
国产通用处理器密码算法指令实现研究*
2022-08-11 08:46:56陈子钰郭翔宇
计算机工程与科学 2022年7期
陈子钰,何 军,郭翔宇
(上海高性能集成电路设计中心,上海 201204)
1 引言
密码安全是信息安全的基石,密码算法作为保证密码安全的关键技术已被广泛应用于信息加密传输、可信计算等领域,深刻地影响着信息安全和国家安全。因此密码算法及其执行效率是学术界研究的重点之一。采用纯软件的方式优化密码算法执行程序[1]、采用定制专用硬件电路[2]或专用处理器[3,4]实现密码算法、采用指令集架构ISA(Instruction Set Architecture)扩展[5 - 7]来支持密码算法,是当前最具代表性的3类提升密码算法执行效率的方式。纯软件优化的方式虽然灵活、成本低,但是优化空间有限且易受侧信道攻击;专用电路和专用处理器实现的方式虽然执行速度快,但成本高、灵活性和可扩展性不佳、不易与其它系统融合。相对而言,面向特定的密码算法采用指令集架构扩展的方式[8]兼顾了硬件和软件的不同特性,同时具有软件优化和硬件加速的优势。该方法既能用硬件加速执行密码算法中的关键操作,又方便软件灵活使用,可以很好地平衡密码算法执行效率与硬件开销、设计灵活性和可扩展性之间的矛盾,达到以较少的硬件资源大幅提升密码算法执行效率和降低代码占用空间的效果,还能灵活地与其他运算模块融合,实现很强的可扩展性。
高级加密标准AES(Advanced Encryption Standard)[9]和安全散列算法SHA(Secure Hash Algorithm)[10]是2种当前应用广泛且影响深远的密码算法,处理器对这2种密码算法的支持情况极大地影响着其在密码安全应用领域的竞争力。Intel X86、IBM Power和ARMv8等主流通用处理器架构中都针对AES和SHA密码算法进行了指令集扩展。基于对AES和SHA密码算法的研究,参考国内外主流通用处理器的密码指令集实现,本文采用指令集架构扩展优化的方式对AES算法和SHA进行指令扩展优化,面向国产通用处理器设计了AES和SHA密码算法扩展指令集,实现了全流水执行的AES和SHA密码算法指令部件,并进行了实现评估分析和优化,以期提高国产通用处理器执行密码算法的效率,并进一步增强国产处理器芯片在密码安全应用领域的性能和竞争力。
2 AES和SHA密码算法
当前,国际主流的密码算法主要有RSA(Rivest,Shamir,Adleman)算法、椭圆曲线ECC(Elliptic Curve enCryption)算法、高级加密标准AES和安全散列算法SHA等。其中AES算法和SHA是由美国国家标准与技术研究所NIST(National Institute of Standards and Technology)制定和发布的通用密码算法,因被广泛使用而在国际上有深远的影响。
2.1 AES算法
AES算法因具有安全性强、加密效率高、硬件开销小和灵活易用等优势已被广泛应用于信息加密和密码芯片等领域。AES算法是一种分组密码算法,其输入、输出分组和加密、解密过程中的中间分组均为128 bit,使用Nr个轮,每轮均需要一个扩展密钥Key参与(Nr取10,12或14,对应的输入密钥长度为128,192或256 bit)。受限于输入密钥的长度,AES算法在运算过程中需要进行密钥扩展(Key expansion),以生成各轮的轮密钥。AES算法的加密流程主要运用了查找SBox并进行字节置换、行变换、列混合和密钥加等4个转换操作。其中,SBox字节置换是指按设定的转换表对每个字节用SBox作一个置换进而生成状态矩阵;行变换的基本操作是循环移位(右移);列混合的基本操作是逻辑异或和定义在有限域上的多项式乘法,多项式乘法运算采用矩阵乘实现;密钥加的基本操作是逻辑异或。除最后一轮仅用3个(无列混合)转换外,每一轮都使用4个可逆的转换。解密是加密的逆过程,在此不再详述。由于AES算法加解密过程运算复杂度高,因此处理器对AES算法的支持性能成为AES算法高效运行的主要限制因素。
