
舒尔特方格与LSTM的注意力分级建模
2022-08-09 05:45秦学斌
计算机工程与应用 2022年15期
王 湃,吴 凡,汪 梅,秦学斌
西安科技大学 电器与控制工程学院,西安 710054
注意力是心理活动对一定对象的指向和集中,是伴随着感知觉、记忆、思维、想象等心理过程的一种共同的心理特征[1]。驾驶过程中的注意力问题一直是驾驶员和飞行员面临的首要问题,一旦他们的注意力分散,就会造成严重交通事故[2]。通过对驾驶员的不同注意力状态进行监测并预警能够有效地降低事故的发生率[3-4]。为此,基于脑电信号的注意力分级研究成为该领域内的研究热点问题。
刘素杰[5]通过构建脑网络,并结合样本熵等脑电的非线性特征对注意力分级进行研究,该方法可以对两级注意力水平和多级注意力水平进行区分,其准确率分别为84.54%和73.43%。龚琪[6]通过提取游戏者的频域各节律特征,定性分析专注游戏状态下的脑电频域特征,并通过计算脑电信号中的节律波频段与原始脑电信号的相关系数,实验得出在游戏者的脑电信号中,α波的相关系数有所提升。吴欢等[7]设计相关实验获得脑电数据,分别对β波/θ波能量占比特征和样本熵特征对注意力的分级进行对比,最终得出样本熵对于多级注意力的区分度更好。但是这两种方法采用的都是脑电中的特定波段作为信号特征,势必会造成特征损失,这种方法对于注意力与非注意的区分效果较好,但是对于注意力多级分类效果不一定好。陈群等[8]采用深度森林的算法对注意和非注意两种状态下的脑电信号进行分析,得到较高的识别准确率。上述的方法未提取出时序特征,不能体现出时序脑电信号的关联性,脑电信号的时序特征对于注意力分类能起到很大作用。以上的研究大大推进了基于EEG信号的注意力的研究,但是仍然存在一些亟待解决的难点问题:(1)脑电信号采集范式没有统一的客观评价标准,不同注意类型的脑电数据采集和标注困难;(2)采用节律数据,不能保证原始脑电信号的完整性,脑电信号时序特征被忽视;(3)现有的注意力研究大多区分的是注意和非注意两种状态,一部分研究提到的注意力多级分类大多只是区分两种注意力状态和静息态共三类状态,极其缺少高注意力、中注意力和低注意力这样的注意力多级分类研究。
针对上述问题,本文提出一种基于舒尔特方格与LSTM的注意力分级模型:设计舒尔特范式实现对不同注意类型脑电数据的采集以及自动标注;采用原始脑电信号,保存脑电数据的完整性;搭建LSTM深度学习网络提取注意力特征并将注意力分为高注意力、中等注意力以及低注意力。
1 基于舒尔特方格与LSTM的注意力分级模型结构设计
