
基于植被指数的三江源高寒草地植物分类与识别方法研究
2022-08-04 01:50:32柳小妮杨冬阳乔欢欢姜佳昌潘冬荣
草地学报 2022年7期
文 铜, 柳小妮*, 纪 童, 杨冬阳, 乔欢欢, 姜佳昌, 潘冬荣
(1. 甘肃农业大学草业学院, 甘肃 兰州 730070; 2. 甘肃省草原技术推广总站, 甘肃 兰州 730000)
三江源区位于青藏高原腹地,是我国重要的天然草场,素有“中华水塔”之称,具有重要的经济价值和生态功能[1]。自三江源自然保护区的建立以来,越来越多的科研工作者对该地区进行着生态健康检测与保护工作。随着实践工作的开展以及研究问题的深入,传统的植物分类手段不能完全满足当前研究的需要[2],因此研究快速分类识别草地植物方法具有重要的意义[3]。
遥感技术的出现很大程度上弥补了传统植物多样性调查方法的不足[4]。高光谱遥感数据包含丰富的光谱信息并且能够对植被进行大面积检测,具有分析简便快速、灵敏度高、大尺度、非破坏性等优势[8-10],在植物分类方面具有很大潜力[6-7]。但高光谱数据存在冗余现象[9],因此直接利用原始高光谱全波段数据进行植物分类,难以达到理想的分类效果[11-12]。而植被指数一直是研究植物检测与分类最简单、最常用的手段[15-16],该手段一般选择对绿色健康植物强吸收的可见光波段和高反射的近红外波段,随着植物叶冠结构和生化组分等变化,这两个范围波段作为植物类型的敏感波段会对植物物理现象的光谱响应产生反差[13],因此可以增强隐含的植物光谱信息减少光谱数据的冗余[11]。
在探索遥感数据的物种识别方法中,越来越多的研究结合高光谱遥感和机器学习算法进行植物分类,有效提高了识别与分类的精度,分类精度总体较高[17]。