
用于骨架行为识别的多维特征嵌合注意力机制
2022-08-09 12:38:20姜权晏吴小俊徐天阳
中国图象图形学报 2022年8期
姜权晏,吴小俊,徐天阳
江南大学人工智能与计算机学院,无锡 214122
0 引 言
行为识别任务的本质是分析视频动作并将其准确分类。由于人与对象交互的多样性及时空推理的复杂性,深度网络在行为分析领域的研究进展缓慢。行为识别任务中的核心需求是捕获复杂的空间信息及动态信息,并在高效处理视频数据的同时尽量使用较低的计算量。
与图像分类任务不同,视频信息的时间维度包含复杂多变的动态信息,其很难通过神经网络进行连贯的推理学习。从基于2维卷积神经网络的分类方法——时间分段网络(temporal segment networks, TSN)(Wang等,2016)到3维卷积网络(3D convolutional neural networks, C3D)(Tran等,2015)与双流膨胀3维卷积网络(two-stream inflated 3D convnets, I3D)(Carreira和Zisserman,2017),在网络建模能力不断提高的同时,网络复杂性的增加使行为识别领域的计算负担逐步增加。如何降低计算成本逐渐成为研究中不可忽视的问题,行之有效的方法是在深度神经网络体系结构中使用分解的3维卷积(Qiu等,2017)或组卷积(Tran等,2018)。这些方法在减少计算成本方面获得了进展,但缺乏同时捕获时间、空间和通道维度依赖性的能力。
在基于骨架信息的行为识别任务中,除了自适应骨骼中心算法(冉宪宇 等,2018),图卷积网络通过运用图结构中的关联信息大幅促进了识别性能的提升,包括动作图卷积网络(actional-structural graph convolutional networks,AS-GCN)(Li等,2019b)、时空图卷积网络(spatial temporal graph convolutional networks,ST-GCN)(Yan等,2018)、双流自适应图卷积网络(two-stream adaptive graph convolutional networks,2s-AGCN)(Shi等,2019b)和有向图神经网络(directed graph neural networks,DGCN)(Shi等,2019a)。该类方法的关键在于为骨架数据确定合适的图形结构,以便图卷积网络能够提取相关特征。然而,如何在图卷积网络中设计一种高效、灵活的多维特征嵌合模块以融合各维度的依赖关系仍是一个尚未解决的问题,本文旨在沿该方向推进包含空间、时间和通道维度在内的注意力机制研究。
注意力机制已在计算机视觉领域得到广泛应用。例如,行为识别任务中的时空注意力网络(Du等,2018)、机器翻译任务中完全取代卷积神经网络的自注意力模型(Vaswani等,2017)、建立图像中每对像素依赖性的非局部注意力网络(Wang等,2018)以及通过全连接层学习上下文依赖关系的池化注意力网络(Miech等,2018)。随着国内外学者对注意力机制进行深入研究,融合两种注意力机制的双重注意力网络逐渐大规模使用。例如,用于场景分割(Fu等,2019)、交互推理(Xiao等,2019)和行为识别(Woo等,2018)的双重注意力网络模型。
本文着重设计一种自适应注意力机制,通过更加灵活简易的方式同时捕获时空动态信息及通道依赖信息。该注意力模型赋予原始特征相应权重,丰富原始特征动态信息并增大不同行为类间差异。区别于以往只能增强空域或时域信息的研究工作,该注意力机制可同时提高多个维度的特征表现能力。这种多维特征嵌合注意力机制(multi-dimensional feature fusion attention,M2FA)同时关注时域与空域的动态信息和通道维度的上下文依赖关系,学习增强行为序列中的关键节点——“何时”、“何处”以及“何种依赖关系”。
