
基于域自适应的云南重彩画无监督情感识别
2022-08-16 09:38彭国琴
图学学报 2022年4期
彭国琴,张 浩,徐 丹
基于域自适应的云南重彩画无监督情感识别
彭国琴1,张 浩2,徐 丹2
(1. 云南大学信息技术中心,云南 昆明 650500;2. 云南大学信息学院,云南 昆明 650500)
计算机视觉中,深度学习之所以取得如此巨大的突破,均得益于可获得的大规模标记数据集,而在图像情感分析中,由于情感语义的模糊性,导致图像情感标注困难,公开可获得图像情感数据集较少,其规模也小,制约了基于深度学习的图像情感分析性能。情感语义具有其特有的有序性和极性分组特征,而已有的图像情感分析方法中很少关注到情感语义的这些本质特征。基于域自适方法,考虑情感语义的本质特征,提出一种基于推土机距离的情感语义对齐方式,将带标记的情感数据集的训练模型更好地迁移到无标记的情感数据集上,实现无监督的图像情感分析,解决情感数据集标注困难的问题。该方法应用于创建的云南重彩画数据集,实验结果表明,其能有效地对齐源域和目标域数据,实现无监督的情感数据集自动标注,有利于扩充图像情感数据集规模。
域自适应;云南重彩画;推土机距离;无监督;自动标注
心理学研究表明视觉内容会诱发观察者的多种情感响应[1]。且随着互联网的发展,人们普遍通过上传视觉内容(图像和视频)到社交平台的方式来表达情感。因此,对这些视觉内容的智能情感分析更加迫切,视觉内容情感分析在舆情监控、教育科技和思想挖掘等多个领域都有广泛地应用价值和意义。近年来随着计算机视觉任务的突破性进展,理解图像所传达的情感,即图像情感分析,也引起了研究者的广泛关注。
图像情感分析是一项具有难度的挑战性任务,主要是由于情感语义的模糊性,主要表现为2方面。一是情感类别语义的模糊性,情感类别的语义之间的边界不清晰,如在EKMAN[2]的6类基本情感(高兴、悲伤、惊喜、害怕、愤怒和厌恶)中高兴和惊喜边界是不清晰的,导致人们在进行情感标注时会模棱两可。情感类别不同于一般的分类任务的类别,其特有的特性为有序性和极性分组,图1展示了6类情感和8类情感的有序性和分组特性。根据情感的愉悦程度,从小到大对情感类别进行排序,即有序性。从左到右情感类别的愉悦度逐渐递增,部分情感类别之间的愉悦程度很接近,如6类基本情感中的高兴与惊喜;根据愉悦程度的正负性,情感类别自然地分为正向情感和负向情感,即分组特性,无论是6类情感模型还是8类情感模型,均具有有序性和分组特性。另一方面,不同文化背景、知识结构的人,对同一张图片会有完全不同的情感体验。情感语义的模糊性导致情感标注更加耗费精力,故可公开获得的情感数据集较少,规模也小,在基于深度学习的方法中,其成为了制约图像情感分析效果的关键因素。因此,要提升图像情感分析的性能,首要解决的是情感数据集规模小的问题。
考虑情感类别的本质特性,即有序性和极性分组,基于域自适方法,提出基于推土机距离(earth mover’s distance,EMD)的情感语义对齐方法,确保源域数据调整到目标域之后的情感语义保持不变。该方法从本质上对齐图像的情感语义,并应用于新创建的云南重彩画数据集,提升了无监督情感数据集的分类性能,实现了无监督数据集的情感标注与识别。情感语义对齐框架图如图2所示。
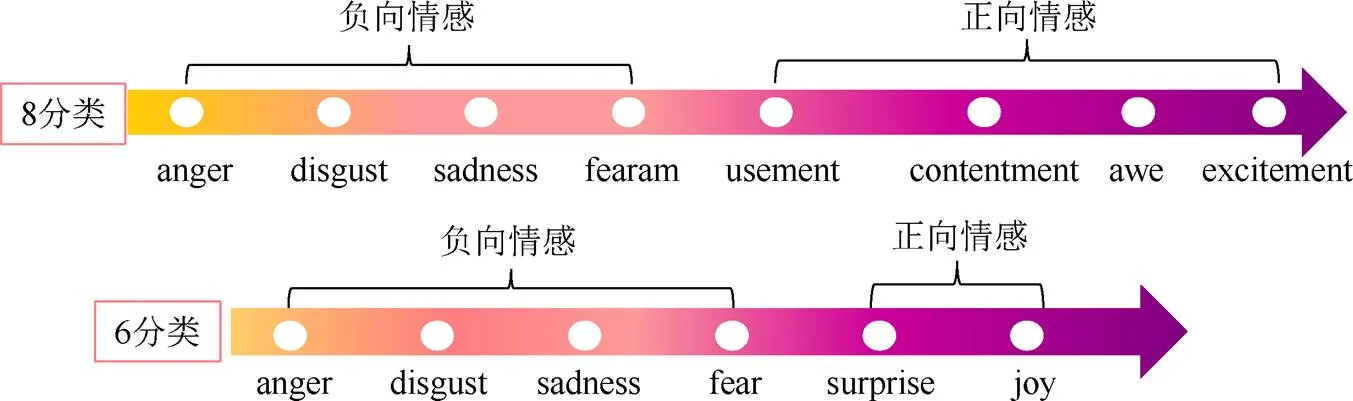
图1 情感的有序性和极性
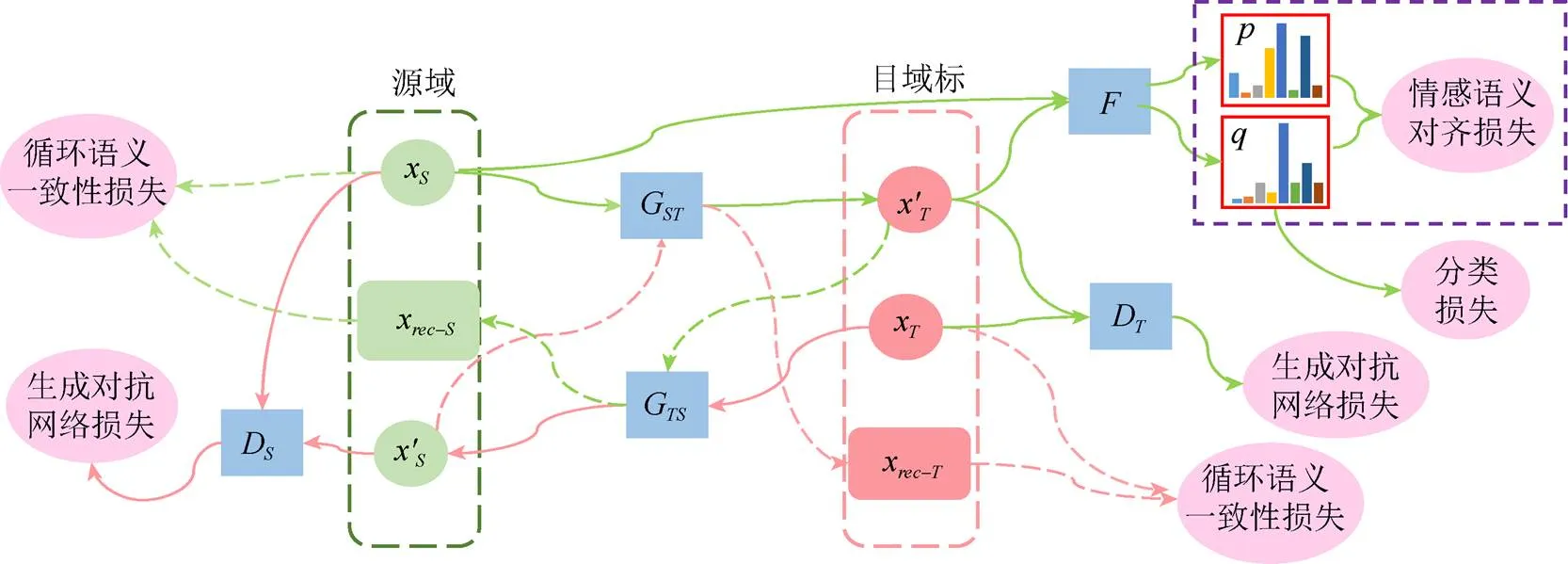
图2 域自适应情感语义分析对齐框架图
1 相关工作
1.1 图像情感分析
心理学上广泛采用的情感表示模型有:离散情感状态和维度情感空间2种。离散情感状态模型认为情感是一些离散的状态,典型的有EKMAN[2]和MIKELS等[3]的情感状态模型,2种情感状态模型分别包括6类和8类基本情感(图1);而维度情感空间模型将情感映射到连续维度空间中的一点,广泛采用的有PAD (pleasure-arousal- dominance)模型[4]和VA (valence-arousal)模型[5]。离散情感状态模型中的情感类别更容易被人们所接受和理解,在图像情感分析中被广泛采用。
