
基于词表示模型的领域文献数据可视分析方法
2022-08-16 09:45张清慧武彩霞
图学学报 2022年4期
张清慧,陈 谊,武彩霞
基于词表示模型的领域文献数据可视分析方法
张清慧,陈 谊,武彩霞
(北京工商大学计算机学院食品安全大数据技术北京市重点实验室,北京 100048)
随着科学技术的发展,科研文献数量越来越大,如何从海量文献信息中找出特定领域的研究主题、有影响力的学者和高水平论文是一个巨大的挑战。为此提出一种基于词表示模型的领域文献数据可视分析方法,首先利用词嵌入模型word2vec向量化推荐领域相关的关键词,根据这些词向量之间的近似度筛选出领域相关的论文;然后应用BERTopic模型从领域论文摘要中提取主题;基于PageRank算法计算论文影响力,应用综合考虑作者署名顺序、发表论文数量和论文影响力的作者影响力评价方法Author-Rank计算作者的影响力;最后使用多视图协同和交互的可视化方法帮助研究人员从领域的主题词频、主题演变、文献影响力和引用关系、作者影响力等多个角度对特定领域进行快速理解和分析。将该方法应用于食品安全领域的文献数据分析,应用结果和用户测试说明了其有效性。
可视化;文献分析;word2vec; BERTopic; Author-Rank;食品安全
文献阅读和分析是科研人员理解学科内涵、探寻学科发展规律、挖掘新兴课题和寻找学术合作机会的重要手段[1]。然而从大量文献中筛选出特定领域论文、从中提取主题、找出高影响力论文和学者,往往需要丰富的知识和大量的分析工作。
近年来出现的词表示模型将文本表示为向量,通过相似度计算大大提高了文献检索的准确率和效率,被广泛应用于学术文献推荐和主题分类等任务[2]。可视分析方法增强了机器学习和自然语言处理模型(如主题建模或词表示)的可解释性[3],可帮助研究人员深入分析大规模文献语料数据,从中快速获得某特定领域的知识,为解决文献分析问题提供了新思路。然而,现有的文献可视分析方法大多适合于领域经验丰富的科研人员,对于刚接触某领域的研究人员而言,如何基于主题的相似性精准找到该领域的研究热点、发展脉络、高影响力文献和学者仍然是一项极具挑战性的工作。
因此,本文提出了一种基于词表示模型的领域文献数据可视分析方法,以帮助初涉某领域的研究人员从主题演变、主题关键词、文献影响力、作者影响力、文献引用关系等多个角度进行快速理解和分析。
1 相关工作
1.1 词表示模型
词表示模型将自然语言中的词转化为可计算的稠密向量,即词嵌入向量的形式,方便使用计算机挖掘词语之间潜在关联[4]。2013年,MIKOLOV等[5]提出的word2vec模型不仅能够捕捉到语法的正确性,还能捕捉到语义特征。BERT (bidirectional encoder representation from transformers)[6]利用Transformer结构创建语境化的词嵌入,生成与周围的单词密切相关的词表示。文献是以大量的词汇、语句和段落组成的,通过对文献数据中的词和句子进行嵌入表示可以挖掘更多研究领域的有效信息[7]。目前,主题挖掘模型能够将文本表示在语义信息更为丰富的主题特征空间上,从而有助于文本分类、聚类和主题演化分析等任务[8]。但是现有的主题提取模型大部分依赖人工确定的参数[9]。BERTopic[10]无需主题数量等参数的设定就可以轻松提取主题信息。因此,本文使用BERTopic模型提取主题。
1.2 作者影响力评估方法
探寻高影响力的作者对于研究人员寻找合作机会尤为重要。h指数[11]是评价科学家在其学科领域的影响力的指标,该理念被研究人员广泛接纳,但其仅依赖作者的发文数量,未考虑论文之间的引用关系。利用文献引用信息不仅可以分析出大量相关领域的背景信息,还可以挖掘文献间的关系。吴淑燕和许涛[12]利用PageRank算法的“网络传播”原理计算文献引用网络中论文的影响力指标值,并对论文进行排序。谢瑞霞等[13]提出了一种依赖作者和论文被引频次的作者影响力指标,然而被引用论文影响力因素的缺失依旧导致该方法未能从论文质量角度评估作者在整个领域中的影响力。因此本文提出一种新的作者影响力指标,旨在参考更多客观评价作者影响力的因素。
1.3 文献数据可视分析方法
随着大数据平台和技术的发展,大量学科文献数据均可从网上获取[14]。可视分析研究已经有效地将许多机器学习和自然语言处理模型融入可视分析系统中[15-17],成为挖掘新兴课题,寻找学术合作机会的主要方式。邵航等[18]使用CiteSpace软件对3 375条文献有关出版物、作者、引文和词频数据等进行分析。但仅使用了“中国知网”一个语料库,没有英文文献,且可视化展示和交互较少,研究人员很难探索潜在的学术合作机会。GUO和LAIDLAW[19]实现了基于主题探索的可视化工具ThoughtFlow,但测试结果仅通过分析少量的文献数据获取。LI等[20]设计并实现了Galaxy Evolution Explorer (Galex)可视分析系统,使用多个控制面板和可视化控件交互工作,帮助研究人员快速理解一个学科的交叉和演变。LIU等[21]提出了一种挖掘分析任务、可视化技术和文本挖掘技术之间关联的方法,并对可视化文本分析进行了综述,但需具有领域知识的专家进行指导。鉴于此,本文从Semantic Scholars语料库中下载文献索引数据,并结合自然语言处理模型和可视分析方法挖掘主题信息、高水平论文和有影响力的作者等领域文献信息。
