
基于环查询和通道注意力的点云分类与分割
2022-08-16 13:43刘玉珍陶志勇
图学学报 2022年4期
刘玉珍,李 楠,陶志勇
基于环查询和通道注意力的点云分类与分割
刘玉珍,李 楠,陶志勇
(辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125105)
点云数据的特征处理是机器人、自动驾驶等领域中三维物体识别技术的关键组成部分,针对点云局部特征信息重复提取、点云物体整体几何结构缺乏识别等问题,提出一种基于环查询和通道注意力的点云分类与分割网络。首先将单层环查询和特征通道注意力机制进行结合,减少局部信息冗余并加强局部特征;然后计算法线变化识别出物体边缘、拐角区域的高响应点,并将其法线特征加入全局特征表示中,加强物体整体几何结构的识别。在ModelNet40和ShapeNet Part数据集上与多种点云网络进行比较,实验结果表明,该网络不仅有较高的点云分类与分割精度,同时在训练时间和内存占用等方面也优于其他方法,此外对于不同输入点云数量具有较强鲁棒性。因此该网络是一种有效、可行的点云分类与分割网络。
点云数据;分类与分割;环查询;通道注意力;高响应点识别
3D传感器技术的快速发展,使得传感器采集的点云数据信息越来越丰富,并广泛应用于机器人[1]、自动驾驶[2]等领域。而点云分类与分割处理又是机器人、自动驾驶等领域中三维场景理解的关键步骤,因此对点云分类与分割进行研究具有非常重要的意义。
由于点云数据的无序性和不规则性,早期对于点云数据的处理是将其体素化到3D网格中,然后使用卷积神经网络(convolutional neural networks,CNN)提取特征。体素化方法会耗费大量计算,占用大量内存,为了减少代价,体积网格会采用较低分辨率,但低分辨率往往会丢失一些几何信息。为了解决这一问题,WANG等[3]提出了基于Octree的方法,动态调整分辨率的大小,从而减少内存占用。PointGrid[4]则是在每个网格单元采样恒定数量的点来提高低分辨率的识别效果。为了提高效率,PointNet[5]将深度学习直接应用于点云原始数据,但其只考虑单点特征,忽略了局部特征。PointNet++[6]对PointNet进行优化,通过多尺度特征提取来处理局部区域信息,但使用球查询邻近点时会造成信息冗余,浪费不必要资源,且无法获取点与点之间信息。为了提高精度,KLOKOV和LEMPITSKY[7]提出了一种新的深度学习网络kd-networks,该网络使用kd-tree结构在点云上构建计算图,但输入点云数量过于庞大,浪费大量资源。SO-Net[8]是一个置换不变网络,通过构建自组织映射来利用点云的空间分布,但其输入点数仍达5 000之多。