
基于RoBERTa‐WWM 的大学生论坛情感分析模型
2022-08-12 02:30:26王曙燕
计算机工程 2022年8期
王曙燕,原 柯
(西安邮电大学 计算机学院,西安 710121)
0 概述
大学生论坛不仅是大学生获取知识信息的来源之一,也是大学生表达情绪的平台。大学生通过学生论坛表达出带有情感倾向性的语句,其中有正面积极的语句,也有一些负面消极的语句。研究人员利用深度学习对这些语句进行情感分析,以便于高校管理者掌握大学生的情感状况,并对近期情绪异常的学生进行开导。
近年来,对于情感分析的研究已经取得较大进展。对文本进行情感分析的方法主要分为基于情感词典的方法、基于传统机器学习的方法和基于深度学习的方法。基于情感词典的方法是根据现有的情感词典,按照语义规则计算句子的情感值,获得句子的情感倾向[1]。这种方法比较依赖于情感词典,无法有效地识别论坛新兴的词语。基于传统机器学习的方法主要有支持向量机(Support Vector Machine,SVM)[2]、朴素贝叶斯(Naive Bayesian,NB)等,现有的有监督学习方法常依赖于复杂的特征工程。文献[3]使用隐马尔科夫模型和支持向量机将情感分析任务转化为标签序列学习问题,在微博情感分析问题中融入上下文语境,改进分类效果。文献[4]利用隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)分析与COVID-19 相关的Twitter信息中突出的主题和情感。基于深度学习的方法是目前主流的情感分析方法,通过深度学习对语句进行情感分析,以抽象特征,从而减少人工提取特征的工作,并且能够模拟词与词之间的联系,具有局部特征抽象化和记忆功能。文献[5]整合现有的情感词语资源来构建一个情绪知识库,根据深度学习算法与情绪知识库提出一种融合情绪知识的案件微博评论情绪分类方法,称为EK-INIT-CNN。文献[6]通过注意力机制关注文本中的关键情感信息,利用卷积神经网络(Convolutional Neural Network,CNN)提取局部语义特征,能够更好地处理转折与复杂句式。文献[7]构建基于多通道双向长短期记忆(Long Short-Term Memory,LSTM)的情感分析模型,对语言知识和情感资源进行建模,以生成不同的特征通道,从而充分学习文本中的情感信息。
词向量分为静态词向量和动态词向量。静态词向量模型与查字典类似,每一个词固定对应一个词向量,但是未解决一词多义的问题,例如,独热编码(One-Hot)、Word2Vec 模型[8]、GloVe 模型[9]等。动态词向量模型根据一个词在不同语句中的上下文关系生成不同的词向量,例如,在“我要好好学习”和“我对学习没有兴趣”两句话中“学习”的词向量表示不同。目前,主流的动态词向量模型主要有基于双向的LSTM 网络[10]的ELMo模型[11]、基于多层双向Transformer[12]的BERT 模型[13]、知识增强的语义表示ERNIE 模型[14]、对BERT 进行改进的RoBERTa 模型[15]以及使用全词掩码策略(Whole Word Masking,WWM)[16]进行预训练的RoBERTa-WWM模型[17]等。
文本情感分析方法多针对某一领域,例如,与社会时事案件相关的互联网微博舆情案件情感分析[5]、教育领域课程评论的情感分析、社交媒体会话中的讽刺语句检测分析[18]。现有的情感分析方法缺少对大学生论坛领域的研究。大学生在论坛上发表的言论具有口语化表达、新兴网络用语等特点,并且还有其领域特性的词语,例如“挂科”“上岸”“九漏鱼”和“重修”等。
本文提出一种基于RoBERTa-WWM 的大学生论坛情感分析模型。通过RoBERTa-WWM 模型得到句子级的语义特征表示,并将其输入到文本卷积神经网络-双向门控循环单元(TextCNN-BiGRU)网络模型中进行训练,以获取局部与更深层次的语义特征,在此基础上,利用Softmax 分类器进行情感分类。
1 相关工作
1.1 RoBERTa-WWM 模型
RoBERTa-WWM[17]模型是基于BERT[13]模型演变而来。为捕获语句中更深层次的双向关系,BERT 模型以多层双向Transformer[12]编码器作为模型的主要架构,通过注意力机制将句子中任意位置的两个词距离转换成1,并且将掩码语言模型(Mask Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)作为预训练目标。MLM 随机选取输入语句中15%的字段,在每次训练中将选取的token 以80%的概率替换为[MASK],10%的概率替换为随机的单词,剩余10%的概率保持原有单词,这样做的目的是提高模型对句子的特征表示能力和泛化能力。NSP 模型用于判断句子B 是否为句子A 的下文,从而对句子之间的关系进行建模。RoBERTa模型[15]改进BERT模型主要分为3个步骤:1)将静态mask 修改为动态mask,当BERT 模型训练数据时,每个样本只进行一次随机mask,在每次训练时mask 的位置都是相同的,而动态mask 在每次训练前都要动态生成一次mask,使得模型能够学习更多的语句模式;2)移除NSP,提高模型的效率;3)使用更大的数据集进行训练,采用字节对编码(Byte Pair Encoding,BPE)处理文本数据。
WWM[16]改变了预训练阶段中的样本生成策略,根据中文文本的特点,以字为粒度的mask 方法转变为以词为粒度的mask 方法,首先将语句进行分词,如果一个词的部分字段被mask,则将整个词也进行mask。对于语句“为未来点赞,为梦想起航,为自己拼搏!”,原始mask 策略和WWM 策略生成的样例如表1 所示。WWM 策略的mask 方式,能够有效提升中文文本表示的效果。