2.2 安全散列算法SHA
SHA是一组哈希密码算法,主要用于数字签名、散列消息认证码和生成随机数等应用。安全散列标准SHS(Secure Hash Standard)FIPS 180-4规定了SHA-1、SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224和SHA-512/256等算法。所有的算法都是根据消息字迭代算法对应的哈希函数来产生消息摘要字,所有操作均以字为单位。SHA中的主要参数如表1所示,对于SHA-1、SHA-224和SHA-256算法,字长为32位,消息块大小为16个字(512位),其它算法字长为64位,消息块大小为16个字(1 024位)。
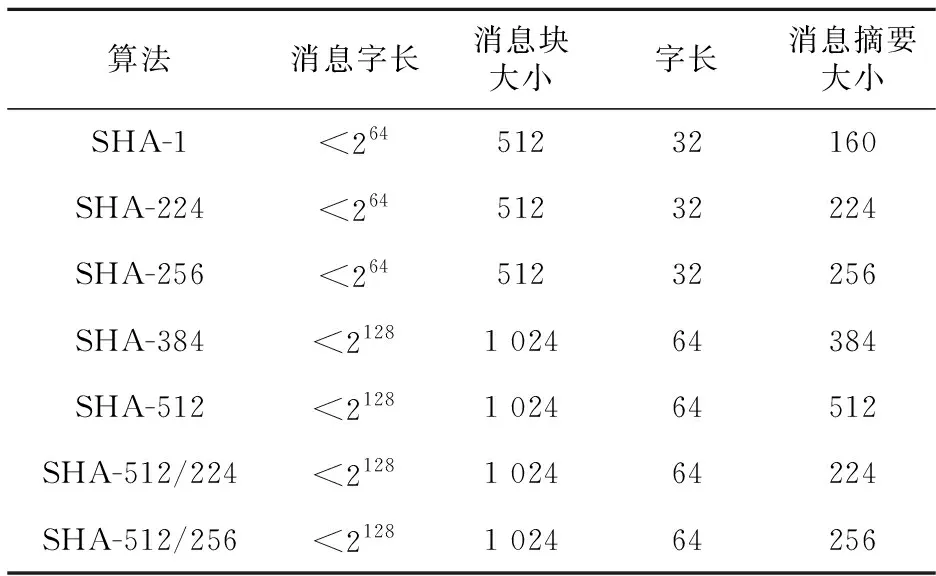
Table 1 Main parameters of SHA表1 SHA的主要参数

3 主流通用处理器对密码算法应用的支持
采用在ISA中扩展密码算法指令的方式能大幅提升密码算法的执行效率,同时还具有硬件开销小、代码占用空间小、灵活性好和可扩展性强等优势。因此,国际主流的通用处理器架构都是通过定义专门的密码算法指令,以扩展指令集的方式来实现处理器对主要密码算法的支持,进而提升处理器在密码安全应用方面的性能。当前,为增强对AES和SHA密码算法应用的支持,Intel X86架构、IBM Power架构和ARMv8架构都在原有指令集的基础上新增了针对AES和SHA密码算法的扩展指令集,如表2所示。其中,Intel X86架构新增了包括6条AES密码指令的高级密码标准指令集AES-NI[11]和7条SHA扩展指令[12],分别用以加速AES加/解密标准算法和SHA(特别是SHA-1和SHA-256);IBM Power指令集[13]也为AES加/解密标准算法新增了5条指令,同时针对SHA-256和SHA-512新增了2条SHA密码算法指令;ARMv8指令集也面向AES和SHA密码算法应用分别扩展了4条和10条密码算法指令[14]。

Table 2 AES/SHA extended instructions of mainstream general purpose processors表2 主流通用处理器的密码扩展指令集
对于AES算法,主流通用处理器的指令集架构的扩展指令都是对轮加/解密中的几个过程进行合并从而实现为一条指令。所不同的是,Intel X86区分了加密轮和尾加密轮,但依然保留了列混合指令。同时,Intel X86有一条专用的密钥生成指令,这条指令对应AES-256密钥生成规则。IBM Power8也区分了加密轮和尾加密轮,单独设有用于字节替换的SBox查找指令(可用于密钥生成Sub Word函数)。ARMv8中将列混合单独作为一条指令,同时不区分是否是最后一轮。上述处理器架构中的指令均为128位向量指令。对于SHA:主流通用处理器的指令集架构主要支持SHA-1、SHA-256和SHA-512,均为128位向量指令。其中,IBM Power8没有指令支持SHA-1,但有指令支持SHA-512,Intel X86和ARMv8不支持SHA-512。SHA密码算法扩展指令主要针对Hash计算提供指令加速,没有对消息填充和分块提供支持。其中,IBM Power8没有对整轮Hash计算过程提供指令支持,而针对Hash计算中的关键函数sigma提供指令支持;Intel X86和ARMv8对整轮Hash计算提供指令支持,包括消息调度和工作变量更新。
