度下降等情况。目前,基于像素的代表方法主要有:引导滤波(GF)[5]、联合双边滤波(MISF)[6]以及密集SIFT(DSIFT)[7]等融合方法。基于块和区域的方法首先使用图像分割技术或固定大小的滑动窗口把源图像分割成块和区域,然后再利用图像梯度或空间频率等聚焦测量方法检测相应块或区域的清晰度,最终选择清晰的块或区域组合成融合结果。尽管基于空间域的融合方法易于实现,但这些方法很难得到完全准确的分割边界,因此最终的融合结果在分割边界周围往往会出现明显的伪影。
目前,卷积神经网络(CNN)因其拥有强大的特征提取能力,被广泛用于医学图像融合[8],红外与可见光图像融合和多曝光图像融合等多个视觉融合任务中。在多聚焦融合领域,刘宇等提出了基于监督训练的CNN融合算法[9]。他们将多聚焦图像融合任务视为一个二分类任务,为了模拟多聚焦图像,他们首先制作了大量的图片对,然后利用卷积神经网络来进行决策图的预测,最终根据得到的决策图获得融合图像。另一种基于监督学习的融合算法是P-CNN[10],它通过在公共数据集Cifar-10[11]添加12种不同形状的高斯滤波并制作聚焦、失焦和未知这3个不同等级的标签。但和CNN不同的是,P-CNN模型输出3种标签的概率,这些概率被应用在融合权重图中。除以上两种方法外,最近提出的通用融合算法IFCNN[12],它通过在RGB-D数据集[13](NYU-D2)上生成大量真实融合图像数据并以监督的方式直接进行融合。以上3种基于监督学习的融合算法虽然充分地利用了卷积神经神经网络强大的提取特征能力,取得了比传统方法更优秀的效果。但是它们都需要制作带有标签的大型数据集,由于标签制作的好坏直接影响生成的决策图的准确性,进一步影响到融合图像的质量,使得算法很难获得理想的融合图像。
因此,针对上述问题,本文提出了一种无监督学习的卷积神经网络算法,它由编解码网络和活动水平检测优化模块组成。首先,编解码网络被用来提取图像特征,训练过程中采用像素损失和结构相似性损失组成的函数作为损失函数,以无监督的方式在现有的数据上训练编解码网络。此外,为了进一步提升网络的性能,我们还在网络中引入了双重注意力机制。活动水平检测优化模块则是通过利用改进的拉普拉斯能量和(SML)[14]对编码部分输出的深层特征进行活动水平检测以生成准确的决策图。最后,根据最终的决策图实现图像融合。与传统方法相比,本文方法生成的融合结果能保有更多的源图像细节特征,在失焦与聚焦边界处也不会产生伪影。本文方法既充分的利用卷积神经网络强大的特征提取能力,又不需要制作新的数据集,与基于监督学习的方法相比更容易实现,节约更多的成本,融合结果毫不逊色甚至更甚一筹。