表1 不同策略生成的样例语句Table 1 Sample sentences generated with different strategies
本文利用RoBERTa-WWM 模型获得句子级的词向量表示,在训练过程中预训练模型的参数根据数据集进行微调。RoBERTa-WWM 模型结合RoBERTa 模型与WWM 的优点,由12 层Transformer组成。RoBERTa-WWM 模型具有3 个特点:1)将预训练阶段的样本生成策略更改为全词掩码策略,但不使用动态mask;2)移除NSP,提升模型效率;3)训练数据集更大,训练步数、训练序列更长。
RoBERTa-WWM 模型结构如图1 所示。模型初始的输入为一条文本语句,用W1,W2,…,Wn表示,将该语句字向量、段向量和位置向量的加和作为模型的输入,用E1,E2,…,En表示,中间层表示12 层双向Transformer 特征提取器,T1,T2,…,Tn为模型的输出向量。
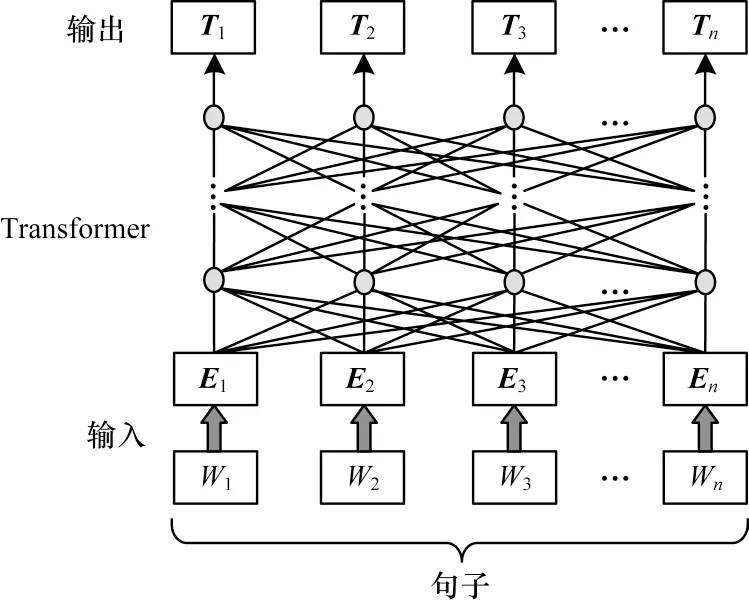
图1 RoBERTa-WWM 模型结构Fig.1 Structure of the RoBERTa-WWM model
1.2 文本卷积神经网络
TextCNN[19]将CNN 应用到文本分类任务中,在短文本领域中训练速度更快且效果更好,因此,适用于大学生论坛领域的情感分类。TextCNN 利用多个不同大小的卷积核提取句子中的关键信息,从而充分捕捉局部相关性,获取更深层次的语义信息。TextCNN 模型结构如图2 所示。

