
一种端到端的自然场景文本检测与识别模型
2022-08-01 03:44王志鹏
测控技术 2022年7期
陈 鹏, 李 鸣, 张 宇, 王志鹏
(南昌大学 信息工程学院,江西 南昌 330000)
自然环境下的文本识别一直是计算机视觉和机器学习挑战性领域关注的热点问题之一[1-2]。传统的光学字符识别(Optical Character Recognition,OCR)系统主要侧重于从扫描文档中提取文本,而场景文本识别从自然场景中捕获的图像中获取文本[3]。场景文本识别分为文本检测[4-9]和文本识别[10-11]两个步骤,比起传统OCR来说更具有挑战性,失真、遮挡、文本角度、背景繁杂等现存的挑战[2]仍未完全解决。
现今出现了各种文本检测技术解决方案,例如特征提取、区域建议网络(Region Proposal Network,RPN)、非极大值抑制(Non-Maximum Suppression,NMS)等方法[12-13],但这些方法需要大量的运算和内存,特征金字塔网络(Feature Pyramid Networks,FPN)[14]应用于当前主流检测模型的特征融合结构,能够很好地解决这一问题。而在文本识别技术方面,RobustScanner模型[15]解决了基于注意框架的编码器对无上下文文本图像的误识别问题,但就目前来说,使用卷积网络与循环网络相结合的识别网络结构仍为主流[9],并存在很大提升空间。此结构对解决脱离上下文环境、导致识别不准确问题效果明显。端到端方面,DRRGCN模型[16]对形状文本检测提出了一种端到端的统一关系推理图。
本文算法和理论分析基于FPN[14]与CRNN[9]模型推导。Lin等[14]通过采用特征金字塔的卷积神经网络进行高层和低层融合的方式,得到空间细节饱满、语义信息丰富的特征,从而提升准确性。Shi等[9]认为使用卷积网络与循环网络结合可以在场景文本识别领域取得非常好的效果。但特征金字塔常用于目标检测领域,而CRNN算法由于训练时容易出现梯度爆炸、消失和无法有效预测长文本序列导致连续字符预测有误等问题,仍然需要进一步进行研究。
