
融合策略优选和双注意力的单阶段目标检测
2022-08-09 12:38戴坤许立波黄世旸李鋆铃
中国图象图形学报 2022年8期
戴坤,许立波,黄世旸,李鋆铃
浙大宁波理工学院计算机与数据工程学院,宁波 315000
0 引 言
目标检测是近些年来计算机视觉和深度学习的研究热点之一,在工业检测、智能交通和人脸识别等领域有着广泛的应用。比较流行的目标检测算法主要分为两类:一类是两阶段(two-stage)算法,如R-CNN(region convolutional neural network) (Girshick等,2014)、Fast R-CNN (Girshick,2015)、OHEM(online hard example mining)(Shrivastava等,2016)、Faster R-CNN (Ren等,2017)和Mask R-CNN(He等,2020)等,该类方法需要先产生目标候选框,然后再对候选框做分类与回归任务。另一类是单阶段(one-stage)算法,如YOLO(you only look once)(Redmon等,2016)、SSD(single shot multibox detector)(Liu等,2016)等,该类方法使用卷积神经网络(convolutional neural network, CNN)直接预测不同目标的类别与位置。两种方法各有优劣,两阶段算法的准确率一般高于单阶段算法,但单阶段算法的速度优于两阶段算法。目前在实际应用中,速度与性能兼备的单阶段算法得到了更多的青睐。另外,以CornerNet(corner network)(Law和Deng,2020)和CenterNet(center network)(Zhou等,2019)为代表的anchor-free模型力图抛开锚框而基于关键点做出检测与匹配,也达到了相当好的效果,但离基于锚框的检测方法尚有少许差距。
最早的单阶段算法是Redmon等人(2016)提出的基于回归问题求解的YOLO算法,随后原作者又提出YOLO的改进版本YOLOv2(Redmon和Farhadi,2017),效率和准确率得到进一步提升。Liu等人(2016)结合YOLO的高效和Faster R-CNN候选区域方法,提出了新的单阶段算法SSD,它在不同的特征图中生成预测框并且进行回归,有效地兼顾准确率和效率。Fu等人(2017)提出一种基于SSD模型改进的DSSD(de-convolution single shot detector)算法,通过对原来特征图进行反卷积操作生成新的特征图,充分利用了浅层的特征,并且将骨干网络换成表征能力更强的ResNet(residual neural network)(He等,2016)网络。Jeong等人(2017)提出另一种基于SSD模型改进的RSSD(rainbow single shot detector)算法,将SSD的初始特征图进行池化和反卷积处理,并且将处理后生成的特征图融合,使特征图同时拥有正向和反向的信息,算法在PASCAL VOC(pattern analysis, statistical modelling and computational learning visual object classes)数据集中准确率与DSSD相当,但检测速度(frame per second,FPS)达到35帧/s,远超过DSSD。之后YOLOv3 (Redmon和Farhadi,2018)模型被提出,相对于YOLOv2,准确率得到大幅度上升且速度没有下降。Lin等人(2020)提出了一种SSD改进版本——Retinanet,模型用ResNet-101-FPN(feature pyramid network)作为骨干网络,并且提出了focal loss损失函数来解决正负样本比例不平衡的问题。