1 提出的方法
图1中显示了本文提出的多聚焦融合算法的整体结构。如图1所示,在训练阶段,本文使用编码模块和解码模块组成的网络来对源图像进行特征提取和重建,未进行融合操作。在测试阶段,训练好网络并固定参数后,本文丢弃解码模块,对编码模块获得的深层特征使用SML计算活动水平来获得粗略的决策图,然后对决策图进行一系列形态学操作得到更准确的决策图,最终根据优化后的策图获得融合的结果图。
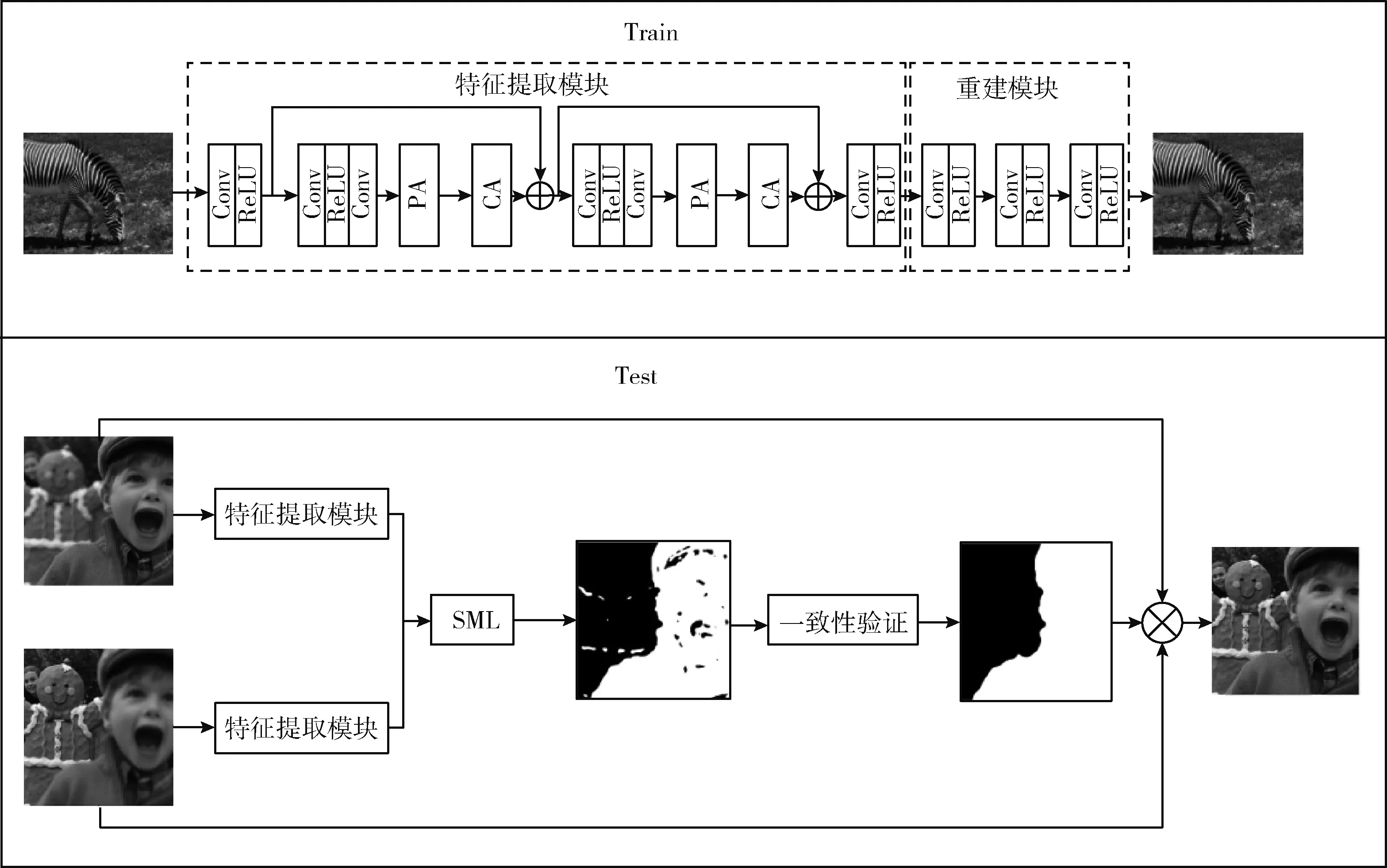
图1 提出的网络结构
1.1 特征提取模块
如图1所示,特征提取模块主要包含两个残差模块,残差模块由一个卷积层和双重注意力模块组成。首先,本文采用一个卷积层从输入图像中提取浅层特征,卷积通道数由1变成64。令Iin表示输入的源图像,浅层特征表示为
F0=Conv(Iin)=δ(Ww×Iin+B)
(1)
式中:Conv(.)表示卷积操作,B表示偏置项,δ表示激活函数ReLU,Ww表示卷积核权重。但是对于CNN来说,随机初始化的卷积核权重容易导致网络模型不稳定,而利用预训练好的模型参数迁移到本文中可以很好地解决此问题。因此,在本文中,采用Pytorch预训练的VGG19模型[15]的第一个卷积层(CONV1)作为本文网络中的第一个卷积,并在训练模型时固定了Conv1的参数。在VGG19模型中,Conv1包含64个大小为7×7的卷积核,其在最大的自然图像数据集(ImageNet)上训练。因此,Conv1能有效地提取图像特征。
此外,如图1中所示,残差模块主要由通道注意力模块、像素注意力模块和跳过连接组成。注意力模块通过对信道或空间特征自适应地进行重新校准,能有效地增强空间特征编码。跳过连接可以绕过低频信息,提高了信息流动能力,增强了网络的稳定性。残差模块表示为
Fn=Hn(Fn-1)
(2)
式中:Hn表示第n个残差模块的作用,Fn-1和Fn表示第n个模块的输入和输出。通道注意力和像素注意力模块可以差异性地对待不同通道特征和像素特征,自适应地重新校准通道和像素特征,通过级联这两个注意力模块,可以在处理不同类型的信息时提供额外的灵活性,扩展CNN的表示能力,提高网络鲁棒性。