图像情感分析经历从传统手工设计到深度学习的特征提取方法。早期主要通过手工设计来提取不同层的特征,如低层特征[6]、中层特征[7]和高层特征[8]。近年来,随着卷积神经网络(convolutional neural networks,CNN)在图像识别任务中取得成功,基于深度学习的方法已被应用于图像情感分析。PENG等[9]基于欧式距离为图像情感分析提出了回归CNN模型;YANG等[10]和ZHAO等[11]通过标签分布学习来揭示每类情感描述图像传达的情感程度;XIONG等[12]考虑情感类别分组和排序的结构化信息,利用情感的分组和有序性,解决标签模糊的问题。ZHAN等[13]认为随着心理学理论的发展,情绪类别更加多样化、细粒化,样本收集更加困难,提出了使用中层语义表示,即形容词-名词对(adjective noun pair,ANP)特征,来构建一个弥合低层视觉特征和高层语义的中间嵌入空间,研究情感识别中的零样本学习问题,目的是识别新出现的、未知的情感。ZHANG等[14]通过CNN结合来自高层的内容和低层的风格信息,如纹理和形状等,分析图像所传达的情感。
但和其他计算机视觉任务相比,图像情感分析的性能不能令人满意,主要是从情感数据集中公开可获得的情感数据集较少,且规模均较小。表1统计了图像情感分析中使用的14个情感数据集,其中只有4个数据集是开放的,且规模均较小。而基于CNN的深度学习方法,在大规模数据集上才能展现其卓越的性能。因此,扩充情感数据集成为图像情感分析性能提升的关键,然而由于情感语义的模糊加剧了人工标注的困难程度,能否借助已有的图像情感识别中取得的成果,通过自动标注来解决图像情感标注的难题。但这方面的研究还未引起研究者的广泛关注,本文基于域自适方法,将在已标记的源域数据上的训练模型迁移到未标记的目标域,实现对未标记目标域数据集的情感识别,实现图像的情感自动标注,进而扩充情感数据集。

表1 情感数据集统计表
注:*为开放数据集
1.2 域自适应
域自适应[15]是一种机器学习范式,研究如何将一个已标记源域的模型很好地迁移到其他稀疏标记或未标记的目标域上,域自适广泛应用于多种计算机视觉任务中。
域自适方法采用2个分支的体系结构来表示源域和目标域的模型,并结合其他的损失来处理域变化问题,如差异损失、重构损失和对抗性损失等。基于差异损失的方法,即度量源域和目标域在对应的激活层的差异,如CORAL基于最后一个全连接层和最后一个卷积层的最大均值差异[16]。基于重构的方法,即结合重构损失来最小化输入和重构输入之间的差异,如GHIFARY等[17]设计了一个在多个输出层的多任务的自编码器,每个输出对应一个域。域自适方法广泛采用基于生成对抗网络模型(generative adversarial networks,GAN),GANIN和LEMPITSKY[18]最先将对抗学习应用于域自适应中,并提出了梯度逆转(reversal of gradient,ReGrad)的优化方法,使得学到的特征表示对源域图像具有更好地辨别能力,同时对目标域图像具有域不变性,实现源域和目标域之间的知识迁移学习;BOUSMALIS等[19]提出的模型利用GAN调整源域图像,视觉上看起来其似乎来自目标域,为了惩罚源域和生成图像在前景像素上的差异,提出了最小化源域图像和生成图像掩码像素的平均均方误差,并泛化到训练阶段未见过的对象上,模型将域自适应的过程从特定的任务框架中分离出来;HOFFMAN等[20]强调循环一致性损失,提出了像素级和特征级的域自适应。ZHU等[21]提出了循环一致对抗网络(CycleGAN),在未配对训练图像时,通过一个反向的生成网络使得生成的目标域图像能恢复为源域的图像,即经过一个循环恢复输入的图像,使生成的图像看起来像来自目标域,但仍是源域图像的内容。
ZHAO等[22]利用CycleEmotionGAN,将域自适应方法应用于图像情感分析中,通过在CycleGAN中增加情感语义一致性来确保源域数据调整到目标域且情感语义不变,并通过KL散度(Kullback-Leibler divergence)来度量调整前后情感语义的差异,目标是使得情感语义差异最小化。由于提出的情感语义一致性未考虑情感类别的本质特性,如有序性和分组特性,且KL散度在度量具有有序性和分组特性的情感类别时,并不能从本质上反应情感类别的语义距离。因此,本文提出通过EMD来度量情感源域和目标域图像之间的情感语义距离。
2 方 法
