
基于大数据分析的医疗质量管控系统设计与应用
2022-08-06 00:47:00李鹏泉黄碧香陈粤宁
医学信息学杂志 2022年6期
李鹏泉 黄碧香 陈粤宁
(中国人民解放军联勤保障部队第九二三医院信息科 南宁 530021)
1 引言
近年来随着医疗信息化快速发展,医疗数据日益复杂多样,医疗服务质量要求不断提升。医院信息系统之间缺乏互联互通、数据共享,导致医院医疗质量管控效果不佳。海量医疗数据亟需大数据技术支撑,挖掘潜在价值,提升医疗管理质量。随着大数据技术引入医学领域,通过模型分析和数据分析发现医疗决策中的规律[1],为医院决策者和医务人员提供重要数据支持[2]。吕道明[3]通过Hadoop平台将医院临床数据整合实现各数据互连互通。朱甜甜[4]运用Hadoop平台与数据挖掘技术对肿瘤数据进行分析挖掘,获得肺癌与致病因素的关系。马骁[5]通过Hadoop技术在集群上分析医疗数据生命周期,有效提升存储设备的存储能力。本文从提升医院医疗质量管控角度出发,设计基于Hadoop架构的医疗管控系统。
2 需求分析
2.1 问题描述
医疗数据具有体量大、多样性等特征,其数据分析没有得到充分利用[6]。例如医院的药占比、收入情况、病种分布情况等得不到及时查询,主要原因是缺少一套能够实时查询科室、治疗过程关键数据并能进行数据分析的系统,无法迅速做出调整。只能使用结构化查询语言(Structured Query Language,SQL)查询提供简单报表,其时效性不高且数据分析质量存在不足[7]。需要构建医院大数据平台并在一定程度上实现数据整合、统计分析及报表导出功能[8]。
2.2 技术分析
Hadoop是分布式系统的一种基础架构[9],是大数据分析平台常用开源架构,其特点是对海量数据进行分布式管理与存储。Hadoop技术已成为顶级公司的分布式系统架构首选。Hadoop具有以下优点[10]:高可靠性[11]、高可扩展性、高效性;成本低,可以采用普通PC机构建集群,不需要购买小型机、刀片服务器等较昂贵的设备。系统开发使用Java语言、J2EE技术,结合SSM(Spring+SpringMVC+Mybatis)开发模式,确保良好兼容性。
2.3 建设目标
利用大数据及智能设备技术将医疗数据转换成管理人员需要的医疗指标,提供线上线下相结合的公众健康服务,为领导层、医生等提供辅助决策,满足相关人员多层次、多方位的需求。将现有和历史医疗数据盘活,开展有价值的数据分析。系统应集成数据中心,提供高并发、高并行的读写和计算能力[12]。每日产生新增数据,数据中心对历史数据进行采集[13]。充分利用医院现有数据,融合既往指标,开展医院精细化管理[14]。
3 系统总体架构
3.1 技术框架
3.1.1 数据层 主要是通过Sqoop采集相关数据,将医院信息系统(Hospital Information System,HIS)历史数据导入,采用分布式文件系统(Hadoop Distributed File System,HDFS)对HIS数据进行分布式存储[15]。HIS数据可分为两类:一类是常年积累的历史数据,一类是业务查询数据。
3.1.2 控制层 主要是利用MapReduce对离线数据进行预处理、分析、离线计算。患者医疗费用数据分析和挖掘通常在Map函数和Reduce函数中执行,最终执行结果供应用层使用。
3.1.3 应用层 对数据整理结果进行可视化呈现。要做好接口工作、前后端数据交互,使用可视化工具Echarts,系统结合SSM框架,采用模型-视图-控制器(Model View Controller,MVC)开发模式,实现数据信息的传输和查询,见图1。

图1 数据处理框架
3.2 医疗大数据处理
3.2.1 数据采集 通过Sqoop组件对HIS数据库中患者费用、医嘱等相关数据进行采集。Sqoop第1次为全量采集,之后每天01:00定时导入增量数据并将其存放在HDFS中。
3.2.2 数据预处理 通过Sqoop导入的HIS数据存在不完整、不一致情况,为提高医疗数据分析质量,保证后续处理数据格式统一,获得规则的结构化数据,必须进行数据预处理。本系统使用MapReduce对元数据进行预处理,具有以下优势:一是MapReduce应用Java语言开发,熟悉度较高;二是MapReduce的分布式计算方式并发处理效率高。
