
基于轻量级结构重参数化网络的口罩检测算法
2022-07-29 06:22:16卢峥松李青云杨世海张小龙
计算机与现代化 2022年7期
李 燕,卢峥松,李青云,杨世海,张小龙
(1.南京信息工程大学自动化学院,江苏 南京 210044; 2.无锡学院物联网工程学院,江苏 无锡 214105;3.中国科学院天文光学技术重点实验室,江苏 南京 210042)
0 引 言
自新型冠状病毒疫情爆发以来,疫情迅速蔓延到世界各国[1]。目前,国际环境仍在不断变化,虽然疫苗正在迅速发展,但还无法对潜在大流行的第一波疫情产生影响[2],我国疫情防控呈现持久性、长期性和稳定性的态势,疫情防控进入持久战阶段[3]。常态化疫情防控形势下,在人群密集的区域(例如商场、超市和车站)容易发生人与人之间的交叉感染,我国在面对疫情的预防和控制上,仍然面临严峻的挑战。在公共场所佩戴口罩可以阻止病毒通过飞沫传播,从而有效降低人们交叉感染的风险。因此,开发一套容易部署的轻量化高精度口罩佩戴检测系统来替代人工检测的方式,其具有重要的现实意义。
近年来,随着人工智能及相关技术的高速发展,基于深度学习的目标检测算法相继被国内外学者提出。一种是以R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]等算法为代表的二阶段网络,另一种是以YOLO系列[7-9]、SSD[10]和Retinanet[11]等算法为代表的单阶段网络。二阶段网络是基于区域来提取候选目标,算法检测精度更好,但由于网络结构较为复杂,检测速度较慢。基于回归的单阶段算法,检测速度较快,而精度稍低。本文研究相关目标检测算法,发现用于人脸检测的深度神经网络可以适用于口罩佩戴的检测任务。邓珍荣等人[12]提出一种基于YOLO算法的密集小尺度人脸检测方法,在多种层级的特征图融合细粒度特征,通过对浅层特征进行空间降维通道升维,丰富感受野区域里的图像信息在卷积网络中映射的特征信息,再和感受野较大的深层特征融合,提高对小尺度人脸特征的检测能力。Kim等人[13]提出了一种新的人脸识别体系结构GroupFace,在该结构中使用多组感知表示(multiple group-aware representations)学习人脸的隐藏组表示,缩小目标身份的搜索空间,最终取得了不错的人脸检测效果。牛作栋等人[14]提出一种基于Retinaface算法的口罩检测算法,增加自注意力机制并优化了损失函数,但模型参数量较大,推理速度仍有较大的提升空间。Retinaface算法[15]是一种鲁棒性较强的单阶段人脸检测器,它利用外监督(extra-supervised)和自监督(self-supervised)结合的多任务学习,在各种人脸尺度上执行像素方面的人脸定位。基于Resnet[16]骨干网络,Retinaface算法在WIDEDR FACE[17]上获取了极佳的检测成绩;基于MobileNet[18]骨干网络则可以在CPU上达到实时的检测速度。在WIDER FACE人脸数据集上,Retinaface的性能优于现有技术平均预测(AP)1.1个百分点,达到91.4%。WIDER FACE是目前业界公开的检测难度最高的人脸检测数据集,也是世界数据规模最大的权威人脸检测平台。
