
基于NR-Transformer的集群作业运行时间预测*
2022-08-11 08:46:58陈奉贤
计算机工程与科学 2022年7期
陈奉贤
(兰州大学网络安全与信息化办公室,甘肃 兰州 730000)
1 引言
高性能计算发展快速,已被广泛应用到科学研究与工程应用等领域。高性能计算由于具有计算能力强、并行规模大和多类型异构计算等特点,在高密度计算和人工智能等领域得到了充分的应用。
高性能计算通常以大规模计算集群的方式提供服务,集群上运行的作业类型多样,不同类型的作业占用的资源和运行时长各不相同[1]。在这种大规模的高性能集群上,作业调度一般由作业调度系统来实现。系统会监控作业的资源消耗、使用时长等特征,再通过相关调度算法,来确定作业在集群上的执行顺序。
常用的调度策略有先来先服务FCFS(First Come First Serve)、轮转(Round Robin)和短作业优先SJF(Short Job First)等[2]。作业根据这些调度算法的预定规则确定的作业顺序按序执行,例如FCFS是按照作业提交的顺序调度作业运行。当集群上计算耗时长的大作业较多时,FCFS调度算法难以利用集群的碎片资源,导致一定程度的资源浪费[3]。回填算法(Backfilling)是一种辅助调度算法,它根据当前集群作业所需的运行时间信息,在不改变原作业执行顺序的情况下,将集群上的碎片资源分配出去,提高集群资源的利用率[4]。由于FCFS算法稳定,对作业和进程调度公平,因此现有的作业调度系统大都采用先来先服务加回填的调度方式,本文工作也是基于该方式展开,该方式对作业运行时间的预估有较高的要求。但用户预估的作业运行时间和实际运行时间之间往往有较大误差,结合用户作业信息和集群作业的历史日志分析预测的运行时间,能较大程度地提高准确率[5]。因此,要提高集群作业的运行效率,需要有效利用用户的历史作业信息,对集群作业的运行时间进行准确的预测[6,7]。
2 相关工作
目前对集群作业运行时间的预测,大多是基于历史日志数据的,即假定同一集群上计算模式和规模相似的作业其运行时长也较为接近。该方法虽然能一定程度上提升准确率,但是,由于历史数据中存在缺失数据和噪声数据[8],使得精确预测作业运行时间成为一道难题。一种策略是利用同一用户的历史作业信息预测该用户未来作业的运行时间,例如将某用户最近2次作业运行时间的平均值作为其下一次作业运行时间的预测值[1],该算法对EASY回填(EASY-Backfilling)算法的调度系统性能有一定的提升,但在大规模的高性能集群上的准确率和适用性都难以达到实用效果,尤其难以预测新用户的作业。文献[9]从历史作业的特征中去衡量不同用户、不同作业的相似度,筛选出与待预测作业最为相似的若干作业,并将这些作业的平均运行时间作为待预测作业的运行时间。该预测算法不依赖于单个用户的历史日志,通过改进作业相似度衡量算法,对噪声数据有一定的抗干扰能力。