其中Rollet等[18]基于径向基函数(Radial basis function,RBF)神经网络并结合K邻近算法(K-nearest neighbors method,KNN)的图像分类算法,对加拿大萨斯喀彻温省的4种植物光谱数据进行了分类识别,比传统图像分类方法有更高的分类精度;李婵等[19]提取了农业区域8种植物的63种光谱特征变量,利用K邻近算法、支持向量机(Support vector machines,SVM)分类模型和随机森林(Random forest,RF)分类模型3种机器学习方法进行植物的分类识别,发现SVM分类准确度要优于KNN与RF;而刘鹏[7]在城市绿化检测和大田及经济作物检测中,利用提取的特征波段,基于KNN和RF开展植物分类识别模型的研究,其研究结果表明,RF算法比KNN算法准确度高。由此说明,SVM,RF,KNN这3种分类识别模型由于对分类问题的适用性较高以及可操作性较易,被广泛应用于遥感分类中[3]。同时不同的研究对象、研究地点植物的分类识别效果不同,因此选择合适的分类模型可以提高结果的精度。
本研究利用ASD(ASD FieldSpec®4 Hi-Res NG,USA)地物光谱仪采集野外光谱数据,对三江源地区的36种常见的高寒草地植物进行光谱特征分析,并筛选利用常用的高光谱植被指数,来建立植物的SVM,RF,KNN的分类识别模型,根据分类结果挑选研究区最适分类模型,为高寒草地高光谱植物分类技术提供理论基础。
1 材料与方法
1.1 植物光谱数据采集
以三江源地区高寒草地36种常见植物(表1)为研究对象,植物名录引用自中国植物志[20]。选用ASD(ASD FieldSpec®4 Hi-Res NG,USA)地物光谱仪手枪式把手配件,于2021年8月中旬盛草期,进行高寒草地植物冠层原始光谱数据采集。
为避免光谱测量时的干扰因素,测试期间光源充足,无云、无大风条件最好。每日工作时间限制在10:00至14:00,雨天或云层较厚时不进行测试。冠层光谱测量时,保持仪器探头向下垂直视场角为25°,并保证视场角宽度为目标植物和前视场角镜头之间直径距离的一半,对每个目标植物进行10次光谱采集确保数据的充分。

表1 植物名录Table 1 Plant list