因此,本文尝试在Retinaface算法的基础上进行改进,提出一种针对口罩佩戴检测任务的算法。主要工作如下:
1)改进Retinaface网络结构,在算法上增加多分类任务,去除人脸关键点损失和面部密集点回归损失等无关的检测任务。
2)改进Retinaface算法的特征提取网络,提出一种双重级联金字塔网络,提升网络对细节的感知能力,实现特征增强,可以更好地应对自然场景下口罩检测存在的小尺度目标漏检等问题。
3)为了满足算法的实时性要求并加强网络的特征提取能力,引入轻量级结构重参数化网络RepVGG-A0[19]骨干网络,提高检测精度,并通过模型推理阶段的重参数化,使网络训练和网络推理阶段使用不同的网络架构,大幅减少参数量,使算法可以部署于低算力的设备上,更好地应用于实际场景。
1 Retinaface算法
1.1 Retinaface算法原理
Retinaface是一种基于像素级的单阶段人脸检测算法。该算法采用联合外监督和自监督的多任务学习策略,可以对各种尺度条件下的人脸做到像素级别的定位。
Retinaface的特征提取网络为特征金字塔网络FPN,分为P2~P6共5个有效特征层,其中P2~P5是从相应的Resnet残差网络输出特征图通过自顶而下和横向连接计算而来。P6将C5通过一个步长为2的3×3卷积计算得到。C2~C5使用Resnet-152残差网络在imagenet-11k数据集上预训练的参数,P6层通过Xavier方法[20]进行随机初始化。Retinaface为了进一步加强特征提取,采用了上下文模块,扩大欧几里得网络的感受野,增强模型的上下文推理能力。同时,采用可变形卷积网络(Deformable Convolutional Network, DCN)[21]代替横向连接和上下文模块中的所有3×3的卷积层,进一步加强卷积神经网络非刚性的上下文建模能力。该算法的整体网络结构如图1所示。
1.2 多任务损失函数
对于一个训练的锚点(anchor)框i,Retinaface算法的多任务损失函数为:
(1)
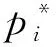
2 改进Retinaface算法用于口罩检测
为了实现在人口密集场所的实时口罩检测,本文在以MobileNet0.25为骨干网络的Retinaface算法上增加多分类任务,并提出一种改进Retinaface的网络结构,主要从特征融合网络和骨干网络2个方面进行改进。采用Resnet50骨干网络的Retinaface算法模型复杂,参数量大,较易产生过拟合,多任务损失可以使不同任务相互作用,提高学习的效果。为了部署在低算力的设备上,本文采用轻量级骨干网络,参数量较少,过拟合情况不明显,同时,为了降低数据标注难度,在多任务损失中舍去了用于人脸对齐的人脸关键点损失以及用于3D人脸分析的面部密集点回归损失等无关的检测任务。
2.1 改进的多尺度特征图融合网络
