
改进EasyEnsemble的软投票策略下的用户购买预测方法
2022-07-29 06:22:34杨进,张晨
计算机与现代化 2022年7期
杨 进,张 晨
(上海理工大学理学院,上海 200093)
0 引 言
用户的购买行为预测一直是零售行业的重要课题[1-3],伴随着大数据时代的到来,人们生活、行为和思考方式发生了变化,同时也提供了大量的数据用于挖掘分析。网民们在电商平台上购买商品,往往伴随着浏览、加购物车和收藏的行为,因此电子商务平台储存了大量的用户购物历史数据,分析这些数据可以更好地预测他们的购物习惯、偏好和意图。本文主要研究消费者网上购买行为的预测,进而网站能够根据用户的喜好推荐用户感兴趣的产品,从而改善用户体验,改善网上购物环境。
对于该问题国内方面,李旭阳等人[4]提出了长短期记忆模型循环神经网络(Long Short-Term Memory, LSTM)[5]和随机森林相结合的预测模型,他们从原始数据中分别提取静态特征和动态特征。静态特征指用户和商品本身的属性特征。动态特征指用户对商品发生交互行为产生的特征。对这些特征通过LSTM进行特征选择,再用随机森林算法做预测。刘潇蔓[6]先是从原始数据中分别提取用户特征、商品特征和用户-商品特征,再通过“滑动时间窗”[7]的方法对历史数据反复使用使得正负样本得以均衡,而后用极端随机树(Extra-tree)的方法提取特征,最后将逻辑斯特回归[8]和支持向量机用软投票(Softvoting)方法相结合后进行预测。周成骥[9]也是通过滑动时间窗的方法来提取新数据,在生成新的特征后,通过求各个特征的皮尔逊相关系数[10]进行特征选择,再通过装袋算法(Bootstrap aggregating, Bagging)把多个极限梯度提升算法(Extreme Gradient Boosting, XGBoost)的预测结果结合后进行预测。胡晓丽等人[11]使用“分段下采样”的方法来平衡样本数据,在特征工程生成衍生特征后用卷积神经网络(Convolutional Neural Networks, CNN)[12]进行特征选择,通过算法LSTM进行预测,实验结果表明,基于CNN-LSTM的预测模型F1值相比基准模型得到了提高。杜世民[13]主要研究电商的复购行为,详细分析了用户的购买行为习惯,分别从用户和商品2个方面构建关联特征,最后用软投票策略将多算法融合后进行预测。
国外方面,Tian等人[14]提供了一种新模型解决Pareto/NBD模型的缺陷,只需要购买行为的频率和时间就可以预测电子商务中消费者的复购行为。Zuo等人[15]通过收集消费者在超市产生的射频识别(RFID)数据,用支持向量机(Support Vector Machines, SVM)模型去预测消费者的购买行为[16]。Chang等人[17]通过聚类分析收集忠诚顾客的关键特征来定位潜在客户,通过关联分析收集忠诚客户的购买信息来预测潜在客户对产品的近期兴趣。Cho等人[18]提出了一种基于最近一次消费、消费频率和消费金额的增量加权挖掘方法来进行用户购买行为预测,并验证了该算法的有效性。Gupta等人[19]对在线客户灵活定价,帮助客户寻找一个合适的价格去购买,并通过机器学习的方法来预测不同价格下的客户购买决策。
