
改进生成对抗网络在图片数据生成中的应用
2022-08-09 05:48曾志高朱艳辉朱文球易胜秋董丽君
计算机工程与应用 2022年15期
孟 辰,曾志高,朱艳辉,朱文球,易胜秋,董丽君
1.湖南工业大学 计算机学院,湖南 株洲 412008
2.湖南省智能信息感知及处理技术重点实验室,湖南 株洲 412008
近年来深度学习的发展解决了很多人工无法解决的问题,但在有监督学习中,人工标注训练集需要大量的成本。直到2014年Goodfellow提出了无监督学习GAN,它能够自动完成这个过程,且拥有较低的成本和较高的效率,之后各种GAN的模型被相继提出[1]。GAN能够完成一些使用传统方法很难完成的任务。在高分辨率图片生成领域,渐进式增长GAN(progressive growing of GANs,ProGAN)[2]和条件GAN(analyzing and improving the image quality of StyleGAN,StyleGAN2)[3]等架构表现出了出色的效果,在文本到图像合成任务上,StackGAN[4]也表现优秀,研究者社区已经对GAN及其应用广泛接纳。
GAN的网络架构由一个生成器网络和一个判别器网络组成,生成器和判别器两个网络之间进行多次迭代,互相对抗,试图战胜对方,从而得到训练。通过生成随机的一组一维向量,经过生成器网络,可以得到所需的图像、文本、音频、视频等数据,而判别器网络需要对输入的真实数据以及生成数据进行区分。通常,GAN中的判别网络是一个二分类的网络,将真实数据判别为1,将生成数据判别为0。训练开始时,判别网络可以很轻松地将生成数据和真实数据区分开来,然而生成网络经过不断地训练,判别网络越来越难将真实数据和生成数据区分开来,于是它就会训练自己的网络,使得判别能力提升,区分出真实数据和生成数据。在两个网络不断训练博弈的情况下,最终达到纳什均衡的状态[5]——判别器的准确率到达50%,即送来的真实数据和生成数据有一半的几率被误判,则此时的GAN就完成了训练。
在GAN的发展历程中,存在训练不稳定的问题,甚至有时完全不收敛,生成网络和判别网络的梯度在训练路径上发散。研究者们为了稳定GAN训练花费了很大的精力。本文中所提出的网络结构可以很好地使GAN的训练变得稳定,在图片数据生成中得到高质量的图片。
在本文中,做出了如下贡献:
(1)改进了原始GAN的结构,使得网络结构具有更高的稳定性、鲁棒性,它在训练中可以有效避免模式崩塌的问题。
(2)设计了一种多分类图片数据生成的网络结构,能够满足一个网络训练多种类图片数据生成的任务。
(3)设计了一种随时间匀速更新学习速率的算法,并将其应用在了本文的网络结构中。
1 研究背景
1.1 生成对抗网络(GAN)
GAN的博弈过程可以看作是一位数据制假者和一位数据鉴别者的博弈,数据制假者代表了GAN中的生成器,数据鉴别者代表了GAN中的判别器。在博弈过程中,数据制假者会一直提高数据制假能力,使生成数据达到以假乱真的地步,成功骗过数据鉴别者。而数据鉴别者的任务是提高自己的鉴别能力,找出真假数据间的区别,成功判别出数据的真假,从而给真实数据打上真的标签,给生成数据打上假的标签。
博弈的最开始,生成数据和真实数据会很容易被鉴别器区分开来,在生成器网络进行训练更新之后,生成数据的质量得到提高,让判别器难以辨别出生成数据与真实数据之间的区别。同时,判别器也得到训练,使得生成数据难以通过判别。在两个神经网络不断训练进步下,生成器的生成数据的数据分布逐渐与真实数据趋于拟合,判别器无法区分真实数据与生成数据,对送来的真假数据都有一半的误判几率,这个博弈过程,如式(1)所示:

式(1)中,G代表了生成器,D代表了判别器,V为式子的价值函数,V(D,G)相当于表示真实数据和生成真实的差异程度,意思是固定住生成器G,尽可能地让判别器D能够最大化地判别出样本来自于生成数据还是真实数据。表示固定住判别器D,训练生成器G,生成器G要将真实样本和生成样本的差异最小化,如图1所示。
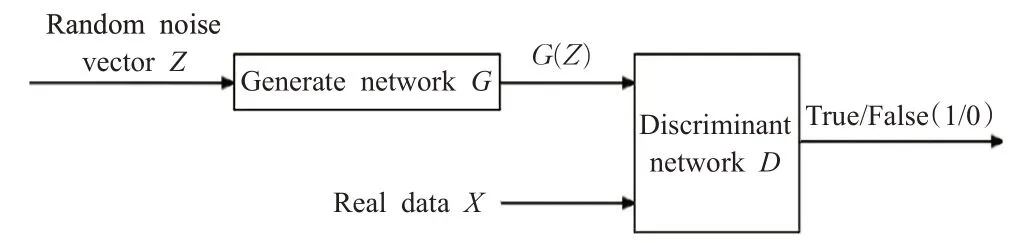
图1 GAN的基本结构Fig.1 Basic structure of GAN
1.2 改进的生成对抗网络模型架构
原始GAN的网络层使用了全连接层进行设计,训练生成的图片数据质量很差。DCGAN[6]使用了卷积层代替了GAN的全连接层,使用了带步长的卷积代替上采样层。DCGAN虽然有着不错的架构,但是没有解决GAN训练的稳定性问题,训练时仍需要小心平衡生成器与鉴别器的训练进程,如图2所示。
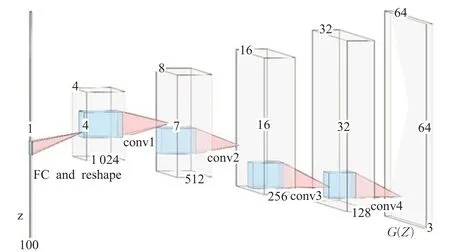
图2 DCGAN的网络结构Fig.2 Network structure of DCGAN
WGAN[7]对原始GAN的损失函数做了改进,使得网络模型在全连接层上也能得到很好的效果,并且提出了使用沃瑟斯坦(Wassertein)距离作为优化方式训练GAN,但为了使用Wassertein距离需要满足利普希茨(lipschitz)连续性,所以进行了权重限制,导致理论证明漂亮,但是实际的训练效果并不好。改进后的WGAN-GP[8]提出了使用梯度惩罚的方式以满足连续性条件,解决了梯度消失和梯度爆炸的问题。
改进的生成对抗网络采用了稀疏表达结构[9]和残差结构[10]组合的生成器网络模型,在生成器网络中,通过两个全连接层构建了4×4×64和24×24×64两种尺度的特征,在其中的4×4×64结构中构建了稀疏连接,引入了多尺度感受野(3×3,24×24)与多尺度融合,使得网络的表征能力上升。为了防止网络梯度在反向传播时产生梯度爆炸或梯度弥散,引入了残差结构,在梯度得不到更新时,梯度会通过短接层进行更新。稀疏表达结构和残差结构组合的策略会导致模型结构复杂,但是能获得生成更高图像质量的网络模型,生成器网络结构如图3所示。
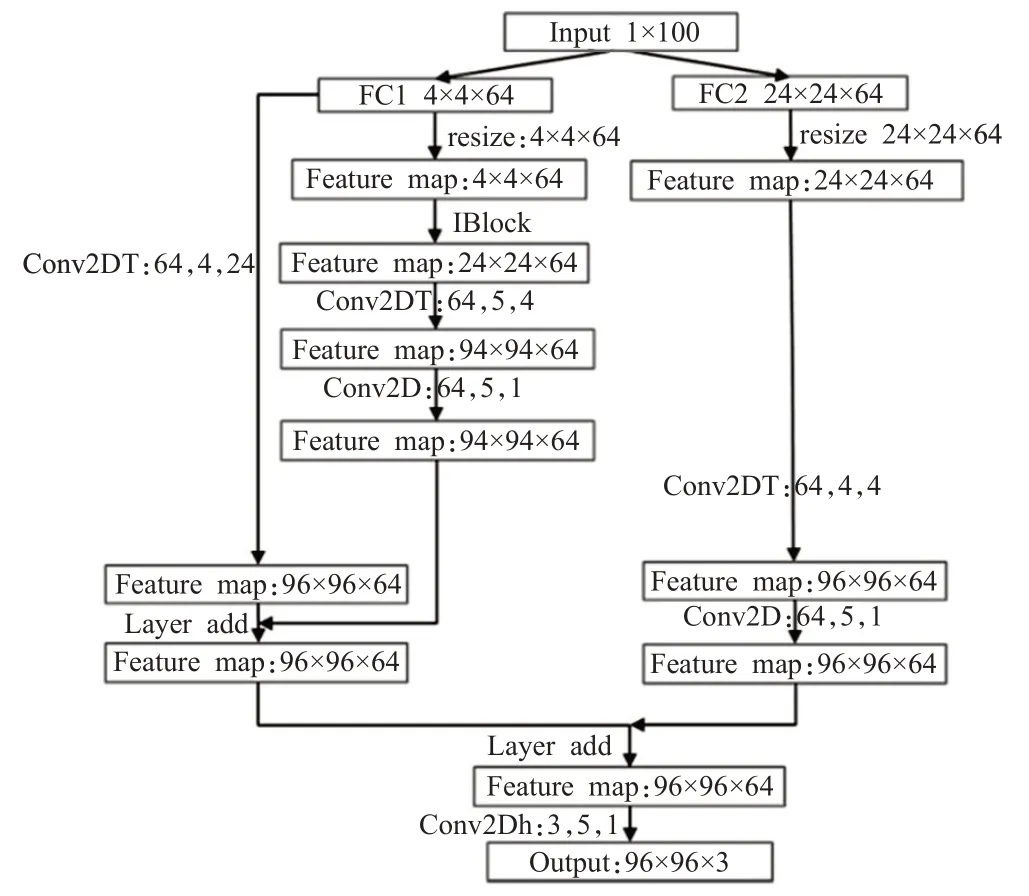
图3 改进的GAN(IGAN)生成器网络结构Fig.3 Improved network structure of GAN(IGAN)generator
在最开始,随机生成的100维向量,通过两个全连接层分别生成一个4×4×64和24×24×64大小的向量。4×4×64的向量重塑成一个通道数量为64的4×4的矩阵,在此时,4×4的矩阵经过多次卷积与反卷积生成通道数量为64的96×96的矩阵。同时,它还经过了一次反卷积生成了另一个通道数量为64的96×96的矩阵,生成的两个矩阵在通道数量维度进行相加,在后续梯度得不到更新的时候,将会通过残差层跳过中间层更新梯度。在右边,通道数量为64的24×24的矩阵也通过反卷积生成通道数量为64的96×96的矩阵,然后与左边生成的通道数量为64的96×96的矩阵在通道数量维度相加,生成一个通道数量为64的96×96的矩阵。最后,通道数量为64的96×96的矩阵经过一个卷积层,生成需要得到的96×96×3的图像。
改进的生成对抗网络构建了一组过完备特征集合。在原始的GAN中,100维特征向量经过全连接成生成了特征集合F(X)={x1,x2,…,x(4×4×64),原始特征集合F(X)经过网络模型不断地进行反卷积生成了输出特征集合F(Y)={y1,y2,…,y(96×96×3)},此时length(F(X))<l ength(F(Y))。改进的生成对抗网络在最初通过两个全连接层生成了两个特征集合,一个为F(X)={x1,x2,…,x(4×4×64)},另一个特征集合为F(X′)={x′1,x′2,…,x′(24×24×64)},此时,length(F(X))+length(F(X′))>length(F(Y)),它比之原始的GAN抽象出了更多的基础特征,这也是第二个全连接层取24×24×64的原因。
改进的生成对抗网络采用了多种不同的卷积核(24×24,4×4),使得网络拥有了不同的感受野,最后进行的两次拼接意味着多种尺度特征的融合。网络层中的短接层,使得训练后期网络仍然能够得到更新。
在每一个卷积(Conv2D)层和反卷积[11](Conv2Dtranspose)层的后面接了一个批规范化层[12](Batch Normalzation,BN)层和激活函数层(leaky relu[13])层,最后一个Conv2D层后面接一个BN层和激活函数层(tanh)层,如图4所示。
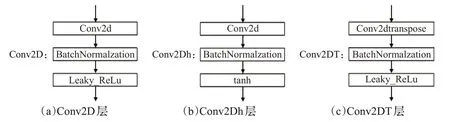
图4 模块名称Fig.4 Module name
在实际任务中,有时需要训练生成多种类图像数据,若每次只训练一种数据,则花费的时间会比较漫长。在多种类图像数据生成中,需要完成的任务比较复杂,需要使用更深的网络进行学习,故沿用IGAN的网络结构进行拓展,在每一层反卷积结束后添加一层通道数相同步长为1的卷积,增加网络的表征能力,并在24×24×64的模块后连接相应分类数量分支网络,并与另一模块生成的分支模块进行连接,得到如图5所示的二分类图像数据生成网络结构。