SK-Net[9]将空间关键点推理和点云特征表示结合以提升精度,但网络模型对于不同点云数量的鲁棒性较差。增加点云数量可提升一定精度,但会多次重复提取相同信息,且对于网络的鲁棒性有较高要求。A-CNN[10]和GGM-Net[11]则通过定义新的卷积算子来提升精度,但A-CNN采用多层环结构也会造成特征信息重复提取,GGM-Net则对于部分分割的应用稍差。MHSANet[12]通过对点云数据进行预处理并结合多头自注意机制提取点云特征,虽然提升了一定的分类精度,但多头特征提取模块只针对分类任务,应用范围稍差。
为了减少资源的不必要浪费及局部相同特征信息的重复提取,加强对物体整体几何结构的识别,提高点云分类与分割精度,提出了基于环查询和通道注意力的点云分类与分割网络。
1 点云数据处理过程
基于环查询和通道注意力的点云网络对点云数据的处理过程如图1所示,左侧为提取局部特征并进一步加强局部特征,右侧为加强物体整体几何结构的识别,然后将加强后的局部特征和整体几何结构特征联合,通过最大池化、共享的全连接层后实现输出。其中最远点采样目的:一是减少点云数量;二是作为单层环查询(single-layer ring query,SRQ)的查询点。最远点采样和环查询用于减少信息冗余,减少内存等资源的耗费,注意力机制和高响应点识别(high response point recognition,HRPR)用于加强特征识别,提高输出精度。左侧局部特征提取并加强中圈处的位置是飞机发动机。
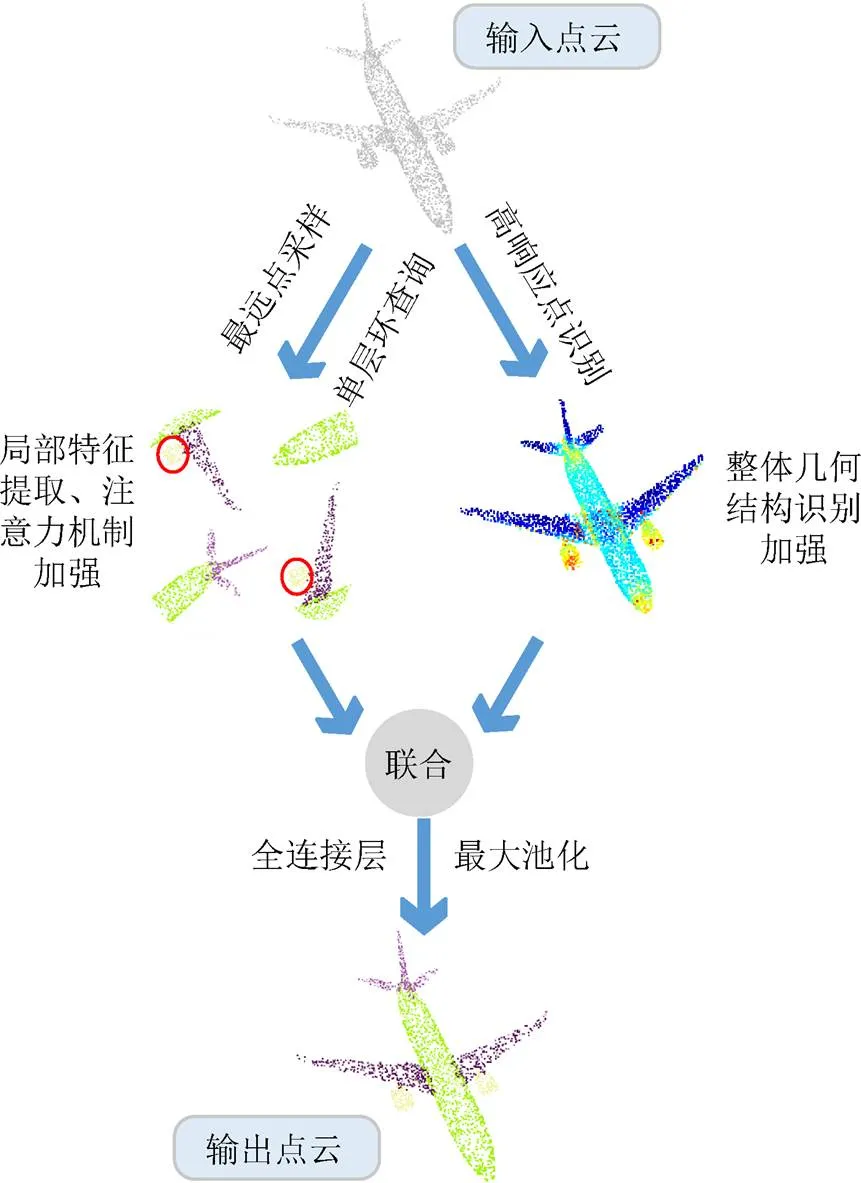
图1 点云数据处理
2 基本原理
2.1 网络模型
图2为基于环查询和通道注意力的点云分类与分割网络,主要包括3个核心模块:SRQ,通道注意力机制(channel attention mechanism,CAM)和HRPR。模型上半部分为分类网络,下半部分为分割网络,分类和分割网络共享相同的特征提取模块。为输入点云数量,1为经过最远点采样(farthest point sampling,FPS)后的点云数量。多层感知器(multilayer perceptron,MLP)中{ }内的数字代表神经元的数量,Max pooling为最大池化操作,Conv为卷积操作,FC表示共享的全连接层(fully connected layers),为分类类别数量,为分割类别数量。在分割网络中,每个模块除了获取局部特征外,还生成相应的语义标签,用于相应地分割任务。

图2 网络模型
2.2 单层环查询
