
基于计算似然比的分布外网络流量数据检测方法
2022-08-02 08:27卓子寒吕欣润刘立坤车佳臻余翔湛张晓慧
无线电工程 2022年8期
卓子寒,吕欣润*,刘立坤,车佳臻,余翔湛,叶 麟,张晓慧
(1.国家计算机网络应急技术处理协调中心,北京 100029;2.哈尔滨工业大学 计算学部 网络空间安全学院,黑龙江 哈尔滨 150001)
0 引言
随着人工智能以及互联网的不断普及和广泛应用,各种网络协议以及网络流量数据应运而生。互联网使信息的流通更加便捷,不断改变着人们的交流方式,但同时还带来了许多问题,例如数据安全问题和隐私保护问题等。随着人们对隐私保护意识的增强,使得网络流量识别以及检测成为了一个极其重要的研究领域。
网络流量识别以及检测的安全问题,主要集中在识别流量类型。流量类型识别是指利用某种算法构造分类模型,并利用该模型对网络流量进行分类识别,其中分类的依据包括应用程序、业务类型和应用层协议等[1]。在过去的研究中,早期网络流量分类主要依据传输层协议类型,即根据UDP或TCP端口号进行分类。该方法虽然易于实现,但是在网络协议多元化、端口伪装技术盛行的今天,基于端口号的识别方法准确率越来越低,并逐渐成为了网络流量分类的辅助方法。由于网络报文协议以及载荷越来越复杂,研究人员发现在这些数据包中的协议头以及载荷部分包含了许多特殊的信息或信息组合,因此出现了深度报文检测(Deep Packet Inspection,DPI)技术。DPI技术主要通过分析TCP流中数据包的头部和载荷部分数据,若与已知程序或协议类型的数据包在某些特征上相似,则可认为该TCP流属于同一个应用程序或协议。Lu等[2]提出并设计了一个基于DPI技术的网络数据分类系统,并结合使用可编程门列阵和三元内容可寻址存储器体系结构,该系统可基本满足分类需求。为了解决数据隐私问题,Li等[3]提出了一种可进行隐私保护的动态深度包检测技术,以解决在对网络流量进行处理的情况下造成的数据隐私泄露问题。付文亮等[4]提出了一个基于FPGA的高性能网络流量法分类框架,使用轻量级DPI方法快速检测流量特征,该框架能够准确识别多种流量且准确率可达97%。由于DPI技术不再以端口号为分类根据,因此不受端口伪装技术的影响。
在近些年的研究中,随着计算机技术的不断发展,网络协议和网络数据包容量和复杂度增加,DPI技术需要检测每一个数据包的包头和载荷,导致其耗费巨大的资源,因此传统的DPI技术渐渐失去了优势。如今,人工智能崛起,通过机器学习或深度学习算法利用网络流量特征训练分类模型成为了主流方法。基于深度学习的识别方法有效地提高了流量类型识别的精度,并在实际应用中也取得了良好的效果。Bernaille等[5]通过分析TCP流的前5个数据包的特征信息,并使用多种机器学习算法,例如决策树、朴素贝叶斯和支持向量机等,对不同TCP流进行分类。鲁刚等[6]提出了基于聚类的流量分类框架TCFEC,该框架由多个不同特征子空间聚类的基分类器和一个最优决策部件构成。但随着应用范围的不断扩大,基于深度学习的分类方法也出现了一些问题。
