
融合自动权重学习的深度子空间聚类
2022-08-12 02:29:28江雨燕
计算机工程 2022年8期
江雨燕,邵 金,李 平
(1.安徽工业大学 管理科学与工程学院,安徽 马鞍山 243032;2.南京邮电大学 计算机学院,南京 210023)
0 概述
聚类作为一种无监督的学习方法,广泛应用于机器学习[1]、模式识别[2]等技术,其通过将数据划分为多个有意义的簇从而达到分类的目的。例如,在人脸识别中,提取人脸特征后往往以特征点之间的距离为单位来衡量图像的相似度,通过聚类分析将数据分为多个簇,将相似度高的数据划分到同一簇中,从而挖掘数据之间的关系以得到正确的分类结果;在图像分割中,为了更好地区分目标与背景,可以依据图像的灰度、颜色、纹理等特征将其分割成几个区域,通过度量不同区域的灰度值将目标特征划分到同一区域,从而实现图像分割的目的。
常见的聚类方法包括K-means[3]、层次聚类[4]、谱聚类[5]、子空间聚类[6]等。K-means 算法将数据点分配给最近的簇,更新每个簇的中心并重新分配所有数据点以达到聚类的效果,其性能简单且高效,但是对异常点较为敏感。谱聚类是基于图论而演化来的聚类方法,其对数据分布的适应性更强,可以识别非凸分布聚类,但是对输入的相似图十分敏感。子空间聚类是目前处理高维数据最流行的方法之一,常见的子空间聚类算法包括低秩表示(Low Rank Representation,LRR)算法[7]、低秩子空间聚类(Low Rank Subspace Clustering,LRSC)[8]、稀疏子空间聚类(Sparse Subspace Clustering,SSC)[9]、核化稀疏子空间聚类(Kernel Sparse Subspace Clustering,KSSC)[10]。其中,LRR 寻找字典中最低秩的表示以更好地捕获数据结构,该方法在处理损坏数据时可以发挥关键作用;LRSC 提出一个联合优化框架以求得闭合解,其能解决子空间聚类中噪声及误差的问题;SSC 利用稀疏表示方法处理数据,当处理分布在多个子空间上的高维数据时,由于其自表示模型的鲁棒性而受到广泛应用;KSSC是SSC基于核技巧的拓展,使用核技巧可以得到高维空间中的稀疏表示,使得数据线性可分,从而获得更好的聚类结果。上述方法面对高维数据时取得了较好的聚类效果,但是,聚类精确性高度依赖于所学习到的相似图。因此,改变相似图学习方式能否提升聚类性能成为新的研究热点。
为了获得稳定且准确的聚类效果,NIE 等[11]提出一种自适应近邻聚类(Clustering with Adaptive Neighbors,CAN),其设计新的相似图学习方式,直接在数据空间中学习相似图,基于局部距离为每个数据自适应分配近邻,同时学习数据的相似性与聚类结构。此外,针对高维数据的处理问题,该文提出基于自适应近邻聚类的投影(Projected Clustering with Adaptive Neighbors,PCAN)方法,这种新的相似图学习方式取得了优异的效果并在实际场景中得到广泛应用。但是,该方法在学习相似图时未考虑不同特征的重要性。因此,文献[12]提出一种自动权重的自适应近邻聚类(Self-Weighted Clustering with Adaptive Neighbors,SWCAN),其对PCAN 进行改进,通过对每个特征赋予相对应的权重以提升聚类性能。