域自适方法关键是源域图像调整到目标域之后,确保对应到图像情感分析中的情感语义不变。本研究考虑了情感类别的有序性和极性特征,提出了基于EMD的情感语义对齐损失,如图2所示,惩罚调整前后图像情感语义的变化,目标是最小化源域图像和目标域图像的情感语义,即源域图像调整到目标域之后图像的情感语义未发生变化。
2.1 情感语义对齐方法分析
图像情感分析中,KL散度广泛用于度量2个情感分布之间的差异,如CycleEmotionGAN通过最小化调整前后图像预测分布的KL散度以度量情感语义一致性的差异,目的是使调整后的图像看起来像来自目标域,但图像的情感语义要保证一致,即
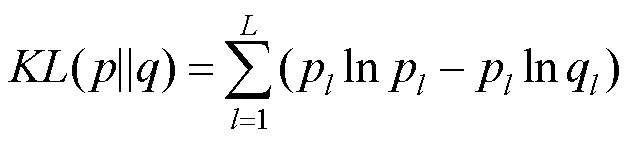
其中,和分别为对应源图像经过分类器之后得到的情感类别的概率分布和调整到目标域之后的图像经过分类器之后的情感类别的概率分布;为总情感类别数。
极性特征是情感类别的一个重要本质特征,离散情感表示模型和连续的维度模型均表现了极性特征。在同一个分组中,情感类别根据愉悦度的强度,得到8类情感和6类情感的有序性和分组特性如图1所示,从左到右表示了情感类别的有序性。在图像情感分析中,将一类情感错误预测为相邻的情感(如将joy预测为surprise)比预测为较远的情感(如将joy预测为sadness)更让人容易接受。但KL散度并不能很好地度量对这种差异的惩罚[12],下面举例说明。
对于一个3分类={1,2,3}的情感分类任务,其中1,2和3是有序的,真实的情感分布={0.6,0.2,0.2},假设有预测分布={0.2,0.5,0.3}和={0.2,0.3,0.5},根据式(1)可知(||ʹ)==(||ʹ)。但是,在图像情感分析中,根据情感类别的有序性,将1预测为相邻的2比预测为较远的3是更易让人接受的,那么预测为3的惩罚应大于2,但是KL散度度量的损失并不能反应这种惩罚的差异。本文方法考虑到情感类别的有序性和分组特性,提出通过EMD来度量2个情感分布之间的距离。最优传输理论中,EMD能更好地度量2个分布之间的差异[23]。
2.2 基于推土机距离的情感语义对齐
考虑情感类别的有序性和分组特性,提出的情感语义对齐分别考虑了有序和分组对齐。
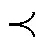


同理,考虑到分组特性,情感分布p与q之间的EMD为


本文提出的域自适图像情感分析,从情感类别的有序性和极性分组特性出发,利用EMD来度量情感分布之间的差异,惩罚图像从源域迁移到目标域之后情感分布的变化,能确保源域图像迁移到目标域后的情感语义保持一致。
2.3 模型优化
本文关注的是带标记的源域数据迁移到无标记的目标域上,实现对目标域数据集的无监督情感识别,即基于源域图像X及其标注信息Y实现对目标域图像X的情感标注。
2.3.1 循环一致性损失
图2为本文模型,涉及2个生成对抗模型:源域到目标域的生成模型G,从目标域到源域的生成模型G,与之相对应的2个鉴别器D和D,图2中绿线表示前向流程,红线表示反向流程。模型的整体思想是学习映射G:X→X将源图像X调整到目标域X,使得生成鉴别器D无法分辨目标域图像的真假,并且保持图像X的情感标注不变地传递给。
理论上,对抗训练学到的映射模型G和G能得到和目标域X和源域X同分布的输出,但要有足够大的容量,网络可以将相同输入图像映射到目标域中的任意图像,学到的任何映射均能生成和目标分布匹配的输出分布。因此,单独的对抗性损失不能确保学到的函数能映射输入到预期一致的输出,为了缩小映射函数空间,学习的映射应循环一致[21],且映射到目标域的图像经过逆映射后得到X-=G(G(X)),使得X-==X,反之亦然,即在反向上也通过循环一致性损失来确保调整之后的图像能恢复到源图像G(G(X))==X。循环一致性损失为

其中,P和P分别为源域图像和目标域图像服从的分布。2个生成对抗模型的损失分别为
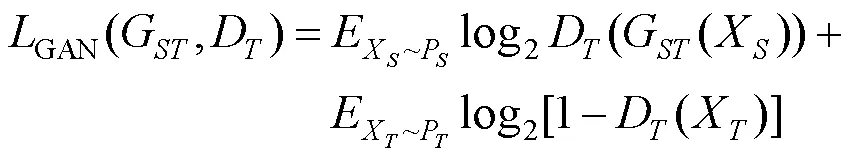

循环模型的损失为

其中,为控制循环一致性损失在模型损失中的相对重要性。
2.3.2 分类损失
为了解决无标签数据集的无监督标记,实现对目标域数据的分类,利用源域数据的标记信息Y,基于提出的情感语义对齐,期望调整到目标域后的数据的情感分布与目标域的数据X一致,且保留了源域数据X的情感标注信息,因此通过在(,Y)上训练分类模型,以实现对目标域数据X的无监督分类,并通过分类模型的最小化交叉熵来优化模型,分类模型的损失为