由于私有网络协议的大量出现,这些私有网络协议在形式和内容上与已有网络协议极为相似,因此在网络流量数据中产生了一个新的异常类型,即分布外数据。分布外数据是指假设存在一个数据集D,数据集D由(X,Y)构成,其中X表示提取的特征集合,Y表示数据的标签集合,若存在样例d(x,y),其中y不属于Y,那么称样例d为数据集D中的分布外数据。分布外数据通常有2个特点:① 与某一已知类型非常相似;② 在现有知识范围内识别不出此类型数据。根据研究显示,深度学习模型的分类结果的可信度并不能得到保证。Nalisnick等[7]的研究结果表明,在CIFAR-10图像数据集上训练出的Glow模型,使用SVHN和CIFAR-10的混合数据集作为测试数据,结果显示,使用深度学习模型会将SVHN中的数据以高置信度分类为CIFAR-10中的数据。因此,在一些数据类型相似的情景下,深度学习模型的分类结果并不可信,而分类错误将会在网络安全问题上带来严重的后果。因此,识别出分布外数据以提高分类结果的可信度对于网络安全问题极其重要。
Lee等[8]提出了一种基于计算马氏距离的分布外数据检测方法,该方法适用于任何预训练的softmax神经网络分类器,在高斯判别分析下,通过获得深度模型特征的类条件高斯分布,从而得出基于马氏距离的置信度得分。Jiang等[9]将分类器得到的置信分数替换成衡量分类器与最近邻分类器置信分数之间的距离得分,定义为信任分数。实验表明,信任分数优于原分类器产生的置信得分或其他基线标准。Liu等[10]提出了一种类别检测算法,检测训练数据集中的分布外数据实例,该算法在已知分布外数据大概占比α的前提下在合成以及标准基线数据集上证明了该算法的有效性。Yu等[11]提出了一个双头CNN网络检测分布外数据,通过训练一个由常见的特征提取器和2个分类器组成的双头CNN,它们具有不同的决策边界,并最大化2个分类器之间的差异检测分布外实例。
根据以上的研究内容分析,对于测试数据集中可能存在分布外数据并导致基于机器学习或深度学习模型分类结果的不可信,因此本文提出了一种基于计算似然比的检测方法。该方法通过训练2个模型,分别使用分布内数据训练原始模型,通过构造扰动数据模拟分布外数据训练扰动模型,最后通过计算2个模型得到结果的似然比判断分布外数据,以保证最后分类结果的可信度,有效防止网络安全事故的发生。
1 网络流量数据采集及预处理
1.1 网络流量数据采集
本文使用的网络流量数据主要分为2个部分:① 公开数据集Moore数据集,是由Moore等在剑桥大学实验室收集,该数据集分为10个部分,包含了多种类型例如邮件流量、恶意流量和数据库流量等,其标签集合为:List_label=[‘www’,‘MAIL’,‘FTP-CONTROL’,‘FTP-PASV’,‘P2P’,‘ATTACK’,‘DATABASE’,‘FTP-DATA’,‘MULTIMEDIA’,‘SERVICES’,‘INTERACTIVE’,‘GAMES’];② 通过使用Selenium,VM,Wireshark和Tcpdump等工具收集的网络流量。
Selenium是一个用于Web应用程序测试的工具,可执行自动化浏览过程,模拟网络环境下的真实用户行为,并允许模拟终端用户执行常见活动,例如输入文字、鼠标移动和任意JavaScript执行等。流量收集过程在本机和一个虚拟机(VM)上进行。VM是一种使用软件而非物理设备来运行程序的计算资源。每个VM都有自己的操作系统,并与其他VM分开运行。本机安装Windows10操作系统,VM安装Ubuntu系统。VM被配置以NAT形式运行,确保网络流量始终通过该机器路由,因此该收集系统可完全捕获所有流量,且基于特定参数控制过滤器不会造成任何流量中断。异常的流量中断可能会影响数据集的质量,甚至导致生成无效的训练数据集。