上述方法均通过CAN 独特的相似图学习方式获得了良好的聚类效果,然而,它们依然存在以下问题需要解决:在处理高维非线性数据时,最优核函数的选择依然存在困难;为数据分配近邻的方式考虑到了全局数据结构但未兼顾局部数据结构。
近年来,在无监督聚类任务中,随着深度学习技术的发展[13],自编码器的应用日益广泛。自编码器具有可压缩性,可以学习到原始数据中的重要特征,原始数据由编码层投影到潜在空间获得低维的潜在表示,再由解码层重构数据,通过最小化重构误差保留数据局部结构信息。JI 等[14]提出一种深度子空间聚类网络(Deep Subspace Clustering Network,DSC-Net),其在编码层与解码层之间加入自表示层,以模仿子空间聚类中的自表示。XIE 等[15]提出无监督深度嵌入聚类(Deep Embedded Clustering,DEC),其通过软分配方法学习数据类别,使用深度网络同时学习数据表示与聚类。LI等[16]提出基于自编码器的自适应近邻聚类,其通过引入自编码器自适应地学习数据的非线性结构,同时更新潜在表示及相似图。文献[17]改进DSC-Net的自表达层,使之由参数化的全连接层变为一个无需参数的闭合解。上述算法利用自编码器的特性能够保留局部数据结构,但是它们认为所有特征的重要性都一致且未考虑数据的全局结构。基于以上分析,为了处理高维非线性数据同时提升聚类准确性及算法泛化能力,在聚类过程中必须兼顾全局与局部数据结构,并根据不同特征、不同重要性来对深度聚类方法进行设计与验证。
本文提出融合自动权重学习与结构化信息的深度子空间聚类(Deep Subspace Clustering Fused with Auto-Weight Learning and Structured Information,DSC-AWSI)算法。对自编码器进行预训练与微调,利用自编码器将原始数据投影到非线性潜在空间以学习数据的潜在表示,根据特征重要性的不同自适应地赋予各特征权重,从而学习相似图并完成聚类。
1 相关工作
1.1 自适应近邻聚类
假设数据矩阵X={x1,x2,…,xn}∊Rn×d,其中,n表示样本数量,d表示维度。每列数据点xi的近邻可以被定义为k-nearest 个数据点,将欧氏距离作为距离度量单位。所有与xi相近的数据点都有一个对应的近邻概率aij,若较小,则对应的aij往往较大,其目标函数如下:

其中:ai∊Rn×1是一个向量;1是所有元素均为1 的向量。式(1)有平凡解,即当概率为1 时其他数据点无法被分配为xi的近邻。为解决该问题,加入正则约束,如式(2)所示:

其中:γ为正则化参数=1;L为拉普拉斯矩阵,表示块对角的相似图;DA为相似图A的度矩阵(对角矩阵),对其添加低秩约束Rank(L)=n-c,n为样本数量,c为类别数量,为了以清晰的结构实现理想的近邻分配,连接分量必须是准确的c值。对于每一个数据点xi,均可以通过式(2)为其分配近邻。为了实现理想的近邻分配使之成为自适应的分配过程,概率应该被施加约束,目的是无需使用K-means 或其他离散方法也能使连接元素被划分为c个类别。
1.2 自编码器
自编码器通过其编码器与解码器的特性,在无监督的场景下可以将原始数据非线性地投影到一个潜在空间,该过程是一种非线性降维。自编码器的作用是利用编码层将高维输入数据编码为低维数据,然后提取低维数据的显著特征[18],自编码器本质上可以作为特征提取器,再通过解码层解码将提取到的特征还原到初始维度,从而得到重构数据[19]。假设神经网络具有m+1 层结构,执行m层非线性转化,对每个输入xi都有对应的潜在表示和重构输出,X={x1,x2,…,xn}∊Rn×d为原始输入数据x,则神经网络的计算过程为:i

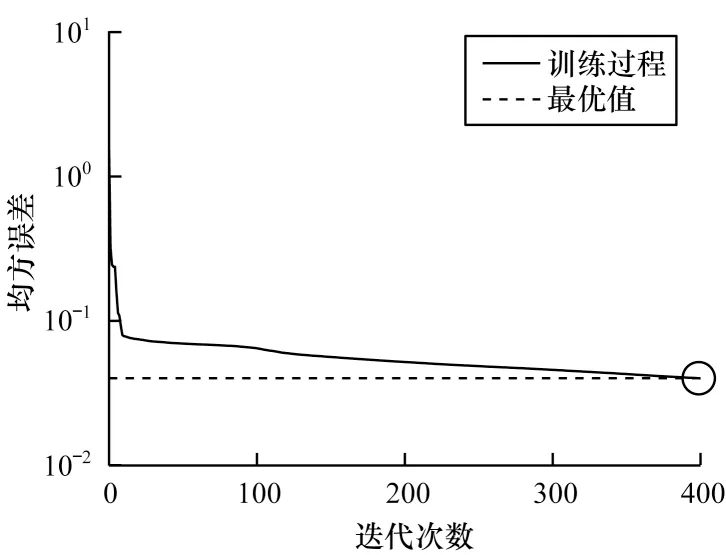
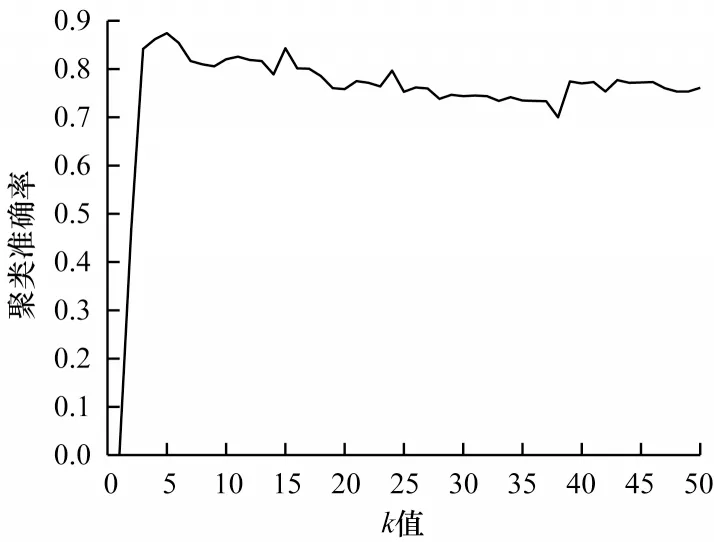
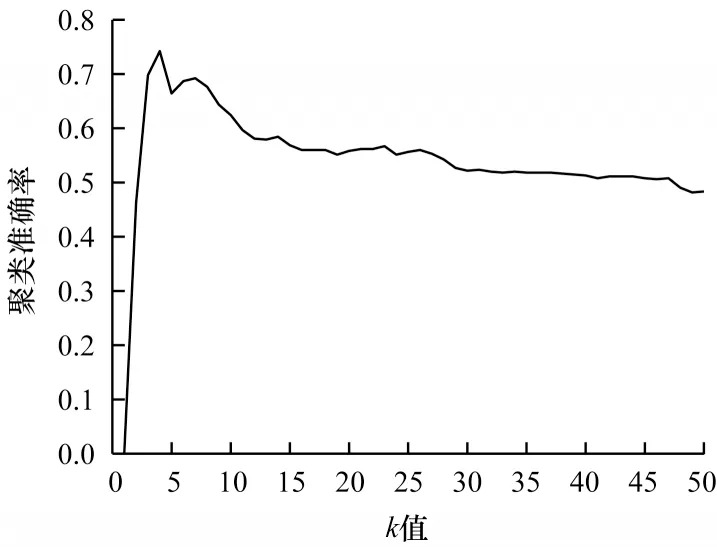
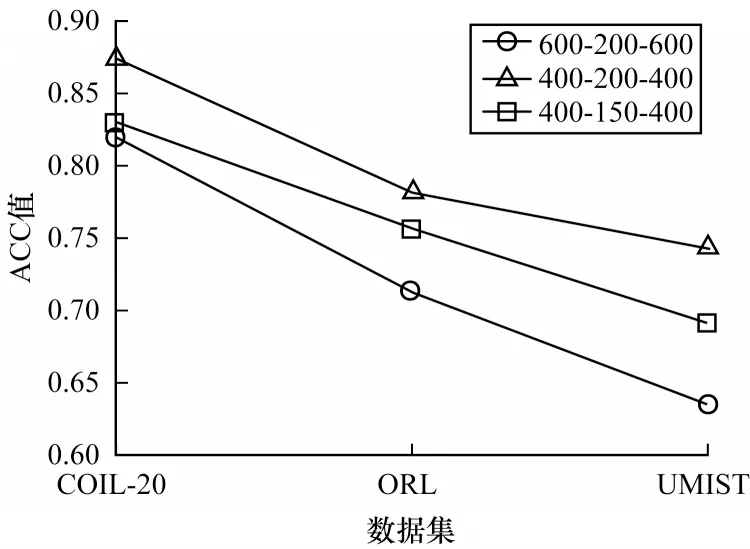
首先,将原始数据映射到潜在空间Z={z1,z2,…,zn}∊Rl×n,其中,l 现有很多聚类方法对大规模数据及噪声敏感,在处理高维数据时往往需要牺牲聚类质量来解决离群样本及大规模扩展问题[20]。为此,一些优秀的特征选择方法被引入到聚类任务中[21-22],该类方法提取感兴趣的特征从而提升聚类效果。本文引入自编码器作为非线性数据处理方法,同时结合文献[12]中的自动权重学习思想,赋予噪声特征较低权重、有效特征较高权重,根据特征不同的重要性来为潜在空间中所学习到的特征赋予不同的权重。本文算法流程如图1 所示。 图1 本文算法流程Fig.1 Procedure of this algorithm 对于所有数据点X={x1,x2,…,xn}∊Rn×d,通过自编码器的编码层将数据转换到潜在空间,得到良好的特征表示Z={z1,z2,…,zn}∊Rl×n。解码层重构数据,表示为则损失函数ℓ1可以表示为: 其中:第一项通过最小化输入与输出之间的重构误差来保留局部数据结构,相比常见的核方法,该自编码器具有更好的显式转换效果及更高的可伸缩性;第二项是正则化项,通过限制神经网络中权重与偏执的大小来避免模型过拟合。 通过编码层转换后,学习到的特征表示为Z={z1,z2,…,zn}∊Rl×n,原始数据得到了更好的低维表征。