
基于多模态模式迁移的知识图谱实体配图
2022-08-12 02:29蒋雪瑶力维辰刘井平李直旭肖仰华
计算机工程 2022年8期
蒋雪瑶,力维辰,刘井平,李直旭,肖仰华
(1.复旦大学 软件学院,上海 200433;2.华东理工大学 信息科学与工程学院,上海 200237)
0 概述
知识图谱是辅助计算机理解实体背景知识的一种重要方式,目前仍以纯符号化的方式表达。随着知识工程与多模态学习交叉研究的开展[1-3],研究者开始寻求更多的数据模态来丰富和完善知识的表达方式,因此,多模态化成为知识图谱发展的主流趋势之一。当知识图谱中的知识表示包含一种以上模态的数据时,称之为多模态知识图谱。当前,以图文表示为主的多模态知识图谱构建是该领域的研究热点[4-6],其核心任务在于为图谱中的实体、概念、关系等符号知识匹配合适的图像,这也是符号接地的一种方式[7]。
现有的实体配图方法可根据图像的数据来源大致分为百科图谱和搜索引擎两大类。在主流的百科知识图谱中,实体的信息页面都会加入一些图像辅助说明,这为实体配图任务提供了非常充足的图像资源,一些百科图谱的构建组甚至整理开放了针对这些图像的检索工具,如Wikipedia[8]提供了Wikimedia Commons[9],在IMGpedia[10]、VisualSem[11]、Richpedia[12]等常见的多模态知识图谱中都用到了百科图片。目前的搜索引擎大部分都提供了针对图像的搜索功能,利用网页中图像上下文中的文本信息,以及用户的点击行为为当前的检索关键字 返回相关图 像[13],如ImageGraph[14]、MMKG[15]、TinyImage[16]、NEIL[17]等都选择图像搜索引擎作为候选图像的来源。
虽然多模态知识图谱的构建在实体配图方面已经取得了一定的成果,但现有方法对图像数据源的应用方式简单粗暴,没有准确把握图像数据来源的特点,并且忽略了实体本身的图像表现规律:实体的图像表现在类内有相似性,而在类间有较大差异性,例如,同属于“人物”这一类别的概念通常都会用人物的“肖像”来表达该实体,而其他诸如“电影”“岛屿”等类别则一般不使用“肖像”来表达实体。
本文根据百科图谱和搜索引擎这两类图像源的特点,提出一种基于多模态模式迁移的知识图谱实体配图方法。借助百科图谱准确的人工标注图像及标题信息,为同类实体从中抽取常见的语义模板和视觉模式。将语义模板应用于构建更精准的检索关键词,为同类的非头部实体从图像搜索引擎中获取更准确的候选图像。在此基础上,利用抽取到的视觉模式对获得的候选图像进行筛选,进一步提高配图准确性。