本文提出一种端到端的场景文本检测与识别方法,通过基于特征金字塔的特征提取,编码用深度双向递归网络、残差网络[17],解码用连接时间分类损失、注意力机制,依次连接构成的网络模型,本文模型具有以下特点:① 在速度和准确率之间进行权衡,可以获得更加鲁棒的语义信息,通过语义信息对长文本检测有很好的效果;② 针对解决梯度爆炸、消失等问题达到了较优的效果,在加快模型训练收敛速度的条件下提升了在自然场景下的文本识别的准确率;③ 端到端检测与识别模型,可进行端到端训练。
本文创新点如下:① 针对小文本的检测问题,利用特征金字塔机制,有效地解决了小文本遗漏问题;② 将残差模块融合进循环神经网络,不仅降低了训练难度且极大地提升了网络的收敛速度;③ 通过增强语义信息提高识别率突破,在连接时间分类损失中引入注意力机制,在识别过程中完成不同序列的权重分配,避免了对标签进行额外的预处理(对齐)及后期的语法处理,同时提高多样本数据的处理速度。
1 相关研究
1.1 文本检测网络
当前FPN应用于位姿估计、语义分割等许多领域的计算机视觉任务。FPN作为特征金字塔概念设计的特征提取器,可根据其特性解决图像目标多尺度问题,对不同场景可设计构建不同的具有高级语义的特征金字塔。通过在原单个网络将每个分辨率的特征图与下一张缩放分辨率的特征图相加,这样每层预测所用的特征图都包含多种分辨率、语义强度的信息,最后得出不同分辨率的融合特征图能够对不同尺寸、分辨率大小目标的有效检测。
FPN通过权衡速度和准确率,获得更加鲁棒的语义信息,解决了以往的文本检测算法只使用顶层特征进行预测而不考虑其他层的特征导致的检测效果不佳的问题。