近年来,聚类、分类和集成学习等机器学习方法越来越多地用于集群作业运行时间预测。文献[10]先从历史日志中筛选出与作业运行时间相关的重要特征,再利用这些特征进行聚类,根据聚类结果预测新作业的运行时间。文献[11]基于K-近邻算法,先通过历史数据训练KD树,然后使用训练好的KD树计算新作业与历史作业的距离,并将新作业划分到与之距离最近的作业类别中,以完成作业的运行时间预测。除使用单一的机器学习算法外,有不少学者尝试使用集成学习的方法预测运行时间。文献[12]以随机森林回归、支持向量回归SVR(Support Vector Regression)和贝叶斯岭回归3种回归模型为基模型来提取VASP(Vienna Ab-initio Simulation Package)的作业特征,预测作业的运行时间,并对预测结果进行了2次学习。同时,该文献将历史数据按运行时间长度分为多个区间,在每个区间内分别进行训练和预测,取得了较好的预测效果。文献[13]将分类和学习算法相结合,提出一种GA-Sim集成学习算法。该算法先用K-近邻搜索相似作业,然后在相似作业集上训练SVR模型,将训练好的SVR模型用于最终的预测。文献[14]先探讨了不同调度策略的特点,再按具体的调度策略,使用梯度提升树方法来提升集群作业运行时间预测预测的准确率。随着神经网络的飞速发展,有研究人员使用深度神经网络对集群作业日志建模,以提升作业运行时间预测的准确率。文献[15]使用俄罗斯科学院联合超级计算机中心(JSCC RAS)的超级计算机MVS-100K和MVS-10P的统计数据,将工作日志特征按重要性排序,确定了最重要特征的互相关,然后使用多种方法建模和预测,最后使用随机森林取得了最佳预测效果。文献[17]使用神经网络建模来预测运行时间和I/O ,将整个作业脚本输入深度学习模型,从而实现运行时间和 I/O资源预测的完全自动化。
本文在上述研究的基础上,提出一种基于注意力机制的NR-Transformer(Non-Residual connected Transformer)网络,对作业日志数据建模和预测。在具体算法中,先使用K-Means聚类算法对集群用户进行聚类,将用户的类别特征作为用户特征加入数据集中;然后根据集群作业运行时间的长度将数据集划分为不同的作业集;同时考虑到集群上作业提交顺序的时序因素,分别使用循环神经网络RNN(Recurrent Neural Network)、长短期记忆LSTM(Long Short-Term Memory)网络和NR-Transformer网络等结构,在各作业集上训练和预测,并对比分析了各网络结构下不同运行时间区间内的预测结果。
3 数据特征处理
高性能计算集群实际产生的作业日志包含多种特征,例如用户ID、使用的CPU数量和作业等待时间等。如果将这些特征全部用于模型训练,一方面会使模型过于复杂,导致训练周期过长,且容易出现过拟合现象;另一方面,由于部分特征包含了大量的缺失数据和噪声数据,这部分特征用于训练会导致模型难以收敛。因此,在训练模型前,需要先对历史作业日志数据的特征进行筛选和清洗。
为验证本文所提网络的有效性和实用性,实验选用高性能集群日志中常用的公共数据集:ANL-2009、HPC2N和KIT[17]。这些数据集中的数据均由实际使用的高性能集群记录产生,其中,ANL-2009是阿贡实验室超级计算机记录的作业调度信息;HPC2N来自北瑞典高性能计算中心Seth的日志信息;KIT来自德国卡尔斯鲁厄技术学院的ForHLR II系统一年半的作业记录。这些数据集的数据均以标准日志格式SWF(Standard Workload Format)的形式记录。本文将这3个数据集分别编号为1,2和3,其详细信息如表1所示。

Table 1 Details of datasets表1 数据集详细信息
3.1 数据特征筛选