2 需求分析与总体思路
2.1 需求分析
针对初涉特定领域的研究人员在探寻该领域研究内容时的需求,通过与12位研究人员进行沟通,其中,10位为计算机专业的硕士研究生,2位为在食品安全与计算机技术跨学科领域具有资深经验的教授,了解其在接触新领域、理解学科领域内涵时遇到的困难和问题。经过45 min的讨论,最终归纳出文献数据可视分析工具需要提供的功能:
(1) R1,支持用户检索特定领域的文献数据。在不了解一个领域的情况下,研究人员需要一种方法可以准确检索到相关领域的文献数据。
(2) R2,为科研人员提供领域内不同主题的研究内容。研究人员需要领域主题信息挖掘有价值的课题,探索不同主题在学科领域的发展规律。
(3) R3,支持寻找高影响力作者。研究人员需要找到在学术领域内的贡献程度和活跃程度高的作者与具有突出贡献的作者进行交流,探寻学术合作机会并挖掘新兴课题。
(4) R4,支持根据主题词自动搜索相关论文。科研人员需要一种能够通过选择感兴趣的关键词自动检索到相关研究内容的论文检索工具,提高查阅文献的效率。
2.2 本研究总体思路
本研究由论文筛选、信息处理和可视分析3个模块组成,如图1所示。本文的文献索引数据来自Semantics Scholar开源文献数据库,其中包含了1 920万条文献索引数据,即论文题目、论文ID、论文摘要、作者、作者、发表年份和引用论文ID等属性。3个模块的具体工作原理是:
(1) 论文筛选模块。首先提取摘要实词,并输入word2vec模型得到摘要实词的向量表示;然后计算各摘要实词向量与粗粒度关键词的相似度,生成数量更多的细粒度关键词;进而筛选领域文献索引数据。
(2) 信息处理模块。首先将领域文献摘要输入到BERTopic模型中,提取领域主题;然后使用论文ID和引用论文ID字段构造文献引用网络,将该网络输入PageRank算法得到论文影响力PR值;进而再应用本文的Author-Rank算法,根据作者发表论文数量、论文PR值、论文发表年份和作者署名顺序计算出作者影响力AR值。
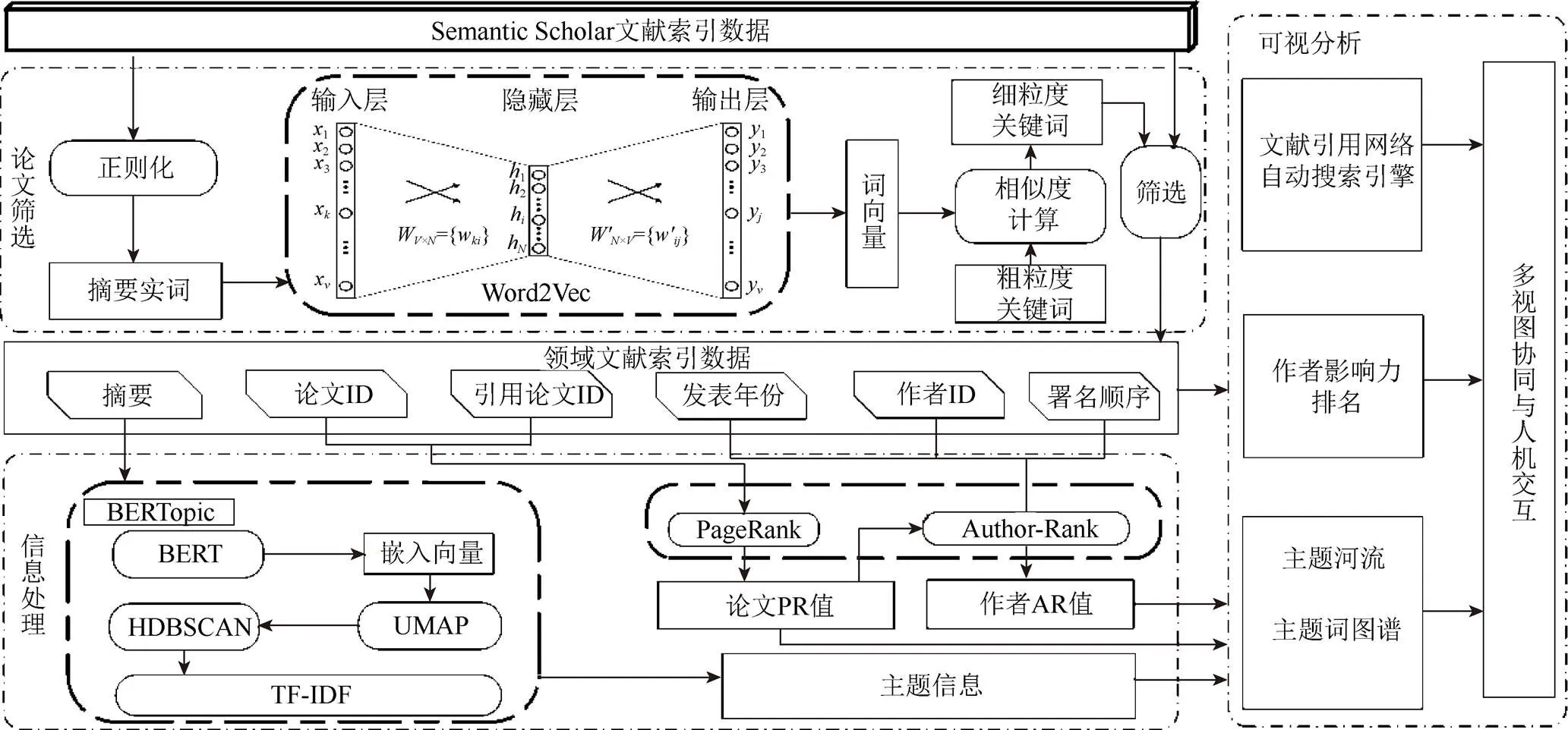
图1 基于词表示模型的领域文献数据可视分析方法研究框架
(3) 可视分析模块。对上述文献信息处理结果进行可视化,生成主题词频、文献引用网络、主题演变和作者影响力排名等多个视图,通过多视图协同和交互帮助用户对特定领域文献信息进行交互式分析,理解领域内涵。
3 基于词嵌入的领域论文筛选
关键词对于检索和筛选文献数据尤为重要,然而,初涉一个领域的研究人员往往只知道该领域很浅显的少量粗粒度关键词,仅通过粗粒度关键词检索领域相关论文是困难的。为了获取与粗粒度关键词食品安全相关联的细粒度关键词,本文利用word2vec对摘要中的实词进行向量化表示。利用词向量之间的相似度寻找相似细粒度关键词,并根据其找到丰富的领域论文(R1)。步骤如下:
步骤1.提取摘要实词。文献索引数据的摘要中存在大量与研究内容无关的虚词和符号,如“a”’“the”“we”“our”和“; ”等。使用正则化方法去除摘要中无用的符号和停用词(即虚词),获取摘要实词,每篇文献索引数据具有一条摘要实词记录。
步骤2.向量化表示摘要实词。将每篇文献索引数据的摘要实词记录看作一个句子,构成可以输入词表示模型的数据格式,作为词嵌入模型的输入数据。然后将所有文献索引数据的摘要实词输入word2vec的skip-gram模型中。该模型分为3层,输入层为当前输入的摘要实词的one-hot编码;输入层到隐藏层之间存在一个权重矩阵,当前摘要实词的one-hot编码与该权重矩阵做乘积运算获取一个输出向量,该向量为隐藏层的输入向量;隐藏层与输出层之间也有一个权重矩阵,隐藏层的输入向量与权重矩阵相乘得到输出层向量;使用softmax对输出层向量进行归一化处理;模型利用对数损失函数计算误差通过反向传播优化权重矩阵;同时,采用层次softmax方法加速训练过程;当训练次数达到预期设定的迭代次数时,词嵌入模型训练完成,此时输出的向量为每个摘要实词的词向量。该过程的目的是将每个摘要实词映射到低维嵌入空间中,并获得词向量。
步骤3. 推荐领域细粒度关键词。相似的词具有相似的词向量。输入领域相关的粗粒度关键词,如“食品”“安全”等。计算粗粒度关键词与其余摘要实词的词向量之间的余弦相似度。余弦相似度值越高,表示该摘要实词与粗粒度关键词的使用场景越相似。根据词向量之间的余弦相似度值对摘要实词进行排序,排名靠前的摘要实词与粗粒度关键词之间的相似度越高,与领域相关的可能性越高,这些相似度值高的摘要实词为领域相关的细粒度关键词。科研人员可以通过这些关键词深度了解领域研究热点,并检索相关的论文。以食品安全领域为例,利用词向量之间的相似度计算出的细粒度关键词见表1。