如图1所示,基于舒尔特方格与LSTM的注意力分级模型主要包括脑电多级注意力数据库构建、脑电数据预处理、脑电信号特征提取与分类等三部分,分别由舒尔特方格范式、小波包分解和LSTM注意力分级网络实现。
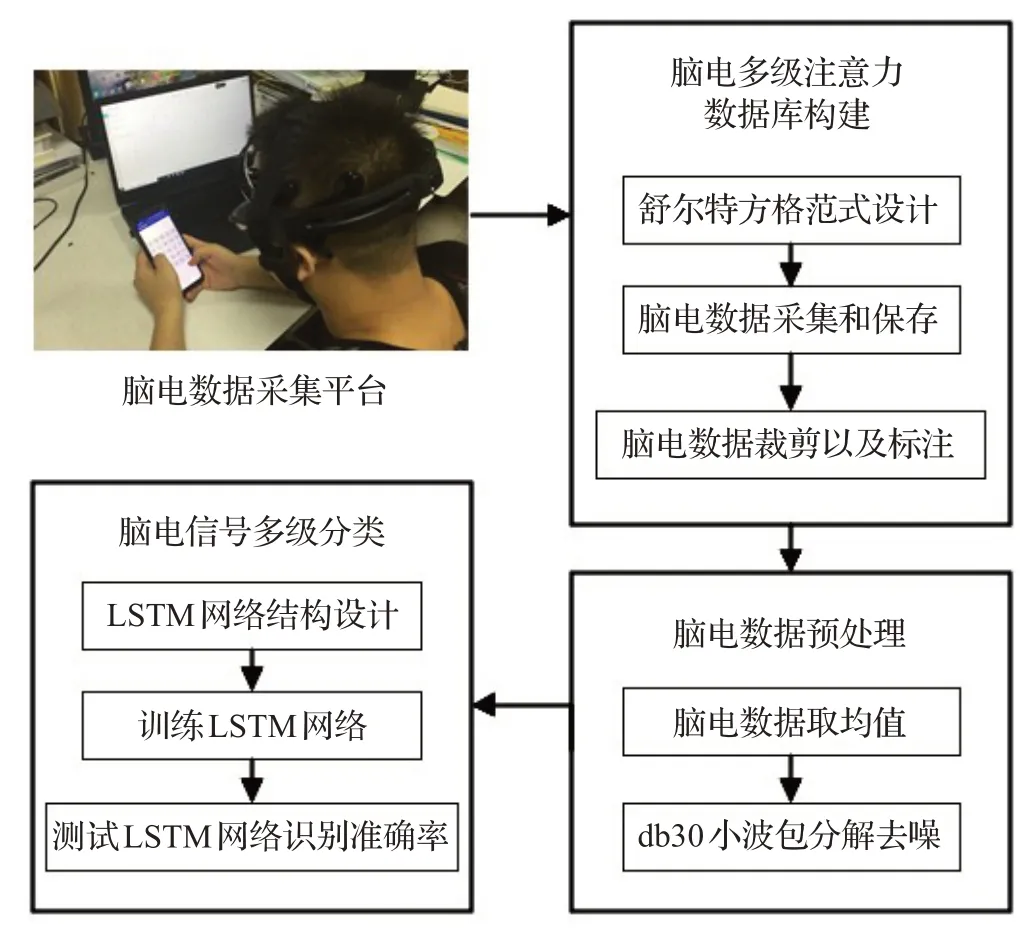
图1 基于舒尔特方格与LSTM的注意力分级模型Fig.1 Flow chart of attention classification model based on Schulte grid and LSTM
2 舒尔特方格范式设计
2.1 传统范式介绍
现有的注意力范式如下:Ke等[9]采用了一种运动员做球类运动视频作为注意任务刺激,被试坐在屏幕前,屏幕上播放运动视频,要求被试集中精力注意视频中运动员的肢体动作,并想象是自己在做运动,与之相对的非注意任务中,屏幕中仍然播放相同的视频,被试仍然注视屏幕,但无需作运动想象而是思考一些与任务无关的事情。Ming等[10]采用了一种吃鱼游戏作为注意任务刺激,被试坐在屏幕前,屏幕上播放游戏视频,要求被试集中精力注意屏幕,并假想游戏是由自己控制,控制一条小鱼不停地游动并吞食其他生物,与之相对的非注意任务中,屏幕中仍然显示与注意任务一样的游戏视频,被试仍被要求注意屏幕,但不需要做出任何反应,不得思考游戏相关内容。燕楠等[11]则采用了读论文和心算作为注意任务刺激,与之对应的非注意任务则要求被试放松,并且不可以注意某一特定的事物。上述研究中的范式能够得到不同注意力水平的脑电数据,但是仍然存在一个技术难题:没有可以量化的指标,数据评价不够客观。
2.2 基于视觉搜索和反应时技术的舒尔特方格范式设计
视觉搜索是认知心理学家长期以来用于研究在复杂视场中注意分配的经典范式,为检验各种注意理论提供了一个平台,典型的视觉搜索任务要求被试记住搜索目标,并对视场中是否存在目标作出反应[12]。本注意力采集范式正是基于视觉搜索范式,按照数字大小搜索目标并作出点击反应。
反应时技术范式是现代认知心理学实验研究中最广泛使用的手段之一[13]。反应时间(RT)是心理实验中使用最早、应用最广的反应变量之一[14]。20世纪80年代末到90年代初,内隐学习研究中出现了新的研究范式-序列学习范式,用以研究人们对序列规则的无意识活动[15]。序列反应时任务正是序列学习范式中的经典任务之一,它以反应时间作为反应指标,以序列规则下的操作成绩和随机序列下的操作成绩之差来表示内隐学习的学习量[16]。本研究正是使用反应时间作为不同注意力水平的衡量标准,并用准确性作为实验条件,使注意力数据更客观。