1.2 植被指数筛选
研究表明[21-23],在400~790 nm可见光波段范围,不同植被的绿度对光谱特征影响极大,在760 nm附近反射率急剧上升,形成植物特有的红边现象,光谱区别明显,因此选取480~760 nm范围内对植物自身绿度特征敏感的光谱指数GI,CI,RGI,MCARI,TCARI,CIred edge和CRI;此外,光谱测定过程中易受外界环境,如大气溶胶、土壤背景、植被冠层等因素干扰,导致结果出现误差,而EVI,RVI,VARI以及SAVI可以有效矫正大气溶胶影响,消除部分辐射误差;NDVI670,NDVI750,mNDVI705和MSR705对植被的冠层结构非常敏感,PSRI可用于植被健康的监测与检测。基于此,共选取出了16种与植物生长状态和特征的植被指数(表2),探究它们对本研究36种植物的分类潜力。
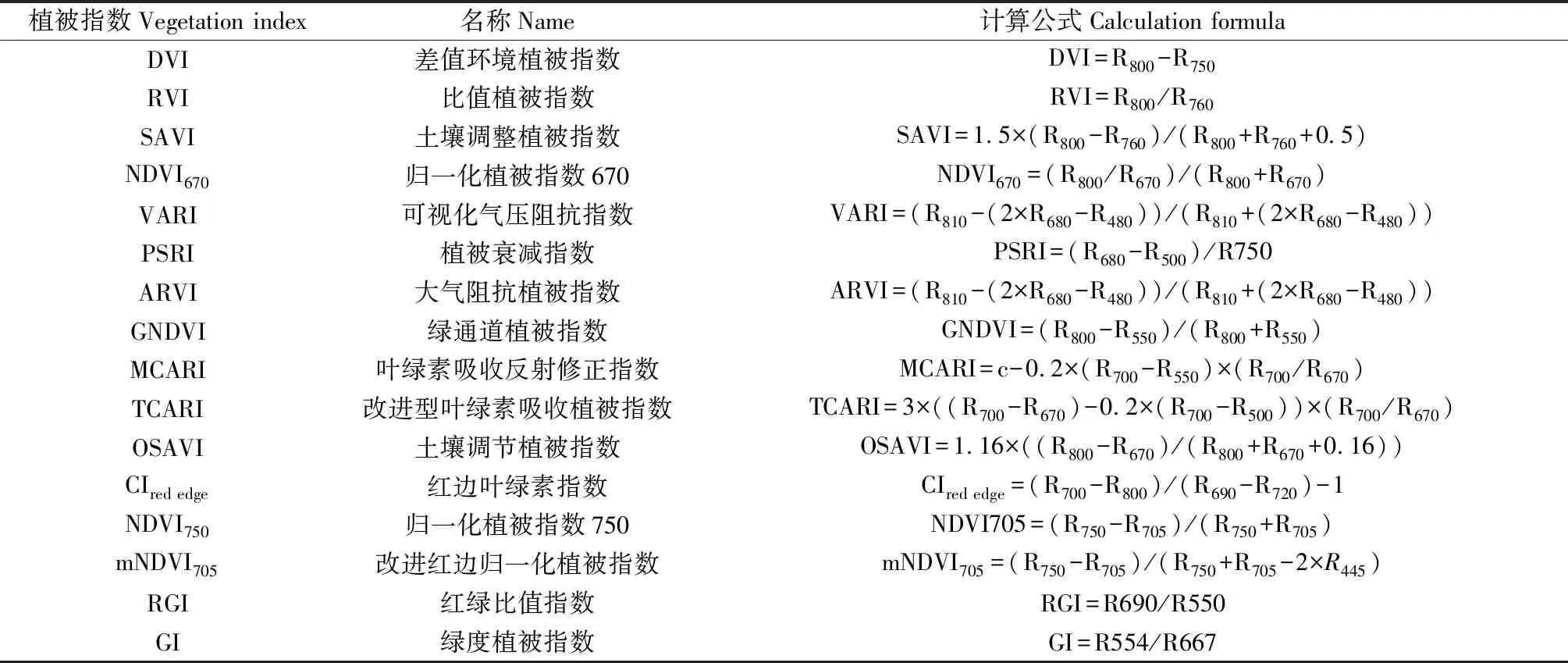
表2 植被指数Table 2 Vegetation index
1.3 植物分类模型的建立
支持向量机[24](SVM)主要是通过找到最大间隔的划分超平面,使得不同类别之间的间隔最大化,在处理小样本、非线性及高维数据等问题中具有一定的优势。其中gamma主要是对低维的样本进行高度映射,gamma值越大映射的维度越高,训练的结果越好,但是越容易引起过拟合;cost值是惩罚系数,表征的是模型对误差的容忍度,值越大表示模型对误差越宽容。
随机森林算法[25](RF)是以K个决策树为基本分类器,进行集成学习后得到的一个组合分类器。当输入待分类样本时,随机森林输出的分类结果由每个决策树的分类结果简单投票决定。其中ntree指定随机森林所包含的决策树数目,表示随机森林的总体规模;mtry指定节点中用于二叉树的变量个数,一般分类模型为数据集变量个数的二次方根。