图5 二分类图像数据生成网络结构(IGAN_V2)Fig.5 Binary image data generation network structure(IGAN_V2)
网络中的IBlock结构由两个上卷积层构成,如图6所示。
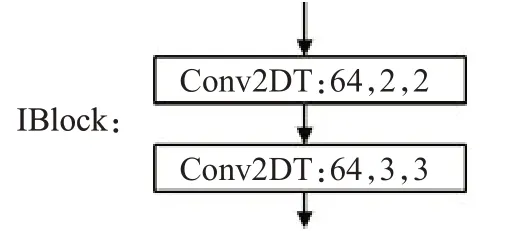
图6 IBlock网络结构Fig.6 IBlock network structure
由此基本结构可以拓展出更多图片种类数据生成的网络结构,图7为N分类图像数据生成网络。
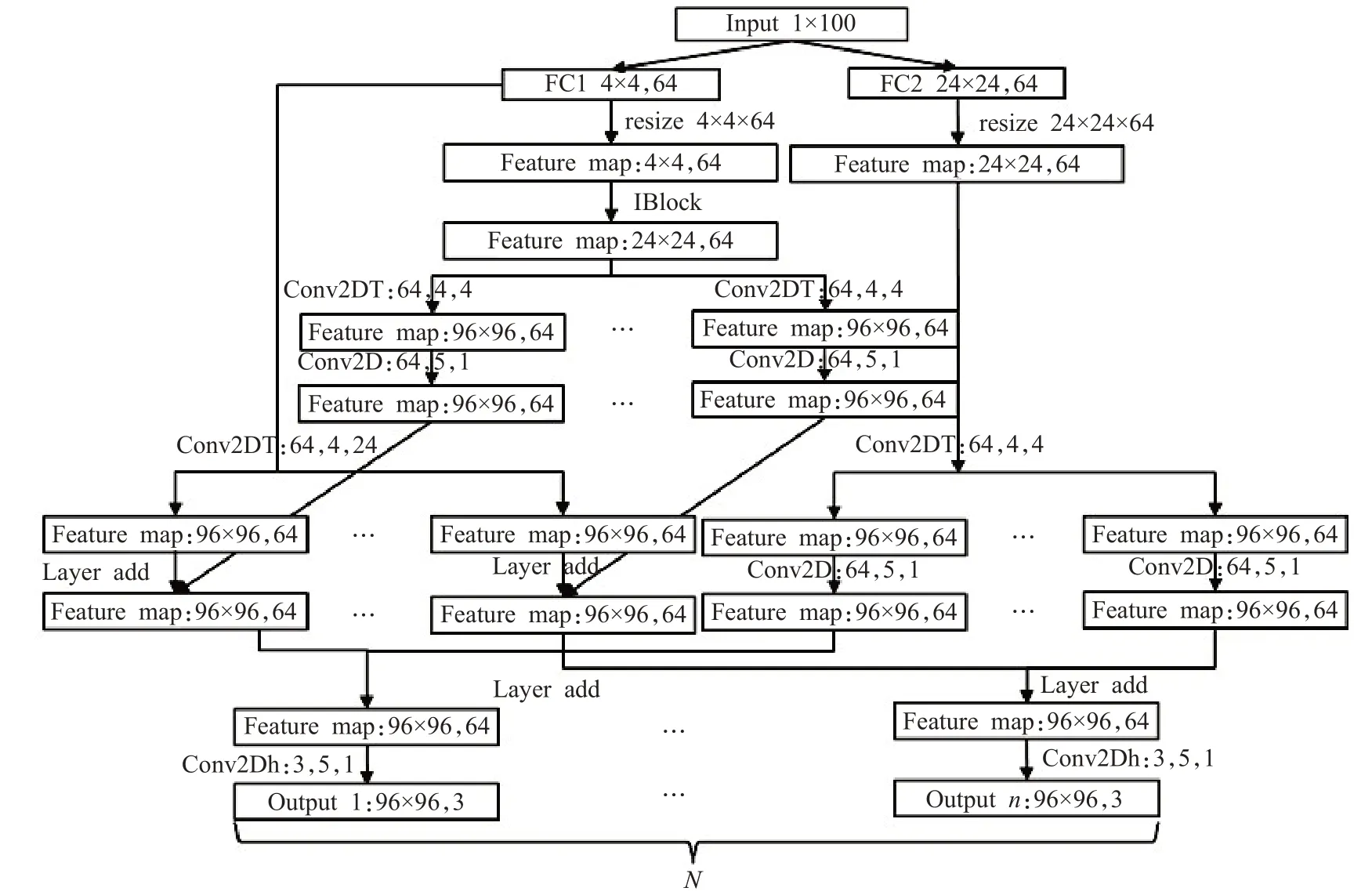
图7 N分类图像数据生成网络结构(IGAN_VN)Fig.7N classification image data generation network structure(IGAN_VN)
判别器采用如图8的网络结构,它将输入的图片数据经过一个残差网络进行分类,判断输入数据为生成数据还是真实数据。在多分类图像数据生成中,生成几分类图片数据,就使用多少个判别器。
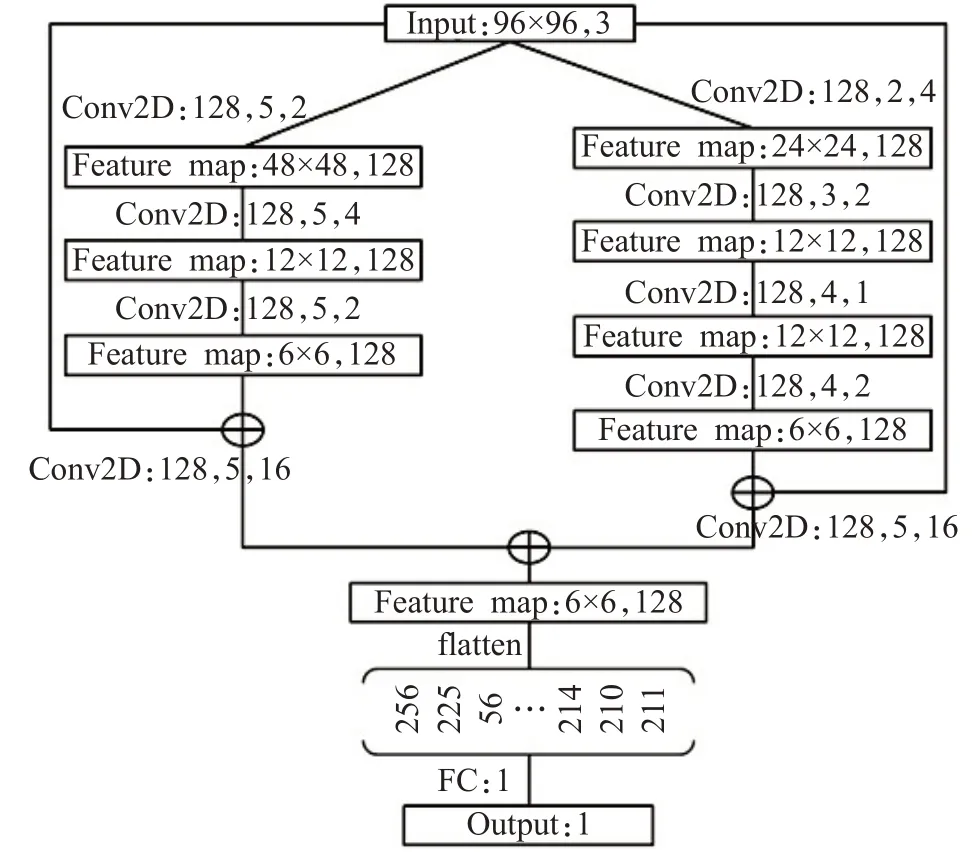
图8 IGAN判别器网络结构Fig.8 Network structure of IGAN discriminator