实际情况中,由于购买的数量远远小于未购买的数量,造成了样本的不均衡。对于该问题,本文采用简单欠采样方法和改进的EasyEnsemble[20]采样方法。简单欠采样以发生购买行为和未发生购买行为按比例为1∶1进行采样,改进的EasyEnsemble采样方法按发生购买行为和未发生购买行为的采样比这种接近原始的数据进行采样。本文通过阿里巴巴天池大赛[21]所提供的数据经过数据处理后做特征工程,生成新的衍生特征,再通过互信息的方法进行特征选择。本文提出使用改进的EasyEnsemble算法下的软投票策略方法对数据做预测,然后将预测结果与传统的机器学习方法的结果相对比,也将简单欠采样、EasyEnsemble和改进后的EasyEnsemble这3种方法得出的预测结果作对比,得出结论。
1 特征模型
本文所使用的数据来源于阿里巴巴提供的2014年11月18日到2014年12月18日的10000名用户在某网站上的用户与商品的历史交互记录。由于无法从这些数据中得到实用的特征数据,所以必须对原始数据进行特征提取。原始数据特征如表1所示。

表1 原始特征
本文根据表1所给出的原始特征来提取新的特征,同样也把它们分为用户特征、商品特征和用户-商品特征3个特征类别。
1.1 用户特征
用户特征保留了原始特征User_id,而对于特征User_geohash缺失数据超过了总数据的2/3,并且对数据进行了加密处理,因此数据间不具有相关性,所以将该特征值剔除掉。新加入的用户特征有用户的活跃度(userF1),即对某用户在过去一段时间购买、添加购物车、收藏和浏览的次数的加权和。用户的购买浏览转化率(userF2)、用户的购买加购物车转化率(userF3)和用户的购买收藏转化率(userF4),是用户在过去的某段时间购买商品的次数分别与用户浏览、加购物车和收藏次数的比值。用户购买数量(userF5)、浏览数量(userF6)、加购物车数量(userF7)、收藏数量(userF8)分别是用户在过去一段时间购买商品的次数和、浏览商品的次数和、对商品加购物车的次数和和收藏商品的次数和。
1.2 商品特征
商品特征保留了原始特征item_id和item_category,增添了新的商品特征。如商品浏览数量(itemF1)是指商品在过去某段时间被浏览的数量;商品收藏数量(itemF2)是指商品在过去的某段时间被收藏的数量;商品加购物车数量(itemF3)是指商品在过去某段时间加购物车的数量;商品购买数量(itemF4)是指商品在过去某段时间被购买的数量;商品热度(itemF5)是指商品在过去的某段时间购买、添加购物车、收藏和浏览的次数的加权和;商品种类热度(itemF6)是指商品不同的种类在过去的某段时间里购买、添加购物车、收藏和浏览次数的加权和。