步骤4.获取领域文献索引数据。利用领域的细粒度关键词,通过筛选得到文献索引数据。为提供更系统全面的领域研究情况,本研究筛选出近31年食品安全领域的14 988条文献索引数据。

表1 根据词向量之间的相似性获取食品安全领域关键词
4 基于BERTopic的主题提取
研究特定领域的主题信息可以帮助科研人员更加系统地探索研究热点和研究趋势。本研究使用主题建模技术BERTopic提取领域主题(R2)。BERTopic是一种主题建模技术,其利用BERT嵌入和基于聚类的TF-IDF来创建密集的聚类,其还使用统一面域逼近和投影(uniform manifold approximation and projection,UMAP)技术,在对文档进行聚类之前降低嵌入的维度,能够轻松解释主题,并在主题描述中保留重要的单词。与LDA和NML方法不同的是,BERTopic无需超参数的设置免去了复杂的参数尝试步骤。BERTopic算法分3个阶段:
(1) 嵌入摘要数据。使用BERT提取文档嵌入。BERT[4]是一种自然语言预处理模型,使用来自语言模型的表述进行迁移学习,且与上下文无关,只需要无标记的数据。将文献索引数据中的摘要输入一个基于英语BERT的模型,使用双向Transformer结构[22]计算摘要的词向量。
(2) 聚类。t-SNE[23]未保留全局数据结构,所以只有在集群距离内才有意义,且计算需要占用大量的内容,而UMAP[24]在高维中使用指数概率分布,任何距离均可以代入直接计算,其使用随机梯度下降(stochastic gradient descent,SGD)代替常规梯度下降(gradient descent,GD),这既加快了计算速度,又减少了内存消耗。因此BERTopic使用UMAP降低嵌入的维数。然后将其词向量输入HDBSCAN,该算法可以自动地推荐最优的簇类结果。HDBSCAN[25]不仅可以减少嵌入向量,还可对相似的文献数据进行聚类。HDBSCAN输出的聚类数量为最终提取的主题数量。
(3) 创建主题表示。利用TF-IDF[26]评价每个词对每个HDBSCAN聚类的重要性。TF是词频,表示一个词在一类文本中出现的频率。IDF是逆向文件频率,一个词的IDF可由一个聚类中总文献数据数目除以包含该词的文献数据的数目,再将商取对数得到。如果包含单词的文档越少,IDF越大,说明词条具有很好的类别区分能力。当有TF和IDF时,可将这2个词相乘,得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么这个词在的重要性就越高,所以通过计算文章中各个词的TF-IDF,并由大到小排序,排在最前面的几个词,就是关键词。因此使用TF-IDF对主题进行提取和精简,可提高最大边缘关联词的一致性。最终获取每个主题中重要的单词。
(4) 根据主题划分文献数据。根据不同主题的主题词在每篇文献数据摘要中出现的频率,计算文献数据摘要与主题的匹配程度。如果在一篇文献数据摘要中出现主题A比其他主题的主题词频率高,则将其划分到主题A。
将食品安全领域文献数据的摘要输入BERTopic,经过训练得到食品安全领域的6个主题,即:食品供应链、食品养殖风险、膳食营养、食品检测方法、食源性疾病和农产品安全,每个主题的详细信息见表2。表2包括主题名称,每个主题除去粗粒度关键词后的10个代表性关键词和每个主题的论文数量。

表2 食品安全领域的主题信息
5 基于Author-Rank评价作者影响力
研究人员可以通过作者排名探索学术合作机会。作者的排名与其影响力有关,因此需要客观度量作者影响力指标的算法,本文提出了一种综合考虑作者署名顺序、论文数量、论文质量和发表年份的作者影响力算法Author-Rank。
目前关于论文合著者顺序分配贡献程度的算法已经有很多[27],其中调和算法[28]可以实现“署名顺序靠前的作者,对论文的贡献程度更高;反之贡献程度更低”的规律,一篇论文中所有作者的贡献度权重之和始终为1,即
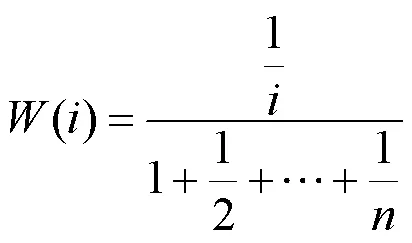
其中,为论文中的作者数量;署名次序为第名的作者贡献度权重值为()。
另外,作者发表每篇论文的影响力受到引用关系和发表年份的影响,发表时间距离数据采集时间越长,其影响力越低。因此作者影响力权重还需要结合论文质量和发表时间,即
本文利用被引关系,使用PageRank算法计算论文的影响力PR值[29]。结合论文PR值、发表时间和作者贡献度权重值计算出作者发表的论文影响力权重为
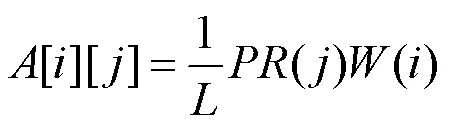
其中,=2021(年)–论文出版年份。
累加作者发表每篇论文获得的影响力权重值,得到作者的总影响力为
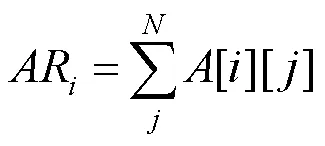
其中,为作者发表的论文数量。AR值越大表示作者的影响力水平越高。