可以看到,判别器网络结构比生成器网络结构要简单,其原因是因为判别数据的难度要比生成数据的难度要小得多,如果使用复杂的判别网络,判别损失会迅速下降到一个很小的数值,使得网络不再更新,同时也为了降低对显卡的要求。如图9所示,网络中的每个卷积块包含一个卷积层和一个批归一化层以及LeakyRelu层。在之后还会采取一些调参技巧(trick)来平衡网络大小不平衡的问题。
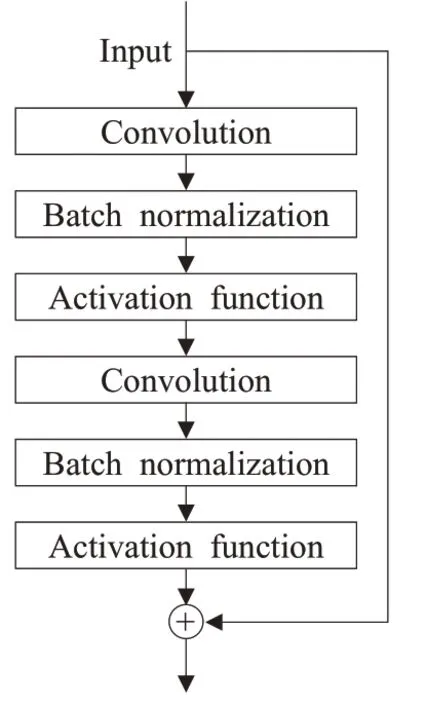
图9 残差块基本结构Fig.9 Basic structure of residual block
2 研究方法
2.1 实验数据准备
本文使用的数据集为Fashion-MNIST、MNIST、CelebA,以及LSUN-bedrooms数据集,实验中的LSUN数据集以及CelebA数据集都经由程序处理成统一的96×96的大小,可将数据预处理或在训练中实时处理,为了在程序运行时,可以减小程序资源的开销,节省时间,本文采用了预先处理。
2.2 网络中的参数设置
2.2.1 使用动态学习速率
在GAN的训练中,生成器最开始拟合的数据分布距离真实数据分布较远,需要使用较大的学习速率进行训练,加快网络的收敛[14]。随着生成的数据分布不断接近真实分布,学习率需要随着训练的进行不断减小,提高网络的稳定性,避免学习率过大跳过最小值。
在学习率的选择上,一般采取以下四种方式:
(1)使用固定的学习速率。