当前,国内主要的处理器研制厂商和机构普遍都采用或兼容Intel X86、IBM Power或ARMv8等主流通用处理器架构及其指令集,因此暂未见到专门面向国产处理器而自主设计的AES和SHA密码算法扩展指令集被公布。然而,我国一直非常重视信息安全和密码研究,为了加速密码算法的执行以增强国产处理器在支持主要密码算法应用方面的性能,国内的主要处理器研制厂商和机构都在积极地发展密码算法扩展指令集,以提升国产处理器芯片在密码安全领域的竞争力。目前,中科龙芯、天津飞腾和兆芯等处理器研制机构都已经在兼容原有指令集架构的同时发展了支持部分国密算法的扩展指令集[15]。
4 国产通用处理器密码算法指令集及其实现
密码算法扩展指令集设计必须采用原有指令系统的指令格式和编码规则,以保证新增指令与原有指令集兼容。同时,新指令的数量不宜过多且执行部件不能太复杂,以避免带来过多的硬件开销导致系统运行速度降低。
4.1 国产通用处理器密码算法扩展指令集
为实现国产通用处理器对AES算法和SHA的支持,根据高级加密标准 (AES) FIPS 197和安全散列标准FIPS 180-4,参考国内外主流处理器的密码指令集设计,针对国产通用处理器架构的指令格式和 256位SIMD(Single Instruction Multiple Data)的特点,结合硬件实现,本文设计了面向国产通用处理器的AES、SHA密码算法扩展指令集,如表3所示,指令长度为32位,指令格式有简单运算指令格式、复合运算指令格式(立即数)和复合运算指令格式(寄存器)3种。AES密码算法扩展指令集支持FIPS 197标准定义的AES算法,包括5条指令,分别用以支持AES所规定的加密轮、加密尾轮、解密轮、解密尾轮和SBox字节替换操作。SHA密码算法扩展指令集支持FIPS 180-4标准定义的SHA,包括8条指令,主要对Hash值计算中的消息调度字准备和工作变量字迭代更新2个重要过程进行加速,支持SHA-1、SHA-256和SHA-512。

Table 3 AES/SHA extended instructions of domestic general purpose processors表3 国产通用处理器的密码算法扩展指令集
4.2 密码算法指令部件的设计实现
密码算法扩展指令集在支持密码算法的同时不应降低原指令集架构的性能,也不宜增加太复杂的硬件。在密码算法指令集执行部件实现的过程中需要将可以并行的部分尽量并行,以使所有的指令都能全流水实现,以减少时间延迟,可以共享的部分尽量共享,以减少硬件开销。同时,为了能满足国产通用处理器的工作频率要求,需要将算法划分为尽可能一致的运算分量,且每一个时钟周期的逻辑不能过多。

Figure 1 Structure of cryptographic algorithm instruction unit图1 密码算法指令部件结构
根据AES和SHA密码算法指令集,密码算法指令部件的结构如图1所示,按密码算法的特征,分别设置AES和SHA 2个子部件,均支持全流水运算。其中,AES密码算法指令子部件的功能是实现5条AES指令,主要基本操作为查表、移位和逻辑异或。并且级联的逻辑数不是很多,各条指令均能在1个时钟周期之内完成。SHA密码算法指令子部件的功能是执行8条SHA指令,由于要实现迭代运算,因此需要根据迭代次数和运算逻辑量进行时钟周期划分,按照频率要求,分别将各条指令的运算划分成基本一致的1~8段运算分量。为减少硬件开销,在满足算法逻辑功能的前提下需要对密码算法的运算过程进行优化。