本研究采用自制舒尔特方格游戏作为注意力数据采集范式。舒尔特方格是美国神经心理医生舒尔特发明的,主要是训练飞行员的注意力,它主要训练内容包括视觉、听觉、动觉注意力训练和注意力的稳定性、广度、转移、分配等注意力要素特征的训练[17],并可训练孩子的学习能力和细心性格。舒尔特方格已是普遍认为可用来训练注意力的方式,用此作为范式将使离线实验数据更为客观。
图2为舒尔特方格实验范式设计,包括练习阶段和实测阶段。首先进行实验训练并接受实验指导,然后进入实测阶段,依次按下1、2直到25,如果其中有错误的地方,点错的格子会闪红提示报错,提示被试。实验完成后实验员对数据进行保存。并记录完成的时间以及准确率。
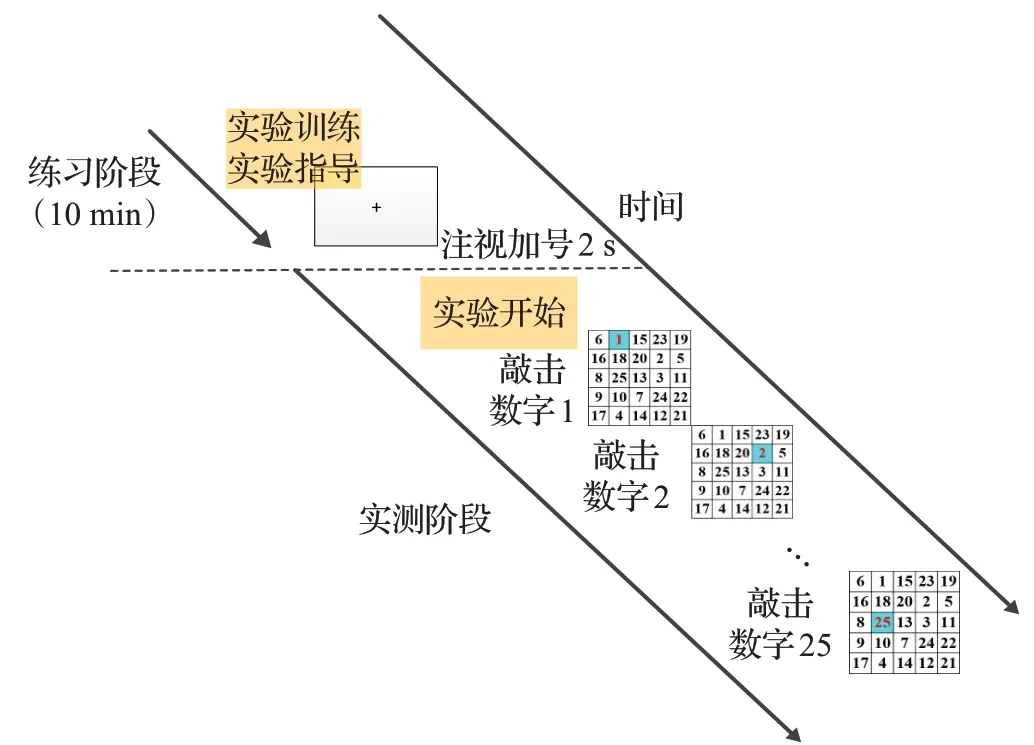
图2 舒尔特方格范式Fig.2 Schulte grid paradigm
2.3 脑电数据采集平台
本研究采用的脑电信号采集设备是Emotiv System公司开发的Emotiv传感器,Emotiv传感器以P3/P4为参考电极[18],上面安装着14个电极,可以采集到14个通道的脑电信号,并进行放大与滤波,然后通过无线USB技术传回计算机。Emotiv传感器的电极安放位置采用国际10-20导联制。
Emotiv的传感器头采用湿电极,盐水作为辅助材料,增强信号质量。脑电耳机通过无线USB以及EmotivPro软件从远程服务器获得各种数据。图3为脑电数据采集平台,安卓端为舒尔特方格范式应用程序,数据采集为头部的Emotiv Epoc+脑电耳机,笔记本负责记录并保存数据。

图3 脑电数据采集实验平台Fig.3 EEG data acquisition experimental platform
3 脑电数据预处理
脑波信号的主要频率在0~30 Hz,处理过程中应该将高频的扰动信号去除[6],所以需要先对脑电注意力信号进行滤波处理[19],一方面保证数据的有效频率,另一方面去除高频噪声,提升数据准确性。
本研究采用小波包分解对脑电数据进行预处理。小波包分解是小波变换的推广,小波包借助于小波分解滤波器在各个尺度上,对每个子带均进行再次降半划分,从而得到比二进离散小波变换更精细的信号分解[20]。小波包是采用非周期信号,通过缩放平移变换的基函数的系数,构成时频尺度图,以便分析突变信号的位置和频率可以选择性去除一部分系数,再反变换回时域信号,达到滤波的目的[21]。
采用db30小波滤波器对信号进行6层分解,使用shannon熵得到小波包树[22],最终重构得到0~30 Hz的有效数据,达到滤波去噪的目的。图4和图5为滤波前后的脑电数据对比,从图中可以看出,很明显滤掉了大量的噪声,提升特征提取准确率。