为了提取3D形状的局部空间上下文特征信息,PointNet++[6]提出了多尺度体系结构,但使用球查询邻近点时会有重叠,如图3左侧所示,即所查找的邻近点可能包含在不同大小的局部区域内,导致信息冗余,降低体系结构性能。为此A-CNN[10]提出了多层环形卷积减少信息冗余,然而多层环结构却增加了训练时间、内存占用等资源的耗费,为了进一步减少资源耗费,本文使用K邻近算法(K-nearest neighbor,KNN)的SRQ查找邻近点,如图3右侧所示。图中q为FPS采样的查询点,1和2表示局部区域的不同感受视野,1和2表示不同感受野的半径大小,通过扩大半径增加感受视野的范围。
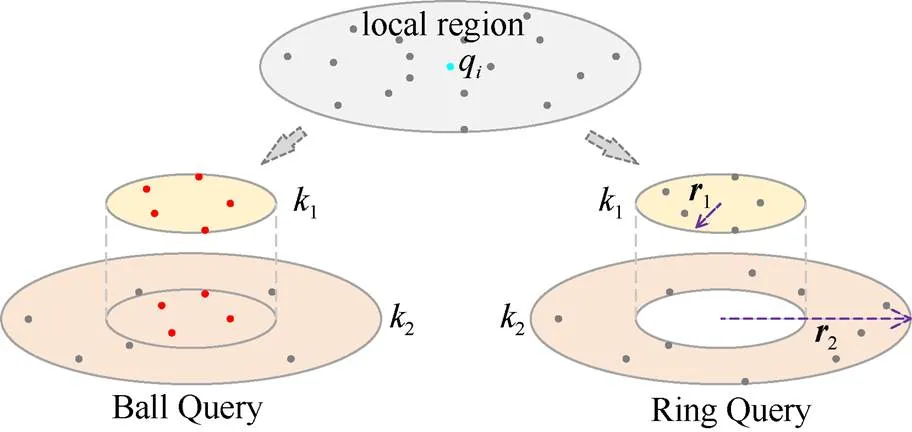
图3 局部邻近点查询比较
图4为具体的SRQ示意图,主要步骤包括投影和排序。首先,将KNN查询到的邻近点投影到查询点q所在的切平面上,投影的目的是为了更方便、有效地对邻近点进行排序。投影和排序操作需借助法线完成,通过计算q点处局部切平面的法线来逼近q点处的法线。然后计算这些邻近点在q点处切平面上的投影(以内环为例,外环中的点x的投影是对内环局部区域的扩大搜索)

其中,为q的邻近点个数;为q点的法向量。

图4 单层环查询
其次,对同一切平面上的邻近点按顺时针排序。因为是环形结构,所以排序方向对于卷积结果无影响。向量与向量-之间的夹角为

其中,向量为从点q开始,连接一个随机的起点1;|| ||为2范数,即求向量模的大小。未排序前,向量之间的夹角默认Î[0,p]。
由于排序后夹角的范围变成了[0,2p],为了区分[0,p]和(p,2p)范围内的点,即

其中,为q点的法向量。若sign≤0,则Î[0,p],若sign>0,则Î(p,2p)。
然后利用式(4)将的余弦值扩大到[-3,1],形成Î(0,2p)上余弦值的单调递减,即
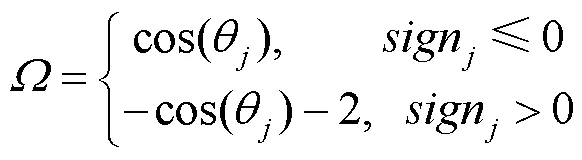
最后,通过对的值降序排序从而对邻近点y顺时针排序。
通过以上计算,内环邻近点已经被表示为有序数组[1,2,3,···,y],为了提取更深层特征,将起始点1和2连接到有序数组末尾形成循环数组[1,2,3,···,y,1,2],连接的起始点个数由内核大小和邻近点个数值共同决定。
2.3 改进通道注意力机制
SRQ减少了资源的耗费,但却在一定程度上降低了输出精度,为了进一步加强局部特征的识别力,提高分类与分割精度,将SRQ与CAM结合,将查询到的局部信息构造成邻近点局部结构图,如图5所示,通过自注意机制和邻域注意机制分别生成不同注意系数。相比通道注意力的多头机制[13],改进的单头通道注意力机制不仅提高了输出精度,同时还减少了资源的耗费。图中,q为FPS查询点,y为SRQ查找的邻近点,=q-y表示边特征。自注意机制通过考虑每个点的自身特征来学习自系数,而邻域注意机制则通过考虑邻域关系来关注局部系数。自系数和局部系数通过LeakyReLU激活函数进行联合,并通过指数函数Sotfmax归一化。
