
分布式能源和电能替代负荷接入的配电网综合负荷概率模型
2022-07-30 10:44:44李振嘉李家珏
河北电力技术 2022年3期
李振嘉,叶 鹏,张 强,孙 峰,李家珏
(1.沈阳工程学院电力学院,辽宁 沈阳 110136;2.国网辽宁省电力有限公司电力科学研究院,辽宁 沈阳 110006)
0 引言
“双碳”背景下,分布式能源和电能替代负荷的大规模接入是配电网发展的必然趋势,但风电场和光伏电站在并网出力时的随机性、间歇性和波动性对电力系统的规划和运行带来了巨大的挑战,并对配电网的供电能力和协调消纳提出了更高的要求[1]。同时,为推动能源转型,实现“双碳”目标,我国正大力推进“煤改电”工程和电动汽车及其充电基础设施的应用,涵盖电采暖和电动汽车的电能替代负荷,将越来越多地接入配电网[2]。然而,电能替代的负荷特性受地理环境,季节更替,设备类型,用电时间等诸多因素影响,表现出间歇性、分散性、集中并发等特点,在规模化地接入配电网之后将促使其负荷特性显著改变。
在传统配电网中,可以将负荷模型看作一个随机变量模型,利用正态分布近似表征负荷的不确定性[3-5]。随着可再生能源和新型负荷的接入,利用负荷网络结构和全部参数建立负荷模型的拓扑等值方式[6]难以反映当下配电网各节点所投负荷之间的自然相关性与时序相关性,这类难以用解析式表达的潜在关系增大了配电网负荷模型构建的难度[7-8],而机器学习算法能剖析各不同特性的负荷之间所具有的内在联系,构建起适应新负荷特性的非拓扑等值模型,因此基于误差逆传播神经网络(BP)、长短期记忆网络(LST M)、渐进梯度回归树(GBRT)、支持向量机(SV M)、随机森林(RF)等算法的负荷模型建立方法应运而生。诸多算法中,基于渐变Boosting的集成学习算法XGBoost(e Xtreme Gradient Boosting)以其精度高,训练时间短等优点在诸多模型中得以应用。文献[9-13]通过对比RF、GBRT、SVM和LST M等多种机器学习算法,验证了XGBoost对电网负荷预测具有较好的拟合度,为搭建负荷模型奠定理论基础。
通过上述研究可以发现,目前机器学习算法对于电网负荷的应用多集中于负荷预测,很少考虑分布式能源和电能替代负荷接入下的配电网综合负荷模型搭建问题。本文在分析了负荷特性与树集成算法发展背景的基础上,将主流机器学习算法XGBoost与电网负荷模型的搭建有效结合,提出了一种用于建立配电网综合负荷模型的多概率函数叠加方法。
1 基础模型
1.1 风电出力概率模型
风电出力特性采用的平均风速数据选用二参数Weibull分布表示,其概率密度函数[14]为

式中:v为风速;k,c为Weibull分布的形状参数和尺度参数。
对于风机出力特性的研究,需要将风速模型转化为风电输出功率模型。忽略尾流效应和变流器损耗,典型风电机组的输出功率函数表达式[15]为

式中:PWT为当前风速的输出功率;v为当前风速;v ci为切入风速;v r为额定风速;v co为切出风速。
1.2 光伏出力概率模型
光伏出力概率模型采用Beta分布,其概率密度函数[14]为

式中:f(·)为光伏Beta概率分布模型;Γ(·)为Ga mma函数;α,β均为Beta分布的形状参数;E为实时光照强度;Emax为某一时段内的光照强度最大值。
大规模光伏并网总出力为

式中:S为组成光伏阵列的光伏子方阵总面积;μPV为光电转换效率。
1.3 传统综合负荷概率模型
传统综合负荷概率模型近似采用正态分布表示

式中:P L为传统综合负荷的有功功率;μP,σP为常规负荷有功功率的期望值和标准差。
1.4 电能替代负荷概率模型
电能替代是在终端能源消费环节,使用清洁电能替代散烧煤、燃油的能源消费方式,如电采暖、电动汽车等。电锅炉是消耗电能满足用户热负荷需求的供热设备,采用“电采暖”可以有效减少高能耗高污染的燃煤锅炉的投入,助力零排放、无污染的绿色环保供暖。同时,电动汽车在节能减排、生态保护、拓展电力市场以及保障油气供应安全等方面有着传统汽车无法比拟的优势,受到了各国政府、汽车生产商以及能源企业的广泛关注[16]。在现有的配电网中,电锅炉与电动汽车及其充电基础设施的大规模应用,对电力系统的运行控制提出更高的要求。因此,在配电网综合负荷等值模型中须考虑“煤改电”下电采暖负荷特性和“油改电”下电动汽车充电负荷特性。
1.4.1 电采暖负荷概率模型
室内外温差影响热负荷的波动,以温度作为变量[17],用户侧电采暖负荷概率模型为