1 相关工作
目前,多模态知识图谱实体配图方法可根据采用的图像数据来源分为基于百科图谱的方法和基于图像搜索引擎的方法。基于百科图谱为实体配图的方法有IMGpedia[10]、VisualSem[11]、Richpedia[12]等。其中:IMGpedia 是规模最大的,但该方法只是将DBpedia Commons[9]中提供的图像加以整理,没有进行筛选,图像的最终质量不可控;VisualSem 使用预训练语言模型CLIP[18]作为图文匹配的工具来检查图像是否匹配,但该方法严重依赖于CLIP 训练集中所包含的实体和概念。基于图像搜索引擎为实体配图的方法有Richpedia[12]、ImageGraph[14]、MMKG[15]、TinyImage[16]等。其中:MMKG、ImageGraph、TinyImage只简单粗暴地使用图像搜索引擎获得的排名靠前的图像,同样没有对实体的图像质量进行把控;Richpedia 虽然同时使用了百科图像和图像搜索引擎两个数据源,但没有利用百科图像质量较高的优势,而是将两者同等对待。
本文同时考虑百科图谱图像数据和图像搜索引擎两个方面,提出一种基于模式迁移的实体配图方法。与Richpedia 不同的是,本文方法筛选了百科图谱中高质量图像及其文字描述作为实体的参考模式,并将该模式用于从图像搜索引擎召回图像,从而充分利用两类图像数据的优势,提高配图准确性。
2 问题定义与方法框架
本节形式化地给出问题定义,在此基础上介绍基于模式迁移的实体配图方法框架。
2.1 问题定义
多模态知识图谱构建工作的核心在于为其中的实体匹配合适的图像。给定实体e,本文的目标是为其获取合适的图像集Me=[m1,m2,…,mn],使得每张图像与实体e在语义上是匹配的。
2.2 方法框架
在本文方法框架中包含以下2 个阶段:
1)模式抽取:从同一类别头部实体的百科图谱的图文对中,利用同类实体的文本描述中的共现性和图像之间的相似性,抽取该类实体典型图像的语义模板和视觉模式。
2)模式迁移:将得到的语义模板和视觉模式迁移到同类非头部实体的图像获取过程中,其中语义模板用于构建搜索引擎检索关键词,视觉模式用于对检索结果去噪。
3 模式抽取
模式抽取方法整体框架如图1 所示,本节分别介绍从百科图谱的图文对中抽取语义模板与视觉模式的具体步骤。
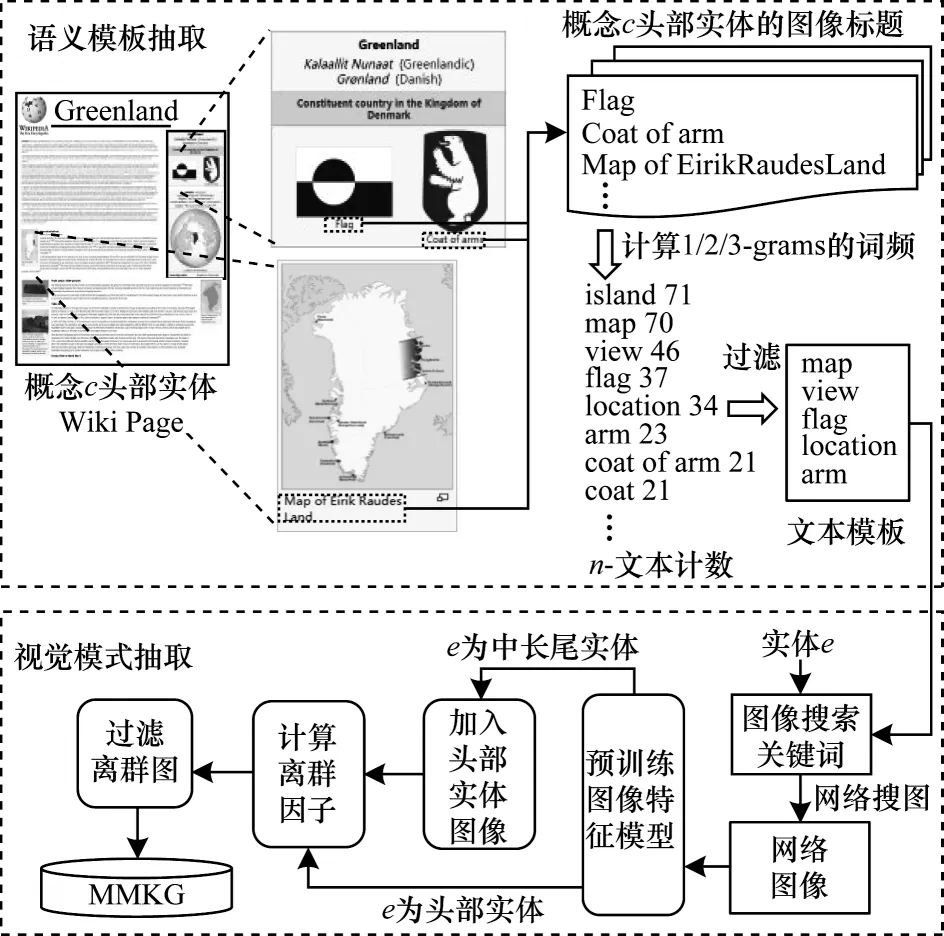
图1 模式抽取方法整体框架Fig.1 Overall framework of pattern extraction method