图2 TextCNN 模型结构Fig.2 Structure of TextCNN model
TextCNN 模型主要有嵌入层、卷积层、池化层和输出层。嵌入层使用预训练好的词向量对语句进行表示,每一条评论语句对应一个m×n的矩阵,其中,m表示一条语句的最大长度,n表示词向量的维度。卷积层通过不同的卷积核来提取文本的局部特征,通常采用的卷积核大小为2、3、4、5,使用卷积核进行卷积时,可以获取到词序及其上下文信息。为了保证文本基本语义单元的完整性,文本卷积是一维卷积,只需要沿着词向量矩阵的垂直方向进行卷积。池化层将卷积层输出的特征进行池化操作,以提取更显著的特征,它能够降低输出结果的维度,使不同尺寸的卷积核得到的特征维度相同。输出层将池化后拼接的向量进行全连接后,将其输入到分类器中进行分类。
1.3 双向门控循环单元网络
门控循环单元(Gated Recurrent Unit,GRU)[20]是LSTM 的变体,两者都旨在解决循环神经网络(Recurrent Neural Network,RNN)中存在梯度消失问题。GRU 具有称为门的内部结构,用于调节信息流,保留或者丢弃序列中的数据。GRU 有一个重置门和一个更新门。重置门主要决定需要遗忘多少过去的信息,重置门的值越小,前一状态的信息被写入的越少。更新门用于控制前一时刻的状态信息有多少被带入到当前状态中,即前一时间步和当前时间步的信息有多少是需要继续传递。更新门的值越大说明带入前一时刻的状态信息越多。相比LSTM,GRU 结构较简单,参数也较少,能够有效提高训练的效率。GRU 的单元结构如图3 所示。

图3 GRU 单元结构Fig.3 The unit structure of GRU
从图3 可以看出,xt表示t时刻的输入,zt表示t时刻的重置门,1−表示门控信号权重1,范围为0~1,表示t时刻的候选激活状态,ht表示t时刻的激活状态,ht−1表示t−1 时刻的隐层状态。
在GRU 网络中,状态信息都是从前向后输出的,只能学习当前时刻之前的信息,而不能学习当前时刻之后的信息。在情感分类任务中,当前时刻、前一时刻与后一时刻的状态信息都要产生联系。本文采用双向门控循环单元(BiGRU)代替GRU,可以学习到一个词的上下文语义信息。BiGRU 是由两个单向、方向相反的GRU 组成神经网络模型,输出由两个GRU 的状态信息共同决定。BiGRU 网络结构如图4所示。

图4 BiGRU 网络结构Fig.4 BiGRU network structure
从图4 可以看出,BiGRU 网络当前的隐层状态是由当前的输入xt、t−1 时刻向前隐层状态的输出和t+1 时刻反向的隐层状态输出这3 个部分共同决定。
2 本文模型
本文提出基于RoBERTa-WWM 的大学生论坛情感分析模型。通过RoBERTa-WWM 模型得到数据集中句子级的语义特征表示,将获取到的特征表示输入到TextCNN 中以获得更深层次的语句特征,然后将拼接和池化后的TextCNN 输出向量输入到BiGRU 网络中获得全面的上下文信息,最终使用Softmax 分类器进行情感分类。本文模型结构如图5 所示。

图5 本文模型结构Fig.5 Structure of the proposed model
2.1 嵌入向量表示层
嵌入向量表示层是将文本语句转化为神经网络模型以识别二维向量。传统的词嵌入方法有Word2Vec[8]、GloVe[9]等,这些方法为每个词提供一个固定的向量表示,但是无法解决一词多义的问题,而RoBERTa-WWM模型根据一个词上下文语境的不同,为每条语句提供一个句子级的特征向量表示。
对于一条语句S={x1,x2,…,xm},本文构建语句S的字向量、段向量和位置向量,将这3 个向量的加和作为RoBERTa-WWM 模型的输入,得到字级别的词向量集合T={t1,t2,…,tm},最终将词向量进行拼接,得到语句S的词嵌入矩阵Rm×n。拼接方式如式(1)所示:

其中:⊕表示行向量拼接运算符;m表示单个语句的最大长度,由于大学生论坛语句多为短文本,因此本文设置m为100;n表示词向量的维度,因为RoBERTa-WWM模型的词向量维度为768,所以n的值为768。
2.2 语义信息获取层
在上一层获取到句子级词嵌入矩阵的基础上,语义信息获取层用于获取更深层次的语义信息和上下文信息。对于词嵌入矩阵,利用TextCNN 进行一维卷积操作,提取文本多类型的局部特征,将卷积后的结果输入到BiGRU 网络,对文本进行正反双向处理,用于获取更全面的上下文信息。
对于TextCNN,为了能有效提取更深层次的特征,本文设置3 种不同大小的卷积核,分别为3、4、5,每种卷积核都设置256 个,并且将填充值设置为same,保证卷积输出向量的维度一致。池化层采用最大值池化,将卷积层输出的特征进行池化操作来提取更显著的特征,并将池化后的特征向量进行拼接操作。本文将pool_size 设置为4,为防止模型过拟合,加入Dropout 层随机忽略掉一定数量的神经元,将随机忽略概率设置为0.5。
GRU 可以捕获长距离的语义信息,但是传统的GRU 只能获取正向的语义信息。本文利用BiGRU网络同时对语句进行正反两个方向处理,用于获取语句全面的上下文信息,BiGRU 网络的输入维度与TextCNN 层的输出维度一致。本文设置GRU 的单元数为128 个,最终将BiGRU 网络的输出进行全连接操作。
2.3 情感计算层
情感计算层将语义信息获取层输出的特征向量通过Softmax 分类器计算语句S在情感标签中的概率向量O=[o1,o2,o3],选择最大值所代表的情感标签作为最终输出的情感标签。Softmax 分类器将输入向量的第i项转化为概率Pi,如式(2)所示:

其中:K为情感标签的数目。本文采用神经网络反向传播机制更新模型参数,损失函数采用交叉熵loss,在训练过程中,将交叉熵最小化,计算过程如式(3)所示:

其中:D为训练集大小;K为情感标签数量;y为真实的情感类别为预测的情感类别。
3 实验与结果分析
3.1 实验数据集
本文通过爬虫技术获取某大学学生论坛9 112 条评论数据,分别标注为负面消极型、客观中立型和积极乐观型3 种情感类别,构建大学生论坛情感分析数据集。每条评论数据有标签、内容、发布人和发布时间4 种属性,以便于之后的应用与分析,并在该数据集上设置多组对比实验。
大学生论坛数据集通过百度贴吧平台某大学贴吧获取得到,经过筛选与处理后,构建含有9 112 条学生论坛评论语句的数据集,采用3 种情感标签进行标注,0 代表负面消极型,1 代表客观中立型,2 代表积极乐观型。负面消极型评论共有1 355 条,客观中立型评论共有6 325 条,积极乐观型评论共有1 432 条。负面消极型评论包括对学习和生活上的消极言论,或者对他人的憎恨与谩骂等;客观中立型评论包括对一些事物的客观评价,或者不带个人感情的叙述等;积极乐观型评论包括对事物积极乐观的看法、描述自己的喜悦,或者对他人的鼓励和正面的建议等。大学生论坛数据集样例如表2 所示。

表2 大学生论坛数据集样例Table 2 Samples of college student forum dataset
本文按照近似8∶2 将实验数据集分为训练集和测试集,训练集共7 289 条评论,测试集共1 823 条评论。大学生论坛数据集分布如表3 所示。