但是,不同特征的重要性不同,在实际应用中往往没有足够的先验知识来判断各个特征的重要性。为了使模型更具鲁棒性,需要针对有效特征、噪声特征设置不同的权重,即对潜在空间的数据矩阵Z赋予不同的权重,且这种自动学习权重的方式不会改变数据的结构信息。因此,本文受文献[11-12]方法的启示,将式(2)改写为: 其中:c为类别数量:W表示权重矩阵,其为一个对角矩阵,每个wi值对应一个zi特征,不同的特征自适应地学习权重;W=diag(wk),0 ≤wk≤1,k=1,2,…,d。目标函数的第一项是学习自动权重与自适应近邻的过程,根据W赋予特征Z不同的权重,再进行自适应近邻过程,学习相似图并实现聚类;第二项是低秩约束项,拉普拉斯矩阵L是半正定的[23],为了对L施加低秩约束,令σi(L)表 示L的第i个最小特征值,σi(L)≥0,根据Ky Fan’s定理[24]中的进行推导得出,其作用等同于式(2)中的Rank(L)=n-c。 综上,本文算法的损失函数ℓsum=ℓ1+λℓ2,具体计算如下: 其中:δ、λ是非负权衡的参数。式(7)右侧第一项为最小化自编码器输入与输出的重构误差;第二项为正则化项,限制神经网络中的权重和偏置;第三项为聚类损失,在学习相似图A的同时根据特征重要性赋予不同的权重wi,A必须为块对角结构,F的最优解是由拉普拉斯矩阵L的c个特征向量对应的最小的c个特征值而构成的。通过本文模型将原始数据投影到低维潜在空间,学习到的特征表示能够兼顾全局与局部的数据结构,同时为不同的特征赋予相对应的权重,从而指导后续聚类工作。 2.2.1P,b更新子问题 其中:g′(·)为激活函数g(·)的导数,g′(x)=tanh′(x)=1-tanh2(x);⊙表示逐元素相乘。 在执行算法前先对所设计的神经网络进行预训练与微调,从而得到初始化的P(m)、b(m)。根据式(8)、式(9),利用随机梯度下降(Stochastic Gradient Descent,SGD)法迭代更新如下: 其中:η表示学习率。 2.2.2W更新子问题 固定ℓsum中的其他变量,除去无关项,对W更新如下: s.t.WT1=1,0≤wk≤1,k=1,2,…,d,W=diag(w)(13) 定理1假设L为相似图A的拉普拉斯矩阵,矩阵Q∊Rn×c的第i行表示为则有: 根据定理1[12],假设qi=Wzi∊Rd×1,即Q=WZ,则有: 再考虑约束WT1=1,式(17)的拉格朗日函数可以写为: 对拉格朗日函数求导并令其等于0,有: 将约束WT1=1 代入式(19)中,则有: 结合式(19)与式(20),对于wi的更新如下: 2.2.3A更新子问题 固定ℓsum中的其他变量,除去无关项,假设∊R1×c表示矩阵F∊Rn×c的第i行,根据定理1,对A更新如下: 由于式(22)在每个i之间是独立的,因此可以对其进行简化以独立解决每个i的A更新问题,如下: 对式(24)使用交替迭代的方法进行更新,其拉格朗日函数如下: 其中:α、β≥0均为拉格朗日乘子。