3.1 语义模板抽取
本文采用Wikipedia 描述页中图像的标题作为抽取语义模板的数据来源,采用以词频统计为基础的抽取方法,并使用视觉信息辅助过滤冗余的语义模板。
首先将同类实体的图文对中所有的文本整理成一个大的文本集合,对文本经过词根还原等预处理后,以实体为单位统计其中n-gram(n=1,2,3)的词频,即如果某实体的文本中该短语出现了多次,也只记1 次,以避免同一实体中反复出现的词对模板词频统计的干扰。
在最终应用于其他同类实体时,本文只选用词频数量排序靠前的k个语义模板,但简单统计n-gram词频进行排序的方法是存在很多噪声的,严重影响了排名前k语义模板的质量。经过分析,笔者总结了以下无效n-gram 类型及解决思路:
1)介词冗余。例如针对模板“map”,在抽取到的n-gram 中会出现“map of ”这类短语,其出现频率与“map”相近,这一模板与“map”在语义表达上有很大的重复,需要去除,应在抽取时过滤掉不是以名词结尾的短语。
2)包含冗余。以“theatrical release poster”为例,在取1/2/3-gram 时,还会取到“theatrical”“release”“poster”“theatrical release”“release poster”这5种额外的情况,且这几个短语的出现频率一定大于或等于“theatrical release poster”,但其中只有“poster”是正确的,其余几项是冗余或者完全错误的。针对这一问题的解决思路是:同词频n-gram 中若存在重叠,则优先保留长度较长的n-gram,在此基础上,从高词频向低词频扫描,若发现当前短语包含其余高频短语,说明当前短语冗余,删去该短语。
3.2 视觉模式抽取
视觉模式抽取阶段主要包括以下3 个步骤:1)获取语义模板对应的图像;2)去除噪声图像;3)过滤语义模板。其中,前2 个步骤是对视觉模式的获取及精化,第3 步是通过视觉模式进一步对语义模板过滤。
1)获取语义模板对应的图像
在抽取到合适的语义模板后,将从Wikipedia 描述页中抽取到的图文对进一步处理成
2)去除噪声图像
通过纯文本比对的方式获得的语义模板,其对应图像中存在噪声,因为语义模板可能出现在图像的标题中但并不是图像所表达的主体。考虑到这种噪声的存在,在本步骤中,借助于整体图像的视觉特征对这些图像进行过滤,这些噪声图像的视觉特征与大部分图像都存在很大的差距,从图像特征的向量空间看,这些图像就是显然的离群点。本文采用预训练图像分类模型VGG16[19]对图像进行编码,得到对应的图像向量,之后用局部离群因子检测方法(Local Outlier Factor,LOF)[20]对这些图像向量进行拟合,计算每张图在向量空间中对应点周围的密度,从而得到其离群因子,最终预测出离群点。