另外,Li和Zhou(2017)提出FSSD(fusion single shot multibox detector),此算法先对VGG(Visual Geometry Group)(Simonyan和Zisserman,2015)中的两个特征图进行融合,然后再生成新特征图。Wang等人(2018)提出了多尺度位置感知内核候选区域(multi-scale location-aware kernel proposals, MLKP),利用对象检测中的高阶统计量,生成更多具有强判别力和高灵敏度的候选框,可以灵活地运用于目标检测。Zhou等人(2018)提出了STDN (scale transferrable dense network),该算法通过尺度变换模块,在获得高级语义多尺度特征图的同时,又不影响检测器的速度。Zhang等人(2018)提出了精细神经网络(refinement neural network, RefineDet)算法,通过对SSD算法、RPN(region proposal network)网络和FPN算法的结合,在保证高效的检测效率的前提下,提高算法对小目标的检测能力。郑浦等人(2020)提出了F_SE_SSD(fusion squeeze and excitation networks single shot multibox detector),此算法对FSSD的特征融合方法进行了改进,加入注意力机制,提升模型对小目标物体的检测能力。Bae(2019)提出了区域分解与装配检测器(region decomposition and assembly detector, R-DAD)算法,通过多尺度候选区域(multi-scale region proposal, MRP)模块以及区域分解和组装(region decomposition and assembly, RDA)模块,对重要特征附近的多个方向语义信息进行融合,更有利于检测受遮挡的目标。唐乾坤和胡瑜(2020)提出了锚点框提升模块(anchor promotion module, APM)和特征对齐模块(feature alignment module, FAM),在一定程度上解决了锚点框不均衡问题。Wu等人(2020)提出了双向金字塔网络(bidirectional pyramid network, BPN)算法,通过双向金字塔网络来解决SSD算法对于弱特征表达不明显的问题。
单阶段目标检测在实际应用中,面临的主要挑战是对模糊图像、小目标和受遮挡物体等目标检测困难(张焕龙 等,2015;尹宏鹏 等,2016;葛宝义 等,2018;方路平 等,2018),以及性能和效率无法很好兼顾。特征融合通过融合网络不同深浅层特征,能够有效提升对困难目标的检测能力,这已经成为一种共识,因此在许多SSD改进模型中得到广泛使用。但多数改进模型都是直接使用特征融合手段,而对于融合的具体策略,如应该对哪些图进行融合、融合后的图如何处理等问题,相关的研究相对缺乏。另外,近些年来注意力机制也广受关注,其通过赋予维度权重,能够使特征图具有一定的“聚焦”作用,如何将其有效结合进单阶段目标检测,也是值得深入研究的问题。对此,本文提出了FDA-SSD(fusion double attention single shot multibox detector)算法,该算法的第1个贡献是设计特征图优化选择策略,为特征融合确定最有效的多层特征图组合以及设计恰当的再处理环节;第2个贡献是为特征融合后的输出特征图添加双注意力机制,使特征图中重要的通道和空间特征得到更多的显著表达,在提高预测准确率的同时,还能保持很高的运行效率。