K邻近算法[26](KNN)是通过计算训练集中的每个样本与测试集样本的距离,通过对距离的排序,取距离最近的k个点,这k个样本中具有最多的那个类别就是测试集样本的类别。KNN算法中k值的设定影响着模型的分类精确度,k值选择过大或过小,都会降低分类准确度,同时也会造成噪声增加,因此k值在选择时一般遵从低于训练样本数的平方根的原则。
1.4 数据处理与分析
运用View Spec Pro数据处理软件进行初期数据预处理及数据格式转化,再将数据导入到Microsoft Office Excel 2019 中进行保存。对不同植物的相同波段原始光谱取样计算,利用SPSS 19.0方差分析采用最小显著差数法(LSD)和显著性进行检验。
2 结果与分析
2.1 原始光谱分析
36种植物冠层反射光谱(图1)比较表明,各个植物光谱反射均符合绿色植物特征,但不同植物相同波段间存在差异。在可见光波段350至550 nm范围内,植物均出现了第一个明显吸收峰,光谱反射率最小的是鹅观草,最大是火绒草。蓝紫光350至450 nm波段,相比其他绿色植物,川青黄芪、密花翠雀与甘肃马先蒿出现了小的反射峰,其中川青黄芪反射率最大且在440 nm处达到最高值;绿色波段450至560 nm范围,除川青黄芪差异性较大(P<0.05)且在560 nm出现“绿谷”现象,其余植物均出现不同程度的“绿峰”现象,此时火绒草反射率最大,高山韭反射率最小。
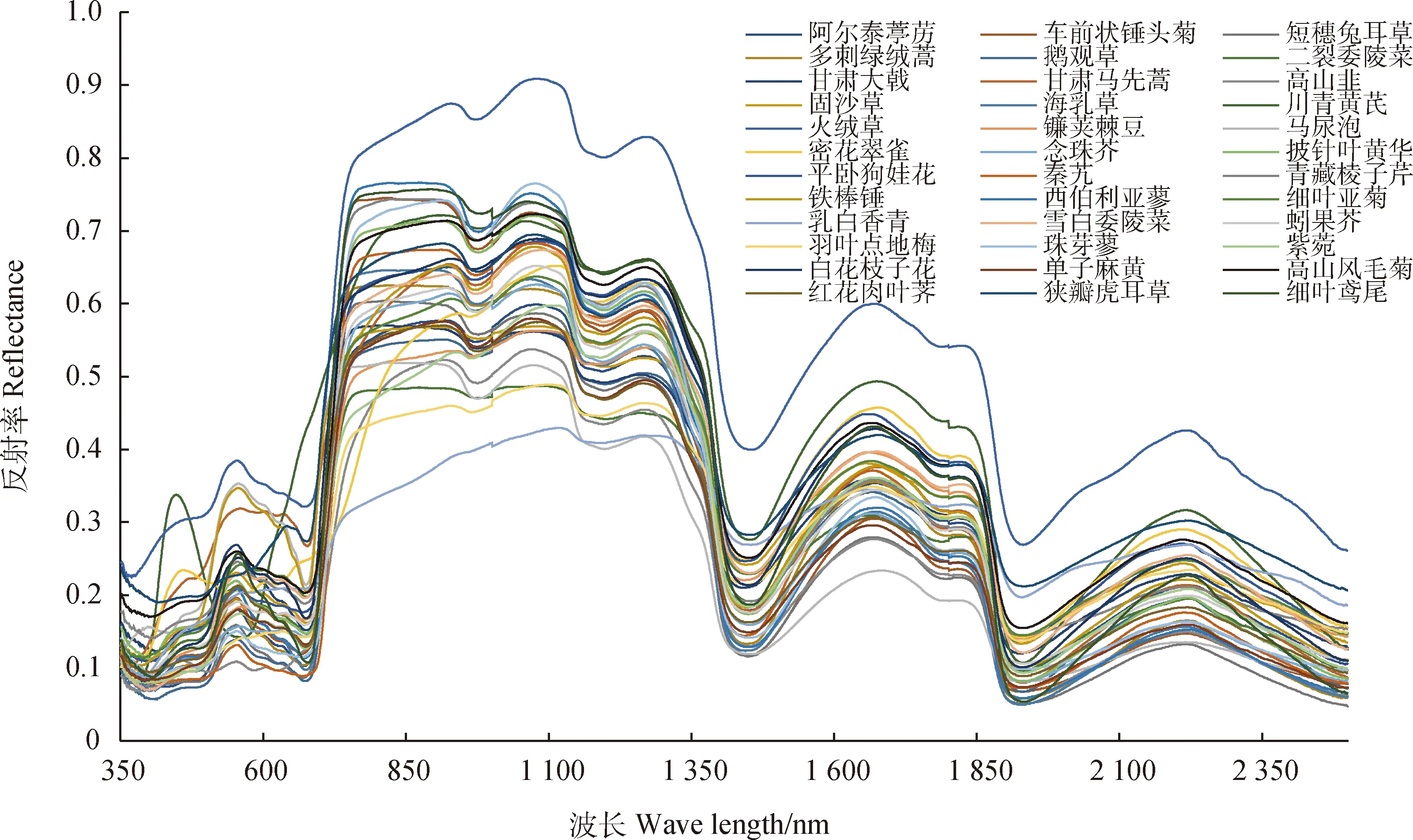
图1 不同植物的原始光谱反射率Fig.1 Original spectral reflectance of different plants
在680 nm附近,反射率迅速上升,形成了植物特有的“红边”现象,除乳白香青、火绒草和密花翠雀红边斜率较低外,其余植物均无明显差异,但甘肃马先蒿在红光波段末端出现了小的吸收峰。
在760 nm至1 100 nm近红外波段,36种高寒草地植物的反射率在1 070 nm处达到最大值,且该波段内不同植物有差异,其中反射率最大为火绒草,最小为短穗兔耳草。在1 450 nm水分敏感波段,火绒草的反射率最大为0.399 8,短穗兔耳草的反射率最小为0.116 0。