笔者没有采用常规的K-Means、G-Means[21]等聚类算法过滤噪声图像,是考虑到不需要明确提取图像聚类,而只用于过滤边缘图像,且聚类算法会引入额外的超参,而这些超参需要针对实体的不同类别进行设置,影响了方法的泛化能力。
3)过滤语义模板
3.1节中获得的排名靠前的语义模板具备很高的质量,但将所有的模板都用作图像召回是不现实的,需要对这些模板作进一步的筛选,截取前k个作为最终的语义模板,这一步需要使用视觉信息进行检验。
在此提出语义模板的另一条隐形规则:语义模板之间是视觉独立的,即一个语义模板所要表达的图像与其他模板所表达的图像应该是低重合度的。基于这样一个隐形条件,本步骤借助于离群点检测的方法对语义模板进行筛选。
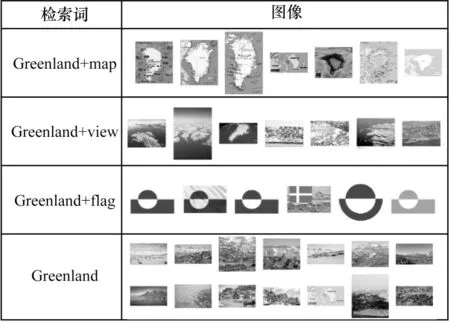
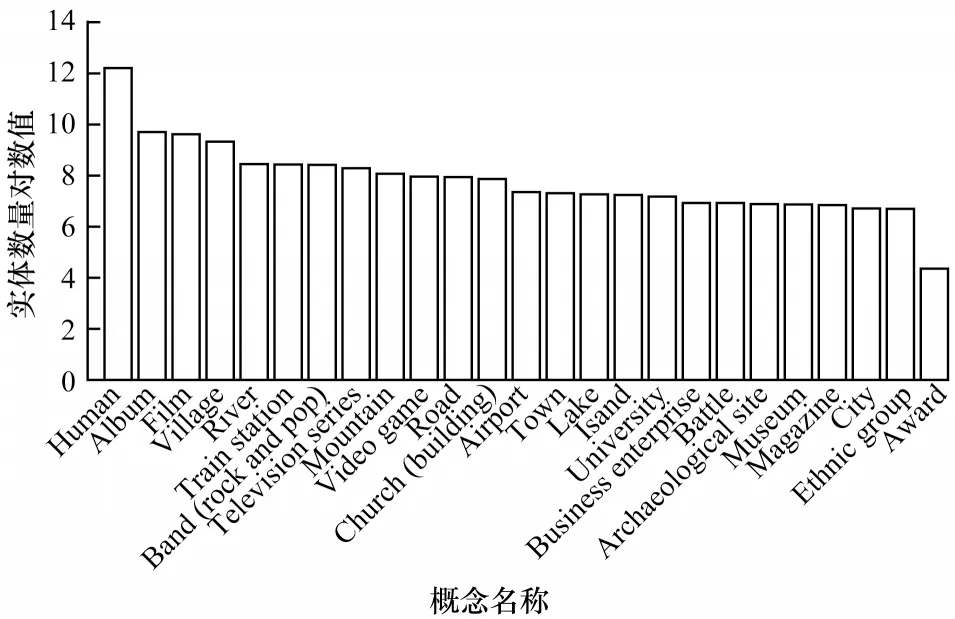
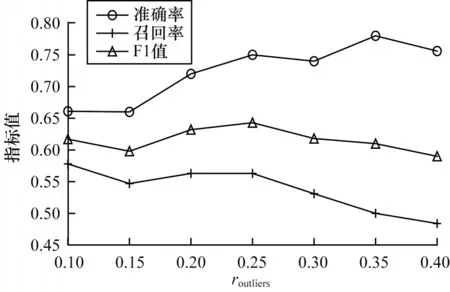
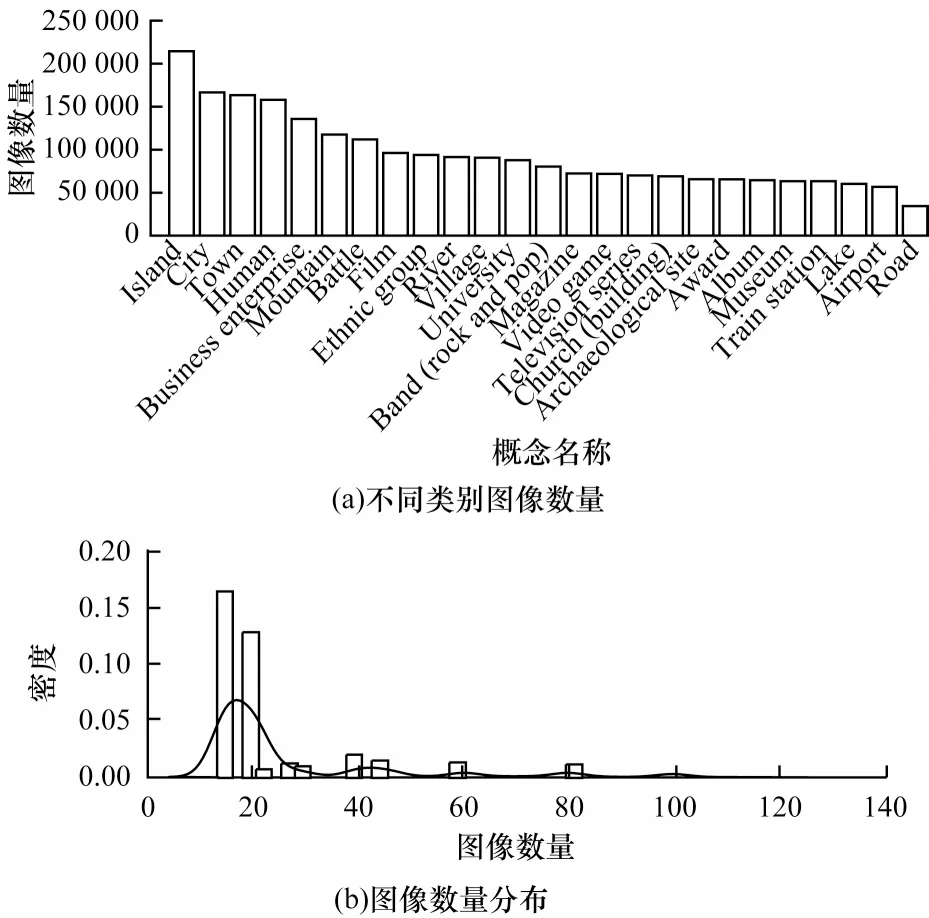
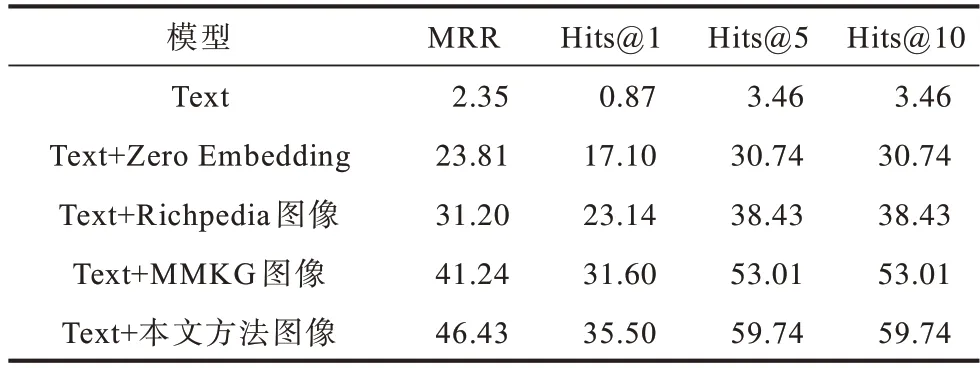
对每个模板pi,若存在pj(j 表1 语义模板示例Table 1 Examples of semantic patterns 本节介绍语义模板和视觉模式的迁移方式。其中,语义模板的迁移主要应用于构建搜索引擎检索关键词,视觉模式的迁移主要应用于检索结果的去噪。 本文提出通过在实体名称后增加关键词的方式,具体化检索的方向。若抽取得到实体e所属概念c有语义模板Pc=[p1,p2,…,pl],则 可以构建l条对应的搜索关键词,用模板pi具体化的检索词对当前实体进行检索,得到的图像就会集中于该实体的pi方面。如图2 所示,在搜索引擎中单纯搜索“Greenland”得到的图像结果十分杂乱,大部分是风景照,中间夹杂了几张地图。但在检索的关键词后加上语义模板对其做进一步约束后,得到的图像结果的表达方式更为集中,且抽取到的多个语义模板也能保证检索结果的全面性。 