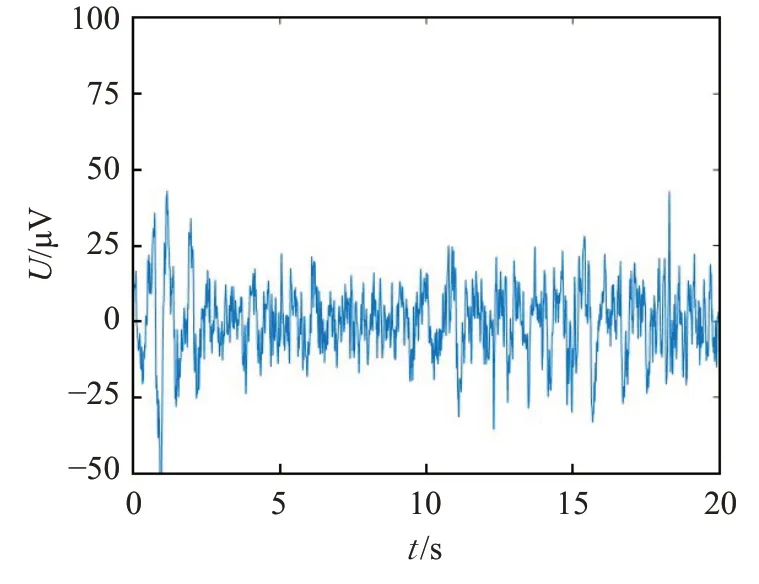
图4 滤波前脑电数据波形Fig.4 EEG data waveform before filtering
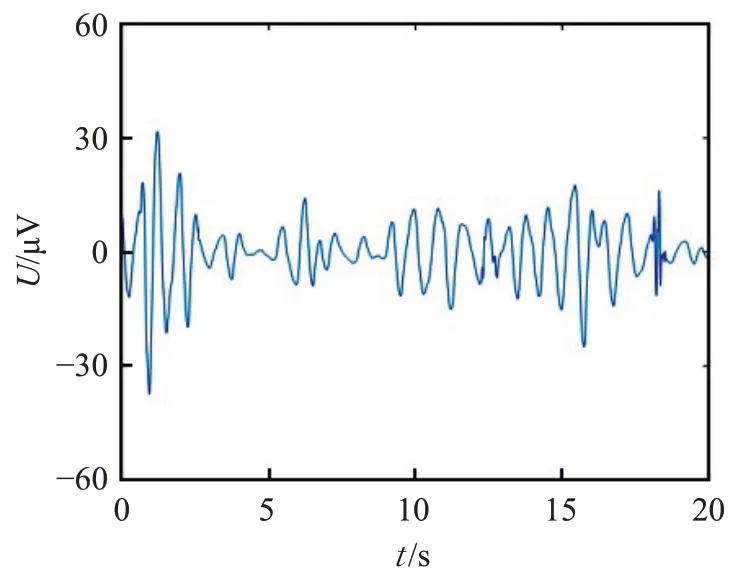
图5 滤波后脑电数据波形Fig.5 EEG data waveform after filtering
4 基于LSTM的注意力分级模型
4.1 LSTM网络原理
本研究通过设计LSTM网络对注意力分级。LSTM是通过引入由输入门、遗忘门和输出门构成的门控单元系统而产生的一种RNN变体。
LSTM神经网络记忆单元的基本结构如图6所示,LSTM用内部记忆单元即细胞的状态保存历史信息,并利用不同的“门”动态地让网络学习适时以往历史信息,依据新信息更新细胞状态,以解决RNN中梯度消失与梯度爆炸的问题[23]。
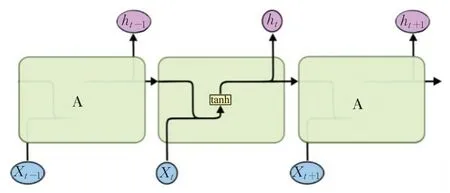
图6 LSTM神经网络记忆单元Fig.6 LSTM neural network memory unit
遗忘门用来计算哪些信息需要忘记,通过sigmoid处理后为0到1的值,1表示全部保留,0表示全部忘记,于是有:
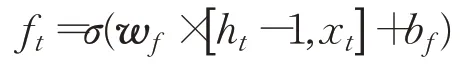
式中,括号表示两个向量相连合并,w f是遗忘门的权重矩阵,σ为sigmoid函数,b f为遗忘门的偏置项[24]。设输入层维度为dx,隐藏层维度为dh,上面的状态维度为dc,则w f的维度为dc×(dh+dx)。
输入门用来计算哪些信息保存到状态单元中,分两部分,第一部分为:
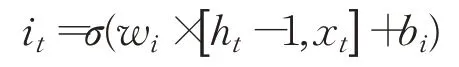
该部分可以看成当前输入有多少是需要保存到单元状态的。第二部分为:
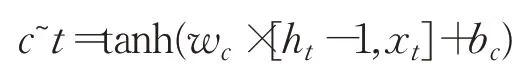
该部分可以看成当前输入产生的新信息来添加到单元状态中。结合这两部分来创建一个新记忆。
而当前时刻的单元状态由遗忘门输入和上一时刻状态的积加上输入门两部分的积,即:
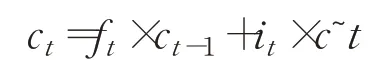
输出门通过sigmoid函数计算输出信息,再乘以当前单元状态通过tanh函数的值,得到输出[25]。
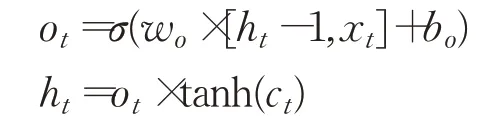
4.2 基于LSTM网络的注意力分级模型