1 FDA-SSD算法
1.1 骨干网络替换
SSD算法采用VGG16改进网络作为骨干网络,本文将原骨干网络替换成参数和计算量更小、深度更深的ResNet网络。
ResNet的block模块形式如图1所示,其中图1(a)为ResNet34网络中由两个3×3卷积层组成的基础块,图1(b)为ResNet50/101/152的由两个1×1卷积层与一个3×3卷积层组成的瓶颈块,假设原有的多层映射表示为H(x),每一层的输入为x,ResNet的残差映射函数为F(x),那么ResNet的残差连接(shortcut)起到的作用为H(x)=F(x)+x,该网络在不加入新参数且不增加计算量的前提下,通过跳跃式连接,使得跨层参数可重复利用,在一定程度上缓解了梯度消失和梯度爆炸的问题。
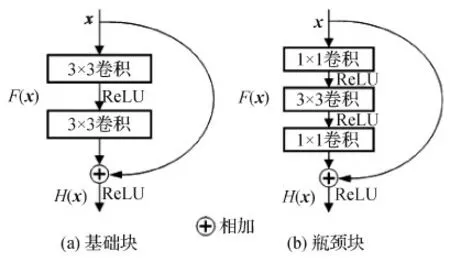
图1 ResNet的block形式Fig.1 Block form of ResNet((a)basic block; (b)bottleneck)
1.2 特征融合策略优选
特征金字塔(feature pyramid networks, FPN)是Lin等人(2017)提出的经典特征融合方法,适用于不同的深度网络学习算法。如图2所示,FPN算法通过自下而上和自上而下的方法,在各层特征图上进行运算,既融合了高层信息,又保留了低层信息。

图2 特征金字塔Fig.2 Feature pyramid network
图2中,自上而下的方法如图3所示,将上采样后的高维特征与经过1×1卷积的特征进行对应元素相乘(element-wise)后相加,得到与原特征图网络维度相同的特征图网络,使得每一低层特征图都含有一部分高层语义信息,提高模型对小目标检测的效率和能力。
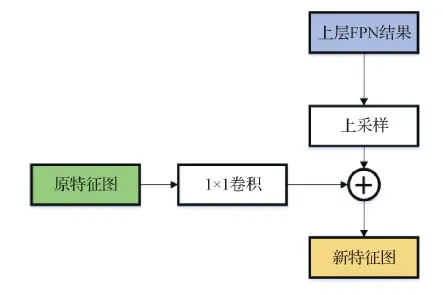
图3 FPN融合方法Fig.3 FPN fusion method
为使骨干网络输出特征图上使用FPN融合的效果更好,以输出表达能力更强的特征图,本文采用一种特征图优化选择策略。通过骨干网络能得到4幅维度不一的特征图r_c2,r_c3,r_c4,r_c5,结合FPN可以构造出多种融合方式,考虑融合对象和方式的不同,构造出8种融合策略:
策略1)为验证来自浅层网络特征r_c2的有用性,对骨干网输出的r_c3,r_c4,r_c5这3层进行FPN,最后对r_c5进行卷积(卷积核大小为3,步长为2,填充像素大小为1),生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,最后删除r_c5_conv3(2×2×256),以生成和原始SSD算法数量和尺度都相同的特征图组。
策略2)提取出骨干网的r_c2,r_c3,r_c4,r_c5,对这4层进行FPN,再对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,最后删除r_c2(75×75×256),r_c5_conv3(2×2×256),本策略可以与策略1)进行对比验证。
策略3)为探究浅层网络特征r_c2的有效融合方式,先提取出骨干网的r_c2,r_c3,r_c4,r_c5,并对r_c2做下采样与r_c3融合成r_c3′,然后对r_c3′,r_c4,r_c5做FPN,再对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,最后删除r_c5_conv3。
策略4)提取出骨干网的r_c2,r_c3,r_c4,r_c5,对r_c2做下采样与r_c3融合成r_c3′,然后对生成的r_c3′,r_c4,r_c5做FPN,再对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,为验证特征图r_c5_conv3的有效性,最后将r_c5_conv3下采样与r_c5_conv4融合。