首先,对查询点q和边特征进行处理,即

其中,(·)为参数非线性函数;为参数,实验中选用神经网络。
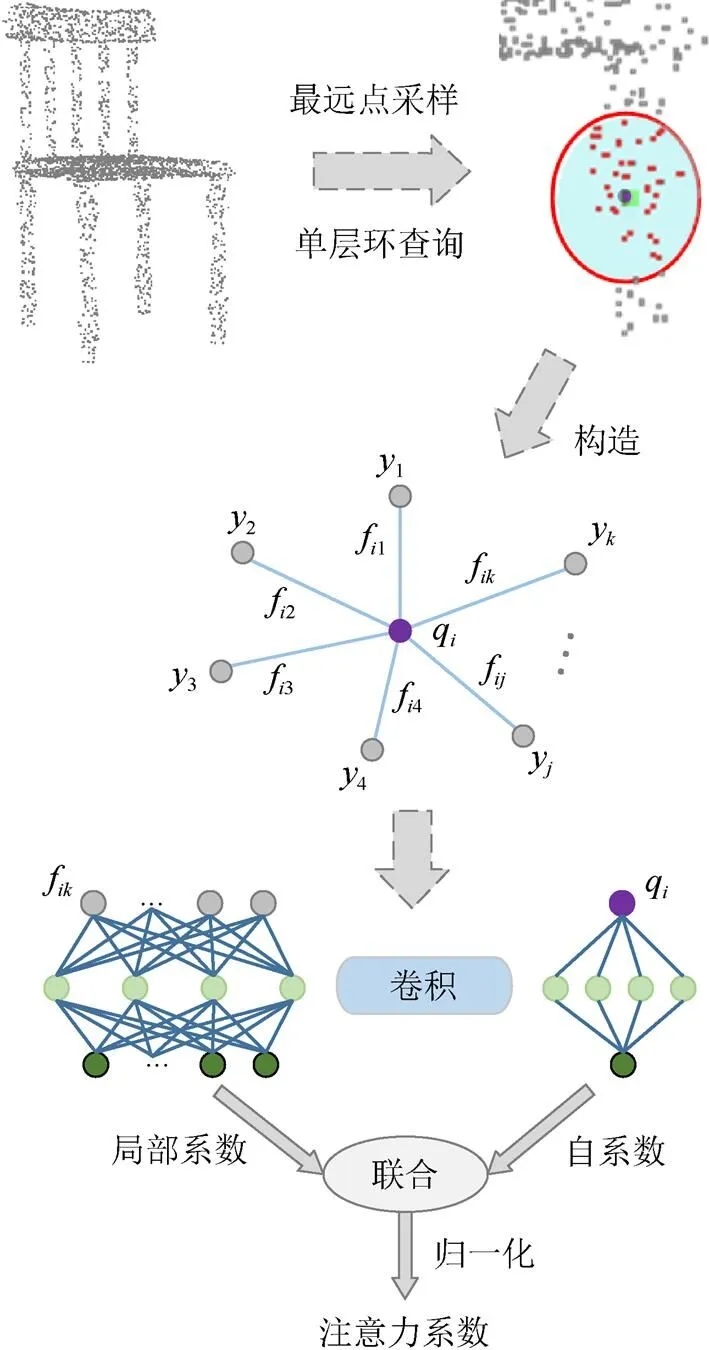
图5 注意力系数生成
注意力系数为
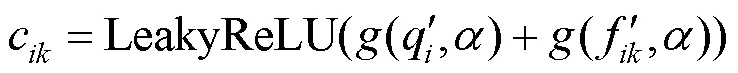
然后,使用归一化指数函数对其进行归一化

其中,为最远点采样个数;为邻近点个数。
最后,将归一化后的注意力系数分配给不同的特征通道用于对局部特征的加强。
2.4 加入高响应点识别
为了解决网络缺乏对点云物体整体几何结构识别的问题,本文加入了HRPR,将识别出的高响应点的法线特征与CAM加强后的局部特征相结合,加入全局特征表示中,进一步提高分类与分割精度。通过计算法线变化识别出物体边缘和拐角处的点,边缘和拐角处的点包含更丰富的几何信息,更能反映物体的整体几何形状。法线变化为每个点指定响应,即

其中,为q处的法线;为邻近点的法线;为响应点;()为邻近点。
因为高响应点位于物体边缘或拐角区域,其法向量变化比一般点变化要明显,因此可以通过HRPR来进一步加强对物体整体几何结构信息的处理。图6为不同物体的HRPR。
3 实验验证与分析
3.1 数据集和实验环境
点云分类实验采用的是普林斯顿大学提供的ModelNet40数据集,是一个大规模的三维CAD模型数据集,共40个类别,12 311个模型。其中将9 843个模型用于训练,2 468个用于测试。每个模型采样1 024个点作为实验初始数据点。
点云部分分割实验采用由16类16 881个点云模型组成的ShapeNet Part数据集,其对象被分割成未重叠的50个部分,且模型中的每个点均有一个特定的语义标签。将14 007个模型用于训练,2 874个用于测试。每个模型采样2 048个点作为实验初始数据点。
所有的实验均在基于Ubuntu操作系统和CUDA10.2的Tensorflow(TF)深度学习环境中进行,表1为训练期间的环境配置和模型参数。
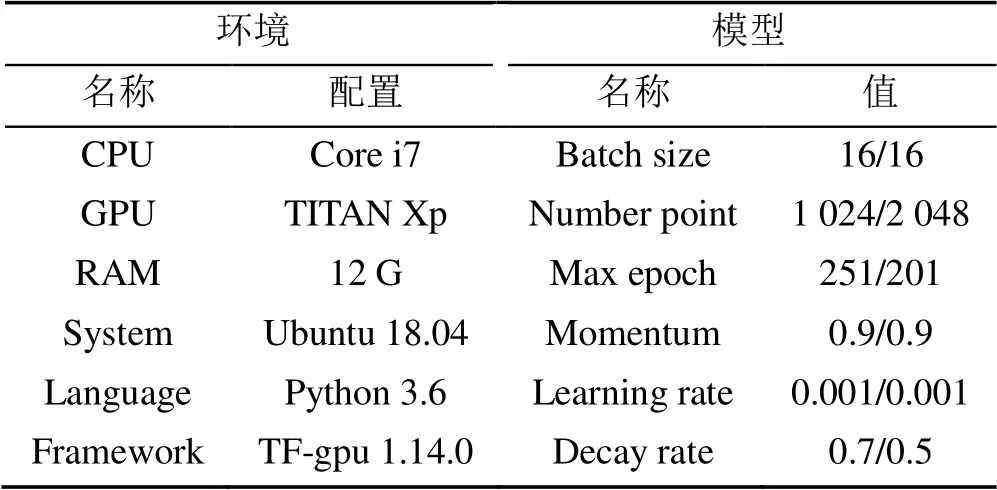
表1 实验配置
注:“值”分别为分类和分割参数值
3.2 分类实验