通道注意力主要通过关注不同的通道的重要性,赋予不同的通道不同的加权信息来实现的。如图2所示,首先,使用全局平均池化得到全局通道信息
(3)
其中,Fn-1是输入特征,H,W分别表示图像的高和宽,Xc(i,j) 是第c个通道上在位置(i,j)的像素值。HP(·)为全局池化函数。通过全局池化,特征图的形状从C×H×W变为C×1×1。为了获得不同通道的权重,还需要经过两个卷积核大小为1×1的卷积层和ReLU激活函数,最后通过Sigmod函数获得范围在0-1的不同权重
CAc=α(Conv(δ(Conv(gc))))
(4)
其中,δ(·) 代表激活函数ReLU,α(·) 表示Sigmod函数。最后,输入特征与与加权过的通道权重逐像素相乘
Fc=CA⊗F
(5)
其中,CA为加权过的通道权重,Fc表示经过通道注意力的特征。
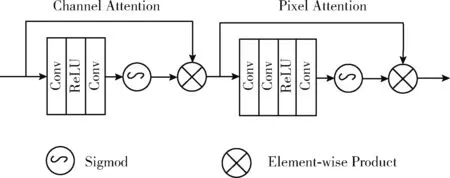
图2 双重注意力模块
此外,还考虑到多聚焦图像在不同位置上像素分布不均匀,提出了一种像素注意力模块,使网络关注不同位置的像素特征,例如,失焦区域和边界区域。和通道注意力不同的是,像素注意力没有使用全局池化函数,而是直接通过两个卷积核大小为1×1的卷阶层和激活函数ReLU,经过上述操作后,特征图的大小从C×H×W变换到1×H×W,然后在通过Sigmod得到不同像素的权重。最后把加权过的像素权重和输入特征进行逐像素相乘
PA=α(Conv(δ(Conv(F*))))
(6)
FPA=F⊗PA
(7)
1.2 损失函数
为了准确重建原始图像,本文使用损失函数L来训练我们的网络
L=λLSSIM+LP
(8)
L由像素损失和结构性损失组合而成,λ是一个常数,用于平衡两个损失的重要性,在本次实验中设置为10。像素损失用于描述输入图像和输出图像之间的距离,表示如下
(9)
其中,I表示输入的图像,O表示输出的图像。结构性损失用来描述输入图像和输入图像之间的结构差异,表示如下
LSSIM=1-SSIM(O,I)
(10)
(11)
其中,σO和σI分别表示输出图像O和输入图像I的标准差,σO,I表示输出图像O和输入图像I之间的协方差。而μO和μI则分别表示输出图像O和输入图像I的均值。C1,C2,C3是3个常数以防止LSSIM在训练过程中分母出现为0的情况。
1.3 活动水平检测优化模块