采用LSTM提取序列的前后依赖关系从而提高识别准确率。如图7所示,本文LSTM网络总共分为五层,主要包括序列输入层、LSTM层、全连接层、SoftMax层以及分类输出层。
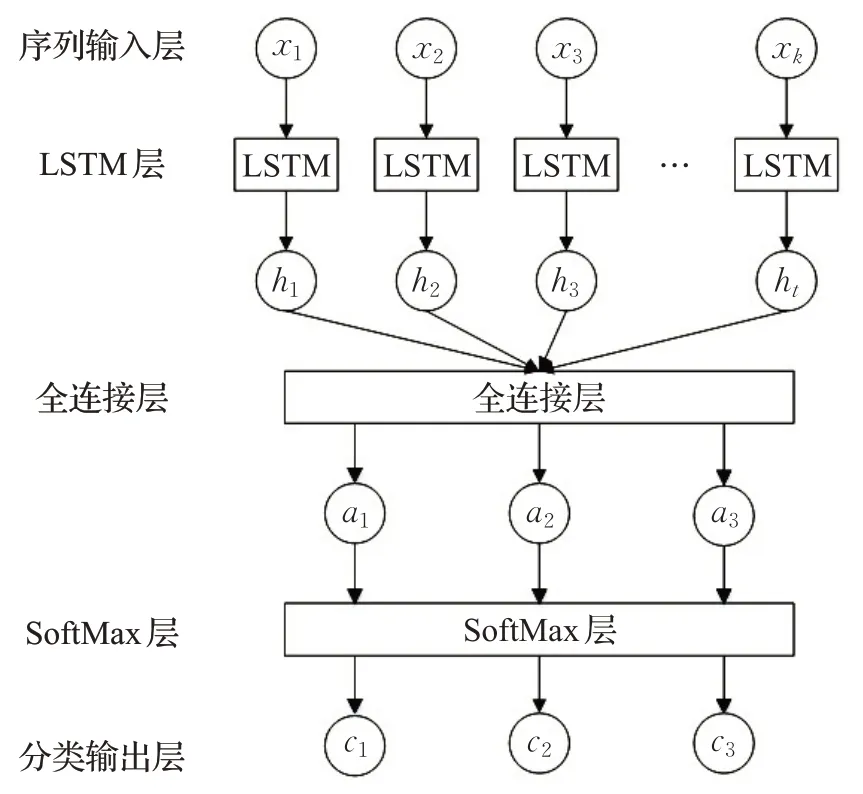
图7 LSTM深度神经网络结构图Fig.7 Structure chart of LSTM deep neural network
5 实验与结果分析
5.1 实验设计方案
本研究采用的实验设计方案如下:(1)高注意力任务:受试者坐在屏幕前,戴上脑电采集装置,并确保信号质量较好,视觉与屏幕保持平齐,双手或单手操作舒尔特方格,开始游戏后要求受试者集中精力,在30 s内按照顺序查找并点击数字;(2)中等注意力任务:受试者坐在屏幕前,开始游戏后要求受试者集中精力,在40~50 s内按照顺序查找并点击数字;(3)低注意力任务:受试者坐在屏幕前,开始游戏后要求受试者集中精力,在1 min以上按照顺序查找并点击数字。在整个实验过程中,保持实验环境安静,让受试者坐在一个舒适的靠背椅上,全身肌肉处于一种放松状态,不产生任何的肌肉紧张与运动,保证受试者不受外界干扰。
10位健康受试者,年龄在20~25岁之间,均在头脑清醒的情况下接受测试,受试者都是有具备该范式采集的经验,脑电电极按照国际标准10~20系统放置,实验共采用14个导联。所有数据采集完成后,首先去除采集数据过程中有错误次数的数据,然后对数据进行以下条件筛选:高注意力任务条件下需要完成时间在30 s以内的数据并且准确率在100%才能作为有效数据;中等注意力任务下需要完成时间在40~50 s以内的数据并且准确率在95%以上才作为有效数据;低注意力任务下需要完成时间在1 min以上并且准确率在90%以上才能作为有效数据。以上三种注意力标签的时间范围均为大量实验获得,可以更好地区分三种注意力水平。
总共得到接近35 min的实验数据,考虑到实验对比,分别得到1 s样本数据2 100个,三种标签样本个数各占700个,其中每一个样本为128×14的矩阵数据;2 s样本数据1 050个,三种标签样本个数各占350个,其中每一个样本为256×14的矩阵数据;3 s样本数据690个,三种标签样本个数分别占230个,其中每一个样本为384×14的矩阵数据。
5.2 注意力数据库的分级准确性分析
对于专注程度的定义方式多为节律信号的组合比值,其中应用比较广泛的定义方式有两种:
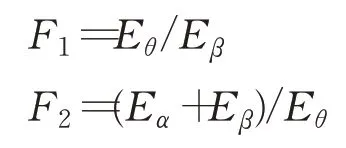
其中Eα、Eθ、Eβ均为单位时间内的频段能量值。E通过计算的α、β和θ波段的小波相对能量得到。其中F1越高表示注意力水平越低,F2越高表示注意力水平越高。