为了验证网络模型的分类性能,与其他先进的网络进行了对比实验(表2),其中平均分类准确率(mean class accuracy,mAcc)和总体准确率(overall accuracy,OA)为主要评估指标。选择输入同样为坐标和法线的几种网络PointNet++[6],A-CNN[10],PointConv[14],SpiderCNN[15],RGCNN[16],DeepRBFNet[17],同时还选择输入点云数量更多的KD-Net[7]和SO-Net[8],最后又对比了使用多头注意力机制的MHSANet[12],GAPNet[13]和使用关键点检测的SRINet[18]。由表2可以看出,本文网络比输入点数最多的KD-Net总体准确率高了1.1%,比效果较好的PointConv总体准确率高了0.4%,比效果较差的SRINet总体准确率高了5.9%,这得益于CAM对提取的局部特征进行了加强,同时高响应点的法线特征又加强了物体整体几何结构的识别。
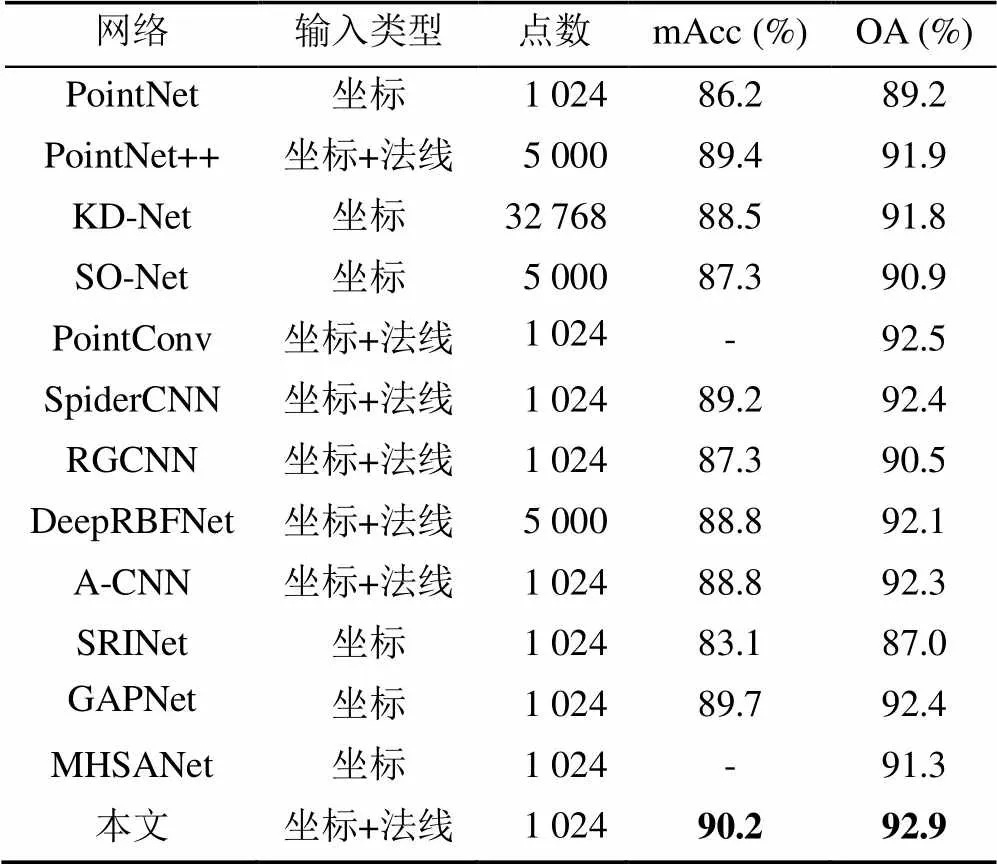
表2 分类测试结果
注:加粗数据为评估指标最优值
为了进一步直观显示网络的分类性能,从表2中选出代表性的几种网络:采用球查询和多尺度体系结构的PointNet++[6]、多层环形结构的A-CNN[10]、多头注意力机制的GAPNet[13]以及采用关键点响应的SRINet[18]与本文网络在ModelNet40数据集进行每个类别上的准确率比较,如图7所示,其中水平轴为40个不同类别,垂直轴为分类准确率。除了bench,bowl,flower_pot,plant和lamp等类别稍逊于其他网络,其他类别均有较好的分类准确率,并且模型有9类的识别率达到0.99 (99%)以上,领先于其他网络。
此外,在训练时间、内存占用和模型大小等方面也进行了对比实验,为了使实验更具说服力,统一设置batch_size大小为16,训练周期为251 epoch,学习率为0.001,momentum初始值为0.9,优化器为adam,衰减率为0.7,每组实验测试3次,取平均值,实验结果见表3。虽然SRINet模型只有10.2 MB是最小的,但准确率也是最低的,而本文网络在训练时间和内存占用均达到了最优,尤其是内存占用比PointNet++减少了78%左右,同时又保持了较高的准确率。这是因为最远点采样结合单层环查询减少了信息冗余,进而减少了内存占用,而CAM和高响应点识别又加强了特征识别,提高了准确率。
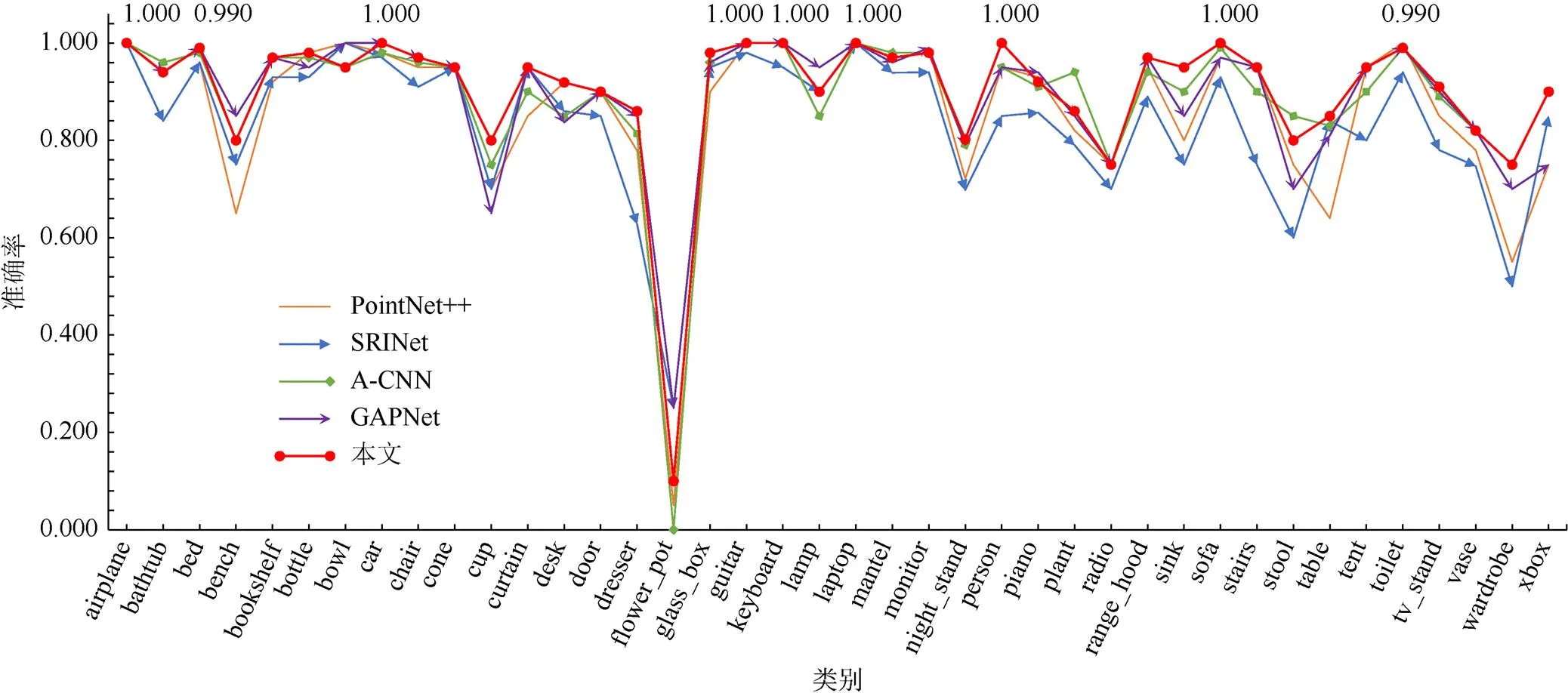
图7 ModelNet40各类别的准确率

表3 网络性能对比
注:加粗数据为最优值
3.3 部分分割实验