1.3 用户-商品特征
对于用户-商品特征,本文将用户购买商品的时间划分为日期和具体的时刻,用户-商品的原始特征无法作为所需要的特征直接使用,但是用户特征、商品特征以及用户-商品特征当中的新特征都是从特征Behavior_type和Time中提取出来的。提取出新的用户-商品特征有用户-商品热度(item_userF1)和用户对商品的购买行为(item_userF2)。用户商品热度是某用户对某商品在过去的某段时间购买、添加购物车、收藏和浏览的次数的加权和。用户对商品的购买行为则是在过去的某段时间用户是否购买过某商品,购买过则设为1,未购买则设为0。用户商品浏览数量(item_userF3)、用户商品收藏数量(item_userF4)、用户商品加购物车数量(item_userF5)、用户商品购买数量(item_userF6)分别指用户在过去的一段时间对某个商品浏览的次数和、收藏的次数和、加购物车的次数和和购买的次数和。
由于不同的时间刻度对当前的预测影响不同,所以选取了5个时间刻度9天、7天、5天、3天、1天,对不同的时间刻度通过以上方式提取特征,再加上保留的部分原始特征,总共有108维特征。
2 算法介绍
2.1 互信息算法
互信息[22]是一种信息度量方式,可以看成为一种随机量包含另一种随机量的信息量。
设2个随机变量(X,Y)的联合分布为p(x,y),边缘分布分别为p(x)、p(y),互信息I(X;Y)是联合分布p(x,y)与边缘分布p(x)、p(y)的相对熵,即:
(1)
公式(1)可计算每一个特征和目标值的互信息值,本文通过大小顺序排列,选择互信息值较大的特征。
2.2 XGBoost算法
XGBoost[23]是根据梯度提升实现的半监督学习算法,可以解决分类、回归等问题。训练采用的数据集样本为(xi,yi),其中xi∈Rm,yi∈R。xi表示m维的特征向量,yi表示样本标签,模型包含K棵树,则XGBoost模型的定义如下:
(2)
其中,fK(xi)表示第K棵决策树,它映射样本特征,使每个样本落在该树的某个叶子节点上,FK(xi)表示K棵决策树的预测结果的累加和。每个叶子节点均包含一个权重分数,作为落在此叶子节点的样本在该树的预测值ω。计算样本在每棵树的预测值(即ω)之和,并将其作为样本的最终预测值。
XGBoost的目标函数定义如下:
(3)
其中,目标函数Obj由2项组成:第一项为损失函数和;Ω(f)项为正则项,倾向于选择简单的模型,避免过拟合。正则化项的定义如下:
(4)
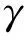
为找到最优的f(xi)使目标函数最优,对公式中的目标函数XGBoost采用了近似的方法。对式(3)改写为:
(5)
XGBoost引入泰勒公式近似和简化目标函数。取二阶泰勒公式的定义如下:
(6)
(7)