根据KKT 条件[25],可推导出: 其中:(·)+表示max(·,0)。若ai仅有k个非零元素,可推出aik>0,ai,k+1=0。根据文献[11]可知,参数γi的取值可以控制数据点的k个近邻数量。在拥有k近邻数据下,学习一个稀疏的相似图A有助于减少后续的计算成本。为了不失一般性,假设∀i,,ai有k个近邻,则有: 将式(27)与式(28)相结合,可得: 为了获得具有k个非零值的ai的优化解,令: 考虑到γ=[γ1,γ2,…,γn],此处假设γi=γ,对γ的求解则可转化为对每个γi相加求均值,如下: 根据式(26)与式(31)可推导出ai中第j个元素的闭合解为: 特别地,当j 2.2.4F更新子问题 固定ℓsum中的其他变量,除去无关项,F更新子问题如下: 根据Ky Fan’s 定理[24],最优解F由拉普拉斯矩阵L的c个特征向量所对应的c个最小的特征值构建。由于算法需要设计准确的c值,因此最优解F可以直接用于聚类任务,无需K-means 或者其他离散方法。 基于上述分析,本文DSC-AWSI 算法描述具体如算法1 所示。 算法1DSC-AWSI 算法 本文所提模型设定的隐藏层数M=2,模型包含神经网络反向传播训练及聚类过程,聚类优化过程分为3 个子问题,A更新子问题的复杂度为O(nd2+n2d),F更新子问题的复杂度为O(n3),W更新子问题的复杂度为O(n2d),聚类过程的总复杂度为O(n3+ndmax(n,d))。假设自编码器中隐藏层的维度最大值为D,则算法的总复杂度为O(n3+ndmax(n,d)+nD2)。 为了验证本文算法的有效性,使用较为常见的几种聚类算法在多种数据集上进行实验测试,并选取10次实验的平均值作为结果。实验环境为AMD Ryzen 2600X处理器、16 GB RAM、显卡配置GeForce GTX 1660ti,在Windows 10 系统上进行实验。 在ORL、COIL-20、UMIST 这3 个数据集上进行实验测试: 1)ORL 数据集中包含40 个人在不同的光照、时间和表情下的400 幅面部图像。 2)COIL-20 数据集包含20 个物体在不同旋转角度下的图像,每个物体有72 幅图像。 3)UMIST 数据集包含20 个人的575 幅图像,每个人具有不同角度、不同姿态的多幅图像。 上述数据集中的图像都为32×32 像素,数据集具体描述如表1 所示。 表1 实验数据集信息Table 1 Experimental datasets information 在实验过程中,自编码器的隐藏层数M=2,隐藏层维度设置为400维-200维-400维(以下简写为400-200-400),类别数目c根据数据集设置不同值,近邻数目k在(2,50)区间内取值,从而观察不同k值下算法的聚类性能(由于k为近邻数目,值为0 或1 均不合理)。设置γ=-1,μ为拉普拉斯矩阵约束参数,为了加速收敛过程,令μ=γ,在每次迭代中,若相似图A的连通分量远小于c,则增大μ,反之则减小μ。