为评估Author-Rank算法的效果,本文以“食品供应链”主题为例,绘制了该主题作者影响力排名视图,如图2(d)所示,并统计了该主题AR值排名前5的作者信息,包括作者ID、作者发表的论文数量、题目、发表时间、PR值、作者署名顺序、作者AR值,以AR值为指标的排名和以PR值为指标的排名,见表3。通过观察图2(d)和表3可以发现,以AR值为基准的作者影响力排名顺序与以论文数量和论文PR值指标为基准的作者影响力排名顺序基本一致,说明根据Author-Rank算法获得的作者影响力排名是有效的。

图2 文献数据可视分析系统界面——以食品安全领域为例((a)文献主题演变视图显示从1990年至2020年间食品安全领域6个主题每年被发表的论文数量和每个主题的论文总数;(b)主题词频视图显示被选定主题有代表性的10个关键词(去除“food” “analysis”和“safety”等食品安全领域的粗粒度关键词)及其在31年间出现的词频数量;(c)文献引用及影响力视图显示6个主题31年间的论文引用情况,节点大小表示论文的影响力指标PR值;(d)作者影响力排名视图显示在31年间研究特定主题的作者影响力排名情况;(e)文献搜索视图可以自动检索与主题关键词相关的论文)
表3中,作者“4989571”的发表论文数量和论文总质量比作者“3092817”的高,但AR值排名低。这是因为作者“3092817”发表的论文年份更新,研究内容更新颖也更具有参考价值。且作者“4989571”虽然有2篇论文,但在一篇论文中的署名顺序为第2名,作者“3092817”署名顺序为第1名,因此其AR值比作者“4989571”高,且排名也更靠前。由此可知,与只考虑作者发表论文数量和只考虑作者发表论文质量的方法相比,根据Author-Rank算法对作者影响力排名的结果更加实用和可靠。
6 文献数据可视分析系统
信息可视化在已有的研究[30]中得到了广泛应用,以帮助人们探索和理解数据。因此本文设计了一种文献数据可视分析方法,支持发现和识别主要的主题趋势、作者之间的关系和论文之间的引用关系。并根据该方法实现了一个文献数据可视分析系统,如图2所示。
6.1 文献主题演变
为观察不同主题的论文数量随年份的变化趋势,系统使用主题河流视图,展示特定学科领域内不同主题的演变趋势,如图2(a)所示。该图的横坐标表示发表年份,每个颜色映射一种主题,每个颜色的面积对应在该时间段内文献发表数量。鼠标悬停在某一个时间点特定主题的区间内,提示框便显示这一年该主题的论文数量及在31年间论文的总数量。如鼠标悬停在该视图蓝色区间(“食品供应链”主题),系统弹出提示框并显示‘2020年“食品供应链”:318/3614’,表示在2020年间“食品供应链”主题的论文数量为318篇,在31年间共计3 614篇。在视图的横轴上还设计了缩放控件,研究人员可以通过鼠标拖动横轴或滚动鼠标滚轴的方式,观察感兴趣时间段内每个主题的数量(R2)。
6.2 主题词频
主题词频视图主要展示对每个主题除去粗粒度关键词之外,最具有代表性的10个关键词(表2)及其在31年间出现的词频,如图2(b)所示。其中不同主题词频出现的多少用不同大小的圆来编码,圆越大表示该词出现的次数越多。该视图中每个圆的颜色为用户在文献主题演变视图中选定主题的颜色。为方便用户观察,鼠标悬停在某个主题词上,该词将高亮显示。主题词频为研究人员探索特定学科领域的研究热点提供了有力的帮助(R2)。
6.3 文献引用及影响力
系统使用节点-链接图结合力导向布局的方式展现论文之间的引用关系,如图3(c)所示。其中,每个节点代表一篇论文,节点越大表示该论文的影响力PR值越高,被参考和学习的价值越高。如果论文之间存在引用关系,则2个节点之间存在一条边。不同的颜色映射不同主题的论文(节点),该视图颜色与主题的映射关系与文献主题演变视图中的颜色映射相同。鼠标悬停在节点上,节点将以高亮形式显示论文题目及其PR值,如图4所示。
6.4 作者影响力排名
作者影响力排名视图展示了特定领域的作者影响力排名结果,如图2(d)所示。视图采用了3色并列柱状图,3种颜色对应3种不同的作者影响力度量指标:蓝色为基于Author-Rank算法作者的影响力评价指标;绿色为基于作者发表论文数量计算的评价指标;橙色为基于作者发表论文总PR值的评价指标。该视图的横坐标为作者影响力度量值,纵坐标为作者ID号,作者顺序按AR值从大到小排列。在视图的右侧,还设置了滑动轴,用户可以通过调整滑动轴的方式,调整视图的显示区间,如图2(d)和图3(d)所示(R3)。
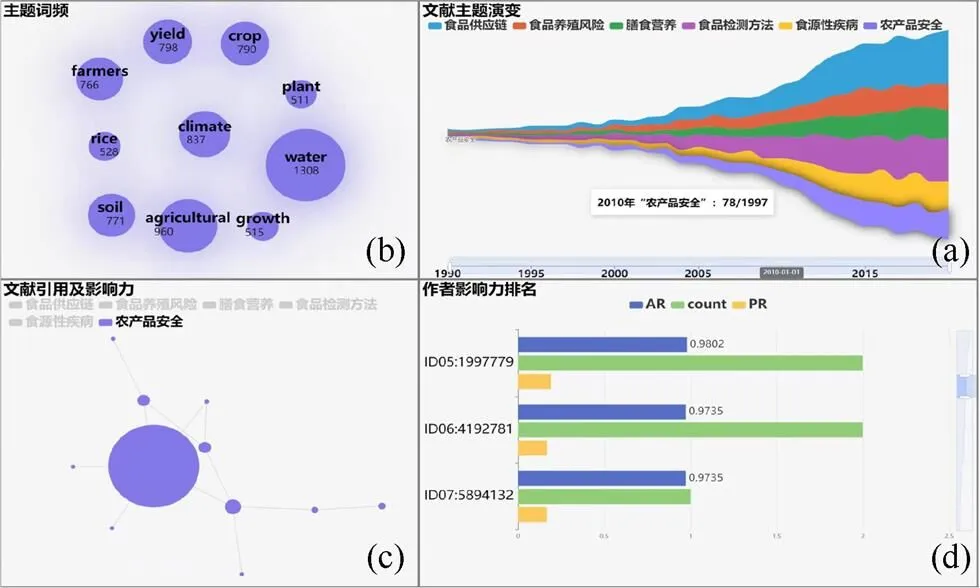
图3 分析“农产品安全”主题的文献信息((a)主题演变趋势;(b)主题关键词词频;(c)高水平论文;(d)高影响力作者)

图4 探索“农产品安全”主题高影响力论文及其引用关系((a)高影响力论文;(b)与高影响力论文有引用关系的论文)
6.5 文献搜索