Windows10系统运行Wireshark,VM运行Tcpdump。Wireshark和Tcpdump是如今较为流行的2款网络嗅探器。Wireshark作为一款网络封包分析软件,具有截取原始网络数据包并显示网络数据包资料信息的功能,使用WinPCAP作为接口直接与网卡进行数据报文的交换。Tcpdump同样作为一款数据包分析工具,支持针对网络层、网络协议、主机、网络或端口作为过滤信息,且更加简单灵活,可以在大部分Linux和Unix变体上运行。捕获的网络流量全部为原始流量数据,捕获后以pcap文件形式保存在本地。
Joy工具是Cisco开源的一款加密流量分析系统,用于从实时的网络流量或pcap文件中提取数据特征,其中数据特征包括数据包长度、时间序列、字节分布以及原始数据包特征。Joy工具从实时网络流量或pcap文件中提取特征后,会以JSON格式进行输出。为便于后续处理以及使用,需要将JSON格式数据转换为CSV格式数据,以便指定label数据作为数据的标签信息。
收集过程通过使用Selenium模拟用户行为产生实时流量,并使用Wireshark和Tcpdump嗅探工具进行原始网络流量的采集并保存在本地。
1.2 网络流量预处理
采集的网络流量数据为pcap文件,为了执行后续操作识别,需要从网络转储文件中提取出代表每种流量类型的特征组合。这些特征分为2个大类:静态特征和动态特征。静态特征包含数据包长度、达到时间间隔以及初始数据包特征等;动态特征包括字节分布特征,字节分布是指一个特定字节出现在流中数据包的有效负载中的概率。本节预处理网络流量主要利用静态特征中的原始时间和空间相关特征表征流量。静态特征的提取过程主要分为3个步骤,处理流程如图1所示。

图1 静态特征提取流程Fig.1 Flow chart of static feature extraction
① 原始网络流量数据为pcap数据包文件形式,其中包含了应用层、传输层和网络层等多个层的数据。首先需要根据五元组信息将原始流量初步划分为不同的流,其中五元组信息包含源/目的IP地址、源/目的端口号和传输层协议。同时,将每一条流的信息作为一条记录保存,以便于后续的处理。
② 通过遍历每一条原始流记录,根据实验设置提取数据包的长度序列,用于计算每个包到达时间间隔序列。对于原始包长度和时间间隔,需要设置合适的参数将数值划分为不同的区间,最后将表征流量的新特征序列保存。保存新特征序列的方式有2种:根据不同序列长度分别保存数据和保存完整序列。后续可以根据不同的序列长度进行数据读取。
③ 特征提取结束后,使用Joy开源工具进行特征的存储。CSV文件是电子表格和数据库最常见的数据导入和导出格式,便于后续模型的训练和数据的输入,对其进行指定label属性作为标签存储到CSV格式文件中,作为学习模型的输入训练数据。
视频流量预处理算法过程如算法1所示。

算法1:网络流量预处2算法输入:原始网络流量pcap文件输出:表征流量特征集合#根据五元组划分不同网络流Diff_stream = 原始网络流量.groupby(源/目的IP地址,源/目的端口号,传输层协议)While(Diff_stream != null)do get(Diff_stream.time series) 计算时间间隔序列 保存序列特征使用Joy工具保存提取特征文件并转换为CSV文件return流量特征集合
2 构造扰动数据以及模型的训练