特征提取过程中,浅层的网络包含的细节特征更丰富,可以用于检测简单的目标;深层的网络则包含更多的深层语义信息,但是对于小物体也就是细节的检测并不是很好。特征融合网络将2种特征信息进行融合,实现特征增强,同时避免了使用单一特征信息而造成大量信息丢失。原始Retinaface算法的特征融合网络为特征金字塔网络FPN(Feature Pyramid Network)。特征金字塔网络是一种有效的特征融合网络,通过对输入图像进行卷积和池化操作,获得不同尺寸的特征图,再使用不同尺寸的特征图同时进行预测,使用浅层的特征检测简单目标,使用深层特征检测复杂目标,使网络在增加较少计算量的前提下融合低分辨率语义信息较强的特征图和高分辨率语义信息较弱但空间信息丰富的特征图。在口罩佩戴检测的任务中,为了进一步提高对小目标的检测能力,网络模型需要利用更多的细节信息,因此需要对FPN进行改进。本文提出一种双重级联金字塔网络DC-FPN(Dual Cascade FPN),把FPN输出的特征再次输入类似FPN的结构中,先通过自底向上的信息流,利用低层次特征对其他层次特征进行加强,提升网络对细节的感知能力,然后通过上采样生成3种不同尺度的有效特征层。最后,因为进行了多次的降采样和上采样操作,会使深层网络的定位信息产生误差,所以将生成的3种不同尺度的特征图分别与原始FPN输出的特征图进行concat操作,进行拼接后再进行预测。双重级联金字塔结构如图2所示。
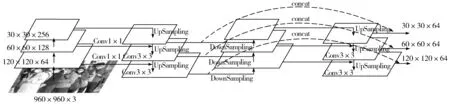
图2 双重级联金字塔网络结构图
2.2 改进的骨干网络
在深度学习目标检测任务中,尽管类似Resnet网络的残差网络相比简单网络有更高的精度,但缺点也很明显。由于残差网络多分支的结构,使显存占用明显增加,也降低了模型的推理速度。多分支网络的优点是利于训练,而不利于推理。而VGG式模型仅使用3×3卷积,在GPU上,3×3卷积的计算密度可达1×1和5×5卷积的4倍,同时,VGG式模型没有任何分支,运算并行度高,节省显存占用。口罩佩戴检测通常部署在小型设备上,计算力有限,通常要求模型较小,推理速度较快,同时满足较高的识别率。为更好地满足口罩识别任务的部署需求,并在保证较高精度的情况下加快推理速度,本文引入RepVGG(Re-parameterization Visual Geometry Group)网络。在训练阶段,RepVGG网络使用identity和1×1分支构建多分支结构提升网络性能,在推理时,RepVGG网络可以通过模型重构,把训练时使用的多分支结构重新参数化,即通过参数的转换,将模型训练时的多分支网络结构和参数转换为推理时的单路网络结构和参数,使RepVGG同时兼顾多分支模型训练时的优势和单路架构推理快、节省内存的优势。RepVGG部分结构如图3所示。
图3 RepVGG训练和推理时的结构图
在模型推理阶段的重参数化过程中,先对残差块中的卷积层和BN层进行融合,计算公式为:
(2)
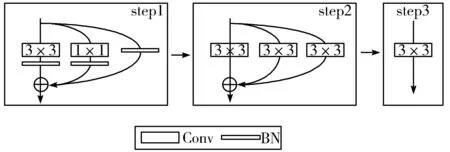
图4 模型重构转换过程
2.3 改进的Retinaface算法模型