本文使用SML对特征梯度进行测量以获得活动水平,而不是测量传统的特征强度来获得活动水平。特征提取模块为源图像中的每个像素提供了高维深度特征。但是,传统的SML和是针对单通道的灰度图像设计的。因此本文针对高维深度特征设计了SML计算方法。设Fe为特征提取模块获得的高维深度特征。Fe(x,y)是一个特征向量,(x,y)是这个向量在图像中的坐标,通过以下公式计算SML
(12)
Fe(x,y)=|2Fe(x+a,y+b)-Fe(x+a-1,y+b)-Fe(x+a+1,y+b)|+ |2Fe(x+a,y+b)-Fe(x+a,y+b-1)-Fe(x+a,y+b-1)|
(13)
其中,r是核半径,a和b分别表示核半径范围内每个坐标的取值区间,与传统的SML不同的是,传统是基于块计算的,本文中的是基于像素计算的,在处理特征图边界处时使用和传统一样的填充方法。接下来比较两幅原图像的高维深度特征的SML,获得粗略的决策图
(14)
得到的初始决策图虽然可以比较好地识别出聚焦区域的位置,但是决策图中不可避免地存在着决策误差。这是由于波动或成像系统生成图像过程中存在的噪声所引发的。在成像过程中,可能会出现高斯噪声或椒盐噪声,这将严重影响改进拉普拉斯能量和的计算。因此,需要一些形态学操作来消除决策图中不正确的聚焦像素。因此,实验中采用一致性验证方法对初始决策图进行校正。首先使用形态滤波运算处理,其表示为RS(.)。通过利用带有圆盘结构元素的形态学运算符进行开闭运算来去除伪影。开运算可以用平滑边界,闭运算可以用来排除小型黑色区域
RD(x,y)=RS(D(x,y))
(15)
初步优化后的决策图RD(x,y)还需要使用小区域删除策略对决策图中的小块区域进行进一步的优化。SF(·) 表示小区域删除操作,其原理是把小块区域面积和设定的阈值S进行比较,如果小块区域面积小于阈值S则判定该区域需要被删除。其中阈值计算设置遵循S=0.1×H×W,H,W是原图像的长和宽
SD(x,y)=SF(RD(x,y),S)
(16)
在获得精确的决策图之后,本文选择加权融合规则得到最后的融合结果,融合结果表示如下
Fu(x,y)=SD(x,y)Img1(x,y)+(1-SD(x,y))Img2(x,y)
(17)
其中,Img1,Img2表示需要进行融合的2张源图像,SD(x,y)表示经过形态学操作处理过的最终决策图。
2 实验结果
2.1 实验设置