4.2.1 AES密码算法指令实现
AES密码算法指令子部件的主要功能是对AES查找SBox并替换字节、AES加/解密轮及其尾轮提供加速,完成 AES轮加密(VAESENC)、AES尾轮加密(VAESENCL)、AES轮解密(VAESDEC)、AES尾轮解密(VAESDECL)和AES字节替换(VAESSBOX)5条指令。子部件主要执行查找加密转换表SBox并替换字节生成状态矩阵、行移位变换、列混合变换、加密密钥加、查找解密转换表InvSBox并替换字节、行移位逆变换、列混合逆变换和解密密钥加等操作过程,其底层的逻辑操作是查表、移位和异或。
AES密码算法指令子部件的结构如图2所示,分别为加密和解密过程定义的基本操作,设置加密查表转换(SUBBYTES)、行移位变换(SHIFTROWS)、列混合变换(MIXCOLUMNS)、解密查表转换(INVSUBBYTES)、行移位逆变换(INVSHIFTROWS)和列混合逆变换(INVMIXCOLUMNS)6个子模块。根据指令控制信息和输入数据,选择对应的数据通路即可实现AES密码算法指令。AES密码算法指令子部件的输入和输出数据的位宽均为256位,可以使用128,192 和 256 位密钥的迭代式对称密钥块密码,并且可以对 128 位(16 个字节)的数据块进行加密和解密,每条指令的执行延迟为1个时钟周期。

Figure 2 Instruction subassembly structure of AES 图2 AES密码算法指令子部件结构
为加速算法执行,将SubBytes和InvSubBytes所定义的表格信息直接用专用电路实现,可以有效地减少因执行AES算法的查表和访存而造成的延迟。此外,行移位变换在电路实现上只需改变信号连线的组合,因此除导线上的信号延迟外移位操作不需要其他时间开销。因为尾轮加密和轮加密相比仅仅少了一个列混合变换,因此VAESENC指令和VAESENCL指令可以共享一组硬件来实现,同理VAESDEC指令和VAESDECL指令也可以共享一组硬件,这样有效地减少了硬件开销。
4.2.2 SHA密码算法指令实现

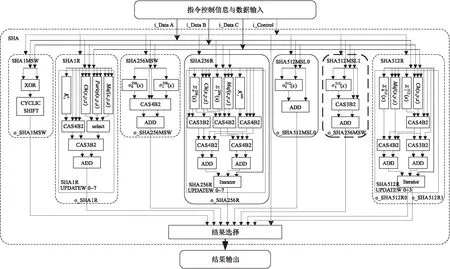
Figure 3 Instructions subassembly structure of SHA 图3 SHA密码算法指令子部件结构
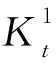
与AES密码算法指令子部件同理,通过改变电路连线直接实现移位操作可有效加速算法中的移位运算。为进一步加速算法执行,实现中将常数选择子模块定义的常数直接用专用电路实现,以减少SHA算法中常数选择判断带来的延迟。此外,需要将能压缩的工作字尽早压缩,以缩短压缩数据所需的时间延迟;将能并行的操作尽可能地并行,以减少工作字迭代带来的时间延迟。在SHA1MSW和SHA512MSL0指令中,因为各消息调度字的生成是独立的,因此这2条指令可各自同时将8个消息调度字并行生成;SHA256MSW和SHA512MSL1指令中由于工作字之间存在数据真相关,单条指令每时钟周期最多只能并行生成2个工作字;SHA1R、SHA256R、SHA512R0和SHA512R1这4条指令中由于每个工作变量字均依赖于前一个工作变量字,因此同一条指令的工作字生成过程无法直接并行,但可采用流水执行来实现,并且在每个工作变量字的生成过程中要尽早压缩能压缩的数据。为减少硬件开销,以减小面积和功耗,实现中采用改进运算步骤的方式对SHA1R的字更新算法进行了优化,将4个条件选择支路中模2w加运算提到选择支路之外,即先选择常数和函数,然后再进行模2w加和压缩,优化后的算法相比原算法在不改变时序延迟和正确性的前提下可减少24个CSA3B2和24个CSA4B2压缩器。此外,SHA512R0和SHA512R1指令的迭代流程相同,只是选取不同结果数据,因此可共享一套硬件来节省硬件开销。