本文将Retinaface算法通过对骨干网络和特征融合网络进行改进。针对轻量化口罩检测任务,本文引入RepVGG-A0作为Retinaface算法的骨干网络,训练时,把原始图片调整为大小960×960的3通道图像,经过数据增强后,传入RepVGG-A0骨干网络。RepVGG-A0共5个stage,分别包含1、2、4、14、1个块,每个块除了第一个单元,都包含identity分支。经过骨干网络后,第3、第4、第5个stage的输出分别通过Conv(1×1)+BN+LeakyRelu的组合,卷积核步长为1,输出3个有效特征层,将3个特征层输入双重级联金字塔网络DC-FPN中,得到3种不同尺度的特征图。最后将金字塔网络输出的3种不同尺度的特征图输入上下文模块进行预测,本文算法结构如图5所示。
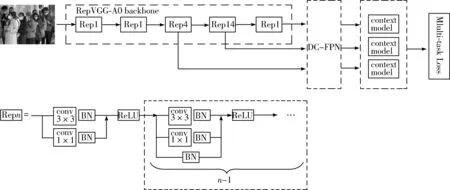
图5 本文算法网络结构
3 实验与结果分析
3.1 实验平台
本文算法在Ubuntu 18.04操作系统中实现,深度学习框架为Pytorch1.6.0,使用GPU加速工具CUDA 10.2,编程语言采用Python 3.8。硬件配置包括AMD RyzenTM7 4800H,Nvidia GeForce RTX 2060显卡,16 GB内存。
3.2 数据集构建和模型训练
目前人脸口罩佩戴图片较少,本文使用WIDER FACE开源人脸图片数据集和MAFA(Masked Faces)[22]开源口罩遮挡人脸数据集部分图片,并通过互联网收集,自制了人脸口罩佩戴数据集。使用labelimg标注软件对数据集进行统一标注,标签分别为:face(人脸)、mask(佩戴口罩人脸)。标注的信息为目标框左上角和右下角点的坐标。数据集共8875张图像,按照8:2的比例将数据集随机划分训练集和测试集。训练集共包含7100张图像,测试集共包含1775张图像,为了验证本文算法对不同尺度目标的检测效果,将测试集分为easy、medium、hard这3种不同难度的子测试集,easy难度共827张,medium难度共587张,hard难度共361张,测试集示例如图6所示。模型训练方法采用随机梯度下降法(Stochastic Gradient Descent, SGD)。初始学习率设置为10-3,动量设置为0.9,batchsize为4。当网络训练110个轮次(epoch)后学习率下降到10-4,然后在第130个轮次(epoch)学习率下降到10-5,整个训练过程一共进行150个轮次结束,共迭代266250次。训练结束后,加载训练好的模型,对该模型执行模型重参数化操作,再加载重参数化后的模型,执行模型推理。另外,在相同的实验环境下,使用相同的训练方式,本文训练了一个以MobileNet0.25为骨干网络的原始Retinaface网络模型,用于分析和比较。

(a) easy (b) medium (c) hard 图6 测试集图片示例
3.3 评价指标
本文选择平均精度(Average Precision, AP),平均精度均值(mean Average Precision, mAP)作为目标检测算法的评价指标。每秒传输帧数表示每秒处理的图片数量,本文使用每秒传输帧数FPS(frames per second)来测试模型的检测效率。