图2 不同检索关键词下的图像搜索引擎检索结果Fig.2 Retrieval results of image search engine with different keywords 通过语义模板得到的关键词检索结果会更精确,可以将当前语义模板限定下的实体图像从广泛的网页图像中召回到排名靠前的位置,但图像搜索引擎检索中噪声问题依然存在,除了排序靠前的图像较为可信外,剩下的图像中依然存在错误图像,尤其是针对中长尾实体,图像搜索引擎的准确率是很不可靠的[22]。因此,还需要使用3.2 节中获取的视觉模式对搜索引擎得到的图像进行筛选和过滤。 图像筛选的方式同3.2 节的噪声过滤类似,即通过LOF 算法对每个语义模板对应的图像集进行离群点检测。需要注意的是,进行离群点检测时需要将同类概念的头部实体图像信息作为参考,一起加入到数据集中,LOF 算法在头部实体图像集拟合的基础上对同类其他实体的图像进行检测过滤,以防止实体从图像搜索引擎检索得到的图像整体视觉模式偏移,无法通过局部离群因子检测的方法过滤离群点。 本节介绍实验数据及其统计信息,以及实验所用到的一些模型和超参的设置。此外,还将对最终获得的多模态知识图谱的规模和数据进行统计分析,并通过与现有多模态知识图谱的比较评估和完成下游任务的情况,证明所提方法的有效性。 5.1.1 数据源 本文实验基于百科知识图谱WikiData[23]开展。WikiData 是 对Wikipedia 和Wikimedia Commons 结 构化处理形成的一个知识库,其包含的实体数量达到9.6×107之多。同时,模式抽取的数据来源是Wikipedia,一个多语言的百科知识图谱,其中用英文表述的文章数量超过6×106。作为WikiData 本身构建的数据来源,Wikipedia 中每个实体的描述页中的信息比WikiData 中的更加完整和全面。此外,用以构建图谱的图像数据来源有百科图像和图像搜索引擎两类,由于数据本身为英文表达,因此采用Google图像搜索引擎。 在实验中,对WikiData 中不同概念的实体数量进行统计和排序,在排除“消歧页”等Wikipedia 的内置类别和“Taxon”“Surname”等明显的非视觉类别[24]后,排名前25 的统计结果如图3 所示,其中,横坐标为类别名称,纵坐标为实体数量的对数值,这么做是因为WikiData数据存在一定的偏向,Human 包含的实体数量远大于其他概念,为了更清楚地显示其数值,故使用对数值(底数为e)。每次从这些概念中选取头部的100 个实体作为参考实体,对当前概念的图像表达模式进行抽取,包括语义模板和视觉模式。经统计,最终为每个概念抽取了平均约2 个语义模板。 