从表1可以看出,3个数据集均来自多用户的高性能计算集群,经过初步整理后这些标准日志数据均包含18维作业特征。这些特征包含:作业的提交时间、等待时间和运行时间等在内的时间类特征;占用CPU数、内存大小等资源类特征:用户ID、用户组等用户类特征。这些作业特征均使用实际数值表示,缺失数据则用-1来表示。上述数据集经过初次清洗和整理后,部分作业特征中仍存在大量缺失数据,因此需要对其进一步地清洗和处理。
表2是各数据集上对缺失数据超过80%的特征的数量统计。从表2中可以看出,数据集1和数据集3有9个特征的数据缺失比例超过80%,数据集2有7个特征的缺失比例超过80%。这些特征由于缺失数据过多,属于无效特征,因此需要将其删除。在剩余的特征中,对包含重复信息的特征只选择其中1维,例如作业号码用于记录作业提交的顺序,其与作业的提交时间重叠,故只保留作业的提交时间。最终,共筛选出7维特征用于模型训练和预测,特征名称和部分值见表3。

Table 2 Feature statistics of missing large amounts of data表2 缺失大量数据的特征统计
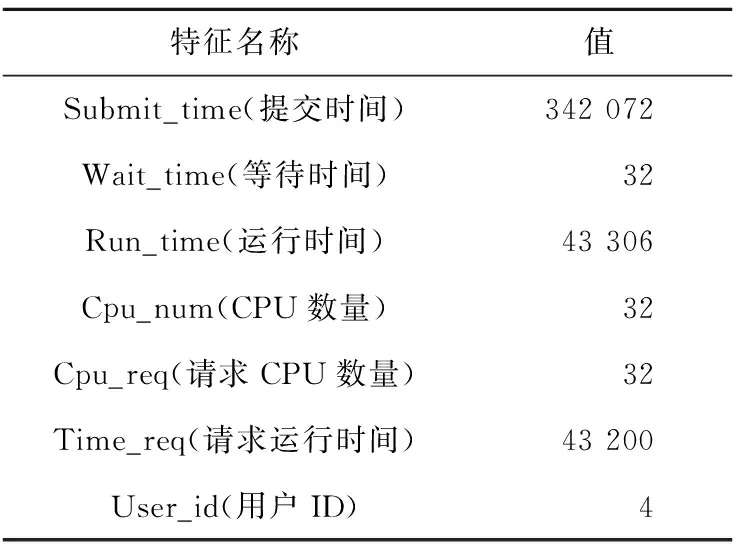
Table 3 Selected features and their values表3 筛选后的特征及其特征值
从表3可以看出,保留的作业特征仍涵盖了上述时间类、资源类和用户类特征,特征筛选没有造成日志数据信息的损失。对于筛选后数据特征中仍存在的少量缺失值,本文使用均值插值法对其进行填充。
高性能作业日志中,部分数据来源于提交的作业参数或程序错误而使作业提前终止的错误作业日志,也需要将其作为噪声数据剔除。本文将作业日志中运行时间少于180 s的作业数据和实际运行时间低于请求作业时间1%的作业数据作为噪声数据从数据集中剔除。除此之外,极少数作业运行时间远大于其他作业,这部分数据作为离群点也被剔除出数据集外。
除此之外,7维特征中,时间类特征值在数量级上远大于其他2类特征,使各特征之间权重失衡,因此需要对数据做归一化处理。本文使用自然对数归一化的方式对时间类的特征进行处理,处理后的特征值在1~15。
3.2 用户聚类
数据经过筛选和标准化后,可用于进一步挖掘行为相似的用户,优化用户类别的数据特征。研究表明,相类似的用户在同一个高性能计算集群上通常会重复提交相似的作业[18,19]。由表1可知,3个数据集上用户数均比较多,用户ID作为离散特征变量直接用于训练模型,可能会因为值过于分散而导致模型难以收敛。因此,本文使用聚类算法,首先根据历史日志中用户作业的计算模式和规模进行聚类分析,得到计算模式相似的用户类别,然后使用该特征作为用户的类别特征,代替用户ID,降低用户特征的离散程度。
本文使用K-Means聚类算法,该算法具有原理简单、速度快等特点。在聚类前,先整理用户的主要特征,统计各用户在平台上的作业数、平均等待时间、平均运行时间和平均使用CPU数目等指标,然后将其作为用户的特征,用于用户聚类。在训练时,K-Means算法需要预先指定聚类的簇值K,但不同的K值对聚类效果影响较大。因此,本文首先对K值预设范围,训练聚类模型时分别使用该范围内的K值,然后用轮廓系数(Silhouette Coefficient)衡量各K值下的聚类效果[20]。样本i的轮廓系数和整个数据集总的轮廓系数的计算方法如式(1)和式(2)所示:
(1)
(2)