分别采用1 s、2 s和3 s作为单位时间,使用F1[26]和F2[27]作为专注度模型,进行不同注意力水平的节律能量对比结果如下:
(1)1 s作为单位时间,F1作为专注度模型,实验结果如图8。
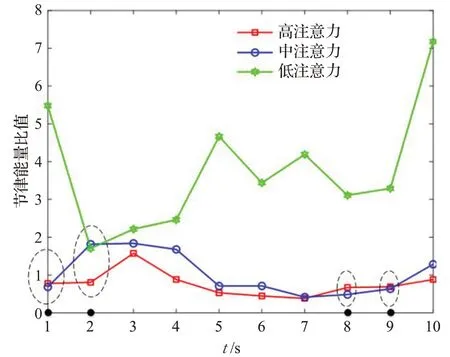
图8 1 s+F1的不同注意力节律能量比值Fig.8 1 s+F1 Rhythm energy ratio of different attention
如图8所示,整体趋势上低注意力数值大于中注意力大于高注意力,其代表注意力水平越高,对应的F1值越小,与F1对于注意力的表达一致。
在t(单位:s)等于1、2、8、9时很难区分中注意力和低注意力,主要是由于F1专注度模型只是包含β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
(2)1 s作为单位时间,F2作为专注度模型,实验结果如图9。
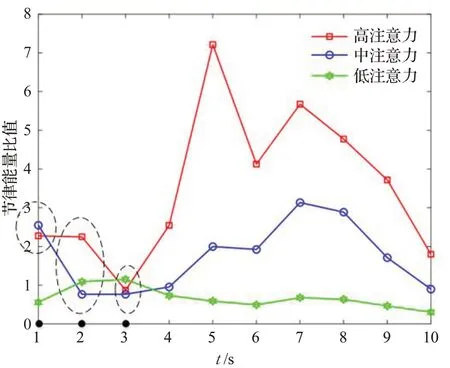
图9 1 s+F2的不同注意力节律能量比值Fig.9 1 s+F2 Rhythm energy ratio of different attention
如图9所示,整体趋势上低注意力数值小于中注意力小于高注意力,其代表注意力水平越高,对应的F2值越大,与F2对于注意力的表达一致。
在t等于1、2、3时很难区分高注意力、中注意力和低注意力,主要是由于F2专注度模型只是包含α、β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
(3)2 s作为单位时间,F1作为专注度模型,实验结果如图10。

图10 2 s+F1的不同注意力节律能量比值Fig.10 2 s+F1 Rhythm energy ratio of different attention
如图10所示,整体趋势上低注意力数值大于中注意力大于高注意力,其代表注意力水平越高,对应的F1值越小,与F1对于注意力的表达一致。
在t等于8、12、20时很难区分中注意力和低注意力,主要是由于F1专注度模型只是包含β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
(4)2 s作为单位时间,F2作为专注度模型,实验结果如图11。
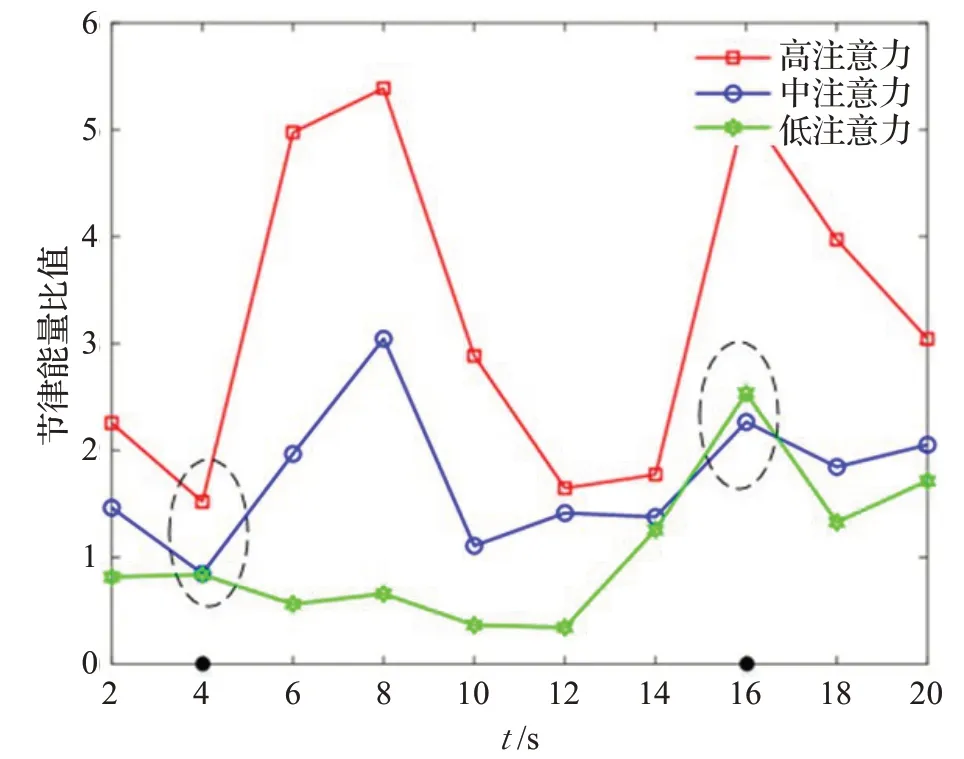
图11 2 s+F2的不同注意力节律能量比值Fig.11 2 s+F2 Rhythm energy ratio of different attention