2.3.3 总损失
在CycleGAN上,调整源域数据与目标域数据的分布一致性,并增加情感语义对齐,确保调整前后情感语义的一致性。调整到目标域后,源域图像的情感语义被传递,通过调整后的图像和源域情感标注信息上训练分类模型,从而实现对目标域数据集的情感识别,因此,整个模型的损失函数为
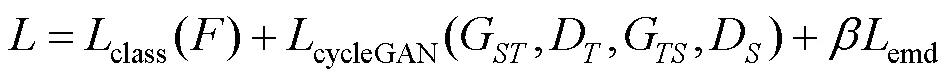
其中,为控制参数。
整个模型的优化过程涉及了G和G2个生成模型,及与其对应的2个鉴别模型D和D,和一个分类模型。采用随机梯度下降,通过交替优化的方式实现对整个网络模型的优化。
3 云南重彩画情感数据集
艺术作品是艺术家思想和情感的表达,对艺术作品的情感分析能有效探索创作者的心路历程、重现客观历史文化内涵,揭示创作者对时事的态度和情感。因此,在数字文化的保护中,尤其是对艺术作品,应当考虑其传递的情感。
21世纪80年代初,丁绍光、蒋轶峰等创作了云南重彩画,结合了中西方绘画的风格,以蓝色为基调,线条鲜明、色彩斑斓,视觉上赏心悦目,如图3所示。绘画内容主要反映云南自然风光和少数民族风土人情,具有浓郁的民族色彩,将东西方绘画语言、古今技法融为一体,夸张与写实相结合,具有较强的视觉冲击和很强的美感体验,是很受欢迎的装饰画。云南重彩画是最具代表的云南绘画流派,是云南民族艺术的璀璨之星,蕴含了丰富的民族文化元素,是民族意识和民族文化通过艺术绘画表现的成功代表。
早在2017年云南大学就开始了云南民族绘画图像的情感研究[24],按照年龄、性别、学历以及艺术素养为标记人员的情感标注设置了不同的权重,具体地,艺术家的标注权重为2,普通人为1,标注类别分为积极情感和消极情感,最终将情感标注概率最大的情感类别作为图像的情感类别。共收集了包括云南重彩画、云南版画、云南水粉画和云南油画在内的1 556张图片,标注为积极的情感有1 149张,消极的有417张。以此为基础,对云南重彩画进行了情感标注,创建了云南重彩画情感数据集,将本文方法用于该数据集,实现对其的无监督标注,验证该方法在无监督情感标注上的有效性。

图3 云南重彩画示例
4 实验与分析
4.1 网络结构
本文的网络模型包括2个GAN和1个分类网络。采用文献[21]的生成网络结构,其在未配对图像的风格迁移、对象迁移和从绘画中生成图片等任务上表现出了卓越的性能,生成网络由2个步长为2的卷积、9个残差块和2个分数步长(步长为1/2)的卷积组成,使用实例归一化策略。鉴别器使用的是70×70的PatchGANs[25],目的是判断该图像块的真伪性,这种块级别的鉴别器结构相较于全图像的鉴别器参数更少,且能在全卷积的网络中对任意大小的图像均有效。初始化生成器和鉴别器的参数服从(0,1)的均匀分布。分类器网络采用的是Resnet101网络结构,微调最后一个全连接层的数量为情感分类的数量8,并初始化为大规模分类数据集(ImageNet)上的预训练权重。
4.2 实验设置
为了实现对云南重彩画情感数据集的自动标注,实验中采用公开的源域数据也是8分类的情感数据集,即Abstract数据集和ArtPhoto数据集。目标域使用的无标记的云南重彩画情感数据集。Abstract和ArtPhoto数据集是文献[6]为验证艺术元素对诱发人类情感的影响而创建的数据集。其中Abstract数据集由抽象画组成,其只包含颜色和纹理,没有具体的含义,通过同行评审进行标注,最终获得280张图片,如图4所示。ArtPhoto数据集由806张艺术照片组成,是专业的艺术家拍摄和标注的,主要通过改变色彩、灯光及组合参数来唤起关注的特定情感,如图4所示。
在云南民族绘画情感数据集的基础上,通过邀请具有专业艺术素养的画家对其中的重彩画,基于Mikels的8类情感类别进行标注,构建了云南重彩画情感数据集,共有476张画作,每类情感的样本分布如图5所示。

图4 部分源域数据集中的图像示例

图5 云南重彩画情感数据集的样本分布
云南重彩画情感数据集的样本分布明显不均衡。存在的问题主要有:①情感数据集的规模较小,是因云南重彩画的规模不大;②云南重彩画大多表达平静、安宁和谐的画面,所以“amusement”和“contentment”的样本最多,而“anger”和“disgust”只有少数几个样本,导致样本不均衡。