其中,a(i)为样本i到其所在簇中其它样本的平均距离,b(i)为样本i到其它簇中样本的平均距离,N为样本数,S(i)为样本i的轮廓系数,SC为整个数据集总的轮廓系数。
聚类的总轮廓系数越接近于1,说明簇内样本之间越紧凑,簇间距离越大;反之,则说明簇间重叠部分大,聚类效果不佳。因此,本文选取预选区间内使轮廓系数最大的K值作为最终的聚类簇值。具体算法流程图如图1所示。
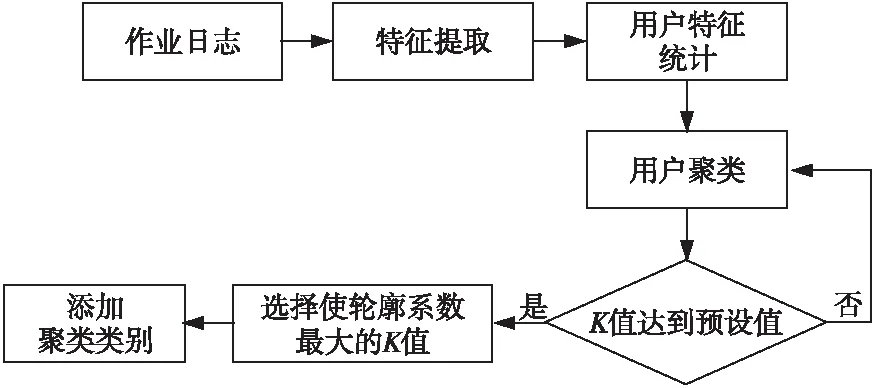
Figure 1 User cluser algorithm图1 用户聚类算法
本文预设的K值在3~18,在3个数据集上分别使用取值范围内的K值训练聚类模型,计算和统计不同K值下的轮廓系数。轮廓系数随K值的变化如图2所示。由图2可知,在3个数据集上,随着聚类的K值增加,轮廓系数整体呈下降趋势,说明数据集上的用户类别分布差异相对较小。数据集1的轮廓系数整体高于其他2个数据集的,而数据集1的数据量小于其他2个数据集的,日志整体的时间跨度也较小,因此可以推断出,数据采样的时间间隔和数据量会影响数据集上用户作业的差异性,时间间隔越久,数据量越多,用户作业的差异性也就越大,这也符合文献[18]的实验结论。
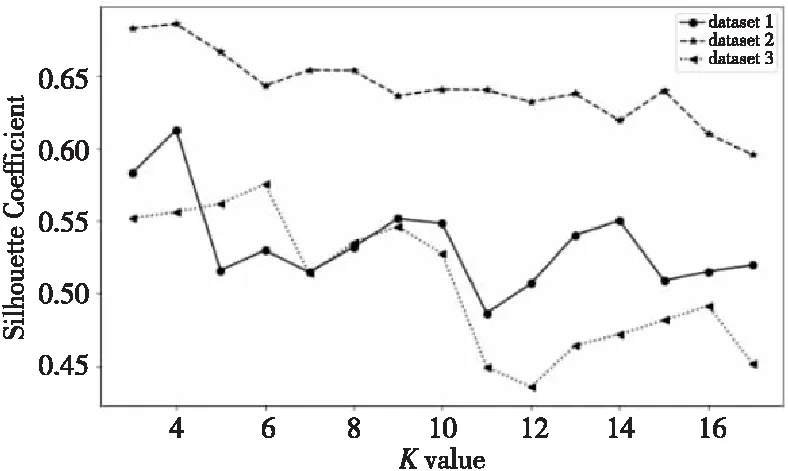
Figure 2 Curve of silhouette coefficient changes with K value图2 轮廓系数随K值的变化曲线
此外,数据集1和数据集2均在K取4时轮廓系数达到最大值,数据集3在K取6时轮廓系数达到最大值。因此,本文对数据集1和2进行K取4时的用户聚类,对数据集3进行K取6时的用户聚类,得到最终的用户类别。
4 预测模型
从第2节对数据集的特征描述可知,作业日志中有多个特征用于记录作业提交和执行的时序信息。现有的研究在分析作业日志时,大都没有考虑前后作业之间的联系。文献[13]筛除时序特征,只利用了用户特征和作业资源特征;文献[21]只将作业提交时间作为作业特征信息用于训练模型,也未考虑作业之间的关联。在实际的作业系统中,新作业的运行状态往往和当前集群上正在运行的作业有关,例如当前系统上作业的运行时间会直接影响到新作业的等待时间。
为了利用数据集上作业之间的时序性,本文在分离长短作业时保留原作业的提交顺序,并按照时间步长L对数据进行采样。采样后的一组数据长度为T,训练时以T为基本长度提取时序信息。在模型选择上,使用能有效利用数据历史信息的循环神经网络、长短期记忆网络和改进的注意力模型Transformer等结构,来提取作业数据的特征和时序信息。训练时,使用长度为T的序列数据预测第T+1位置的作业运行时间。
4.1 循环神经网络
循环神经网络RNN通常用于序列数据的建模,在语音序列、自然语言和时间序列等数据上有广泛的使用。RNN通过有向循环连接,在计算当前隐藏层的状态时,同时考虑了当前的输入向量和上一时间步的隐藏层状态,使神经网络能够学习历史信息[22]。但是,RNN在输入序列过长时,通过循环连接累积的梯度容易造成梯度的消失/爆炸,致使RNN无法获取序列的长期依赖。为了解决上述梯度问题,文献[23]在RNN细胞结构中引入门控单元,通过输入门、遗忘门和输出门等结构构建了长短期记忆LSTM网络[24]。通过门控单元对每次输入进行非线性变换,避免了梯度消失/爆炸,解决了序列数据的长期依赖问题。