3.2.3 数据入库 将预处理好的结构化数据导入数据仓库Hive。使用MapReduce进行数据分析效率不高,且写代码工作量巨大,因此使用HiveQL对相关数据进行分析。数据入库主要步骤如下:从数据源导入数据到数据仓库的操作数据存储(Operational Data Store,ODS)层(源数据),数据经过提取、转换、加载(Extract-Transform-Load,ETL)到数据仓库(Data Warehouse,DW)层并确定分析主题,基于主题寻找相关联事实表数据,根据业务需求确定分析维度,对数据进行采集、预处理,再把数据填充到数据仓库创建好的事实表中并映射成功,展开后续分析工作。
3.2.4 数据分析 将数据映射成Hive当中的表,根据业务需求、业务指标编写相关HiveQL,分析计算出需要的指标和结果。所编写HiveQL分析语句被Hive编译成MapReduce任务提交到Hadoop的YARN上运行。数据分析是根据业务需求分析提供的指标在系统中不断更新、维护的过程,根据需求编写HiveQL。
3.2.5 数据可视化 使用图形表格的形式将分析结果和规律进行展示,也可称为数据报表。HiveQL分析结果通过Sqoop导出到HIS的Oracle数据库,数据导出到持久层,使用前端可视化工具Echarts对分析结果做报表。Echarts属于前端技术开发的基于Javascript的可视化工具。根据数据分析的需求选择创建折线图、饼状图、柱状图等多图表混合展示。
3.3 数据可视化后端Web架构
使用Maven的Tomcat插件启动项目,将导出在Oracle的数据按照需要的格式查询返回给前端。当用户使用浏览器访问页面发起请求,请求被表现层接收,再调用业务层,对具体业务进行操作,持久层对数据进行增删改查,确保业务落实在数据库中。医院的Oracle数据创建好相应数据库表,数据仓库Hive将数据分析结果通过Sqoop导入Oracle存储。DAO层即可访问Oracle中的数据分析结果,返回给业务层,业务层对相关数据进行转换调整返回给表现层,最后展示在浏览器。在表现层使用SpringMVC,业务层使用Spring及其生态圈,持久层使用Mybatis,见图2。
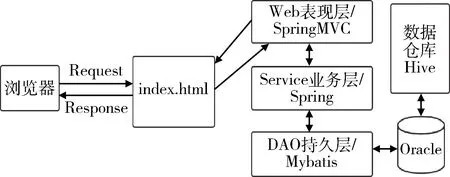
图2 后端Web架构设计
3.4 系统结构
3.4.1 整体架构 基于Hadoop的医院管控系统主要分为4个功能模块,见图3。

图3 系统结构
3.4.2 功能分析 (1)药占比分析。查看全院上周、上月、上季度、上一年的药占比趋势;查询目前全院、某个科室药品使用比例;能够按时间粒度查询;查询个人药品总费用、西药和中药占比;能够下载打印报表。(2)材料占比分析。查看全院上周、上月、上季度、上一年耗材占比趋势;查询目前全院、某个科室、个人耗材使用占比;能够按时间粒度查询,比较今年与去年的耗材占比;能够下载打印报表。(3)平均住院日分析。查看全院和各临床科室平均住院日,对科室今年趋势与去年同一时期比较,可设置目标平均住院日。(4)抗菌药物使用率分析。查看全院以及所有科室抗菌药物使用率,今年跟去年同一时期趋势比较;能够按住院号、药物名称、日期时间检索;查看在院和出院情况;查看抗菌药物使用率、医生排名和药物排名。(5)收入结构分析。查看全院和各科室总收入情况,科室今年趋势与去年同一时期比较,收入汇总包括总收入、纯收入、住院总收入、门诊总收入。(6)手术等级结构分析。查看全院和各科室手术等级结构,包括手术例数、1级手术例数、2级手术例数、3级手术例数、4级手术例数、3级以上手术率。(7)病种结构分布分析。查看单病种患者在各科室分布情况,统计全院病种总例数,统计病种名称分布。(8)出院例数分析。查看全院和各临床科室出院例数情况,科室今年趋势与去年同一时期比较。(9)手术例数分析。查看全院周次手术例数变化和上周、上月、上季度手术例数,同比和环比变化。(10)床位使用率分析。查看全院或临床科室床位使用率情况,信息包括床位使用率、床位周转数、实际床位工作日、实际平均床位工作日。
4 Hadoop集群配置
4.1 硬件环境