图3 概念分布统计Fig.3 Statistics of concept distribution 5.1.2 实验设置 在视觉模式抽取中,本文采用VGG16 作为图像特征的抽取算法,并将VGG16 分类模型中分类层之前的最后一个池化层的输出作为特征向量,其为一个512 维的向量。 在对模板进行视觉重合度检测时,评估不同离群点比例routliers的取值对最终得到的语义模板的影响。实验结果如图4 所示,可以看出,routliers取值越大,对语义模板的过滤效果越好。最终选取F1 值最大的routliers=0.25 作为过滤阈值,即当模板pi的图像集中只有不超过25%的图像对于模板pj是离群点时,认为pi与pj视觉重合度高,过滤其中之一。 图4 routliers 取值对语义模板的影响Fig.4 The influence of routliers on semantic pattern 经统计,本文方法为25 类实体,共1.27.8×105个实体收集了1.8×106张图像。抽取到的图像数量按类别分布如图5(a)所示,可见其中“Island”“City”“Town”这3 类所收集到的图像数量最多。实体按图像数量的分布如图5(b)所示,可见为每个实体最多收集了124 张图像,且由于语义模板加入构造搜索引擎检索关键词,每加入一个语义模板就多检索一次,每次检索爬取20张图像,因此实体包含的图像数量以20 为间隔出现一个小的峰值。 图5 实体图像数据统计Fig.5 Statistics of entity images data 本文选取4 个多模态知识图谱(IMGpedia、VisualSem、Richpedia、MMKG)对图像质量进行比较,每次为一个实体分别从对比的多模态知识图谱和本文所构建的图谱中获取对应图像进行评估,若本文方法的图像质量高于对比图谱则打分“better”,若一致则打分“equal”,否则打分“worse”。打分的标准包括准确性、多样性、数量,且优先级为准确性>多样性>数量,当准确性一致时才比较多样性,当多样性也一致时才比较图像数量。每次由3 位专家进行评分,若3 位专家的评分完全不一致,则说明该实体图像准确率受主观因素影响较大,直接舍去这条数据,否则取3 个评估结果中一致的打分作为评估的结果。最终从4 个基线多模态知识图谱与本文的多模态知识图谱的交集中抽取200 个结果进行评估,结果如图6 所示,可以看出,本文方法所获得的图像质量普遍优于4 个基线方法。 图6 多模态知识图谱对比Fig.6 Comparison of multi-modality knowledge graph 在评估的过程中,本文方法在同名实体消歧、去除噪声图像等方面的效果也得到了验证。