式(7)中,gi为损失函数的一阶梯度统计;hi为二阶梯度统计。gi、hi计算公式分别如下:
(8)
(9)
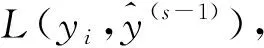
(10)
2.3 随机森林
随机森林[24]是一种集成学习方法,该方法结合Bagging[25]集成学习理论和随机子空间方法,将多个决策树作为基分类器,以一定策略选取部分属性和数据分别建树;在预测阶段根据森林中各棵树的预测结果进行投票表决,最终表决结果为随机森林预测结果。
2.4 软投票策略
软投票[26]也称加权平均概率投票,是使用输出类概率分类的投票法,其通过输入权重,得到每个类概率的加权平均值,并选择值较大的那一类。
2.5 EasyEnsemble算法
EasyEnsemble[27]算法主要处理类别不平衡问题,使样本数据能得到充分利用。
算法流程主要描述如下:
输入:所有大类样本数据N;所有小类样本P;从N中采样的子集数量m。
输出:集成模型H(x)。
1)fork=1:m
2)从N中随机采样子集Ni,且满足|Ni|=|P|。
3)将小类样本集合P和大类样本子集Ni组合成一个均衡的训练样本子集Ni∪P。
4)在训练样本子集Ni∪P上训练分类器:
(11)
其中,hk,j(x)是Hk的第j个弱分类器,αk,j为hk,j(x)所对应的权重,θk为集成的阈值。
5)end for
6)集成模型为:
(12)
3 模型构建
本文模型主要分为3个步骤:1)产生训练样本子集;2)训练基分类器;3)基分类器融合。
3.1 产生训练样本子集
先将数据集分为购买和未购买2个大类,再从这2类数据中进行随机抽样,使抽取的测试集数据中购买和未购买这2类数据比例接近数据集中购买与未购买的数量比,再对抽取的数据进行特征提取,得到训练样本集。
3.2 训练基分类器
随机森林(RF)是机器学习中常用的解决分类问题算法之一,是一个包含多个决策树的分类器。
XGBoost是基于提升树模型设计的,还支持二阶导数运算和并行计算,可以利用正则项控制模型复杂度,准确率高。
本文选择XGBoost和随机森林作为基分类器,用改进的EasyEnsemble算法来解决类别不平衡的问题。为了方便调节参数,用一般网络搜索和贝叶斯方法调参,都会花费大量时间,本文通过逐步调节各个参数,根据F1值的大小来选取较优的参数。
3.3 基分类器的集成
通过前2步的工作,可以得到m个经由不同的训练集进行训练的以软投票策略融合XGBoost和RF的基分类器。运用EasyEnsemble的方法将这些基分类器通过公式(12)联合起来做预测。
给定样本x=(x1,x2,…,xn),xi∈Rm,集成模型有m个基分类器h1(x),h2(x),…,hm(x),则对于样本x,其集成输出的结果为:
(13)
3.4 本文算法描述
输入:未购买行为样本N和发生购买行为样本集P,且使得样本集N与P的比值关系满足数据集中未购买行为和发生购买行为的数据比;基分类器的个数m;
输出:购买行为预测结果H(x)。