5 密码算法指令实现评估
对照高级加密标准FIPS 197和安全散列标准FIPS 180-4可知,本文提出的密码算法扩展指令集对AES和SHA提供了比较完备的支持。对比主流通用处理器架构中的密码算法扩展指令集,对AES算法,该AES扩展指令集的功能设置与Intel X86、IBM Power和ARMv8等主流通用处理器指令集中的AES扩展指令集大致相同,但因该AES扩展指令集中的所有指令支持256位的SIMD运算,并且在实现上都仅需1个时钟周期即可完成,因此具有更短的执行延迟。对SHA,由于不同的SHA扩展指令集提供的加速过程及其运算量都不一致,难以直接通过对比指令的延迟时钟周期数来评估不同扩展指令集间的性能差异,但在功能上本文提出的SHA扩展指令集能同时支持SHA-1、SHA-256和SHA-512,并且既能加速工作字迭代,又能加速消息调度字生成,因此该SHA扩展指令集比当前主流的SHA扩展指令集的功能更加完善。
为验证密码算法指令部件的功能和执行结果的正确性,本文采用已经验证正确性的密码算法程序为参考模型,通过源操作数取随机值和典型特征值的方法进行大量模拟实验。此外,还针对设计实现代码进行了代码覆盖率和功能覆盖率分析,代码覆盖率和功能覆盖率均可达100%。实验表明,密码算法指令部件的功能和执行结果正确,达到了设计预期。
为评估密码算法指令部件的时序、功耗和面积等性能指标,采用Design Compiler综合工具,基于某工艺条件,时钟频率2.0 GHz,对密码算法指令部件的Verilog设计代码进行了逻辑综合,结果如表4所示。其中,对SHA1R算法的优化可使SHA密码算法指令子部件面积减小3.32%,功耗减小0.94%。

Table 4 Logic synthesis results of AES and SHA表4 密码算法指令执行部件综合结果
为分析AES和SHA密码算法扩展指令相比原指令集对密码算法执行效率的改善,需分析密码算法指令部件相对软件采用原有通用指令实现密码算法的加速比。由于软件程序在实际执行时情况非常复杂,且采用相同指令集的不同处理器的硬件配置也各有差异,为使指令集性能优化分析结果不依赖于具体的硬件配置、软件执行环境和测试平台,同时使分析过程有效和简化,对软件采用的原有通用指令执行密码算法做以下假设:(1)密码算法中查表所需的数据已全部存储到处理器的数据缓存中;(2)所有访存全部命中;(3)所有指令全部流水执行;(4)不存在数据真相关的指令全部能并行执行。
以AES轮加密指令VAESENC为例,采用AES密码算法指令部件实现只需1个时钟周期即可完成,但如果通过软件采用原有通用指令来实现则需要查SBox表替换字节、行移位、列混合、加密钥加4个过程,依次需要调用装入立即数指令(LDI,1个时钟周期)、装入长字整数指令(FLDD,4个时钟周期)、长字逻辑右移指令(SRLL,1个时钟周期)和逻辑异或指令(XOR,1个时钟周期),即便不考虑处理器并行指令数的限制,软件最少也有7个时钟周期的执行延迟,因此AES轮加密指令VAESENC具有7.00倍的最小加速比。