表3 大学生论坛数据集分布Table 3 Distribution of college student forum dataset
为验证本文模型在情感分析公共数据集上的有效性,本文使用的公共实验数据集是NLPCC2014数据集。NLPCC2014 数据集分为训练集和测试集,包括none、happiness、like、anger、sadness、fear、disgust 和surprise 8 种情感标签。为了与对比实验一致,本文去除了none标签的数据,在剩余数据集中训练集共7 407 条评论,测试集共2 394条评论。NLPCC2014数据集分布如表4所示。
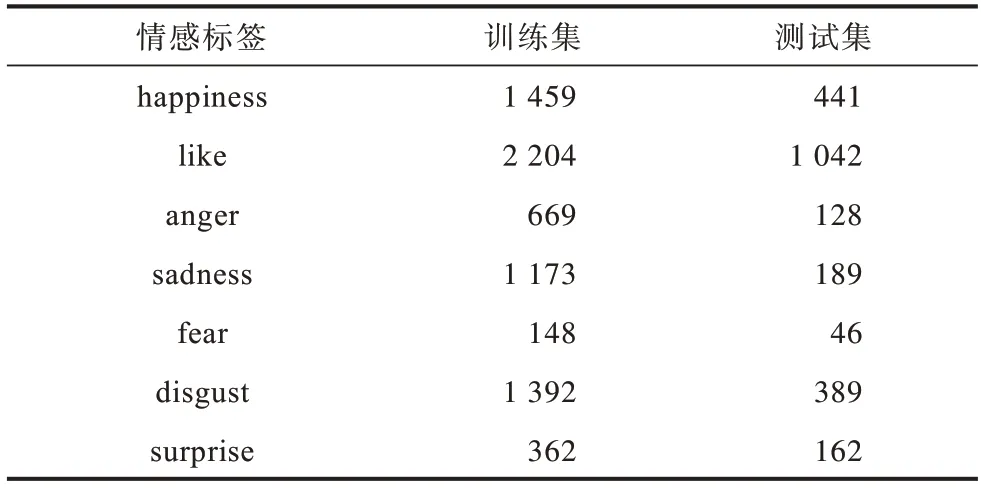
表4 NLPCC2014 数据集分布Table 4 Distribution of NLPCC2014 dataset
3.2 对比模型
本文选取5 种模型与本文所提的RTB 模型进行对比,这5 种对比模型主要是:1)TextCNN 模型[19],将卷积神经网络应用到文本分类任务中,通过Word2Vec 模型[8]生成每个词对应的词向量,并将其输入到多个不同窗口大小的卷积核中,以实现情感分 类;2)BiLSTM 模 型[21],由前向 和后向 的两个LSTM 组合而成,获取文本全面的上下文信息,从而进行文本分类;3)TextCNN-BiGRU 模型[22],是一种将BiGRU 的语义特征提取能力与TextCNN 的深层特征提取能力相结合的模型,采用Word2Vec 模型作为词嵌入层;4)BERT 模型[13],Google 在2018 年提出的一种预训练模型,将多层Transformer 作为模型的主要架构,提取BERT 中文预训练模型的动态词向量直接进行情感分类;5)RoBERTa-WWM 模型[17],该模型结合RoBERTa[15]和BERT-WWM[16]的优点,在RoBERTa 模型的基础上,将预训练样本生成策略修改为WWM,并将该模型作为本文的基准模型。
3.3 实验参数设置
本文经过多次对比实验后,选取参数的最优值用于其他所有实验。本文实验的可调参数设置如表5所示。

表5 本文实验的参数设置Table 5 Parameters setting of the proposed experiment
3.4 结果分析
3.4.1 大学生论坛数据集实验结果
在大学生论坛数据集上不同模型的评价指标对比如表6 所示。由于数据集0 类(负面消极型)和2 类(正面积极型)的样本相对较少,1 类(客观中立型)的样本相对较多,因此模型需要更加关注带有情感语句的分类效果。本文采用宏平均精准率(Macro_P)、宏平均召回率(Macro_R)、宏平均F1 值(Macro_F1)以及微平均F1 值(Micro_F1)作为评价指标。