(2)每迭代step次后学习率减少gamma倍。

(3)学习率呈多项式曲线下降。

(4)学习率随迭代次数增加而下降。
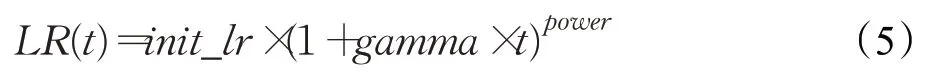
实验中采用了第四种策略的变体。
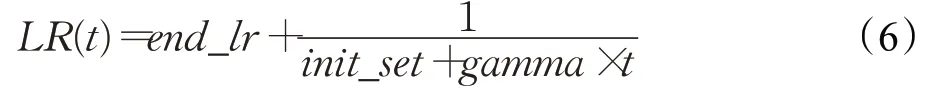
此时:
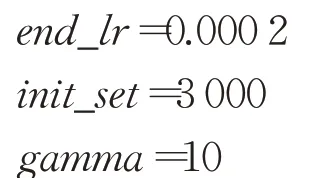
在式(6)中,end_lr为最后的学习速率,end_lr+为最初的学习速率,gamma为学习速率衰减率,通过控制end_lr、ini t_set、gamma可以动态地控制学习速率,图10为学习速率衰减曲线。

图10 动态学习速率曲线Fig.10 Dynamic learning rate curve
2.2.2 单侧标签平滑
在原始GAN的训练中,分类器的标签只使用0或者1、0代表生成数据,1代表真实数据。标签平滑是指将标签处理成α(真)、β(假),而不是采取0(假)和1(真)的处理方式。此时,GAN的损失函数变为式(7):
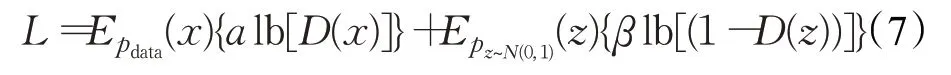
在实际训练中,去掉了log函数,此时,GAN的损失函数变为式(8):
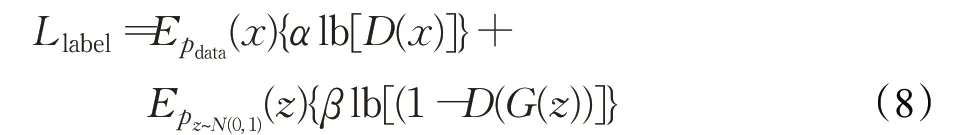
其最优解D(x)变为:
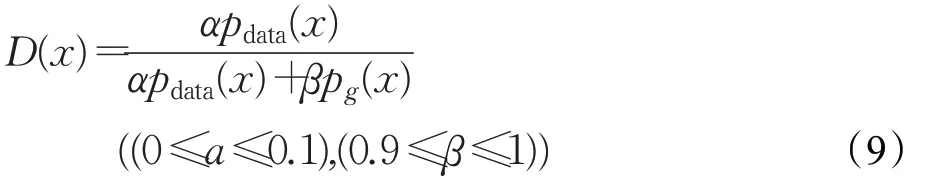
真实数据和生成数据都需要进行平滑处理,有助于GAN进入纳什均衡状态、损失函数得到收敛、增加程序的鲁棒性。
2.2.3 批归一化(batch normalzation)
批归一化技术是将特征向量归一化,把非线性函数映射后向取值区间饱和区靠拢的输入分布,调整至均值为0、方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,避免梯度消失。该技术可提高学习过程的稳定性,以及解决权重值初始化效果差的问题。将该技术作为预处理步骤应用于神经网络的隐藏层,有助于缓解内部协变量转移的问题,如图11所示。
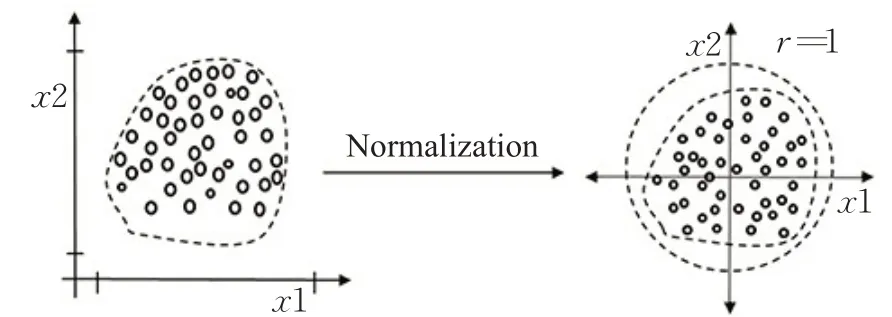
图11 数据经过BN层后数据分布示意图Fig.11 Diagram of data distribution after data passing through batch normalization(BN)layer
批归一化需要对所有隐藏层应用,而不仅仅是输入层使用。
2.2.4 工程手段
在实际应用中,一些调参技巧对图像质量的改进拥有不错的效果,在本文实验中,采取了如下调参技巧。
(1)在判别器进行数据输入时,将输入图像的数值范围限制在[-1,1],在最后输出图像时再还原成[0,255],归一化限定了输入向量的最大值跟最小值不超过隐层跟输出层函数的限定范围。
(2)在生成数据以及真实数据送入判别器之前,给其分别加入一个高斯噪声[15],这样可以有效提高程序的鲁棒性。
(3)给所有的随机数设置一个随机数种子,以便于之后的实验复现。
(4)由于网络复杂度的不平衡,在训练一次生成器之后训练三到五次判别器,可以有效平衡两个网络。
(5)在反卷积时使用PixelShuffle和转置卷积进行上采样[16],避免较大化池用于下采样,使用带步长的卷积,减少梯度稀疏。
(6)给生成器与判别器设置不同的学习速率[17],通常生成器的学习速率设置的大一点,实验中将生成器学习速率设置为判别器的1.5倍。
(7)激活函数选择使用Leaky_ReLu代替ReLu避免梯度稀疏[18]:

激活函数示意图如图12所示。
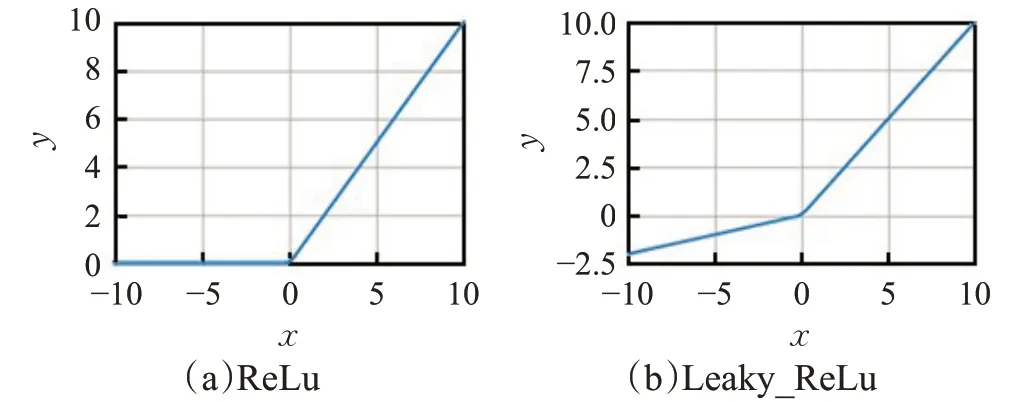
图12 激活函数示意图Fig.12 Activation function diagram
(8)选择ADAM作为优化器加快训练。
(9)实际代码中用反转标签来训练G更有效[19],即让生成图片使用真实的标签来训练,而真实数据使用生成数据的标签进行训练。
此时,GAN的损失函数变为:
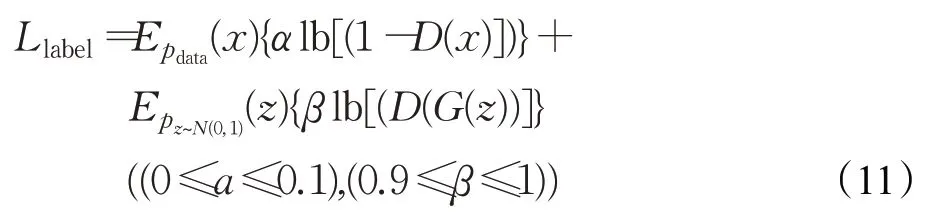
(10)在发现损失值不变时,或者生成图像质量不好时,不要终止训练,GAN的训练非常耗时,多等等会得到好的结果。但是在判别器的损失快速接近0的时候,可以终止训练、调整网络、重新训练。
(11)加入一个惩罚项来惩罚那些和历史平均权重相差过多的权重值,本文采用的是WGAN-GP中的梯度惩罚,梯度惩罚损失函数如式(12)所示,其中x͂为真实样本,x为生成样本。
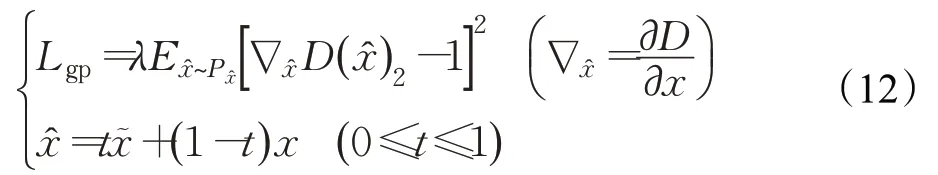
(2)使用随机失活技术——DropOut,也是为了引入一定的噪声,在生成器的某几层中使用DropOut,增加网络的鲁棒性[20],如图13所示。
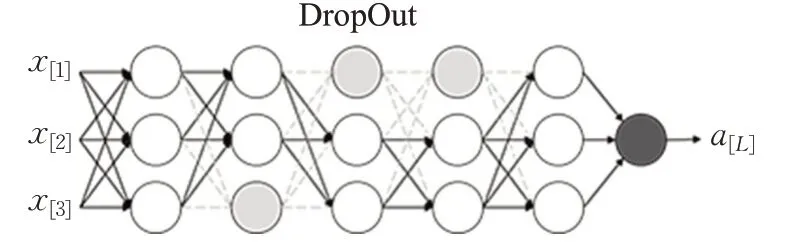
图13 DropOut示意图Fig.13 DropOut diagram
3 实验
3.1 实验配置
生成网络和判别网络架构由1.2节所示。损失函数L=Llabel+Lgp,Lgp中惩罚因子λ设置为5。一轮训练大小设置为64,因为数据集大小过大,一个轮次设置为一个批次数据的学习时间,而不是跑完整个数据集所用的时间。学习速率设置为动态学习速率,每100轮保存一次权重以及可视化输出结果查看训练情况,每30轮保存一次损失值。所用机器为NVIDIA 2 070 s,内存32 GB,使用的深度学习的框架为tensorflow2.0。
3.2 简单数据集训练情况
MNIST(手写数字数据集)包含了60 000个用于训练的示例和10 000个用于训练的示例,这些数字已经经过标准化并位于图像中心,为值0到1的28×28大小的图像。Fashion-MNIST(服饰数据集)包含了70 000张28×28的灰度图像,其中包含了60 000个图片的训练集以及10 000个图片的测试集,共包含了10类图像。在MNIST(手写数字识别数据集)和Fashion-MNIST(服饰数据集)等简单数据集上,IGAN和IGAN_v2都能取得不错的结果,图14为在IGAN网络和IGAN_v2网络上MNIST的生成结果,图15为在IGAN网络和IGAN_v2网络上Fashion-MNIST生成结果。