Abstract数据集和云南重彩画情感数据集均为绘画作品的数据集,在绘画技法上是相同的。因此,2个数据集的数据分布差异较小,更适合于目标域为云南重彩画情感数据集的域自适方法中的分布拟合。
实验中设参数=10,=10。通过交替优化的方式完成对所有网络结构的优化,经过多次循环之后,最后得到一个在(,Y)上的分类模型,且在X表现良好。优化过程伪码描述如下:
输入:源域图像及其标注信息(X,Y),目标域图像X。
输出:目标域图像X的情感预测结果。
步骤1. 初始化生成器G和G及相应的鉴别器模型D和D的参数,其服从(0,1)均匀分布,分类器的参数为在ImageNet上的预训练权重。设置最大迭代次数为MAX;
步骤2. for step=1 to MAX执行;
步骤2.1. 从源域图像集X中随机抽取相同数量的样本,再从目标域图像集X中随机抽样相同数量的批量样本,执行一次前向过程;
步骤2.2. 固定鉴别器D和D、分类器的参数,根据式(8)和式(4)的损失值及损失值反向传播的梯度,采用随机梯度下降的方式优化生成器G和G的参数;
步骤2.3. 固定生成器G和G的参数,根据式(6)和式(7)的对抗损失来更新鉴别器D和D的参数;
步骤2.4. 根据当前生成器G,得到迁移到目标域的图像ʹ,(ʹ,Y)输入分类器,根据式(9)计算分类损失;
步骤2.5. 固定生成器G和G,以及鉴别器D和D的参数,反向传播分类损失来更新分类的参数。
在更新鉴别器时,使用的是生成的历史数据而不是最新生成模型生成的数据,为此,为每个生成模型设置了一个大小为50的生成缓存,每次随机从源域和目标域中各抽取1张图片,即设置批量大小为1。
4.3 实验结果
4.3.1 域自适应结果
表2展示了源域为Abstract数据集,在目标域云南重彩画情感数据集上的分类准确率,从实验结果可知,对比实验2的分类准确率最高,这是由于其设置为有监督的分类方法;与对比实验1(无监督)相比,分类准确率提升了7.61%;本文方法的分类准确率比最先进的CycleEmoitonGAN的准确率高1.90%,表明在域自适中,其考虑了情感类别的本质特征,通过EMD来度量的情感语义对齐损失的方法,比KL散度更适合于度量这种具有有序性和分组特性的情感类别的分布之间的距离。

表2 目标域上情感分类准确率对比(%)
图6展示了部分源域图像,迁移到目标域之后的效果,从图6(c)可以看出,调整到目标域之后的图像,表现出了目标域图像具有的蓝色基调。但由于Abstract数据集的分类性能不高,导致迁移后在目标域上的分类性能也不高,其原因是Abstract数据集的规模较小且不均衡,部分类别样本只有个位数。这也是开展本研究的初衷,解决情感标注困难,实现对情感数据集的自动标注,扩充情感数据集。

图6 源域图像自适应到目标域图像的结果示例((a)源域图像;(b)目标域图像;(c)源域图像调整到目标域之后的结果)
4.3.2 消融实验
基于域自适的图像情感分析的关键是保证图像从源域调整到目标域之后,确保情感语义不发生变化,通过情感语义对齐来保持情感语义的一致性。为了进一步说明增加情感语义对齐的必要性,设置了未考虑情感语义对齐的基准实验,如图7所示。基准实验的设置与本文方法相同,只是在目标函数中未考虑情感语义对齐损失,从图7的消融结果可知,考虑了情感语义差异的无监督分类准确率均高于基准方法,说明在域自适的图像情感分析中,有必要考虑源域和目标域图像的情感语义一致性。另基于KL散度的CycleEmoitonGAN的分类准确率高于基准,说明KL散度在保障情感语义一致性上有一定的效果;而本文方法取得了最优的效果,说明采用的EMD更能从本质上对齐情感语义,从而使得在目标域上分类的准确率最高。
4.4 情感标注
本研究的目的是实现无监督的图像情感标注,图8展示对云南重彩画的无监督标记结果,其中第1行是待标记图像,第2行展示了训练好的模型分类器对第1行输入图像的预测概率分布,预测概率最高的类别为图像的标记情感类别,从标记结果可知预测结果和真实的情感标注类别是一致的,说明本文方法将带标注的源域上训练的分类模型很好地迁移到了未带标注信息的目标域数据集上,并对目标域的图像进行情感标注,分类模型能做出有效地识别和正确地判断,表明其有效性。本文方法能对未标注的数据集进行情感标注,解决了图像情感分析中情感标注困难的难点,有利于促进情感数据集规模的扩充,对基于CNN的深度学习方法提升图像情感分析的性能提供了数据集基础,有利于性能的提升。