2.1 构造扰动数据
分布外(Out-of-Distribution,OOD)数据,对于深度学习模型训练使用的训练数据,包含的数据类型全部为已知类型,即全部数据都存在已知标签进行分类。模型投入使用后,测试数据中并不能保证全部数据均为有标签的已知类别,这些类别数据被称为OOD数据类型。深度学习模型之所以会将这些未知数据错误分类为已知类别,是因为某些OOD数据与某一已知类别在特征上特别相似。根据这一特性,本文将通过对已知类别数据加入噪声的方式模拟OOD数据进而训练扰动辅助模型提高分类结果的置信度。
本文使用高斯白噪声作为构造扰动数据的方式。高斯白噪声是一种概率分布为正态函数,一阶矩为常数,幅度分布服从高斯分布的噪声函数。高斯白噪声可以通过改变参数从而小幅度地改变数据均值以及结构,是生成某些对抗样本、添加噪声的最优方法之一。高斯白噪声有2个参数:均值μ和噪声比θ。本文中,根据网络流量的特征性质将2个参数分别设置均值为0,噪声比为0.02。一些点数据在加入了参数分别为0和0.02的高斯白噪声的效果如图2所示。

(a) 原始二维点数据
2.2 原始模型训练
原始分类模型指的是使用已知类别网络流量数据作为训练数据训练出的模型。由于对网络流量数据进行预处理后,表征流量的特征数据形式为序列数据,且为多类别分类,因此原始模型训练将采用决策树、随机森林和LSTM等3种机器学习和深度学习算法,文献[12-17]分别介绍了3种算法的具体实现。
决策树是基于树结构进行决策,每个内部节点表示一个属性判断,每一个分支代表一个判断结果的输出,最后每个叶节点代表一个分类结果。从根节点到每个叶节点的路径对应了一个判定序列。决策树算法的目的在于产生一颗泛化能力强的决策树,拥有处理未知实例的能力。
随机森林是从决策树演变而来的一种机器学习算法,将许多决策树结合起来以提高分类的准确率。随机森林为集成学习算法之一,该集成学习方法基于以下思想:通过组合多个较弱的学习器,从而创建一个较强的学习器。该机器学习算法训练过程速度较快、实现简单、对于高维数据不需要降维操作,适用于执行分类任务。
以上2个算法均为机器学习算法。深度学习是机器学习领域的一个新的研究方向,是一个更加复杂的机器学习算法,在序列、语音和图像等数据识别分类方面取得的效果远远超过先前相关技术。因此本文将采用深度学习算法长短期记忆(LSTM)训练分类模型。LSTM网络是一种时间递归神经网络,适合处理和预测时间序列中间隔和延迟相对较长的数据。在LSTM网络中,主要通过引入自循环和3个门控制信息的传递,分别为遗忘门、输入门和输出门。LSTM的网络结构较为复杂,门的状态通常有3种:全开(信息通过概率为1)、全闭(信息通过概率为0)以及半开(信息通过概率0~1)。对于这3种门信息通过均用概率形式表示。一个信息进入LSTM网络当中,需要根据规则来判断是否有用,只有符合算法认证的信息才能保存,不符的信息则会通过遗忘门被遗忘。LSTM神经元在时间维度上向后传递了2种信息:单元格状态(cell state)和隐藏状态(hidden state)。隐藏状态是单元格状态经过一个神经元和一个输出门之后得到的,即隐藏状态包含的记忆实际上是单元格状态衰减后的。因此,单元格状态存储的是长期记忆,隐藏状态存储的是短期记忆。
在训练过程中,ct-1表示t-1时刻的cell state,ht-1表示t-1时刻的hidden state,xt表示t时刻的输入,ft表示遗忘门,it表示输入门,ot表示输出门,根据数据的流向可以得到一个简单的计算流程:
① 利用t-1时刻的hidden state计算遗忘门ft的结果,ft=σ(Wfxt+Ufht-1+bf);
② 利用t-1时刻的hidden state计算输入门it的结果,it=σ(Wixt+Uiht-1+bi);
③ 利用t-1时刻的hidden state计算候选值c′t的结果,c′t=σ(Wcxt+Ucht-1+bc);
④ 利用t-1时刻的hidden state计算输出门ot的结果,ot=σ(Woxt+Uoht-1+bo);
⑤ 根据t时刻的cell state和t-1时刻的cell state、遗忘门、输入门和候选值计算ct,ct=ft×ct-1+it×c′t。
W和U是模型中线性关系的参数矩阵,在整个LSTM网络中是共享的;b为偏差;σ为激活函数,这里的激活函数使用sigmoid函数。
与前馈神经网络相似,LSTM网络的训练同样采用误差的反向传播算法。因为LSTM网络一般适用于处理序列数据,而经过预处理的流量数据形式为序列数据,因此本文采用LSTM算法为主要模型训练算法。
2.3 扰动模型训练
对于网络流量数据,数据特征元素可以总结为2大类别:① 以背景统计数据作为特征提取主要来源,记作XB;② 以分布内数据的某些特殊模式或语义作为特征提取主要来源,记作XP。每种数据结构都同时存在这2大特征构成,但所占比重不同,起到决定性作用的来源也不同。例如,对于图片数据,在选取图片数据特征时几乎都采用背景统计数据(background),因此在训练模型时往往需要庞大合理的数据集;对于文本数据,其特征提取大部分取自文本中特殊的模式语义(pattern)。而对于流量数据,往往需要对流量数据进行预处理,预处理后的数据大部分转换成为了向量的形式(也有转换成为图片格式,本文所做预处理将流量数据转换成为向量形式)。向其加入高斯白噪声仅仅改变了其特殊模式或语义特征,并未改变其背景统计数据特征,因此训练扰动模型的目的在于放大数据特殊语义特征所占分类依据比例,从而得到更高的分类结果可信度。
扰动模型的训练过程以及使用算法及参数与原模型训练过程中完全一致,唯一区别在于使用的训练数据不同。扰动模型训练采用的训练数据为加入高斯白噪声后的扰动数据。
3 似然比计算以及分布外数据识别算法
3.1 似然比计算
似然比[18](Likelihood,LR)是反映真实性的一种指标,也可反映二者之间的关联程度。LR指标反映出的关联价值,相对独立且非常稳定,其计算仅仅涉及灵敏度和特异度,并不受到假阳性率的影响。因此LR可以作为判定OOD数据的有效指标。
对于网络流量数据,可以假设数据转换成为了一个d-维向量x=x1,x2,…,xd,其中每一维的数据都来自于背景统计数据特征或语义特征,且这些特征相互独立,那么样本x的概率P(x)定义为:
P(x) =P(xB) ×P(xP)。
在训练生成模型时,根据流量数据的向量特征表示,很难区分数据背景特征和语义特征。由于加入高斯白噪声后破坏了原有的语义特征而并未改变数据背景统计特征,因此假设2个模型所使用的的训练数据语义特征不同但背景统计特征大致相同,则会有以下定义和推导:
假设使用原训练数据训练出的模型为A(·)(使用的原训练不包含异常样例),使用扰动数据训练出的模型为B(·),则样本x的似然比LR(x)定义为:
上述公式中,由于实验中并未改变数据的背景统计特征,因此可以得到A(xB)≈B(xB),且模型A使用原数据训练得到,因此得到的分类分数一定略高于使用加入扰动的数据训练得到的模型B给出的分类分数,因此得到的LR将会是一个正数,便于之后的计算和比较判断。通过以上说明,可以将上述公式改写为:
式中,lbA(x)表示样例x与分布内数据的关联性;lbB(x)表示样例x与分布外数据,即分布外数据的关联程度。若样例x为分布内数据,则与分布内数据关联性较强,lbA(x)则偏大,反之亦然,lbB(x)就会偏小,则计算出的二者差值LR(x)就会偏大;以此类推可以得到,若x为分布外数据,则计算出的LR(x)就会偏小。因此,根据差值并设置合理的阈值,就可以识别出分布外数据。
3.2 算法描述
本文提出的OOD数据识别算法有以下几个步骤:
① 提取流量指纹特征。利用流量指纹特征中的原始时间、空间相关特征表征流量。首先根据五元组信息划分不同流,其次设置提取数据包长度序列以及计算包到达时间间隔序列,并将表征流量的新特征序列保存起来,最后生成CSV文件作为模型训练的输入数据。
② 使用预处理的原始数据训练原始分类模型A。使用算法为决策树、随机森林和LSTM网络。
③ 生成扰动数据。扰动数据用于模拟OOD数据,通过利用加入高斯白噪声的方法构造扰动数据。
④ 使用扰动数据训练扰动模型B。扰动模型训练采用步骤③生成的扰动数据作为训练数据,且训练过程、采用算法以及参数与步骤②训练原始分类模型一致。
⑤ 计算2个模型得到结果的LR,判断OOD数据。
OOD数据识别流程如图3所示。

图3 OOD数据识别流程Fig.3 OOD data identification flow chart
OOD数据识别算法描述如算法2所示。

算法2:OOD识别算法输入:原始网络流量输出:OOD数据(1)数据预处理使用算法1得到表征流量特征集合(2)OOD识别① 使用训练数据训练原始模型A② 对训练数据加入噪声构造扰动数据③ 使用扰动数据训练扰动模型B④ fori in test_data:a = A(i)b = B(i)LR(i) =lb A(i) -lb B(i)ifLR(i) < threshold > is OOD⑤ end
4 实验与分析
为了验证该OOD识别方法的可行性,本文设计以下实验并进行结果分析。将采用Moore数据集以及自行采集的流量数据作为实验数据,其中Moore数据集中数据作为分布内数据训练原始模型,将自行收集的数据以及加入噪声后的Moore数据集作为分布外数据,并作为测试数据测试模型性能,验证OOD数据的识别准确率。
4.1 数据集
本文通过网络嗅探工具采集不同类别网络流量,具体类别以及数据包信息如表1所示。
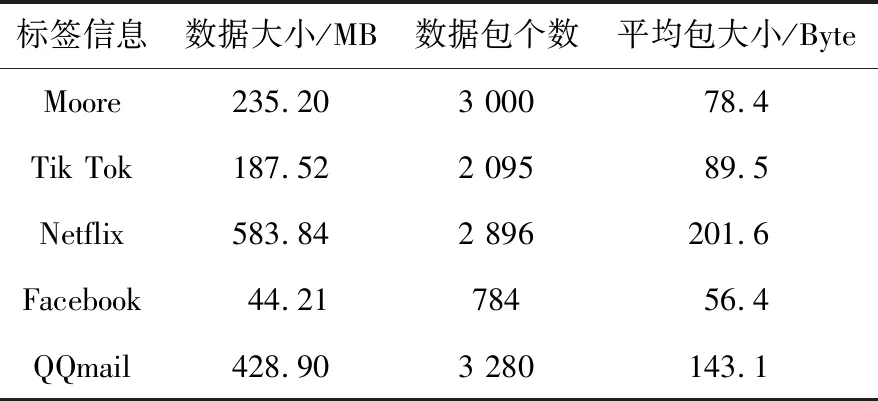
表1 流量收集结果Tab.1 Traffic collection results
4.2 评价指标
为了验证加密视频流量识别方法的可行性,实验中使用3种评价指标:准确率、F1值和AUC值。对于这些指标通常由TP,FN,FP,TN构成的混淆矩阵,如表2所示。

表2 混淆矩阵Tab.2 Confusion matrix
TP为将正类预测为正类数,FN为将正类预测为负类数,FP为将负类预测为正类数,TN为将负类预测为负类数。根据它们可以计算其他评价指标。
准确率如下:
F1值是通过精准率和召回率进行计算:
AUC定义为ROC曲线下的面积,通常大于0.5小于1。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是AUC值:
4.3 实验设置与结果
本文训练分类模型使用的决策树、随机森林以及LSTM网络算法参数设置如表3和表4所示。
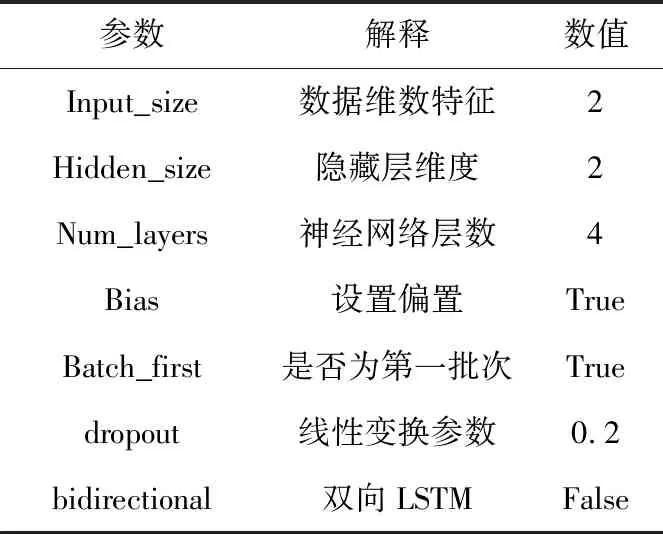
表3 LSTM算法参数表Tab.3 Parameters of LSTM algorithm

表4 决策树算法参数表Tab.4 Parameters of decision tree algorithm
实验中,将实验数据随机打乱后均分为10等份,其中9份作为训练数据,1份作为测试数据。在测试过程中采用十折交叉验证方式 (Ten-fold Cross-validation)[19],即将数据集等分为10份后,轮流将其中9份作为训练数据,1份作为测试数据进行测试验证。每一次实验都会得到相应的准确率,最后将10次结果的正确率在计算平均值之后作为对算法精度的估计。本实验共通过3次十折交叉验证,最后求其均值作为最后的算法估计值。
实验1采用Moore数据集作为原始模型训练的训练数据,对其进行加噪处理后作为训练扰动模型的训练数据,测试数据采用Moore数据集和自行收集的网络流量数据,其中自行收集的数据作为需要被识别的分布外数据;实验2采用自行收集的流量数据作为训练数据训练原始模型,对这些数据进行加噪处理后作为扰动数据训练扰动模型,测试数据采用自行收集的网络流量,未进行标签划分的数据作为需要识别的分布外数据。实验1和实验2的结果如图4所示。通过实验结果可以看出,对于3种算法,决策树、随机森林和LSTM神经网络算法的识别准确率都可以达到92%以上,有效性高于目前部分识别方法,可精准识别测试数据中OOD数据样例。同时,在这3种算法中,LSTM神经网络算法模型准确率最高,识别精度可以达到95%以上,并能确保很小的假阳率,减少误报。
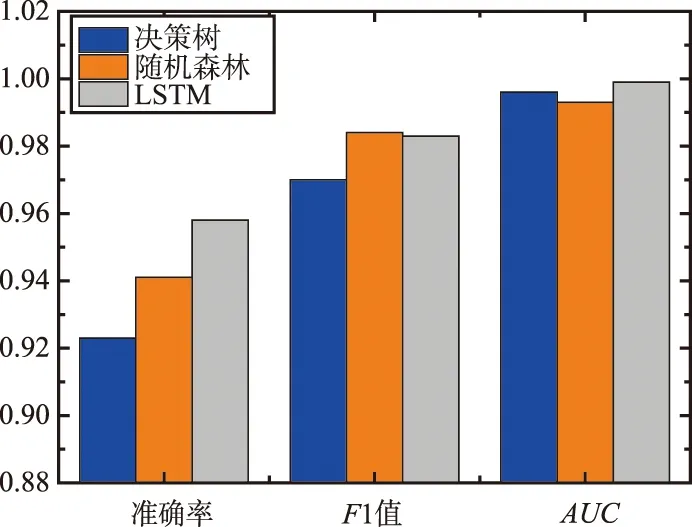
图4 3种算法模型的指标Fig.4 Indicators of the three algorithm models
5 结束语
本文提出了一种基于计算似然比的分布外网络流量数据识别方法,解决深度学习模型分类结果不可信的问题。通过对原始数据加入噪声构造扰动数据模拟分布外数据,并用此扰动数据训练新的扰动模型,利用2个模型得到结果的LR判别分布外数据,提高单一模型分类结果的置信度。通过在Moore数据集以及自行收集的数据集上验证了该方法的性能,结果显示在2个数据集上都取得了良好的识别效果,识别分布外数据的准确率可以达到92%以上,有效的检测分布外数据将会规避许多网络安全问题。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
舰船科学技术(2022年10期)2022-06-17
计算机与数字工程(2022年3期)2022-04-07
计算机应用与软件(2022年2期)2022-02-19
山东建筑大学学报(2021年6期)2021-12-23
北京航空航天大学学报(2021年7期)2021-08-13
民用飞机设计与研究(2020年4期)2021-01-21
物联网技术(2018年8期)2018-12-06
现代电子技术(2016年24期)2017-01-19
湖南师范大学学报·自然科学版(2014年5期)2014-11-14