为了验证M2FA的有效性,在NTU-RGBD(Shahroudy等,2016)和Kinetics-Skeleton(Yan等,2018)数据集上进行实验,并通过将M2FA移植到不同的骨干图卷积网络,验证其广泛的有效性和适用性。使用M2FA的图卷积网络在基于骨架数据的行为识别任务中相较于其他同类型网络获得了明显优势,产生了显著的性能提升。
本文主要贡献如下:1)提出一种用于骨架行为识别的多维特征嵌合注意力机制M2FA,通过增强特征表现能力提高图卷积网络识别性能;2)M2FA同时捕获时域和空域的动态信息及通道维度蕴含的上下文依赖关系,单个注意力模型即可增强多个维度的特征表现能力;3)M2FA同时参考全局信息和局部信息对特征权重的影响,通过不同感受野的信息融合增强原始特征;4)不同公开数据集实验结果显示,M2FA应用于不同图卷积网络架构均能改善网络识别能力。
1 相关工作
1.1 基于骨架数据的行为识别
由于在视频分类及智能监控等领域不可或缺的作用,行为识别一直是计算机视觉中重要的研究主题。例如,多特征融合算法(谭等泰 等,2020)在基于视频数据的行为识别中结合多种特征压缩原始数据,获得了更高的识别精度。与直接使用视频数据不同,基于骨架数据提出了众多不同的体系结构。骨架数据使用人体关节在空间中的2维或3维坐标表示人体,因此了解动作序列中每个人体关节在时域及空域中的动态变化至关重要。在单帧中连接相邻关节点、在连续帧序列中连接代表相同位置的关节点构造时空图结构是一种简洁直观建立时空依赖性的方法。AS-GCN(Li等,2019b)提出一种编码器与解码器联合结构捕获动作序列包含的潜在依赖关系。Shi等人(2019b)使用多分支架构搭建双流自适应图卷积网络2s-AGCN,该框架同时考虑关节信息和骨骼信息。通过计算相邻关节点坐标的矢量差表示关节点之间的骨骼信息。虽然关节流信息和骨骼流信息共同丰富了图卷积结构中的空间信息,但在捕获动作序列中的运动信息上,单纯增加信息流并不能高效地挖掘连贯的空间信息中包含的动态信息。因此,本文避免以大幅增加计算负担为代价提高模型的准确性,通过注意力机制充分挖掘特征映射中忽视的动态信息及上下文依赖关系。
1.2 注意力机制
注意力模块已经广泛应用于大规模的分类任务中,它们往往通过捕获上下文相关性来增强卷积神经网络的性能。SE-Net(squeeze-and-excitation networks)(Hu等,2018)通过建模输入特征的通道间关系,得到不同通道的权重附加至原始输入特征之上,达到了根据通道间关系进行特征重标定的目的。卷积块注意力模块(convolutional block attention module,CBAM)(Woo等,2018)通过添加最大池化推断更精确的通道注意力,并结合空间注意力模块形成双流注意力机制。但以往应用于卷积神经网络的注意力机制在基于骨架数据的图卷积网络中性能受到诸多限制,核心原因在于关节点信息与视频像素信息不同,往往由工具箱分析视频数据生成的人体关节坐标序列构成。盲目结合多种池化操作或应用复杂的卷积层将凸显骨架信息中的噪声信息,降低不同动作类别之间的差异表现。
CBAM(Woo等,2018)提出空间注意力模块和通道注意力模块共同强化图像信息中蕴含的空间及通道依赖性,两种注意力模型应用形式如图1所示。

图1 CBAM注意力模型结构图Fig.1 Diagram of convolutional block attention module