策略5)对骨干网输出的r_c2,r_c3,r_c4,r_c5进行FPN,生成fpn_r_c2,fpn_r_c3,fpn_r_c4,fpn_r_c5。为探究r_c2经过FPN后的有效性,将fpn_r_c2下采样和fpn_r_c3进行融合,再对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,最后删除r_c5_conv3(2×2×256)。
策略6)前半部分同策略5),后面对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,为验证该情况下特征图r_c5_conv3的有效性,最后将r_c5_conv3下采样与r_c5_conv4融合。
策略7)前半部分同策略5),后面先对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,之后采用类似SSD算法生成额外特征图的方式,对r_c5_conv2再做卷积(卷积核大小为3,步长为1,填充像素大小为0),生成r_c5_conv3。
策略8)前半部分同策略4),后面对r_c5进行卷积,生成r_c5_conv1,r_c5_conv2,之后采用类似SSD算法生成额外特征图的方式,对r_c5_conv2做卷积(卷积核大小为1,步长为1,填充像素大小为0),生成r_c5_conv3。

在经过FPN处理后,生成如图4所示的8个特征图,为了保证模型对比的公平性,体现本文方法生成特征图的有效性,只保留与SSD算法维度及个数相同的6幅特征图。考虑保持最大尺寸为38×38像素,但由于75×75像素的特征图包含更多细节,直接舍去可能会影响对小目标的检测能力,因此通过增强融合的处理方法,将75×75像素特征图的信息做适当保留。如图5所示,将最大的fpn_r_c2(75×75×256)先经过一个1×1卷积(卷积核个数为256,卷积核大小为1,步长为1),然后再通过双线性降采样与一个经过1×1卷积(卷积核个数为256,卷积核大小为1,步长为1)的fpn_r_c3进行拼接,生成new_fpn_r_c3(38×38×512)来代替原来的fpn_r_c3。最终的输出是r_c5_conv1,r_c5_conv2,r_c5_conv4,r_c5,fpn_r_c4,new_fpn_r_c3。

图4 特征图优化选择Fig.4 Character diagram optimized selection
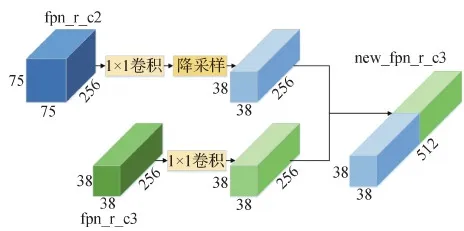
图5 特征图增强融合Fig.5 Feature diagram enhanced fusion
1.3 优选策略分析
在策略5)中,对骨干网络输出的4层特征进行FPN,保证了特征信息的全面性,在增强融合时,通过降采样将低层特征部分保留,同时保持最大图的尺寸不变,兼顾了速度和性能,在操作顺序上先FPN再增强融合,相当于进行一步反向FPN,比先增强再FPN的特征整合效果要好,最后去掉与r_c5_conv4功能重复的r_c5_conv3以减轻干扰。这是该策略优于其他策略的因素所在。
图6(a)为原始输入图像,图6(b)(c)为经过ResNet-50骨干网络输出尺寸为75×75和38×38像素的特征图,图6(d)为经过策略5)处理后的38×38像素的特征图,通过对比可以看出:高像素特征图6(b)包含的纹理、细节特征更丰富,低像素特征图6(c)虽然图像较模糊,但是对于目标图形轮廓和形状信息的语义更直观,经过策略5)得到的图6(d)既结合了高像素特征图的细节特征,又包含了低像素特征图丰富的语义表达,能够更好地描述目标对象。