系统根据论文PR值和文献URL信息构造了一个文献搜索引擎,该视图显示关键词检索结果。由于视图空间有限,视图仅显示论文的题目和部分摘要信息,其中题目为蓝色字体,摘要为黑色字体。搜索结果按照论文PR值的大小从上到下依次排序,如图2(e)所示。鼠标点击感兴趣的论文题目,页面将跳转到Semantic Scholar文献数据库对应的页面,显示该篇论文更详细的信息,帮助研究人员高效检索论文(R4)。
6.6 交互方式
系统使用过滤、高亮、缩放等交互手段帮助研究人员观察在特定领域中不同主题的研究趋势、研究热点、作者影响力和文献影响力信息。为在有限的界面提供给用户良好的可视化效果,系统设计了对用户友好的交互方式。
6.6.1 过 滤
在文献主题演变视图和文献引用及影响力视图中,用户可以通过选择主题对应色块的方式,筛选感兴趣的主题,观察不同主题从1990年至2020年间每年的论文数量(图2(a)和图3(a))、论文引用关系和论文的PR值。
6.6.2 高 亮
为了追踪用户感兴趣的主题信息,系统为文献主题演变、主题词频、文献引用及影响力和作者影响力排名视图添加了高亮功能,当用户的鼠标悬停在某个有效区间,该区间将会高亮显示如图2(a),图3(a)和图4所示。
6.6.3 协同交互
为帮助用户能够快速地获取领域中每个主题对应的学科内涵,系统设计了文献主题演变、主题词频和作者影响力排名视图之间的协同交互。点击文献主题演变视图中的主题区间并高亮显示,主题词频和作者影响力排名视图的信息将变换为1990年至2020年间该主题对应的代表性关键词和作者影响力排名信息,如图2(a),(b)和(d)所示。
6.6.4 自动检索论文
为帮助用户了解感兴趣关键词的详细研究工作,系统提供了自动检索论文功能。用户点击主题词频中的词汇,文献搜索视图中将自动填充用户选择的主题关键词,以检索相关论文,并进行自动搜索排名,如图2(b)和(e)所示。
6.6.5 自动跳转页面
由于视图空间有限,未能在界面中显示每篇论文的详细信息,系统设计了自动搜索论文功能。用户点击文献引用及影响力视图中的节点或文献搜索视图中的论文题目(蓝色字体),页面将跳转到Semantic Scholar数据库对应的论文网页,用户可查看该论文的详细信息。
7 案例分析和用户测试
本研究邀请12位研究人员参与调研,使用食品安全领域1990年至2020年间14 988篇论文的文献索引数据进行案例分析和用户测试,以验证文献数据可视分析系统的实用性和有效性。
7.1 探索不同主题的演变情况
通过观察文献主题演变视图可以发现食品安全领域的论文数量呈现增长态势,尤其在2010年后发展迅速,2020年受疫情影响论文数量并未减少,由此可见随着经济的发展,人们越来越关心食品安全问题。通过观察和比较文献主题演变每个主题对应的颜色区间,可以发现近10年“食品供应链”和“食品检测方法”主题的研究较多,这是由于物联网技术和深度学习技术的出现促进了学科融合,这为食品安全领域的研究带来了发展前途。综上所述,本系统可以帮助用户挖掘食品安全领域的文献主题演变规律(R2)。
7.2 比较不同主题的研究内容
比较不同主题的研究内容可以帮助初涉该领域的研究人员寻找到感兴趣的研究课题。首先在文献主题演变视图中点击“食品供应链”主题,主题词频发生变化,呈现该主题常见的专业词及词频,同时作者影响力排名视图中的作者信息也随之更新,如图2和图3所示。研究人员可以获知在食品安全领域“食品供应链”主题中的研究内容,该主题的研究热点词为“agricultural” “supply” “chain” “control”等;其最具影响力的作者ID为“3145569”。
除了“食品供应链”主题,研究人员还选择了“农产品安全”主题进行可视化探索,如图3所示。在文献主题演变视图中,点击“农产品安全”主题,可发现研究热点词为“water” “climate” “yield”等;该主题影响力排名第5位的作者ID为“1997779”。在“农产品安全”主题中,论文“World agricultural towards 2030/2050: the 2012 revision”的PR值为0.270 7 (图4(a)),是一篇高水平论文,值得对“农产品安全”领域感兴趣的研究人员阅读和参考。另外,由于论文之间的引用关系不是全连接图,而是由多个子图构成,每个子图的研究内容相似,因此通过观察子图可以找到相关研究课题及参考文献。在“农产品安全”主题的一个子图中,论文“World agriculture towards 2030/2050: the 2012 revision”被论文“Sustainable food consumption in China and India”引用,2篇论文在同一个子图中,因此这2篇论文研究课题相似,如图4所示。
7.3 自动搜索文献信息
为了解细粒度的论文信息,研究人员点击主题词频视图中的关键词,文献搜索框将自动填充该关键词,搜索与该关键词相关的论文信息。如,用户在主题词频视图中点击关键词“detection”,文献搜索框将自动搜索包含该关键词的论文信息,如图5(a)和(c)所示。在这些论文中,排名第一的论文影响力是最高的,论文题目为“Recognition of Multiple-Food Images by Detecting Candidate Regions”。