图7 消融实验分类结果对比

图8 无监督图像情感分类结果示例((a)示例1;(b)示例2;(c)示例3;(d)示例4)
5 结 论
在基于深度学习的方法中,制约图像情感分析性能的一个重要因素是情感数据集规模小,以致标注困难。为了解决问题,本文提出了基于域自适应的图像情感分析方法,试图将带有标注信息的源域数据集上训练的模型迁移到未标注的目标域数据集,实现对目标域数据集的无监督标注。关键是要对齐源域数据和目标域数据,将已有的方法通过KL散度来度量情感分布之间的差异,由于情感类别具有分组和有序特性,KL散度并不能很好地度量样本情感分布之间的差异。为此,提出了通过EMD来度量情感分布之间的差异,从情感的本质特征上对齐了源域和目标域数据。为了验证本文方法的有效性,在云南民族绘画情感数据集的基础上创建了云南重彩画情感数据集,并应用于该数据集,实现对其无监督情感分类和标注,与最相关的域自适应情感分析方法相比较,该方法提升了无监督情感分类的性能,表明基于EMD的情感语义对齐方式在图像情感分析中更加有效。
虽然该方法解决了无监督的图像情感识别问题,但整体分类准确率不高,是由于目前在源域数据集上的识别性能不高,制约了迁移到目标域之后的情感分类性能。究其原因是源域数据集规模较小、数据不均衡,这也是研究的初衷,希望通过无监督的情感标注,进一步扩充情感数据集,更好地发挥基于大规模训练集的深度学习在图像情感分析中的性能。
[1] DETENBER B H, SIMONS R F, BENNETT G G. Roll ‘em!: the effects of picture motion on emotional responses[J]. Journal of Broadcasting & Electronic Media, 1998, 42(1): 113-127.
[2] EKMAN P. An argument for basic emotions[J]. Cognition and Emotion, 1992, 6(3-4): 169-200.
[3] MIKELS J A, FREDRICKSON B L, LARKIN G R, et al. Emotional category data on images from the international affective picture system[J]. Behavior Research Methods, 2005, 37(4): 626-630.
[4] MEHRABIAN A. Framework for a comprehensive description and measurement of emotional states[J]. Genetic, Social, and General Psychology Monographs, 1995, 121(3): 339-361.
[5] RUSSELL J A. A circumplex model of affect[J]. Journal of Personality and Social Psychology, 1980, 39(6): 1161-1178.
[6] MACHAJDIK J, HANBURY A. Affective image classification using features inspired by psychology and art theory[C]//The 18th ACM International Conference on Multimedia. New York: ACM Press, 2010: 83-92.
[7] ZHAO S C, GAO Y, JIANG X L, et al. Exploring principles-of-art features for image emotion recognition[C]// The 22nd ACM International Conference on Multimedia. New York: ACM Press, 2014: 47-56.