图6 不同特征图输出对比Fig.6 Output comparison of different feature graphs ((a) original map; (b)backbone network output (75×75 pixels); (c) backbone network output (38×38 pixels); (d) policy 5 output(38×38 pixels))
1.4 并联双注意力机制
借鉴瓶颈注意力模块(bottleneck attention module, BAM)(Woo等,2018)和SE(sequeeze and excitation) (Hu等,2018)的思想,本文设计一种并联双注意力机制来整合特征图的通道和空间信息,通过通道注意力和空间注意力提高特征图对于目标形状和位置的双重聚焦作用,如图7所示。

1) Squeeze操作(Fsq)。对U特征图中的每个特征做全局平均池化操作,压缩成一个(1,1,C)的实数,具体为
(1)
式中,Zc表示Squeeze操作的输出,uc表示特征图的第c个通道,H和W表示特征图的高和宽,uc(i,j)表示第c个通道的第i行,第j列元素。
2) Excitation操作(Fex)。类似循环神经门的机制,通过参数W为每个特征通道生成权重,具体为
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(2)
式中,s为Excitation操作得到的权重,z为Squeeze操作的输出,W1和W2为全连接操作,δ为ReLU函数。
3) Reweight操作(Fscale)。将Excitation的输出的权重通过乘法加权到原先的特征上,具体为
(3)

图7 双注意力模块核心结构Fig.7 Core structure of dual attention module
空间注意力机制同样也由3个操作组成:
1) Pooling layer。将原特征图分别进行最大值池化和平均值池化,分别生成特征图a(W,H,1)与m(W,H,1),然后拼接,让得到的权重图既具有最大值信息,又具有平均值信息。
2) Convolution layer。将拼接后的权重图通过卷积核大小为7、填充大小为3的卷积操作,使得权重图的尺寸重新从c(W,H,2)降维到v(W,H,1)。
3) Reweight layer。将经过卷积层的权重图通过乘法加权到原先的特征上,得到特征图x(W,H,C)。
通过对每个特征图进行通道注意力机制和空间注意力机制的并联相加处理,有监督地强化重要的细节特征,削弱无用的干扰特征,同时,将特征图中的空间信息做相应的空间变换,提取其中重要的空间位置信息。
经过双注意力模块处理后的特征图如图8所示,图8(a)为原始输入图像,图8(b)为ResNet50骨干网络输出尺寸为38×38像素的特征图,图8(c)为经过双注意力模块处理后尺寸为38×38像素的特征图。通过对比可以看出,图8(b)基本上只保留了边缘特征,而图8(c)通过整合通道和空间信息,能同时提取到边缘特征、结构信息及色块信息,更能凸显出有效特征。

图8 不同特征图对比Fig.8 Comparison of different feature graphs ((a) original picture;(b) backbone network output; (c) dual attention module output)
1.5 FDA-SSD网络结构