图7(a)~图7(c)都是常见的通过直接搜索实体名称容易引入的噪声类型,本文通过引入语义模板的方式规避了这些问题:图7(a)中“Brazil”指的是一部电影,但由于与国家“Brazil”重名,单在搜索引擎中搜索“Brazil”得到的图像便全是巴西的地图,而本文方法在检索时会在关键词中加入“poster”这个限定词,检索得到的图像就都是正确指向电影的图;图7(b)中“Moby”是一个人,通过名字在搜索引擎上搜索得到的图像,除了“Moby”本人的照片,还会出现与他人的合照,这也是通过图像搜索引擎搜索人名时经常会遇到的噪声,而本文方法在检索时通过加入“portrait”这个语义模板,将图像搜索引擎的结果正确引向了人物个人的肖像;图7(c)中“IBM”指的是一个企业的名字,但由于与一款计算机同名,导致其搜索结果中包含很多个人电脑的照片,而本文通过在检索时加入“logo”“headquarters”等关键词,将检索结果引向了正确的图像。图7(d)是少数MMKG优于本文方法的一个例子,“Walter Lantz”是一位画家,但由于他也是一个人,本文方法在检索时同样加入了“portrait”作为限定,但其画作中也存在肖像,因此导致最终搜索结果偏向了他的画作。 图7 案例分析Fig.7 Case analysis 为进一步检验使用本文方法获取的图像的质量,本文设计一种基于“Prompt”[25]的链接预测方法在数据集FB15k(Freebase[26]的子集)上对收集得到的图像进行评估。任务定义如下:输入三元组 此处借鉴Frozen[27]的思路,将链接预测任务转换成完形填空问题,实现方式如下:针对三元组 图8 基于Prompt 的链接预测模型结构Fig.8 Structure of link prediction model based on Prompt 本实验为FB15k 中包含数据量最大的15 种关系构建了语义填空模板,例如:针对FB15k 数据集中的关系“/film/actor/film./film/performance/film”,可构建填空模板“sis an actor of[MASK].”。根据这15 种关系分别对FB15k 已有的训练集、验证集、测试集进行筛选,最终得到3 927 条训练数据、378 条验证数据和462 条测试数据。 为了检验实体图像带来的作用,本节还进行了以下消融实验:1)只使用预训练文本编码(Text);2)传入空的图像编码(Zero Embedding);3)替换其他多模态知识图谱的图像。