本文以RNN和LSTM网络作为基准模型,验证对作业日志数据进行时序建模和预测的有效性。
图3是循环神经网络预测模型。其中,输入为第2节中处理后的作业特征数据;神经网络部分是3层的RNN/LSTM网络,每层均包含64个神经元;输出是一个全连接网络层,用于调整预测值的维度。在激活函数的选择上,RNN选用ReLU函数,以避免梯度问题;LSTM根据各个门限结构的特点,使用Sigmoid函数和Tanh函数。
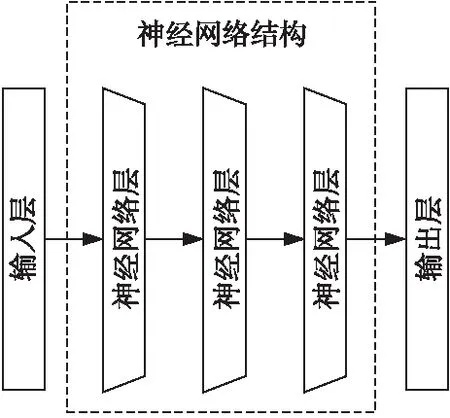
Figure 3 Recurrent neural network model图3 循环神经网络模型
4.2 NR-Transformer网络
注意力机制AM(Attention Mechanism)通常应用于Seq2Seq结构中,用于处理输入端和输出端序列长度不等的数据。在编码端,对于每一时刻的输入,AM都计算该时刻基神经网络的输出状态值,并将该状态值用于解码端的输入。基神经网络一般选择RNN或LSTM,使用注意力机制的Seq2Seq网络可以获取比LSTM更长的序列历史信息,在自然语言处理和部分时间序列上都取得了较好的效果。但是,由于RNN和LSTM无法并行化,使得模型的训练速度较为缓慢。
Transformer是Google提出的基于自注意力机制的Seq2Seq结构[25]。由于自注意力结构计算时不依赖前一时刻的输出值,因此可以通过并行化来加速模型的训练速度。该网络使用位置编码PE(Positional Encoding)计算序列中数据的相对位置,以获取数据的时序关联信息。编码端和解码端都使用多头自注意力结构,每层之间使用残差连接,并进行了层正则化处理[26]。
使用原始的Transformer在作业日志数据上训练时,模型收敛速度较慢,其预测准确率和基准模型的有较大差距。因此,本文根据Transformer和日志作业数据的特点,提出一种改进的NR-Transformer结构:在注意力计算上,使用缩放点积的计算方式;在层与层的连接上,去除各子层之间的残差连接,并只对部分层进行层正则化处理;在输出端,使用全连接层对模型的状态向量进行映射变换。NR-Transformer的结构如图4所示。
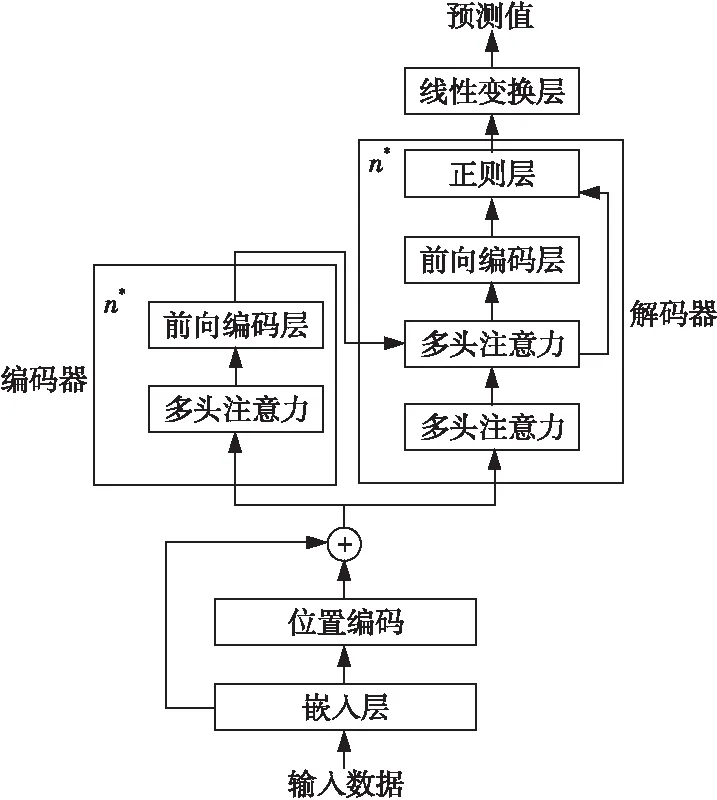
Figure 4 NR-Transformer structure图4 NR-Transformer结构
输入数据先经过由单层全连接网络组成的嵌入层,将输入数据特征编码为向量表示。位置编码模块提取输入向量的时序信息,具体计算如式(3)所示:
(3)
其中,PE(t,2i)表示输入向量中t时刻第i维的位置编码向量,dmodel表示输入向量的维度大小。通过位置编码模块,得到包含作业数据时序信息的位置编码向量,再将位置编码向量和输入向量相加得到新向量,作为编码器和解码器的输入。
编码器和解码器的核心模块是多头注意力(Multi-Head Attention),它是Transformer中提出的一种注意力计算算法。该算法通过降维映射和缩放点积多次计算输入的注意力,并将这些计算结果拼接起来,计算公式如式(4)所示:
MultiHead(Q,K,V)=
Concat(head1,…,headh)Wo
(4)
其中,h是头的个数,即计算次数;headi通过缩放点积求得,如式(5)所示:
(5)