SE-Net只关注通道上下文依赖关系,而CBAM是一种结合空间与通道注意力机制的模块。两种注意力模型结合的方法是串联处理输入特征。除此之外,在场景分割任务中提出的双重注意力网络(Fu等,2019),其空间注意力模块与通道注意力模块采取了并联处理输入特征的结合方法。但上述方法本质上都运用多种关注不同维度的注意力模块进行堆叠,且双重注意力机制的模式依旧不能满足行为识别任务中同时捕获多个维度之间依赖性的需求。即基于骨架数据的行为识别任务中,如何利用注意力机制获取多维度依赖信息尚未得到深入研究。本文对于注意力机制的研究旨在仅通过一个包含多维特征嵌合模块的注意力模型,捕获以往双重注意力模型难以提取的多维特征协同依赖信息,进而增强图卷积网络的分类学习能力。
2 多维特征嵌合注意力机制
2.1 多维特征描述符
在基于视频数据的行为识别框架中,如关键语义区域链框架(马淼 等,2020),原始数据经过卷积神经网络转换为F∈RN×C×H×W×T的特征映射。其中,N代表数据批量大小,C表示特征映射的通道数,H与W分别表示特征图的高与宽,T表示视频序列特有的时间维度。与原始视频数据不同,骨架信息表示为X∈RN×C×T×V×M。其中N、C、T在特征映射中的含义不变。由于骨架信息与图像信息性质不同,C表示的维度在输入图卷积网络之前由关节点的空间坐标信息和置信度分数组成,而V表示图结构中的关节点数目,M为在该序列中出现的最大有效人数,通常固定M为2。因此,图卷积网络为了便于计算,通常将形如X的原始数据重塑为X′∈R(N×M)×C×T×V的形式,将N×M看做总数据批量大小。本文将图卷积网络中的特征映射维度简化表示为N×C×T×V。

(1)
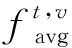

(2)
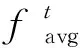
时域特征描述符则映射了每一帧在当前动作序列中的重要程度,是包含动态信息最丰富的维度。TSM(temporal shift module)(Lin等,2019)通过将特征映射在时间维度上错位移动的方法使2维卷积网络不增加计算负担也能进行时空建模。本文利用时间移位操作集成每一帧与相邻帧之间的特征差异,以不增加模型复杂度的形式获取更加丰富的动态信息。移位操作的过程如图2所示。
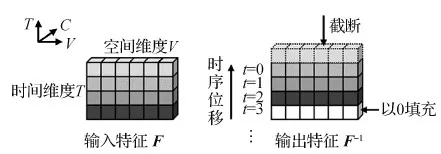
图2 时间位移操作结构图Fig.2 Diagram of temporal shift operation

(3)
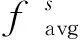
2.2 多维特征描述符融合
通过压缩全局信息提取不同维度的特征描述符之后,将其输入特征融合模块,使评估时域信息、空域信息及通道上下文依赖信息的标准集成在同一个特征映射之中。该多维特征描述符融合模块的结构如图3所示,图中⊕代表通道维度的级联操作。
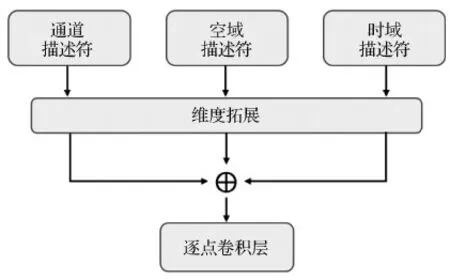
图3 特征融合操作结构图Fig.3 Diagram of feature fusion operation
(4)
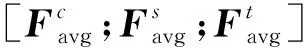
2.3 多尺度特征嵌合
卷积神经网络中的多尺度金字塔结构(Chen等,2016)经常用于融合多层特征获取高分辨率语义特征。本文除了融合多维特征描述符以加强特征映射表现外,还通过嵌合多尺度特征达到全局与局部注意力机制相结合的效果。该多尺度特征嵌合模块的结构如图4所示,图中⊕代表两个特征映射逐位相加,绿色区域表示多维特征描述符的融合过程,黄色区域表示多尺度特征嵌合模块。
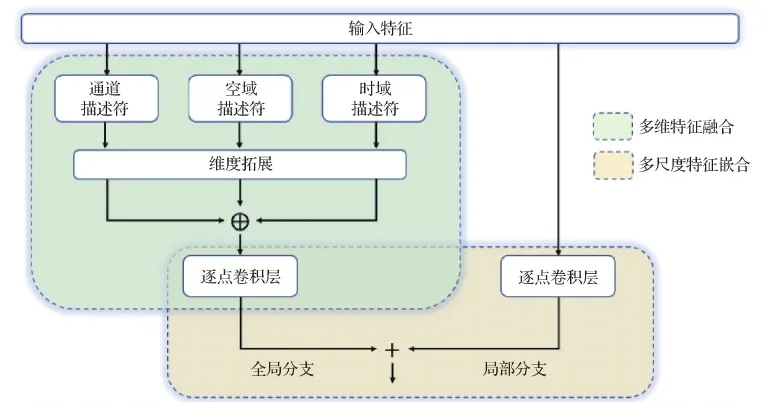
图4 多尺度特征嵌合结构图Fig.4 Diagram of multi-scale feature fusion operation