2.2 不同植物的分类识别模型
2.2.1支持向量机SVM 表3为SVM的gamma与cost不同参数设置错误率。
根据表3可以看出,当gamma取1e-01、cost取10时误差最小,因此作为SVM分类的模型参数。此时,SVM的准确度为0.93,kappa系数为0.93(表4),从而说明SVM模型较好,能够较好的区分36种植物。
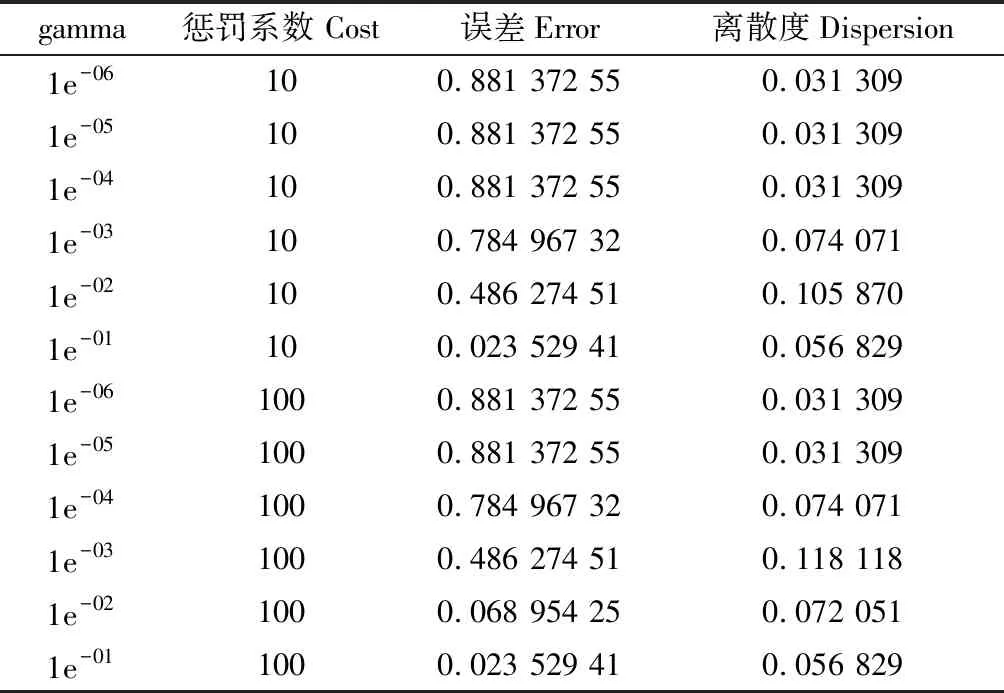
表3 “Gamma”与“cost”设置Table 3 “Gamma” and “cost” parameter settings

表4 SVM分类模型参数表Table 4 SVM classification model parameter table
由SVM模型混淆矩阵气泡图(图2)可知,SVM分类方法识别36种植物时,在SVM预测集混淆矩阵中,除无法区分雪白委陵菜与羽叶点地梅(误差率为100%)外,其余植物均被很好的区分,未出现误差。
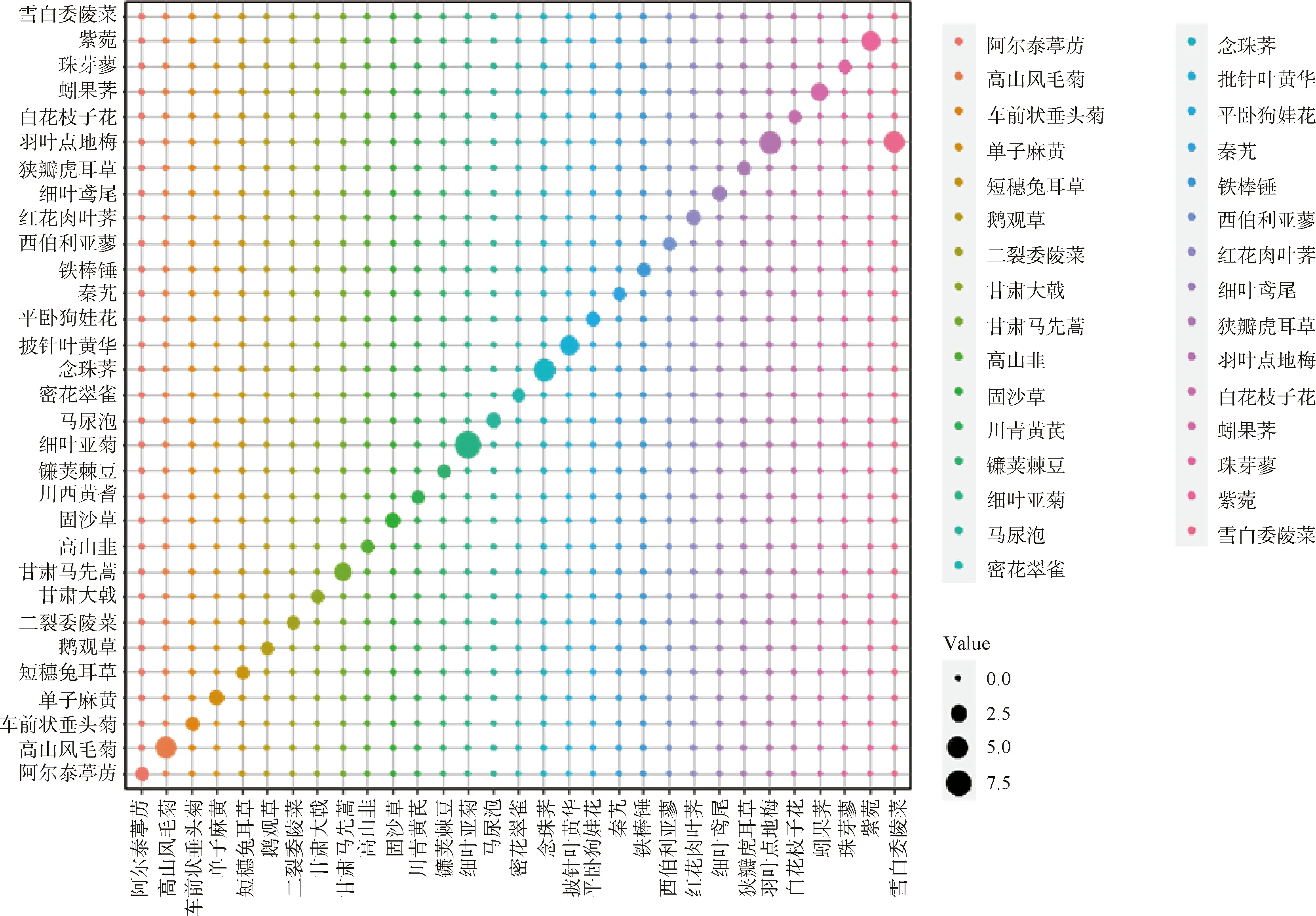
图2 SVM模型混淆矩阵气泡图Fig.2 SVM model obfuscation matrix diagram注:图中对角线以外的气泡代表误判,气泡大小代表判断数量,样本数量越大气泡越大Note:In the figure,Bubbles outside the diagonal line represent misjudgments,and bubble size represents the number of judgments. The larger the sample size,the larger the bubbles
2.2.2随机森林算法RF 由RF不同决策树数量植物分类误差图(图3)可知当ntree=50 时模型内草种误差基本稳定,即ntree取值50。