为了验证网络性能,在ShapeNet Part数据集上对网络进行分割测试,并与PointNet[5],PointNet++[6],KD-Net[7],SK-Net[9],SpiderCNN[15],SRINet[18],DGCNN[19],DCG-Net[20],FDGCNN[21]和LRC-Net[22]先进模型进行了对比实验,结果见表4,其中,联合平均交并比(mean intersection over union,mIoU)为主要评估指标,其值越大表明分割精度越高。由表4可知,本文分割精度比效果较差的SRINet高了12.5%,比效果较好的FDGCNN高了0.3%,比采用多尺度体系结构的PointNet++高了0.9%,且本文在8种类别的分割精度达到了最好。像ear phone,motor bike,rocket等分割精度值很低的类别,也达到了较优的分割精度,高于其他网络。此外,还对16个类别进行了可视化,如图8所示,其中Ground Truth为原始点云数据,本文进行可视化时,每个类别只采样2 048个点,远小于Ground Truth和PointNet可视化时采样全部点数,但依然可以准确地分割出物体各个部分的形状。如飞机类别,尽管只采样2 048个点,还是准确地分割出飞机的机身、机翼、尾翼、发动机等部位,而PointNet则未准确分割出发动机,并在尾翼上出现过度分割现象。再如表4中分割精度值较低的motor bike,rocket等类别,图8中依然可以准确地分割出物体的各个部分。
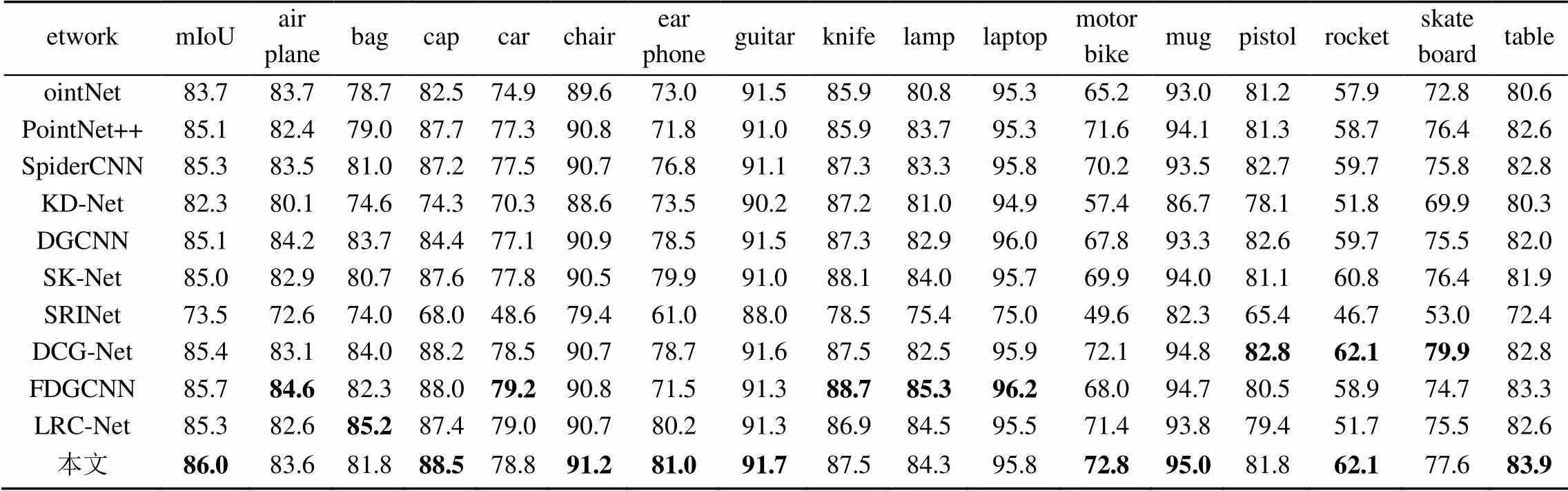
表4 部分分割测试结果(%)
注:加粗数据为最优值

图8 部分分割可视化
3.4 不同点数鲁棒性实验
由于实际场景中不同物体的规模大小、结构复杂度均有所不同,准确表示出物体所需要的点云数量也不相同,因此对于同样物体,要求网络模型对于不同的输入点数具有一定鲁棒性,防止因点云数量的变化导致输出精度大幅下降。为测试网络模型对于不同点云数量具有一定鲁棒性,改变输入点云数量,分类与分割分别选取输出精度峰值对应的点数及两端的点数,实验结果见表5,当增加或减少输入点数时,分类和分割精度均有小幅度下降,这表明网络对于不同输入点数具有一定鲁棒性。图9为分类网络的平均损失曲线,图10为相应的准确率曲线。平均损失越小,相应的准确率就越高,大约80个周期后,不同曲线趋于收敛,且与峰值点数对应的曲线拟合度较好,这也表明网络模型对于不同输入点数具有较好的鲁棒性。图11为不同输入点数的椅子分割可视化图,可以看出即使较少的256点也可以分割出椅背、坐垫、椅腿等部位。以上实验均表明本文网络模型可以有效提取点云特征信息,对点云数量具有一定鲁棒性。
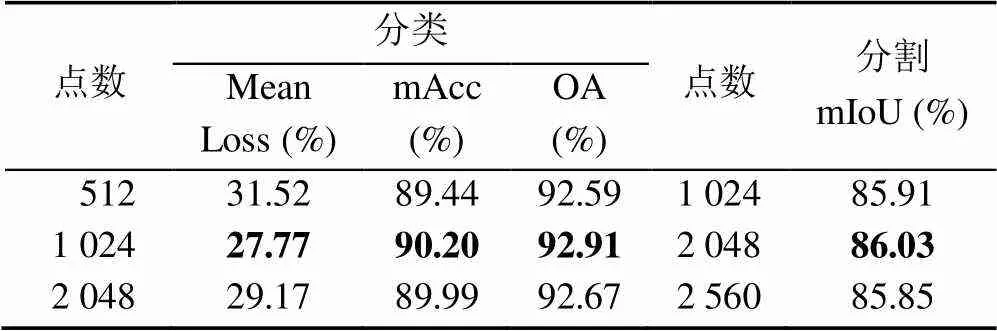
表5 不同输入点数结果
注:加粗数据为分类和分割最优输入点数的测试结果