1.2 文本识别网络
1.2.1 Bi-LSTM编码与ResNet网络
长短期记忆人工神经网络(Long-Short Term Memory,LSTM)作为一种独特设计结构的时间递归神经网络(Recurrent Neural Network,RNN),LSTM内部主要通过忘记阶段、选择记忆阶段和输出阶段解决长序列训练过程中的梯度消失、爆炸问题。而同一时刻两个不同方向的LSTM组成的Bi-LSTM 很好地优化了LSTM无法编码从后向前的信息问题。Bi-LSTM在自然语言处理任务中都常被用来建模上下文信息。
而残差网络(ResNet)的灵感来源于使用全等映射直接将前一层输出传到后面的思想。图1(a)和图1(b)分别为ResNet及Bi-LSTM网络结构模型。
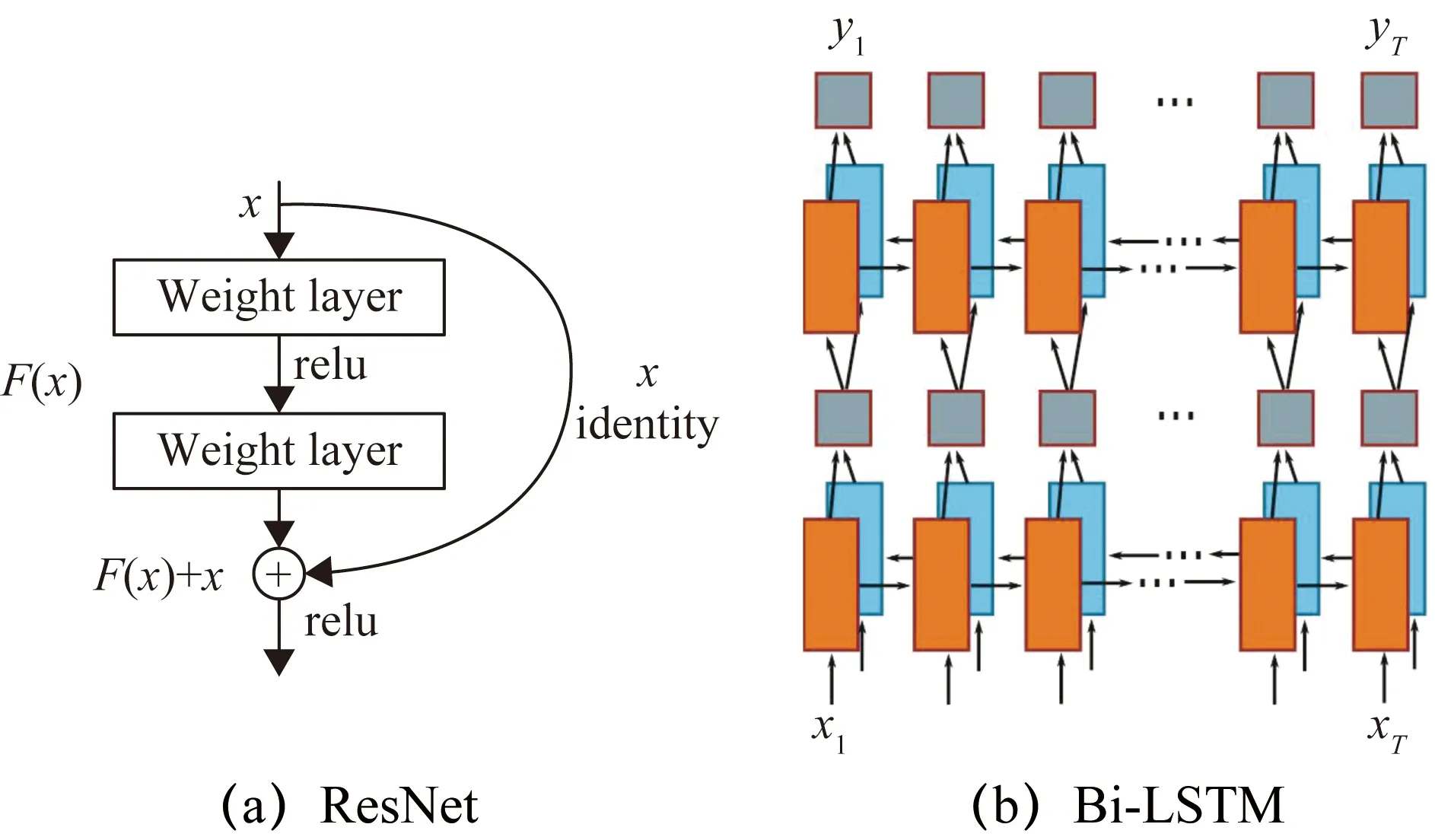
图1 残差网络与双向递归网络结构图
1.2.2 CTC解码与Attention机制
连接时序分类器(Connectionist Temporal Classification,CTC)[23]通过避开传统输入与输出手动对齐方式从输入序列找出预测概率最高的输出序列,CTC利用输出序列和最终标签空间映射关系(多对一)来解决传统输入输出序列手动对齐的问题,如果输入特征、输出标签对齐存在不确定性问题,CTC能够自动完成优化模型参数和对齐切分边界任务。
注意力机制(Attention mechanism)可以视作一种资源分配的机制,根据Attention对象重要程度,将原本平均分配的资源重新进行分配。在深度神经网络的结构设计中,Attention模型能够通过合理对源数据序列进行数据加权变换从而学到多种类型模态间的相互关系,更好地表示信息。
2 提出算法
2.1 模型框架