图3 随机森林n_tree误差图Fig.3 Random forest n_tree error graph注:图形横坐标为决策树选择数量,纵坐标为不同植物分类的误差值Note:The abscissa of the graph is the selection number of the decision tree,and the ordinate is the error value of the classification of different grass species
图4表明,RF分类模型准确度为99.4%,袋外误差为2.86%,说明用RF模型来识别这36种植物效果较好。在预测集中单子麻黄、短穗兔耳草误差较大(误差率均为20%),高山风毛菊较小(误差率为5%),其余33植物误差率均为0。
由图5A可知,RGI为RF识别模型平均下降准确度(Mean decrease accuracy)最大变量,由图5B可知SAVI为平均下降基尼系数(Mean decrease gini)中数值最小的变量。
2.3 K最邻近算法kNN
由表5可知,当K=2时KNN模型准确度达到高值(88.0%),kappa系数为0.87。且可知此时是设置K值中的拐点,随着K值的增加模型准确度不再上升,因此设K=2作为KNN分类模型的参数。
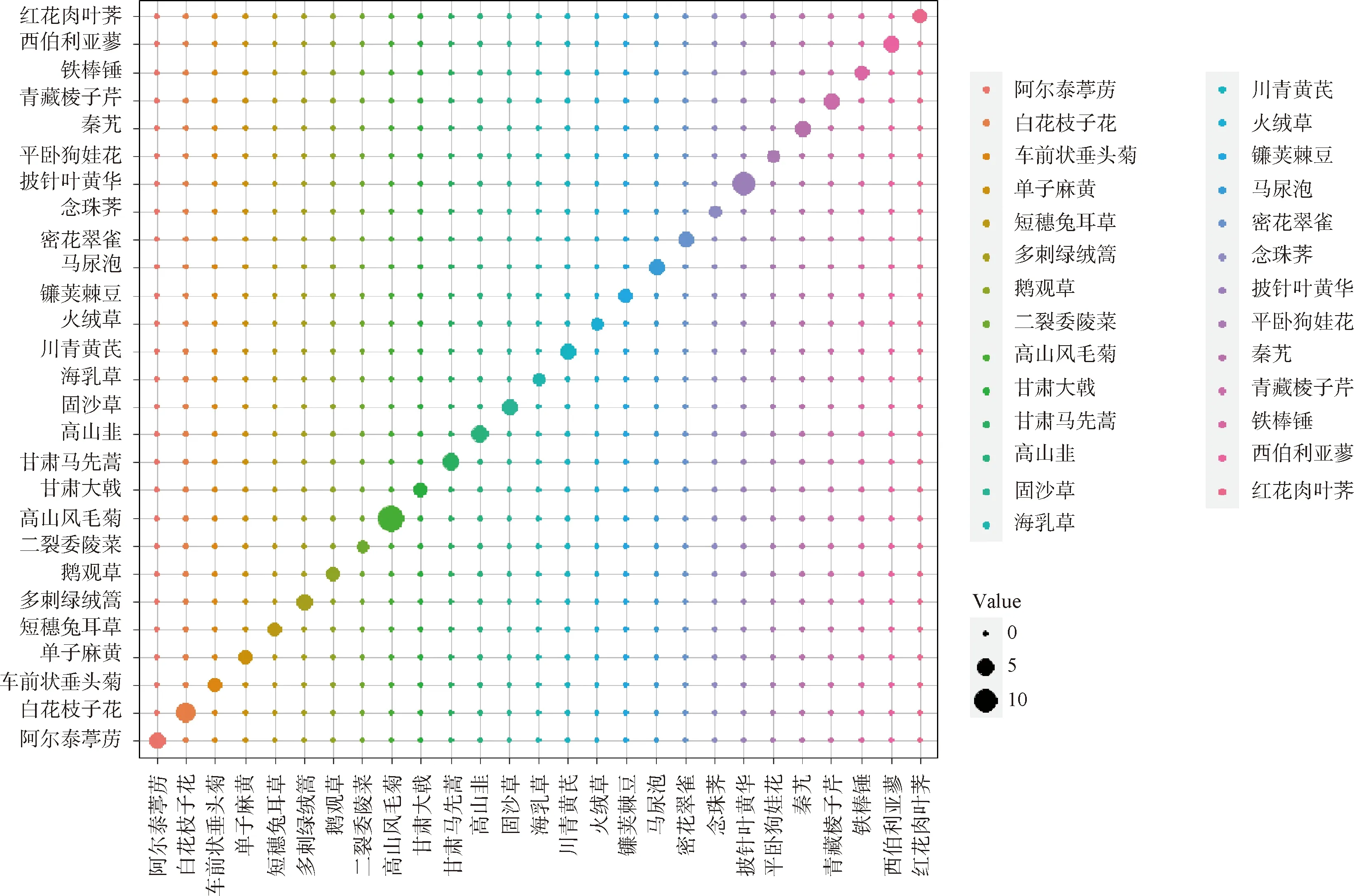
图4 随机森林模型混淆矩阵图Fig.4 Random forest model obfuscation matrix diagram

图5 随机森林分类模型变量重要性图Fig.5 Random forest classification model variable importance map注:A为精确度系数图,图中变量值越大说明变量的重要性越强,B为基尼系数图,图中系数越低,分类切割越好Note:A is the accuracy coefficient map, the larger