
利用门控网络构建用户动态兴趣的序列推荐模型
2022-08-12 02:30:24赵妮妮
计算机工程 2022年8期
王 燕,范 林,赵妮妮
(兰州理工大学计算机与通信学院,兰州 730050)
0 概述
在互联网飞速发展和移动设备大量普及的背景下,信息量爆发式增长,但信息冗余致使用户无法从海量信息中准确、快速地筛选所需信息,从而导致用户体验不佳。推荐系统很好地解决了这一问题,并且在搜索引擎、电子商务、娱乐等许多网络应用中发挥着非常重要的作用,因此,推荐系统具有重要的实用价值及研究意义。
目前多数推荐系统模型可分为基于协同过滤(Collaborative Filtering,CF)的模型和混合推荐模型。传统基于协同过滤的推荐模型虽然取得了不错的效果,但其基础的线性结构极大地限制了模型的表达能力。神经网络能够通过改变激活函数、选择和组合隐藏层单元来以任意精度近似任何连续函数特性,这使得深度神经网络不但能处理复杂的用户交互模式,而且还可以很好地拟合用户的偏好。凭借神经网络强大的数据泛化能力,结构复杂的混合推荐模型所表现出的性能远优于传统推荐模型,因此,基于深度学习的混合推荐模型是本文的主要研究对象。用户历史行为序列中包含丰富的用户兴趣信息,精确地捕捉用户兴趣是提升推荐系统推荐准确的关键。
近期,研究者提出了多种对用户兴趣建模的方法。文献[1]提出一种基于贝叶斯图卷积神经网络的框架,用于对用户-物品交互的不确定性建模,以更好地描述用户和物品之间的关系,同时建模用户的偏好,但图模型的复杂度较高,提取用户兴趣偏好需要的计算量较大。文献[2]提出使用长短期记忆网络建模用户兴趣的方法LSTPM,将用户的交互记录看作是一个很长的序列进行用户长短期兴趣的建模,但该方法在用户交互序列很长时,随着模型的复杂度增加,提取的用户兴趣变得不再准确,且模型将提取到的用户兴趣看作同等重要,这显然不符合现实逻辑。受自然语言处理(Natural Language Processing,NLP)领域Transformer 模型中注意力机制方法[3]的启发,研究者将注意力机制应用到推荐系统中,解决了许多模型将用户兴趣项看作同等重要的问题。文献[4]提出一种新的自适应分层注意力增强门控网络,为了获取可区分的细粒度特征,其引入注意力机制层来学习重要的语义信息特征以及这些特征之间的动态联系。文献[5]提出一种基于自注意力的协同神经网络模型,将用户相似度和物品相似度结合起来,利用注意力机制从用户购买历史中多方面计算物品的权重,进而捕捉用户兴趣信息。
尽管目前在捕捉用户兴趣信息方面已经有大量研究,但大多将用户历史行为视为按操作时间戳排序的操作序列,并未从特征层面捕捉用户兴趣,而从特征层面捕捉细粒度的用户兴趣可有效地提升推荐性能。同时,捕捉项目之间的成对关系对用户兴趣的建模同样重要,这种项目间成对的共现模式在推荐系统中很常见。此外,用户兴趣是动态变化的,如何建模用户的动态兴趣变化,也是需要解决的一个重要问题。
针对上述问题,本文提出一种利用门控网络构建用户动态兴趣的序列推荐模型DCGN。在用户的历史行为数据中捕捉用户兴趣,使用双层门控线性单元(Gated Linear Unit,GLU)从特征层面捕捉细粒度的兴趣信息,保留用户交互中重要的特征以及交互项目。使用GRU 聚合学习到的用户兴趣信息,并通过注意力权重动态更新GRU 的隐藏状态,捕获用户动态变化的兴趣偏好。在此基础上,利用双线性特征交叉方法对项目对之间的关系进行建模,通过多层全连接网络学习得到最终的输出结果。
1 相关工作
1.1 序列推荐模型
传统的协同过滤模型以静态的方式拟合用户与项目之间的交互模式,且其捕捉的用户兴趣对于用户而言是一种广义的模式,缺乏个性。不同于传统的协同过滤推荐模型,序列推荐模型的构建基于连续的用户-项目交互序列。用户-项目交互序列是一个动态变化的序列,且交互序列前后具有很强的关联性。序列推荐模型通过拟合用户与物品之间的交互模式捕捉用户的偏好,并利用用户交互序列中丰富的上下文信息描述用户的意图和消费趋势。
传统基于马尔科夫链的序列推荐模型[6]假设用户当前的交互项仅依赖于最近的几个交互项,但忽略了用户较早的交互项对当前交互项的影响。基于因子分解机的序列推荐模型[7]将用户与项目的交互分解为用户和项目的隐因子向量,通过参数分解对特征之间的高阶交互进行建模,但模型易受数据稀疏性的影响,使得推荐结果不够理想。深度学习技术的兴起,能够很好地解决传统序列推荐模型的不足,获得较大的性能提升。
1.2 基于深度学习的序列推荐模型
利用深度学习技术构建序列推荐模型通常先将用户交互的项目序列转换为低维稠密的嵌入向量进行表达,再使用加和、平均和取最大值的方法融合用户的历史交互信息,得到用户的兴趣表达,但模型将用户交互序列中的交互项视为同等重要,结果中只包含了用户部分重要的兴趣,且无法建模用户兴趣的变化。
一些研究者尝试利用更复杂的模型结构来构建用户兴趣并提高推荐性能。基于GRU 的序列推荐[8]通过建模给定交互序列中的依赖来预测下一个可能的交互项,但其只使用了交互项信息,并未考虑到其他信息对结果的影响。文献[9]提出根据用户偏好自适应地选择项目中有吸引力的潜在特征,然后利用提取到的特征对用户兴趣进行建模。文献[10]基于RNN 建模用户的交互序列,考虑用户行为的特征信息,然后使用注意力机制计算每个交互项的权重,得到用户的兴趣向量表示。文献[11]基于RNN 建模用户交互序列中的微观行为,利用RNN 对用户行为的特征信息建模,在用户微观行为、商品等多个层面得到兴趣向量。基于RNN 构建的序列推荐模型存在无法有效建模行为序列中多个行为间关联的问题,对此,研究者将NLP 领域的Transformer 模型应用到推荐系统中。文献[12]将用户的行为序列划分为多个会话,发现每个会话区间内用户的兴趣往往是固定的,然后基于Transformer 模型建模每个会话内用户的行为序列,再使用RNN 聚合多个会话内的兴趣信息。为更好地捕捉用户兴趣,文献[13]尝试利用胶囊网络建模用户的行为序列,获得多个用户的兴趣向量,然后使用一个可控的多兴趣聚合模块平衡用户兴趣的多样性与准确性,这一模型的提出,也为序列推荐模型的研究提供了全新的思路。
针对现有序列推荐模型没有从特征层面充分考虑用户交互项之间的联系,以及用户兴趣动态变化和相似交互项连续出现的问题,本文提出利用门控网络构建用户动态兴趣的序列推荐模型DCGN。该模型基于门控网络提取用户兴趣,且通过注意力权重动态调整信息聚合函数,以获得用户的动态兴趣,同时,考虑项目间成对的联系信息,进一步提升推荐的准确率。
2 DCGN 模型
本文提出的DCGN 模型从用户交互序列中学习用户动态变化的兴趣表示,目标是从特征的层面提取用户的兴趣,同时通过挖掘项目对之间的联系提升模型效果。DCGN 模型结构如图1 所示,具体步骤如下:

图1 门控网络中用户动态兴趣构建流程Fig.1 Procedure of user’s dynamic interest construction in gated network
1)将高维稀疏的用户交互序列、项目特征及用户特征作为模型的输入。
2)通过嵌入层将所有的特征映射到一个低维的空间中,得到低维稠密的嵌入向量。
3)将用户交互序列嵌入向量输入到一个双层的门控网络中,利用GLU[14]从用户交互的特征层面对用户兴趣进行建模,过滤输入序列中的项目特征并保留对用户重要的交互项目,即用户兴趣。
4)使用双线性特征交叉方法学习目标项目对之间的联系,捕捉2 个项目之间的共现模式。
5)对门控网络提取到的用户兴趣进行聚合,此部分采用GRU 循环门控网络,结合目标项向量与提取到的兴趣向量,使用注意力机制获得相应兴趣项的注意力权重,并利用该权重对GRU 的隐状态进行更新,得到最终的用户动态兴趣表示。
6)通过堆叠多个全连接层得到最终的预测结果。
2.1 嵌入层
为了对序列推荐任务进行建模,对于每个用户i的交互序列,按时间顺序表示为Si={si(1),si(2),…,si(t),…,si(l)},其 中:Si∊Rd×f×l;l∊R 为 用户交互序列的长度;f∊R 为交互项的特征数;si(t) ∊Rd×f表示用户交互序列中第t次购买/评价的项目。将该序列作为输入,解释为在用户-项目交互序列Si中,给定l个连续项目,预测其他N个项目接下来将被交互的可能性。将交互序列输入到嵌入层转换为低维稠密的向量表示,用户第t个交互项的嵌入向量如式(1)所示:

2.2 门控网络
DAUPHIN 等提出的门控线性单元(GLU)[14]在语言建模任务中控制信息传递,用于下一个单词的预测。GLU 计算公式为:

其中:Χ为单词的嵌入向量;W、V为卷积操作中的卷积核;b、c为偏置参数;σ是sigmoid 函数;⊗为矩阵之间的元素乘积;*为卷积操作。公式中的后半部分,即有激活函数的卷积σ(X*W+c),就是门控机制,其控制(X*W+b)中可以传入下一层的信息。
将上述方法用于用户行为序列的兴趣提取,GLU 网络结构如图2 所示。

图2 GLU 网络结构Fig.2 Network structure of GLU
由于卷积运算中卷积核的特性,导致只提取到一部分特征,数据中丰富的特征信息丢失,因此将卷积运算替换为向量的内积,在运算中保留特征信息。使用两层线性门控网络提取交互序列中的重要特征和与未来交互有关联的项目,即提取用户兴趣。先使用一层门控网络提取适合用户偏好的项目特征:

其中:W1,W2∊Rd×d;b∊Rd为可学习的参数;⊗为向量的元素乘 积;σ是sigmoid 函 数;ui为用户i的向量表示。然后,采用不同于使用注意力机制模型的做法,使用上一层门控网络提取到的重要交互特征作为输入,选取交互序列中与预测未来的交互项更相关的项目,如式(4)所示:

其中:W3∊Rd;W4∊Rd×f为可学 习参数;f为特征数量∊Rd×f为门控网络最终提取出的用户兴趣,用户交互的主要特征和项目已被选择,无关的特征和项目被过滤。
2.3 注意力机制
从数学的角度来看,注意力机制只是对平均操作或加和操作进行改进,换成了加权平均或加权,这种加权方式对于模型的效果有明显提升作用。从注意力权重计算的一种形式上来看,其与全连接网络的结构颇为相似,但不同的是,注意力权重参数是位置无关的,权重是根据输入的前后信息进行计算的,一旦输入的前后信息发生变化,其权重也会相应地发生变化。这种根据输入的前后信息来计算权重的方式,能够更好地刻画输入序列中的重点信息,帮助模型对输入信息进行区分。计算注意力分数的公式如下:


2.4 GRU 动态兴趣聚合
上节通过两层门控线性网络得到用户兴趣的表示,本节使用GRU 对提取到的用户兴趣进行聚合,结合注意力机制对用户的动态兴趣进行建模。注意力得分在GRU 的每一步中都可以增强相关兴趣所起的作用,减弱无关兴趣对总体结果的影响,更好地建模用户对目标项的兴趣变化,如下式所示:


2.5 项目特征交叉与模型预测
项目之间成对关系的学习[15]对于推荐系统十分重要,在序列推荐问题中,密切相关的项目有很大概率会在将来的项目交互序列中连续出现。
传统元素积的形式难以有效地对稀疏数据进行特征交叉建模,且模型的表达能力不强。为捕捉这种项目之间的共现模式,本文使用双线性交叉函数进行学习,其结构如图3 所示。

图3 双线性特征交叉函数结构Fig.3 Structure of bilinear feature crossing function
双线性特征交叉函数如下所示:

其中:Wj,q∊Rd×d为参数矩阵;∙为内积运算;⊙为哈达玛积;j,q∊(1,2,…,m);m为目标项目数量。对项目j与项目q特征交叉结果pj,q∊Rd通过平均池化聚合为当前项目的向量表示pj=avg(pj,q),pj∊Rd。将xi=向量输入到MLP 中,得到最终的预测结果:

其中:a(0)为网络的输入xi;l为网络的深度;δ为ReLU激活函数;W(l)、b(l)为可学习参数;a(l)为第l层的输出。将最后一层L的输出输入到sigmoid 函数中,得到最终的预测结果:

其中:σ为sigmoid 函数;a(L)为最后一层网络的输出;W(L+1)、b(L+1)为可学习的参数。通过最小化以下目标函数进行模型学习:
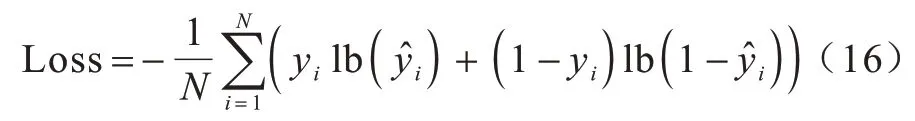
其中:yi为训练样本i的真实值为预测 值;N为 训练样本的数量。
3 实验
3.1 实验数据集
采用电影评分数据集ML100K[16]、亚马逊电子商务数据集Amazon ecommerce dataset[17]和电子 商务网站行为数据集Retailrocket[18]这3 个数据集进行建模。Retailrocket 数据集由一家个性化电子商务公司发布,包含6 个月的用户浏览记录;ML100k 数据集包含用户编号、电影编号、电影评分、时间戳及电影的相关信息,且该数据集已经过清洗;亚马逊电子商务数据集包含多种类型(如CD 销售数据、图书销售数据等)的数据,此处采用电子产品类的数据集Amazon 5-Elect,其中包含多个字段。本文实验仅使用商品编号、用户编号、产品评分和Unix 格式时间戳字段。每个用户编号、商品编号都是唯一的,对每个用户交互的商品编号,根据数据字段中的时间戳进行排序,得到用户对应的交互序列。为了消除噪声数据对模型结果的影响,过滤掉出现次数少于5 次的项目,然后删除数据集上少于2 项的所有交互项,将评分大于4 的设置为1,小于4 的设置为0。数据集中的数据属性及数据特征如表1 所示,所使用3 个公开数据集的数据统计结果如表2 所示。

表1 Amazon 5-Elect 数据集数据属性Table 1 Data properties of Amazon 5-Elect dataset

表2 实验数据集统计Table 2 Statistics of the datasets in experiments
3.2 评价指标
本文使用精确率Precision@K、归一化折损累积增益NDCG@K和命中率HR@K,其中,K为推荐列表的长度,实验分别设置K=5,10 来评估模型性能。
精确率表示模型预测为正的样本中有多少是真正的正样本,计算公式为:

HR@K指标衡量的是推荐结果的召回率,反映推荐模型的准确性,计算公式为:

NDCG@K用于评价排序的准确性,即评价推荐系统所给出的推荐列表的好坏。该指标关注的是预测到的项目是否放在推荐列表中更靠前的位置,即强调推荐系统的“顺序性”,计算公式为:

在式(19)中,r(i)为推荐列表中项目i的相关性分数,如式(20)所示:

其中:p为推荐列表;G为实验测试集;pi表示推荐列表中的第i个项目。
3.3 对比模型及实验设置
为了评估本文模型性能,选取以下序列推荐模型,在数据集ML100k、Amazon 5-Elect 和Retailrocket上分别进行对比验证:
1)NARM[19]:该模型通过RNN 最后一步的输出来捕捉用户的序列行为,根据RNN 中每一步的输出,通过注意力机制来捕捉用户的主要兴趣偏好。
2)GRU4Rec[20]:该模型首次利用RNN 从用户的会话序列中获取用户交互序列中的顺序依赖关系,相较于混合结构的序列模型,单一RNN 的结构比较简单。
3)STAMP[21]:该模型是基于注意力机制捕捉用户兴趣偏好的序列推荐模型,解决了传统的RNN 结构不能很好拟合用户兴趣的问题。
4)NLR[22]:该模型将序列推荐看作一项认知任务,根据离散数学的理论设计了具有逻辑推理能力的网络用于推荐任务。
5)SASRec[23]:采用自注意力机制对用户的历史行为信息进行建模,提取更有价值的信息,同时通过注意机制可以基于相对较少的用户交互进行预测。
6)Caser[24]:采用卷积神经网络捕获用户行为序列,再利用全连接层将拼接的序列特征与用户偏好映射到用户在当前时间与每个物品交互的可能性。
7)AFM[25]:通过注意力机制自动学习每个二阶交叉特征的重要性,过滤无用的交叉特征,提升模型的稳定性。
在此次实验中,学习率调整范围为[0.000 1,0.001,0.005,0.01,0.1],嵌入向量以及隐层维度调整范围为[8,16,32,64,128],在ML100k 数据集上进行参数调整。模型训练数据的批大小设置为100,模型参数采用服从N(0,0.1)高斯分布的随机数进行初始化。
3.4 实验结果比较
在ML100K、Amazon 5-Elect 和Retailrocket 数据集上,所有对比模型的NDCG 和Precision@K评估指标分别如图4~图6 所示。在Amazon 5-Elect 和Retailrocket 数据集上,所有对比模型的HR@K评估指标如图7 所示。

图4 ML100K 数据集上不同模型的NDCG@K 和Precision@K 对比Fig.4 Comparison of NDCG@K and Precision@K by different models on ML100K dataset