1)对样本集N中的数据进行排序,按照顺序不重复地均匀划分为m个子样本集Ni(i=1,2,…,m);
2)将样本集Ni分别与样本集P组合成m个训练集train_datai(i=1,2,…,m);
3)令hi=Softvoting(RF,XGBoost)(i=1,2,…,m),对测试集test_data预测得到m个结果;
4)将得到的m个结果hi(x)代入式(13),得到最终的二分类预测结果。
3.5 本文算法优势
在处理样本类别不平衡问题上,本文采用改进的EasyEnsemble的采样方法。传统的EasyEnsemble方法从大类样本随机选取和小类样本相同的数据,会导致样本数据不能够全面地利用大类样本数据。相比传统的EasyEnsemble方法,改进后的EasyEnsemble方法将反例均匀划分成若干个集合分别与正例一起供不同的分类算法学习,这样不仅可以充分利用样本数据,又可以借鉴Bagging的思想来降低算法预测结果的偏差。通过软投票的方法将XGBoost和随机森林进行结合后做预测,降低了单一算法预测产生的概率偏差,可以使一些预测概率接近0.5的数据得到正确预测,从而优化预测效果。
4 参数优化
4.1 XGBoost调优
max_depth、min_child_weight和colsample_bytree是XGBoost的3个重要参数。max_depth为决策树的最大深度,取值范围为1~32,其F1曲线如图1所示。min_child_weight表示叶节点的最小样本权重,取值范围为1~6,其F1曲线如图2所示。colsample_bytree表示样本特征采样比,取值范围为0.5~1,其F1曲线如图3所示。

图1 在XGBoost中关于max_depth的F1曲线
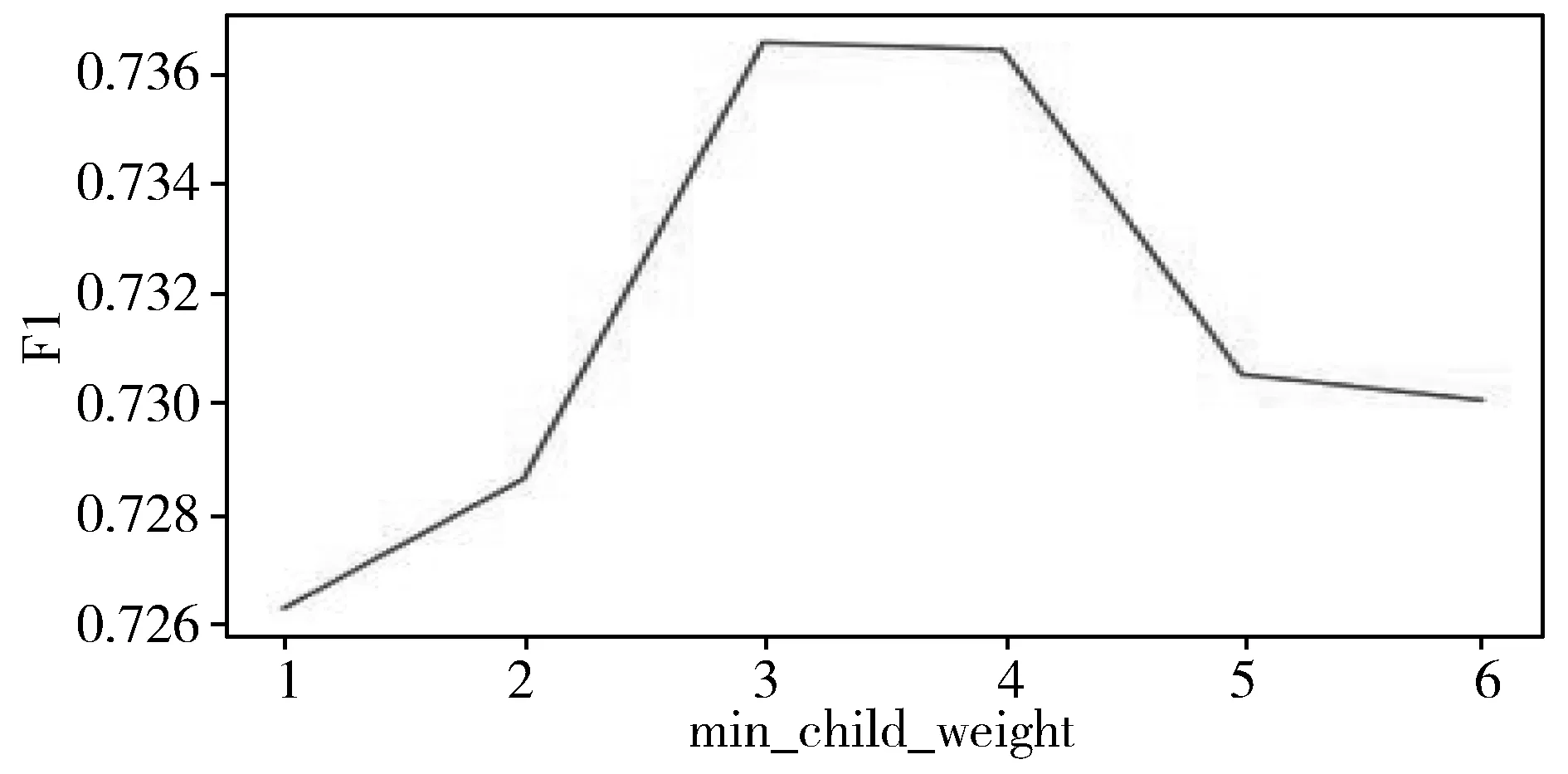
图2 在XGBoost中关于min_weight_child的F1曲线

图3 在XGBoost中关于colsample_bytree的F1曲线
由图1~图3可知,本文实验得到的XGBoostt算法的最优参数选择如下:max_depth为10,min_child_weight为3,colsample_bytree为0.74。
4.2 随机森林调优
n_estimators、max_depth、min_child_leaf是随机森林的3个重要参数。n_estimators是决策树的数量,取值范围为10~200,其F1曲线如图4所示。max_depth为决策树的最大深度,取值范围为1~40,其F1曲线如图5所示。min_child_leaf表示最小的叶节点样本数,取值范围为1~50,其F1曲线如图6所示。
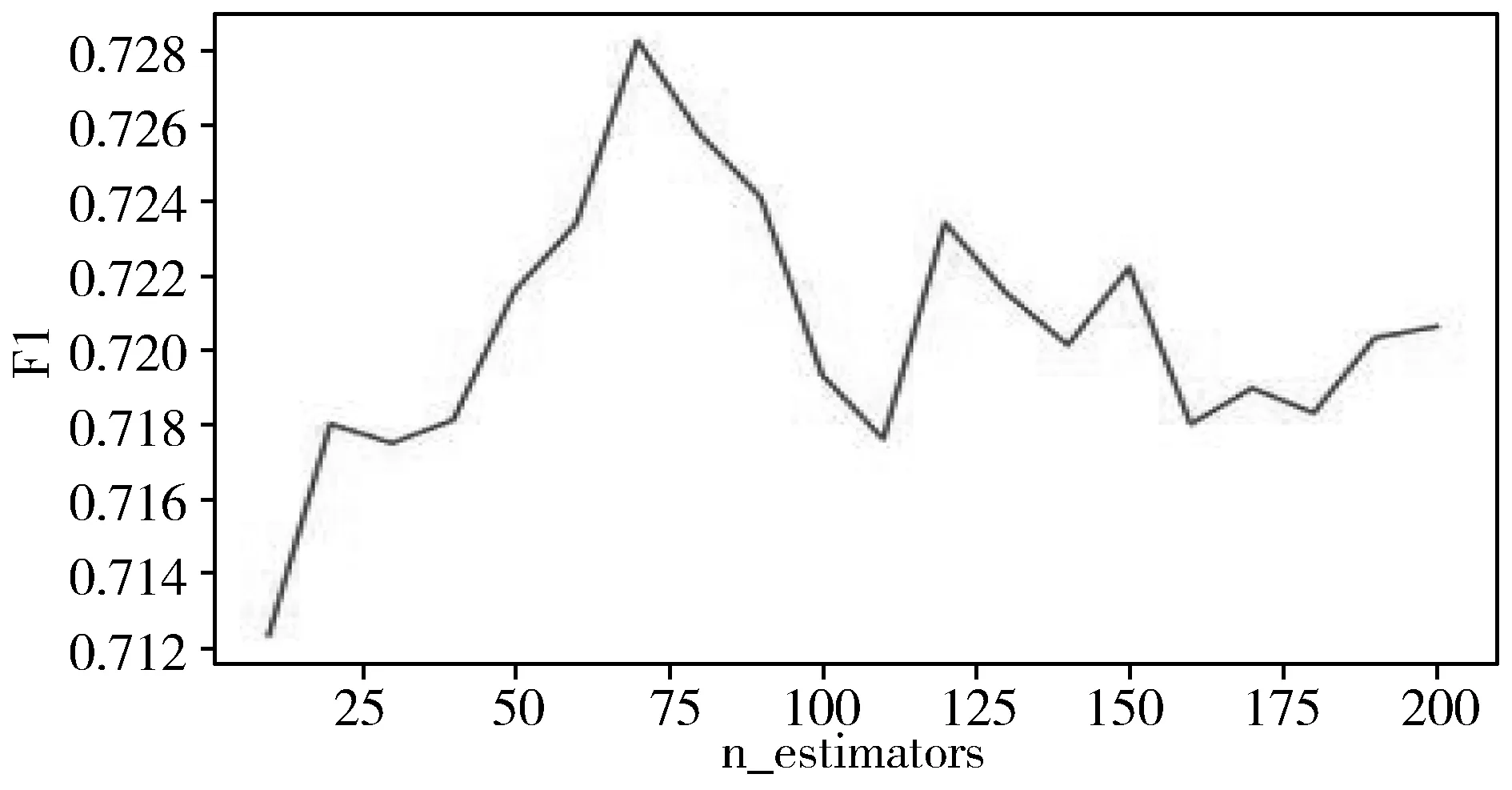
图4 在随机森林中关于n_estimators的F1曲线
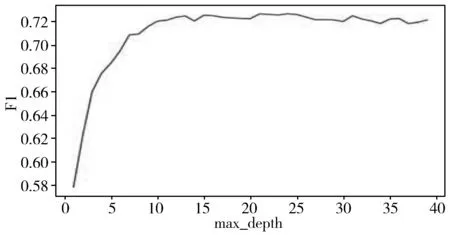