学习率η设置为η=2-12,δ设置为固定值10-3,根据不同数据集,参数λ从{5×10-4,10-3,5×10-3,10-2,5×10-2,10-1}中选出最优值。此外,当网络的均方误差损失最小值小于10-3或迭代次数达到400 时,则默认算法收敛。 将本文算法与6 种常见的聚类算法在上述数据集上进行实验,对比算法包括LRR[7]、LRSC[8]、SSC[9]、KSSC[10]、CAN[11]、SWCAN[12]。上述6 种算法均由原作者提供的代码进行实验,为确保公平性,算法具体参数根据原论文设置为最优,在最优参数下进行结果对比。使用常见的聚类指标ACC(Accuracy)、NMI(Normal Mutual Information)来衡量算法的聚类性能,实验结果如表2 所示,最优结果加粗表示。 表2 各算法在3 个数据集上的实验结果对比Table 2 Comparison of experimental results of each algorithm on three datasets 从表2 可以看出,相比子空间聚类算法及自适应近邻聚类算法,本文算法在公开数据集上可以得出更好的聚类效果:在COIL-20 数据集上本文算法的ACC 相比CAN、SWCAN算法提高了6.6 和3.23 个百分点;在ORL 数据集上本文算法的ACC 相比CAN、SWCAN 算法提高了3.51 和1.75 个百分点;在UMIST 数据集上本文算法的ACC、NMI 值相比CAN、SWCAN 平均提高了6.94 和5.12 个百分点,这说明引入自编码器可以在特征选择时更好地保持局部数据结构,验证了深度网络处理高维非线性数据的有效性,同时也体现出自动权重学习通过赋予特征权重的方式能够解决噪声数据问题,使得邻接矩阵能够取得更好的学习效果。但是,本文算法的NMI 值与SWCAN 算法相差较小,原因可能是两者的子空间相似图学习方式相同。在ORL 数据集上,本文算法的NMI 值低于SSC 算法,原因可能是本文算法没有使用数据自表示以及对相似图的分割没有使用谱聚类,这说明了数据自表示方法有利于加强相同簇内数据点之间的联系。 图2~图4 分别表示在不同数据集上根据迭代次数增加的神经网络训练的重构损失变化。从中可以看出,在迭代400 次以后,COIL-20 数据集上的均方误差最低达到0.017 88,ORL数据集上的均方误差最低达到0.060 34,UMIST 数据集上的均方误差最低达到0.039 986,即随着迭代次数的增加,通过深度网络训练的重构误差逐渐减小,表明在影响(误差)较小的情况下能够通过深度网络保留数据局部结构。 图2 深度网络在COIL-20 数据集上的均方误差Fig.2 Mean square error of depth network on COIL-20 dataset 图3 深度网络在ORL 数据集上的均方误差Fig.3 Mean square error of depth network on ORL dataset 图4 深度网络在UMIST 数据集上的均方误差Fig.4 Mean square error of depth network on UMIST dataset 由于特征权值有部分是稀疏的,因此在某些维度上判别性较低。