由于特征描述符的提取计算中包含全局平均池化操作,多维特征描述符仅由各维度的全局压缩信息构建而缺乏局部信息与之相互补偿。为了兼顾注意力机制的轻量级,利用逐点卷积层从原始特征映射中直接学习局部上下文信息。将全局信息与局部信息构建的特征映射逐位相加,从而嵌合多尺度特征,进一步增强特征表现能力。获取多维特征描述符是多尺度特征嵌合模块的基础。通过全局信息分支与局部信息分支的特征融合,多尺度嵌合特征Fscale∈RN×C×T×V的计算过程可概括为
(5)
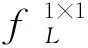
2.4 多维特征嵌合注意力模型
通过上述多维特征描述符与经过逐点卷积的原始特征映射进行嵌合,新的融合特征同时具备多维度全局依赖信息和局部上下文信息。通过对该特征融合结果进行批量标准化及激活处理,可以捕获原始特征映射的注意力权重图M∈RN×C×T×V,本文选取了sigmoid激活函数重置注意力权重的分布。对于给定的注意力权重图M与原始输入特征F,经过多维特征嵌合注意力模型逐点重置权重的过程为
FM2FA=M⊗F=σ(BN(Fscale))⊗F
(6)
式中,⊗表示一一对应的逐点相乘,FM2FA则是通过多维特征嵌合注意力机制增强后的特征映射。BN代表批量标准化操作,σ是sigmoid激活函数。
多维特征嵌合注意力模型不仅集成多个维度的特征描述符共同构建关键帧、关键节点和关键上下文依赖关系,且同时嵌合局部信息与全局信息加强特征表示。M2FA的整体框架如图5所示,多维特征嵌合注意力模型主要分为3个阶段,即多维特征融合、多尺度特征嵌合以及注意力权重映射。多维特征嵌合注意力模型仅通过一次注意力权重映射即加强了以往双重注意力机制忽略的多维依赖关系及局部信息,相比于其他类似CBAM应用多个注意力权重映射的双重注意力结构(如图1所示),M2FA避免多次应用激活函数,以防特征映射信息强度削弱。同时,注意力模型整体仅由两个逐点卷积层辅助融合特征信息,相比于其他类似SE-Net结构的注意力机制堆叠多个全连接层,M2FA节省了额外的计算开销。
2.5 多维特征嵌合注意力机制与原始框架集成
本文提出的多维特征嵌合注意力机制可以无缝集成到基于骨架数据的行为识别网络架构中,有效提升网络识别准确率。注意力模块与原始框架的集成方式如图6所示。如图6(a)所示,与普通卷积神经网络一样,图卷积网络由多个图卷积块堆叠构成,其中每个图卷积块包含如图6(b)所示的图卷积单元。在图6(b)所示AGCN块原始结构中(Shi等,2019b),⨁表示残差连接的逐位相加。每个AGCN图卷积块都由空间图卷积与时间图卷积共同构成。输入特征通过两种图卷积计算后都会归一化并激活,且在两种图卷积单元之间添加dropout层可以有效避免网络训练过拟合。M2FA在原始图卷积块中的具体叠加位置如图6(c)所示,图中⊗表示M2FA将注意力权重图与原始AGCN图卷积单元的输出特征逐元素相乘,以达到强调或抑制相应维度信息的目的。
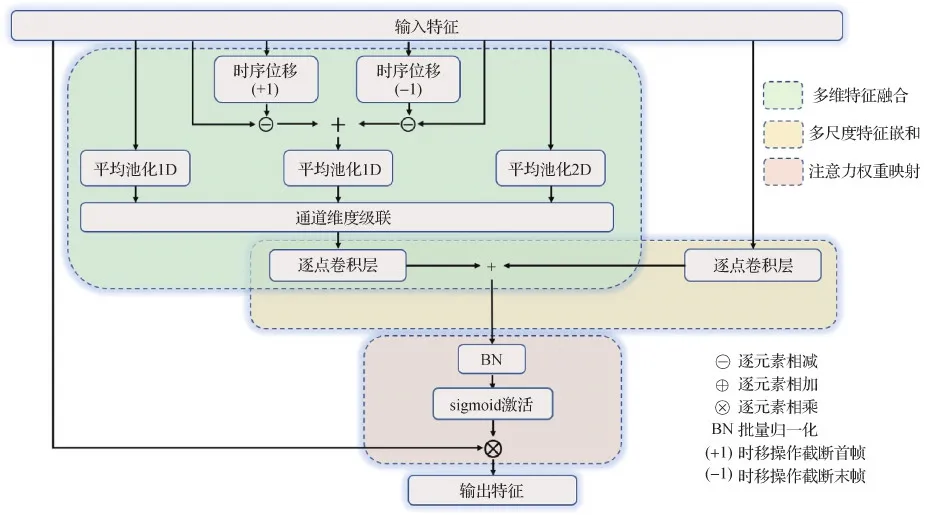
图5 多维特征嵌合注意力机制结构图Fig.5 Diagram of multi-dimensional feature fusion attention mechanism
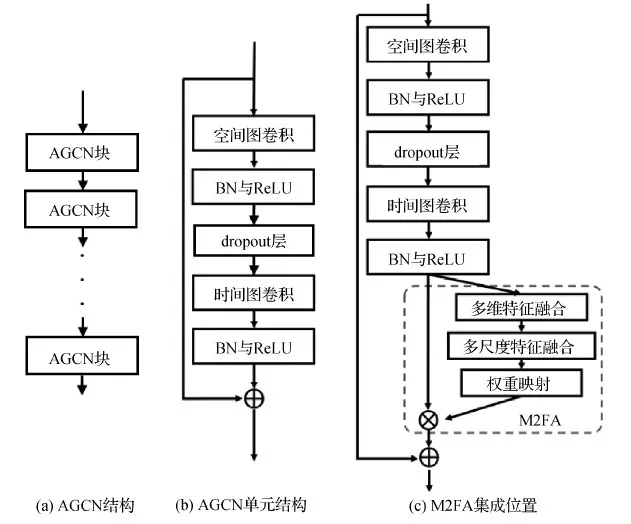
图6 M2FA与AGCN块集成结构图Fig.6 M2FA integrated with AGCN blocks in 2s-AGCN((a) AGCN block; (b) AGCN unit; (c) M2FA integrated)
2.6 自适应图卷积网络框架