在原始输入图像经过骨干网络和特征金字塔层后,得到7个特征层,如图9所示,分别为:new_fpn_r_c3,fpn_r_c4,fpn_r_c5,r_c5_conv1,r_c5_conv2,r_c5_conv3,r_c5_conv4,大小分别为38×38×512,19×19×256,10×10×256,5×5×256,3×3×256,2×2×256,1×1×256,然后加入双注意力机制进行权重分配计算,进行加法融合后得到同时含有通道和空间信息的特征图。最终FDA-SSD算法生成的预选框个数与SSD算法相同,但是得到的特征图包含了更多有效信息,因此该算法的边界框就更容易进行学习。

图9 FDA-SSD模型网络结构Fig.9 Network structure of FDA-SSD model
1.6 预测框与损失设计
为公平比较,本文算法的预测框与损失设计采用与SSD算法一致的方法,先验框的设置包括尺度和长宽比两个方面。从先验框的尺度来看,其会随着特征图大小的降低而线性增加,即
(4)
式中,m表示特征图数量,第1层是单独设置的,为说明本文方法的有效性,将m设置为5,与SSD算法保持一致,Sk为先验框与图像的比例(第1个框设置为0.1),Smax和Smin表示比例的最大和最小值,设定为SSD给出的值0.2和0.9。对于长宽比,选取αr∈{1,2,3,1/2,1/3},对于特定长宽比,计算先验框的宽度与高度,即
(5)

算法的损失函数分为2个部分:位置损失Lloc和置信损失Lconf,位置损失采用SmoothL1损失函数来计算真实框与预测框之间的误差,置信损失采用Softmax损失函数来计算分类准确率,损失函数表示为
(6)
式中,N表示正样本数量,x为一个指示参数,当x=0时,表示在某一类中先验框与真实框不一致;当x=1时,表示在某一类中先验框与真实框一致,c表示类别置信度预测值,l表示边界框的位置预测值,g表示真实框的位置。
2 实验结果与分析
2.1 实验平台与数据
实验采用Paddlepaddle 1.8.0作为开发框架,运行环境基于Tesla V100和Titan X,CUDA9.0和CuDNN7.6。数据集为PASCAL VOC(Everingham等,2010)2007+2012数据集和TGRS-HRRSD-Dataset(high resolution remote sensing detection)(Zhang等,2019)遥感数据集。预训练模型为ImageNet(Russakovsky等,2015)。
2.2 数据增强
为保证模型对比的公平性,本文设置与SSD算法一致的预处理方法与参数:1) 归一化。对图像进行归一化,加快梯度下降的求解速度;2) 随机翻转。将图像随机翻转一个角度;3) 标准化边界框。对生成的边界框进行标准化处理;4) 随机展开。对图像进行最大展开比为4、RGB填充画布值为(104,117,123)的图像展开;5) 随机裁剪。对图像按照一定尺寸范围进行随机裁剪;6) 随机扭曲。对图像进行亮度、对比度和饱和度分别在(0.875,1.125)、(0.5,1.5)和(0.5,1.5)区间的图像随机扭曲。
2.3 实验指标评估
算法评估指标采用平均精度均值(mean average precision, mAP),由准确率(precision)和召回率(recall)计算而来。
1)准确率。在所有预测为正类的样本中,实际为正类的占比,即
(7)
式中,TP表示实际为正类、预测为正类的样本,FP表示实际为负类、预测为正类的样本。
2)召回率。在所有预测中,实际为正类且预测为正类在所有实际为正类的占比,即
(8)
式中,FN表示实际为正类、预测为负类的样本。
3)通过准确率和召回率求出每一类的AP(average precision),然后再对AP取平均,得到mAP值,即
(9)
