
基于ALBERT-UniLM模型的文本自动摘要技术研究
2022-08-09 05:47孙宝山
计算机工程与应用 2022年15期
孙宝山,谭 浩
1.天津工业大学 计算机科学与技术学院,天津 300387
2.天津市自主智能技术与系统重点实验室,天津 300387
随着我国新一代5G通信技术的快速发展,用户的信息数据已经呈指数级的增长,如何从海量的日常生活信息中快速有效地提取出用户需要的有用信息,已成为当下亟待解决的问题。文本自动摘要技术是指在保证保留原文关键信息的情况下,快速地精简源文本,并根据其主要内容来生成短文本摘要,有效地为人们快速获取信息提供了很大的便利。
文本摘要技术按照摘要的实现方式可分为抽取型摘要和生成型摘要。抽取式摘要方法主要通过对原文中的词句进行排序组合,抽取出能够代表原文主要信息的短语、句子以形成摘要。生成式摘要方法主要通过使用编码器获得原文上下文的特征信息,综合分析原文的信息后通过算法自动生成一个新句子作为一篇文本摘要。随着语言模型BERT的推出,基于神经网络的文本自动摘要技术得到了广泛关注并取得了显著效果。文章的创新点及贡献如下:
(1)文章将词向量模型ALBERT与统一预训练模型UniLM相结合,提出一种处理文本生成任务的自动摘要模型ALBERT-UniLM。该模型采用ALBERT模型替代传统BERT基准模型,大幅降低模型预训练参数的同时保证有效地进行特征提取获得词向量;将融合指针网络的UniLM模型对下游文本生成任务微调,结合覆盖机制降低重复文本生成,获得文本摘要。使得ALBERTUniLM摘要模型适用摘要生成任务。
(2)文章选取NLPCC-2018单文档中文新闻摘要评测公开数据集。实验结果表明,ALBERT-UniLM模型与传统文本摘要相比,所得实验结果在3个Rouge评测指数均有明显提高,证明了该模型的有效性与优越性。
1 相关工作
文本自动摘要研究作为自然语言处理领域的重要研究任务,科研工作者已对其进行了长期的研究。随着机器学习以及自然语言处理的快速发展,众多准确高效的文本摘要算法被提出。2015年,Rush等[1]受到了采用先进的深度学习技术来直接实现机器翻译的技术启发,使用序列-序列模型生成文本摘要,有效地解决了由一个单句的摘要产生标题的问题。Nallapati等[2]在2016年提出了一种基于循环神经网络的序列-序列模型的方法来研究和解决生成摘要的问题。2017年,See等[3]首次提出指针及覆盖网络机制。在摘要片段生成的过程中,通过指针控制从原文中选择生词或者是从字表中选取生词进行生成,解决了摘要片段生成中可能出现的未注册登录的生词问题,并且引入了一种覆盖机制来有效地解决摘要中的片段重复问题。Tan等[4]提出了一种基于视图的注意力机制的神经模型。2018年,Lin等[5]首次提出了一种基于序列-序列模型的卷积神经网络,用来在文章层次上获得语义表示,以减少摘要生成时的语义无关。利用VSM对自动文本摘要进行词汇相似度测试,并对自动文本摘要实现的效果进行比较。Ren等[6]使用了层级注意力计算句子相似度,提出基于篇章关系的抽取式摘要模型。利用预习语言模型的思想,Yu等[7]提出了一种基于预测下一句子的文本摘要任务预习语言模型。基于预训练语言的模型BERT[8],Liu等[9]对抽取式摘要方法进行了微调,并通过简单的模型结构得到了较好的实效。Lan等[10]提出ALBERT模型,该模型是基于BERT模型的一种轻量级预训练语言模型,采用双向Transformer模型[11]获取文本的特征表示。
上述可见,尽管抽取式摘要方法已被验证有很好的效果[12-15],然而基于Seq2Seq框架的生成式文本摘要模型更适合于短文的生成,而不适合长文本。虽然自编码双向语言模型BERT在自然语言理解方面取得了较好的效果,但是它在文本生成方面的性能变现欠佳,且存在模型预训练参量较大等问题。
本文提出的ALBERT-UniLM模型适用于中文长文本,显著降低参数量的同时并对BERT模型在生成文本任务中的欠缺表现加以改进,有效提高了模型生成文本摘要质量。
2 本文模型与方法
本文所提出的ALBERT-UniLM模型将ALBERT预训练语言模型[16]与UniLM模型[17]相结合,其主要分成两个阶段实现,即基于ALBERT预训练模型的词向量参数获取阶段以及融合指针网络的UniLM模型的摘要生成阶段。ALBERT-UniLM模型第一阶段利用预训练语言模型ALlBERT获取源文本的词向量,得到输入序列;第二阶段将得到的输入序列输入到融合指针网络的UniLM模型Seq2Seq LM进行微调,并使用覆盖机制减少生成重复文字,得到文本摘要。
2.1 基于ALBERT预训练模型的词向量获取阶段
将文本输入到模型中进行处理,需要先使用编码器对文本进行特征提取。ALBERT模型是基于BERT模型的一种轻量级预训练语言模型,采用双向Transformer编码器(Trm)获取文本的特征表示,其模型结构如图1所示。其中,E1,E2,…,E N表示文本序列中的字符,通过多层双向Transformer编码器的训练后,得到文本序列的特征向量表示T1,T2,…,T N。
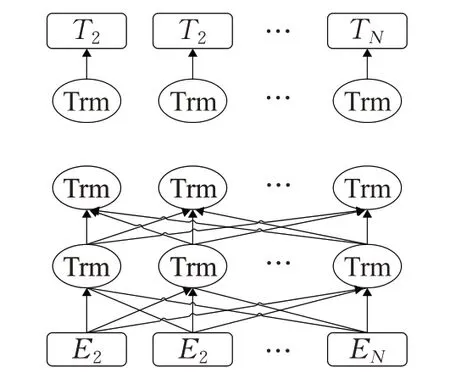
图1 ALBERT模型结构Fig.1 ALBERT model structure
基于自注意力机制Seq2Seq框架的Transformer模型,其结构为编码器-解码器,模型结构如图2所示。ALBERT采用其编码器部分,编码器由N个相同的网络层堆叠而成,每个网络层有两个子网络层:第一层为多头自注意力层;第二层为前馈网络层,用于融入词语的位置信息。自注意力机制的输入部分通过Query向量和Key向量相乘来表示输入部分字向量之间的相似度。另外,每个子层网络中都有Add&Norm层,将本层的输入与输出信息相加进行归一化处理,并在两层网络子层中使用残差进行网络连接,进而得到句子中所有词向量的权重求和表示。这样得到的词向量结合了上下文信息,表示更准确。计算方法如下:

图2 Transformer模型结构Fig.2 Transformer model structure

其中,W o是附加权重矩阵,能使拼接后的矩阵维度压缩成序列长度大小;Q、K、V分别表示输入文本序列中的Query、Key和Value向量。Q、K、V的权重矩阵分别为W Qi、W Ki、W Vi;每个词的Query和Key向量的维度用d k来表示;归一化激活函数为Softmax(·),z则用来表示N维的行向量。
2.2 融合指针网络的UniLM模型摘要生成阶段
UniLM模型是一款统一预训练模型,其能够同时完成三种预训练目标,即通过单向、双向、序列到序列三种训练方式进行预训练。UniLM模型架构基于BERT基准模型结构实现,通过不同的Mask方式实现不同的训练任务。因此该模型不仅可用于语言理解任务,还可以用于自然语言生成任务。表1为常用预训练模型[18-24]的机制对比。

表1 常用预训练语言模型对比Table 1 Comparison between language model(LM)pre-training objectives
相较于单向语言模型ELMO、GPT以及双向语言模型BERT,UniLM模型的优势在于模型中三种不同训练目标的Transformer模型网络参数进行共享,避免了训练过程中模型过拟合于某一语言模型,使得学习得到的文本表征更具普适性。另外,由于UniLM模型引入了序列到序列语言模型,使得该模型在完成语言理解任务的同时,也能出色地完成语言生成任务。
Transformer是UniLM模型中的核心框架,针对自然语言生成任务,UniLM模型首先对解码器中的词随机进行掩码,然后再进行预测。即将给定的文本输入序列输入至UniLM模型,模型根据上下文信息获得每个遮蔽的向量表征。为能够从输入的文本中获取更多的重要信息,文章在UniLM模型中引入指针网络及覆盖机制。模型生成关键词与指针生成网络从输入文本中复制词的功能相结合,有效提高了生成新闻标题的丰富度。
2.2.1 输入表征
针对文本生成任务,经过文本数据清洗及预处理后文本数据集,选取输入文本序列X,在序列的文本起始处插入起点标记([SOS]),并在每段文本序列的末尾插入结束标记([EOS])。标记[EOS]可让神经模型学习到在文本生成任务解码过程的时间。模型表征输入时将文本通过WordPiece进行子词标记。针对每个输入遮蔽,凭借与之对应的遮蔽嵌入、位置嵌入以及文本段嵌入进行求和运算得到相应的矢量表示。
2.2.2 指针生成网络
解码器解码时,每一个时刻t通过复制指针pgen控制预测词是从词表中生成还是从文本中复制。指针pgen计算方式如式(5)所示:

其中,K t、V t是解码器t时刻提取的文本特征向量,Qt是解码器t时刻提取的文本摘要特征向量,WTQ、WTK、WTV、bptr是学习参数,σ是Sigmoid激活函数。
融合指针网络模型的解码器,可以通过指针pgen选择从文本中直接复制关键信息词。计算词表的分布概率前,先将文本中的未登录词提取出来扩充到词表中构建新的词表,然后再计算t时刻预测词w的分布概率。计算方式如式(6)所示:

可知,若预测词w是未登录词,pvocab(w)则为零。使得预测词w可以仅从文本中生成。当中,αt是文本序列对解码器t时刻预测词的注意力分布权重,通过解码器提取摘要获取的Q特征矩阵与编码器提取文本中得到的K、V特征矩阵计算而得。计算方式如式(7)、(8)所示:

因文本中可能存在多个w i都为预测词w的情况,因此计算词表概率时需要将所有预测词w的注意力权重进行累加,如公式(6)所示。
为了解决生成词语重复的问题,本文引入覆盖机制。通过覆盖机制对指针生成网络模型进行改进,能够有效减少生成摘要中的重复。向量c t公式如下:

c t表示目前为止单词从注意力机制中获得的覆盖程度。使用覆盖向量c t影响注意力分布,重新得到注意力分布a t。其中,解码器当前时间步对所有时间步的关注程度为e ti,计算公式如下:

2.2.3 模型微调
模型微调部分采用UniLM模型中Seq2Seq框架结构处理文本摘要自动生成任务。微调下游任务与预训练任务中使用自注意机制掩码相似。设定文本中源序列S1及目标序列为S2。使其与特殊遮蔽相整合,得到输入序列「[SOS]S1[EOS]S2[EOS]」。
本文模型的微调结构如图3所示。微调任务通过对目标序列中设置比例的遮蔽进行随机覆盖,使模型学习还原被遮蔽的词进行任务微调。基于前后文本被遮蔽的最大似然度得到文本摘要。

图3 ALBERT-UniLM模型微调结构Fig.3 ALBERT-UniLM model fine-tuning structure
3 实验与分析
3.1 实验数据集
本文的实验部分使用2018年CCF国际自然语言处理与中文计算会议提供的NLPCC2018中文单文档新闻摘要评测数据集,其样本来自于今日头条的新闻数据,是广泛使用的中文开放评测数据集。该数据集信息统计如表2所示。
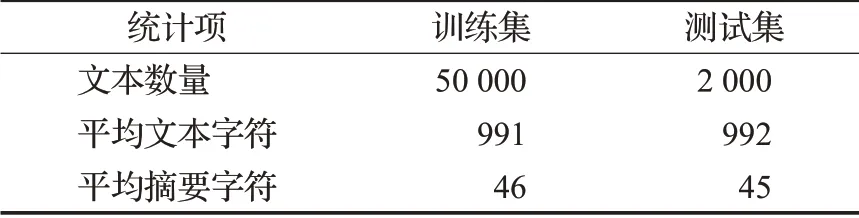
表2 NLPCC2018数据集信息统计Table 2 NLPCC2018 data set information statistics
3.2 评价指标
该文使用由Lin等[25]发表的ROUGE自动摘要评价算法,该算法是评估自动文摘的重要评价参数。该评测方法基于文本摘要中共现N元词(N-gram)的摘要信息进行评测,表示为ROUGE-N(N值可为1、2、3、4等)、ROUGE-L、ROUGE-S、ROUGE-W等。该方法基本思想为先构建标准摘要集,将模型所得文本摘要与标准摘要相对比,采用统计两篇摘要之间重叠的基本单元(N元语法、词序列和词对)数目等信息,用以评价模型生产摘要的优劣,本文使用的ROUGE-1、ROUGE-2、ROUGE-L作为评价指标。ROUGE-N计算公式如式(11)所示:

N表示字符N元词N-gram的长度,Countmatch(gramn)表示同时在模型生成摘要与标准摘要的N-gram字符数量,Count(gramn)表示在标准摘要中N元词N-gram的数量。
3.3 实验参数设置
ALBERT-UniLM模型参数主要包含ALBERT及UniLM模型的参数。ALBERT模型采用对文本词嵌入参数进行因式分解的方法,通过划分子阵将矩阵词嵌入参数从O(V×H)降至O(V×E+E×H)。两个矩阵的参数进行模型学习,在不降低模型学习效果的要求下,通过共享参数的方法,可明显降低模型的参数向量。表3为相同规模下两种模型的参数对比。

表3 BERT模型与ALBERT模型参数对比Table 3 Comparison of main BERT and ALBERT models parameters
本文模型中的ALBERT模型采用Google发布的中文预训练模型ALBERT-Base,设置最大序列长度为128,Train_batch_size为16,Learning_rate为5E-5。模型参数如表4所示。