为了充分的训练网络提取特征的能力,实验中所采用的数据集是MS-COCO2017[16],该数据集包含82 783张训练图像,40 504张验证图像。实验中采用ADAM optimizer[17]作为优化器,其中设置β1=0.9,β2=0.999和ε=10-8。初始学习率设置为lr=0.0001,然后2个周期减少0.8。批大小设置为8,并训练30个周期。在图像预处理方面,首先对输入的图片进行灰度化,然后调整大小为256×256。根据实验需求,我们采用深度学习框架Pytorch1.5实现网络模型,使用Cuda10.0对网络模型进行加速,该网络的训练和测试是在使用一个NVIDIA 2070Super GPU,总共16 GB内存的系统上进行的。
2.2 实验结果分析
为了验证本文提出方法的有效性,本实验选择Lytro[18]彩色多聚焦图像数据集作为测试集,把本文算法和其它12种最近提出的先进算法,如SR[19]、DSIFT[6]、CNN[8]和DEEP_FUSE[20]等12种算法,从主观和客观两方面进来了比较验证。首先,从主观视觉方面定性比较本文算法和其余算法之间的性能差异。多聚焦融合结果应该尽可能包含所有源图像的清晰细节特征。为此,本文同时可视化了各种算法的融合结果与对应伪彩图像,以便可以更好观察到它们主观视觉差异。
图3展示了测试集中“潜水员”源图像和各种算法的融合结果图,此外,为了更方便观察对比,将融合结果的局部进行放大并置于左下角。和图3(a)源图像比起来,图3(c)中潜水器的轮廓没有源图像清晰。图3(d)中镜框下方在聚焦和失焦边界存在小块模糊,图3(e)、图3(i)和图3(k)中潜水器和海水区域边界存在着伪影。图3(h)中整个图像颜色和亮度都发生了改变。图3(g)和图3(n)整个图像和源图像比起来都呈现出模糊。在图3(o)中既没有出现模糊,也没有在边界处出现伪影,充分融合了源图像中的各种细节特征。
此外,为了更好地观察融合过程中的细节,实验通过使用图3的每个融合结果减去源图像A产生的伪彩图,在伪彩图中,聚焦和失焦有清晰的边界,且减去的部分没有轮廓,在这里减去的部分就是人脸部分,说明融合效果越好,反之,若边界周围存在噪声像素,则说明融合效果越差。在图4中,可以观察到,只有DSIFT、CNN、MWG和本文方法,人脸部分被减去,呈现出干净的画面,表明这4种方法在融合过程中充分利用了源图像信息,没有引入其它的噪声,而其余的9种方法,在人脸部分就存在明显的噪声像素,则表示融合效果不佳。此外,对边界位置进行局部放大,本文方法和DSIFT、CNN、MWG相比,本文方法在聚焦和失焦区域保存着完整且清晰的边界轮廓,其余3种方法中,边界周围存在着很多噪声像素,这些噪声像素会很大程度影响融合图像的质量,说明本文方法在边界部分细节融合得更好。