图14 模型在MNIST数据集上生成结果Fig.14 Model generates results on MNIST dataset

图15 模型在Fashion-mnist数据集上生成结果Fig.15 Model generates results on fashion MNIST dataset
在训练这类简单数据集的时候,如直接使用0.000 2的学习速率,判别网络的损失将会锐减至很小,导致不能指导生成网络的参数进行更新,所以需要将最开始的学习速率调成0.002,然后逐步衰减至0.000 2,可使用2.2.1小节中的动态学习速率。
可以看到,经过IGAN与IGAN_V2的网络,生成的结果可以清楚地判别出它的类别,生成质量优秀。
3.3 名人人脸属性数据集(CelebA)训练情况
在GAN中,应用最多和最全的便是人脸数据生成,数据集采用了名人人脸属性数据集——CelebA,其中包含了10 177个名人身份的202 599张人脸图片,该数据集经过预处理成96×96×3大小后分别送入IGAN与IGAN_v2网络进行训练,得到了如图16、图17的高质量人脸图片。

图16 IGAN在CelebA数据集上生成结果Fig.16 IGAN generates results on CelebA dataset

图17 IGAN_v2在CelebA数据集上生成结果Fig.17 IGAN_v2 generates results on CelebA dataset
在图中可以发现,人物的肤色光影可以很好地生成出来,这说明图像数据生成的质量和多样性能够得到保证。而且在训练中,网络生成的背景趋于同一种颜色,保证了生成图像的真实性。
3.4 大规模图像数据集(LUSN)训练情况
LUSN Dataset是一个大规模图像数据集,包含了10个场景类别和20个对象类别,共计约100万张标记图像,本文使用了LUSN Dataset数据集中的bedding-room类别的训练部分数据集。在这些数据集中,能否生成优秀的图像是一个大的挑战。
将图片预处理成96×96×3大小的数据集,然后经过IGAN与IGAN_v2神经网络的训练,分别得到如图18、图19所示的生成样本。