平均精度AP的值反应单一目标的检测效果,其计算方式为:
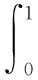
(3)
其中,p(r)表示精确率(Precision,P)和召回率(Recall, R)的映射关系,精确率P和召回率R的计算方式为:
(4)
(5)
其中,TP表示检测模型检测正确的样本数量;FP表示检测模型检测错误的样本数量;FN表示没有被检测出来的样本数量。
mAP表示所有类别平均精度的均值,反映了总体上的目标检测效果,其计算方式为:
(6)
其中,n表示类别的个数,i表示某个类别。
3.4 结果分析
为了使本文算法可以在自然场景下进行口罩佩戴检测,本文引入的RepVGG-A0通过结构重参数化可以有效降低模型大小和计算量。训练过程中,边界框回归损失函数和分类损失函数的变化情况如图7所示。模型重构后,本文算法的模型参数量由12.3 MB减小到11.0 MB,模型减小10.56%。模型推理时的帧速率由64.94 fps提高到92.59 fps,结构重参数化后的模型参数量对比和输入为640×640时与其他主流算法的帧率对比如表1所示。虽然以MobileNet0.25为骨干网络的Retinaface算法检测效率更高,达到133.033 fps,但本文算法对小目标的检测效果显著高于原算法,且充分满足实时检测的需求,可以满足在移动端和嵌入式端部署的需求。
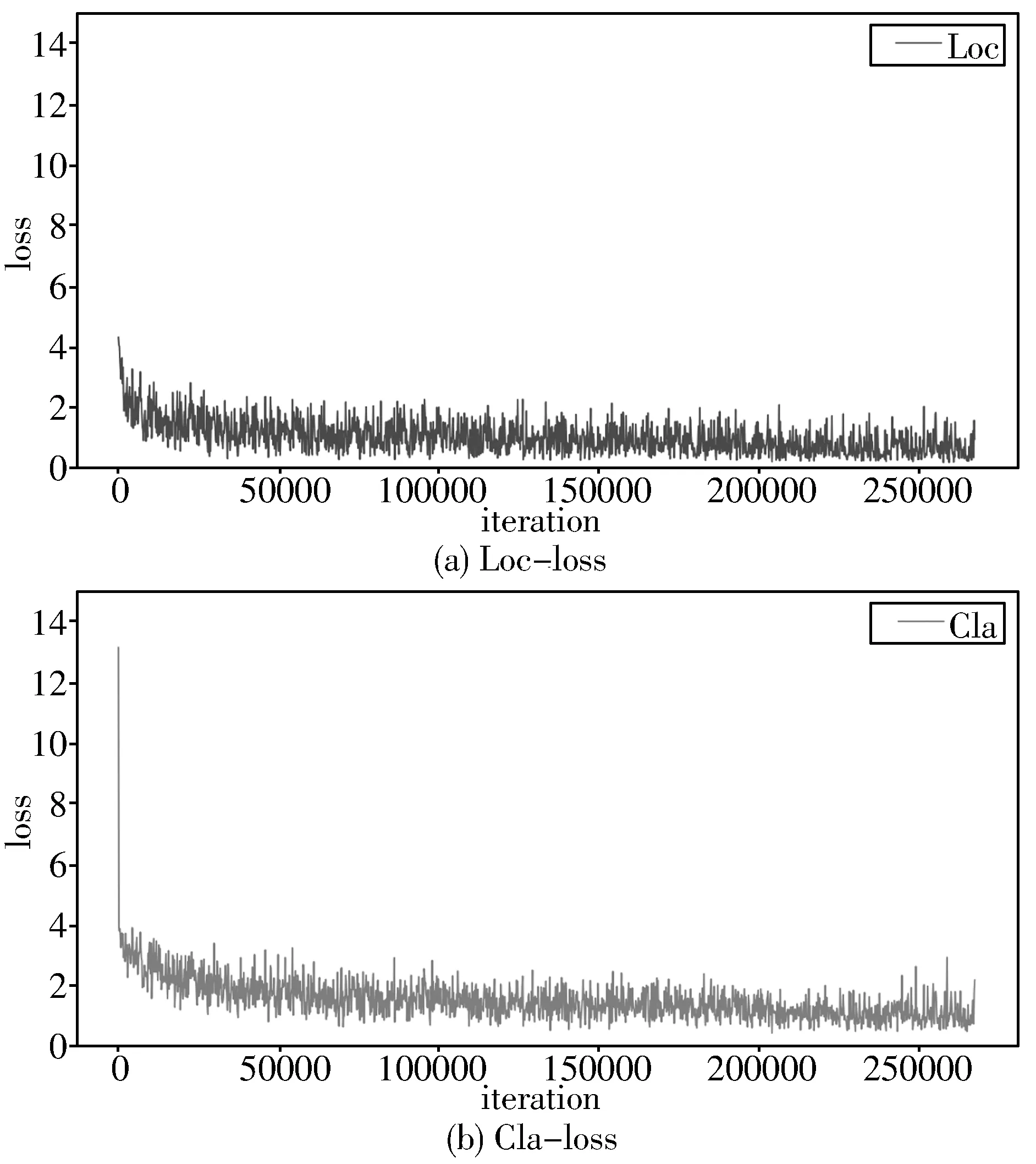
图7 损失函数变化情况
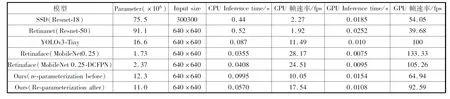
表1 GPU RTX2060与CPU R7-4800H实时性对比
为了研究骨干网络和特征融合网络对模型的影响,将本文算法裁剪成3组分别进行训练和测试,模型①为基于MobileNet0.25骨干网络的原始Retianaface算法,模型②在模型①基础上增加了双重级联金字塔网络DC-FPN,模型③在模型②的基础上增加了RepVGG-A0骨干网络,在不同难度的测试集上进行对比分析。为了进一步验证本文算法的有效性,与SSDRetinanet和YOLOV3-Tiny算法进行对比。本文将IoU设置为0.5时的实验结果如表2所示。
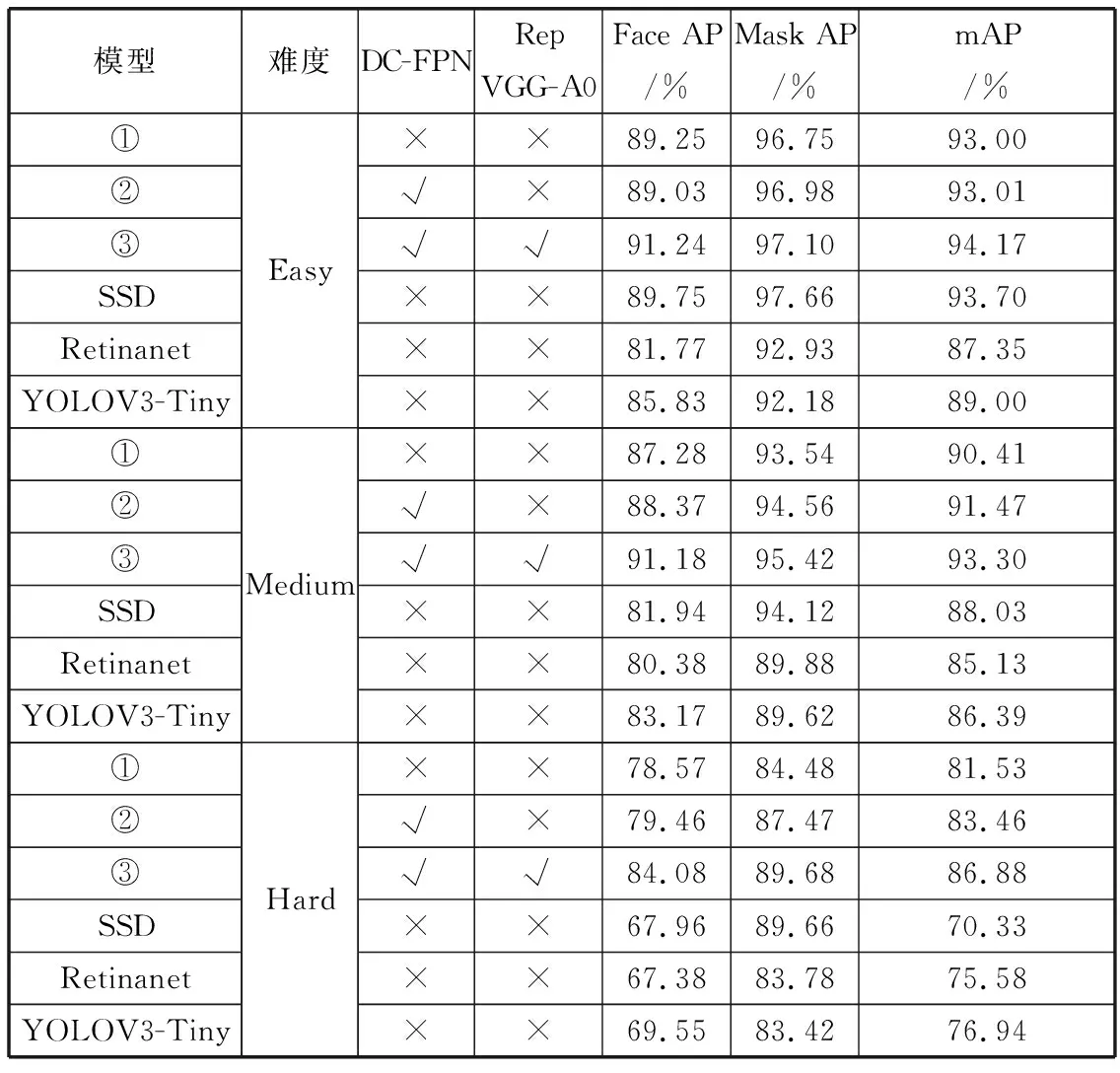
表2 实验结果性能对比
从表2可以看出,在easy难度上,检测目标较大,特征较好提取,主流算法和本文算法均取得了不错的检测效果,但相比之下模型③即本文算法仍然取得较高的测试结果。在medium难度上,模型②增加了双重级联金字塔网络DC-FPN后,对比原始算法,mAP提高了1.06个百分点,说明改进的DC-FPN结构丰富了3个有效特征层的细节信息,进一步提升了网络的检测效果。模型③相比模型②,引入了RepVGG-A0骨干网络,人脸目标检测和人脸佩戴口罩目标检测的AP值分别提高了2.81个百分点和0.86个百分点。