图5~图7 给出不同数据集下学习到的各个特征的不同权重,图中横坐标为200 维特征,纵坐标为权重。根据学习到的特征权重值可以区分有效特征、噪声特征、无用特征,因此,自动学习权重的方式可以学习判别性低的特征,从而有效指导后续的聚类工作。 图5 在COIL-20 数据集上学习到的特征权重Fig.5 Feature weights learned on COIL-20 dataset 图6 在ORL 数据集上学习到的特征权重Fig.6 Feature weights learned on ORL dataset 图7 在UMIST 数据集上学习到的特征权重Fig.7 Feature weights learned on UMIST dataset 本文相似图学习方法与CAN、SWCAN 算法相同,近邻数k值在很大程度上影响了聚类准确率,为了测试k值变化对算法性能的影响,将k的取值区间设置为(2,50)以显示不同的聚类结果。通过图8~图10 可以看出,在COIL-20 数据集上,当k=5时聚类准确率达到最优,在ORL 数据集上,当k=3时聚类准确率达到最优,在UMIST 数据集上,当k=4 时聚类准确率达到最优。从中可知,k值对于聚类效果较为敏感,通过对k值进行调整能够提升算法性能。 图8 在COIL-20 数据集上不同k 值的聚类结果Fig.8 Clustering results of different k values on COIL-20 dataset 图9 在ORL 数据集上不同k 值的聚类结果Fig.9 Clustering results of different k values on ORL dataset 图10 在UMIST 数据集上不同k 值的聚类结果Fig.10 Clustering results of different k values on UMIST dataset 为了研究深度网络中隐藏层的大小对算法性能的影响,分别使用600-200-600、400-200-400、400-150-400这3 种不同维度的隐藏层进行实验,结果如图11、图12所示。从中可以看出,当隐藏层的维度设置为400-150-400 时,算法的ACC 与NMI 值均低于400-200-400,但均高于600-200-600;当隐藏层的维度设置为600-200-600 时,3 个数据集下算法的ACC 与NMI值均低于其他2 种情况。因此,深度网络的隐藏层维度设置为400-200-400 时最优。 