如图11所得,整体趋势上低注意力数值小于中注意力小于高注意力,其代表注意力水平越高,对应的F2值越大,与F2对于注意力的表达一致。
在t等于4、16时很难区分高注意力、中注意力和低注意力,主要是由于由于F2专注度模型只是包含α、β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
(5)3 s作为单位时间,F1作为专注度模型,实验结果如图12。
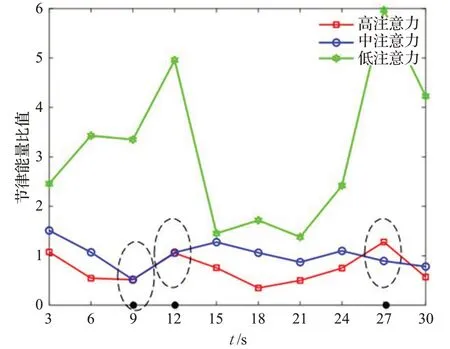
图12 3 s+F1的不同注意力节律能量比值Fig.12 3 s+F1 Rhythm energy ratio of different attention
如图12所示,整体趋势上低注意力数值大于中注意力大于高注意力,其代表注意力水平越高,对应的F1值越小,与F1对于注意力的表达一致。
在t等于9、12、27时很难区分中注意力和高注意力,主要是由于F1专注度模型只是包含β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
(6)3 s作为单位时间,F2作为专注度模型,实验结果如图13。
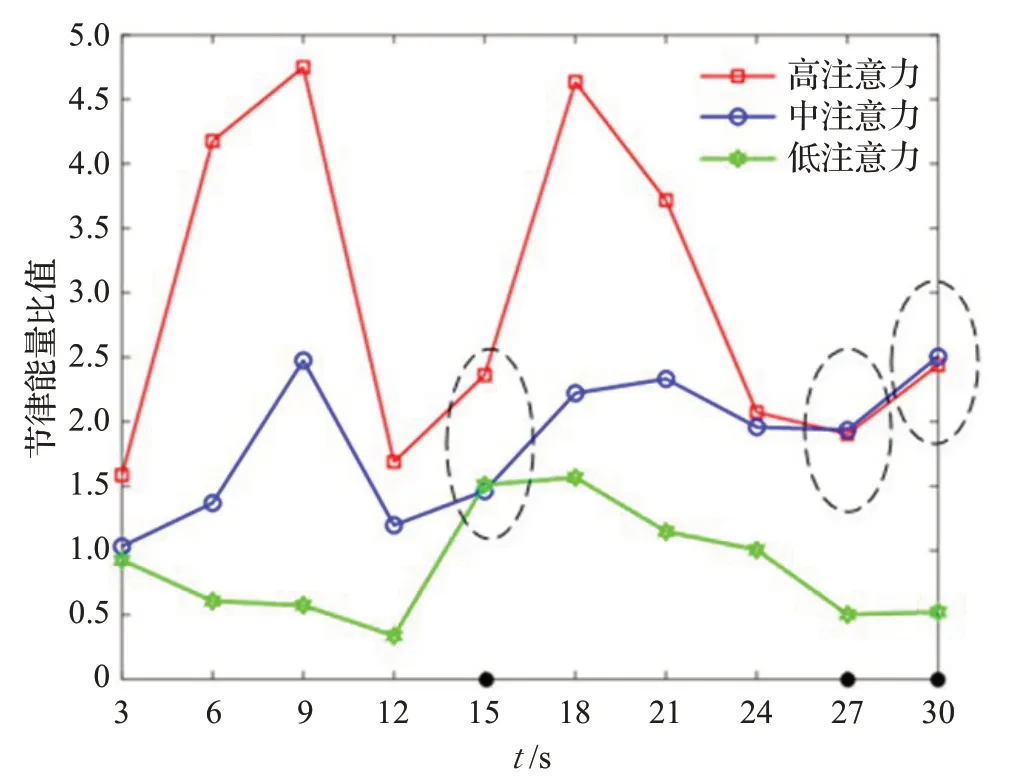
图13 3 s+F2的不同注意力节律能量比值Fig.13 3 s+F2 Rhythm energy ratio of different attention
如图13所得,整体趋势上低注意力数值小于中注意力小于高注意力,其代表注意力水平越高,对应的F2值越大,与F2对于注意力的表达一致。
在t等于15、27、30时很难区分高注意力、中注意力和低注意力,主要是由于F2专注度模型只是包含α、β和θ波段的小波能量,不能够完全表征原始脑电注意力状态,所以判断出现问题。
5.3 注意力分级准确率对比
本文采用十折交叉验证法,1 s样本的训练数据为1 890个,测试数据为210个;2 s样本的训练数据为945个,测试数据为105个;3样本的训练数据为621个,测试数据为69个。然后将其余9份依次作为测试数据共可得到10次准确率,10次平均即得到最终的识别准确率。分别采用DWT、近似熵、共空间模式(CSP)以及基于相干系数的注意力脑网络作为特征并结合支持向量机SVM作为分类算法以及CNN对数据进行分类处理,并与本注意力分级模型对比,并得到1 s、2 s和3 s样本前提下的识别准确率。