本文致力于通过多维特征嵌合注意力机制增强原始图卷积网络的特征映射表现能力。对于叠加M2FA模块的基线方法,保持其原始网络框架设定。如图6(a)所示,2s-AGCN网络(Shi等,2019b)由自适应图卷积块堆叠而成,具体的图卷积模块堆叠方式及网络构成细节如图7所示。2s-AGCN框架包括9个图卷积模块连接。批量归一化层(batch normal-ization,BN)在网络开始位置,用于规范化原始输入数据。数据规范化操作后,使用一个特殊的不包含残差连接的图卷积模块增加原始特征映射的通道数量。随后将9个图卷积模块分成3组连续堆叠,每组包含3个图卷积模块,不同组的图卷积模块输出通道数量依次为64、128和256。图卷积网络的初始步长为1,如果卷积块的输入与输出特征的通道数量不同,则将步长提升为2。全局平均池化层放置在图卷积模块之后,用于强制不同的动作序列样本生成大小相同的特征图。动作序列分类结果由网络末端的softmax分类器生成。

图7 双流自适应图卷积网络(2s-AGCN)框架Fig.7 Illustration of the 2s-AGCN
3 实验及分析
为了验证本文提出的多维特征嵌合注意力机制的有效性,在两个大型公开骨架数据集NTU-RGBD(Shahroudy等,2016)和Kinetics-Skeleton(Yan等,2018)上进行实验。同时,为了验证注意力机制在不同图卷积网络体系结构中的普遍适用性,在Pytorch框架中重现了ST-GCN(Yan等,2018)与2s-AGCN(Shi等,2019b)网络,并通过在实验中添加注意力模块对比识别准确率。
3.1 数据集与实验环境
消融实验在NTU-RGBD(Shahroudy等,2016)和Kinetics-Skeleton(Yan等,2018)数据集上进行,采用2s-AGCN作为骨干网络框架,评估每个特征融合模块的效果。Kinetics-Skeleton数据集包含400个类别,30万个人体动作序列。NTU-RGBD数据集包含60个动作类别,56 880个人体行为序列,分为Cross-Subject和Cross-View两组基准。Cross-Subject基准的训练集和测试集分别包含40 320和16 560个动作片段,Cross-View基准的训练集和测试集分别包含37 920和18 960个动作片段。
实验均使用两个2080Ti GPU进行。在NTU-RGBD的两组基准中,训练周期均为50,初始学习率为0.1,在第30个训练周期转换为0.01,在第40个训练周期转换为0.001。对于Kinetics-Skeleton数据集,网络训练周期延长为65,分别在第45和第55个训练周期衰减学习率。
3.2 消融实验
M2FA由3部分构成,分别是多维特征描述符融合、多尺度特征嵌合以及自适应注意力机制的映射。消融实验的目的是验证多维特征嵌合注意力机制中每个组成部分的合理性。与2s-AGCN(Shi等,2019b)为了减少歧义采取的实验策略相同,本阶段消融实验中标示的AGCN与实验结果阶段标示的2s-AGCN代表的含义不同,AGCN表示基线方法仅采用单个信息流作为输入数据,而2s-AGCN代表同时将关节流信息和骨骼流信息作为输入数据的双流网络架构分类结果。为了验证多维特征嵌合结构的合理性,使用单个信息流作为输入可以有效避免双流框架对融合策略的效果产生干扰。
3.2.1 多维度特征描述符的有效性验证
实验使用Kinetics-Skeleton的关节流数据验证融合多个维度特征描述符的有效性。为了防止局部上下文信息对特征映射的表现能力产生干扰,本阶段采取的策略是仅使用多维特征描述符融合模块及自适应注意力图映射模块。通过控制参与特征描述符融合的维度数量验证融合策略的合理性。为了更直观地验证M2FA作为注意力机制的优势,对比骨干AGCN网络与SE注意力模块(Hu等,2018)结合的识别效果,获得的测试集分类准确率如表1所示,其中策略C、S、T分别表示注意力机制融合了通道(C)特征描述符、空域(S)特征描述符和时域(T)特征描述符。由表1可见,SE注意力机制对基于骨架数据的行为识别框架帮助有限,而如今应用范围较广的自适应注意力机制多启发于SE注意力机制,其中包括CBAM等众多双重自适应注意力机制。由此可见,研究多维特征嵌合注意力机制对基于骨架数据的行为识别任务来说至关重要。CBAM等双重注意力框架仅融合SE通道注意力机制及空间注意力机制,而M2FA同时考虑特征映射的所有信息维度(时间、空间、通道)。对于视频序列,CBAM等双重注意力框架忽视了时间维度的动态信息以及多尺度关联信息。