[8] ALI A R, SHAHID U, ALI M, et al. High-level concepts for affective understanding of images[C]//2017 IEEE Winter Conference on Applications of Computer Vision. New York: IEEE Press, 2017: 679-687.
[9] PENG K C, CHEN T, SADOVNIK A, et al. A mixed bag of emotions: Model, predict, and transfer emotion distributions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 860-868.
[10] YANG J, SUN M, SUN X. Learning visual sentiment distributions via augmented conditional probability neural network[C]//The 31st AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2017: 224-230.
[11] ZHAO S C, DING G G, GAO Y, et al. Discrete probability distribution prediction of image emotions with shared sparse learning[J]. IEEE Transactions on Affective Computing, 2020, 11(4): 574-587.
[12] XIONG H T, LIU H F, ZHONG B N, et al. Structured and sparse annotations for image emotion distribution learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33: 363-370.
[13] ZHAN C, SHE D Y, ZHAO S C, et al. Zero-shot emotion recognition via affective structural embedding[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 1151-1160.
[14] ZHANG W, HE X Y, LU W Z. Exploring discriminative representations for image emotion recognition with CNNs[J]. IEEE Transactions on Multimedia, 2020, 22(2): 515-523.
[15] LONG M S, WANG J M, DING G G, et al. Transfer joint matching for unsupervised domain adaptation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 1410-1417.
[16] ZHUO J B, WANG S H, ZHANG W G, et al. Deep unsupervised convolutional domain adaptation[C]//The 25th ACM International Conference on Multimedia. New York: ACM Press, 2017: 261-269.
[17] GHIFARY M, KLEIJN W B, ZHANG M J, et al. Domain generalization for object recognition with multi-task autoencoders[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2551-2559.