the value of the variable in the figure,the stronger the importance of the variable. B is the Gini coefficient map. The higher the coefficient in the figure,the better the classification and cutting

表5 K值设置Table 5 K parameter settings
图6可知KNN分类结果中,披针叶黄华误判为高山风毛菊(40%)、多刺绿绒蒿误判为阿尔泰葶苈(66.7%)、火绒草误判为高山风毛菊(100%),其余植物分类未出现误差。
3 讨论与结论
本研究表明,36种植物的原始光谱均符合绿色植物特征,但不同植物在相同波段间具有差异性。如在蓝紫波段,由于密花翠雀、川青黄芪与甘肃马先蒿在光谱采集时均已开花,花色分别为淡紫色、淡灰蓝色和紫红色,因此它们的蓝紫光反射率较高;在绿光波段,火绒草与乳白香青出现反射峰主要原因是叶片上的白色绒毛产生了漫反射;在红光波段的末端,只有花呈暗紫红色的甘肃马先蒿反射率出现小幅降低。由此可见,植物的形态特征不同,光谱差异主要集中在可见光波段。
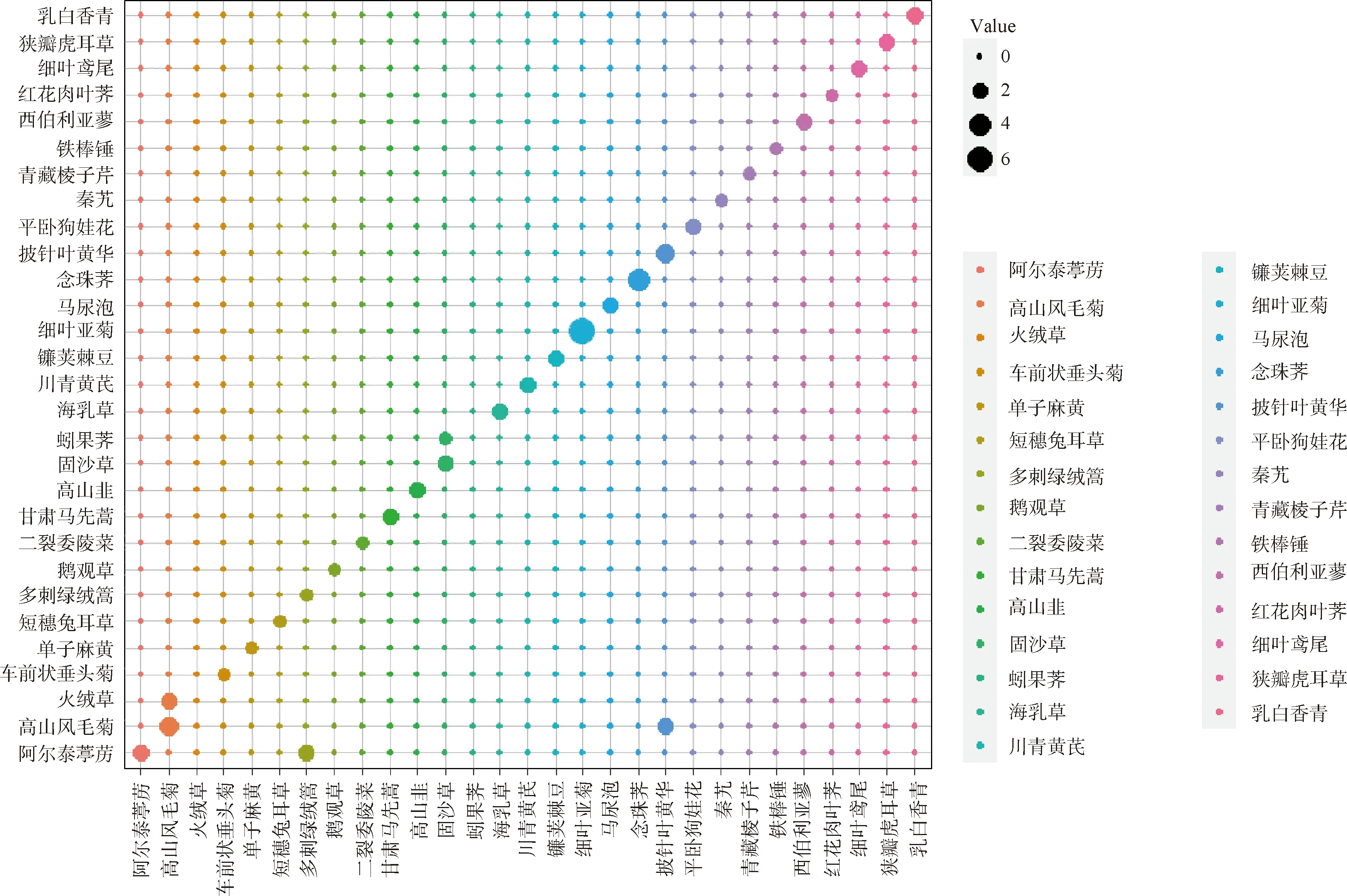
图6 KNN混淆矩阵气泡图Fig.6 K-nearest neighbor model obfuscation matrix diagram
分类模型结果表明,虽然3种模型分类精度较高,依次为RF(99.4%)>SVM(93.2%)>KNN(88.0%),模型的精确度都大于85%,均可适用于该研究区域[3],但都出现了特殊的误判情况。如雪白委陵菜与羽叶点地梅由于叶片形状相似且叶柄均有白色绒毛,16种植被指数数值相近,导致SVM模型无法区别;而单子麻黄与短穗兔耳草的植被指数除NDVI670外均相同,RF对该2种植物的识别效果较差。