Feed Forward层是编码器和解码器中的最后一个模块,该部分对多头注意力的输出进行非线性变换。它由2个全连接网络和激活函数组成。解码器的输出经过1层全连接网络得到最终的预测结果。在本文中,激活函数使用ReLU函数,编码器和解码器的层数n均为3,头的个数h为8。
5 实验与结果
5.1 数据集划分
运行时间相差较大的作业,其特征差异也往往较大,如果不加区分地使用全部数据训练模型,模型难以很好地学习数据集的特征,导致模型难以收敛到最优点。现有的研究通常按照作业的实际运行时间将数据集中的长短作业分离,分别在各作业集上进行训练和预测。
本文先对3个数据集的运行时间区间进行统计,然后根据各区间的样本数,划分各数据集上的长短作业集。图5~图7分别是数据集1,2和3的区间频数统计图。从图中可以看出,3个数据集上运行时间在0~5 000 s的短作业样本最多,大于40 000s的长作业样本较少。本文按照运行时间的区间和各区间的样本数,将3个数据集分别划分成长、中、短3类作业集,具体划分如表4所示。
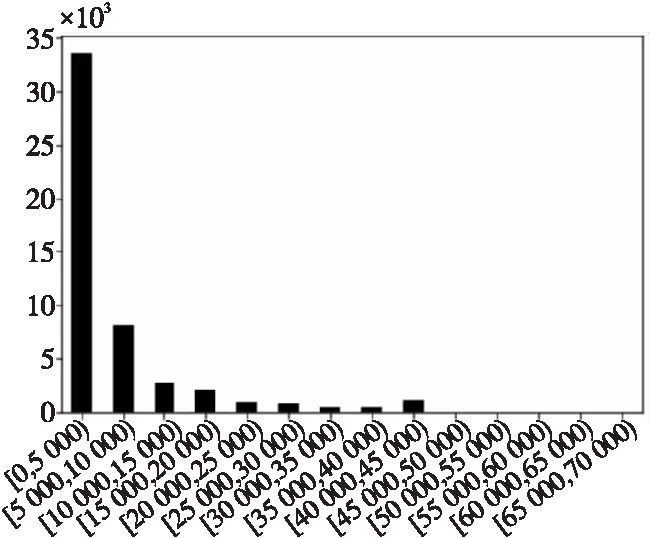
Figure 5 Runtime interval distribution on Dataset1图5 数据集1运行时间区间分布
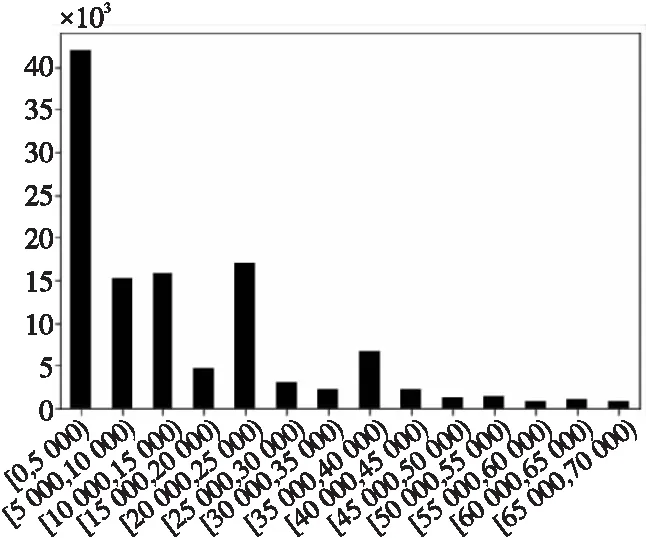
Figure 6 Runtime interval distribution on Dataset2图6 数据集2运行时间区间分布
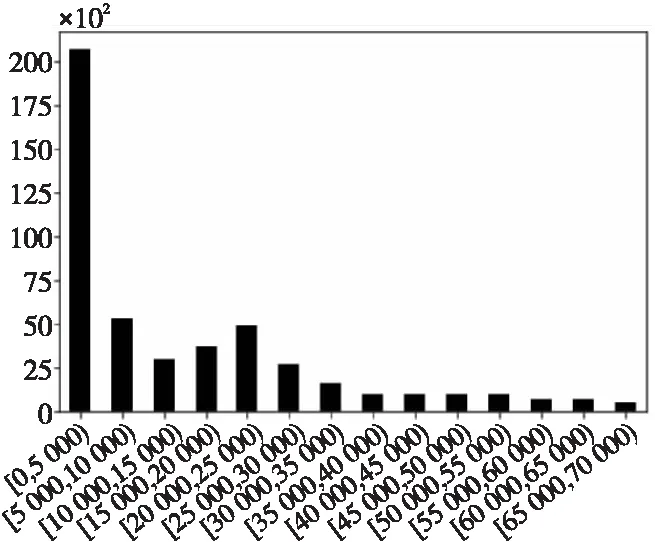
Figure 7 Runtime interval distribution on Dataset3图7 数据集3运行时间区间分布

表4 长短作业划分
从表4中可知,3个数据集中,数据集2的作业日志数最多,在各作业集上的样本数也均多于数据集1和数据集3的;数据集1主要由短作业样本组成,中长作业样本远少于短作业样本;数据集2和数据集3上各作业集的样本数则较为均衡。
在后续实验中,各作业集按照8∶1∶1的比例划分训练集、验证集和测试集。其中,训练集和验证集用于模型的训练,测试集用于评估模型的预测效果。
5.2 实验参数和评价方式
实验中网络参数的选择按照第3节中的预设为主:RNN和LSTM均使用3层网络,神经元个数为64;NR-Transformer使用的编码器和解码器均为3层,多头注意力中的h为8;优化器均使用Adam优化算法[27],初始学习率为0.001,Batch Size为128,时间步长为20。在训练时,使用Dropout来防止过拟合[28]。模型使用PyTorch框架实现,计算使用单块的NVIDIA Tesla V100显卡。
本文使用Huber函数作为目标函数[29]。该函数对平均绝对误差MAE(Mean Absolute Error)函数进行了平滑,避免训练时出现梯度爆炸的情况。
在模型预测效果的评测方式上,本文使用平均绝对百分比误差MAPE(Mean Absolute Percent Error)和平均预测准确率APA(Average Predictive Accuracy)2个指标。
在对模型预测的误差评估上,由于本文使用多种不同运行时间长度的数据集,因此难以直接用平均绝对误差衡量。平均绝对百分比误差则能较好地衡量预测值相比于实际值的偏离程度,其值越小,说明预测模型的预测精度越好。记测试集样本数为N,其MAPE计算如式(6)所示:
(6)
平均预测准确率是测试集上所有作业的预测准确率的平均值,单个作业的预测准确率计算如式(7)所示:
(7)
在整个测试集上的平均预测准确率如式(8)所示:
(8)
APA的值在0~1,其值越接近于1,说明预测值越接近于实际值。
5.3 实验结果
本文分别使用BP神经网络BPNN(Back Propagation Neural Network)、RNN、LSTM和NR-Transformer 4种神经网络结构进行实验。其中,BP神经网络用于和时序神经网络对比,其网络层数和神经元数与RNN的相同。
数据集分别使用4.1节中划分的各长短作业集,在每个作业集上,分别使用上述4种神经网络训练模型。在实际训练中,为防止训练时出现过拟合现象,本文使用了早停法,即在5个连续的训练周期中,如果验证集的损失函数没有下降,则提前结束训练。
由4.1节可知,数据集2上的作业样本数最多,且各作业集的样本量也较为均衡,因此本文对数据集2上的实验结果进行详细分析,再验证结论在数据1和数据集3上是否具有一致性。
图8和图9分别是4种神经网络在各测试集上的预测结果。由图可知,BP神经网络和其它3种时序网络相比,在各作业集上误差率较高,准确率较低。NR-Transformer网络则在各作业集上都有较低的百分比误差和较高的准确率,在长作业集上平均预测准确率达0.905。在该数据集上,NR-Transformer预测的结果和文献[13]中使用SVR等机器学习算法预测的结果相比,平均预测准确率提升了近0.2。
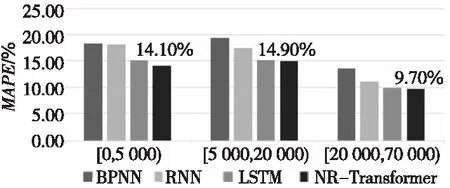
Figure 8 MAPE of each job set on Dataset2图8 数据集2上各作业集MAPE
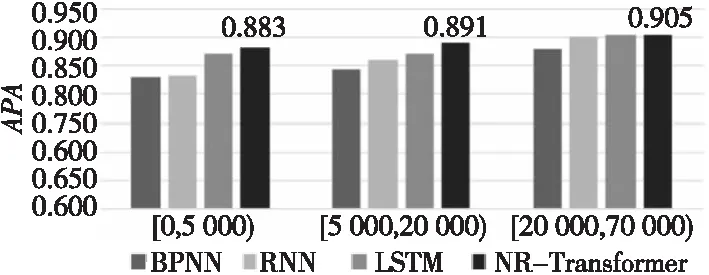
Figure 9 APA of each job set on Dataset2图9 数据集2上各作业集APA
图10和图11分别是BPNN和NR- Transformer在中作业集上的部分预测值和实际值的对比。从图中可以看出,BPNN没有充分学习到作业运行时间的变化规律,其预测值大部分为该作业集上运行时间的中值,也没有预测出作业运行时间的变化趋势;NR-Transformer则较好地从历史作业信息中学习到了作业之间的时序信息,对部分运行时间变化较大的点也有较高的预测准确率。

Figure 10 Comparison of values predicted by BPNN and the actual value图10 BPNN预测值与实际值对比

Figure 11 Comparison of values predicted by NR-Transformer and the actual value图11 NR-Transformer预测值与实际值对比
由上述分析可知,BPNN在实际预测中,难以学习到作业数据中的时序信息,因而平均准确率较低。而在时序网络中,LSTM通过门控结构、NR-transformer通过位置编码模块和自注意力机制都能获取到较长的作业历史信息,在平均预测准确率上高于RNN。

Figure 12 MAPE and APA on Dataset1图12 数据集1上的MAPE和APA