实验结果如表1所示。由表1可以看出:对比各种算法,LSTM方法识别准确率显著高于各传统机器学习算法,以1s样本为例LSTM识别准确率高出各传统机器学习算法至少13.32%,高出CNN9.05%,主要是由于在大样本的前提下,深度学习算法相对传统机器学习算法有极大的优势,可提取泛化能力,即更本质的特征,LSTM除了具有普通深度学习网络的优点外,还具有提取时间序列信号的前后依赖关系特征,而EEG信号在时序前后本身就具有极强的关联性,另外,随着样本长度增加,其样本数据量减少,这些也就是在脑电注意力研究方面,LSTM极大优于各经典特征提取算法的主要原因。在小样本的前提下,传统机器学习算法随样本量的减少,其准确率变化相对不大,而深度学习算法随着样本量的降低,准确率有明显的降低。综上所述,由于LSTM所具备的大样本下的优势以及时序特征的提取,因此,LSTM更有助于脑电注意力的分级研究。
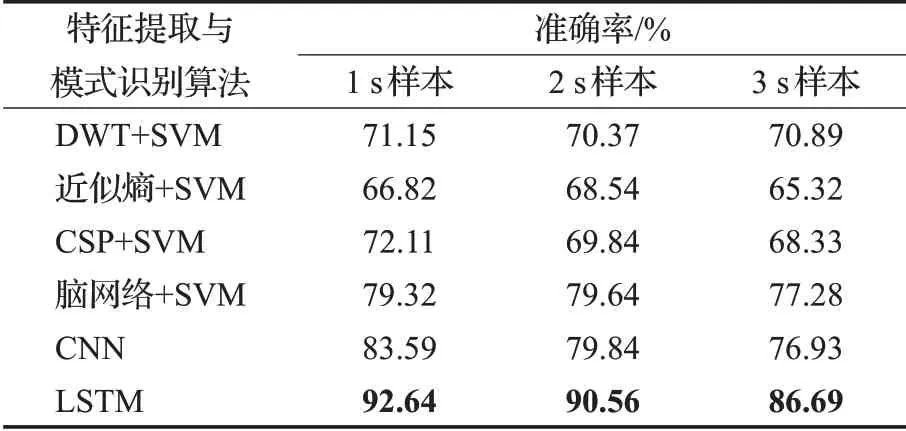
表1 识别准确率对比表Table 1 Comparison table of recognition accuracy
6 结论
注意力分级模型在驾驶员注意力监测方面具有重大的意义,因此本文提出了基于舒尔特方格和LSTM的注意力分级模型,具体完成如下工作:
(1)采用舒尔特方格作为数据采集范式,量化检验指标,并采用原始脑电数据,保证数据完整性,实现对不同注意类型数据的采集以及自动标注。
(2)采用小波包实现脑电数据的滤波和去燥,并设计长短时记忆深度学习网络,实现不同注意力水平的分级。
(3)实验结果表明:本注意力分级模型可以很好区分高、中、低三种注意力水平;对比DWT、近似熵、CSP、基于相干系数的脑网络特征提取算法以及CNN,五种基于脑电信号的注意力分级方法,本模型识别准确率高出DWT21.49个百分点;高出近似熵算法25.82个百分点;高出CSP算法20.53个百分点;高出基于相干系数的脑网络算法13.32个百分点;高出CNN9.05个百分点。
猜你喜欢
心理学报(2022年10期)2022-10-12
中国化肥信息(2022年7期)2022-08-31
数学小灵通(1-2年级)(2021年12期)2021-12-30
数学小灵通(1-2年级)(2020年12期)2021-01-14
小学生导刊(2018年16期)2018-11-30
小学生导刊(2018年1期)2018-03-15
中央民族大学学报(自然科学版)(2017年3期)2017-10-22
时代英语·高一(2017年3期)2017-06-13
天津体育学院学报(2016年3期)2016-12-18
环球时报(2016-08-23)2016-08-23