式中:P lt为用户侧所需的热负荷;I为供热范围内用户数量;q i为建筑物内单位面积散热系数;S i为标准家庭用户面积;T tinside为t时刻室内平均温度;T t-outside为t时刻室外平均温度;PEB为电锅炉输出功率;μ为电热转化效率。
1.4.2 电动汽车充电负荷概率模型
由于电动汽车品牌众多,不同车企间采用的充电模式不尽相同,为简化分析,本文将电动汽车充电负荷近似为恒功率模型
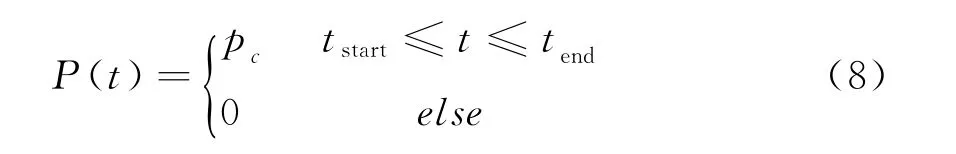
式中:p c为充电功率大小;tstart为充电起始时刻;tend为充电结束时刻。
根据全国家庭旅行调查(National Househol d Travel Sur vey,NHTS)的统计数据可知,充电时刻概率分布符合正态分布式中:μc为起始充电时刻期望值;σc为起始充电时刻标准差。

电动汽车日行驶里程满足对数正态分布

式中:μc1为行驶里程期望值;σc1为行驶里程标准差。
电动汽车起始充电荷电状态Sstart与单次行驶里程L和一次充电行驶次数N有关,即

式中:Send为上一次完成充电后的荷电状态;Lfull为标定续航里程数。
在确定电动汽车电池容量、保有量和充电功率的前提下,考虑起始充电时刻和起始荷电量,可得电动汽车充电负荷为

式中:PEV为电动汽车充电负荷功率;n为区域内电动汽车保有量。
2 基于XGBoost多概率函数叠加的配电网综合负荷概率模型
2.1 XGBoost的算法机理
XGBoost是借助梯度提升技术实现的机器学习算法,可以高效、灵活地针对不同的输入变量进行学习,找到各输入变量的内在关联,进而得出目标输出。
假设第t次迭代训练的树模型是f t(x),则有

式中:x i为给定的样本数据为第t棵树的输出结果为前t-1棵树的输出结果;f t(x i)为第t棵树的模型。
XGBoost模型的目标函数为

式中:l(·)为衡量模型精度的损失函数L;正则项和λ作为惩罚系数分别控制叶子数T和叶子结点权重向量w不会过大。
将第j个叶子结点遍历的所有样本x i划入同一集合I j中将目标函数采用泰勒级数展开至第二项可得

式中:g i为损失函数L的一阶导数;h i为损失函数L的二阶导数;G j为样本集合I j中g i的和;H j为样本集合I j中h i的和。
整个目标函数Obj达到最值的条件为各子式达到最值。假设当前树结构已经固定,结合一元二次函数性质,可更新目标函数为

目标函数越小,表示当下分裂法的树结构已经达到最优。
2.2 配电网综合负荷概率模型
分布式能源和电能替代负荷接入下的配电网负荷具有一定季节周期性和日周期性,本文考虑特定季节下以日为周期的短期负荷波动特性。在建立配电网综合负荷概率模型时,不考虑风电场、光伏电站、传统综合负荷、电锅炉和电动汽车的内部结构和参数及遵循的内在规律,仅对筛选出的特征数据进行分析,考虑风光荷的自然属性,探究特征数据与综合负荷的关系[18]。
在具有多概率函数的配电网中搭建综合负荷模型,本质上就是将具有时序性且类型各异的连续函数进行叠加。为简化处理,将连续函数分段化,取某一时间段内特征输入对应函数值的均值作为特征数据,把概率密度函数叠加的问题转化为探究特征数据与综合负荷内在关联的问题。
以风电出力概率模型为例,在设备参数给定的情况下,影响风电机组出力特性的主要因素为实时风速,将实时风速作为特征输入代入式(1)、式(2),并将得到的风电出力具体数值作为特征数据。1节中各类模型特征输入与特征数据的关系如图1所示。

图1 特征输入与特征数据的关系
将传统综合负荷模型所连的虚拟母线上增加分布式能源和电能替代负荷模型,即可得到配电网综合负荷概率模型,其结构如图2所示。

图2 配电网综合负荷模型结构
XGBoost算法可以避免分析系统内部复杂机理,深度挖掘特征数据之间的自然属性关系和特征数据与综合负荷的内在关联,解决配电网综合负荷概率建模问题。
XGBoost算法的多概率函数叠加过程如图3所示,将给定的原始特征数据划分为训练集和测试集,基于交叉验证的思想,将训练集划分为5等份,利用其中任意4份对XGBoost模型进行训练,并基于训练好的XGBoost模型对未训练部分和测试集运行输出,反复进行,获得基于训练集得到的5组输出结果以及基于测试集的5组输出结果,并将测试集的5组输出结果取均值作为配电网综合负荷大小。