图5 在随机森林中关于max_depth的F1曲线
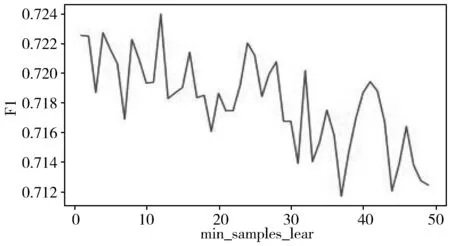
图6 在随机森林中关于min_samples_leaf的F1曲线
由图4~图6可知,本文实验得出的随机森林算法的最优参数选择如下:n_estimators为70,max_depth为15,min_samples_leaf为12。
5 实验及结果分析
5.1 实验数据集
本文实验数据来源于阿里巴巴天池大赛提供的2014年11月18日到2014年12月18日移动电商平台数据集,以11月中的27日、28日和29日用户对商品的交互行为实验数据,其中行为信息有浏览、收藏、加购物车、购买4种方式。
5.2 数据预处理
对于提供的数据,先将重复数据去掉,再对数据进行特征提取。对于生成的大量空数据,根据实验数据的特点来进行填充,提取购买浏览转化率、购买收藏转化率、购买加购物车转化率的特征时,浏览、收藏、加购物车的次数为0,则特征为空值的意义是接近于无穷大,那么选择用相对较大的数据进行填充。特征工程结束后,对数据进行归一化处理,用互信息的方法对数据进行特征选择,选择了互信息值较大的58个特征。
5.3 评价指标
本文采用精确率P、召回率R和F1值这3个指标来对模型的性能进行评估。其中,将预测类别组合化为真正例(TP)、真负例(FP)、假正例(TN)、假负例(FN),3个指标的计算公式为:
5.4 实验设计
为了验证本文提出的预测模型及算法的有效性,实验使用上述的数据集和评价标准,与当前热门的机器学习模型进行纵向对比,其中包括逻辑回归模型(LR)、支持向量机模型(SVM)、随机森林模型(RF)、梯度提升树模型(GBDT)和极限梯度提升模型(XGBoost)。再对数据集进行不同采样方法的横向对比,其中包括简单欠采样、EasyEnsemble和改进后的EasyEnsemble这3种采样方法。最后对特征选择前和特征选择后的数据结果进行对比。
5.5 实验结果
以精确率P、召回率R和F1值为评价指标,与当前热门的机器学习算法进行纵向对比,与不同的采样方法进行横向对比,特征选择前的对比见表2,特征选择后的对比见表3。
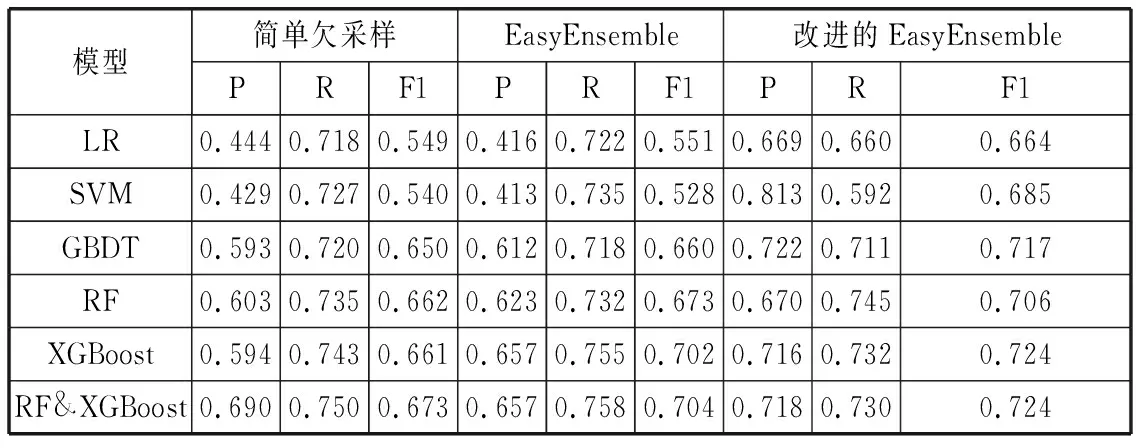
表2 特征选择前的不同算法对比

表3 特征选择后的不同算法对比
1)所有对比实验中,本文改进的EasyEnsemble的软投票策略模型的P值和F1值最高,说明对用户购买行为预测效果最好。
2)2种关于EasyEnsemble采样方法都比简单欠采样方法预测结果更好,说明平衡样本数据对于模型的训练十分有必要。
3)进行特征选择后的预测结果不仅没有低于特征选择前的预测结果,甚至还略优于特征选择前的预测结果,说明特征选择不仅能够减少计算量,还能减少一些带有噪声的数据。
4)本文算法的分类效果比其它的模型要优秀很多,主要是因为改进的EasyEnsemble的采样方法能够使全局数据参与模型训练,而且也降低了模型的偏差和方差。使用本文的方法,使P值和R值更加均衡,从而提高F1值。