表6 在大学生论坛数据集上不同模型的评价指标对比Table 6 Evaluation indexs comparison among different models on college student forum dataset %
从表6 可以看出,本文RTB 模型在大学生论坛数据集上的各项评价指标均以Word2Vec 作为词嵌入层的TextCNN 模型、BiLSTM 模型与TextCNN-BiGRU 模型的评价指标均较低,与BERT 模型相比还有较大的差距。在TextCNN 模型、BiLSTM 与TextCNN-BiGRU模型中,Macro_F1与Micro_F1之间差值约6个百分点,说明模型对于样本数量较少的0 类和2 类的分类效果相对较差。本文模型相对于TextCNN-BiGRU 模型的Macro_P、Macro_R、Macro_F1 和Micro_F1 分别提升7.29、12.57、10.28 和6.70 个百分点。相比BERT 模型,本文模型的评价指标分别提升了3.59、2.08、2.77 和1.44 个百分点。本文使用TextCNN-BiGRU 模型获取更深层次的语义信息,相比RoBERTa-WWM 模型,本文模型的各项指标分别提升了2.16、1.15、1.61和0.75个百分点,说明加入TextCNN-BiGRU 模型进行训练,能够更好地学习语义特征。
3.4.2 NLPCC2014 数据集实验结果
在NLPCC2014 数据集上不同模型的评价指标对比如表7 所示。本文以宏平均F1 值(Macro_F1)和微平均F1 值(Micro_F1)作为实验的评价指标。对比模型是EMCNN[23]、DAM[24]与EK-INIT-CNN[5]。EMCNN 模型利用表情符号生成的特征矩阵对语句进行语义增强,改进分类效果。DAM 模型在BiLSTM 的基础上引入双重注意力机制与情感符号,增强对语义的捕获能力。EK-INIT-CNN 模型使用情绪知识表示,通过INIT-CNN 和注意力机制生成情绪知识和语义特征矩阵,将情绪知识特征与语义特征相融合,在NLPCC2014 数据集上取得较好的分类效果。
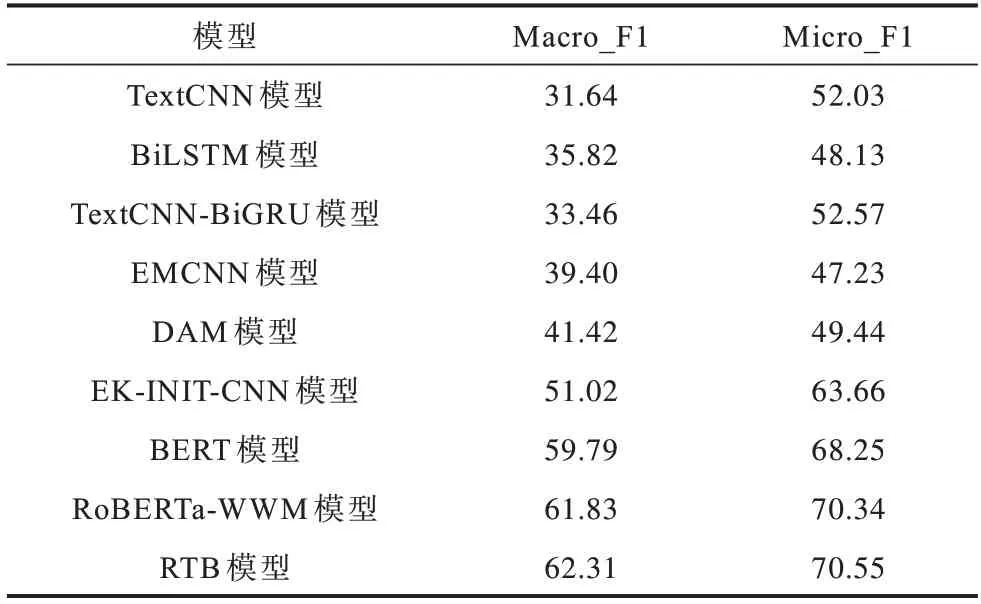
表7 在NLPCC2014 数据集上不同模型的评价指标对比Table 7 Evaluation indexs comparison among different models on NLPCC2014 dataset %
从表7 可以看出,相比其他模型,本文模型的Macro_F1 和Micro_F1 具有较高的评价指标。对于TextCNN 和TextCNN-BiGRU 模型,同一模型的Macro_F1 和Micro_F1 值之间差值约20 个百分点,其原因为数据集中的fear 标签数据量太少,没有被预测出来,导致该标签的各项指标都为0。BiLSTM模型将每个标签都预测出来,但综合指标不是很高。相比TextCNN、BiLSTM 模型,TextCNN-BiGRU 模型的综合指标相对较高。相比以上3 个基准模型,EMCNN 和DAM 模型的Macro_F1 指标都有了较大的提升。EK-INIT-CNN 模型将微博情绪知识库融合到了微博语句中,效果有了很大的提升。BERT 和RoBERTa-WWM 模型在海量语料上对语句进行了更好的向量表示,有效提升了分类效果。本文模型在RoBERTa-WWM 模型的基础上,结合深度基准模型学习更深层次的语义特征,对比TextCNN-BiGRU模型,本文模型的Macro_F1 和Micro_F1 值分别提升28.85 和17.98 个百分点。相比DAM 模型,本文模型的指标分别提升了20.89 和21.11 个百分点。相比EK-INIT-CNN 模型,本文模型的指标分别提升11.29和6.89 个百分点。对比BERT 和RoBERTa-WWM 模型,本文模型分别提升了2.52、2.30 和0.48、0.21 个百分点。因此,本文模型具有较优的分类效果。
3.4.3 模型分析与评价
为了评估模型的准确性与价值,本文使用ROC曲线(受试者工作特征曲线)对RTB 模型进行分析,结果如图6 所示。
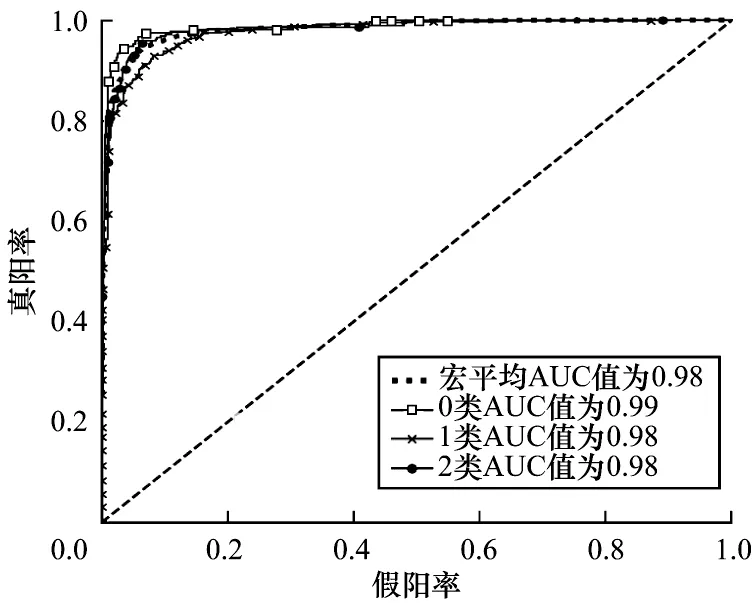
图6 RTB 模型的ROC 曲线Fig.6 ROC curves of RTB model
从图6 可以看出,本文模型的ROC 曲线完全在对角线上方,宏平均AUC 值为0.98,因此,本文模型具有较优的预测能力。对于0 类(负面消极型)标签的分类具有较优的性能,这是由于0 类语句的情感特征较为明显。对于2 类(正面积极型),被预测错误的样本多数被预测为了1 类(客观中立型),原因是缺少明显的情感词语,例如,数据集第8 015 条语句“学习,是生活必需。特别是现代社会,信息化发展很快,学习尤为重要。”被预测为1 类,因其没有提及到情感词语。总之,本文模型用于分析大学生论坛语句具有较优的性能和实用价值。
3.4.4 单个类别分类性能对比
本文将RTB 模型与RoBERTa-WWM 模型在单个类别的分类性能上进行对比,以F1 值作为评价指标,结果如图7 所示。