式中,N表示图像总数,p(k)表示第k幅图像的准确率,Δr(k)表示从第k-1幅图像到第k幅图像的召回率变化量,m表示所有图像的类别个数。
2.4 训练参数设置
训练参数如表1所示。

表1 训练参数Table 1 Training parameters
2.5 优化策略实验
表2显示了1.2节中基于Tesla V100的8种优化策略的实验结果,实验输入图像大小为300×300像素,训练15万轮,batch_size为16,训练数据集为PASCAL VOC2007+2012,测试集为PASCALVOC2007。
根据表2的结果,策略5)的准确率高于其他方案,策略3)和策略7)的速度较快,但是准确率过低,因此在兼顾准确率和检测速度的合理考量下,选择策略5)为最优策略,最终将基于该策略改进的SSD命名为F-SSD(fusion single shot multibox detector)。
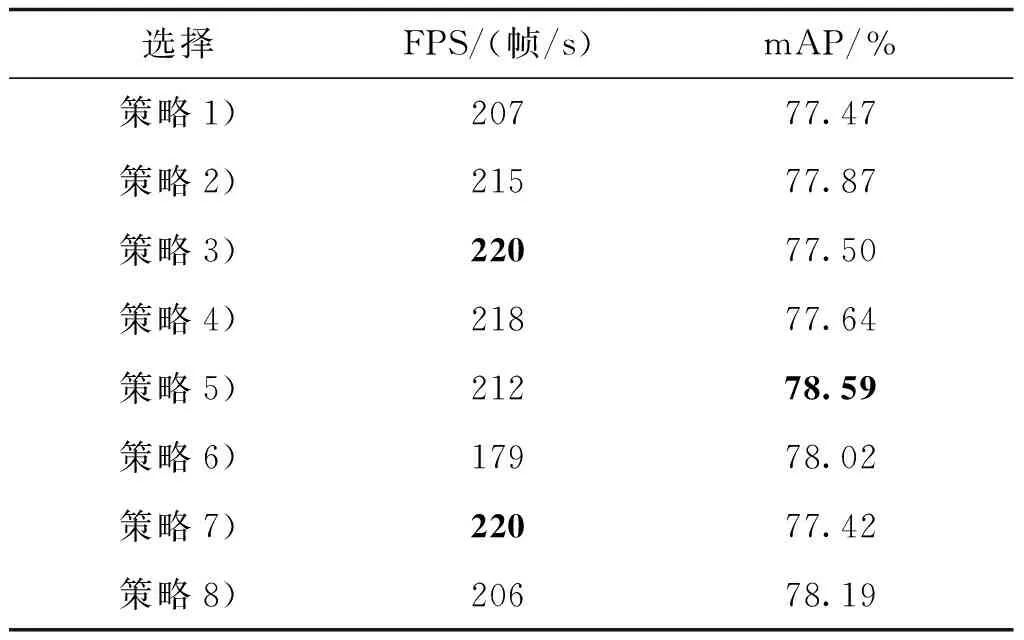
表2 各方案结果对比Table 2 Comparison of results of various schemes
最后在F-SSD的基础上加入双注意力模块进行消融实验,表3展示了基于Tesla V100上的消融实验结果。双注意力模块能有效提升模型的准确率,又能保持与模型的原检测速度相近,最终将此模型命名为FDA-SSD。

表3 注意力消融实验Table 3 Attention ablation experiment
2.6 骨干网络实验
以策略5)为融合策略,针对不同的骨干网络进行测试,训练数据集为PASCAL VOC2007+2012,测试集为PASCAL VOC2007,batch_size为8的训练轮数为36万轮,batch_size为16的训练轮数为15万轮。表4展示了基于Tesla V100上的实验结果,不同ResNet骨干网络的FDA-SSD模型的性能存在一定的差异,无论输入图像尺寸是300×300像素或是512×512像素,以ResNet50为骨干网络的检测速度最快,以CBResNet(composite backbone residual neural network)为骨干网络的准确率最高。将骨干网络从ResNet替换为CBResNet后,准确率平均提升1.7%,检测速度平均下降32帧/s。另外,骨干网络的深度也有不小的影响,无论是ResNet还是CBResNet,50层网络版本都比101层版本在准确率上低1%左右,但在检测速度上更快。因此对于FDA-SSD算法,采用替换为更深的骨干网络在提升准确率上有更显著的效果。
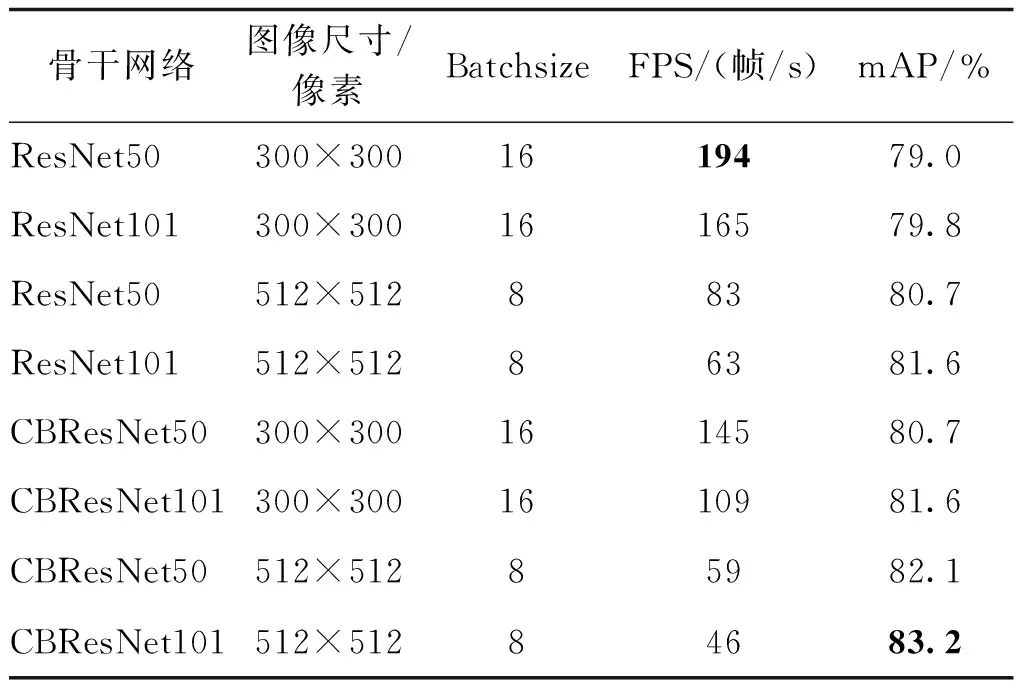
表4 不同类型ResNet与图像尺寸测试结果Table 4 Test results of different ResNets and image size
2.7 PASCAL VOC 2007数据集实验
表5显示了各种模型在PASCAL VOC2007数据集上的结果对比,这些模型包括了主流目标检测模型Faster RCNN和YOLO系列、SSD及其各种改进版和其他一些检测模型,表中的测试结果来自原算法作者论文的最优结果及一些公开平台的测评结果。
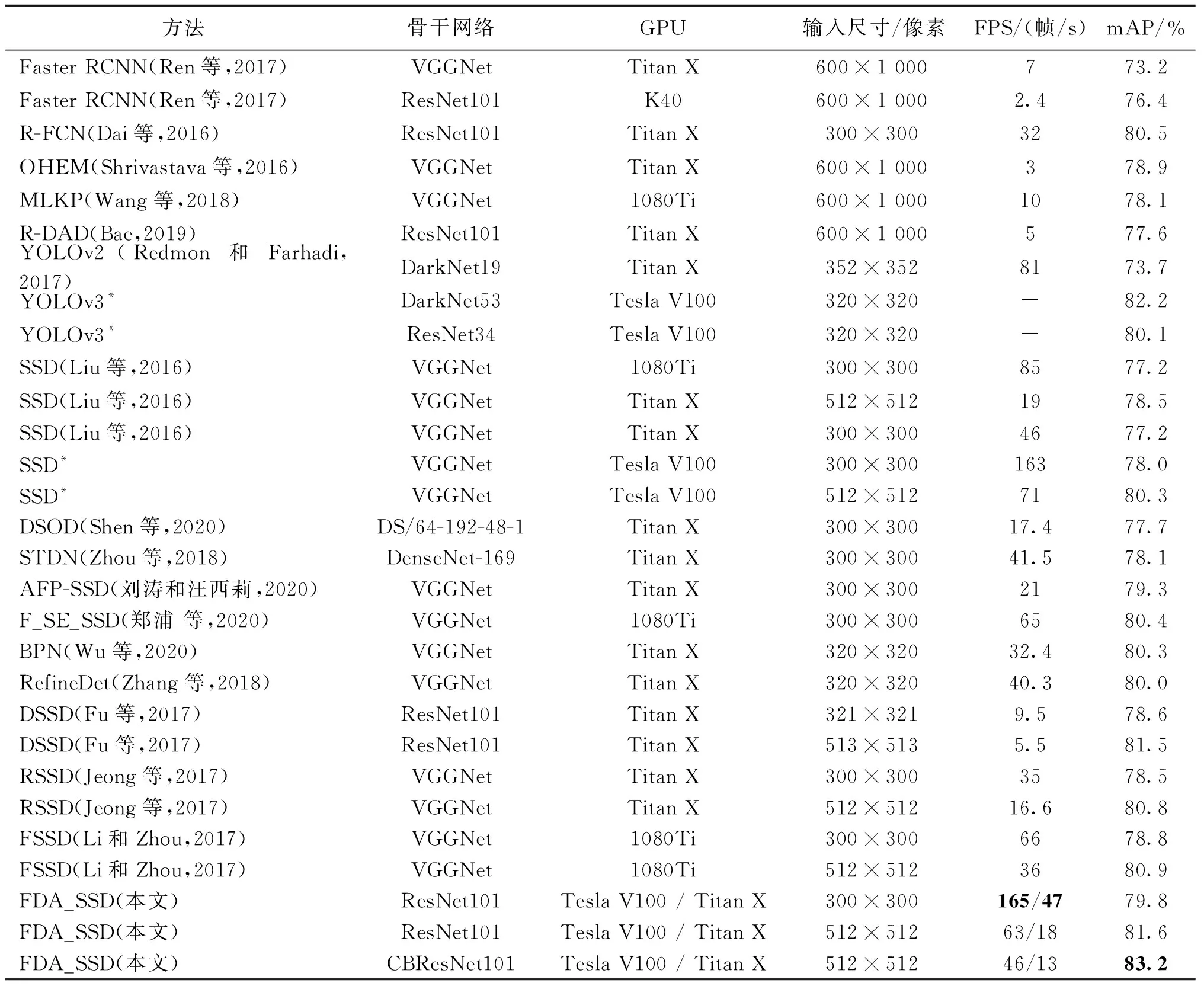
表5 各种算法结果对比Table 5 Comparison of results of various algorithms
以输入图像尺寸为300×300像素为例,FDA-SSD的推理速度与原始SSD算法相当,明显快于DSSD、RSSD、FSSD、AFP-SSD(atrous filter pyramid single shot detector)等各种SSD改进算法。而从准确率来看,FDA-SSD模型已经优于绝大部分的SSD改进模型。因此综合速度和性能来看,FDA-SSD达到了最好的平衡。实验还显示了当采用CBResNet为骨干网时,FDA-SSD可以达到更高的准确率,说明本文算法在不同的骨干网上都具有较强的适用性。