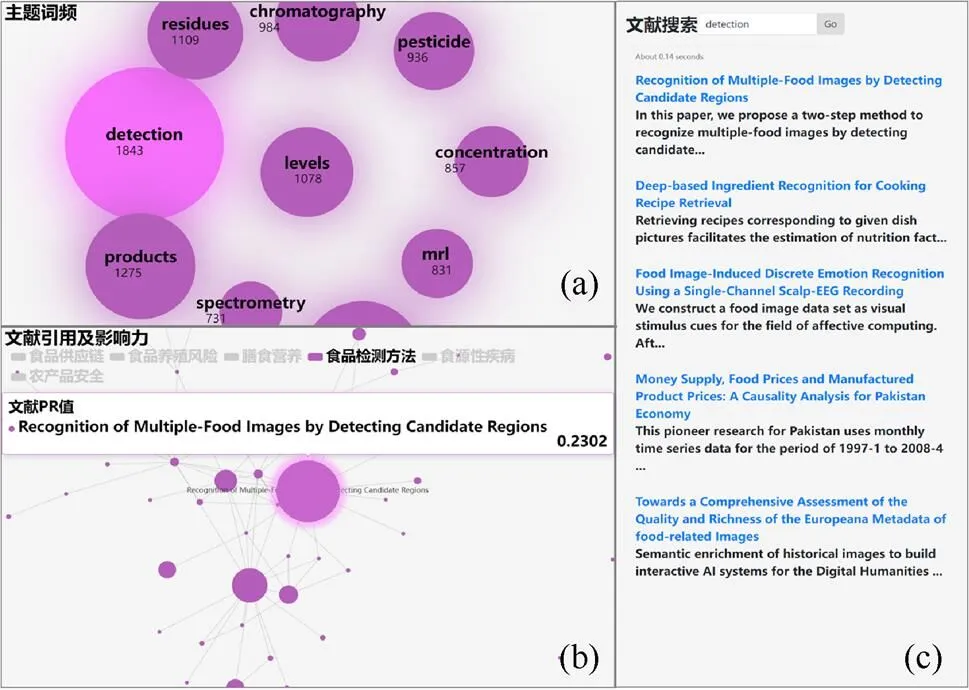
图5 自动检索“食品检测方法”主题论文示例图((a)主题词频及高频词汇;(b)高影响力论文及其引用关系;(c)检索到的论文)
研究人员将鼠标悬停在文献引用及影响力视图中最大的节点上,提示框显示该论文为“Recognition of Multiple-Food Images by Detecting Candidate Regions”。该文是该主题中PR值最大、影响力最高的论文,与文献搜索视图中排名第一的论文相同。研究人员点击搜索引擎栏中的论文题目,页面将跳转到Semantic Scholar学术平台中该篇论文的索引页面,以显示该论文的详细信息,节省了用户查询文献的时间。
通过实验证明,本系统通过过滤、高亮、缩放等交互方式多视图协同呈现不同主题的文献引用结构、作者影响力和研究热点等信息,帮助用户快速了解食品安全领域的学科内涵信息。
7.4 用户测试
为了解系统的实用性,被邀请的12位研究人员对系统中每个视图的满意程度进行评定,统计结果如图6所示,通过观察图6可以发现,研究人员对文献主题演变、主题词频和文献搜索视图的满意度普遍较高,没有“完全不满意”的视图。研究人员认为可以从系统中提取到食品安全领域的主题信息,对初涉该领域的研究人员的工作具有一定的帮助,基本能够满足其分析文献主题信息、高水平论文和高影响力作者信息的需求。但与其他目标相比,研究人员对作者影响力排名信息的“不满意”数量最多,经过沟通后发现,在使用中,因为作者信息与其著作信息不透明,所以不能直接在系统中获取到作者的更多有效信息。但12位研究人员对系统整体设计满意,系统可以帮助研究人员快速了解特定领域的研究工作。

图6 用户对各个视图功能的满意程度调查结果
8 结束语
本文提出了一种基于词表示模型的领域文献数据可视分析方法。首先利用word2vec计算词向量,根据相似度推荐丰富的关键词,以此筛选出领域相关的论文;然后利用BERTopic提取特定领域的主题,提出了一种综合计算多种指标的作者影响力评价算法Author-Rank;另设计并实现了一个文献数据可视分析系统,帮助研究人员探索领域主题演变趋势、高水平论文、研究热点和作者信息,快速掌握领域研究内涵,同时为研究人员了解领域发展趋势、探寻合作机会、寻找创新点提供新思路。
[1] PONTA L, PULIGA G, ONETO L, et al. Identifying the determinants of innovation capability with machine learning and patents[EB/OL]. [2021-11-15]. https://ieeexplore.ieee. org/document/9136883.
[2] BELTAGY I, LO K, COHAN A. Scibert: a pretrained language model for scientific text [EB/OL]. (2019-09-10) [2021-12-21]. https://arxiv.53yu.com/abs/1903.10676.
[3] ABDUL-RAHMAN A, ROE G, OLSEN M, et al. Constructive visual analytics for text similarity detection[J]. Computer Graphics Forum, 2017, 36(1): 237-248.
[4] IUCHI H, MATSUTANI T, YAMADA K, et al. Representation learning applications in biological sequence analysis[J]. Computational and Structural Biotechnology Journal, 2021, 19: 3198-3208.
[5] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//The 26th International Conference on Neural Information Processing Systems. New York: ACM Press, 2013: 3111-3119.
[6] DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [EB/OL]. (2019-05-24) [2021-12-21]. https://arxiv.53yu.com/ abs/1810.04805.
[7] 王卫军, 姚畅, 乔子越, 等. 基于词嵌入的国家自然科学基金学科交叉知识发现方法: 以“人工智能”与“信息管理”为例[J]. 情报学报, 2021, 40(8): 831-845.