[18] GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by back propagation[C]//The 32th International Conference on Machine Learning. New York: ACM Press, 2015: 1180-1189.
[19] BOUSMALIS K, SILBERMAN N, DOHAN D, et al. Unsupervised pixel-level domain adaptation with generative adversarial networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 95-104.
[20] HOFFMAN J, TZENG E, PARK T, et al. Cycada: cycle-consistent adversarial domain adaptation[C]//The 35th International Conference on Machine Learning. New York: ACM Press, 2018: 1994-2003.
[21] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]// 2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2242-2251.
[22] ZHAO S C, LIN C, XU P F, et al. CycleEmotionGAN: emotional semantic consistency preserved CycleGAN for adapting image emotions[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33: 2620-2627.
[23] LEVINA E, BICKEL P. The earth mover's distance is the Mallows distance: some insights from statistics[C]//The 8th IEEE International Conference on Computer Vision. New York: IEEE Press, 2001: 251-256.
[24] 赵贝贝. 基于可视化语义的云南民族绘画情感标注系统的设计与实现[D]. 昆明: 云南大学, 2017.
ZHAO B B. The design and implementation of the Yunnan national drawing system based on visual semantics[D]. Kunming: Yunnan University, 2017 (in Chinese).
[25] ISOLA P, ZHU J Y, ZHOU T H, et al. Image-to-image translation with conditional adversarial networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 5967-5976.
Unsupervised emotion recognition of Yunnan Heavy Color Paintings based on domain adaptation
PENG Guo-qin1, ZHANG Hao2, XU Dan2
(1. Information Technology Center, Yunnan University, Kunming Yunnan 650500, China; 2. School of Information Science and Engineering, Yunnan University, Kunming Yunnan 650500, China)
Thanks to the large-scale labeled datasets available, deep learning has made a great breakthrough in computer vision. However, due to the ambiguity of emotion semantics, it is hard to annotate the emotional labels for images. Thus, only a few small-scale image emotion datasets are open and available, restricting the performance of image emotion analysis based on deep learning. The semantics of emotions have unique characteristics, such as order and polarity, but few studies have paid attention to these essential characteristics in image emotion analysis. Thus, in the paper, based on domain adaptation, considering the essential characteristics of emotion semantics, that is, the ordered and grouped polarity, we proposed to measure emotion semantic differences through earth mover’s distance (EMD). The goal is to better transfer the trained model with labeled emotion dataset to unlabeled emotion dataset and complete the unsupervised image emotion analysis. The Yunnan Heavy Color Paintings Emotion dataset was created in this paper, and was applied to our proposed method. The experimental results demonstrate that the proposed method can effectively align the emotional semantics between the source domain and the target domain, realizing the unsupervised automatic annotation of emotion dataset, thus expanding the size of the image emotion dataset.
domain adaptation; Yunnan Heavy Color Paintings; earth mover’s distance; unsupervised; automatic annotation
29 November,2021;
National Natural Science Foundation of China (61761046); Applied Basic Research Key Project of Yunnan (YNWR-YLXZ-2018-022); Scientific Research Project of Yunnan Province Education Department (2021J0029)
PENG Guo-qin (1986-), lecture, Ph.D. Her main research interests cover computer vision, image emotion analysis, image semantic analysis and Machine learning. E-mail:pengguoqin@ynu.edu.cn
TP 391
10.11996/JG.j.2095-302X.2022040641
A
2095-302X(2022)04-0641-10
2021-11-29;
2021-12-30
30 December,2021
国家自然科学基金项目(61761046);云南省“云岭学者”专项(YNWR-YLXZ-2018-022);云南省教育厅研究项目(2021J0029)
彭国琴(1986-),女,讲师,博士。主要研究方向计算机视觉、图像情感分析、图像语义分析和机器学习。E-mail:pengguoqin@ynu.edu.cn
徐 丹(1968-),女,教授,博士。主要研究方向为图形学、计算机视觉、图像分析与理解、数字文化保护及图像情感计算等。E-mail:danxu@ynu.edu.cn
XU Dan (1968-), professor, Ph.D. Her main research interests cover graphics, computer vision, image analysis and understanding, digital culture preservation, image emotion computing, etc. E-mail:danxu@ynu.edu.cn
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
计算机技术与发展(2020年11期)2020-12-04
少儿画王(3-6岁)(2020年4期)2020-09-13
美术界(2017年4期)2017-06-22
艺术科技(2016年12期)2017-05-04
青年文学家(2015年29期)2016-05-09
微型计算机(2009年4期)2009-12-23
中国校外教育(上旬)(2006年7期)2006-07-21
早期教育(美术教育)(2006年7期)2006-07-13