图9 平均损失曲线
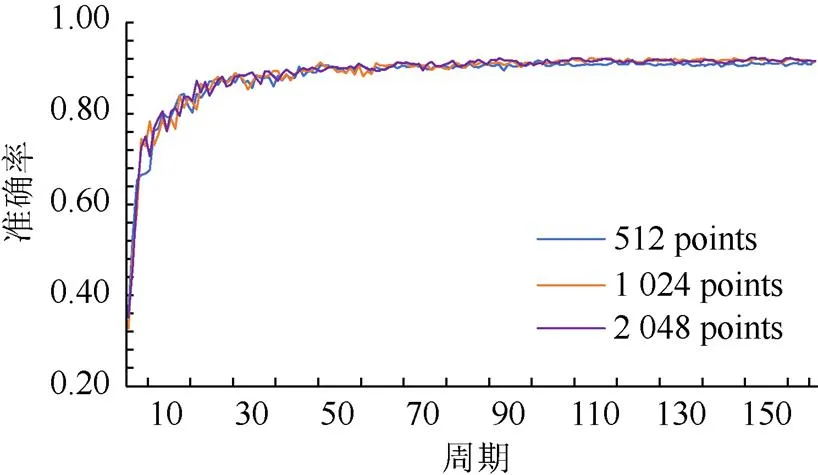
图10 准确率曲线

图11 不同点数的椅子可视化
3.5 消融实验
为了验证网络结构的有效性,将网络模型的3个核心模块采用不同组合方式进行分类与分割的消融实验。实验结果见表6,采用CAM和HRPR的组合方式效果最差,因为单纯采用注意力机制并不能在大量信息冗余时很好地提高局部特征识别力。采用SRQ,CAM和HRPR的组合方式效果最好,分类和分割精度均比其他组合高,主要原因在于FPS和SRQ减少了信息冗余、减少了特征重复提取,而CAM又在此基础上对局部特征进一步加强,然后又结合边缘、拐角区域高响应点的法线特征来加强物体整体几何结构的识别。实验结果验证了本文模型的有效性和可行性。

表6 不同模块组合的测试精度(%)
注:加粗数据为本文网络模型的实验结果精度
4 结 论
本文提出一种基于环查询和通道注意力的点云分类与分割网络,首先将最远点采样和环查询结合,减少特征信息的重复提取,在此基础上通过通道注意力机制对提取的局部特征进行加强,而后又与高响应点的法线特征结合,进一步加强对物体整体几何结构的描述。在ModelNet40和ShapeNet Part数据集上的分类与分割精度实验、训练时间和内存占用等实验均要优于一些先进的网络,提高精度的同时又减少了时间和内存等资源的耗费。此外,本文网络对不同输入点云数量还具有一定鲁棒性。
由于实际应用中的环境复杂多样,下一步将继续加强对局部特征和整体几何结构的描述,并对数据进行增强以满足网络对于更加复杂环境的挑战。同时进一步提高网络对于更少或更多点云数量的鲁棒性,让网络适应不同规模的场景。
[1] WANG Z T, XU Y T, HE Q, et al. Grasping pose estimation for SCARA robot based on deep learning of point cloud[J]. The International Journal of Advanced Manufacturing Technology, 2020, 108(4): 1217-1231.
[2] CHEN S H, LIU B A, FENG C, et al. 3D point cloud processing and learning for autonomous driving: impacting map creation, localization, and perception[J]. IEEE Signal Processing Magazine, 2021, 38(1): 68-86.