WANG W J, YAO C, QIAO Z Y, et al. Method of discovering interdisciplinary knowledge of the national natural science foundation of China based on word embedding: a case study on artificial intelligence and information management[J]. Journal of the China Society for Scientific and Technical Information, 2021, 40(8): 831-845 (in Chinese).
[8] JI X N, SHEN H W, RITTER A, et al. Visual exploration of neural document embedding in information retrieval: semantics and feature selection[J]. IEEE Transactions on Visualization and Computer Graphics, 2019, 25(6): 2181-2192.
[9] 黄佳佳, 李鹏伟, 彭敏, 等. 基于深度学习的主题模型研究[J]. 计算机学报, 2020, 43(5): 827-855.
HUANG J J, LI P W, PENG M, et al. Review of deep learning-based topic model[J]. Chinese Journal of Computers, 2020, 43(5): 827-855 (in Chinese).
[10] ABUZAYED A, AL-KHALIFA H. BERT for Arabic topic modeling: an experimental study on BERTopic technique[J]. Procedia Computer Science, 2021, 189: 191-194.
[11] KELLNER A W A, PONCIANO L C M O. H-index in the Brazilian Academy of Sciences: comments and concerns[J]. Anais Da Academia Brasileira De Ciencias, 2008, 80(4): 771-781.
[12] 吴淑燕, 许涛. PageRank算法的原理简介[J]. 图书情报工作, 2003, 47(2): 55-60, 51.
WU S Y, XU T. An introduction to PageRank algorithm theory[J]. Library and Information Service, 2003, 47(2): 55-60, 51 (in Chinese).
[13] 谢瑞霞, 李秀霞, 韩霞, 等. 基于加权被引频次与署名顺序的作者影响力评价指标构建[J]. 情报科学, 2018, 36(8): 90-93, 111.
XIE R X, LI X X, HAN X, et al. Evaluation index of author influence based on weighted cited frequency and signature order[J]. Information Science, 2018, 36(8): 90-93, 111 (in Chinese).
[14] WU S Y, LI W B, WU J R. Construction of deep resolution and retrieval platform for large scale scientific and technical literature[C]//2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis. New York: IEEE Press, 2018: 375-379.
[15] CHEN Y, LV C, LI Y, et al. Ordered matrix representation supporting the visual analysis of associated data[J]. Science China Information Sciences, 2020, 63(8): 1-3.
[16] CHEN C M, SONG M. Visualizing a field of research: a methodology of systematic scientometric reviews[J]. PLoS One, 2019, 14(10): e0223994.