本文提出了一种端到端的场景文本检测与识别方法,利用FPN特殊结构的卷积神经网络(Convolutional Neural Networks,CNN)作为检测器;在Bi-LSTM中加入ResNet作为编码器,最后利用CTC融合Attention作为解码器。算法流程框架如图2所示。
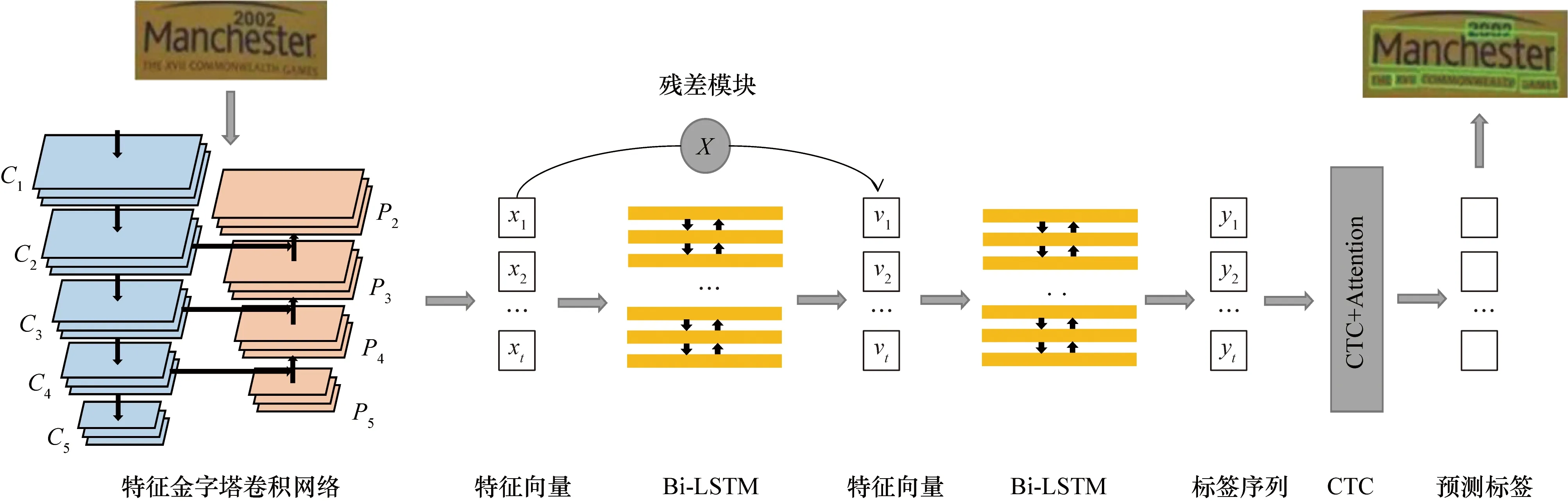
图2 算法框架流程图
2.2 文本检测网络
本文算法检测网络以FPN为主干网络,为了充分利用其高分辨率和强大的语义特征,FPN涉及自下而上的路径、自上而下的路径与横向连接。自下而上的路径是在每个阶段定义一个金字塔级别,使用每阶段最后一个残差结构特征激活输出表示为{C2,C3,C4,C5},分别对应conv2~conv5,相对于原输入图像,具有{4,8,16,32}像素步长。而自上向下的数据传输路径则从更高的金字塔层次对更强的特征图进行语义上的提升,从而产生更高分辨率的特征。然后,通过每个横向连接将自下而上的路径和自上而下的路径具有相同空间大小的特征图合并,这一步是为了利用底层的定位细节信息。最后,得到一组特征图,标记为{P2,P3,P4,P5}。将特征图{P2,P3,P4,P5}作为连续输入,输入到文本识别部分。特征金字塔结构如图3所示。
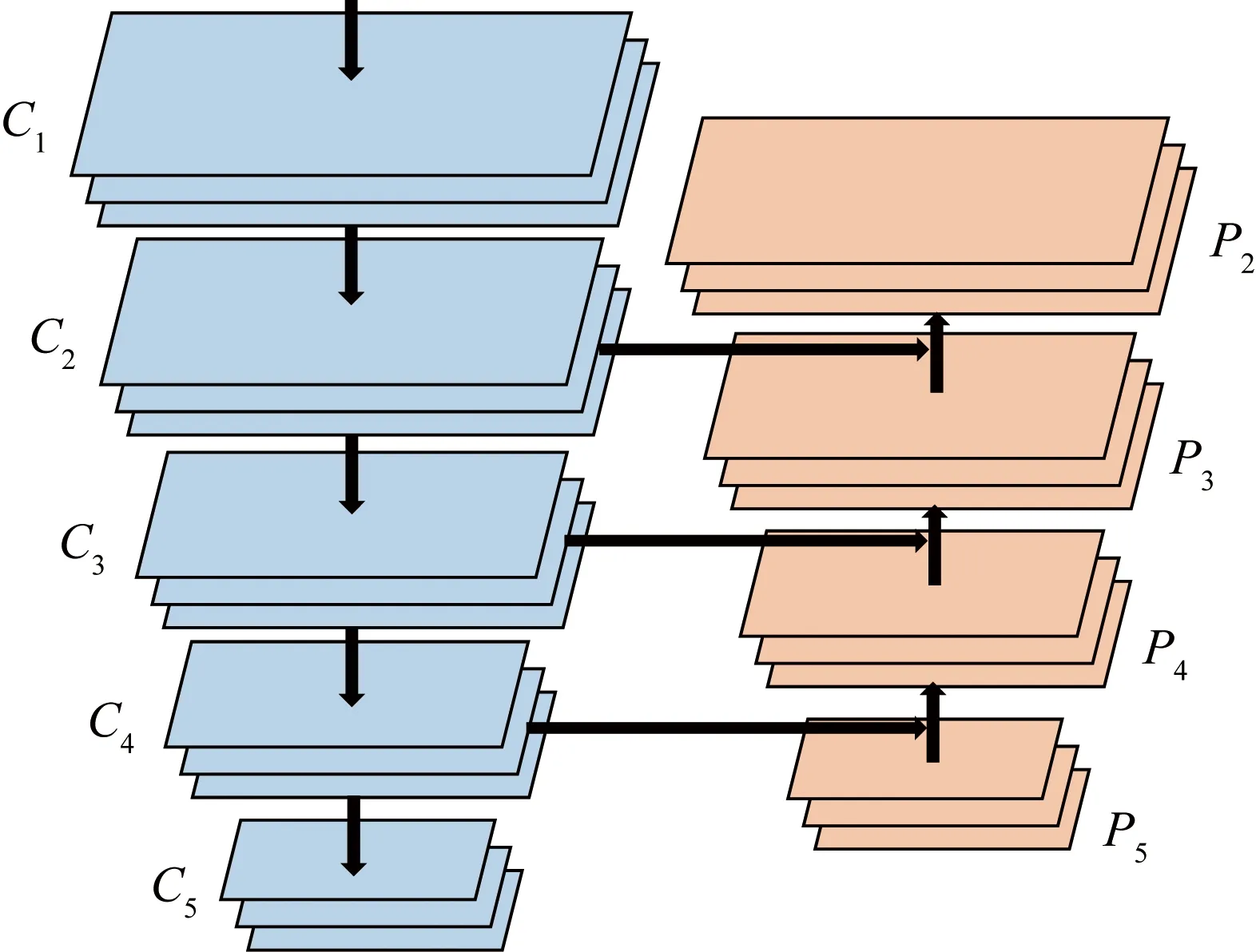
图3 特征金字塔结构
2.3 文本识别网络
2.3.1 Bi-LSTM编码
文本识别部分采用经典的Bi-LSTM结合CTC构架,而Bi-LSTM组成部分RNN随着距离的增大,存在将以前的信息连接到当前的任务时容易导致梯度爆炸、消失等严重问题。网络层数越深,时间间隔越长,这些都会因梯度问题致使模型不但训练困难,且无法处理长距离信息传递反馈问题,考虑到Bi-LSTM的缺陷,ResNet网络的加入能够很好地解决这个问题。