图5 Amazon 5-Elect 数据集上不同模型的NDCG@K 和Precision@K 对比Fig.5 Comparison of NDCG@K and Precision@K by different models on Amazon 5-Elect dataset

图6 Retailrocket 数据集上不同模型的NDCG@K 和Precision@K 对比Fig.6 Comparison of NDCG@K and Precision@K by different models on Retailrocket dataset

图7 数据集Amazon 5-Elect 和Retailrocket 上不同模型的HR@K 对比Fig.7 Comparison of HR@K by different models on Amazon 5-Elect and Retailrocket datasets
通过实验对比可以得出以下结论:
1)在3 个数据上,NARM 模型的效果始终优于GRU4rec 模型,而两者都是基于RNN 的推荐模型,可见注意力机制的运用有效地提升了模型性能。
2)实验结果中AFM 模型的性能总体较差,表明融入注意力机制的简单模型性能有限,模型性能还与模型的复杂程度有关。
3)实验中STAMP 模型的效果次于NARM 模型,两者都融入了注意力机制,表明基于RNN 的模型相比基于MLP 的模型的效果更佳,在推荐系统中仅仅考虑用户交互序列的特征交叉是不够的,还需要考虑用户交互行为前后的关系以捕获用户的顺序行为。
4)SASRec 模型的效果始终优于Caser、GRU4Rec、STAMP、NARM 模型,说明叠加多个自注意力机制层能够学习更复杂的特征转换,可有效提高模型性能,相较于传统基于CNN、RNN 的模型具有明显优势。
5)DCGN 比SASRec 和NLR 模型具 有更好的效果,可见利用门控网络和注意力机制从用户交互序列中学习用户动态兴趣有效地提升了推荐效果,采用传统结构的DCGN 模型相较于采用复杂结构的NLR 模型表现更好,表明模型复杂的结构不是提升推荐性能的关键。
3.5 模型消融实验
在ML100K、Amazon 5-Elect 和Retailrocket 这3 个数据集上进行消融实验,验证有无注意力机制对模型的影响,以及用户兴趣聚合部分使用GRU 和双向GRU 给模型带来的差异。实验结果如图8 所示,其中:No-Attention 代表无注意力机制;Bi-GRU 表示双向GRU。

图8 在3 个数据集上模型消融结果对比Fig.8 Comparison of model ablation results on three datasets
根据上述实验结果可以看出:
1)在无注意力机制时模型的效果下降明显,这表明使用注意力机制可有效地捕获用户兴趣的动态变化,在不使用注意力机制进行GRU 更新门的更新时,GRU 只能学习到用户静态的兴趣表示,进而模型的效果有所下降。
2)在使用双向GRU 后,并未给模型效果带来明显的提升,这是因为双向GRU 较单向GRU 更复杂,参数量的增多导致模型拟合不够充分。
3)通过对比在3 个数据集上的NDCG@K性能指标可以看出,模型在使用注意力机制后效果更好。同时,为降低模型的训练难度,本文并未采用双向GRU。
3.6 参数对模型的影响
学习率和隐藏层的维度对实验结果产生一定的影响,尤其是隐藏层维度(即嵌入向量的维度)限制了模型的表达能力,理论上嵌入向量的维度越大,所蕴含的信息越多,模型的效果越好。但实验结果表明,较高的维度会导致模型效果有所下降。在ML100K 数据集上的实验结果如图9 所示。

图9 学习率及隐藏层维度对模型性能的影响Fig.9 The influence of learning rate and hidden layer dimension on model performance
由实验结果可知:当隐藏层的维度较大时,模型的效果出现下降,在本文所选隐藏层的维度中,维度为64 时效果最好;当隐藏层的维度下降时,在ML100K 数据集上,模型效果下降最为明显;当模型隐藏层的维度较大时,训练所需要的参数增多,模型训练所需的计算资源增多,训练周期变长,模型的过拟合风险增大。
4 结束语
在序列推荐问题中,现有多数方法只使用了用户交互序列中的物品信息,而忽略了相似物品会在交互序列中相继出现这一重要特征,并且用户兴趣是动态变化的。针对以上问题,本文提出一种利用门控线性网络构建用户动态兴趣的推荐模型DCGN。基于门控线性网络细粒度建模用户的兴趣表示,使用注意力机制动态构建用户的兴趣表示。通过双线性特征交叉方法对项目之间的共现模式进行建模,从而使模型的泛化能力得到显著提升。后续将针对用户的长期兴趣和短期兴趣分别进行建模,以明确用户的长短期兴趣对于推荐效果的影响。此外,用户的长短期兴趣对于推荐用户未来交互项目的影响是不同的,因此,还将对两者的差异进行研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