本文对比的多模态知识图谱为Richpedia 和MMKG,这是由于现有的多模态知识图谱本身构建依赖的符号知识库不同,所包含的实体也不同,只有包含FB15k 中实体的多模态知识图谱才适合用于比较。尽管VisualSem、IMGpedia 的一部分实体可以与FB15k 中的实体对齐,但数量太少,不足以支撑训练,故不在此进行比较,最终实验结果如表2 所示。 表2 链接预测消融实验结果Table 2 Ablation experiment results of link prediction % 通过对比使用纯文本预测和加入图像信息进行预测的结果可以发现,图像信息的引入有效增强了模型对实体的预测能力。同时对比加入本文方法所收集的图像和加入其他多模态知识图谱的图像的结果,可以发现,本文方法收集到的图像训练所得的链接预测模型在各个指标上均超过其他多模态知识图谱,证明了本文方法的有效性和优越性。 本文提出基于多模态模式迁移的知识图谱实体配图方法,借助同类实体图像之间存在的共性,以语义和图像2 个角度,从头部实体的百科图像与标题中抽取相关的语义模板和视觉模式,并迁移应用到非头部实体的图像获取过程中。基于本文方法为25 类实体,共1.278×105个实体收集1.8×106张图像。与4 个现有多模态知识图谱的对比结果表明,本文方法收集到的图像具有更高的准确性和多样性,在下游任务链接预测中引入本文方法收集的图像,可使模型效果得到显著提升。在目前的多模态知识图谱构建工作中,对图像质量的评估方法仍有很多不足,导致构建所得的知识图谱整体质量得不到有效评估,也就很难应用于下游任务,后续将对此进行相关研究。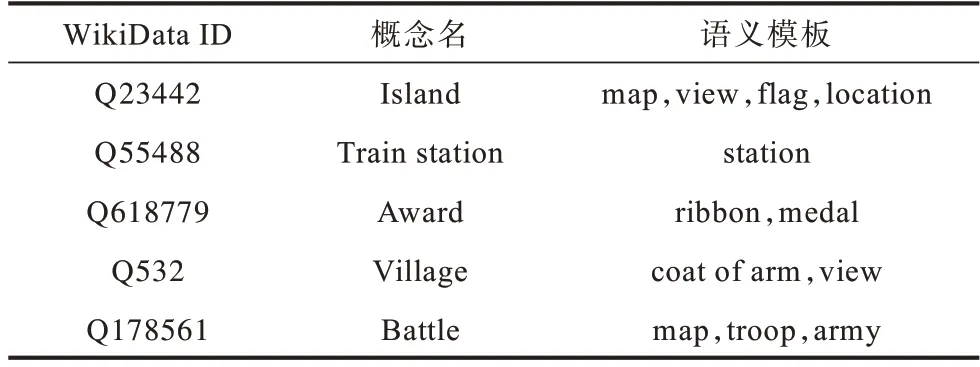
4 模式迁移
4.1 语义模板的迁移
4.2 视觉模式的迁移
5 实验
5.1 数据源与实验设置
5.2 数据统计
5.3 多模态知识图谱对比
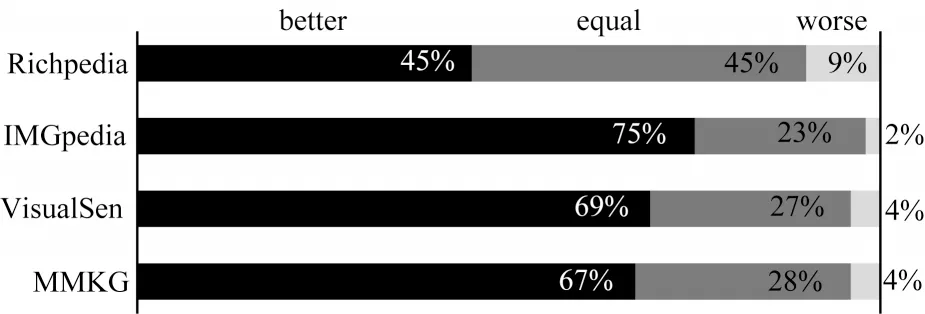

5.4 下游任务实验

6 结束语
猜你喜欢
计算机与网络(2022年2期)2022-03-17
世界科学技术-中医药现代化(2021年7期)2021-11-04
少先队活动(2020年12期)2021-01-14
疯狂英语·新阅版(2020年11期)2020-12-21
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
科学导报·学术论坛(2013年5期)2013-06-26