将ResNet分别加入Bi-LSTM模型输入和输出层,不仅有效解决了Bi-LSTM固有的梯度爆炸、消失的问题,同时也加快了模型的收敛速度,融合模型如图4所示。
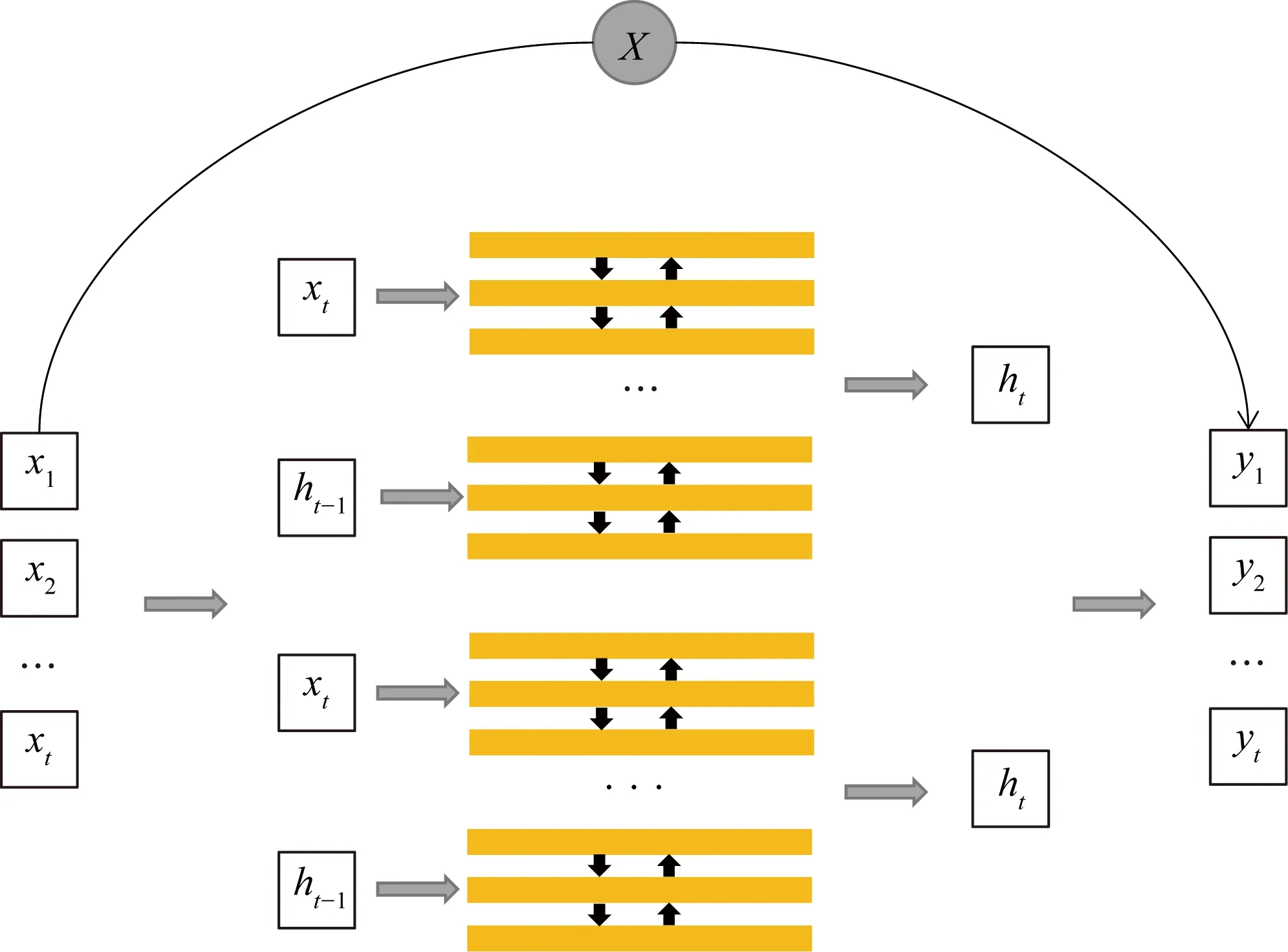
图4 Bi-LSTM+Resnet融合模型
本文以F(x)为原模型,取x=3。
y=F(x)
(1)
则F(3)=3.1。
在F(x)中加入ResNet得到模型D(x)。
y=D(x)
(2)
根据 ResNet可知:
D(x)=F′(x)+x
(3)
则
D(3)=F′(x)+x=F′(x)+3=3.1F′(x)=0.1
当进行模型训练,已知反向传播中输出与梯度产生强相关,在网络进行反向传播时,随着网络层数的增加,梯度消失的情况越来越容易出现。假定输出从3.1变为3.2,则
借鉴上述结论,引入ResNet将前一层输出恒等映射到后面,输出变化与权重的调整效果成正比,使网络对输出变化更灵敏,从而在反向传播中梯度计算时避免梯度消失、爆炸,优化了训练效果。
2.3.2 CTC解码
由于CTC每帧标签是单独输出每个字符的概率,会忽略整体信息而只针对局部信息进行预测,导致CTC对于长文本序列预测不尽人意。通过引入Attention的CTC实现对特征序列的解码,有效解决了CTC解码无法有效预测长文本序列的问题。
给定输入特征序列X={x1,x2,…,xv},隐变量Z=(ztD∪blankt=1,2,…,V),输出长度为l的序列Z=(yiD|l=1,2,…,T)。其中,V为序列数(编码);T为字符数;D为字典(所有字符)。CTC假设标签之间是独立的,利用贝叶斯计算预测序列的后验概率分布:
(4)
式中:p(Y)为字符级语言模型;p(zt|zt-1,Y)为已知上一时刻输出的隐变量预测下一时刻的隐变量的条件概率;p(zt|X)为隐变量概率(由已知输入特征可得)。
直接计算与Attention结合的CTC的联合预测序列的概率:
(5)
式中:p(y1|y1∶l-1,X)为已知输入特征X和前l个输出得到l时刻的预测概率。
2.4 损失函数
检测模块结束方式返回是否为文本分类及边界框回归,定义多任务损失:
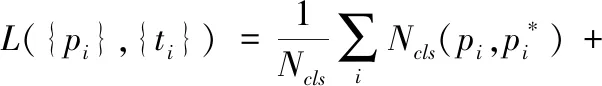
(6)
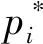
以Softmax损失作为分类损失,以光滑损失L1作为回归损失,有
(7)
(8)
(9)
式中:Lcls为分类通道的损失。
3 实验分析
3.1 实验细节
笔者提出的算法可进行端到端训练。在Ubuntu 16.4系统上,框架选用Tensorflow,选取知名竞赛数据集ICDAR(International Conference on Document Analysis and Recognition) 2013[24]和ICDAR 2015[25]进行训练(训练图片为ICDAR 2013、ICDAR 2015数据集229、1000张图像),模型其他新层权值是均值为0、标准差为0.01的随机高斯分布的随机权值。为训练检测器,本文通过为每个锚点分配一个标签来定义正负标签。文本是正锚,背景是负锚。利用SGD算法对模型进行优化,即每次更新时使用一个随机样本进行梯度下降,随机样本表示所有样本对超参数进行调整,加快了迭代速度。将学习率、动量、动量衰减和批量大小分别设置为0.0002、0.8、0.0004和1。预训练完成后分别将ICDAR 2013、ICDAR 2015数据中233、500张图像用于测试。
实验机器配置为Intel i7 9700 CPU、Nvidia 1080ti GPU和16 GB RAM。标定的训练图像,高度不大于600像素,宽度不大于1200像素,比例不变。
3.2 实验结果
3.2.1 文本检测性能测试