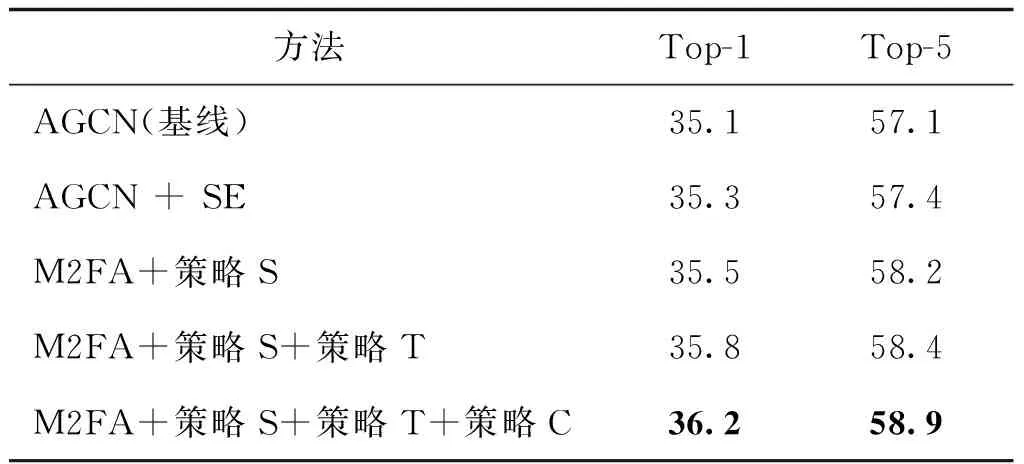
表1 不同融合策略在Kinetics-Skeleton上的实验结果Table 1 Comparison of different fusion strategies on the Kinetics-Skeleton test set /%
如上所述,广泛应用的SE注意力机制及CBAM注意力机制主要针对RGB图像进行分析加强。对于加强通道维度上下文依赖性的SE注意力机制来说,RGB图像信息与骨骼序列信息生成的特征映射尚有共通之处,因此SE模块能够微弱提升基线方法AGCN的分类效果(表1)。对于CBAM中针对RGB图像信息提出的空间注意力机制,由于RGB信息与骨架信息构成的空间要素差异较大,RGB图像的空间信息由高×宽的像素信息组成,而骨架序列的空间信息由人体关节点的坐标构成,故而缺乏在基于骨架信息的图卷积网络中应用CBAM双重注意力模型的实践意义。本文研究的M2FA受以往注意力机制架构的启发,不再局限于单一维度或两个维度的信息加强,注重多个维度特征表现能力的增强,弥补了骨架信息行为识别领域对于多维特征嵌合注意力机制研究的忽视。
根据表1展现的实验结果,只有将3个维度的特征描述符统一融合才能获取最好的识别效果,单纯使用一个维度的特征描述符完成自适应注意力图映射或结合两个维度的特征描述符都不能完整地捕获关键帧、关键关节点以及关键上下文依赖信息。因此,本文提出的多维特征描述符融合模块能够有效帮助骨干网络获取更高的分类准确率。
3.2.2 全局信息和局部信息的有效性验证
实验使用NTU-RGBD的关节流数据在Cross-Subject基准验证全局信息与局部信息融合模块的有效性,获得的测试集分类准确率如表2所示,其中“全局”表示直接使用多维特征描述符生成注意力权重图,“全局 + 局部”表示增添了多尺度特征嵌合模块使之构建为完整M2FA获得的分类准确率。由表2的结果可知,M2FA不仅能在大型数据库Ki-netics-Skeleton中促进图卷积网络加强特征映射中的关键信息,在NTU-RGBD数据库中也能达到同样的优异效果。M2FA将输入特征映射直接进行逐点卷积获得的局部上下文信息与多维特征描述符压缩的全局上下文信息形成互补,合理运用互补融合后的全局与局部信息生成了更准确的注意力权重图。因此,通过逐点卷积操作学习输入特征的局部信息是必不可少的。
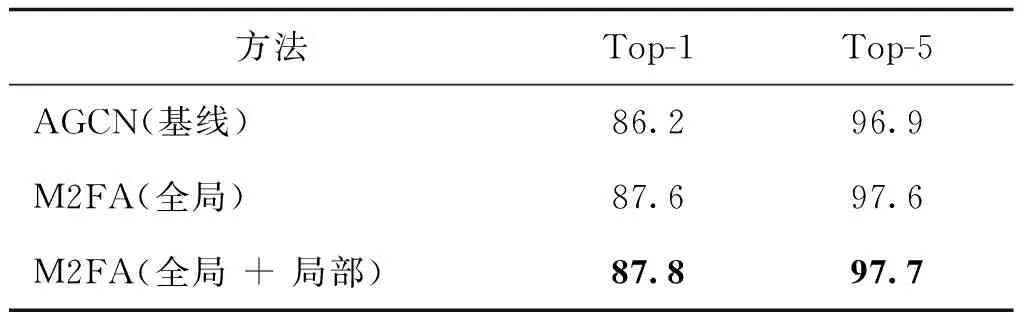
表2 不同聚合规模在NTU-RGBD上的实验结果Table 2 Comparison of different aggregation scales on the NTU-RGBD test set /%
3.2.3 拓展至其他图卷积网络的有效性验证
为了进一步验证本文提出的M2FA的广泛有效性,将其拓展至骨骼流及其他基于骨架数据的图卷积网络中验证其有效性。相比于关节流是由工具箱在视频数据中直接提取关节点坐标信息,骨骼流数据是由关节流数据计算而来。图结构中每两个相邻关节点之间坐标的矢量差定义为骨骼信息,因此骨骼信息往往有更多的噪声,分类效果也与关节流略有差距。关节流和骨骼流互补的双流网络与基于视频数据的RGB流和光流互补的思想类似,都是通过更多的信息流直接补偿相应的空间信息与动态信息。表3是在Kinetics-Skeleton数据集中将M2FA应用至骨骼流的实验结果。由表3可知,即使在不同的信息流中,M2FA依旧能捕获关键骨骼、关键帧及关键上下文依赖关系。通过对比表1与表3,发现M2FA对骨骼流的提升效果比关节流显著,说明多维特征嵌合注意力机制可以准确地使骨骼流注意关键信息,并尽可能削弱了噪声信息强度。