图5是测试集中“女孩”的源图像和各种算法的融合结果图,图5(c)、图5(d)和图5(e)在建筑和女孩衣服的边界处,没有清晰的界限,出现小块模糊,甚者在图5(e)中有部分建筑覆盖在女孩的衣服。图5(j)和图4(i)背景部分整体不够清晰,图5(i)和图5(k)在女孩周围存在一层伪影,这些区域都出现了对源图像细节信息的严重丢失。图5(h)整体图像出现失真,光度偏亮的效果,对源图像细节的丢失更加严重。图5(o)不但没有出现伪影,颜色亮度都保持和源图像一致,成功融合了源图像的所有细节。同样地,根据图5产生了对应算法的伪彩图。如图6所示,从图中可以看出,在所有的融合算法中,只有CNN、DSIFT和本文的算法,小女孩部分被干净地减去,在聚焦和失焦区域有明显的分割边界,其余算法的分割边界都是模糊不清或者存在大量噪声像素,而CNN和DSIFT算法的分割边界周围也有部分噪声像素,只有本文的算法有干净的分割边界。

图3 “潜水员”图像融合结果
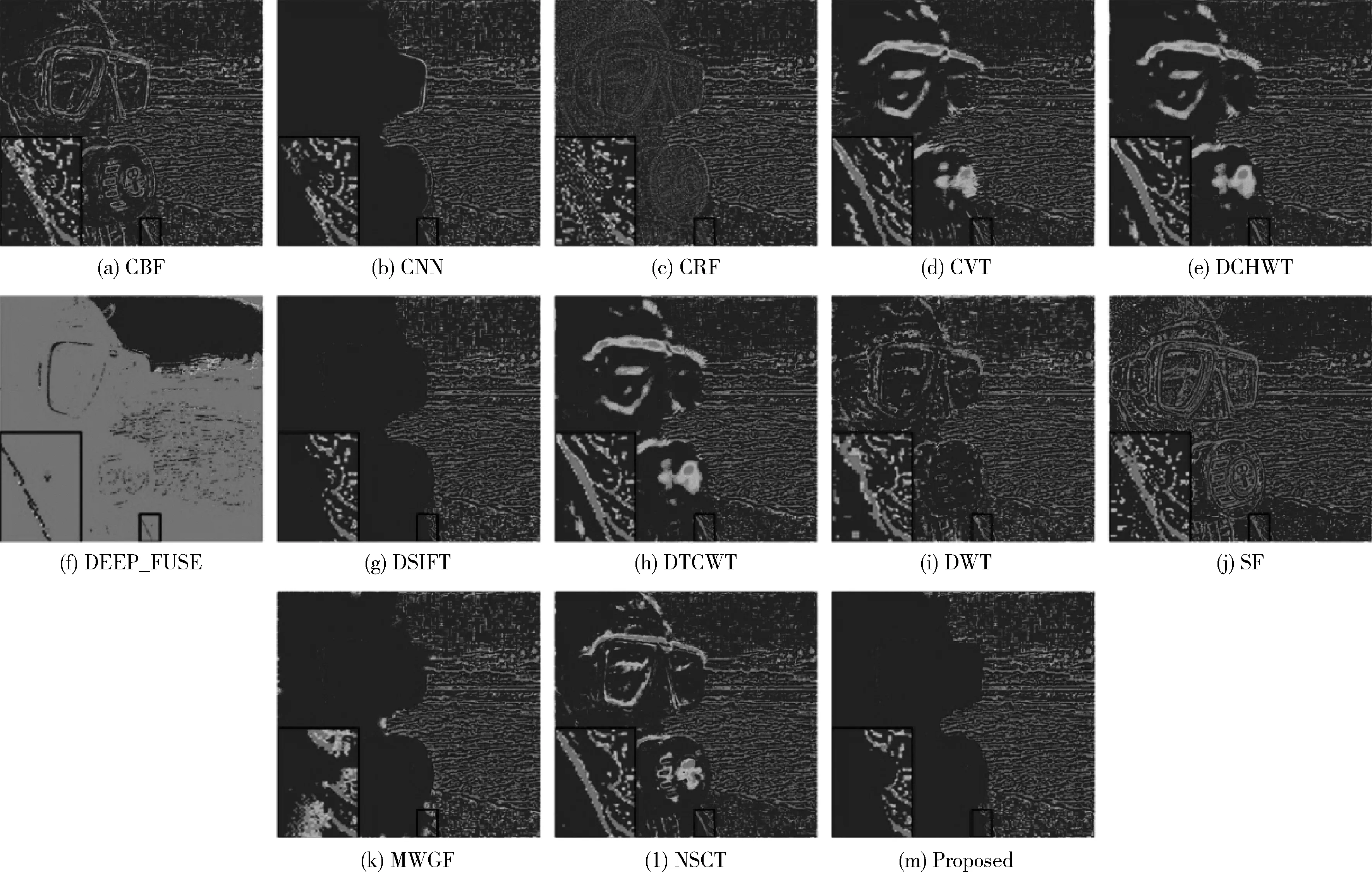
图4 “潜水员”图像各融合结果的伪彩

图5 “女孩”图像融合结果

图6 “女孩”图像融合结果的伪彩图
图7可视化了测试集中“猴子”图像的各种算法融合结果。在图7中,通过对猴子的帽子边缘部分进行局部4倍放大,可以看出源图像A中帽子部分是清晰的,而后面建筑物是模糊的,源图像B中帽子是模糊的,后面的建筑物是清晰的。图7(c)虽然帽子部分是清晰的,但是建筑物部分是模糊的,没有较好融合源图像B中的信息。图7(d)、图7(l)、图7(n)和图7(k)中帽子和建筑物都呈现出模糊的状态,更糟糕的是图7(k)中在帽子部分还有噪声像素,这些融合算法都没有很好融合两幅源图像中的信息。图7(g)和图7(m)帽子是模糊的,建筑物是清晰的,这两种算法没有更多融合源图像A中的信息。只有图7(i)和图7(o)帽子和建筑物都是清晰的,但是图7 (i)中帽子下边缘存在伪影,因此只有图7(o)充分的融合了源图像A和源图像B中的清晰部分的信息。相应地,图8可视化了图7对应的伪彩图。从伪彩图中可以看出,图8(b)、图8(g)和图8(n)在清晰和模糊部分形成了明显的边界,对帽子和建筑物接触位置进行局部4倍放大,根据局部放大图可以看出,只有图8(n)中的帽子还保持完成轮廓,其余两种算法要么在帽子轮廓周围存在噪声像素要么已经丢失了帽子的基本轮廓。