[17] FEDERICO P, HEIMERL F, KOCH S, et al. A survey on visual approaches for analyzing scientific literature and patents[J]. IEEE Transactions on Visualization and Computer Graphics, 2017, 23(9): 2179-2198.
[18] 邵航, 宋英华, 李墨潇, 等. 我国食品安全与数据科学交叉研究的科学计量学分析[J]. 食品科学, 2020, 41(13): 291-301.
SHAO H, SONG Y H, LI M X, et al. Scientometric analysis of cross-disciplinary studies on food safety and data science in China[J]. Food Science, 2020, 41(13): 291-301 (in Chinese).
[19] GUO H, LAIDLAW D H. Topic-based exploration and embedded visualizations for research idea generation[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(3): 1592-1607.
[20] LI Z Y, ZHANG C H, JIA S C, et al. Galex: exploring the evolution and intersection of disciplines[J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(1): 1182-1192.
[21] LIU S X, WANG X T, COLLINS C, et al. Bridging text visualization and mining: a task-driven survey[J]. IEEE Transactions on Visualization and Computer Graphics, 2019, 25(7): 2482-2504.
[22] FULTON S R, SCHUBERT W H. Vertical normal mode transforms: theory and application[J]. Monthly Weather Review, 1985, 113(4): 647-658.
[23] WANG Y F, HUANG H Y, RUDIN C, et al. Understanding how dimension reduction tools work: an empirical approach to deciphering t-SNE, UMAP, TriMAP, and PaCMAP for data visualization[EB/OL]. [2021-12-02]. https://arxiv.org/abs/2012. 04456v2.
[24] MCLNNES L, HEALY J, MELVILE J. Umap: uniform manifold approximation and projection for dimension reduction [EB/OL]. (2020-09-18) [2021-12-21]. https://arxiv. 53yu.com/abs/1802.03426.
[25] MCINNES L, HEALY J, ASTELS S. Hdbscan: hierarchical density based clustering[J]. The Journal of Open Source Software, 2017, 2(11): 205.
[26] QAISER S, ALI R. Text mining: use of TF-IDF to examine the relevance of words to documents[J]. International Journal of Computer Applications, 2018, 181(1): 25-29.
[27] SHEN C W, HO J T. Technology-enhanced learning in higher education: a bibliometric analysis with latent semantic approach[J]. Computers in Human Behavior, 2020, 104: 106177.
[28] WALTMAN L. An empirical analysis of the use of alphabetical authorship in scientific publishing[J]. Journal of Informetrics, 2012, 6(4): 700-711.
[29] DU M C, BAI F S, LIU Y S. PaperRank: a ranking model for scientific publications[C]//2009 WRI World Congress on Computer Science and Information Engineering. New York: IEEE Press, 2009: 277-281.
[30] 陈谊, 孙梦, 武彩霞, 等. 食品安全大数据可视化关联分析[J]. 大数据, 2021, 7(2): 61-77.
CHEN Y, SUN M, WU C X, et al. Visual associations analysis of big data in food safety[J]. Big Data Research, 2021, 7(2): 61-77 (in Chinese).
A visual analysis approach for domain literature data based on word representation model
ZHANG Qing-hui, CHEN Yi, WU Cai-xia
(Beijing Key Laboratory of Big Data Technology for Food Safety, School of Computer Science and Engineering, Beijing Technology and Business University, Beijing 100048, China)
With the development of science and technology, scientific literature is mounting to an increasingly large scale. How to quickly and accurately seek the research topics, influential scholars, and high-level papers in a specific domain from the vast amount of publications remains an enormous challenge. The visual analysis method for domain literature data based on word representation model employed word2vec to recommend domain-related keywords by the similarity between word vectors, and filters the domain-related papers according to these keywords. Then it utilized the BERTopic model to extract topics from the abstracts of domain papers. Next, the values for paper impact were calculated using PageRank, and the values for author influence were calculated using Author-Rank, the author impact evaluation method, taking into account the order of authorship, the number of publications, and the impact of papers. Finally, the multi-view collaborative and interactive visualization approach could help researchers gain a quick understanding and analysis of specific areas from multiple perspectives, such as topics word frequency, topics evolution, literature impact, citation relationships, and author impact. The method can be applied to literature data analysis in the field of “food safety”, and the results and user tests can validate this method.
visualization; bibliometric analysis; word2vec; BERTopic; Author-Rank; food safety
30 December,2021;
National Natural Science Foundation of China (61972010); National Key R&D Program of China (2018YFC1603602)
ZHANG Qing-hui (1997-), master student. Her main research interests cover visualization and visual analysis. E-mail:1930401028@st.btbu.edu.cn
CEHN Yi (1963-), professor, Ph.D. Her main research interests cover visualization, visual analysis, machine learning etc. E-mail:chenyi@th.btbu.edu.cn
TP 391
10.11996/JG.j.2095-302X.2022040685
A
2095-302X(2022)04-0685-10
2021-12-30;
2022-03-02
2March,2022
国家自然科学基金项目(61972010);国家重点研发计划项目课题(2018YFC1603602)
张清慧(1997-),女,硕士研究生。主要研究方向为可视化与可视分析。E-mail:1930401028@st.btbu.edu.cn
陈 谊(1963-),女,教授,博士。主要研究方向为可视化、可视分析和机器学习等。E-mail:chenyi@th.btbu.edu.cn
猜你喜欢
NBA特刊(2018年14期)2018-08-13
鄱阳湖学刊(2018年3期)2018-07-28
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
人大建设(2017年11期)2017-04-20
鄱阳湖学刊(2016年5期)2016-11-15
电脑知识与技术(2016年13期)2016-06-29
鄱阳湖学刊(2016年1期)2016-01-28
瞭望东方周刊(2015年12期)2015-04-14