口罩检测AP值相对人脸检测AP值提高较少,因为口罩遮挡人脸减少了大部分人脸特征且medium难度检测目标相对较大,口罩遮挡人脸特征相对容易提取,所以模型①和模型②也取得了不错的检测效果。在hard难度上,检测目标均为较小的目标,模型②比模型①mAP提高了1.93个百分点,模型③相比于模型①,2种类别AP值分别提高了5.51个百分点和5.20个百分点,mAP提高了5.35个百分点,取得了显著的提高效果。说明带有残差结构的RepVGG网络相比MobileNet0.25网络具有更强的学习能力。同时,对比其他主流算法,本文算法在各个难度的验证集上均取得了较好的检测效果。综上,本文对Retinaface算法的改进明显提高了人脸佩戴口罩检测效果,尤其针对自然场景下的小尺度目标检测效果提高显著。具体检测示例效果如图8所示。

图8 不同算法结果对比
第一组图片中,SSD和Retinanet算法检测小目标的效果明显不如Retinaface和YOLOV3-Tiny算法,但本文算法置信度更高。第二组图片中,针对中等尺度口罩目标,主流算法也得到了良好的检测效果,但本文算法检测出后方屏幕上的目标,说明本文算法对小目标的检测效果和分类效果均有显著提高。第三组中,本文算法在口罩目标较密集的情况下,相比其他算法,漏检情况较少,置信度较高,取得了更好的检测结果。综上,本文算法对于人脸佩戴口罩的检测效果明显优于Retinaface算法和其他算法,能够应对自然场景中目标密集,小尺度目标较多等问题,可以有效地进行口罩佩戴检测。
4 结束语
本文通过改进Retinaface算法,提出一种改进的轻量级结构重参数化网络,为了加强网络对细节的感知能力,引入双重级联金字塔网络(DC-FPN),把FPN输出的特征再次输入类似FPN的结构中,先通过自底向上的信息流,利用低层次特征对其他层次特征进行加强,然后进行上采样生成3种不同尺度的有效特征层,最终提高了对多尺度目标的检测效果。为更好地满足算力有限设备的口罩识别任务部署需求,并在保证较高精度的情况下加快推理速度,引入RepVGG-A0骨干网络,通过模型参数重构,把训练时的多分支模型转换为推理时的单路模型。实验表明,在口罩佩戴检测任务中,本文算法在easy、medium、hard这3个难度的测试集上,分别提高了1.06个百分点、2.59个百分点、5.96个百分点,检测速率达到92.59 fps,满足实时性要求,可以很好地胜任人脸口罩佩戴检测任务。但本文算法仍有改进空间,如何使轻量化网络在保证检测速度的同时让检测准确率接近大型网络,同时,满足更丰富的使用场景是接下来待解决的问题。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
当代水产(2019年11期)2019-12-23 09:02:54
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
动漫星空(2018年9期)2018-10-26 01:17:14
知识经济·中国直销(2017年5期)2017-06-15 20:28:19
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