图7 “猴子”图像融合结果

图8 “猴子”图像融合结果的伪彩图
为了更全面评价不同算法的融合结果,除了以上的客观评价,还需要对融合结果进行客观指标的分析。近年来,针对融合图像质量的评价指标,主要包括4个方面评价指标:①基于信息论的指标;②基于图像特征的指标;③基于图像结构相似性的指标;④基于感知的指标。本文采用了覆盖以上4个方面的非线性相关信息熵(Qnice)、平均梯度(AVG)、标准差(STD)和Tsallis熵(Qte)等7个客观指标对最近提出的14种算法生成的融合图像客观评价。这7个指标可以客观地反映各种融合结果在视觉方面,结构方面以及细节方面的能力。对于这7个客观指标,值越高,代表融合的图像质量越好。
不同算法在Lytro测试集上20组图像的客观指标平均值见表1,每一项指标中加粗值表示最好的指标,加下划线值表示第二好的指标。从表1中可以看出,7项指标中,本文算法有6项指标是最高的,在只有平均梯度指标排在第二。特别地,本文算法的VIFF值比SF算法提高了0.2593,AVG值也提高了3.1434,可以看出基于深层特征的聚焦检测比直接在灰度图片上进行聚焦检测拥有更大的优势。综合所有算法在主观和客观上的表现,本文算法融合效果更加显著,指标明显领先于其余14种算法。
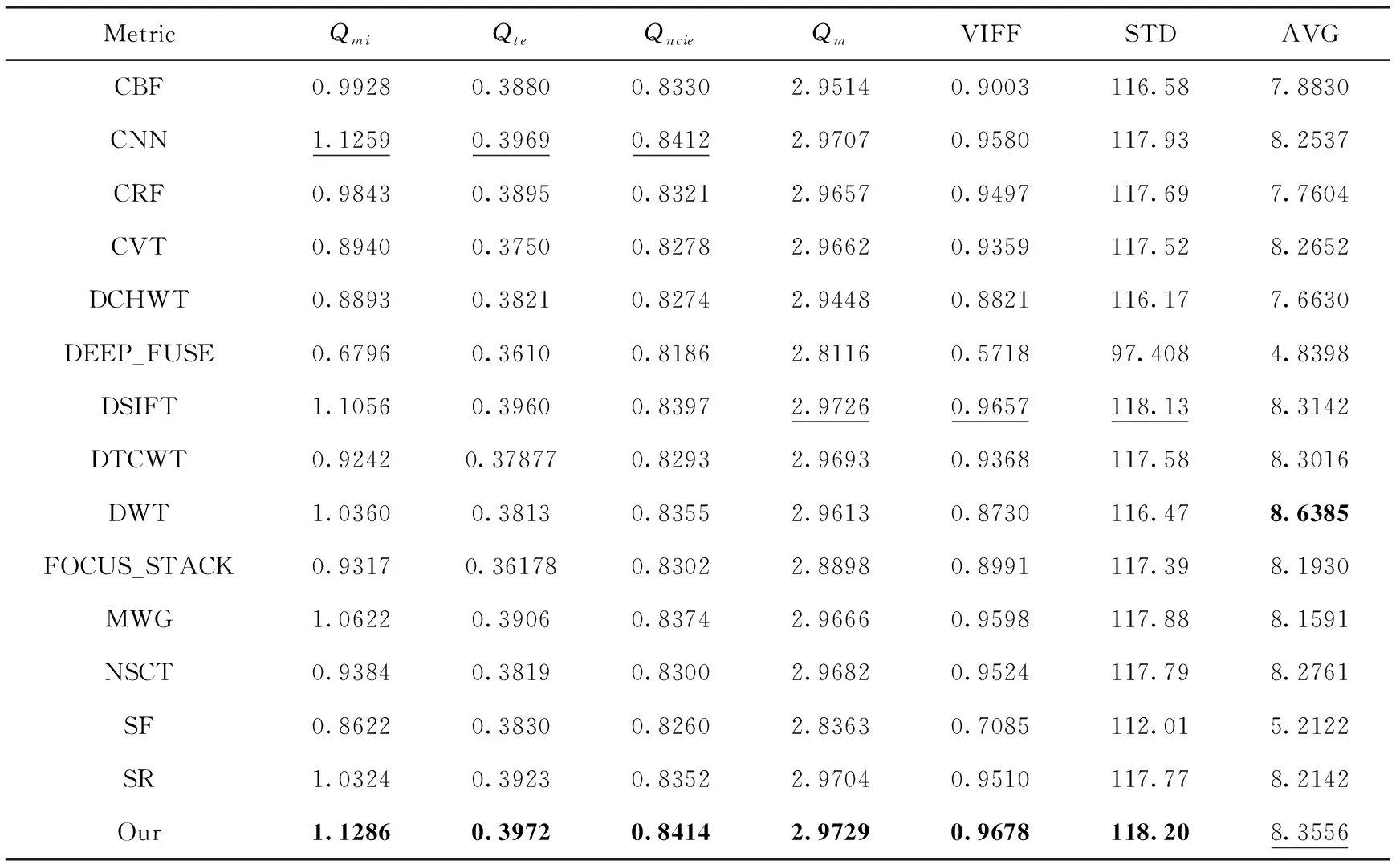
表1 Lytro数据集各方法评估指标
3 结束语
本文通过将编解码模型和改进的拉普拉斯能量和相结合,实现了一种有效且新颖的多聚焦图像融合算法,并取得不错的融合效果。算法首先将注意力机制引入到编解码模型之中增加网络的鲁棒性和特征提取能力,网络通过无监督学习的方式进行训练。然后再利用传统方法中的改进的拉普拉斯能量和进行活动水平检测获得决策图,并根据决策图进行图像融合。实验结果表明,与目前的融合方法相比,提出的方法具有优越的融合性能。之后,会在本文方法基础上探索更有效更灵活的活动水平检测方法,以获得更好的融合框架实现更好的融合性能。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