本文采用ICDAR自然场景文本检测竞赛系列数据集检验各类方法模型的性能。ICDAR2013数据集包括复杂背景、不均匀光照和强干扰背景,同样,ICDAR2015背景比ICDAR2013更加复杂,光照、失焦等干扰因素更多。表1、表2为本模型检测端与其他检测模型的比较结果。
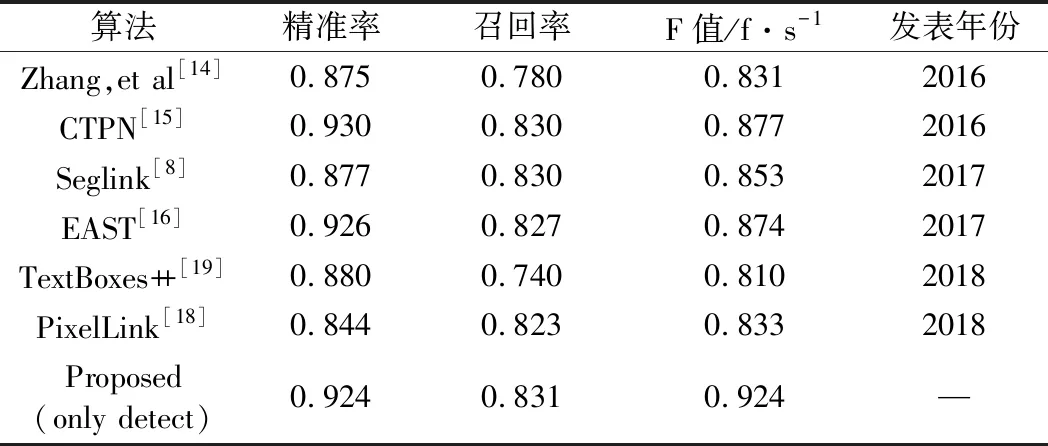
表1 检测模型在ICDAR2013数据集性能比较
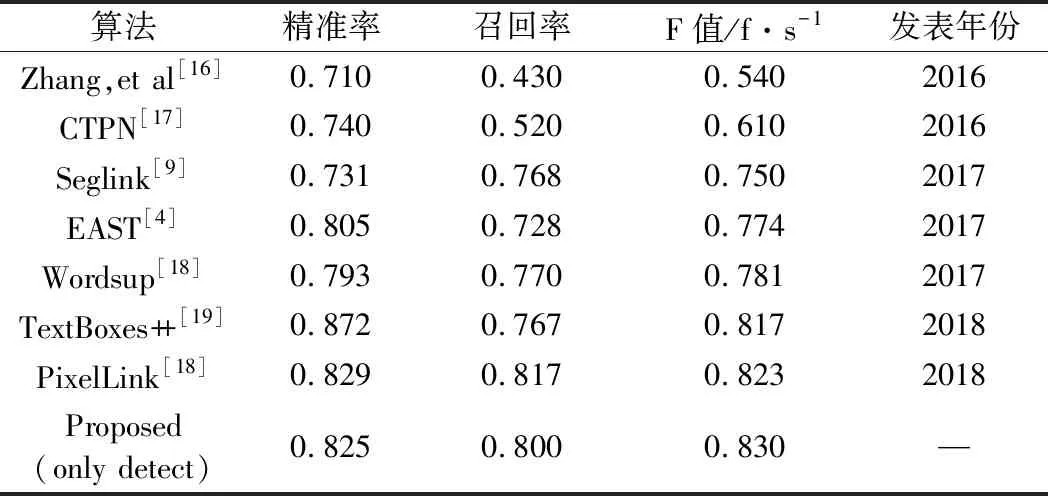
表2 检测模型在ICDAR2015数据集性能比较
可见,本文模型检测端与著名模型在数据集ICDAR2013、ICDAR2015中进行性能测试,识别准确率有2%~4%提升,计算速度有3%~8%提升。引入特征金字塔的检测端充分地利用多尺度特征,提升了文本定位准确性。
3.2.2 端到端性能测试
本文端到端系统采用ICDAR2013和ICDAR2015数据集,评估方案分为“文本检测”标准和“端到端”标准[26]。文本检测中性能评估只关注图像中出现在预先指定词汇中的文本实例,忽略其他实例。端到端关注所有出现在场景图像中的文本实例。端到端下候选转录包含了了强上下文、弱上下文和泛型3个词汇表。
如表3所示,将近几年著名端到端模型的性能进行总结比较。
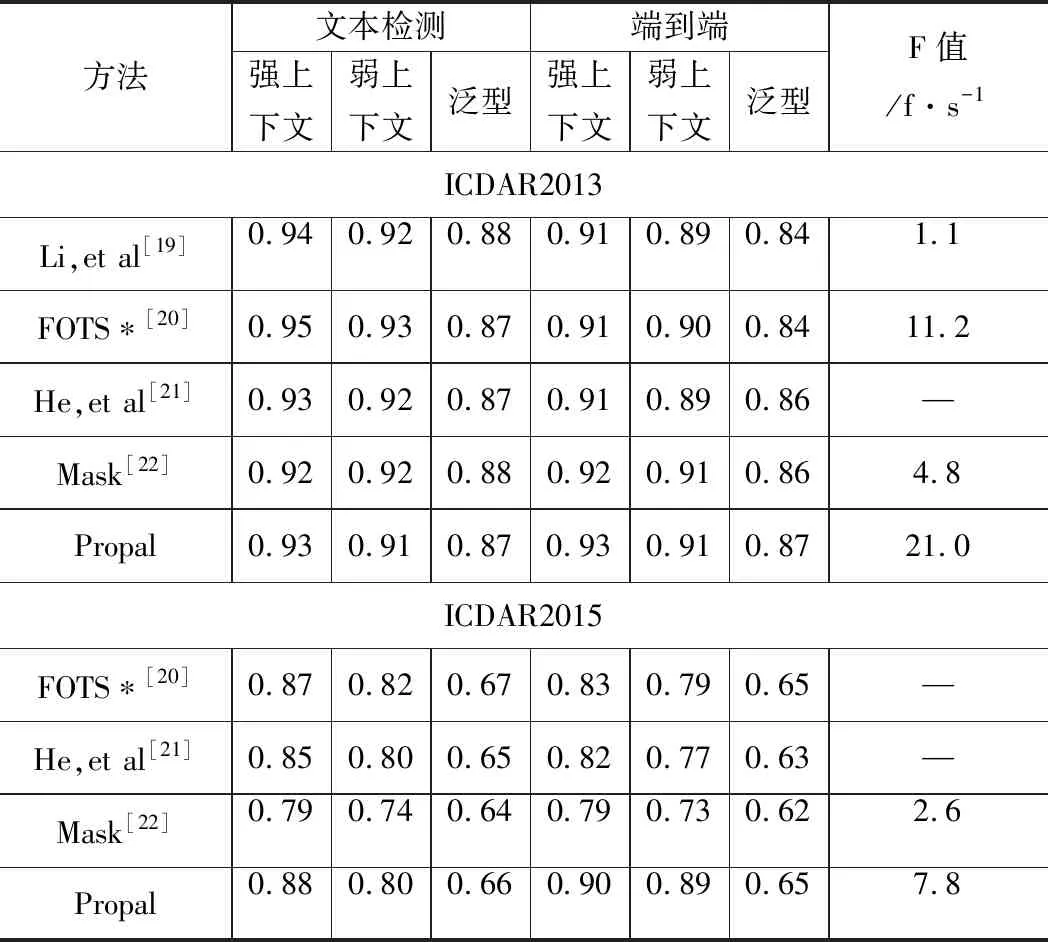
表3 端到端模型在ICDAR2013和ICDAR2015数据集性能比较
由表3可见,本文端到端模型与其他端到端模型在数据集ICDAR2013、ICDAR2015中进行性能测试,统一使用512×512的比例测试时,本文端到端模型在精度、召回率和F值上均有优势,识别准确率有1%~8%的提升,识别速度远超其他模型,且本文方法计算和存储增量很小。实验证明,本文端到端模型不仅提高了识别准确率,还提高了识别速度。