图7 不同模型的单个类别分类性能对比Fig.7 Each category classification performance comparison among different models
从图7 可以看出,RTB 模型与RoBERTa-WWM模型都在1 类(客观中立型)上具有较优的分类效果,但是在0 类(负面消极型)和2 类(积极正面型)上相对较差。由于1 类的样本数量相对较多,因此模型对1 类语句的语义特征学习较为全面。在0 类和2 类中一些语句的情感特征不是很明显,导致分类错误。相比RoBERTa-WWM 模型,RTB 模型在0 类、1 类 和2 类上的F1 值 分别提高了3.59、0.73 和0.52 个百分点,在0 类的分类效果提升较为明显,说明加入TextCNN-BiGRU 网络能够充分捕获负面消极情感的语义特征。因此,RTB 模型相比RoBERTa-WWM 模型在各类别分类上都具有更优的性能。
4 结束语
本文构建基于RoBERTa-WWM 的大学生论坛情感分析模型。利用RoBERTa-WWM 模型对文本数据进行向量化处理,以解决传统词嵌入层的一词多义问题,同时将文本向量输入到TextCNN-BiGRU 模型进行训练,获取更深层次的语义信息。在大学生论坛与NLPCC2014数据集上的实验验证了本文模型的有效性,结果表明,相比TextCNN、BiLSTM、TextCNN-BiGRU等模型,本文模型能够有效地对大学生论坛语句进行分类。后续将逐渐减少Transformers 层数,分析Transformers 不同层数对分类结果的影响,在不影响模型分类效果的条件下减少模型参数量。此外,通过对语句进行更细粒度的标注,进一步提高模型的泛化能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
电视技术(2014年19期)2014-03-11 15:38:20
语文知识(2014年4期)2014-02-28 21:59:52