系统数据分析模块应用Hadoop技术,搭建环境为医院网络中心,数据源基于医院HIS平台Oracle数据库。医院中心机房已实现虚拟化管理,光纤交换机和存储等设备已相互连接,只需使用管理集群虚拟化软件Vmvare vCenter Server分配资源、创建服务器即可。
4.2 集群配置
安装3台虚拟机Linux CentOS7操作系统,主服务器1台作为Namenode主节点,两台Datanode为从节点,见表1。安装JDK8u161、Hadoop 2.7.4、Hive 2.1.1、Sqoop等关键组件,开启服务,对HIS数据库数据抽取测试。Oracle数据库与HDFS、Hive之间导入导出主要通过Sqoop组件完成。
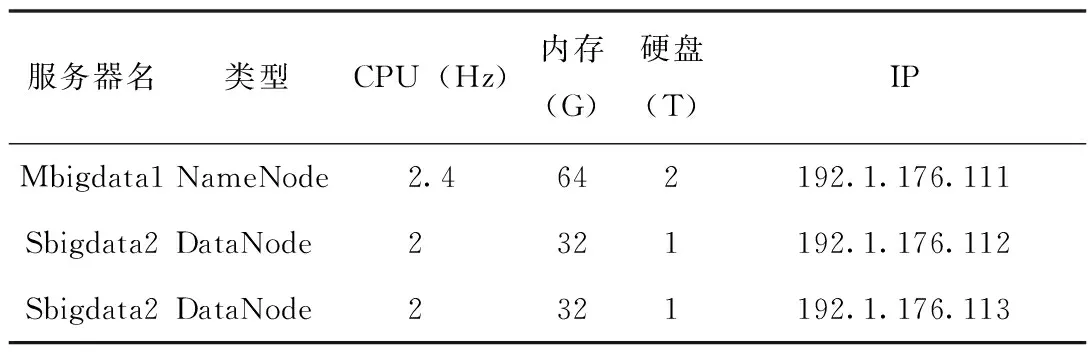
表1 集群配置信息
5 关键医疗数据分析结果展示
5.1 系统导航
在系统首页导航中可以清晰看到全院住院药占比、耗材比、抗菌药物使用率、床位使用率、当天手术例数、出院人数、平均住院日、总收入等关键数据。
5.2 药占比趋势分析
用户可以选择以周、季度、年为时间单位查看全院各临床科室药占比趋势分析。过度医疗或者高额医疗费用通常都是在用药部分占较大比例,应合理管控各住院科室药占比,避免出现天价药费情况。同时对药占比较为突出的科室进行整顿或者经济处罚,使管理层有据可依、奖罚分明。
5.3 抗菌药物使用率分析
可对比分析今年和去年抗菌药物使用率。滥用抗菌药物会引发患者产生耐药性、菌群失调、身体不良反应等危害。系统对滥用抗菌药物提供数据支撑[16],帮助医院严格管控抗菌药物使用。
5.4 病种结构分析
近年来开始实施按病种收付费用,效果并不理想,符合病种付费标准的患者费用差异较大。病种分布饼状图和条形图帮助管理者了解各病种患者数量和病种的占比率,图形显示包括疾病名称、患者例数、病种百分比。
5.5 床位使用率分析
床位使用率=实际使用床位数/实际床数。床位使用率分析界面反映的是床位使用情况和负荷情况。显示内容包括科室名称、床位使用率、床位周转次数、实际床位工作日、实际平均床位工作日。
6 创新性及特点
传统方式主要依靠统计人员经验或简单的查询系统统计临床指标,针对多个部门需要做不同报表,时效性难以保证,难以得到满意的结果。大数据医疗质量管控平台硬件投资成本较低,多层次处理和自动负载均衡,自动收集、清洗、转换所需数据保存到大数据平台数据仓库中。提供完整的数据信息链处理和深度数据挖掘,智能化信息交互和工作协同体系,操作便捷快速,可检索所需的结果、打印报表。同时大数据医疗质量管控平台能够将所有医疗指标分类排列,根据不同角色人员灵活分配所需数据指标,还能够在系统中对所选指标窗口自由布局,满足不同用户浏览习惯。医疗管控平台充分整合和挖掘医院历史数据,从多个角度对运营指标进行全方位、精细化管控,改变传统、简单的管控模式,美观、高质量的数据图表有效辅助医院管理决策,加强了医疗质量管控。
7 结语
医疗质量管控系统应用能够及时监控医院药占比、耗材占比、抗菌药物使用率等关键数据。对病种结构、平均住院日、床位使用率、出院例数、手术例数分析等能够辅助医院管理层做决策。系统能够满足医院医疗质量管理需求。随着大数据技术日益成熟,基于Hadoop架构难以充分满足数据检索查询速度需要,而基于Spark内存的批处理模式要比MapReduce更加高效,今后将引入Spark框架提升系统运行效率。
猜你喜欢
医院管理论坛(2020年11期)2020-07-10 03:36:18
杂文月刊(2019年3期)2019-02-11 10:36:13
中国卫生(2018年5期)2018-01-16 05:38:33
中国医院(2017年6期)2017-06-19 19:36:32
中国医院院长(2017年7期)2017-06-15 12:58:09
中国实用医药(2016年31期)2017-05-27 19:34:22
中国工程咨询(2017年1期)2017-01-31 02:55:42
时代青年·视点(2016年12期)2017-01-14 19:29:26
中国卫生(2015年4期)2015-11-08 11:16:14
江苏卫生事业管理(2014年2期)2014-02-28 01:59:36