3.2.3 识别损失函数、准确率变化曲线
在测试数据集测试,进行2000000个时期,批量大小为32,初始学习率为0.01,指数衰减为每500000个时期0.1。引入残差网络、注意力机制后的模型明显解决了梯度爆炸、消失问题,同时网络训练收敛更快。图5为改良前后的模型敛散状态。
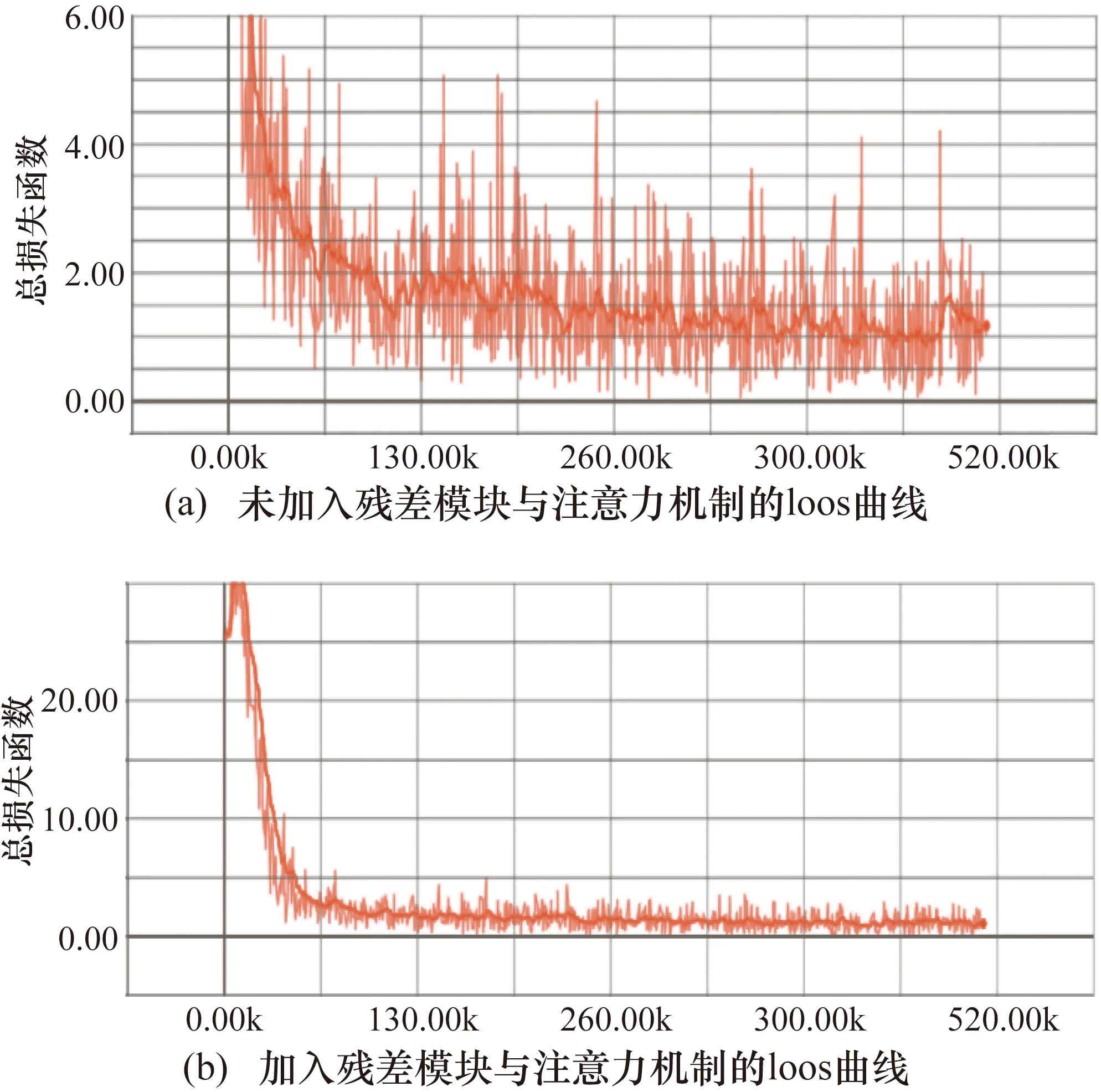
图5 模型改良前后loss曲线收敛性
3.2.4 识别结果
识别结果如图6所示,选用3组图片进行识别(分别为上、中、下),左图为原图片,中图为识别图片(识别文字),右图为框住图中文本的文本框的坐标数据与识别结果。显然,第2组和第3组图中不定长的小文本得到准确的识别。

图6 ICDAR2013、ICDAR2015数据集上测试的结果
4 结束语
本文利用特征金字塔来提取多尺度特征,通过引入残差网络、注意力机制的Bi-LSTM、CTC分别进行编码及解码,达到端到端识别模型的识别。该方法不仅解决了梯度爆炸、消失等问题,降低了训练难度,还提升了网络的收敛速度,提高了文本识别准确率。该模型在不同数据集上均获得良好结果。在后续工作中,将首先改进检测网络架构,解决任意形状或者多角度的文本检测问题,扩展模型应用范围;其次增加多语种数据;最后在识别网络架构上进行进一步的优化,提升识别率。
猜你喜欢
环球时报(2022-09-19)2022-09-19
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
考试与评价·七年级版(2020年4期)2020-10-23
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
小学教学研究·新小读者(2017年9期)2017-10-25
中学生数理化·高三版(2016年9期)2016-05-14