图11 不同网络层数对算法ACC 值的影响Fig.11 Influence of different network layers on ACC value of algorithm 图12 不同网络层数对算法NMI 值的影响Fig.12 Influence of different network layers on NMI value of algorithm 近年来,子空间聚类由于其计算效率高、易处理等特性而得到广泛研究与应用,然而,子空间学习方式在对高维非线性数据进行聚类时难以很好地捕获局部数据结构。因此,本文提出一种融合自动权重学习的深度聚类算法,通过端到端的学习方式,引入自编码器将特征投影到潜在空间并进行降维,从而实现子空间聚类。该算法能够兼顾全局数据结构与局部数据结构,并通过自适应学习特征权重的方式赋予潜在空间特征不同的权重,其中,赋予有效特征更高的权重,赋予噪声特征更低的权重,以此获得更好的聚类效果。在公开数据集上进行对比实验,结果表明,该算法的聚类效果优于LRR、LRSC、SSC 等算法。下一步将在深度网络设计中加入生成对抗网络,以更精确地判别所学习到的特征,提升算法的聚类性能。2 模型与优化
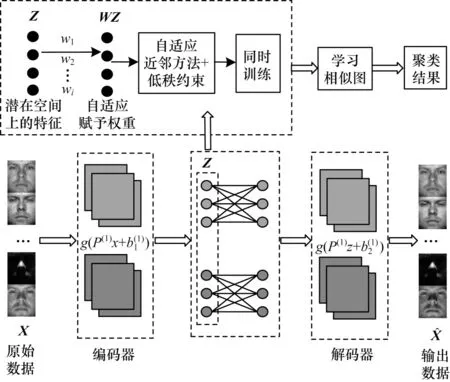
2.1 深度聚类模型


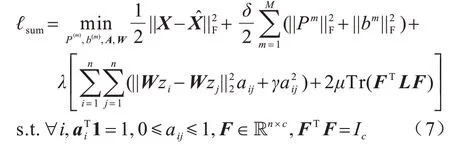
2.2 算法优化


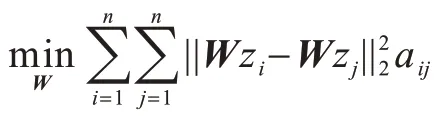



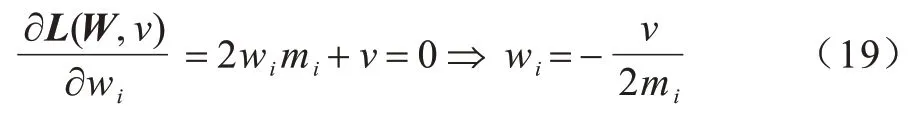


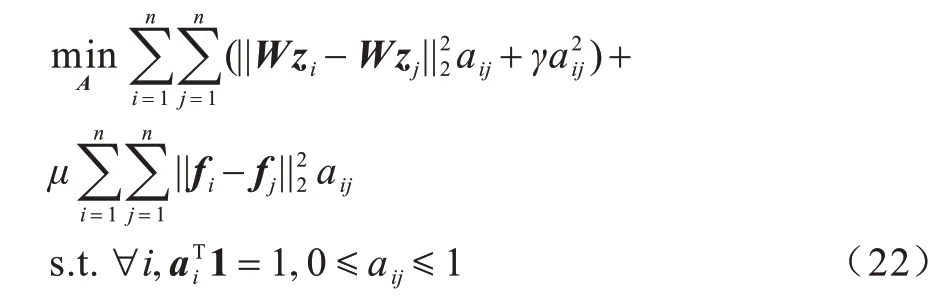

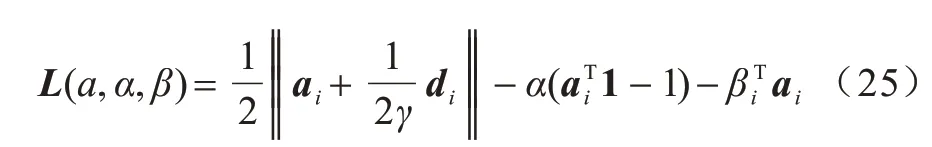

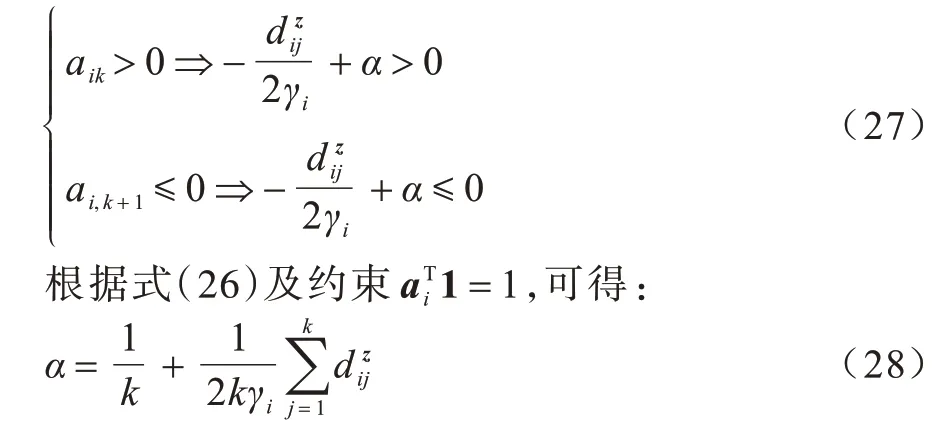



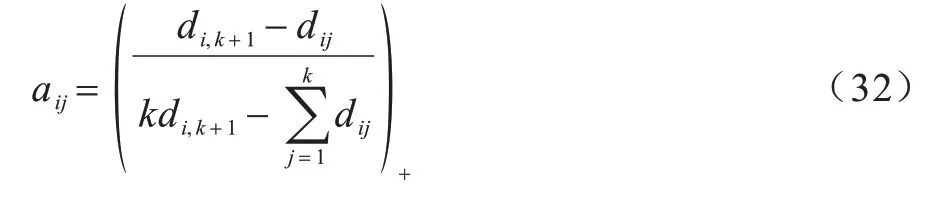
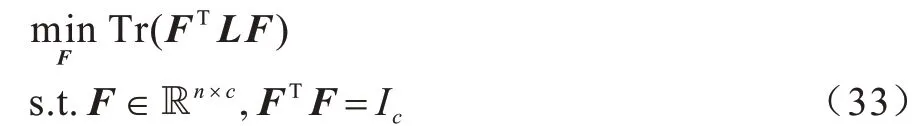


2.3 复杂度分析
3 实验结果与分析
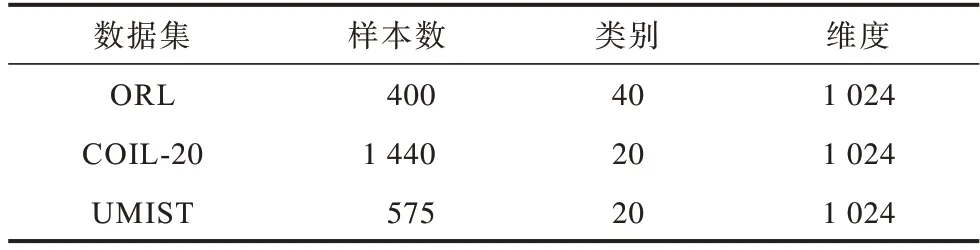
3.1 实验设置
3.2 结果分析








4 结束语
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
数学物理学报(2017年5期)2017-11-23 07:51:31
电子设计工程(2017年20期)2017-02-10 03:39:29
广东技术师范大学学报(2016年5期)2016-08-22 09:07:32
中国市场(2016年45期)2016-05-17 05:15:48
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
上海理工大学学报(社会科学版)(2014年2期)2014-02-28 14:42:19