5.6 特征有效性实验
关于各个特征在商品购买预测的重要性,可以在删去某些特征后,通过训练分类器得到F1值来判断,F1值越小,则删去的特征重要性越强。本文将分别对用户特征、商品特征和删除用户-商品特征作对比,如表4所示。再分别删除关于不同时间形成的特征作对比,如表5所示。
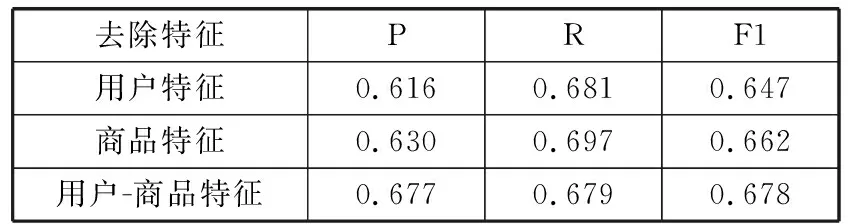
表4 不同属性特征对预测结果的影响
由表4得知,删除用户特征、商品特征或者用户-商品特征,其F1值均有下降,说明这些特征对于商品销售预测均有意义。从这3种特征的比较中,发现去除用户特征后,F1值较去除另外2种特征有明显下降,说明在用户购买预测中,用户特征发挥着更重要的作用。

表5 不同时间构造的特征对预测结果的影响
由表5得知,删除由时间刻度9天生成的特征对预测值的影响最大,F1值的下降也更为明显,说明在给用户推荐商品时,9天以内的销售记录发挥很重要的作用,也更能显示用户网上购物的倾向程度。
6 结束语
本文提出了一种改进的EasyEnsemble算法的软投票策略下用户购买预测方法。通过分析阿里巴巴天池大赛所提供的数据,从用户、商品和用户-商品方面提取了108个特征。使用互信息的方法对数据进行特征选择,一方面降低了计算量,另一方面消除了部分数据噪声。在处理类别不平衡问题方面,使用了改进的EasyEnsemble算法,与简单采样法和传统EasyEnsemble算法相比,它利用了集成学习机制,将反例均匀划分成与正例数量相同的若干组数据,用分类算法对每组数据进行训练,这样就可以将全局数据进行充分利用。用软投票的方法将XGBoost和随机森林结合起来进行训练,再作为一个分类器做预测。用改进的EasyEnsemble算法可以把Bagging和Boosting方法结合起来,降低偏差和方差。通过用软投票的方法将XGBoost和随机森林进行融合的方法与单一的算法相比,可以更好地判断一些“似是而非”的数据,从而提高了F1值。在与热门的机器学习算法进行对比实验后,本文提出方法具有更高的F1值,表明本文模型更加有效,也能更好地解决用户购买预测问题。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2018年1期)2018-04-18 11:52:35
数学学习与研究(2017年3期)2017-03-09 18:12:42
电子制作(2017年23期)2017-02-02 07:17:06
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国老区建设(2016年1期)2016-02-28 09:32:00
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2014年15期)2014-04-04 12:05:20