图18 IGAN在LUSN数据集上生成结果Fig.18 IGAN generates results on LUSN dataset

图19 IGAN_v2在LUSN数据集上生成结果Fig.19 IGAN_v2 generates results on LUSN dataset
可以看到,图像中的窗户、门、床,甚至是挂饰也可以比较不错地生成,但是其中也会出现一些图片训练的有些失败,这也是在训练GAN时必然会碰到的问题,即图像越复杂,生成难度越高,生成质量越差。
3.5 实验评估
3.5.1 评估方式介绍
在GAN进行了图像生成任务后,需要一个度量指标来衡量生成的图像是否优秀,在进行一项任务的度量时,不能完全靠主观判断对图像进行是否优秀的判断,从以下两方面来考虑:
(1)图片自身的质量(是否逼真,是否清晰,内容是否完整)。
(2)多样性。在一项任务中,生成网络所产生的图片是多种多样的,如果只产生一种或者几种类型的图像,将会出现模式崩溃(mode collapse)的现象。
进行图像评价时,一般使用如下两种常用的评价指标,IS(inception score)和FID(fréchet inception distance)[21]。
但是IS评价标准的Inception V3权重是在ImageNet下训练出来的,而本文中使用了其他四个数据集生成图像,这种跨数据集的计算IS是错误的,所以在利用ImageNet以外的数据集计算IS时,得出的结果没有意义。
为了克服IS评价的缺点,本实验中使用FID进行评价。FID可以计算真实图像和生成图像的特征向量距离的一种度量,特征向量由Inception V3 Network所得到,它使用的是Inception V3 Network分类网络倒数第二个全连接层的输出的1×1×2 048维图像特征向量进行距离度量。
这个距离可以衡量真实图像和生成图像之间的相似程度,FID值越小,相似程度越高,在FID=0时,两个图像相同。
使用式(13)计算数据的FID:
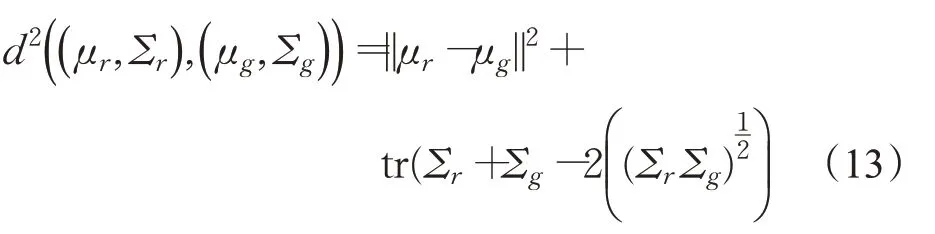
其中,tr表示矩阵对角线上元素之和——迹(trace)。均值为μ协方差为Σ。此外r表示真实图片数据,g表示生成图片数据。
FID对模式崩溃更加敏感。相比较IS来说,它的对比用到了生成数据和真实数据,比IS更加灵活,而且可以使用不同的数据集进行训练。
3.5.2 评分结果
受限于设备和数据集的大小,不能将整个数据集与生成的图像进行对比,为保证公平性,将抽取数据集中的一部分样本与生成样本进行FID计算,抽取样本的大小为10 000,实验结果如表1所示。
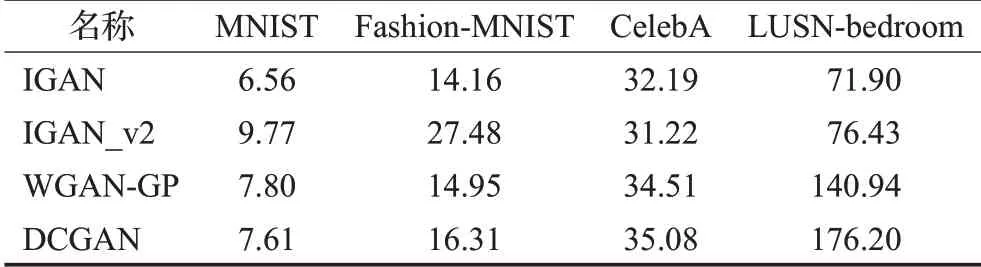
表1 FID分数Table 1 FID score
由表1可以看出,IGAN在简单以及复杂的数据集上表现都很优异,而IGAN_v2在简单数据集上的效果并不理想,因为它复杂的网络在小数据集上很难得到收敛,而在复杂数据集上,它的表现和单分类生成同样优秀。
3.6 主观评价
在图像生成领域最直观的还是主观评价,客观量化至今还存在着各种问题。图20、图21为IGAN生成图像,图22、图23为IGAN_v2生成图像,图24、图25为WGAN-GP生成图片,图26、图27为DCGAN生成图像。

图20 IGAN在CelebA数据集生成图像Fig.20 IGAN generates results on CelebA dataset

图21 IGAN在LUSN-bedroom数据集生成图像Fig.21 IGAN generates results on LUSN-bedroom dataset

图22 IGAN_v2在CelebA数据集生成图像Fig.22 IGAN_v2 generates results on CelebA dataset

图23 IGAN_v2在LUSN-bedroom数据集生成图像Fig.23 IGAN_v2 generates results on LUSN-bedroom dataset

图24 WGAN-GP在CelebA数据集生成图像Fig.24 WGAN_GP generates results on CelebA dataset

图25 WGAN-GP在LUSN-bedroom数据集生成图像Fig.25 WGAN_GP generates results on LUSN-bedroom dataset

图26 DCGAN在CelebA数据集生成图像Fig.26 DCGAN generates results on CelebA dataset

图27 DCGAN在LUSN-bedroom数据集生成图像Fig.27 DCGAN generates results on LUSN-bedroom dataset
从这些图可以看到,四组生成结果之中,IGAN与IGAN_v2网络的生成效果最佳,DCGAN中还出现了模式崩溃的问题,生成了模糊重复的图片。在客观量化手段还不能完全替代主观判断的今天,主观判断仍然是图像生成质量评价的一大手段。
3.7 结论
实验在两种类型的数据集之间进行了对比,分别是简单数据集——手写数字数据集(MNIST)、服饰数据集(Fashion-MNIST),以及复杂数据集——名人人脸属性数据集(CelebA)、大规模图像数据集(LUSN)。在简单数据集上,对比于其他的网络模型,IGAN与IGAN_v2几乎不需要进行调参,而其他的GAN需要经过精心的调参才能达到接近的效果。在复杂的数据集上,IGAN和IGAN_v2达到了最佳生成质量效果,这和它复杂强大的网络模型是分不开的。在进行真实实验场景应用时,如果需要生成简单数据集数据且没有相应的计算资源时,可以使用传统GAN架构。在进行复杂图像任务,并且拥有计算资源的情况下,推荐使用IGAN的架构,它更适合复杂的图像任务。
4 未来研究方向
在完成了现有的工作后,可以发现,GAN在很多领域具有广阔的应用前景,甚至在一些领域还是一片蓝海。
(1)在进行有监督学习的时候,神经网络需要大量的数据,而获取这些数据的成本却十分高昂,耗时耗力。在只有一个小规模数据集时,一旦训练好一个GAN,就可以使用GAN来生成大量的数据,用来进行训练,可以节省很多精力。
(2)在设计领域,设计过程不仅耗时耗力,而且需要具备专业技能。借助人工智能和GAN,可以进行各种各样的设计,或者生成初始数据供设计师启发灵感,可以节省大量的时间成本。
(3)在多分类图像生成网络结构中,由于生成器结构复杂,且每一分类的图像生成对应一个不同的判别器,导致特别耗费GPU资源,在之后可以对网络结构进行优化,使得计算资源的使用更加合理。
近些年来,研究者们研发出了数以百计的GAN架构,GAN的领域不断变得丰富,今后将继续研究,并设计新的架构,不断完善GAN的能力,使GAN的应用落地。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
西安邮电大学学报(2020年1期)2020-12-17
计算机系统应用(2019年9期)2019-09-24
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