Figure 13 MAPE and APA on Dataset3图13 数据集3上的MAPE和APA
图12和图13是上述神经网络在数据集1和数据集3上的测试结果。可以看出,由于数据集上样本数量的差异,这2个数据集上各神经网络的整体预测效果均差于数据集2的。这说明深度神经网络往往需要较大量的数据,才能训练出较优的模型。在各作业集的具体表现上,各神经网络的性能和数据集2上的结果基本一致,BPNN和RNN的性能略差于LSTM和NR-Transformer的。数据集1的长作业集样本只有3 964个,在该作业集上,BPNN预测准确率只有0.67。可以看出,在样本量较小时,结构简单的BPNN难以学习到作业数据的特征;NR-Transformer的结果和RNN和LSTM的相比有较为明显的提升,说明该网络同样适用于小样本量数据。
图14是训练好的各模型在数据集2的测试集上预测所用时间的对比。从图14中可以看出,由于各区间的测试集数据量相近,因此模型在这3个作业集上的预测时间相一致。其中,BPNN由于结构简单,在3 000组测试数据上预测所用时间最少,最短时间只有0.15 s;LSTM结构较为复杂,且不能并行化执行,所用时间最长;NR-Transformer和RNN所用时间相近,预测3 000组测试数据用时在0.5 s左右,但在平均预测准确率上,NR-Transformer高于RNN的。在实际预测新作业的运行时间时,NR-Transformer能在较短时间内预测出准确的作业运行时间。
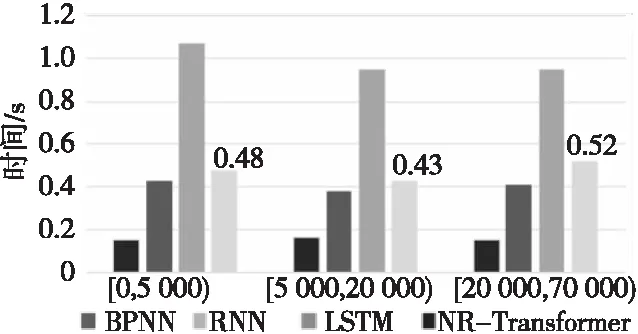
Figure 14 Prediction time of test dataset on Dataset2图14 数据集2上的测试集预测所需时间
综上所述,本文分别使用4种不同的神经网络结构在3个数据集上的不同作业集上进行了训练和预测。本文提出的NR-Transformer结构在多个作业集上的预测性能优于RNN和LSTM的,最高平均预测准确率达0.9,同时在样本数较少的作业集上也有较好的预测准确率,说明NR- Transformer能较好地用于作业数据的运行时间预测。在实际作业调度系统中,可以在考虑误差率的情况下,将NR-Transformer预测的运行时间作为作业的估计运行时间,配合回填算法提高集群的调度效率。
6 结束语
使用回填策略等算法提升高性能集群作业调度效率,需要准确的作业运行时间估计。本文从历史作业数据的相似性出发,先对集群用户进行聚类,将类别信息添加到作业特征中;再使用多种神经网络,在各作业集上进行训练和预测。实验结果显示,时序性神经网络在作业运行时间预测上有较高的平均预测准确率和较低的预测百分比误差。其中,本文提出的NR-Transformer结构在多个作业集上较RNN和LSTM网络都有更准确和更稳定的预测结果。
今后将在实际的高性能集群上试用NR-Transformer来预测作业的运行时间,并进一步改进,以提升集群的利用率。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
电子测试(2017年15期)2017-12-18 07:19:27
数学物理学报(2017年5期)2017-11-23 07:51:31
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