图3 基于XGBoost的多概率函数叠加基本流程
基于XGBoost算法的配电网综合负荷概率模型建模流程如图4所示。

图4 基于XGBoost算法的配电网综合负荷概率模型建模流程
3 算例分析
3.1 参数选择
以辽宁某地区电网2022年1月冬季典型日的真实数据进行试验,将出力与负荷数据按小时取平均值,全天共计24个采样点。以1月1日-1月28日的样本数据作为训练集,所选取的特征数据为各模型参数给定下的出力与负荷数据及配电网综合负荷历史数据,试验数据清单如表1所示。以1月29日的各模型参数给定下的出力与负荷数据为XGBoost模型的输入数据,模型输出数据为1月29日配电网综合负荷大小。

表1 试验数据清单
为得到新能源出力和电能替代负荷的相关数据,需确定对应模型参数。其中太阳辐照度观测资料采用辽宁气象台统计数据,风速观测资料采用区域内测风塔统计数据,相关计算参数如表2所示。

表2 基础参数
区域内建筑物,电锅炉和电动汽车相关计算参数如表3所示。

表3 基础参数
XGBoost算法中包含的参数较多,本文选用的XGBoost算法的主要参数如表4所示,其他参数为默认值。

表4 _XGBoost算法的主要参数
3.2 评价指标
本文采用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差百分比(Mean Absolute Percent Error,MAPE)作为配电网综合负荷模型评价指标

R RMSE和M MAPE值越小表示所选用的模型精度越高。
3.3 结果分析
为了验证XGBoost算法用于多概率密度函数下配电网综合负荷模型搭建的可行性,将其与随机森林(Random Forest,RF)算法进行对比。利用1月29日配电网综合负荷的大小,反应上述2种算法所建模型的精度,图5为不同模型下1月29日配电网综合负荷。

图5 不同模型下1月29日配电网综合负荷
将输入的起始充电时刻、室外实时温度、实时风速、实时光照强度、用户用电习惯5类特征数据归一化处理,利用特征重要性描绘各输入特征对于综合负荷模型的影响,该数值由树模型各叶子节点权重叠加得到,图6所示为特征重要性分布图。

图6 特征重要性分布
采用Pearson相关系数分析XGBoost算法中各输入特征之间的关系,二维向量的Pearson相关系数计算式为

将上文5类特征数据进行两两计算得到Pearson相关性分析图,各输入特征自然性与时序性相关系数如图7所示。

图7 各输入特征自然性与时序性相关系数
2种算法对配电网综合负荷模型的评价指标对比如表5所示。

表5 不同算法的评价指标
根据图5-7和表5可得到如下结论:
(1)相较于RF算法,基于XGBoost算法的配电网综合负荷概率模型能够更好地利用源-荷间的自然相关性拟合日负荷变化。
(2)在冬季典型日下,室外温度对于综合负荷的构建具有较强的特征重要性,其值为0.673;实时风速的特征重要性次之,其值为0.132。
(3)室外温度与实时风速的Pearson相关系数为0.67,具有较强的正相关性,结合图5信息,说明二者对综合负荷的波动有主导性影响。实时风速与实时光照强度的Pearson相关系数为-0.54,说明二者的出力具有互补性,适当调节其接入电网的比例可以使分布式能源的出力更加稳定。
(4)相较于RF算法,利用XGBoost算法所建模型在均方根误差和平均绝对误差百分比的评价指标中表现出较高精度。
4 结论
面向大规模分布式能源和电能替代负荷接入的配电网,考虑风电、光伏以及电采暖设备、电动汽车充电负荷对于配电网负荷特性的影响,提出了基于极限梯度提升的多概率函数叠加方法,建立了配电网综合负荷概率模型,所建模型能够挖掘源-荷间的主要特征,对于日负荷波动具有较高的拟合精度,可以为电力系统运行规划提供重要依据。考虑到季节性是影响电力系统发电与负荷的重要因素,下一步探究方向将针对各类电气设备接入的配电网,研究不同季节的日负荷波动情况以及对于上述模型的结构优化。
猜你喜欢
中学生数理化·高一版(2021年3期)2021-06-09 06:10:16
汽车维修与保养(2021年8期)2021-02-16 00:28:32
动漫星空(兴趣百科)(2019年3期)2019-03-07 07:47:46
电子测试(2018年10期)2018-06-26 05:53:50
海外星云(2016年17期)2016-12-01 04:18:42
电测与仪表(2016年23期)2016-04-12 00:23:00
河南电力(2016年5期)2016-02-06 02:11:35
中学生数理化·中考版(2015年10期)2015-09-10 07:22:44
电测与仪表(2015年5期)2015-04-09 11:31:12
自动化博览(2014年10期)2014-02-28 22:33:55