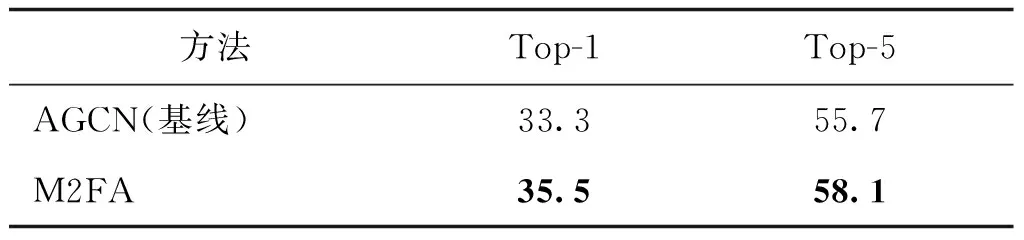
表3 骨骼流在Kinetics-Skeleton上的分类结果Table 3 Classification accuracy of bone flow on the Kinetics-Skeleton test set /%
3.2.4 可视化对比
为了更直观地验证M2FA相对于基线方法2s-AGCN的改进效果以及M2FA相较于SE注意力模块在骨架图卷积网络中的优势,将可训练的邻接矩阵可视化。图8展示了2s-AGCN中自适应邻接矩阵的可视化结果。矩阵中每个元素的灰度表示一对关节在空间维度的连接强度。图8(a)是NTU-RGBD数据集中的原始邻接矩阵,ST-GCN(Yan等,2018)在训练的过程中采用这种固定连接强度的邻接矩阵,使图卷积网络学习到的依赖关系受限于物理连接(如手与手腕)。图8(b)是2s-AGCN训练得到的自适应邻接矩阵,可学习的邻接矩阵相较于固定连接强度的邻接矩阵更加灵活,且不受人体关节物理连接的限制,能够学习距离较远的关节之间的依赖关系(如手与脚)。图8(c)是叠加了SE注意力模块训练得到的邻接矩阵,以往广泛应用于RGB信息研究领域的SE注意力机制既不能增强骨架序列物理连接关节点之间的依赖关系,也不能捕获非物理连接关节点之间的关联信息。图8(d)是M2FA邻接矩阵,与其他邻接矩阵对比可知,M2FA训练得到的邻接矩阵同时捕获关节点之间的物理连接及非物理连接的依赖关系,且连信息丰富程度。图8验证了M2FA对于基线方法2s-AGCN的提升效果,体现了M2FA在基于骨架信息的行为识别任务中相较于SE注意力模块的优势。
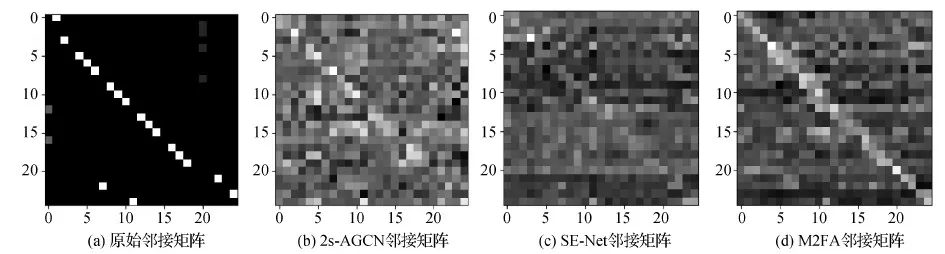
图8 可训练的邻接矩阵可视化Fig.8 Example of the learned adjacency matrix ((a) original adjacency matrix; (b) adjacency matrix learned by 2s-AGCN; (c) adjacency matrix learned by SE-Net; (d) adjacency matrix learned by M2FA)
M2FA除了应用于AGCN(Shi等,2019b)架构中,还可用于其他图卷积网络。表4显示了使用关节流信息将M2FA应用于图卷积网络ST-GCN(Yan等,2018)获得的分类准确率。可以看出,即使在不同的图卷积架构中,M2FA依旧能够合理重置关键信息权重,并稳定提升图卷积网络的分类性能。
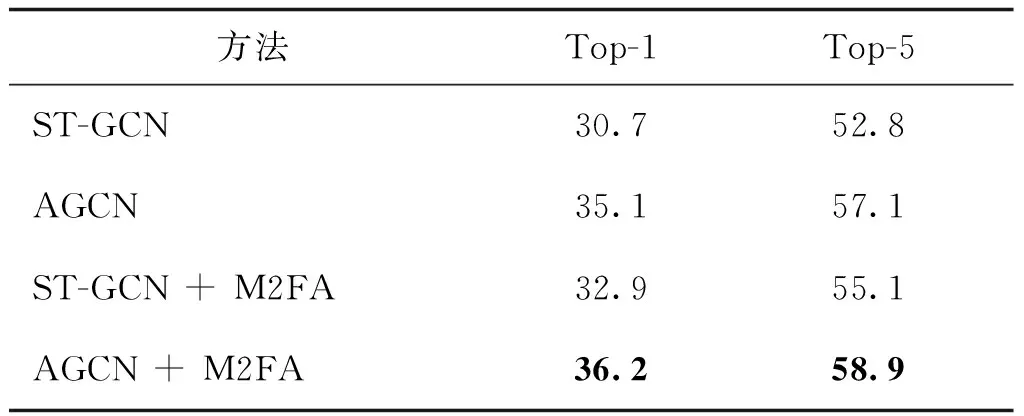
表4 不同基准在Kinetics-Skeleton数据集的实验结果Table 4 Comparison of different baselines on the Kinetics-Skeleton test set /%
3.3 实验结果
根据上述消融实验的评估结果,M2FA在大规模数据集中能够显著提高行为识别任务的分类准确率。为了进一步展现其优势和有效性,以2s-AGCN为骨干网络,将使用M2FA增强的关节流与骨骼流的识别效果进行融合,获得最终的双流网络分类性能,分类结果如表5所示。其中NTU(cv)和NTU(cs)分别表示M2FA在NTU-RGBD数据集Cross-View基准和Cross-Subject基准中的分类准确率,KS是在Kinetics-Skeleton数据集中的分类准确率。
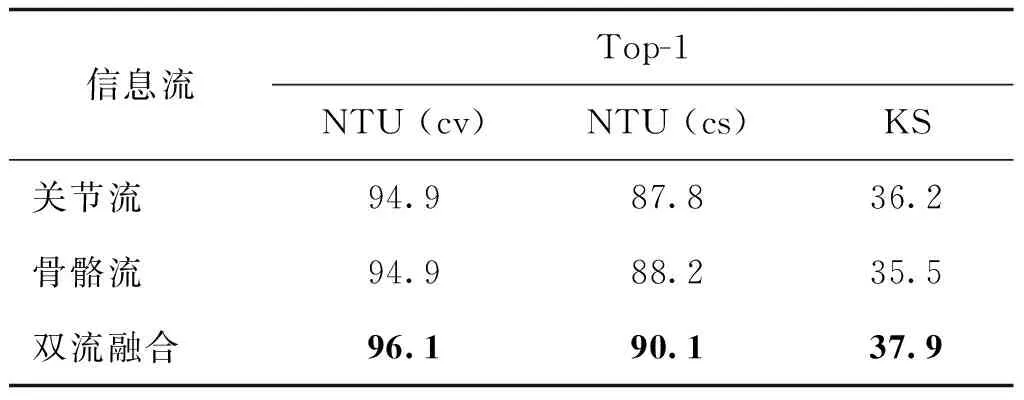