由此可知,SVM与RF分类模型算法对特征相似度较高的植物分类效果较差。另外,KNN误判火绒草为高山风毛菊,这就暴露了KNN本身的算法缺点,即样本数量不平衡时,会将样本数较少的植物(火绒草样本数仅为5)优先识别为样本数较多的植物(高山风毛菊样本数为15)。因此,在利用KNN模型时可控制样本数量的平衡避免该问题的出现。
虽然模型的精度并不能简单的说明分类算法本身的优劣[25],但对三江源区高寒草地植物而言,RF不仅模型精度高,且额外具有能对所构建模型参数进行重要性分析的功能。RF参数评估结果表明,RGI红绿比值指数与SAVI土壤调节指数是提高RF分类识别模型精度的重要参数。这是由于植物的不同花色和叶片被白色绒毛等独特的现象导致不同植物在相同波段间的原始光谱有差异,从而也导致植物间的RGI红绿比值指数产生显著差异(P<0.05),如乳白香青、火绒草(叶片被白色绒毛)和密花翠雀(花色独特);另外,因密花翠雀、乳白香青和火绒草分别为极度退化、重度退化和轻度退化的优势种[28],而草地退化后植被盖度减少,土壤裸斑面积增加[29],能反映土壤背景的SAVI土壤调节指数对此较为敏感。
综上所述,RF相较于SVM和KNN,无论是模型的适用性还是功能性,均为本研究中的最佳植物分类识别模型。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
印制电路信息(2022年11期)2022-11-30 03:40:58
海洋通报(2022年4期)2022-10-10 07:40:26
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
电子器件(2017年2期)2017-04-25 08:58:37
高师理科学刊(2016年8期)2016-06-15 20:27:45
西藏科技(2015年4期)2015-09-26 12:12:58
西藏科技(2015年1期)2015-09-26 12:09:29