基于上述假设,分别分析软件采用原有通用指令实现AES和SHA扩展指令的最小执行延迟。结果如表5所示,AES指令部件的最大执行延迟DImax均为1个时钟周期,软件实现AES指令对应算法的最小延迟DSmin为5~19个时钟周期。用软件的最小执行延迟DSmin与AES指令部件的最大延迟DImax的比值表征密码算法指令的最小加速比,则AES指令的最小加速比为5.00~19.00倍,几何平均数为8.90倍。SHA指令部件的最大执行延迟DImax为2~9个时钟周期,软件实现SHA指令对应算法的最小延迟DSmin为5~74个时钟周期。不同SHA指令的最小加速比为2.50~8.22倍,几何平均数为4.75倍。因AES和SHA密码算法指令部件均支持全流水执行,因此SHA密码算法指令的实际平均执行延迟会小于最大执行延迟DImax,即在全流水执行的情况下每个时钟周期都能完成一条密码算法指令,此时SHA密码算法指令的最小加速比达5.00~74.00倍,几何平均数为19.30倍。考虑到软件在使用原有通用指令实现密码算法时还存在构建查表、访存不命中、处理器指令执行部件和并行指令数有限、不能全部流水执行等情况,实际的软件程序延迟会大于最小延迟DSmin,AES和SHA密码算法指令的实际加速比会大于最小加速比。因此,表明该密码算法指令部件能显著地加速处理器对密码算法的执行效率。

Table 5 Speed up of AES/SHA instructions表5 密码算法指令部件的性能加速比
6 结束语
本文基于国际主流密码算法AES和SHA,综述了主流通用处理器架构的密码算法指令发展现状;面向国产通用处理器设计了一个密码算法扩展指令集,包括5条AES密码算法指令和8条SHA密码算法指令,相比于当前主流的密码算法扩展指令集,该扩展指令集能对AES密码算法和SHA密码算法提供更完备的加速支持,并且AES指令具有更短的执行延迟。还实现了能全流水执行的AES和SHA密码算法指令部件,通过流水执行、专用硬件电路实现查表、及时压缩中间运算结果以及改进运算步骤等方法对算法实现进行了优化,既提高了算法执行效率,又减少了密码算法指令部件的硬件开销和功耗。最后对本文设计进行了正确性验证、逻辑综合和性能评估分析。结果显示,该密码算法指令部件的功能和正确性达到了设计预期,工作频率可达2.0 GHz,总面积为17 644 μm2,总功耗为59.62 mW。相比基于原有通用指令集采用软件实现密码算法,新增AES和SHA密码算法指令后,密码算法指令部件对AES密码算法的最小加速比为8.90倍,对SHA密码算法的最小加速比为4.75倍,全流水情况下可达19.30倍。表明新增密码算法指令集及其执行部件能显著加速处理器对密码算法执行的性能,有望应用于国产通用处理器并进一步提升国产通用处理器芯片在密码安全应用领域的竞争力。此外,该密码算法指令部件还可以封装成专门用于支持密码算法的IP,应用于密码安全领域的专用芯片中。
猜你喜欢
数学小灵通·3-4年级(2021年9期)2021-10-12 05:47:46
电脑报(2021年49期)2021-01-06 18:36:55
小学生学习指导(低年级)(2020年10期)2020-11-09 09:21:58
制造技术与机床(2018年9期)2018-09-19 06:48:16
海外华文教育(2017年6期)2017-08-07 03:11:00
数学大王·中高年级(2017年2期)2017-02-08 15:52:55
学苑创造·A版(2016年4期)2016-04-16 17:57:51
电测与仪表(2016年21期)2016-04-11 12:42:34
水电站机电技术(2016年1期)2016-02-28 14:21:50
中国信息化周报(2014年19期)2014-07-22 15:43:11