表5 双流融合的分类结果Table 5 Classification accuracy of two stream fusion /%
将表5中双流融合结果与Kinetics-Skeleton和NTU-RGBD上的最新算法进行比较,结果如表6和表7所示。实验详细列出了在NTU-RGBD的两种不同基准及Kinetics-Skeleton中的识别精度。经过M2FA加强后的2s-AGCN不仅分类准确率显著提高,且在与较新算法,如DGNN(directed graph neural network)(Shi等,2019a)、NAS(neural architecture search)(Peng等,2020)的对比中的取得优势。表6与表7中,DGNN并非通过轻量级注意力模型提升特征的表现能力,而是通过融合骨架信息的不同信息流提高分类准确性。DGNN不仅包含空间流信息还计算了骨架序列的运动流信息。运动流信息通过计算两个连续帧内对应的关节或骨骼坐标差异得到。故而为了提升分类准确率,DGNN采取的方法是使用4种不同的信息流提供更多的空间信息和动态信息,这意味着消耗巨大的计算资源且通过大量迭代学习才能完成收敛。2s-AGCN中的双流识别算法是将关节流和骨骼流信息作为网络模型的输入数据,虽然包含了两种不同信息,但都属于空间流信息。NAS通过定义新的时空动态模块建立恰当的网络结构提升模型的识别准确率,同样忽视了使用注意力模型加强网络识别能力。这意味着近期针对骨架数据行为识别的研究注重通过给网络输入更多的信息源以及改变时空图结构寻求更强大的特征表现能力,忽略了信息流本身尚未挖掘的时空动态信息。M2FA从更精细且节省计算资源的角度实现了网络性能提升,有效增强了关键维度及关键上下文信息,显示了同时捕获丰富上下文依赖性和准确增强不同维度关键特征的良好效果。
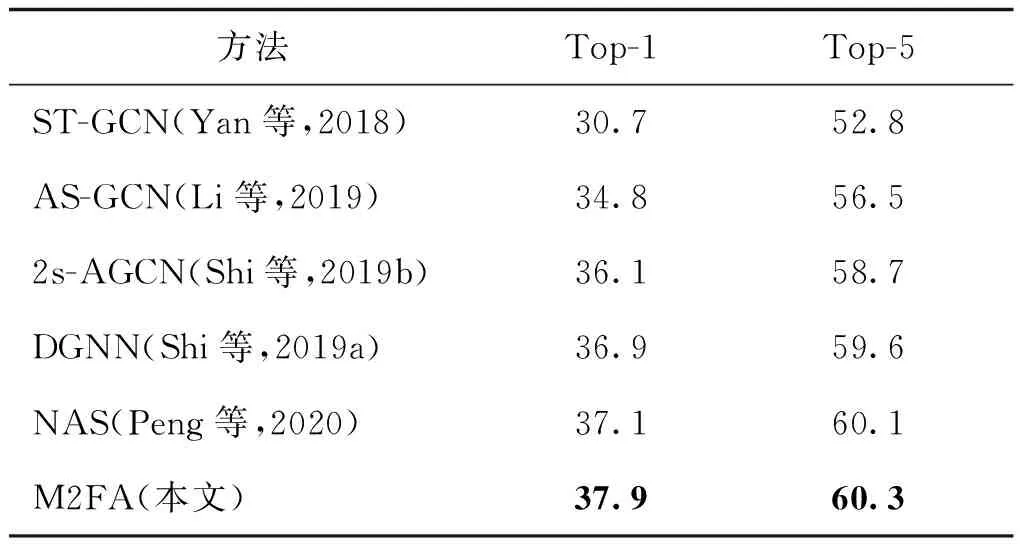
表6 在Kinetics-Skeleton数据集对比当前方法的效果Table 6 Performance comparison on Kinetics-Skeleton with current methods /%
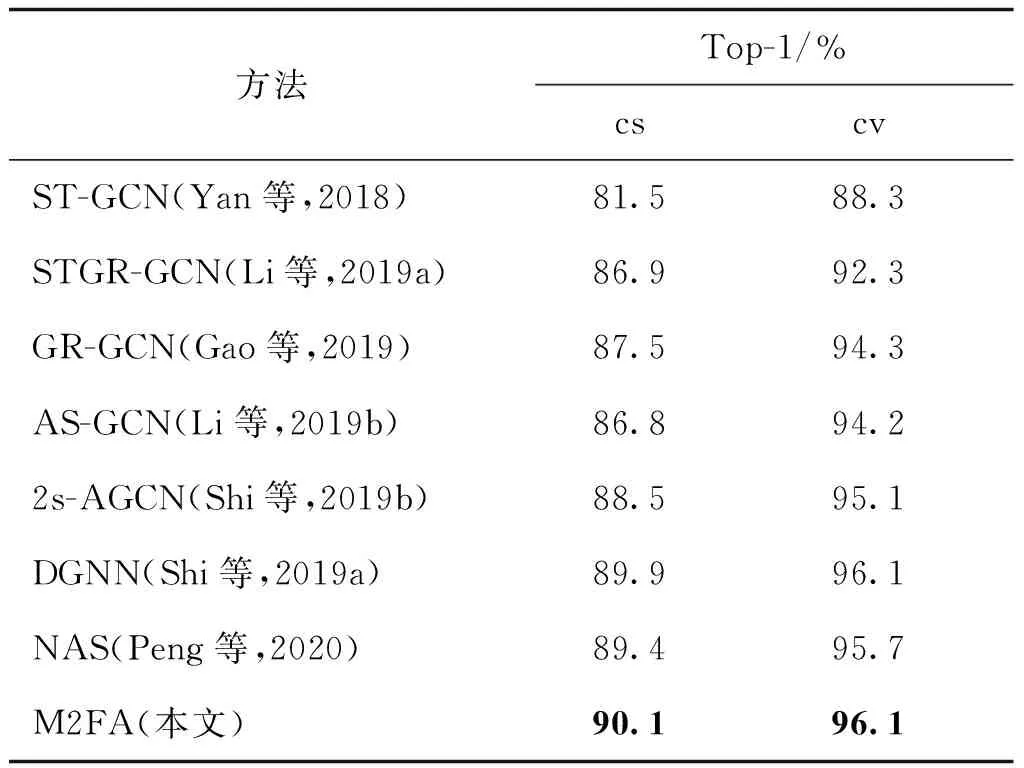
表7 在NTU-RGBD数据集对比当前方法的效果Table 7 Performance comparison on NTU-RGBD with current methods
4 结 论
本文提出一种用于骨架行为识别的多维特征嵌合注意力机制M2FA。不同于以往的注意力机制只强调单个维度的关键信息或重复叠加多种注意力模块,M2FA仅通过一个注意力模块同时捕获不同维度之间的相互依赖性,且整合了全局及局部信息以增强特征表示,在实现较大性能改进的同时保持较小的计算开销。M2FA在两个不同的大型公开数据集中成功增强了骨干图卷积框架的性能,使原始图卷积网络框架具有加强关键帧、关键节点和关键上下文依赖关系的能力,验证了其广泛有效性。
未来的研究工作将致力于将多个维度的依赖信息直接编码于注意力图中,以张量注意力机制的形式代替当前基于特征融合的注意力机制,达到更高效便捷辅助图卷积模型行为识别的目的。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
测绘学报(2022年12期)2022-02-13 09:13:01
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数字通信世界(2018年1期)2018-04-18 11:05:22
传媒评论(2017年3期)2017-06-13 09:18:10
测绘科学与工程(2017年5期)2017-05-07 06:30:44
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