图10展示了各模型的mAP-FPS实验散点图,FDA-SSD512的mAP达到了81.6%,与SSD改进模型中准确率最高的以Resnet-101为骨干网络的DSSD512相当,但速度是DSSD512的3倍有余。FDA-SSD300的mAP达到79.8%,比SSD改进模型中准确率最高的以VGG16为骨干网络的FSSD300高1.00%,速度要更快。在以300×300像素为输入尺寸的各模型中,FDA-SSD300最靠近右上,充分显示了其在性能和速度上的双重优越性。

图10 各算法在PASCAL VOC2007测试集上的FPS与mAPFig.10 FPS and mAP of each algorithm in PASCAL VOC2007
图11展示了SSD模型与FDA-SSD模型的一些图片预测效果对比,其中上半部分图片为经过PASCAL VOC2007+2012训练集所训练出来的SSD模型,在PASCAL VOC2012测试集上的部分预测结果;下半部分图像为FDA-SSD模型在PASCAL VOC2012测试集上的部分预测结果。从对比中可以看出,SSD模型对于受遮挡(图11(a))、小目标(图11(b))、多目标重叠(图11(c))、图像模糊(图11(d))及大长目标(图11(e))的检测较为困难,而FDA-SSD模型的表现相对稳健很多。

图11 SSD模型与FDA-SSD模型在PASCAL VOC test2007测试集中图像预测效果对比Fig.11 Comparison of picture prediction effect between SSD model and FDA-SSD model on PASCAL VOC test2007 datasets((a)occluded target; (b)small target; (c)overlapping targets; (d)fuzzy target; (e)growth target)
2.8 TGRS-HRRSD-Dataset数据集实验
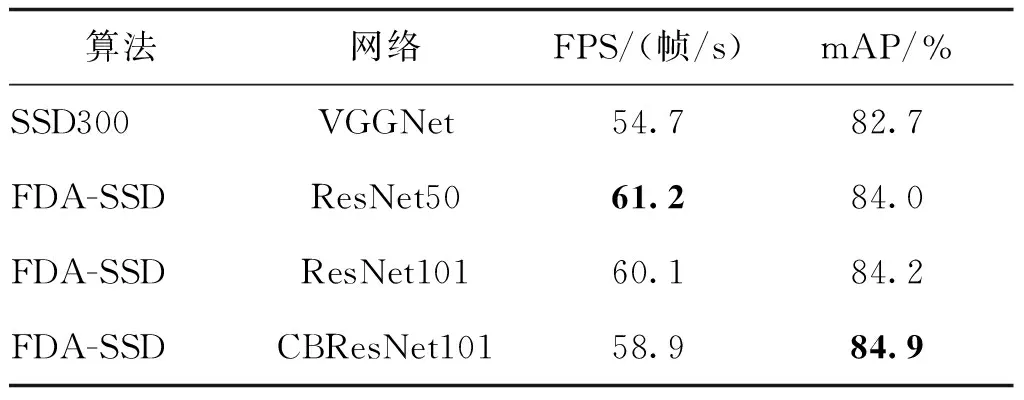
表6 TGRS-HRRSD-Dataset数据集上的算法结果对比Table 6 Comparison of algorithm results on TGRS-HRRSD-Dataset
3 结 论
本文提出了一种基于融合策略优化选择和双注意力机制的单目标检测模型FDA-SSD,采用层次更深的ResNet网络来代替原SSD算法中深度较浅的VGG16网络作为骨干网络,其次提出融合策略优化选择方法,通过在骨干网络之后增加特征金字塔,产生融合各种跨层信息的特征图候选集,经过不同的特征融合、删除图层和卷积运算等操作,选择出表征能力强、语义信息丰富的特征图组,最后增加双注意力机制,进一步优化各特征图中的通道权重。实验表明,相比现有的多种SSD改进模型,本文模型表现出精度和速度上的双重优势,在小目标、受遮挡、模糊图像等难目标的检测上也具有很好的性能。
虽然FDA-SSD模型在基于SSD系列改进模型中表现出色,但本文工作主要基于研究特征图的优化,而在预测框生成与非极大值抑制方法上还留有很大的研究空间,这些都有待在未来的工作中继续深入。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
中国新通信(2017年9期)2017-05-27
读者(2015年9期)2015-05-04