表4 ALBERT预训练模型参数Table 4 ALBERT pre-training model parameters
UniLM模型设置隐向量维度为768,微调学习率Learning_rate设为5E-5,预热步骤参数Num_warmup_steps设为500,微调的训练步数Num_training_steps设为10 000,Epochs设为55。批处理大小Batch_size设为16,Beam_search解码时的Beam_size为5。本文实验环境及配置如表5所示。

表5 实验环境及配置Table 5 Lab environment and configuration
3.4 实验结果与分析
为验证ALBERT-UniLM模型处理自动文本摘要任务的优越性,本文实验部分选取7种基准模型进行生成指标对比。所选基准模型包含3种抽取式摘要模型及4种生成式摘要模型。所选模型介绍如下:
(1)MMR:该模型又称为最大边界相关模型,该模型设计之初用于处理Query文本与被搜索文档的相似度,然后对文本排序的模型。
(2)Lead-3:该模型思想为选取文档首段的前3句作为文本摘要。因文章起始处常含有关键信息,因此该方法为常见且有效的抽取式摘要算法。
(3)TextRank:该模型受到图算法模型的启发,通过计算文本句子间的重要程度,然后将句子进行排序重组生成摘要。
(4)Seq2Seq+Attention:该模型将序列到序列框架与注意力机制结合,是目前研究摘要生成任务的标准结构模型。
(5)Pointer-Generator:该模型在Seq2Seq模型的基础上,通过指针网络选择摘要词,并添加覆盖机制解决输出信息错误及未登录词的问题。
(6)BERT+LSTM:该模型采用Seq2Seq基础架构,将Encoder替换为双向Transformer编码,Decoder采用LSTM。使用BERT模型对编码端参数进行初始化处理,解码端从初始状态训练。
(7)BERT+UniLM:该模型采用Seq2Seq基础架构,将Encoder替换为双向Transformer编码模块,Decoder采用UniLM。使用BERT模型对编码端参数进行初始化处理,解码端从初始状态训练。
选取7种对比模型与该文模型在NLPCC-2018新闻摘要中文单文档公开数据集上进行效果验证。实验评测结果如表6及图4。

表6 模型评测对照表Table 6 Comparison of model evaluation

图4 各模型ROUGE-1、ROUGE-2、ROUGE-L得分对比Fig.4 Comparison of ROUGE-1,ROUGE-2,ROUGE-L scores of each models
由图4、表6可以得出:
(1)生成式文本摘要算法评测得分整体优于抽取式文本摘要算法。可见,通过对原始文本进行文本数据分析处理,通过文本生成技术获得文本摘要的生成式摘要算法相较于抽取文本中重要的词语组合成摘要的抽取式摘要算法更适合于中文长文本摘要任务。
(2)与基于Seq2Seq+Attention的生成式文本摘要模型相比,Pointer-Generator模型对生成的摘要质量有了进一步的提高。模型中的指针网络及覆盖机制有效缓解了摘要生成过程中的未登录词以及重复生成词问题,证明指针网络可以明显提高生成摘要的质量。
(3)预训练语言模型BERT的引入,使得生成式摘要算法评测得分进一步提升。BERT模型由于其在海量语料上的训练而使得模型具有优秀的向量表征能力,然而其庞大的训练参数量使得在少量数据训练时容易产生过拟合问题。
(4)与BERT-UniLM模型及其他模型对比,本文提出的ALBERT-UniLM模型在三项ROUGE评测指标上均取得最好成绩。表明模型通过两阶段进行文本摘要生成的算法能够有效的将ALBERT模型与UniLM模型的优势相结合,引入指针网络及覆盖机制,在降低摘要中未登录词的同时,有效减少重复内容的生成。
表7为该文模型生成摘要示例,由表7可以得出:通过与原文及标准摘要做直观对比,可看出ALBERTUniLM模型生成的摘要内容更丰富、更全面、更贴近标准摘要,说明该模型对原文的理解更加充分,对文中的句词进行更准确的表达。

表7 模型生成摘要示例Table 7 Generate summarization example
4 结束语
针对文本摘要自动生成任务,文章提出一种基于深度学习的生成式摘要模型ALBERT-UniLM,该模型结合迁移学习的思想,将预训练模型ALBERT与UniLM相结合。ALBERT模型显著降低了预训练模型的参数量并有效获取到词向量。利用指针生成网络及覆盖机制对UniLM模型中的序列到序列生成机制加以改进,使得ALBERT-UniLM的预训练模型适用于自然语言处理中的生成任务。实验表明,与传统的基准模型相比,ALBERT-UniLM模型在文本摘要生成任务中生成的摘要结果更接近标准摘要,具有更好的准确性和可读性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
软件学报(2020年6期)2020-09-23
当代陕西(2019年9期)2019-05-20
文苑(2018年21期)2018-11-09
广东第二课堂·小学(2017年9期)2017-09-28
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年12期)2015-12-10
中国火炬(2014年4期)2014-07-24