[3] WANG P S, LIU Y, GUO Y X, et al. O-CNN: octree-based convolutional neural networks for 3D shape analysis[J]. ACM Transactions on Graphics, 2017, 36(4): 72:1-72:11.
[4] LE T, DUAN Y. PointGrid: a deep network for 3D shape understanding[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9204-9214.
[5] CHARLES R Q, HAO S, MO K C, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 77-85.
[6] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[EB/OL]. [2021-08-20]. https://arxiv.org/abs/1706.02413.
[7] KLOKOV R, LEMPITSKY V. Escape from cells: deep kd-networks for the recognition of 3D point cloud models[C]// 2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 863-872.
[8] LI J X, CHEN B M, LEE G H. SO-net: self-organizing network for point cloud analysis[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9397-9406.
[9] WU W K, ZHANG Y, WANG D, et al. SK-net: deep learning on point cloud via end-to-end discovery of spatial keypoints[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4): 6422-6429.
[10] KOMARICHEV A, ZHONG Z C, HUA J. A-CNN: annularly convolutional neural networks on point clouds[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 7413-7422.
[11] LI D L, SHEN X, YU Y T, et al. GGM-net: graph geometric moments convolution neural network for point cloud shape classification[J]. IEEE Access, 2020, 8: 124989-124998.
[12] GAO X Y, WANG Y Z, ZHANG C X, et al. Multi-head self-attention for 3D point cloud classification[J]. IEEE Access, 2021, 9: 18137-18147.
[13] CHEN C, FRAGONARA L Z, TSOURDOS A. GAPNet: graph attention based point neural network for exploiting local feature of point cloud[EB/OL]. [2021-09-10]. https://arxiv.org/ abs/1905.08705.
[14] WU W X, QI Z A, LI F X. PointConv: deep convolutional networks on 3D point clouds[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 9613-9622.
[15] XU Y F, FAN T Q, XU M Y, et al. SpiderCNN: deep learning on point sets with parameterized convolutional filters[EB/OL]. [2021-12-03]. https://arxiv.org/abs/1803.11527.
[16] TE G S, HU W, ZHENG A M, et al. RGCNN: regularized graph CNN for point cloud segmentation[C]//MM’18: The 26th ACM International Conference on Multimedia. New York: ACM Press, 2018: 746-754.
[17] CHEN W K, HAN X G, LI G B, et al. Deep RBFNet: point cloud feature learning using radial basis functions[EB/OL]. [2021-09-17]. https://arxiv.org/abs/1812.04302.
[18] SUN X, LIAN Z H, XIAO J G. SRINet: learning strictly rotation-invariant representations for point cloud classification and segmentation[C]//The 27th ACM International Conference on Multimedia. New York: ACM Press,2019: 980-988.
[19] WANG Y, SUN Y B, LIU Z W, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): 146:1-146:12.
[20] BAZAZIAN D, NAHATA D. DCG-net: dynamic capsule graph convolutional network for point clouds[J]. IEEE Access, 2020, 8: 188056-188067.
[21] HONG J, KIM K, LEE H. Faster dynamic graph CNN: faster deep learning on 3D point cloud data[J]. IEEE Access, 2020, 8: 190529-190538.
[22] LIU X H, HAN Z Z, HONG F Z, et al. LRC-Net: learning discriminative features on point clouds by encoding local region contexts[J]. Computer Aided Geometric Design, 2020, 79: 101859.
Point cloud classification and segmentation based on ring query and channel attention
LIU Yu-zhen, LI Nan, TAO Zhi-yong
(School of Electronic and Information Engineering, Liaoning Technical University, Huludao Liaoning 125105, China)
Feature processing of point cloud data is a key component of 3D object recognition technology in robotics, autopilot, and other fields. In order to address the problems of repeated extractions of local feature information of point cloud and lack of recognition of the whole geometric structure of point cloud object, a point cloud classification and segmentation network based on ring query and channel attention was proposed. First the single-layer ring query was combined with the feature channel attention mechanism to reduce local information redundancy and strengthen local features. Then the high response points of the edges and corners of the object were identified by calculating the normal changes, and the normal features were added to the global feature representation, thereby strengthening the recognition of the whole geometric structure of the object. Compared with many point-cloud networks on ModelNet40 and ShapeNet Part datasets, the experimental results show that the network not only has higher accuracy for point cloud classification and segmentation, but also outperforms other methods in training time and memory consumption. In addition, the network is strongly robust for the number of different input point clouds. Therefore, the proposed network is an effective and feasible network for point cloud classification and segmentation.
point cloud data; classification and segmentation; ring query; channel attention; high response point recognition
6 December,2021;
National Key R&D Program of China (2018YFB1403303)
TP 391
10.11996/JG.j.2095-302X.2022040616
A
2095-302X(2022)04-0616-08
2021-12-06;
2022-03-06
6 March,2022
国家重点研发计划项目(2018YFB1403303)
刘玉珍(1964-),女,教授,硕士。主要研究方向为图像处理、现代通信理论与仿真、信号与信息处理等。E-mail:825807294@qq.com
LIU Yu-zhen (1964-), professor, master. Her main research interests cover image processing, modern communication theory and simulation, signal and information processing, etc. E-mail:825807294@qq.com
猜你喜欢
装备制造技术(2022年5期)2022-09-06
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
甘肃教育(2020年22期)2020-04-13
数学教学通讯·高中版(2018年11期)2018-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
大众文艺(2016年23期)2016-03-02
